
Abstract
In the study of wireless ad hoc and sensor networks, clustering is an important research problem as it aims at maximizing network lifetime and minimizing latency. A large number of algorithms have been devised to compute “good” clusters in a WSN but few papers have tried to characterize these algorithms in an analytical manner. In this paper, we use a local world model to understand and characterize the functioning of three tree based clustering algorithms. In particular, we have chosen simple tree, CDS Rule K, and A3 topology construction protocols. Using our theoretical framework based on a complex network model, we have also tried to quantify some of the observed features of these algorithms such as number of cluster heads and average degree of the resultant graph. The theoretically obtained measures have reasonably matched with measures obtained by simulation studies.
1. Introduction
Wireless sensor networks (WSNs) are made up of a large number of sensor nodes. These nodes are usually deployed in the environment to monitor several physical phenomena. However, sensor nodes heavily depend on batteries as they are the only source of energy in many WSN applications. As a result, one major problem in WSNs is known as topology management that leads to energy efficient transmission of data. In this regard, connections are set with nodes that are close enough for radio signal to arrive with acceptable signal strength. However, in order to improve energy efficiency, topology control process helps in reducing the connections with other neighbors of the node in the network. Topology control is an insistent process in which there is an initialization phase which is common to all WSN deployments. In the initialization phase, nodes make use of the revelation process by using maximum transmission power to build the initial topology. The initial network topology includes connections and nodes that allow direct communication and every node communicates with a subset of the nodes according to the distance between them.
Often, the topology of a large wireless network is structured in terms of a hierarchy where the network is viewed as a number of clusters and in each cluster there is a cluster head and other normal members. Normal members in a cluster communicate only with the cluster heads and the cluster heads communicate with the sink in one or multihop manner. There are many challenges in finding out the “best” set of cluster heads in a given network and, in many formulations, these problems turn out to be intractable. Consequently, there are many algorithms to select the cluster heads and the clusters in a WSN that minimizes latency and maximizes network lifetime.
In many cluster head selection algorithms, every node is selected as the cluster head in different rounds and the probability of selecting a node as a cluster-head is the same for all nodes. In this method, the chances of energy dissipation in cluster heads reduce if we consider large homogeneous WSNs. There are other approaches where the idea of dominating set of graphs is used to devise an algorithm. Some of these approaches are tree based. Most of these algorithms are distributed and work with local (at the most 2-hop) information available from any given node. In this paper, we have considered three such topology construction protocols, namely, simple tree, CDS-Rule K, and A3 protocols for further exploration.
In another development, the theory complex networks have recently received increasing attention for understanding the topological structure, functions, and dynamical properties of many real-world networks such as the social networks, biological networks, and ad hoc networks. One of the most important models that can be used to formally characterize clustering algorithms is known as B-A model [1]. This model is based on two foundational mechanisms: growth and preferential attachment. A new node is added to the network at each step and connects with an existing node with a specific probability, which is related to the degree of the existing node. The B-A network has the scale-free property and follows the power-law distribution.
The B-A network model is capable of capturing some basic mechanism that is responsible for the power-law degree distribution. Still, it had many limitations. Li-Chen model [2] has improved upon B-A model. This model has been able to better capture the dynamics of networks constructed with a local preferential attachment mechanism.
The local preferential attachment model [3] is based on the common sense that people can collect information easily from their local community than from far away environment. Using preferential connection as the fundamental basis, many variations of the scale-free network model have been proposed during recent years such as comprehensive multilocal-world model [4]. Similar to preferential attachment model, the physical position neighbourhoods' model [5] mimics the actual communication network. The Poisson growth model [6] uses the number of edges added at each step as a random variable that corresponds to Poisson distribution. This model can generate many kinds of networks by controlling the random number.
Chen et al. [7] have studied an evolving mechanism for formalizing fault-tolerant communication topology among cluster heads with complex network theory. Based on the B-A model's growth and preferential attachment mechanisms, they not only used a local-world strategy for the network when a new node was added to its local-world but also selected a fixed number of cluster heads in the local world, for the purpose of obtaining a good performance in terms of random error tolerance.
Luo et al. [8] performed theoretical analysis and conducted numerical simulation to explore topology characteristics and network performances with different energy distributions among nodes. Their results have shown that the network is better clustered and average path length for transmitting data is reduced when energy distribution among nodes is more heterogeneous.
In [8], a new dimension is added as the nodes are not only allowed to join the network through preferential attachment but they are also allowed to leave the network or not join the network through nonpreferential attachment. Further the nodes distinguish themselves as cluster head nodes and normal nodes which is consistent with the function of many clustering algorithms in WSNs.
In this paper, we have tried to provide a formalism for some algorithms which computes clusters in a WSN using a modified local network model based on similar models proposed in [2, 9] and [8]. In particular, we have used three tree based clustering algorithms, namely, simple tree, CDS Rule K, and A3. Using our theoretical framework, we have also tried to quantify some of the observed features of these algorithms such as number of cluster heads and average degree of the resultant graph. The theoretically obtained measures have reasonably matched with measures obtained by simulation studies.
The paper is organized as follows. Section 2 describes a very brief review of the local-world model. In Section 3, we have described the application of local world model to provide a framework to describe the functioning of three clustering algorithms. In Section 4, results of theoretical results and simulation studies are jointly presented. Section 5 concludes the paper.
2. A Brief Review of Topology Control Protocols and Local-World Network Model
In this section, we shall discuss very briefly the Li-Chen model [2] and two topology control protocols which are used in this paper.
2.1. A3 Protocol [10]
The A3 protocol uses four types of messages: Hello message, children recognition message, parent recognition message, and sleeping message. The sink node starts the protocol by transmitting an initial hello message to its neighboring nodes. Nodes accept the message if they have not been covered by another node; they set their states as covered, select the transmitter as its parent node, and answer back with a parent recognition message. If a parent node does not get any parent recognition messages from its neighbors, it turns off. The parent node sets a timeout period to accept answers from its neighboring nodes. Once timeout occurs, the parent node sorts the list of neighbor accepting its message in decreasing order of some selection metric. Then, parent node broadcasts a children recognition message that includes the complete sorted list to all its candidates. Once the children accept the list, they set a timeout period proportional to their position on the candidate list. During that timeout they wait for sleeping message from their brothers. If a node accepts a sleeping message during the time out period, it turns itself off.
2.2. CDS Rule k Protocol [11]
The CDS Rule k algorithm utilizes connected dominating set algorithm and pruning rules. The idea is to start from a big set of dominating nodes that produces a minimum criterion and prunes it according to a particular rule. In the first stage, the nodes will interchange their neighbor databases. A node will remain progressive if there is at least one pair of separated neighbors. In the second stage, a node chooses to unmark itself if it determines that all its neighbors are covered by marked nodes with higher precedence, which is given by the degree of the node in the tree. Lower level implies higher precedence. The ultimate tree is a more compact version of initial one with all redundant nodes with higher or equal priority removed.
2.3. Local Network Model
We have used Li-Chen Model [2]. This model is used to form a generalized local-world model. Using the generalized model, we have analyzed clustering algorithms of wireless sensor networks. In this model, each node has only local connection information. Nodes connect only in their local world based on their local connectivity. The following parameters are required to explain the dynamics with reference from Figure 1.
We start from a small number of nodes When a new node chooses a connection to other nodes, the probability, We select M nodes randomly from the existing network which is referred to as local world of the new node. When a new node arrives, we add that node with m edges, linking the new node to m nodes in the local world determined in (3) using preferential attachment with a probability where


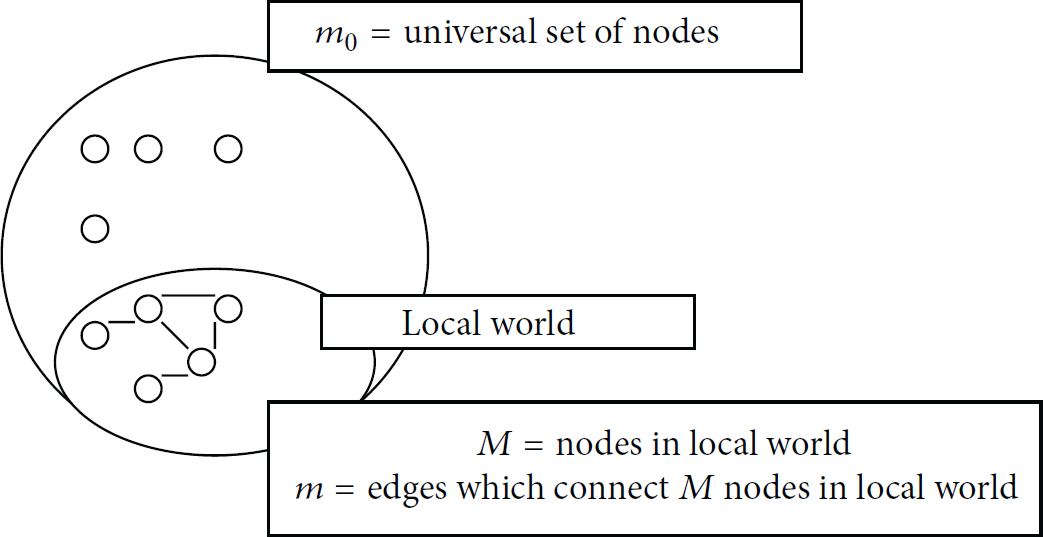
Illustration of various parameters in their roles as describing the local world and the universe.
After t time steps, there will be a network with
3. Applying Local-World Model in WSN Topology Control Algorithms
To use local world model to capture functioning of WSN clustering algorithm, the model has to take into account two types of nodes: normal nodes and cluster nodes. The cluster nodes are the cluster heads and the normal nodes are members in a cluster. There is only one cluster node attached to a normal node; in other words, the normal node has only one edge, which means that the normal node cannot relay data from other nodes. A cluster node can integrate and transmit data from other nodes. Both of these two types of nodes can connect to a cluster node and the number of edges is limited in every cluster node because of its energy consideration. When a new cluster node joins the network, it is randomly assigned an initial energy
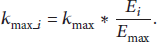
The growth model is described as follows. Starting with a small number of nodes (all of them are cluster nodes), they randomly link each other. This results into an initial network.
Growth. At every time step, a new cluster node or a normal node with one edge enters into the existing network with a probability p or Preferential Attachment. A new node arriving at the network links to an old cluster node that is selected randomly from the already existing network. Nodes in WSNs have the constraint of energy and connectivity and only communicate data with the cluster nodes in their local area. First, M cluster nodes are selected randomly from the network as the new incoming node's local world; then, one of the cluster nodes is chosen to link with the new node according to the probability
If the new incoming node is a cluster node, then the probability is set as follows:

If the new incoming node is a normal node, then the probability is defined as follows:

Total preferential probability is given as follows:

In [12], authors have considered the expenditure of energy in the process of linking nodes together. The disadvantage is that the energy in a cluster node will be exhausted in only few rounds if self-organization is allowed. In fact, the energy consumption will be relatively low, if only
Antipreferential Attachment. Let us consider a parameter z called the deletion rate or antipreferential attachment factor, which is defined as the rate of links removed divided by the rate of links added. It is observed that lesser the energy of the node, the more will be the probability of it being deleted. Let this probability be denoted as
For the outgoing cluster nodes, we have

For the outgoing normal nodes, we have
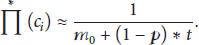
So the total antipreferential probability is given as follows:

Using mean field theory [9, 13] a qualitative analysis of dynamic characterization of a wireless sensor network can be given. By the mean-field theory, the preferential and nonpreferential attachment may be combined in the following differential equation:

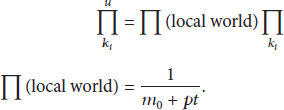
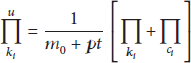



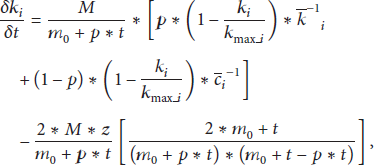

3.1. Analysis of the Dynamic Equation
3.1.1. Case I
If

3.1.2. Case II
If


Putting the value of (20) in (19) we have

By definition

Therefore,
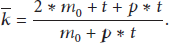
Similarly, we have for
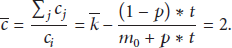
Equations (21) and (23) are used to find the values of
Finally the following equation is formed after substituting the values of

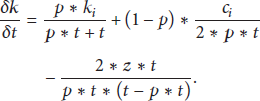

with initial conditions given as
By integration, we have the solution as
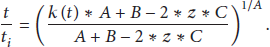




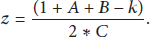
By setting the value of z to zero, we have the following relation

4. Analysis of Topology Control Algorithms
In this section, we have carried out simulation of three localized topology control protocols, namely, A3, Simple tree Protocol, and CDS Rule K. Simulation was carried using the Atarraya [14] simulator. Total number of nodes was 100, 200, 300, and 500, respectively, and they were tested for A3, Simple Tree Protocol, and CDS Rule K. The output was recorded for average degree of nodes, k, for three protocols mentioned earlier.
Figure 2 shows an example of clustering and computation of average k value.

Clustering as obtained by running simple tree protocol in a network of 100 nodes.
Figure 2 shows the cluster heads in red circles with which normal nodes are attached. Taking the number of all the neighboring nodes of every cluster heads and dividing by the number of cluster heads we obtain the average value of k. By similar procedure we have obtained the average value of k for different number of nodes.
We have also carried out simulation study using simple tree protocol for different number of nodes. The number of clusters obtained using theoretical calculation (35) is compared against the number of clusters obtained using simulation study, which is presented in Table 1.

N = number of nodes, k = number of neighbors, p = probability of selecting a cluster head (35),
Similar simulation study was also carried out using CDS-Rule k Protocol for different number of nodes. The number of clusters obtained using theoretical calculation (35) is compared against the number of clusters obtained using simulation study, which is presented in Table 2.

N = number of nodes, k = number of neighbors, p = probability of selecting a cluster head (35),
Similar simulation study was also carried out using A3 Protocol for different number of nodes. The number of clusters obtained using theoretical calculation (35) is compared against the number of clusters obtained using simulation study, which is presented in Table 3.

N = number of nodes, k = number of neighbors, p = probability of selecting a cluster head (35),
4.1. Discussion on A3 and Simple Tree Protocol
Next, we plot the theoretically calculated number of clusters and experimentally calculated number of clusters as shown in Tables 1 and 3 for A3 and simple tree protocols.
We observe the following.
In A3 and Simple Tree protocols, the curves for theoretically calculated number of clusters and experimentally calculated number of clusters follow fourth degree equation. The trend line polynomial options of MS Excel have been used to study the degree of curve fit of the curves to obtain the following polynomials:
In Figure 3, there is gap between the theoretical and experimental curves in case of A3 and simple tree protocol. This may be attributed due to the fact that A3 (approximate CDS) only preserves 1-connectivity whereas the simple tree protocol has multiple connectivity. So, A3 protocol requires less energy to construct the tree as compared to spanning tree which confirms to the experimental results.


Number of nodes versus number of cluster heads in simple tree protocol and A3 protocol.
4.2. Discussion on CDS Rule K
Consider (34) which is mentioned in the following:

Table 4 enumerates the value of z for various values of k corresponding to different number of nodes in the network.
Value of z for different k values in networks of different sizes.

From the results of Table 2 we obtain Figure 4.
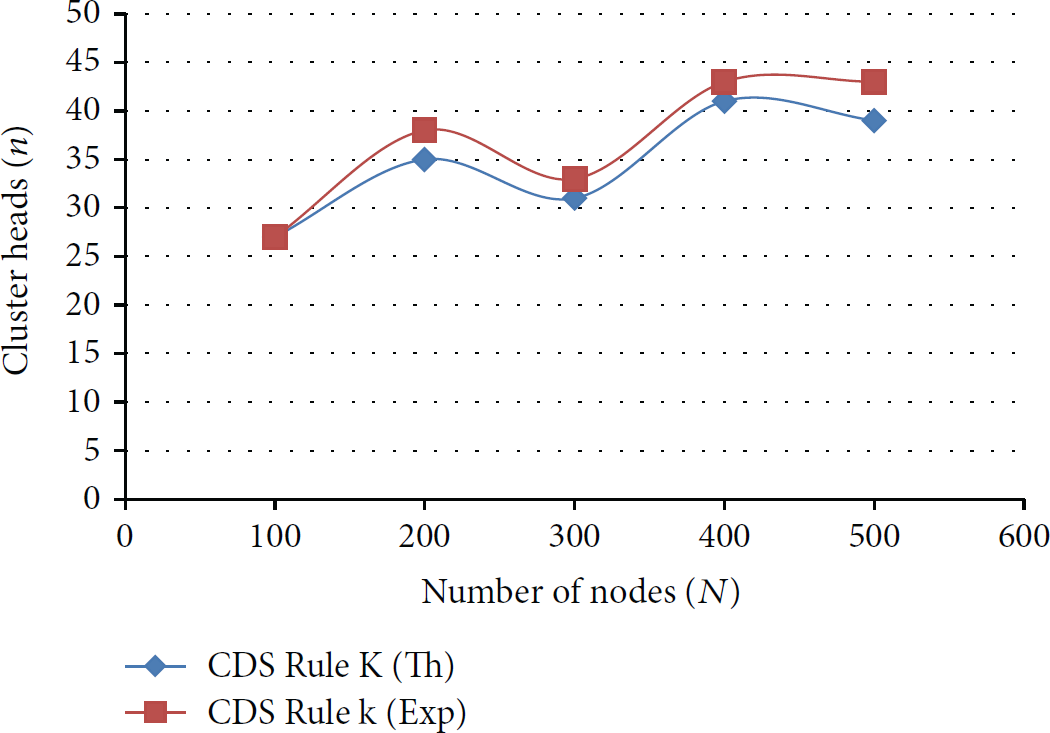
Total number of nodes
In Table 4, the maximum value of z corresponds to a probability value 0.5 which indicates that the clusters have dissociated into one cluster head and one normal node which ideally predicts the case when the energy of the nodes has drained out.
In Figure 4, it can be seen that the mechanics of clustering in CDS-Rule K is in accordance to the assumptions considered while deducing the distribution function using mean field theory. Unlike A3 and Simple tree protocol, CDS-Rule K also exhibits a relation of degree 4 as shown (
Above experimental results lead us to the following explanation of the antipreferential factor z.
The antipreferential factor can have three distinct values.
When When When
5. Conclusions
In this paper, we have tried to provide a framework to formally model tree based clustering algorithms in a WSN. Based on the formalism, we have theoretically calculated some parameters such as number of cluster heads and average number of degree for a given algorithm. The theoretical results tally with results obtained by simulation studies. We have introduced a factor called z in network evolution model. It seems that the z factor has an impact on functioning of these protocols. We keep that study as a future exercise. The study at the current stage is more suitable for modeling tree based clustering algorithms that work on the top of connected dominating set construction. Algorithms that are based on more parameters have to be modeled appropriately in the framework before application.
In recent papers energy distribution has been considered in network evolution model for wireless sensor networks. But, so far, the framework of network evolution model has not been used to capture the characteristics of clustering algorithms.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.