
Abstract
A novel activity recognition method is proposed based on acoustic information acquired from microphones in an unobtrusive and privacy-preserving manner. Behavior detection mechanisms may be useful in context-aware domains in everyday life, but they may be inaccurate, and privacy violation is a concern. For example, vision-based behavior detection using cameras is difficult to apply in a private space such as a home, and inaccuracies in identifying user behaviors reduce acceptance of the technology. In addition, activity recognition using wearable sensors is very uncomfortable and costly to apply for commercial purposes. In this study, an acoustic information-based behavior detection algorithm is proposed for use in private spaces. This system classifies human activities using acoustic information. It combines strategies of elimination and similarity and establishes new rules. The performance of the proposed algorithm was compared with that of commonly used classification algorithms such as case-based reasoning, k-nearest neighbors, support vector machine, and multiple regression.
1. Introduction
Advances in context-aware personalized services have resulted in the development of unobtrusive and inexpensive sensors for recognizing activity and providing the resulting information. State-of-the-art machine learning algorithms have also been developed for analysis of this information. Even though activity recognition (AR) is more complicated and difficult than ID or location recognition, automatic detection of user activity in a smart space, including activities of daily living (ADL) such as cooking, dining, and drinking, using an AR service may be more accurate than a service that determines system response by recognizing user identity and location. Automating the recognition and tracking of ADL may be an important step toward enhancing the well-being of smart home residents. To support ADL, AR has strength that another context-based recognition does not have. For example, as for the location-based method, since it is impossible to classify unexpected user behavior, its accuracy is low except for structured and repeated behavior. If the location streaming pattern is structured and hence behaviors are surely estimated by location sensors such as GPS, then location-based behavior recognition is adoptable in the applications. However, a variety of behaviors can randomly occur in a certain location stream (e.g., dining, conversation, or reading at living room), which results in decreasing the accuracy of location-based recognition. Viable smart home or smart building, which the proposed method focuses on, should cope with the multibehaviors at one-location problem [1].
However, the privacy concern is one of the important issues in location- and vision-based AR: people hesitate to be permanently monitored by LBS (location-based service) or camera at her/his personal space, whereas the tracking and record of user daily life is technically important to improve the quality of AR-based services [2]. While the gesture-based AR is popular in research domains, its application is difficult in private domains such as users' homes because it uses camera captured data. Moreover, AR systems that use visual information are costly to develop and operate, and their accuracy is poor. To preserve user privacy, LBS may not gather his trajectory information in centralized storage [3], but it still has excessive information out of the usage. Highly sensitive nature of personal image results in higher privacy concern about the visual sensors. Even though network security is emphasized to cope with these problems [4], users still feel uncomfortable about the vision-based activity sensing. Consequently, AR is a challenging issue in terms of privacy concern [5], and another method to alleviate privacy concern is needed.
When it comes to activity recognition, conventional activity recognition methods have used vision- or motion sensor based. However, since vision-based recognition suffers from privacy concern, applying the method to activity recognition is strictly restricted such as surveillance system, not home or office where the proposed method aims to be implemented. Motion-based recognition using motion sensor such as accelerometer in the mobile device can recognize very small set of activities such as standing, walking, running, or falling down. Dining, chatting, reading newspaper, and many other human activities in everyday life, which we aim to recognize, cannot be identified by motion sensors. Hence, we here in the paper adopted sound-based activity recognition based on RBS and RBE. Meanwhile, existing sound recognition methods are voice recognition to identify what the people in the space are saying. This must not be applied in home and office due to privacy concern. RBS and RBE do not attempt to recognize voice—it will be identified as noise, and hence the proposed method is free from privacy concern.
A promising AR method that protects more privacy than vision-based activity sensing is acoustic information-based AR. The primary characteristic of acoustic information is frequency. Analysis of frequency helps identify activity because each activity has its own frequency pattern. However, discernment of acoustic information of similar frequency is still not easy. For example, a handclap and a whistle may be easily distinguished by their different frequency bandwidths, but the acoustic information of putting down a bowl versus that of putting down a cup may be more difficult to distinguish. Furthermore, the more behaviors of similar frequency there are, the more difficult it is to separate them [6].
Hence, in this paper, a new supervised learning method is proposed that correctly classifies activities using acoustic information for privacy protection. This system can distinguish activities regardless of their similarity in terms of sound frequency. The proposed method may be used for recognizing multiple activities sequentially occurring in the same place, especially in the smart home domain. For example, it can be applied in a smart home by optimizing light automatically. The automatic light control application assesses whether a person is eating, reading, or doing other activities based on sound patterns collected by microphone, providing an appropriate light atmosphere by dimming or illuminating the lights. This system can be tailored for the situations of individual inhabitants. Other various behaviors may be recognized, such as sleeping, speaking on the phone, or having a conversation. To show the feasibility of the idea proposed in this paper, an experiment was conducted using two metrics: accuracy and elapsed time. Previous algorithms for classification of acoustic information are compared with the proposed method.
This paper is organized as follows. Section 2 summarizes previous research related to AR and describes existing methods of acquiring acoustic information. Section 3 introduces the proposed method and describes the strategy. Section 4 describes system implementation and compares the performance of the proposed method with that of other methods. Finally, Section 5 concludes.
2. Related Work
Most human AR studies categorize human activity by location, gesture/motion, or acoustic information. These three different categorization methods are outlined below.
2.1. Human AR by Location
The proliferation of wireless technologies in infrared, Bluetooth, and ultrasonic technologies has fostered a growing interest in location-sensing devices. Carrying a mobile device, a user's current location can be determined by an embedded GPS sensor or cell phone information. By comparing this information to prior information about user behavior in a particular location, current activity can be inferred from location data only. This simple method can be very cost effective. For example, we can assume that a user is most likely to be eating when the current location is a restaurant.
However, the accuracy of location-based AR is low in some problematic domains in which various activities may occur in the same location. For example, because a user may eat, have a conversation, read a book, or even sleep at a dining table at home, activity inference using location alone is impossible. In addition, two different activities may be performed concurrently in one place. In such cases, AR is more difficult [6]. Therefore, there is an AR research that recognizes the environment sounds such as vacuum cleaner (house cleaning), shaving (shaving beard), and taking shower [7], but it aims for the dissimilar sound aroused in the different places.
2.2. Human AR by Gesture and Motion
Human gestures are most often recognized using visual information or acceleration sensors. A person's position provides a lot of visual information about his or her behavior. Human gesture recognition systems divide the body into several parts (e.g., arms, head, feet, and joints) and then recognize various poses using body layout information. Based on the direction and extent of movement of each body part, the system searches for the most similar gesture from several predefined gestures to infer the current activity. This method has been applied to gaming, animation, video editing, sociology research (e.g., observation of smoking behavior), and surveillance systems.
Another method of motion recognition is to build a model of the structure of relations among fragmented images of the parts of an object (e.g., the head). In this method, a pose is represented by an energy graph, the function of which is represented as
Pose estimation has been a very active research area because it is used in gaming, e-learning, and development of smart control systems. Using visual information, the appearance-based method is another form of human AR based on gesture. This method recognizes activity by the shape and appearance of an image. The important part of a given shape is represented as light, that is, brightness. Behavior is then recognized by changes in brightness. However, visual methods must observe the actual appearance of a person. The context-aware-based personal service is useful and promotes its service acceptance, whilst the privacy concern discourages a user to accept it [8, 9]. Therefore, due to privacy concerns, it can be only applied to gaming or special cases such as health care settings or the military. As a result, this method is limited in its ability to assist in the daily lives of most people.
To mitigate privacy concerns, a method of recognizing behavior using handheld mobile phones or wearable sensors has been reported. However, in this method, the user must constantly be carrying the device. For this reason, this method is obtrusive and demanding, and users find it difficult to accept. It may be suitable only for outdoor use, but not in AR of ADL, which occurs indoors in the home or office. Moreover, personal differences in behavior and highly abstracted behavior such as shopping, eating, drinking tea, or having a conversation make use of this method difficult.
2.3. Human AR Using Acoustic Information
Human AR using acoustic information involves use of acoustic sensors. Acoustic sensors recognize sound waves associated with certain behaviors. They come in the form of a microphone [10, 11], a wearable acoustic sensor [12–14], or a handheld mobile phone [15, 16]. For example, BodyScope, a wearable acoustic sensor, records the sounds produced in the area around a user's throat and classifies them into 12 possible activities such as eating, drinking, speaking, laughing, or coughing. A support vector machine (SVM) may then be used to classify the sounds [14]. To increase the accuracy of AR using acoustic information, a method combining GPS, heat sensors, and other devices has also been used [12, 16, 17].
Sound collected from acoustic sensors embedded in microphones may be interpreted using acoustic information recognition methods. Among these, CASR (computational auditory scene recognition) and CASA (computational auditory scene analysis) are most notable [18]. The CASR method infers the background situation (e.g., street, subway, and bedroom) and recognizes user behavior based on that information. The CASA method extracts only relevant information from the entire spectrum of recorded sound. However, because of the lower frequencies of radio waves and the high number of false positives using these methods, their accuracy is only about 60% [3, 18].
Acoustic information-based AR has the advantage of greater accuracy than other methods. For example, while the camera may recognize the behavior of drinking tea, the acoustic information-based AR system may also recognize how fast or how much the user is drinking [19]. This richness of acoustic information has increased the amount of research on acoustic information-based AR in the home domain to include bathroom activity [20] and eating in the living room or at the dining table [12, 14], which are domains in which visual sensors are unwelcome due to privacy concerns.
However, AR by attaching a wearable acoustic sensor may also be obtrusive. In general, context sensing using wearable devices and mobile devices such as a smartphone is unacceptable for use in everyday life [19]. In addition, the various wearable sensors that are available are generally costly and still do not address privacy concerns. Accordingly, in this study, a method is proposed that involves use of a fixed microphone rather than a wearable acoustic sensor.
3. Methodology
The overall framework of the acoustic information-based AR developed in this study is shown in Figure 1. A novel algorithm to classify activities based on acoustic data collected at home is the main body of the framework.
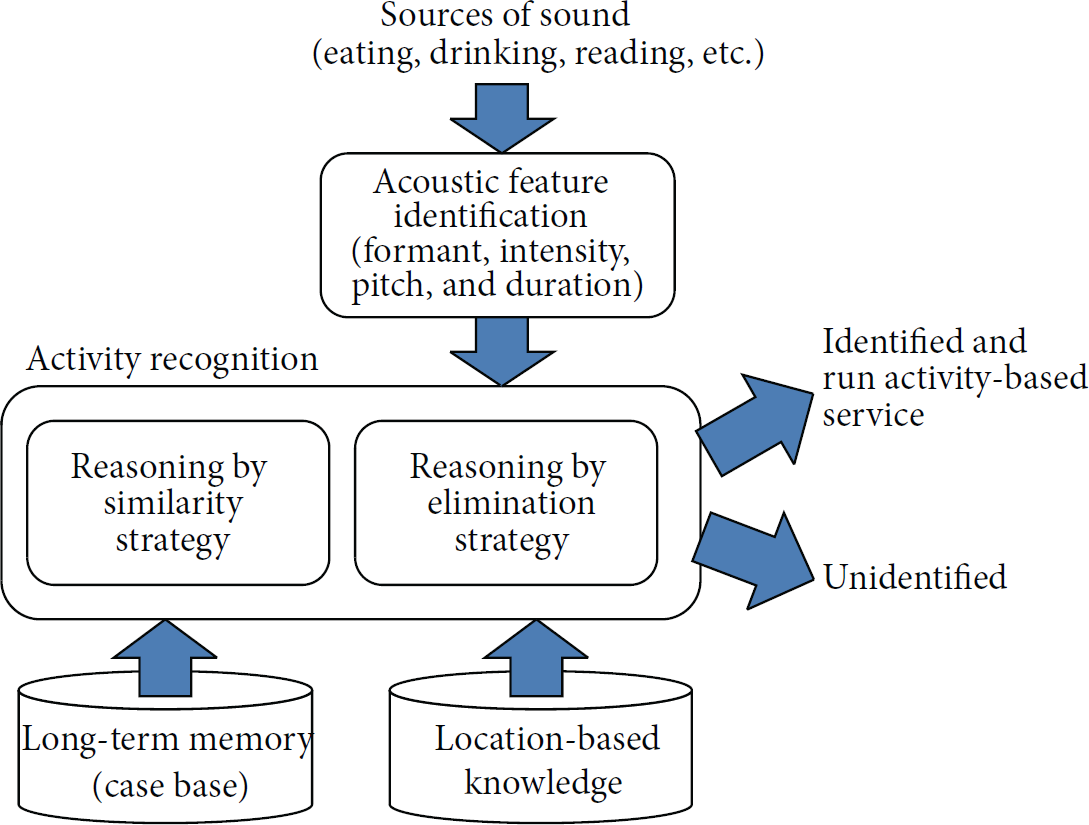
Framework of acoustic information-based AR.
The framework is based on Carroll's framework of three mental structures in cognitive psychology [21]: sensory stores, working memory, and permanent memory. The sensory stores take in the sound generated from a variety of activities experienced in everyday life and retain it for a short period of time in an unanalyzed form. The information in the sensory stores is refreshed and analyzed in working memory. Working memory refers to a limited capacity system of temporary storage and manipulation of input that is necessary for complex tasks such as comprehension and reasoning, which are inherent in AR [22, 23]. Long-term memory is the unit that contains, among other things, knowledge of the world. In this framework, the relationship between activities and corresponding sounds is regarded as long-term memory.
In the proposed framework, acoustic features are identified as short-term memory. The features must be identified based on activities and corresponding sounds that could happen in a given location. In human behavior recognition systems, an adjustment mechanism is available to determine which activity causes which sound. A set of acoustic features of candidate activities is uploaded from case base as long-term memory that are similar to the acoustic features in the sensory store. If no candidate is found because no similar sounds are stored in memory, then the sound cannot be identified. When some candidates are found but selecting one activity over the others is too difficult, some candidate activities must be eliminated, which cannot happen using location-based knowledge alone. For example, when the system hears something at the dining table at home, any activities will be eliminated that do not normally happen at home at the dining table.
3.1. Acoustic Feature Identification
To recognize activity, the sound characteristics used in our proposed method include formant, intensity, pitch, and duration. First, a formant is defined as “the transfer function of energy from the excitation source to the output… described in terms of the natural frequencies or resonance of the tube” [24]. Simply put, formant is vocal tract resonance. In speech science and phonetics, formant refers to an acoustic resonance of the human vocal tract. Using formant data, sharpness and thickness of sound can be detected and applied for estimation of human emotion such as anger, laughter, and surprise. Moreover, formant depends on the size of the object making the sound [25, 26].
Second, intensity is defined as the sound power or loudness per unit area. It is usually measured in the context of sound intensity in the air at a listener's location. The ratio of a given intensity to the threshold of hearing intensity is measured in decibels (dB).
Next, duration (in ms) is the elapsed time necessary to produce a unit of sound (e.g., a vowel). Identifying acoustic cues used to distinguish the place of articulation in the mouth for some consonants may be difficult for consonants that are very short in duration and low in intensity [27]. In vowel analysis, vowel duration provides the main distinction between short and long vowels. For example, /i/ is different from /i:/ in terms of duration.
Last, pitch, which is the fundamental frequency of a speech signal, is strongly dependent on the highs and lows of sound [24]. From a physical perspective, pitch means the difference in frequency. In the auditory sense, the more frequencies a sound has, the higher it is, and vice versa. A fundamental frequency is the lowest frequency among the harmonics. It occurs when an entire material object vibrates. Harmonics are measured in multiples of the fundamental frequencies (e.g., double, triple, and quarter). An overtone occurs when a part of a material object vibrates.
This information can be easily extracted from sound analysis programs. For example, information regarding formant, pitch, and duration may be extracted (Figure 2).
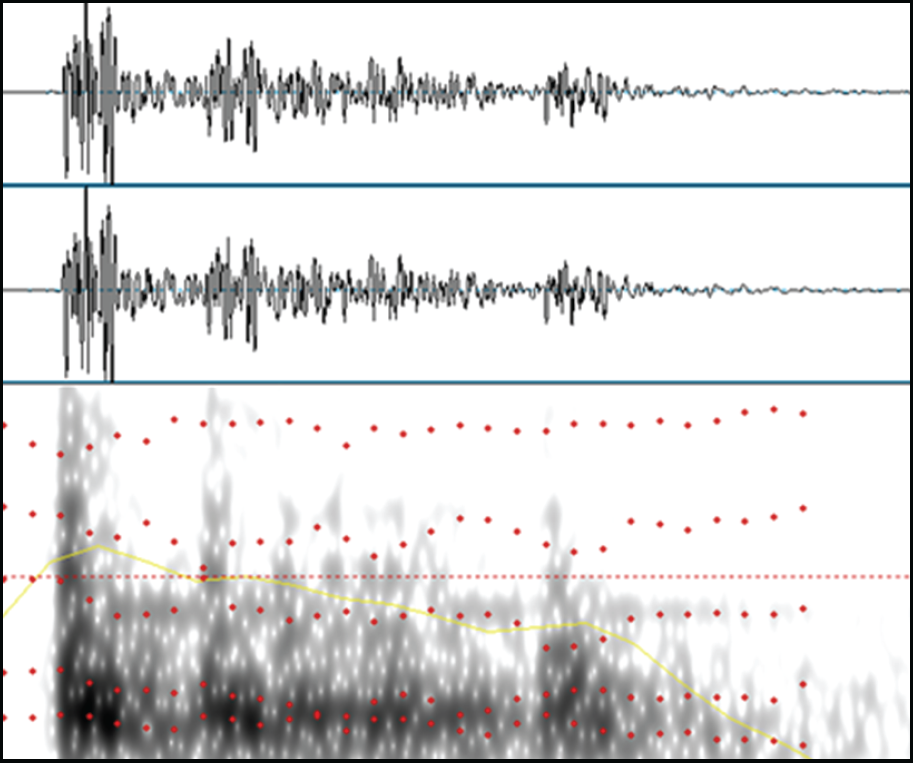
Formant and intensity as measured by spectrogram.
3.2. Acoustic Sensor Based AR
Various classification algorithms have been used for AR, and a variety of sensor technologies have been developed: the k-nearest neighbor (k-NN) classifier [28], Bayesian network [29], decision trees such as the C4.5 [30], and the SVM [5, 31]. Unlike these conventional classification algorithms, we focus on how the sound of a certain activity may be distinguished from other various sound categories that indicate different activities. First, if the characteristics of a particular sound tone differ significantly from the characteristics of other familiar sounds, it may be eliminated from the candidate set of activities. For example, when a person hears a soft bumping sound when shaking a small box, the list of possible candidates may be reduced by eliminating some candidate materials that do not generate such a sound, such as a large stone or powder. Second, if the overall characteristics of a sound are similar to those of another familiar candidate, then the decision can be made that the candidate is in the same category as the heard sound. In other words, the human brain has a mechanism by which it can identify familiar sounds. These two strategies are called reasoning by similarity (RBS) and reasoning by elimination (RBE). They are specified more clearly as follows.
RBS: when a person hears a sequence of sounds and discriminates it, he or she selects the sound that is entirely similar in characteristics to the characteristics of the target sound. RBE: when a person hears a sequence of sounds and discriminates it, if some of the characteristics of the heard sound differ from the candidate sound, unlikely candidates are eliminated. This process is repeated until the heard sound is matched to a candidate sound.
Recognizing an activity with acoustic information using RBE and RBS is classified as supervised learning. In the smart home context, very high accuracy and performance must be provided by the AR system. A limited number of target activities must be recognized automatically using acoustic data from a single microphone. Although unsupervised learning has certain advantages mainly in terms of greater flexibility and extendibility than supervised learning, this learning strategy is less accurate.
Algorithm 1 depicts the classification algorithm based on RBS. Algorithm 2 shows the classification algorithm based on RBE used in conjunction with RBS.
[1] Reasoning By Similarity (RBS) Strategy
FOR each data record RUN case based reasoning with Euclidean distance; IDENTIFY the rank and distance of each data record;
[2] Reasoning By Elimination (RBE) Strategy
Initialize multiplier (6.0), precision (0.001) Read LBK location-behavior set = SELECT location-behavior FROM LBK WHERE location = #value Compute average number and standard deviation of the data set FOR each data record WHILE (remaining class code > 1) { Threshold = multiplier − loop ∗ precision; For each class code IF class code is not included in location-behavior set THEN ignore; ELSE IF at least one field satisfies ((test data > (average + threshold ∗ standard deviation)) OR (test data < (average − threshold ∗ standard deviation)) THEN ignore; IF only one class code remains THEN accept the class code; ELSE IF more than one class code remains THEN increase loop by one; }
Based on the information provided by the RBE and RBS strategies, the proposed learning algorithm is applied. This method of AR from acoustic information combines the two strategies according to the “generate combining rules” strategy, as shown in Algorithm 3. The algorithm generates AR rules by using these two strategies concurrently. At the time of combination, the algorithm firstly refers to RBS and then considers the results from RBE.
[3] Generate combining rules
GET similar class codes BY RUN Perform reasoning by similarity strategy; If the distance between target sound and the most similar sound is greater than threshold, then stop. The sound is unidentified, and then new case is added to the server. GET remaining class code BY RUN Perform reasoning by elimination strategy; For each (remaining class code X similar class codes X distance of the class codes) Get most frequent result; Generate rules (“IF remaining class code X similar class codes X distance of the class codes THEN result”)
4. Experiment
To demonstrate the feasibility of the idea proposed in this paper, an experiment involving inference of human behavior at a table in the home was conducted. Human activity was recognized based only on acoustic data gathered by a microphone in a fixed location, which was used for data collection and performance evaluation. The human activities recognized at the dining table were as follows: drinking soup, eating rice, placing a pottery bowl, placing a metal chopstick, drinking tea 1, drinking tea 2, drinking tea 3, placing a plastic soup bowl, and placing a plastic rice bowl. A variety of bowls and corresponding materials was used in the acoustic data collection for the experiment (soup and rice bowls made of paper, wood, and porcelain). This variety was included in the performance evaluation to show the superiority of the acoustic information-based recognition system over vision-based recognition systems. Recognizing fine dissimilarities between materials is very hard to do using a camera.
4.1. Materials and Equipment
Data samples were collected under laboratory conditions. Implements and equipment used in the experiment are shown in Figure 3. A sample data set was extracted by creating an acoustic file saved through a microphone whenever each behavior was measured. Praat, a C-based open source program which has been widely used for acoustic recognition, was also used in this study. A low-priced microphone was adopted for recording because, in a real home setting, the collected sound may be unclear due to noise and poor microphone performance. The general-purpose open source program and low-specification microphone were used in the experiment because we focused on measuring a recognition algorithm rather than on the microphone or acoustic analysis program itself. In real-life application, many devices lack economic validity due to high specifications and the price of related equipment, despite the efficacy of the recognition algorithm. Therefore we selected these less expensive options.

Eating implements and equipment used in the acoustic recognition experiment.
4.2. Experimental Samples
The methods for securing acoustics samples for each behavior were as follows (Figure 4).

Experimental conditions.
4.2.1. Drinking Soup
As soup is generally served together with rice, the sound of drinking soup was selected as one of the activities. In the experiment, a porcelain soup bowl was used, as this is the most widely used type of soup bowl. The sounds of drinking soup and eating soup with a spoon were recorded. The sound of a spoon being dropped into a bowl was also included in the data.
4.2.2. Eating Rice
As one of the selected activities, eating rice was chosen, as rice is the staple food of Koreans. Cooked rice is common in most households. The bowl and spoon used for eating cooked rice were made of porcelain and metal, respectively. Data were recorded for the sound of eating rice, including the sound of spooning it up with a metal spoon and chewing it. The sound of chewing rice was comparatively quiet as compared to the sound of a metal spoon being lowered into the porcelain bowl for spooning up the rice.
4.2.3. Putting Down Metal Spoon and Metal Chopsticks
The sounds of putting down a metal spoon and metal chopsticks were also detected in this study. All sounds occurring in between holding the metal spoon and metal chopsticks together and putting them down on the table were also recorded. In the experiment, a common wooden table covered with cloth made of vinyl was used.
4.2.4. Putting Down Bowls (Porcelain Rice Bowl, Plastic Rice Bowl, and Plastic Soup Bowl)
The sounds of putting down rice and soup bowls were recorded during the activity of setting the table prior to a meal. Two types of bowls, porcelain and plastic, were used and their sounds were detected separately. All sounds occurring in between the holding of the bowl containing rice and putting the bowl on the table were also saved.
4.2.5. Drinking Tea (Type 1: with a Saucer)
Drinking tea was one of the activities that can happen at the table which was evaluated in this study. The sound of placing a porcelain teacup on the table was detected for the purpose of recognizing the activity of drinking tea. In the experiment, the teacup contained green tea. The teacup and saucer were both made of porcelain. All sounds occurring between putting the saucer and teacup on the table and putting the teacup on the saucer after drinking tea were included. The sound of the teacup being placed on the saucer, which is a relatively louder sound than that of drinking tea holding a teacup, was also included.
4.2.6. Drinking Tea (Type 2: without a Saucer)
All conditions for measurement of this sound were the same as those for type 1 (drinking tea with a saucer), but the sound of drinking tea with a teacup only, but no saucer, was included.
4.2.7. Drinking Tea (Type 3: Drinking Hot Tea)
In addition, the sound of drinking hot tea was included because gulping and sipping a liquid have different acoustic patterns. When drinking hot tea, people tend to sip it rather than gulping. This distinction is useful for the activity-based application system to identify the temperature of the liquid without the need for temperature sensors. All sounds generated between holding the cup containing hot tea and drinking, as well as swallowing after cooling it down by blowing, were saved and analyzed. As in the previous two conditions, the teacup contained green tea, and a plastic cup was used.
4.3. Results
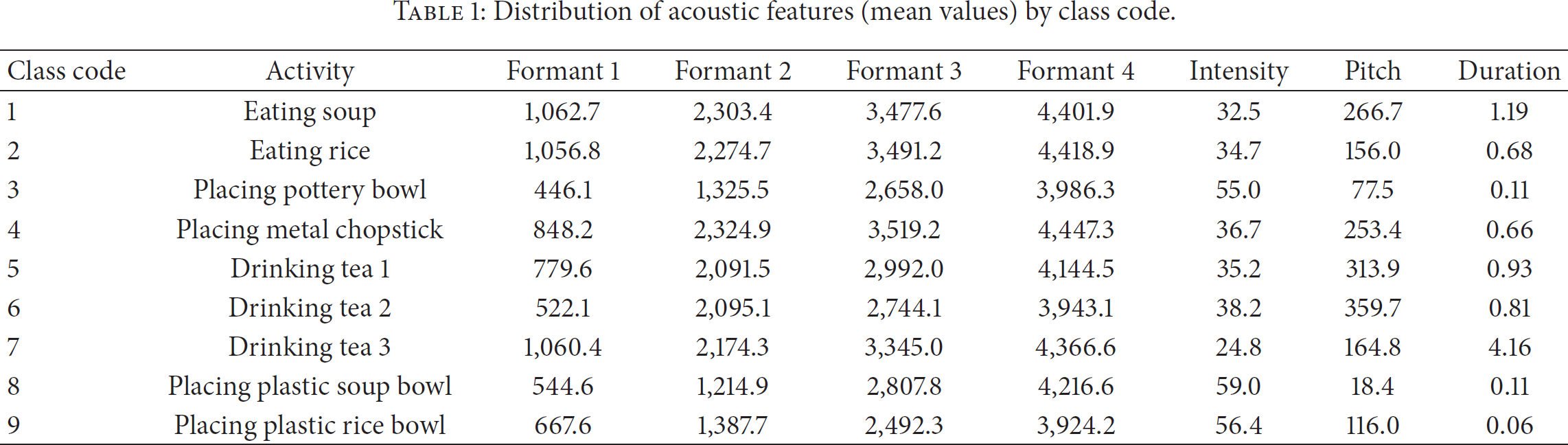
In total, 310 recorded instances of the 9 types of activities were collected for evaluation. Acoustic features by respective class code are listed in Table 1. These acoustic features varied by class code, but they were similar within each class, such as in the conditions for drinking tea type 1, drinking tea type 2, and drinking tea type 3.
Distribution of acoustic features (mean values) by class code.
A random subsampling method was applied. For each experimental condition, 75% of the sample data were randomly selected for training, and the rest were used for testing. In applying the proposed method, the combined rules were generated by utilizing the RBE and RBS strategies. The results are shown in Table 2. In the table, the letter “E” indicates that the results of the RBE strategy concurred with the actual results, while “S” shows that the results were inferred by the RBS. “E-S” indicates that the results using the RBE and RBS were used together to derive the correct answer. For example, cell (1, 4) shows that an inference of behavior “1” from the results of the acoustic analysis using the RBE strategy concurred with the rule of discriminating from behavior “4” using the RBS strategy. In addition, E-DIFF means that part of the answer was inferred by the RBE strategy, while other parts are not; that is, the RBS strategy was right for some rules, but some of them were inferred as a separate class code irrespective of inferences resulting from the RBE or RBS. These cases imply that the suggested method is capable of learning from failure. Lastly, “X” shows that no such cases were found during the learning. For example, “X” designated in (1, 3) means that none of the things recognized as “1” in the RBE strategy were inferred as result “3” using the RBS strategy. The existence of a cell designated with “X” means that the final inference becomes effective in time. In the case of (1, 3), for example, if the algorithm estimates a sound as “1,” then it is by no means “3,” so the estimation process will be reduced by the elimination of that option, performing more accurately and promptly thereafter. According to Table 2, the elimination strategy appears more often than the similarity strategy, which indicates that the elimination strategy is considered superior to the similarity strategy in terms of enhancing accuracy. Second, the more these two strategies are combined and used together, the more effective the system is and the more the overall accuracy improves (E-S case). This reveals a positive effect of the combination of these two strategies.
Final result when a class code is selected using the RBS and RBE strategies.
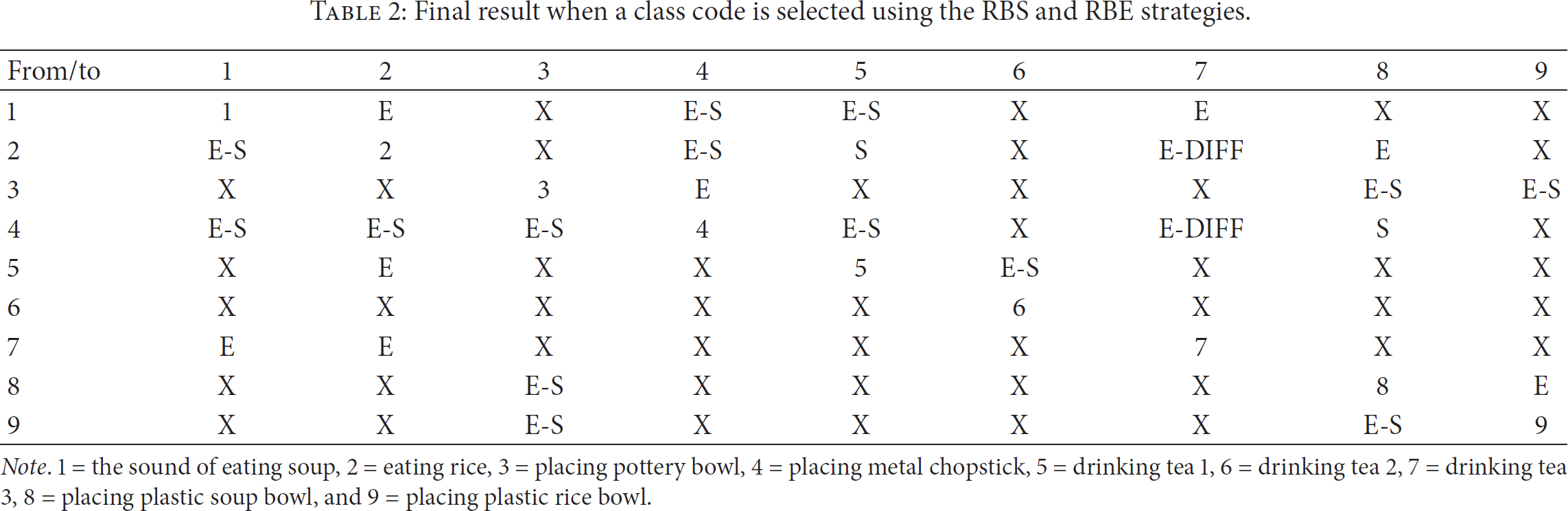
Note. 1 = the sound of eating soup, 2 = eating rice, 3 = placing pottery bowl, 4 = placing metal chopstick, 5 = drinking tea 1, 6 = drinking tea 2, 7 = drinking tea 3, 8 = placing plastic soup bowl, and 9 = placing plastic rice bowl.
For comparison of the outcomes using different classification algorithms, overall accuracy and elapsed time were adopted as performance measures. Since the class value was nominally coded from 1 through 9, the results of the evaluation were labeled as “correct” or “incorrect” and hence metrics such as MSE and RMSE were not applicable.
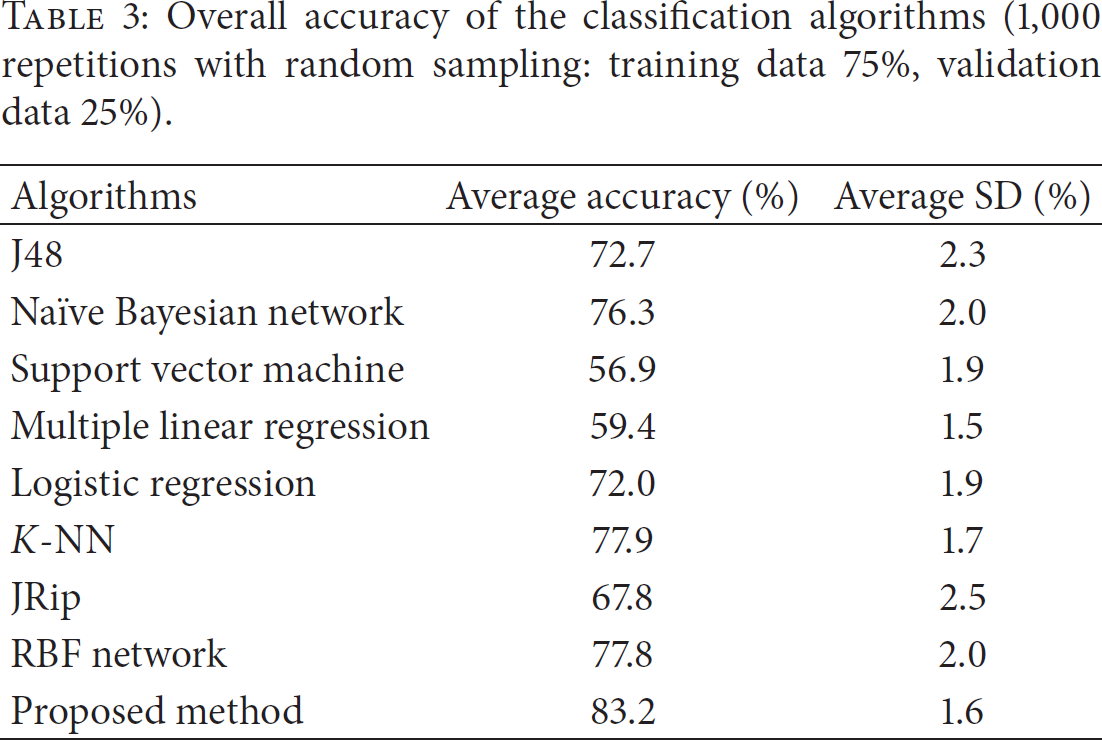
Eight AR algorithms were selected for comparison of performance with the proposed method: decision tree (J48), naïve Bayesian network, SVM (sequential minimal optimization), multiple regression, logistic regression, k-NN (IBK), JRip (RIPPER), and the radial basis function (RBF) network, which is a kind of artificial neural network provided by Weka. For k-NN, the IBK algorithm was used to select the appropriate value of k based on cross-validation [27]. Distance measuring is also possible by IBK. The results are shown in Tables 3 and 4. According to Table 3, the proposed algorithm yields more accuracy (83.2%) than any other algorithm. Second, in the analysis of elapsed time, the proposed method performed very well (0.092 sec) compared to J48 (0.016 sec), naïve Bayesian network (0.015 sec), multiple linear regression (0.017 sec), k-NN (0.005 sec), and JRip (0.034 sec). However, artificial neural networks such as the RBF network (2.279 sec) would not be scalable as the amount of training and test data increases. Consequently, we concluded that the proposed algorithm, which combines rules generated from RBE and RBS, outperforms the other classification algorithms currently considered in AR research.
Overall accuracy of the classification algorithms (1,000 repetitions with random sampling: training data 75%, validation data 25%).
Elapsed time of the classification algorithms (1,000 repetitions with random sampling: training data 75%, validation data 25%).

5. Conclusion
Recognizing human activities unobtrusively and accurately is challenging. Using acoustic data is appropriate since it avoids the privacy issues inherent in other methods (camera-based activity sensing and voice recognition) and is less obtrusive (observation method and verbal request for input about the user's activity) to users. Moreover, even acoustic-based recognition methods adopt general classification algorithms, such as the hidden Markov chain [32] and artificial neural networks, which are not quite the same as human acoustic information recognition processes for identifying activity that generates sound. These may cause inferior performance in terms of accuracy and elapsed time.
In this paper, an alternative method was introduced for tracking activities in smart home environments. A novel algorithm for automatic recognition of ADL from acoustic data was investigated. Following Carroll's framework of triple mental structures in cognitive science, which is the natural AR process, the algorithm combines RBE and RBS strategies to mimic a person's mental information processing during activity identification through processing of acoustic data. First, RBE is to identify activity very promptly, because delayed activity recognition deeply weakens the usefulness and quality of the activity-based service (e.g., turning on light long after a user comes in). Second, RBS minimizes the wrong recognition due to using similarity-based computations. Through the experiment, the results suggest that the RBS significantly increases the recognition accuracy in the experiment. Moreover, the proposed method performed better in terms of accuracy and elapsed time than the conventional classification algorithms usually applied for AR.
Furthermore, while the legacy sound recognition methods are voice recognition approach, which aims to identify what the people in the space are saying, this must not be applied at home and office due to privacy concern. RBS and RBE do not attempt to recognize voice—it will be identified as noise, and hence the proposed method is free from privacy concern. The proposed method does not incorporate any voice recognition algorithms.
While this method is a useful advancement in the field of smart home applications, additional research may enhance the algorithms in the future. First, incorporating more sound features will increase the accuracy of acoustic recognition. In case of formants, for example, using both the average values of formants and formant dispersion (average distance between each adjacent pair of formants) can also be considered. Second, recognition of more elaborate activities can be accomplished by considering the features of an artifact that generates sound. Richer contextual information can be acquired from the acoustic information. For example, the sound of putting a cup on a wooden table may differ from that of putting it on a plastic table. These differences are hard to obtain using camera-based recognition. By extending the proposed method, both artifacts and current activity can be identified. Identification of which artifact is being used may be achieved by considering information on the physical characteristics of the artifact that generates sound. Design features such as weight, density, hardness, and tensile strength of the artifact may be included in the algorithm.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This work is supported by the National Strategic R&D Program for Industrial Technology (10041659), funded by the Ministry of Trade, Industry and Energy (MOTIE).