
Abstract
Multitag identification is one of the main advantages of the radio frequency identification (RFID) system. In the RFID system, the capture effect often happens in the real environment. When the capture effect occurs, the reader will not completely identify the tags in its scope. In many RFID applications, to get the real-time number of tags, the reader identifies the tags repeatedly. In these cases, the tag in the reader's scope is a staying tag or an arriving tag. The reader already stores the IDs of all staying tags, so it can just verify the existence of these tags to rapidly identify them. As a result, the reader can spend the main time in recognizing arriving tags. To cope with the capture effect and identify staying tags rapidly, this paper presents a collecting collision tree protocol for RFID tag identification with capture effect (CCT). In CCT, a collecting mechanism is adopted and a lot of staying tags can be recognized in a slot. What is more, the reader can identify all tags in its range when the capture effect happens. Finally, various analysis and simulation results show that CCT outperforms the existing algorithms significantly.
1. Introduction
Radio frequency identification (RFID) is a noncontact automatic identification technology [1], which is one of the most important technologies of the internet of things (IOT). The RFID system has been widely used in locating and tracking, warehouse management, goods inventory, and other aspects of daily lives [2, 3]. The main components of the RFID system are reader and multiple tags. When multiple tags send information to the reader simultaneously, collisions between these tags' signals will cause that the reader cannot receive the tags' data correctly. The colliding tags need to retransmit their IDs to the reader to be identified. The retransmitting will increase the reader's identification delay and waste spectrum resources. Therefore, we need to propose effective tag anticollision algorithms to solve the problem of collision between tags.
Tag anticollision algorithms of the RFID system can be classified into aloha-based [4] and tree-based algorithms [5]. The main drawback of aloha-based algorithms is that a specific tag may not be identified by the reader for a long time, which is the so-called “tag starvation” problem. Tree-based algorithms do not have the “tag starvation” problem. Tree-based algorithms continually split colliding tags into two subsets, until a subset only contains one tag. Tree-based algorithms can be further divided into binary tree (BT) [6], query tree (QT) [7], and collision tree (CT) [8]. The CT algorithm adopts a bit tracking technology, in which the reader can get the precise locations of all colliding bits. As a result, idle slots are avoided. The CT algorithm has the maximum efficiency among tree-based algorithms. This paper focuses on CT-based algorithms.
In the RFID system, when several tags send data to the reader simultaneously, among these tags, if a tag's signal strength is much larger than the other tags', the reader can still receive the tag's data correctly, which is called capture effect [9–12]. The reader will not recognize all the tags in its range when the capture effect happens. To cope with the capture effect, some algorithms, such as the generalized binary tree protocol (GBT) [11], the general query tree 1 (GQT1) and general query tree 2 (GQT2) [12], and a multiround collision tree (MRCT) [13] were proposed. These algorithms can completely identify the tags in the reader's range.
In many RFID applications, the reader identifies the tags in its scope continually. For example, in an exhibition, the organizers want to get the real-time number of visitors in each showroom. For another instance, the library manager wants to know the real-time numbers of different books in every bookshelf. Similar demands may also exist in ranch monitoring, warehouse management, and so on. In these situations, a tag in the reader's range is either a staying tag or an arriving tag. The reader should spend the main time in identifying arriving tags and recognize staying tags rapidly. For these applications, many algorithms were proposed [14–17], but these algorithms cannot work in the capture environment.
Considering the two requirements mentioned above, we present a collecting collision tree protocol for RFID tag identification with capture effect (CCT). When the capture effect happens, CCT reader can recognize all the tags in its range. If CCT reader identifies the tags in its range repeatedly, it can identify many (e.g., 32, 64, or more) staying tags in a slot by using a collecting mechanism. As a result, the reader's efficiency is improved greatly.
The rest of this paper is organized as follows. Section 2 describes related works. Section 3 depicts the details of the proposed CCT. CCT is analyzed in Section 4. Simulation results and discussions are contained in Section 5. Finally, Section 6 concludes the full text.
2. Related Works
Before introducing related works, we define two terms which are round and slot. A round represents the period from the time the reader starts to send commands to the time the reader identifies all the tags in its scope. The ith round is labeled as
2.1. Bit Tracking Technology
Manchester code is widely used in the bit tracking technology. The encoding rule of the Manchester code is that bit 0 is represented by a positive transition and bit 1 is depicted by a negative transition. In the RFID system, when multiple tags transmit their IDs, which is encoded as Manchester code to the reader simultaneously, the reader can locate the positions of colliding bits. Assume that the IDs of Tag A and Tag B are 1100 and 1011, respectively. When the two tags send their IDs to the reader at the same time, the reader will receive a bit string of

Bit tracking technology.
2.2. Collision Tree (CT)
The bit tracking technology is used in CT. A CT reader maintains a stack Q to store ID prefixes. The initial value of Q is empty. At the beginning of a round, the reader sends a Query command without a parameter. All tags in the reader's scope send their IDs to the reader when receiving the command. If the reader detects no tag or only one tag replies, it terminates the current round. Otherwise, if the reader receives that the tags' responses are colliding, assuming the received bit string is
2.3. Multiround Collision Tree (MRCT)
A CT reader cannot identify all the tags in its scope when the capture effect happens. MRCT is proposed to cope with the capture effect.
MRCT includes multiple CT process. The tags hidden by the capture effect are identified in the subsequent CT process. The implementation process of MRCT is similar to CT. In MRCT, when a reader identifies a tag correctly, it sends an ACK command with the tag's ID. After receiving the ACK command, the tag whose ID matches the command parameter exits from the current round. After the completion of a CT process, MRCT reader continues to send a Query command without a parameter, and the command lets all the hidden tags reply to the reader. After MRCT reader sends a Query command without a parameter, if no tag replies to the command, the reader terminates the current round.
MRCT reader can identify all the tags in its range. However, if the reader recognizes tags repeatedly, the reader has to use the same operations to identify staying tags. To let a staying tag exit from the current round, the reader needs to transmit an ACK command. When the number of staying tags is large, the reader consumes many slots to send ACK commands. Although the reader has stored all staying tags' IDs, each staying tag retransmits its ID to the reader. As a result, the reader still spends long time in identifying staying tags.
2.4. Generalized Binary Tree Protocol (GBT)
GBT is modified from BT. GBT reader uses multiple BT process to identify the tags in its range completely. The tags hidden by the capture effect will be identified by the reader in the next BT process. GBT reader can identify all the tags in its range when the capture effect occurs. However, in the real environment, the probability of the capture effect may be small, or even 0, and in this situation, if the reader needs to identify tags repeatedly, GBT cannot recognize staying tags rapidly and staying tags will collide with arriving tags.
2.5. General Query Tree 1 (GQT1) and GQT2
GQT1 is modified from QT. The reader in GQT1 stores a stack Q which is a prefix set. The initial values of Q are
The difference of GQT2 from GQT1 is that when the tag response is successful, the reader stores q to Q, rather than
From the identification process of GQT1 and GQT2, we can get that the reader can identify all tags in its range in the capture environment. However, when the probability of capture effect is low, there will be many idle slots in GQT1 and GQT2 and the identification delay of the reader will be increased. Meanwhile, if the reader needs to identify the tags in its range repeatedly, the reader has to recognize all tags in the same way. GQT1 and GQT2 cannot avoid the collisions between staying tags and arriving tags and cannot identify staying tags rapidly.
3. The Proposed Algorithm
3.1. The Principle of CCT
To cope with the capture effect and identify staying tags rapidly, we propose CCT. CCT reader can not only recognize all the tags in its range, but also identify staying tags quickly by using a collecting mechanism. Because of the collecting mechanism, many staying tags are identified by the reader in a slot and the collisions between staying tags and arriving tags are prevented. Thus, the data amount transmitted by tags is reduced greatly and the efficiency of the reader is improved significantly.
CCT reader uses two phases to identify all tags in its scope. In the first phase, the reader adopts the collecting mechanism to recognize staying tags. Based on the collecting operation, many (e.g., 32, 64, or more) staying tags reply to the reader in a slot. The reader can identify all staying tags contained in the slot, even though the responses of these tags are colliding with each other. In the second phase, the reader can identify all arriving tags when the capture effect happens. What is more, if the reader recognizes an arriving tag successfully, it assigns a unique TID which is larger than 0 to the arriving tag. As a result, the arriving tag will quit from the current round. In the next round, if the arriving tag still stays, it will be identified by the reader as a staying tag.
3.2. System Requirements and Assumptions
In CCT, the reader maintains a stack Q to store the prefixes of tag ID. Each tag maintains a counter TID which means temporary ID. The TID is recorded as a temporary variable, such as a register which will lose value if the tag leaves from the reader's scope. We assume that the coverage areas of any two readers are not overlapped. Thus, if a tag comes back again after it leaves from the reader's range for a while, it will be considered as an arriving tag. The value of TID is used to distinguish whether a tag is a staying tag or an arriving tag. The length of TID is 16. The TID of a staying tag is larger than 0 and the TID of an arriving tag is 0. The values of staying tags' TIDs are different from each other. If a staying tag leaves from the scope of a reader, its TID should be reset to 0 when it enters next time. CCT reader uses a two-dimensional table CQ to save the associated relationship between TIDs and IDs. The first column of CQ saves TIDs and the second column of CQ contains IDs. In the RFID applications, the reader should prepare a large memory if it needs to identify a large number of tags, even though the number of tags may be small in some cases. For simplicity and ease to process, the size of the CQ table can be static, which means that the static memory is only used to save tags' TIDs and IDs.
Besides the assumption of the reader's coverage area described above, some other assumptions adopted in the proposed CCT are as follows.
In a slot, all tags reply to the reader simultaneously. As a result, the reader can get the locations of all colliding bits. The wireless channel between the reader and tags is ideal. Thus, receipt errors are caused by collisions rather than channel errors.
These assumptions are common in the existing researches [8–13].
3.3. The Improvements of CCT
CCT has the following two improvements compared to MRCT.
In CCT, if the reader identifies an arriving tag successfully, the reader sends an ACK command with RID and RTID, where RID is the received ID and RTID is used to assign a unique TID to the tag. To keep track of the existing TIDs in the CQ table, the reader should save the tag's TID and ID to CQ. When an arriving tag is recognized by the reader, the tag's TID becomes a nonzero value, indicating that the tag becomes a staying tag, and then the tag no longer responds to the reader's command which is sent to the arriving tags.
CCT reader uses three commands to identify all the tags in its range, which are Query, ACK, and Collect. The commands Query and ACK are used to identify arriving tags and the command Collect is used to recognize staying tags. The parameters and responding conditions of these commands are described below:
Query: the command's parameter is prefix. Only arriving tags (TID = 0) reply to the command. If the prefix is null, all the arriving tags send to the reader. Otherwise, if the prefix is not null, the arriving tag, whose ID matches the prefix, replies the rest of its ID to the reader; ACK: the command's parameters are RID and RTID. Only arriving tags respond to the command. When receiving the command, the tag with ID = RID sets its TID to RTID. When assigning TIDs to tags, the reader should keep the continuity of tags' TIDs. For example, if there are three staying tags in the reader's scope, the TIDs of these tags are 1, 2, and 4, respectively, and then the reader should firstly assign 3 to the next arriving tag. If the TIDs of staying tags in the reader's range are already continuous, the reader assigns TID to the next arriving tag incrementally; Collect: the command's parameters are
3.4. The Procedure of CCT
The pseudocode of CCT is shown in Pseudocode 1, where (a) shows reader operations and (b) depicts tag operations.
(a) (1) Q = empty, (2) (3) (4) (5) MS = 0 (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) Transmit a Collect command with (23) Receive tag responses (24) (25) Delete all the TID which belong to (26) (27) Delete the TID whose reply bit is 0 and the associated ID from (28) (29) (30) (31) (32) (33) (34) prefix = pop(Q) (35) Transmit a Query with prefix (36) Receive tag responses (37) (38) readall = 1 (39) (40) Save two prefix to Q (41) (42) Generate a unique RTID (43) Set RID as the received ID (44) Save the RTID and ID to (45) Transmit an ACK with RID and RTID (46) (47) (48) (49) (b) (1) (2) TID = 0 (3) (4) Receive a command s from the reader (5) (6) (7) Reply a bit string (8) (9) (10) (11) (12) TID = RTID (13) (14) (15) (16) (17) (18) Transmit the remaining ID (19) (20) (21)
3.4.1. Reader Operations
Before the current round begins, the reader initializes parameters as shown in lines 1–6 of Pseudocode 1(a), where
The identification process of the reader is divided into two phases. The first phase identifies staying tags and arriving tags are recognized in the second phase.
To identify staying tags, the reader transmits a Collect command with
Then, the reader ends the first phase and starts the second phase. In the second phase, the reader pops a prefix from Q and sends a Query command with the prefix. When popping a prefix from Q, the reader sets prefix to null if Q is empty.
After sending a Query command, the reader receives tags' responses. If no tag replies, the reader checks whether the prefix is null or not. If the prefix is null, the reader sets readall to 1 as shown in lines 37-38 of Pseudocode 1(a). If the tags' responses are colliding, the reader stores two prefixes to Q according to the first colliding bit as shown in lines 39-40 of Pseudocode 1(a). If the tags' responses are readable, the reader sets RID as the received ID and generates a unique RTID which should keep the continuity of TIDs, and then the reader stores the RTID and RID to CQ and sends an ACK command with the RTID and RID as shown in lines 42–45 of Pseudocode 1(a). After receiving tags' responses or sending an ACK command, the reader checks whether readall is 1 or not. If readall is not 1, the reader continues to pop a prefix from Q and send a Query command with the prefix; otherwise, if readall is 1, the reader terminates the current round.
3.4.2. Explanations of CQ Table Management
From the procedure of the reader operations, we can get that the management of CQ table is complicated. We add some explanations here.
In the first phase of reader operations, the reader should delete the leaving tags' TIDs and IDs from CQ. However, in the second phase, the reader should save the arriving tags' TIDs and IDs to CQ. Besides the deleting and saving operations, as the reader should keep the continuity of TIDs, the reader needs to search for all TIDs. Therefore, the operations about CQ are deleting, saving, and searching.
In the RFID system, the reader generally has enough storage and computation ability. Thus, the operations of storing the new TIDs and being sure of not having conflicts, searching for TIDs, and updating the table are acceptable for the reader. What is more, in the proposed CCT, the tags would be waiting for the reader's command after they replied to the reader. Based on this mechanism, the reader also has enough time to complete these operations.
3.4.3. Tag Operations
If the tag first enters the reader's scope, it sets its TID to 0 as shown in lines 1–3 of Pseudocode 1(b). When the tag receives a Collect command with
4. Performance Analysis
The identification delay of a tag anticollision algorithm is defined as the number of slots a reader consumes to recognize all the tags in its range. In [13], the identification delay of MRCT is analyzed. However, the slots that a reader transmits ACK commands are not considered; for example, if MRCT reader uses r times CT process to identify n tags, then the reader's identification delay is as follows:
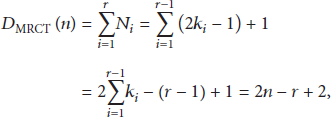
According to the result in (1), if the capture effect does not occur, MRCT reader needs two CT process to complete the identification; that is,
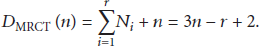
When the capture effect does not occur, the identification delay of MRCT is
The capture effect can reduce the identification delay of a reader. When the capture effect does not occur and the reader identifies tag repeatedly, we analyze the identification delay of CCT and MRCT. Assume that the number of tags in

For CCT, the reader uses two phases to identify all tags. In the first phase, the reader can identify

Next, we analyze the data transmission amount of CCT and MRCT, which are labeled as
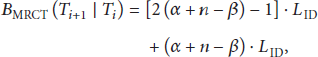
For CCT, the data transmission amount is calculated as follows:

5. Simulation Results
In this section, we simulate the performance of CCT in identification delay: this metric means the total number of slots used by a reader to identify all tags, which is the most important performance indicator; number of collision slots: a collision slot contains a reader command and tag responses, but the reader cannot recognize any tag in the slot. Thus, high-performance anticollision algorithms should reduce the number of collision slots; data transmission amount: in the identification process, the data transmission between the reader and tags takes up the most part of the recognition time, so the data transmission amount is also an important factor that affects an anticollision algorithm's performance.
When a reader identifies tags repeatedly, we analyze the impact of staying tags' number and arriving tags' number on the performance of CCT, MRCT, GBT, GQT1, and GQT2. We define the staying ratio
In a practical RFID system, the probability of the capture effect cap is typically low. Therefore, cap is set to 0.2 in all the simulations. The tag ID length is set to 96, which is the most commonly used in practice. We repeat every simulation 300 times and get the average values.
5.1. Impact of Staying Tags
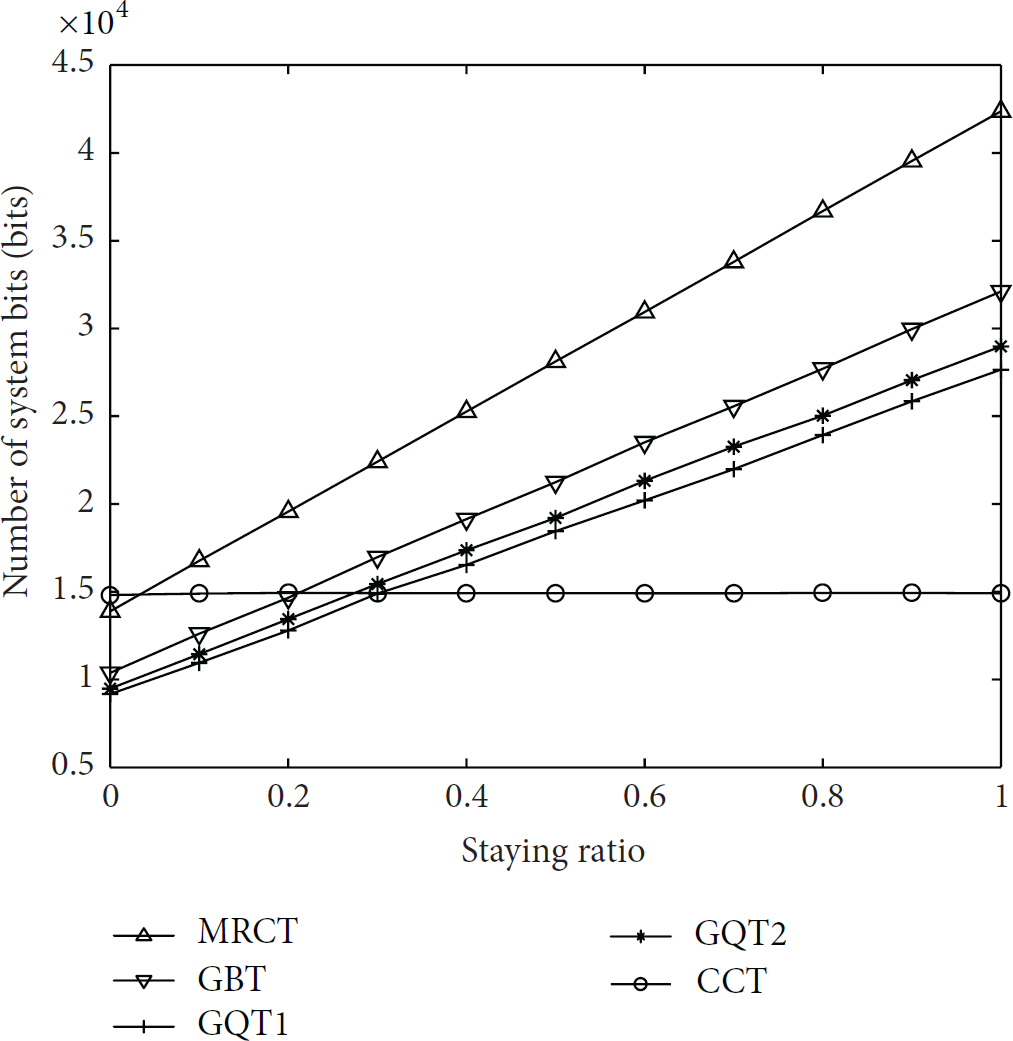
Table 1 shows the simulation parameter settings. The identification delay, numbers of collision slots, and data transmission amount of these algorithms are shown in Figures 2, 3, and 4, respectively.
Simulation parameter settings.


The impact of

Impact of
Impact of
Figure 2 depicts the impact of
Figure 3 describes the effects of
Figure 4 shows the changes of these algorithms' data transmission amount as
5.2. Impact of Arriving Tags
When we evaluate the effects of
Simulation parameter settings.

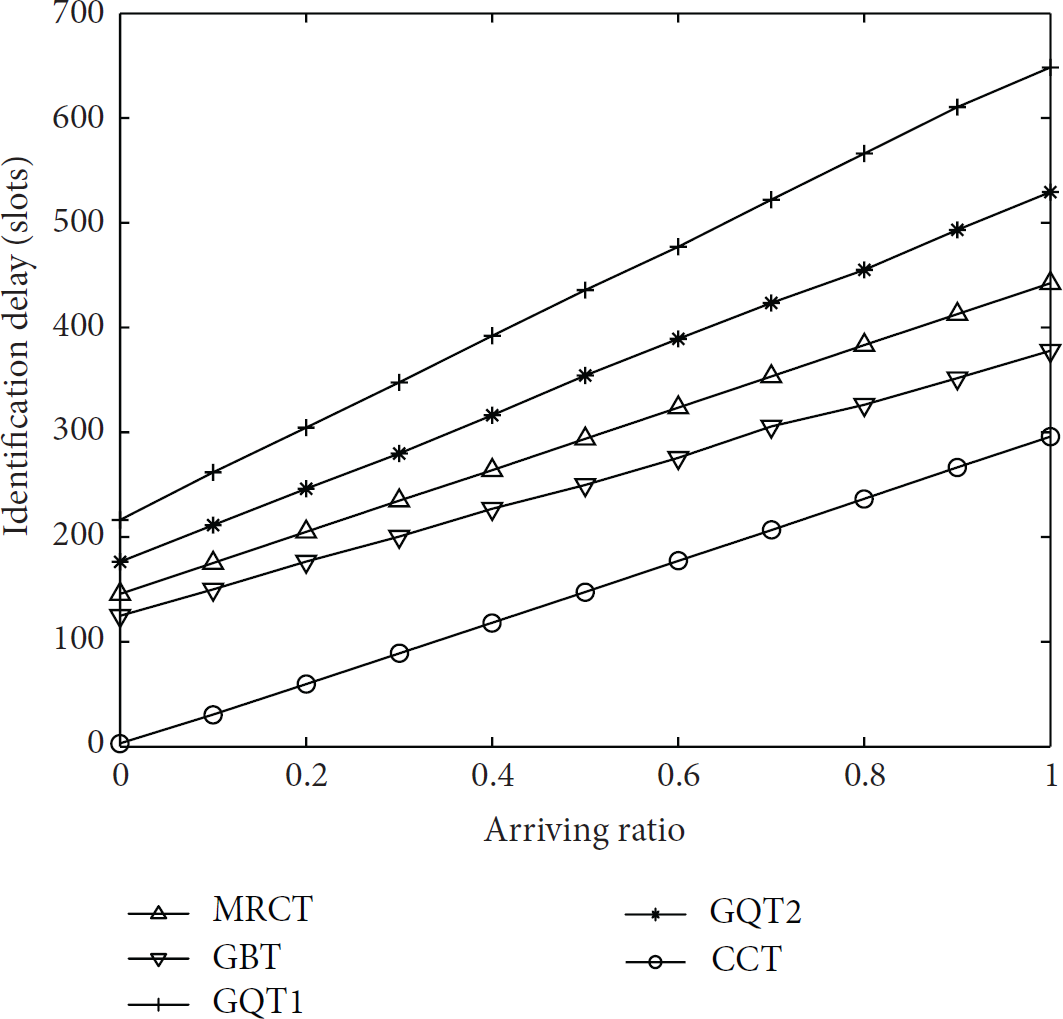
The impact of

Impact of

Impact of
Figure 5 shows the impact of
Figure 6 shows these algorithms' numbers of collision slots when
Figure 7 illustrates the data transmission amount of these algorithms when
6. Conclusion
Capture effect is an inevitable phenomenon in the RFID system. When a reader identifies the tags in its scope repeatedly, it should recognize staying tags rapidly and spend the main time in identifying arriving tags. Based on these demands, this paper presents a collecting collision tree protocol for RFID tag identification with capture effect (CCT). Compared to the existing algorithms, CCT has the following advantages.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This work is supported by National Natural Science Foundation of China (no. 61201167).