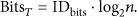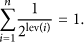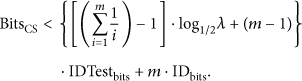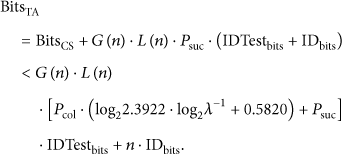Recently, RFID technology has come into end-user applications for monitoring, tracking, and so forth. In RFID system, a reader identifies a set of tags over a shared wireless channel. When multiple tags communicate with the same reader simultaneously, all packages will be lost and no tag can be recognized, which is known as tag collision. Tag collision is a significantly important issue for fast tag identification. We firstly make a thorough analysis among a variety of traditional RFID anticollision algorithms. Then a novel hybrid anticollision algorithm called T-GDFSA is proposed. Tags are assigned to different groups based on the initial tag estimation and then experience several dynamic read frames for identification. When a collision occurs in current slot, a tree-based recursive process will be deployed immediately. T-GDFSA combines the advantages of ALOHA-based and tree-based together and acquires higher system throughput by reducing unnecessary idle and collision slots and lower communication complexity by decreasing the data transmitted, which makes it identify tags faster with less power consumption. Simulations show that the theoretical values match well the simulation results. Moreover, T-GDFSA also has a good tolerance for the inaccuracy of initial tag estimation and the length variation of tag's ID.
1. Introduction
In the recent decades, Radio Frequency Identification (RFID) has become one of the most commonly used technologies in our daily life. RFID technology is similar to the technologies of barcodes and magnetic strips, but, in addition, it has the capability of identifying objects uniquely and even without requiring direct line of sight. It is nowadays getting more prevalent in daily applications, such as electronic toll collection, public transport, access control and security, and airport luggage position tracking [1, 2]. A basic RFID system is composed of a reader and a set of tags. The reader inquiries tags that are able to communicate on the wireless channel, returning their IDs. Tags are typically passive devices, which answer to reader's query by backscattering the received signal [3, 4]. However, because of all readers and tags sharing the same communication channel, when more than one reader tries to transmit to the same tag or more than one tag tries to communicate with the same reader simultaneously, all their packages will be lost. This phenomenon is called RFID system collision, which leads to long identification time, low system efficiency, and high power consumption [5, 6]. As illustrated in Figure 1, there are two different categories of collisions in RFID system: (1) reader collision and (2) tag collision. Reader collision happens when multiple readers coexisting in the same area interfere with each other, and can be overcome by the coordination strategy among readers. Tag collision occurs among tags simultaneously transmitting to the same reader and may be more difficult to solve because of constraints of energy supply and computing complexity on tags with low functionality. Since tag collision is considered as a key problem affecting the universal adoption of the RFID system, in this paper, we primarily focus on tag collision in single reader scenarios.
(a) Reader collision in RFID system. (b) Tag collision in RFID system.
In order to avoid tag collision, many tag anticollision algorithms have been proposed so far, which can be classified into two categories, ALOHA-based probabilistic anticollision algorithms [7–10] and tree-based deterministic anticollision algorithms [11–13]. ALOHA-based algorithms decrease the probability of collision by randomly scheduling the response time of tags. In those algorithms, identification time is slotted and time slots form up read frames. Frame size varies over time and is broadcast by the reader to all tags at the beginning of each read frame. When receiving frame size, tags select one time slot from current read frame randomly and only respond the reader when the selected time slot comes. Colliding tags are scheduled into the next read frame to be slotted and identified, until there are no tags left. The main representatives are DFSA [8, 9] and EDFSA [10], both of which need to estimate the initial tag population to set the proper read frame size to optimize performance. However, when the number of tags becomes much larger compared with the frame size, the performance deteriorates seriously. A detailed study of these two algorithms is presented in Section 2. On the other hand, tree-based algorithms proceed with the identification process represented as a tree where the root responds a set of tags to be identified. The algorithms periodically query a subset of tags which match the given query property, and continuously split a set of tags into two subsets until each set has only one tag. Although the identification time may be longer than that of ALOHA-based algorithms, they are deterministic which can avoid that a specific tag may not be identified all the time, leading to the so-called “tag starvation problem.” The main representatives are BS [11], QT [12], and QTI [12]. Unfortunately, there are many distinct disadvantages in BS, QT, and QTI. A great number of colliding subsets exist in BS, while performance of QT and QTI is very sensitive to the distribution of tag's ID. A more detailed description is shown in Section 2.
Furthermore, a good tag anticollision algorithm for RFID passive tags should have the following characteristics. Firstly, a reader must identify all tags existing in its covering range, as tag starvation problem may cause failure of tracking and positioning objects. Second, system throughput should be high enough to ensure tags are recognized promptly, which is of great importance for mobile tag identification. Finally, communication complexity ought to be low, since passive tags supplement power supply from the reader's electromagnetic wave, which causes the available power for tags being very limited. On the other hand, low communication complexity is also very useful for the RFID applications where large scale mobile readers are deployed.
Based on the analysis hereinbefore, we propose a novel hybrid anticollision algorithm to improve the performance of RFID tag identification. The new algorithm, called Grouped Dynamic Framed Recognition and Binary Tree Recursive Process (T-GDFSA), generally identifies tags by grouped dynamic frames and calls binary tree recursive process to solve each colliding slot. As T-GDFSA combines ALOHA-based and tree-based anticollision together, it avoids the waste of idle slots in the late identification stage in ALOHA-based and colliding slots in the early identification stage in tree-based. Also because of the combination, the communications between the reader and tags become reduced which means less power is consumed. According to the later simulations in Section 4, T-GDFSA acquires higher system throughput by reducing unnecessary idle and collision time slots and lower communication complexity by decreasing the data transmitted between the reader and tags, which overwhelm other main anticollisions and make it easier to be realized in the end-user applications.
The remainder of this paper is organized as follows. In Section 2, a variety of ALOHA-based and tree-based tag anticollision algorithms are observed specifically. In Section 3, the main concept and description of T-GDFSA are present in detail. In Section 4, evaluation of time complexity and communication complexity of T-GDFSA are proposed, respectively. In Section 5, performance simulations between T-GDFSA and other anticollision algorithms are shown via Matlab. Lastly, Section 6 gives conclusion.
2. RFID Tag Anticollision Algorithms
In this section, we review the main representatives of ALOHA-based and tree-based tag anticollision algorithms for RFID system. The major metrics observed include time complexity and communication complexity. We analyze time complexity by the identification time for recognizing a set of tags, expressed by T, and study communication complexity by the total bits sent by the reader and the average bits sent by single tag for the identification, expressed by and , respectively.
2.1. Dynamic Framed Slotted ALOHA (DFSA)
DFSA is an ALOHA-based algorithm which can adjust the read frame size dynamically according to the estimation of tag population. The identification process is made of several read frames, which is slotted into intervals of time, called time slot, whose duration is equal to the tag's ID transmission time. Before the initialization of the first read frame, the reader estimates the unidentified tag population n and sets the read frame size L. Tags randomly select one time slot in the range of and only respond the reader when the selected slot comes. As the proper frame size is decided in advance, DFSA decreases the potential collision probability to a great extent. The population of unidentified tags is estimated in the following way. Let be the number of colliding time slots; let be the number of time slots with single tag which can be identified successfully and let be the ratio of and n which can be calculated by (1). When the current read frame is finished, the population of unidentified tags varies to , which is set to be the new size of the next read frame to maintain an optimal system throughput:
If we define as the duration of time slot, as the initial frame size, L as the actual frame size after initial frame, as the possibility of successful identification for a tag after k times attempts, as the symbol length of slot interval, as the symbol length of acknowledgment sent by the reader after receiving tag's ID, and as the length of tag's ID, the major metrics of DFSA can be described as follows:
However, when tag population is large, the performance of DFSA deteriorates heavily. This is because the size of memory recording the selected slot in tags is limited and cannot keep pace with the increase of tag population, which makes the optimal condition that the frame size is set equal to the tag population not satisfied.
On the basis of DFSA, in order to enhance the system performance when tag population is large, EDFSA introduces the grouping strategy that it randomly splits tags into different groups according to the maximal frame size and the estimated number of unread tags. Only the tags associated with one of the groups are queried in the following read frames; then the identifications for tags in other groups are followed sequentially. In fact, the grouped identification is more like a combination of several DFSA processes. Chebysev's inequality is used in the end of each read frame to estimate the number of tags left, which is used to adjust the number of groups and frame size for the incoming read frames.
The grouping and frame sizing strategy is represented in Table 1, where the group number and frame size are adjusted in the way of doubling or halving, which can be easily realized in practical applications by the operation of left shifting or right shifting the group register.
The strategy of grouping and frame sizing.
Tag populationn
Frame sizeL
Group sizeG
Tag populationn
Frame sizeL
Group sizeG
⋯
⋯
⋯
177–354
256
1
6–11
8
1
355–707
256
2
12–19
16
1
708–1416
256
4
20–40
32
1
1417–2831
256
8
41–81
64
1
⋯
⋯
⋯
82–176
128
1
If we define the same notations as given in DFSA above, the major metrics of EDFSA can be derived as follows:
2.3. Binary Tree Algorithm (BS)
BS and Query Tree (QT) are both tree-based algorithms, in which the reader iteratively queries a subset of tags matching a given property until all tags are identified. They differ in the way of querying tags: according to a binary random number in BS and a query prefix in QT. In BS, the reader recognizes tags in the time interval called read cycle. Colliding tags are split into two subsets recursively until just one tag is allocated in every subset. The tag has a counter initialized to 0 in the very beginning. Only tags with counter value equal to 0 can respond the reader query in current read cycle, and other tags keep silent and wait for their counters decreasing to 0. Tags modify the value of counter depending on the result of current identification. If a collision happens, colliding tags add a 1-bit binary value randomly to their counters, which are split into two subsets with the counter at 0 and the counter at 1, respectively. Other tags not involved in the collision increase their counters by 1 to maintain their former identifying order unchanged. In case of identifying successfully or no response, all tags unread decrease their counters by 1, and tags with counter at 1 respond the reader in the next read cycle.
If we define as the duration of a read cycle, as the minimal integer not less than , as the length of query command, and other parameters as the same notations given in DFSA above, the major metrics of BS can be expressed as follows:
The expressions (4) and (5) are general equations when k, collision times, that is, the depth of current node (read cycle) in the binary tree (the whole identification process), tends to positive infinity. For convenience, we derive the lower bounds of T and for reference. As in BS the binary tree representing the whole identification process is a strict binary tree; the intermediate nodes denoted by (i.e., the colliding times) achieve minimal value when they are regarded as a complete binary tree whose number of nodes can be expressed as . Consider the fact that the number of all nodes in the strict binary tree satisfies the inequation , and each node corresponds with a read cycle, so we can derive the following expressions for fast tag estimation:
2.4. Query Tree Algorithm (QT)
QT splits a tag set according to tag's ID. The reader transmits a query including a bit string, and only the tag whose ID has a prefix matching the query string responds by transmitting its ID. In particular, if the current query string is and leads to a collision, the reader uses two 1-bit longer queries, that is, and , in the next read cycles in turn, which splits the set of colliding tags into two subsets. If a collision still occurs when the new 1-bit longer query string is sent, then the string length is further increased by 1 bit with 0 or 1 added to the end of the current query string, until the collision is solved and a tag is identified successfully. The reader has a stack S to manage query strings. In the beginning, S is initialized as NULL, which causes all tags response. When collision occurs, the reader pushed two 1-bit longer query strings into S. When current read cycle is finished, it pops a query string from S for the next read cycle. That S is popped empty indicates that all tags are recognized. Notice that collisions in QT correspond to the intermediate nodes, not including the root node, compared with BS.
If we define the same notations as given in BS above, the major metrics of QT can be derived as follows:
2.5. Query Tree Improved Algorithm (QTI)
There are amounts of useless query strings in QT, which increase the read cycles and depress the system throughput. QTI is an enhancement that removes those certainly causing collisions in advance. For example, consider the case in which query prefix q has produced a collision, while result in no response. As definitely leads to a collision, QTI skips it directly and takes as the next query prefix.
Compared with QT, QTI only reduces the amount of data transmitted by the reader, while it maintains the amount of data sent by tags unchanged, which also makes the expression of unchanged.
If we follow the same notations defined in BS, we can obtain the formulas as follows:
From what has been discussed hereinbefore, we can see clearly that, regardless of time or communication complexity, the metrics of ALOHA-based, including DFSA and EDFSA, are the same order infinitesimal of n, while the metrics of tree-based, including BS, QT, and QTI, are the higher order infinitesimal of n. Although the metrics of tree-based algorithms seem worse, they are deterministic which can avoid the so-called “tag starvation problem” that a specific tag may not be identified all the time in ALOHA-based algorithms.
3. The Proposed Algorithm T-GDFSA
The proposed algorithm T-GDFSA can be divided into two steps, the step of the estimation of tag population and the step of tag identification. The former is just implemented once to estimate the initial number of tags existing in the covering range of the reader, which is used in the second step to calculate the optimal number of groups and frame size in each group. In T-GDFSA, the method used for tag estimation is similar to TEM (Tag Estimation Method) [14]. At the end of each read cycle, the recorded triple numbers can be obtained from the reader's memory, which quantifies the number of idle time slots, successful time slots occupied by only one tag, and colliding slots with more than two tags, respectively. Meanwhile, the expected triple numbers can be computed from the given frame size N and the number n of tags by statistical knowledge. According to Chebyshev's expression, the outcome of a random experiment involving a random variable X is most likely somewhere near the expected value of X. This property is used to calculate the distance between the recorded results and the expected results of each read cycle as defined in (10). When theminimal distance is achieved, the corresponding n is considered to be the optimal estimation of tag population. Consider
where is the expected value of colliding slots with k tags; then
In (10), the minimal ε is supposed to be achieved by a searching process with n varying in the range , where is the lower bound of n according to [15], since tags have been identified, and if there are collisions, at least tags collided. The upper bound of n is set to , since by simulation no further accuracy in the estimation is obtained if the upper bound is set to higher values.
From [1] we know that the system throughput becomes optimal when the frame size is set equal to the number of tags. In order to satisfy this condition, the grouping size is adjusted by 1 each time to ensure that the number of tags in each group is very close to the frame size. The optimal grouping size is decided by the expected system efficiency. Suppose the current number of groups is k; it will be increased to if the expected system efficiency with groups rises just equal to that with k groups. Consider
From (12), the maximum number of tags with k groups is
By the utilization of (13), the optimal grouping size G can be obtained with a varying n and a given frame size L.
Then the optimal G is broadcast by the reader with a random number to tags. Grouping rule is as follows. Each tag generates a new random number by the old received one and its serial number (tag's ID). Then the new random number is divided by G, and all tags have a group number randomly in the range . In the current read frame, only tags with group number 0 are permitted to respond the reader. When all of them have been identified, the reader begins a new read frame and tags with group number 1 are involved. The process continues until tags having group number are queried, which means all tags have been recognized. The frame size of each read frame decides how many time slots are included in it. At the beginning of each read frame, the reader broadcasts the optimal frame size L to all tags which means there are L time slots in the incoming read frame, and tags involved generate an integer in the range and save it in its slot counter. By this means, tags are allocated into L time slots randomly. In the first time slot initiated by the reader, tags with slot counter at 0 are permitted to respond the reader. When all tags in current time slot have been identified, the reader polls the next time slot and informs other unidentified tags to decrease their time slot counter by 1. Tags whose value of slot counters decreasing to 0 are permitted to respond the reader in the incoming time slot. If a collision happens in the current time slot, tags involved add 0 or 1 randomly to their slot counters which cause them to fall into two subsets. It means that a binary tree is introduced, and colliding tags are subdivided into two child nodes of the current parent node randomly. Other tags increase their slot counters by 1 so as to counteract the effect caused by splitting for the colliding tags to keep their former identification sequence unchanged. After splitting, the reader firstly turns to identify the tags in the left child node of current parent node, and if a collision is still detected, the node-splitting process will be executed again and tags falling into the deeper left child node will be read in the incoming time slot. The process will keep on going recursively until there is no collision happened in the current left child node. Because there is no more than 1 tag in the leaf, tag in it can be identified successfully and then muted. Next, the reader returns up to the parent node of the current left child node, then turns down to the right child node and identifies tags in it. There are three possible outcomes. Collision slot will cause a new node-splitting process similar to that represented beforehand. 1-tag slot will make the reader identify the tag successfully and then return to the parent node. Idle slot will make the reader directly come back to the parent node. Next, as all the child nodes of the parent node have been identified, the reader will return to the upper parent node. The procedure will continue recursively until all nodes of the binary tree have been queried, which means all tags in current colliding time slot have been identified. In the initiation of each binary tree recursive process, the reader sets a level counter for current colliding slot to record the depth of current node (i.e., read cycle) in the binary tree. It is increased by 1 when a collision happens in current node and the reader goes deeper to the child nodes and is decreased by 1 when all tags in the child nodes are already identified and the reader returns to the upper parent node. Level counter which decreased to 0 indicates that all tags in the current collision slot have been identified. In Figure 2, the tag identification process for group 1 is illustrated, where means the level counter, Φ denotes no tag responding, and each “•” represents one tag. The identification processes for other groups are similar.
The execution process of the T-GDFSA.
4. Performance Evaluation
In this section we will evaluate the performance of T-GDFSA. There are several metrics focusing on different aspects of RFID system. We take time complexity and communication complexity for emphatic analysis. Because time complexity reflects the identification efficiency which is of great importance for fast tag identification, and communication complexity indicates power consumption of the reader and tags which is of great significance for mobile RFID applications. Time complexity is defined as the total time spent to identify a set of tags in the covering range of the reader. Communication complexity refers to the amount of data transmitted between the reader and tags, which can be composed of two parts: (the total number of bits sent by the reader) and (the total number of bits transmitted by single tag in average).
Prior to deeper analysis, it is necessary to make the following important assumptions.
Assumption 1.
As data received by the reader are mostly short symbols such as acknowledgement symbols and so forth, which are much less compared with the data sent by the reader, we simply ignore it and consider that totally represents the communication complexity on reader.
Assumption 2.
The duration of time slot in read frame is set equal to that of read cycle in binary tree, which is denoted by the unified symbol , making it possible to calculate the system throughput quantificationally.
Assumption 3.
In most RFID applications, power consumption of tags is more sensitive than that of the reader. So we proposed a new strategy dedicated to reducing , which is deployed as follows. Instead of sending complete tag's ID directly, tag firstly sends IDTest (a short bit string) to test the state of the current time slot. If no collision happens, IDTest can be received by the reader successfully. The reader responds with the acknowledgement IDReq to require the tag to transmit its complete ID. The strategy eliminates the useless mass data transmission of tag's ID caused by collisions and ensures that tag's ID is sent only once. Since the length of IDTest is much shorter than that of tag's ID, is decreased drastically.
4.1. Time Complexity
The total consumed time, denoted by T, consists of three parts, (time cost in the estimation of tag population), (time cost in read frames), and (time cost in read cycles of binary tree recursive process). Then we get
Let denote the initial grouping size for the estimation of tag population, and let denote the actual grouping size calculated by (13). and represent the initial frame size and the actual frame size separately. n is the number of unidentified tags. Then and can be expressed as and , respectively. According to [1], when the condition of maximal throughput of framed slotted ALOHA, the read frame size is equal to the number of unidentified tags, is satisfied, the average number of tags in each colliding time slot is about 2.3922 on average. Because is very close to n in T-GDFSA, the average number of tags in each colliding time slot, denoted by , can be considered as 2.3922 simply.
According to the representation above, we know that the binary tree process for each colliding time slot is a strictly binary tree, so there is no 1-degree node included, meaning that any non-leaf node (the root node or the intermediate node) has two child nodes. Let and be the number of non-leaf nodes and leaf nodes, respectively; then can be easily deduced [16]. Since the root node corresponds to the colliding time slot which has already been counted in the read frame before, the effective number of nodes in every binary tree is . Since the leaf nodes are composed of 1-tag leaf nodes and idle leaf nodes, the number of actual nodes in every colliding time slot, denoted as , satisfies the inequation on average. Note the fact that when is small it is very close to , so the inequation above can be considered as equation simply. By probability knowledge, we can derive that the expected value of colliding time slots is , where is the probability of detecting a colliding time slot, and that is no less than . Substituting (14) with the all results above, we acquire the final expression of T as follows:
In expression (15), where is the probability of a tag selecting a time slot from total time slots.
4.2. Communication Complexity on Reader
is defined as the amount of data transmitted by the reader to identify a set of tags appearing in its irrigation range, which reflects the communication complexity on reader suitably. From the above analysis, we realize that, no matter in the step of initial tag estimation or in the step of tag identification process, the amount of data sent by the reader representing group size and frame size are both bits. The reader also needs to transmit QueryRep periodically to make the current time slot increased continually so as to poll tags allocated in different time slots of current frame, and the amount of data of this part can be expressed as . Besides, in every binary tree recursive process, as expressed above, the number of read cycles, , is equal to . As nodes in a binary tree consist of collision nodes and leaf nodes and the leaf nodes need no extra read cycles to query, the number of actual nodes for which reader sends read cycles should be on average. The reader sends at most 1 read cycle in every node, so the number of read cycles in every binary tree recursive process is almost 0.3922. Considering that the expected number of collision slots is , the total number of read cycles in all binary tree recursive processes is . Let be the string length of one read cycle and let be the string length of sent by the reader, respectively; can be finally expressed as follows:
4.3. Communication Complexity on Tag
Here we take for consideration to indicate the average amount of data transmitted by single tag. Because of the randomness of tag identification, the average bits of data sent by single tag are difficult to observe exactly, so the lower bound and the upper bound are introduced for reference.
(a) The Lower Bound. If one lets be the level of the ith leaf node in a strict binary tree with n leaf nodes, where i varies from 1 to n, according to the property of strict binary tree, the following equation can be easily derived:
Since , we can obtain
Expression (18) shows that the sum of levels of all leaf nodes in a strict binary tree with n leaf nodes is no less than . Because the level of node indicates that the collision times tags allocated in it have experienced, and the colliding times in a strict binary tree with n tags become minimal only when the number of leaf nodes is equal to n, the total colliding times in a strict binary tree with n tags are no less than . Let and denote the expected possibility of colliding slots and singleton slots, respectively; according to Assumption 3, the amount of data transmitted by tags in all colliding time slots satisfies
The total amount of data sent by all tags, represented by , is composed of two parts: data sent by the tags in colliding time slots and data sent by the tags in singleton slots. The former is expressed by (19). Since every tag allocated in the singleton slot transmits as well as tag's ID only once, and there are singleton slots with only 1 tag, can be derived as the following expression:
Finally, the lower bound of can be obtained as follows:
(b) The Upper Bound. In order to measure the largest amount of data sent by tags, we must take the worst condition into account. Consider the following extreme situation. Let be the probability of all colliding tags falling into the same child node simultaneously after splitting current collision node, and λ is the probability of only one tag falling into one child node. Obviously, is much large than λ at the beginning of the binary tree recursive process, which means colliding tags will fall into the same child node after splitting. As the splitting process is ongoing recursively, is decreasing and approaching λ. If and only if becomes not great than λ for the first time, the splitting of current collision node will result in one child node with only 1 tag and the other child node with the remainder tags, which separates 1 tag from the colliding tags and identifies it successfully. The splitting process will repeat recursively for the remaining tags in the colliding child node until there is no more than 1 tag falling into every node, or we can say the leaf node has been reached. Assuming that the ith identified tag has experienced times of collision before being identified successfully and m denotes the total number of colliding tags in the binary tree, we can get
So the amount of data sent by m tags in the binary tree can be considered as
In the expression above, the fact that the range of i does not include m is because the mth tag will be identified undoubtedly in the next read frame if the th tag has been identified. Therefore, by expressions (22) and (23), we get the following expression:
Seeing that is the sum of the first m terms of the harmonic series and its upper bound is [16], expression (24) can be rewritten as
Considering , so the total amount of data sent by all tags is
And the average amount of data sent by single tag is shown as follows:
Thus, the final expression of can be deduced form expressions (21) and (27), which is expressed as an inequation with a lower bound and an upper bound as follows:
5. Simulation
Next, we need to verify how close the mathematic formulas presented in Section 4 match the reality. As the key factors influencing application for anticollision algorithms include the system throughput and the communication complexities, which indicate how fast tags can be identified (especially important for mobile tags) and how low the energy is consumed, the comparisons for both of them between our algorithm and traditional ones should be made. So we program on Matlab7.1 and the simulations include (1) comparing theoretical values calculated by the mathematic formulas mentioned above with the simulative results acquired from simulations, (2) comparing the complexity of T-GDFSA with that of traditional algorithms including DFSA, EDFSA, BS, QT, and QTI, and (3) comparing the system throughput of T-GDFSA when the length of tag's ID varies in a large range or the initial estimation of tag population becomes inaccurate. System throughput, denoted by S, is defined as the ratio of the number of tags to the sum of all time slots used in the read frames and all read cycles produced for querying the nodes of binary trees and can be obtained from the formula , where is the duration of one time slot as well as the duration of one read cycle.
Before simulation, some parameters need to be set properly. The parameters are set as follows: , , , , , , , , and . Considering that the possibility that each tag falls in a slot is when the frame size is L, we set to . set to 14 means the maximal time slots in a read frame can be 214. set to 5 indicates that the maximal grouping size is 25. is set to 4, which refers to the fact that the maximal depth of the binary tree in recursive process is 24. Obviously, can be set to 23 as a sum of . and set to 8 means the reader and tags use a 1-byte string to achieve the strategy of slot test. The value of is decided by the encoding method of commands and set to 4 in our simulations, which means each command sent by the reader is represented by a 4-bit binary string. As , the maximal frame size, refers to the memory used in tags which is usually very limited in reality, it is just set to 256 in our simulations which means 1-byte memory is required in tags. Besides, the following parameters are tuned:
the number of tags to be identified. It is increased by 50 in each trial in the range .
: the initial estimated number of unidentified tags. This value is used to set the initial read frame size. It is set to , , , and for inaccurate estimation.
: the length of tag's ID. It is assigned to the value sequentially.
Running times: the times each simulation runs. It is set to be 100 times and the average result is taken for analysis.
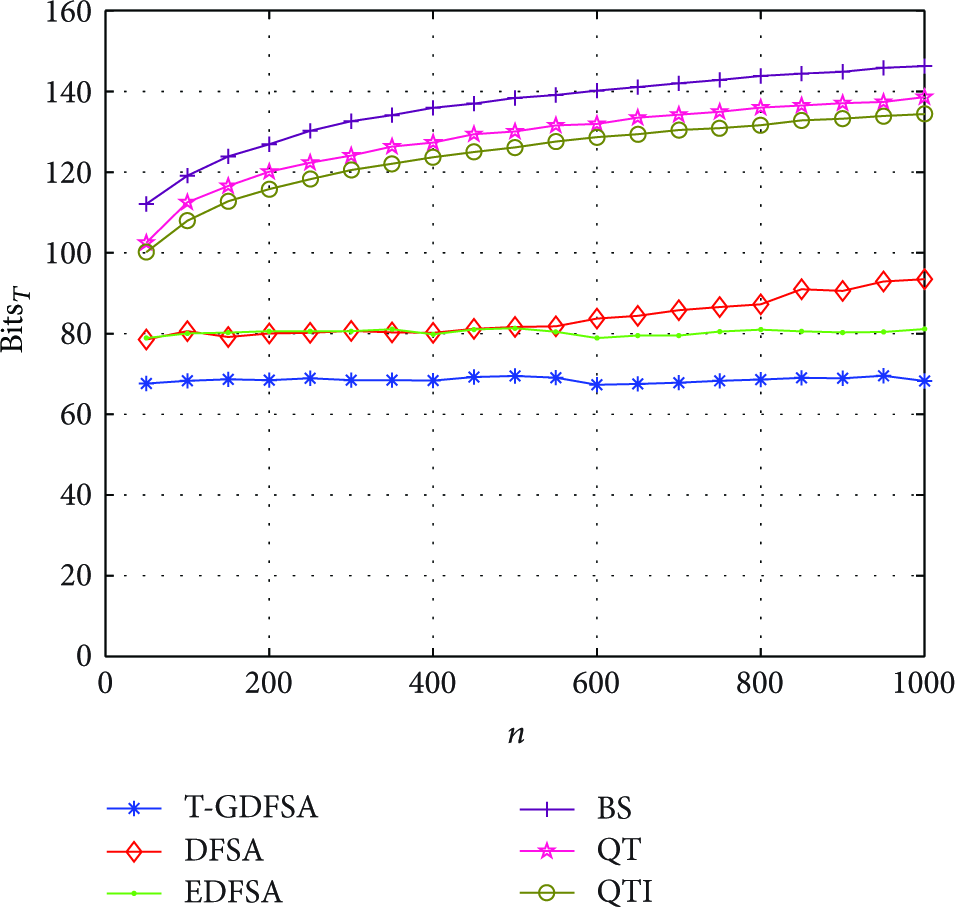
In Figures 3–5, performance comparison of T-GDFSA between theoretical values and simulative results is shown. In Figure 3, the theoretical curve of S appears as a zigzag line surrounding the curve of simulative results. The points of the wave crest of the theoretical curve correspond to the increase of grouping size, which reduces tags per group drastically and deteriorates S significantly because of more extra idle slots. Figure 4 shows that the theoretical matches well the simulative one. In Figure 5, simulative values of are mostly 69 bits and the lower bound of theoretical values is near 58 bits, with the length of tag's ID set to 48 bits. Notice that the upper bound of theoretical values is very close to simulative results when λ is set to 0.01.
The comparison of S.
The comparison of .
The comparison of , with and tag's ID uniformly distributed.
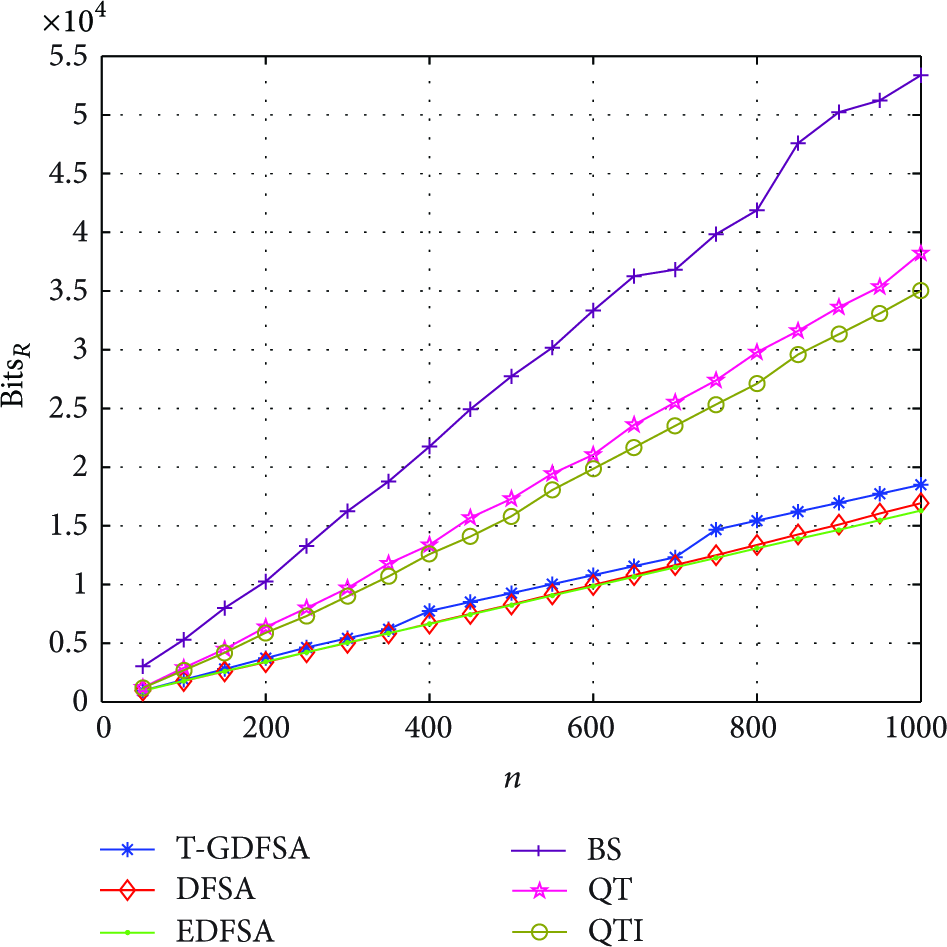
In Figure 6, compared with other traditional anticollision algorithms, T-GDFSA has the highest S about 0.41 when tag's ID is set to 48 bits long and uniformly distributed. Figure 7 shows that T-GDFSA has agreeable which is reduced by at least half of that of tree-based algorithms and nearly equal to that of ALOHA-based algorithms. In Figure 8, T-GDFSA has the lowest which means more power is saved in tags compared with other traditional algorithms.
The comparison of S, with and .
The comparison of , with and .
The comparison of , with and .
Figure 9 shows the variation of S with inaccurate initial tag estimation. When the estimated number is varying from to , S is still higher than 0.38, which indicates that T-GDFSA has great tolerance for the inaccuracy of initial tag estimation. We also notice that T-GDFSA performs better in underestimation than overestimation. This is because smaller frame size in underestimation causes more tags to fall into colliding time slots, which can make full use of the advantages of T-GDFSA, while in the case of overestimation the identification process is more like an EDFSA identification, with more 1-tag time slots and idle time slots. Figure 10 shows that length variation of tag's ID has little influence on S. When tag population exceeds 450, this effect can be approximately ignored.
S versus n, when with the inaccuracy of initial estimation of tag population.
S versus n, under the condition of and the length variation of tag's ID.
The simulations above reflect the following. (1) Our mathematic formulas of the main metrics match well the reality. (2) Compared with traditional algorithms, T-GDFSA achieves higher system throughput while maintaining lower computing complexities, which is not available for traditional algorithms shown above. This significant advantage makes our algorithm easier to be realized in end-user applications.
6. Conclusion
In this paper, we firstly make a summary of traditional RFID anticollision algorithms, and then propose a novel hybrid anticollision algorithm called T-GDFSA to improve the performance of RFID tag identification. T-GDFSA, which is based on grouped dynamic frame-slotted ALOHA and binary tree recursive process, has optimal group size and optimal read frame size and solves colliding time slots by introducing the binary tree recursive process. System model and mathematics formulas are present, and theoretical values of metrics show great agreement with the simulative results obtained from simulations. Compared with traditional ALOHA-based and tree-based anticollision algorithms, T-GDFSA exhibits excellent comprehensive performance with preferable system throughput around 0.41 and lower communication complexity which is similar to EDFSA but at least half less than that of tree-based algorithms. Furthermore, T-GDFSA has tolerance for the inaccuracy of initial tag estimation and the length variation of tag's ID.
As we can see, an accurate estimation of actual tag population in T-GDFSA is very significant. The estimation is used to set the optimal grouping size and frame size which ensures the performance. Meanwhile, the computing complexity of estimation cannot be very high to ensure the reader to identify tags promptly. However, the estimation in T-GDFSA follows TEM (i.e., Vogt's method), which may not be optimal in both of time and accuracy, so one of the possible directions of our next work is to find a way to improve the estimation method for T-GDFSA to achieve better performance of RFID tag identification.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was sponsored by the National Natural Science Foundation of China (Grant nos. 61102034, 61172156, and 61071038), the Doctoral Fund of Guangdong University of Technology (Grant no. 113002), and Shenzhen Application Foundation key project (Grant no. JCYJ20130401095559824).
References
1.
KimS. S.KimY. H.AhnK. S.An enhanced slotted binary tree algorithm with intelligent separation in RFID SystemsProceedings of the IEEE Symposium on Computers and Communications (ISCC ′09)July 2009Sousse, Tunisia23724210.1109/iscc.2009.52022402-s2.0-70449510404
2.
LuoX.XuZ.YuJ.ChenX.Building association link network for semantic link on web resourcesIEEE Transactions on Automation Science and Engineering20118348249410.1109/tase.2010.20946082-s2.0-79960112691
3.
ZhaoJ. M.LiW. T.LiD.-A.Identifying the missing tags in categorized RFID systemsInternational Journal of Distributed Sensor Networks201420141258295110.1155/2014/5829512-s2.0-84904634738
4.
BagnatoG.MaselliG.PetrioliC.VicariC.Performance analysis of anti-collision protocols for RFID systemsProceedings of the 69th Vehicular Technology Conference (VTC ′09)April 2009Barcelona, SpainIEEE1510.1109/vetecs.2009.50737752-s2.0-70349664276
5.
ZhangW.GuoY.-J.TangX.-M.CuiG.-H.WuL.-K.MeiY.An efficient adaptive anticollision algorithm based on 4-ary pruning query treeInternational Journal of Distributed Sensor Networks20132013784874610.1155/2013/8487462-s2.0-84893823969
6.
YanX.-Q.LiuY.LiB.LiuX.-M.Numeric evaluation on the system efficiency of the EPC Gen-2 UHF RFID tag collision resolution protocol in error prone air interfaceInternational Journal of Distributed Sensor Networks20142014971623210.1155/2014/7162322-s2.0-84897552379
7.
NamboodiriV.DesilvaM.DeegalaK.RamamoorthyS.An extensive study of slotted Aloha-based RFID anti-collision protocolsComputer Communications201235161955196610.1016/j.comcom.2012.05.0152-s2.0-84866357102
8.
KeatC. S.ShyanL. N .Dynamic framed slotted ALOHA algorithm for RFID systems with enhanced tag estimation techniqueProceedings of the IEEE International Conference on RFID-Technologies and Applications (RFID-TA ′13)September 2013Johor Bahru, Malaysia1410.1109/rfid-ta.2013.6694517
9.
ChaJ. R.KimJ. H.Dynamic framed slotted ALOHA algorithms using fast tag estimation method for RFID systemProceedings of the 3rd IEEE Consumer Communications and Networking Conference (CCNC ′06)2006Las Vegas, Nev, USA768772
10.
LeeS.-R.JooS.-D.LeeC.-W.An enhanced dynamic framed slotted ALOHA algorithm for RFID tag identificationProceedings of the 2nd International Conference on Mobile and Ubiquitous Systems: Networking and Services (MobiQuitous ′05)July 2005San Diego, Calif, USA16617210.1109/mobiquitous.2005.132-s2.0-33749512062
11.
HushD. R.WoodC.Analysis of tree algorithms for RFID arbitrationProceedings of the IEEE International Symposium on Information Theory (ISIT ′98)August 1998Cambridge, Mass, USAIEEE10711410.1109/isit.1998.7086952-s2.0-84890380390
12.
LawC.LeeK.SiuK.-Y.Efficient memoryless protocol for tag identificationProceedings of the 4th International Workshop on Discrete Algorithms and Methods for Mobile Computing and Communications (DIALM ′00)August 2000Boston, Mass, USA75842-s2.0-0034592716
13.
MyungJ.LeeW.SrivastavaJ.ShihT. K.Tag-splitting: adaptive collision arbitration protocols for RFID tag identificationIEEE Transactions on Parallel and Distributed Systems200718676377510.1109/tpds.2007.10982-s2.0-34248658262
14.
VogtH.Multiple object identification with passive RFID tagsProceedings of the IEEE International Conference on Systems, Man and Cybernetics (SMC ′02)2002Hammamet, Tunisia69
15.
BonuccelliM. A.LonettiF.MartelliF.Instant collision resolution for tag identification in RFID networksAd Hoc Networks2007581220123210.1016/j.adhoc.2007.02.0162-s2.0-34547813120
16.
LangsamY.AugensteinM. J.TenenbaumA. M.Data Structure Using C and C++ (2nd Edition)19952ndEnglewood Cliffs, NJ, USAPrentice Hall