
Abstract
Based on the deployment knowledge and the irreversibility of some hash chains, a novel pairwise key distribution scheme (DKH-KD) for wireless sensor networks is proposed. In DKH-KD scheme, before the nodes in the network are deployed, the offline server constructs a number of hash chains and uses the values from a pair of reverse hash chains to establish their pairwise keys among the nodes in the same region, while, among the neighbor nodes in the different regions, some pairs of the hash chains based on the deployment knowledge are employed to establish the pairwise keys. These procedures make the attackers hard to break the network and ensure that the probability of the pairwise key establishment is close to 1. Compared with the Dai scheme and the q-composite's scheme, our analyses show that DKH-KD scheme can improve the probability of the pairwise key establishment and the invulnerability more efficiently.
1. Introduction
Compared with traditional networks, a wireless sensor network (WSN) is an acentric, self-organizing, multichannel routing, distribution-intensive, and dynamic topological network. There exist a large number of resource-limited nodes in a WSN. WSNs have been widely used for a variety of purposes and situations, such as in smart homes, environmental monitoring and medical surveillance, national defense and national security, and other sensitive areas. At the same time, due to the fact that the sensor nodes in the network are resource-limited in their storage spaces, communication capability, and computing power, WSNs face many security challenges [1–3]. To an extraordinary degree, these security issues reside in the security of the keys used in WSNs. Therefore, to design a safe and reliable key management scheme for WSNs is the crucial point of these security issues, while the key distribution is one of the core steps of the key management.
In 2002, Eschenauer and Gligor proposed a key distribution strategy (denoted as “E-G scheme” for short) for the large-scale distributed sensor networks (DSNs) [4]. In E-G scheme, the precondition that makes any two nodes communicate with each other is that the two nodes must have at least one shared key chain from their own key pool. Some previous work improved the E-G scheme. Such as in [5], the improved scheme required that any two nodes must have at least q the same keys to communicate with each other, but it is more secure than the E-G scheme. The pairwise key predistribution scheme described in [6] was based on Blom-matrix with threshold characteristics and a binary symmetric polynomial. Although this scheme improved the security significantly, the node's energy consumption also increased. In [7], a deterministic key distribution scheme was proposed. This scheme adopted an incomplete block design and a finite projective plane to construct the pairwise keys, and its advantage was that any two adjacent nodes could establish a shared pairwise key, but it has the disadvantage that the nodes would lose some storage space and their security was also reduced. In [8], a combinatorial design solution was introduced based on a generalized quadrangle. This solution made up the shortcomings of the scheme given in [7], but it also reduced the node's local connection probability. Because the nodes within the same region will more likely become their adjacent nodes than the nodes deployed in different regions do, some improved pairwise key distribution schemes were proposed based on the deployment knowledge in [9–11]. These schemes had a relative balance between the local connection probability and the security. Based on the deployment knowledge and some hash chains, in this paper, a key distribution scheme for WSNs is proposed.
The remainder of this paper is organized as follows. Some notations and hash chains are given in Section 2. Some related key distribution schemes for WSNs are introduced in Section 3. Based on the deployment knowledge and some hash chains, a novel key distribution scheme, called DKH-KD, is proposed in Section 4. In Section 5, based on our simulating results, we make the performance analysis on our scheme. Finally, some conclusion remarks are made in Section 6.
2. Notations and Hash Chains
2.1. The Notations
Some notations with their implications are introduced in “Notation” section, and they are to be used in our following discussions.
2.2. Hash Chain
(For a seed s, a generated hash chain may be fore-and-aft symmetric; that is, its reverse hash chain becomes the same to the hash chain. It will result in some potential safety hazard to our scheme. In order to prevent this phenomenon, we can check whether the obtained hash value is equal to some previous hash values when we compute the hash value. If it happens, then we reselect the seed s and regenerate the hash chain, or we can make the hash value plus 1 or minus 1 and then compute the next hash value. If our selected hash function is a cryptographically secure hash, then fore-and-aft the symmetric hash will be produced in a very small probability.)
Definition 1.
By randomly selecting a seed s and a hash function


A hash chain.
2.3. Reverse Hash Chain
Definition 2.
Let
2.4. GetHash Function
Definition 3.
Suppose that
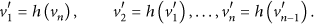
The model of
2.5. Network Model
The traditional key distribution technologies are generally used in some large-scale wireless sensor networks. But these technologies had some inherent disadvantages. For example, in order to ensure a certain local connection probability, the nodes must store a large number of keys. Usually, two adjacent nodes have stored a lot of meaningless key relative information of other nonadjacent nodes and it will waste the nodes’ storage space. What is more, if these nodes are caught by an attacker, then they will seriously threaten the other nodes’ security.
Most of the current key distribution schemes cannot ensure the local connection probability and security well at the same time. Since deploying nodes in batch will hide the nodes’ location information, it can efficiently ensure the local connection probability and security simultaneously. In fact, deploying nodes in batch has some good characteristics, such as the nodes deployed in different batches may become adjacent nodes, and the probability of the nodes deployed in the same batch becoming neighbors is greater than that of the nodes deployed in adjacent batches becoming neighbors. Using the deployment feature can improve the local connection probability but will not reduce the network security. The network model using the deployment knowledge can be described as in Figure 3. We use

The network model based on the deployment knowledge.
3. Some Related Schemes
In this section, we introduce the basic random key distribution scheme and two improved key distribution schemes that we will deal with in our newly proposed key distribution scheme.
The E-G scheme is a basic key distribution scheme for sensor networks and it consisted of three phases, that is, key predistribution, shared-key discovery, and path-key establishment.
The key predistribution phase was composed of the five off-line steps; that is, (1) generating a large key pool, (2) randomly drawing some keys out of the key pool to establish the key ring of each sensor node, (3) loading the key ring into the memory of each node, (4) saving the key identifiers of a key ring and the associated sensor identifier on a trusted controller node, and (5), for each node, loading the ith controller node with the key shared with that node. The key predistribution phase ensures that only a small number of keys need to be placed on each node's key ring to ensure that any two nodes share a key with a chosen probability. The shared-key discovery phase takes place during DSN initialization in the operational environment where every node discovers its neighbors in wireless communication range with which it shares keys. In this phase, any two nodes will discover whether they share a key. The path-key establishment phase assigns a path-key to the selected pairs of the sensor nodes in wireless communication range that do not share a key but are connected by two or more links at the end of the shared-key discovery phase.
Chan et al. proposed a random key predistribution scheme for sensor networks in 2003 [5]. This scheme was an improved version of the E-G scheme and it is a well-known probabilistic key predistribution scheme, generally called the q-composite scheme for short. This scheme can achieve greatly strengthened security under small scale attack while trading off increased vulnerability in the face of a large scale physical attack on network nodes. The q-composite scheme uses a key pool and requires any two nodes to compute a pairwise key for their communication from at least q predistributed keys they share.
The structure of the q-composite scheme is similar to that of the E-G scheme but differs only in the size of the selected key pool S and the fact that multiple keys were used to establish communications between two nodes instead of just one key.
In its initialization phase, that is, in the key predistribution phase, a key pool set S is selected from the total key space; then, for each node, multiple keys are randomly chosen from S and stored into the node's key ring. In the key-setup phase, each node must discover all shared keys it possesses with each of its neighboring nodes. After its key discovery, each node can identify every neighbor node with which it shares at least
Based on a polynomial-based scheme over a finite field, Dai and Xu proposed an improved key predistribution scheme for WSNs using deployment knowledge [12]. We called it “Dai scheme” for short. Similar to basic key distribution scheme, it also consisted of three phases: key predistribution, shared-key discovery, and path-key establishment.
The Dai scheme includes two parts: the group-based node deployment and the polynomial-based key predistribution. The strategy of the group-based node deployment is to divide the nodes into several groups
The authors claimed that their scheme would achieve a high connectivity and enhance the resilience against node capture by increasing the size of security threshold.
In 2013, Bechkit et al. proposed a hash-based mechanism to enhance the network resiliency of key predistribution schemes for WSNs [13]. This mechanism can be applied to the existing pool based key predistribution schemes to enhance the network resiliency. To achieve this goal, the authors introduce a new method based on one way hash chain to conceal the keys such that the disclosure of some keys that reveals only the derived versions which cannot be used to compromise other links in the network using the backward keys. This mechanism was called HC. HC was applied to the q-composite scheme and the symmetric balanced incomplete block design scheme [8] to develop a new probabilistic key predistribution scheme and a new deterministic key management scheme. The authors showed that their approach would enhance the resiliency up to 40% without introducing any new storage or communication overheads except for inducing some computational overhead.
4. A Key Distribution Scheme Based on Deployment Knowledge and Hash Chain
In this section, using the deployment knowledge and some hash chains, we will describe a novel key distribution scheme called DKH-KD for short. In DKH-KD scheme, by using the irreversible characteristic of the hash function and the deployment knowledge, the nodes in the same
In our following discussion, we suppose that the nodes will not be physically captured in a short time period
4.1. Constructing the Hash Chains
Since the irreversibility of the hash function is the important guarantee of our DKH-KD scheme's security, it is very important to construct the effective hash chains. Let the number of
(1) The Forward Hash Chains
Step 1.
If
Step 2.
If
Step 3.
If
Step 4.
If

(2) Reverse Hash Chains
Step 5.
If
Step 6.
If
Step 7.
If
Step 8.
If

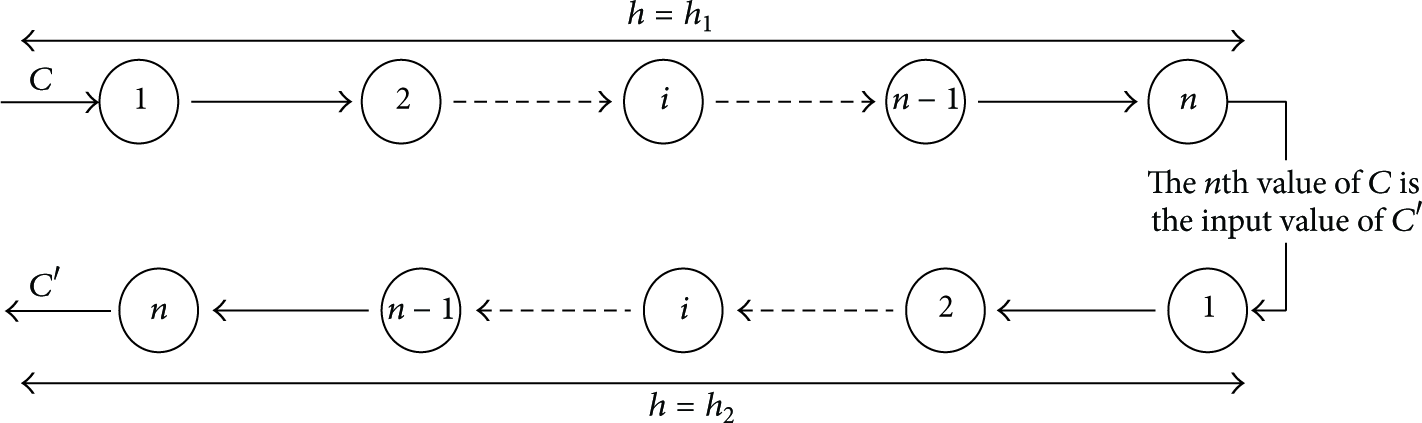
According to the above Steps 1 to 8, the all needed hash chains have been constructed in the whole networks. As in Figure 4, each
The structure of the hash chains in
4.2. Key Relative Information Distribution for the Nodes
After the hash chains of
Assume that U is the kth node in one cell. Then the offline server will distribute the kth hash value for some hash chain in U, and it also needs to distribute the (
The allocation algorithm can be described as shown in Algorithm 1.
(1) Set (2) Set NodeNum:= the number of the nodes in (3) Set ChainNum:= the number of the hash chain in (4) Initialize While (k <= NodeNum) { While (t <= ChainNum) { if ( (a) flag = True; //Mark that the values of this hash chain will be cooperatively used with the reverse hash chain; (b) Store the following six messages } else { (c) flag = False; //Mark that this chain is a common hash chain; (d) Store the following six messages } t++; } k++; } (5) End.
According to Algorithm 1,
4.3. The Establishment of the Pairwise Keys
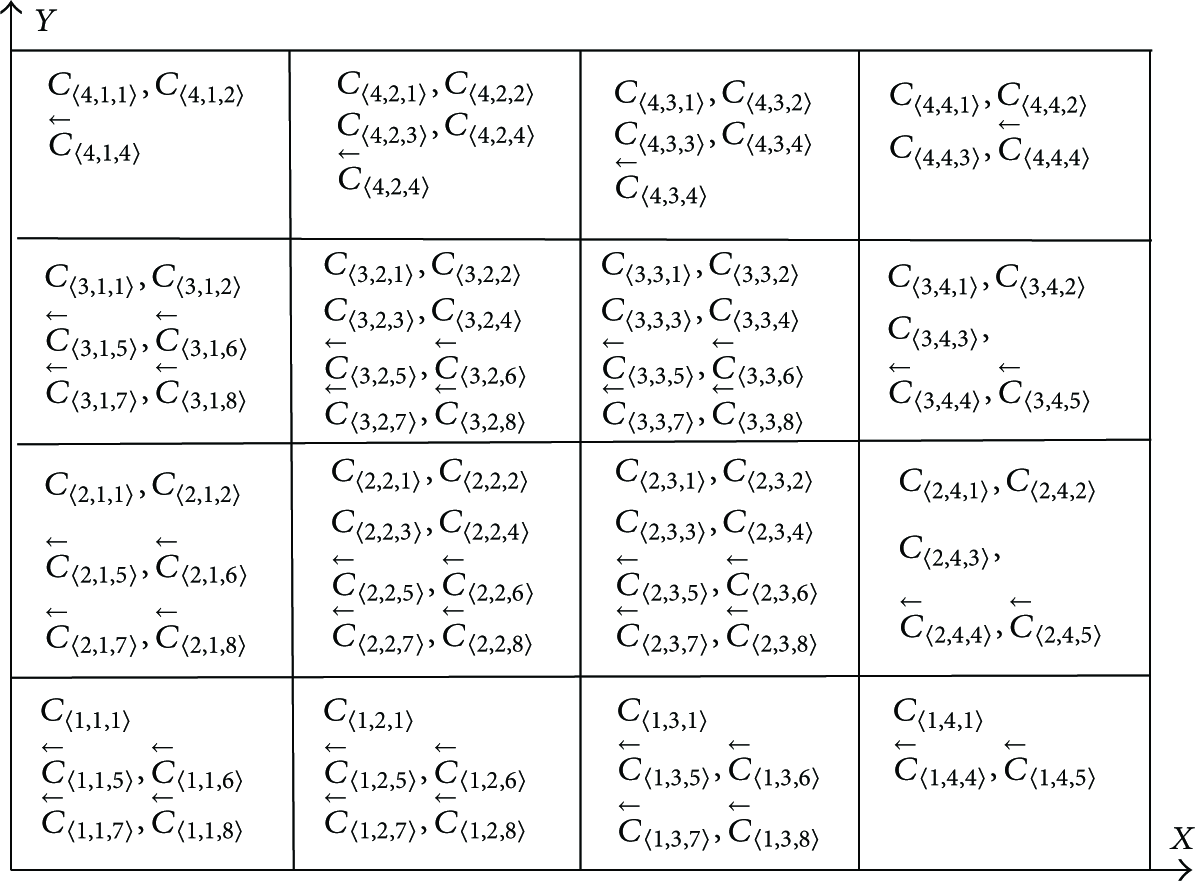
After the key relative information distribution process is completed, the nodes will immediately begin to establish the pairwise keys. Table 1 shows the hash chain information stored in one node after the key distribution Algorithm 1 has been implanted. From Table 1, we know that the adjacent nodes in the same
The key related information of one hash chain.

In the initialization phase, the nodes broadcast the key related information except
(1) Establishing the Pairwise Key for the Adjacent Nodes in the Same
Let U and V be two nodes. Suppose that the key-value pairs stored in the nodes U and V are
Step 1.
Node U establishes a pairwise key with Node V.
If If
Step 2.
Node V establishes a pairwise key with Node U.
If If
(2) Establish the Pairwise Key for the Adjacent Nodes in the Adjacent
Step 1.
Node U establishes a pairwise key with Node V: after Node U has received the broadcast messages including the subscripts from Node V, it can establish pairwise keys as follows:
U computes U computes U computes its pairwise key as
Step 2.
Node V establishing pairwise key with Node U: after node V has received the broadcast message including the subscripts from U, it can establish pairwise key as follows:
V computes V computes V computes its pairwise key as
After their pairwise keys have been established, the nodes will delete all the predistribution messages.
5. Performance Analysis
In this section, we will give detail performance analyses on our key distribution scheme. We have described that Bechkit et al. proposed a hash-based mechanism (HC) to improve the q-composite scheme and the combinatorial design version of the key predistribution scheme. The authors claimed that HC was a hash-chain based approach, but in fact it was a technique that applies a hash function multiple times on the shared keys between neighboring nodes. That is, their hash-based mechanism is totally different from our method which applies the hash chains as Figure 1 shows. In a HC based key predistribution scheme, each node has to compute a large number of hash values in order to establish the shared keys with its neighboring nodes. HC definitely strengthens the sensor network's ability against node capture attacks, but it increases some amount of computation cost and energy consumption. Since a HC based key predistribution scheme just adds many hash operations, we will not consider the two HC based key predistribution schemes HC (q-composite) and HC (SBIBD) described in [13] but the original q-composite scheme in our following discussions.
5.1. Network Simulation Parameters
To analyze the performance of our DKH-KD scheme, we will compare it with the q-composite scheme and the Dai scheme.
The Dai scheme constructed the node pairwise key by using the deployment knowledge and a polynomial pool, while the q-composite scheme is an improved scheme based on the E-G scheme, where the neighbor nodes can construct their pairwise keys if and only if they have at least q common predistribution secret key.
The following are our network simulation parameters.
The cell scale is The network node number is set to be In the Dai scheme and the q-composite scheme, the key pool size is
5.2. Probability of the Local Connectivity
Theorem 4.
In DKH-KD scheme, all the neighbor nodes in the network can establish their pairwise keys; that is, the probability that the neighbor nodes in the network can successfully establish their pairwise keys is 1.
Proof.
(1) According to the node key predistribution algorithm given in Section 4.3, we know that the neighbor nodes’ pairwise keys in the same cell are constructed by using the hash values in the same pair of the reverse hash chains, and each node in the network stores the hash values of a pair of reverse hash chains. Hence, the neighbor nodes in the same cell can establish their pairwise keys as long as they are, respectively, within their counterparts’ emission radius; that is, the probability that any two neighbor nodes in the same cell will establish the pairwise key is 1.
(2) As described in Section 4.3, the neighbor nodes’ pairwise keys in the adjacent cells are established by using the hash values in a pair of special hash chains.
Let
To sum up, any two neighboring nodes can construct their pairwise keys, that is, the network local connectivity's probability is 1. This completes the proof.

Hash chains that applied in the adjacent cells.
In DKH-KD scheme, each node will delete all the distributed information except the stored neighbor nodes’ pairwise keys and the messages of two pairs of the hash chains as soon as the nodes complete the establishment of the pairwise keys. Hence, the number of the pairwise keys stored in a node is equal to the number of the neighbor nodes plus 4.
Here, we will evaluate the local connection probability based on the average number of the pairwise keys stored in a node. For the convenience of our analysis, we assume that, after the nodes have been deployed, the average number of the neighbor nodes of a node is
Local connectivity probability under different radiuses.
5.3. Security Analysis
Theorem 5.
In DKH-KD scheme, if no nodes are captured within a short time
Proof.
(1) Within the same cell, the pairwise keys stored in the neighbor nodes are constructed through a pair of reverse hash chain values and they will not be exposed if some nodes are captured. In addition, the irreversibility of our used hash functions also ensures that the capture of some nodes will not break the network connectivity. The reasons are as follows. First, our scheme is proposed based on a supposition that the nodes will not been physically captured within the time
(2) Within the adjacent cells, the capture of some nodes will also not destroy the network connectivity. This is because of the following three reasons. (1) In any two adjacent cells, there certainly exist two hash chains as shown in Figure 5, and it can still ensure the remaining node network link's security if some nodes have been physically captured because the adversary cannot simultaneously obtain two hash values of a pair of hash chains. (2) After the nodes have constructed the key relative information, they delete all the predistribution messages (by the off-line server) including the subscript message of the first hash values of the hash chains. Hence, based on the supposition that no nodes will be physically captured in the time
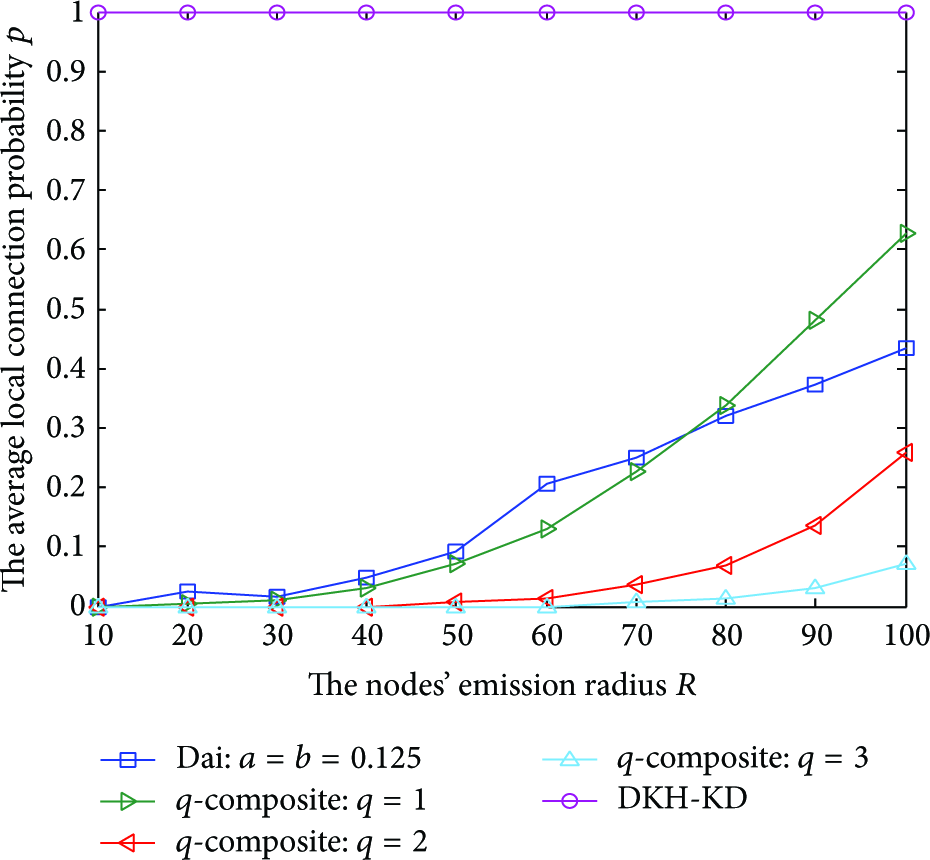
To sum up, our DKH-KD scheme is theoretically secure. That is, when some nodes in the adjacent cells are physically captured, the probability that the network link will be broken is close to 0. This completes the proof of Theorem 5.
Figure 7 shows the probability that the network link is broken with the number of the captured nodes for the three schemes DKH-KD, Dai, and q-composite when

The probability of the network link broken to the captured node number at
5.4. Storage Analysis
In the early period of the deployment, the number of the key relative messages distributed by the off-line server for a node is related to the position of the
After their pairwise keys have been established, the actual number of the keys (pairwise keys) stored in one node is equal to its neighbor node number plus 2 hash values and their subscripts, while a node's neighbor node number is related to its emission radius. Table 2 shows the average number (denoted as K) of the keys stored in one node in our DKH-KD scheme at different emission radiuses (denoted as R) in meter. Table 3 shows the number of the keys stored in a node in the schemes Dai and q-composite at different local connection probabilities for
Average number of the keys stored in a node in DKH-KD under different radius R.

The number of the keys stored in a node in Dai and q-composite under different local connection probabilities with R = 40 m.

As Tables 2 and 3 show, when the local connection probability is 0.15 or 0.69, then the number of the keys stored in a node in the Dai scheme is 19 or 279, respectively. While the number of the keys stored in a node in the q-composite scheme are 118 for
In summary, our DKH-KD scheme has some advantages over both the Dai scheme and the q-composite scheme in the storage space.
5.5. Energy Consumption Analysis
The security of our DKH-KD scheme is based on the irreversibility of our used hash chains. The establishment of the nodes’ pairwise keys is completed by computing the hash values many times. Hence, the average number of computing the hash values for the hash function will be a measure for the node's energy consumption.
According to the key distribution algorithm and the structure of the hash chains, the same values in the hash chain can be used only once. Hence, between the two hash values in the same chain, the number of computing the hash values can be counted as in the following.
Let n be the length of the hash chain, then the probability that a hash value is selected is 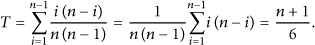
Because any two hash chains between the adjacent
Figure 8 shows the relationship of the average number

The average times of executing hash functions under different hash chain lengths.
As shown in Figure 8, if the emission radius R is a definite value, then
(1) On one hand, if the emission radius of the nodes becomes shorter, then the number of the adjacent nodes will become less and the value of
The number of the node's neighbors under the different hash chain lengths and the different launch radius R.

(2) On the other hand, the energy consumption for executing the hash function once is very low. We take CrossBow node and Ember node as the nodes for our discussion. They will, respectively, consume 154 μJ and 75 μJ to execute a SHA-1 function once [14]. If
6. Conclusion
For the security consideration, the node's key management plays a critical part in wireless sensor networks. This paper proposes pairwise key distribution schemes (DKH-KD) based on deployment knowledge and hash chains. We analyze in detail the performance of our scheme in its local connectivity, security, storage, and energy consumption, and it shows that our DKH-KD scheme can be realized with the local connection probability reaching to 1 and the nodes’ security can been significantly improved. Compared with the Dai scheme and the q-composite scheme, our scheme has certain advantages in the local connected probability, security, and storage capacity. But if some nodes in the network are physically captured during a short time period
In 2012, Stevens introduced that he implemented a differential path attack which is considered to be the most efficient attack against SHA-1 [15]. He claimed that he had a fully working near-collision attack against full SHA-1 working with an estimated complexity equivalent to
Footnotes
Notations
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work is partially supported by Zhejiang Qianjiang Talents Project (2013R10071), Zhejiang Natural Science Foundation of Outstanding Youth Team Project (no. R1090138) and the Natural Science Foundation of China (no. 61272045 and no. 61401128).