
Abstract
Data aggregation scheduling for variable aggregation rate model has wide application and should take network lifetime and energy efficiency into consideration. In this paper, the time-slot scheduling problem for the variable aggregation rate model is presented, and a time-slot scheduling integrating consideration of minimizing the energy consumption named Makeup Integer based Data Aggregation Scheduling (MIDAS) is proposed. The proposed MIDAS scheme integrates two core phases, namely, data aggregation set construction and aggregation set based scheduling algorithm. The key idea of MIDAS is to minimize the number of receiving and sending data packets in hotspot and to reduce the number of aggregated packets in network for better scheduling performance in network lifetime. Furthermore, it is also essential to increase energy utilization efficiency of the nodes in the middle layer by exploiting the remaining energy of peripheral nodes. A series of experiments are simulated to demonstrate that the proposed scheme has significantly increased the network lifetime and the energy utilization efficiency under the different aggregation rates and different network scales. Comparing with the SDAS, the lifetime can be increased by as much as 25%. The energy utilization efficiency can be improved by as much as 30%.
1. Introduction
Wireless sensor networks (WSNs) have captured considerable attention recently due to their enormous potential for environmental monitoring, surveillance operations, and industrial automation [1–5]. In wireless sensor networks, data aggregation is an important method of improving transmitting efficiency, and most existing researches have mainly focused on energy consumption [6–11] or transmission latency [12–19]. Some works have investigated the energy latency tradeoff [20–22].
In most past researches, data aggregation refers to the situation in which data packets meet at a node in the routing procedure and they are aggregated into one new data packet. Based on the assumption of transmitting one data packet in one time-slot, each node needs only one time-slot to transmit this one data packet. In real-life application, n nodes are aggregated into multidata packets. So multislots need to be assigned for one node, which may result in the allocation complexity of time-slot scheduling. And the following factors should be comprehensively considered.
(1) Interference. Each sensor is equipped only with a single radio transceiver, sending and receiving cannot be carried out simultaneously. The interference range r is the maximum distance within which nodes in receiving mode will be disturbed by an unrelated transmitter, thus suffering a loss. If a node hears more than one message at the same time, it can receive none of them correctly; therefore this causes a collision. Thus, two links are interfering if the receiver of at least one link is within the range of the transmitter of the other link.
(2) Time Constraints. Node scheduling should obey a sequential order. The time-slots are not necessarily continuously allocated for one node. A time-slot can be used for different purposes. It can be used to transmit its original data as well as the aggregated data. It can also be used to transmit other nodes' original data as well as the aggregated data. Thus, how to allocate multislots for one node will be a challenging issue.
(3) Energy Consumption. Because of the limitability of energy in WSNs, the energy consumption of sensor nodes should be considered in the process of data transmission [23–25]. Therefore, it is our major concern how to design an effective TDMA based aggregation scheduling algorithm, which can minimize the number of receiving and sending data packets in network to optimize the energy of WSNs.
Therefore, it is a challenge to study on data aggregation scheduling combining time-slot and variable aggregation rate. The main contributions of our work are as follows.
(1) This paper addressed the time-slot scheduling problem for the variable aggregation rate model. In the model, each node aggregates the original data of its child nodes and its own original data based on the given aggregation rate and then packs the aggregation result into m new data packets (
(2) This paper presented a Makeup Integer based Data Aggregation Scheduling (MIDAS) integrating to minimize the energy cost. Based on the aggregation model and the given aggregation rate, we select some nodes to construct multiple aggregation sets so that the size of each set is as close to its round-up integer as possible. And then the number of aggregated packets in the network is reduced for better scheduling performance. This method can decrease the energy consumption near the sink, increase the energy utilization efficiency, and improve the network lifetime. The key challenge is then to construct aggregation set. The aggregation set guarantees each node to aggregate once in the set. The nodes within the same aggregation set aggregate at the aggregation node in one sample cycle. And the nodes except aggregation node only forward the data from the upper stream sensors in the aggregation set. After the establishment of the aggregation set, the next step is to solve the problem of time-slot scheduling. In the schedule algorithm, the nodes in hotspots would hold on transmission and accumulate their data before sending them to sink at once.
Constructing the aggregation set with a round off thought can reduce the number of the aggregated data packets of the nodes in the first layer near the sink and decrease the energy consumption of the nodes in this area. For no aggregated nodes in the area far from the sink, the number of transmission data is not smaller but more than that near the sink. Thus, the remaining energy far away from the sink is fully utilized, which increases the energy utilization efficiency of the nodes in the middle layer and improve the energy utilization efficiency of the network.
(3) The results of simulation on the random generated tree topologies show that the time-slot scheduling proposed in this paper could realize the dual goals of improving the network lifetime and increasing energy efficiency. Comparing with the simple time-slot scheduling, the lifetime can be improved by as much as 25%. The energy utilization efficiency can be increased by as much as 30%.
The rest of this paper is organized as follows: In Section 2, the related works are reviewed. In Section 3, we discuss the research motive. The system model is described in Section 4. In Section 5, a data aggregation scheduling scheme for variable aggregation rate is presented. The simulation results and performance are analyzed in Section 6. Finally, we conclude in Section 7.
2. Related Work
The current data aggregation scheduling schemes are discussed in this section. Most previous works have mainly focused on energy-saving issue and it has been investigated in [6–11]. Krishnamachari et al. [6] illustrated the impact of data aggregation by comparing its performance with traditional end-to-end routing schemes. Wu et al. [8] used TDMA as the MAC layer protocol and scheduling the sensor nodes with consecutive time-slots at different radio states while reducing the number of state transitions. Wen et al. [9] proposed Heuristics for cluster construction and data aggregation routing such that total energy consumption is minimized. Mo et al. [10] presented a stochastic sensor selection algorithm that randomly selects a subset of sensors according to a certain probability distribution. Li et al. [11] proposed a connected dominating set based transmission scheduling algorithm. There are some papers that build a data aggregation tree to control the delay in [12–19]. The minimum-latency data aggregation problem (MDAT) in wireless sensor networks is well studied and proved to be NP hard [12]. Chen et al. had designed an approximation algorithm with the delay bound of
However, the abovementioned algorithms are all based on the assumption that data packets from n nodes can be aggregated into one data packet or n data packets and study the time-slot scheduling under these models [26, 27]. They are not suitable for the network with variable aggregation rate.
3. Research Motivation
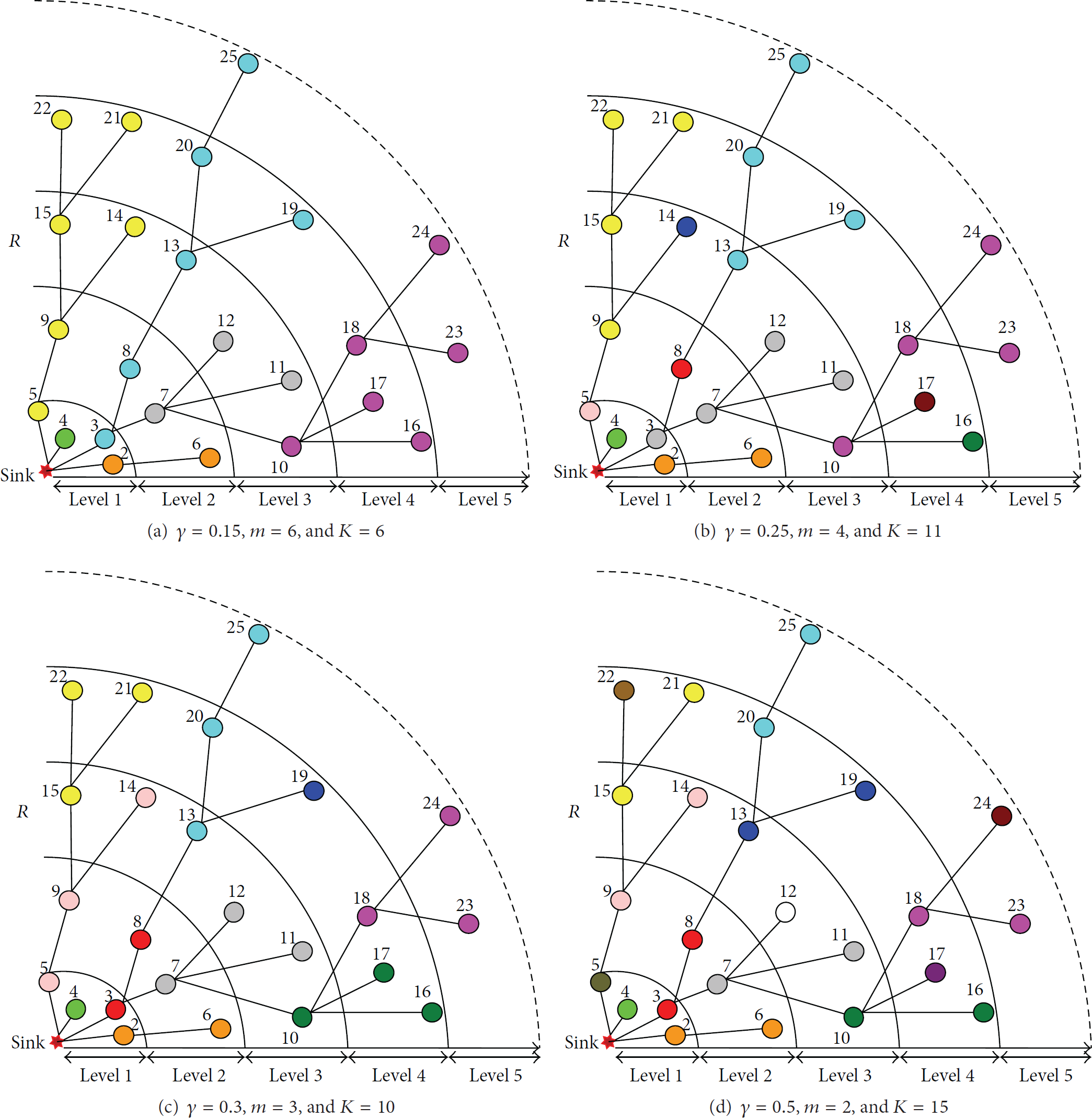
The tree topology of a random network with 25 nodes rooted at the sink is illustrated in Figure 1. And the node ID is marked in the figure. The arrow line represents data transmission paths and the dashed line indicates the transmission interference.

A randomly generated aggregation tree with 25 nodes.
Having the minimum scheduling period of one hop node set
The time-slot assignment for all nodes.

The data aggregation mechanism in [19] is based on the assumption that data packets of n nodes can be aggregated into one data packet. But if the aggregated data packets are more than one, and then there have some problems as follows.
(1) A node can not only be assigned one time-slot, but also may require multiple time-slots, which will make time-slot scheduling more complicated.
For instance, there exit two data packets that are produced by node 18 after the aggregation computation by the original data of node 18, node 23, and node 24. It must be assigned two time-slots to node 18 for transmission of the two data packets. And there are two data packets that are produced by node 10 after the aggregation computation by the original data of node 10, node 16, and node 17. It must be assigned two time-slots to node 10 for transmission of the two data packets. In addition, node 10 also needs to transmit the aggregation result of its child node 18. Thus we need to assign four time-slots totally for node 10.
Therefore, previous research methods assigning only one time-slot for one node cannot be adapted to the case where n nodes are aggregated into multidata packets. How to allocate multiple time-slots for one node to transmit its own original or aggregated data as well as its child nodes' original or aggregated data will be a challenging problem.
(2) How to design an effective aggregation scheduling algorithm which can balance the energy consumption is an important issue. Furthermore, it is also essential to increase energy utilization efficiency and prolong the network lifetime by exploiting the remaining energy of peripheral nodes.
We consider the subtree rooted at node 13 in Figure 1. Several typical aggregation scheduling approaches are selected for this explanation and the data aggregation rate is 0.25 for every node. The first is as shown in Figure 2(a), assuming that one data packet is produced by node 13 after the aggregation computation by the original data of nodes 13, 19, 20, and 25. It must be assigned one time-slot to node 13 for transmission of the one data packet. The second is as shown in Figure 2(b), assuming that one data packet is produced by node 13 after the aggregation computation by the original data of node 13 and node 19. And one data packet is produced by node 20 after the aggregation computation by the original data of node 20 and node 25. It must be assigned two time-slots to node 13, where one time-slot is used to transmit the aggregation result of itself, and another is used to transmit the aggregation result of its child node 20. The third is as shown in Figure 2(c); one slot is assigned for node 13 to send its own data, one slot is assigned to transmit the data of node 19, and one slot is assigned to transmit the aggregation result of its child node 20; that is, three slots are required for node 13. The forth is as shown in Figure 2(d); one slot is assigned for node 13 to send its own data, and three slots are assigned to transmit the data of nodes 19, 20, and 25, respectively; that is, four slots are required for node 13. The digital above the arrows represents the number of packets being sent in Figure 2.

Several typical aggregation forms of node 13.
Assume
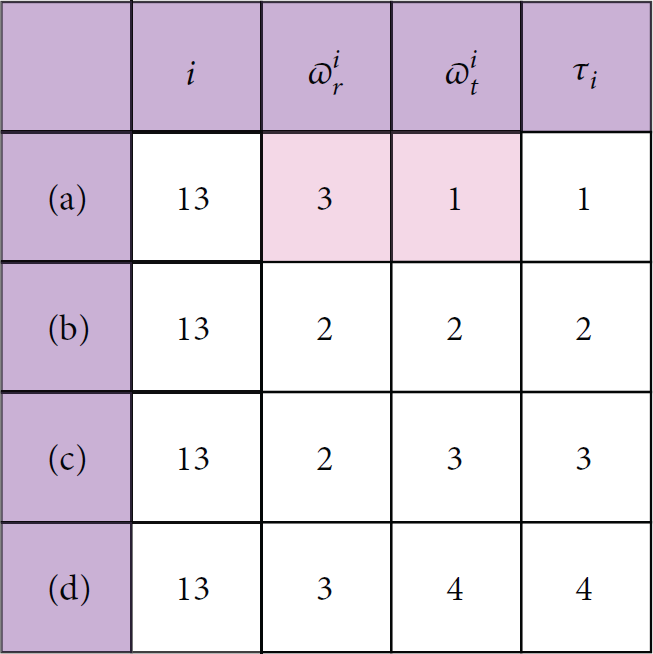
The results of an instance under different cases.
As can be seen from Figure 3, the number of receiving and sending data packets of node 13 is different when exploiting different aggregation scheduling approaches, which leads to the different number of slots required for node 13. It is obviously that the more number of forwarding packets causes the more energy cost. We can see from Figure 3 that node 13 will receive three data packets and send one data packet by exploiting the method shown in Figure 2(a). Therefore, the number of sending data packets of node 13 is the least and the energy consumption also is the lowest. So, if we design an aggregation scheduling approach which can reduce the number of receiving and sending data packets near the sink and increases the number of the transmitting data packets far away from the sink, it will balance the energy consumption and thus prolong the network lifetime.
4. The System Model and Problem Statement
4.1. Network Model
We consider a wireless sensor network 
In this paper, nodes are called one hop neighbors if there exits interferences between them. To ensure data transmission interference free, when any node is receiving data at any one timeslot, the other one hop neighbors cannot send data except to one of child nodes. And, when any node is sending, the other one hop neighbors cannot receive packets except from its parent node. We assume that the relationship between one hop neighbors except parent-child nodes is indicated by dashed lines in the aggregation tree (the same in the following).
4.2. Energy Consumption Model
The energy consumption model in this paper is the same as [29]. The energy cost when a node sends l bits data is computed by (2). The energy cost when a node receives l bits data is computed by (3). Consider the following:
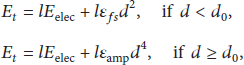

4.3. Data Aggregation Model
For each sample cycle, all sensor nodes do sampling once. At the beginning of each sample period, each sensor node generates a packet with the sensed information. The sample period is composed of multiple integer timeslots. And we assume the source data packet of each node is generated synchronously. Actually, one data packet needs to be transmitted in one time-slot. If the calculated data packet size is less than that of one packet after aggregation, we should transmit it as one data packet. And the transmission of one data packet must be finished in one time-slot. Therefore, 1.25 packets require two time-slots for transmission and 2.5 packets need three time-slots for transmission.
Definition 1 (the number of data packets ϖ).
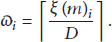
Definition 2 (data aggregation rate γ).
γ denotes data aggregation rate which is a decimal between 0 and 1. For example,

Data aggregation model.
Definition 3 (aggregation model).
For data aggregation, one adopts the lossless step-by-step multihop aggregation model. In such aggregation model,
When node i receives data 

For example, as green nodes depicted in Figure 4, we assume that the packet size is 


4.4. Problem Statements
The objective is to design a Data Aggregation Scheduling (MIDAS) scheme for variable aggregation rate WSNs. The scheduling time of the node i is denoted by
We use the energy cost model presented in Section 4.2 to calculate the network energy consumption. In this paper, network lifetime is defined as the time when the first node dies. After the first node dies in the network, it could seriously affect the connectivity and coverage of network, so that the network cannot fully play its due role. Considering all nodes in the network, the network lifetime is represented by (10), where 

There is a complex relationship among transmitting data packet, energy consumption of nodes, and network lifetime. So we try to reduce data packets transmitted in the network, especially packets in the area near the sink. In the schedule algorithm, the nodes in hotspots would hold on transmission and accumulate their data before sending them to sink at once. This could realize the dual goals of increasing the amount of information aggregated to sink and decreasing the number of the transmitting data packets in network. Thus, according to (4) in Section 4.3, we select m packets to aggregate at the aggregation node i, the minimum value of m is represented by

The work of schedule is to assign multiple time-slots to each node in the network to ensure interference free and the network lifetime maximization and the energy utilization efficiency maximization. In conclusion, the optimization goal of this paper is expressed in the following formula, where 
5. Scheme Design
5.1. Construct the Aggregation Set of Nodes
Definition 4 (aggregation set).
Given an integer m and a series set
The aggregation set results of Figure 1.
Characteristic 1. If
Characteristic 2. According to the Characteristic 1, we know that,
Our aggregation scheduling algorithm is based on an aggregation tree. Assume the maximum level number of the aggregation tree is H.
According to (12) in Section 4.4, we can get
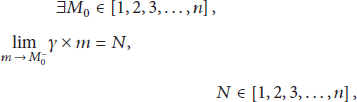
The parameters used in Algorithms 1–6 are as shown in Table 2. Consider
(3) (5) (6) (7) (8) ( ( (12) Call Search_bnode( (13) (14) (15) (16) (17) (18) (19) (
(1) Find the father node of j is (2) (3) (4) (5) calculate the number of nodes L in set (6) (7) break; (8) (9) (10) Send the message
(2) (3) (4) (5) calculate the number of nodes L in set (6) (7) break; (8) (9) (10) (11) (12) (13) break; (14) (15) Send the message
// The nodes are arranged layer by layer downward, and those in the same layer are arranged by node's ID (2) (3) (4) (5) (6) Call Tsft_Set( (7) (8) (9) (10) (11) (12) (13) Call Tsft_Forw( (14) (15) (16)
(1) (2) Calculate the number of nodes (3) (4) assign a time-slot to j which meet C3; (5) (6) (7) assign the minimum available time-slot to the child node of j in (8) assign a time-slot to j which meet C3; (9) ( ( ( ( (14) (15) (16) assign a time-slot to (17) (18) (19) ( ( (22) (23) Send the message
(1) (2) (3) (4) (5) (6) (7) (8) assign z time-slots which meet C4, C5 to j for forwarding e's aggregated data; (9) (10) (11) (12) (13) (14) ( (16) ( (18) (19) (20) (21) (22) (23) assign (24) (25) (26) (27) (28) Send the message
The main idea is to select m data packets to ensure the total amount of aggregated data close to an integer. The principle of selecting m packets for aggregation is as follows.
Given aggregation rate γ, for convenience, we assume
The pseudo code of the data aggregation set construction (CAS) process is presented in Algorithm 1. It includes a Search_fnode subfunction and a Search_bnode subfunction, which are shown in Algorithms 2 and 3, respectively.
Additionally, CAS has achieved higher time efficiency as each node would be accessed at most twice. When first being accessed, a node will be put into an aggregation set. When being accessed again, a node will be inquired and it is no longer considered when it has already existed in an aggregation set. Accordingly, CAS offered optimized algorithm for the data aggregation set construction, and time complexity of which was polynomial
For example, exploiting our proposed Algorithm 1, a series aggregation set
5.2. The Design of MIDAS
In this part, we designed an aggregation set based scheduling algorithm (TSAN), which assigns time-slots for all the nodes in the network. The approach contains two steps.
The purpose of the first step (Tsft_Set) is assigning one or multislots to nodes except aggregation node in the set. In this case, leaf node finishes its original data transmission in the assigned time-slot. And other nodes transmit their original data in the earliest assigned time-slots and forward the received data from the upper stream nodes in the same set in other time-slots. In addition, it needs to allocate one slot for aggregation node to transmit the aggregated data of the aggregation set.
The purpose of the second step (Tsft_Forw) is assigning one slot or multislots to nodes in the journey of the aggregation node to sink for forwarding the aggregated data of the aggregation set.
We search the tree layer by layer downwards in the first step. If there exists a node j that has not assigned a time-slot, we get the aggregation set The time-slot of child nodes for transmitting its original data is later than the time-slot of its father transmitting its original data. Namely, the first time-slot for transmission of the child node is later than the first time-slot for transmission of the father node. Node i has been assigned one time-slot The time-slot assigned for aggregation node is later than that of its children in the same aggregation set and of its father node in the different aggregation sets.
In the above time-slot allocation, the relay nodes transmit more data as they do not aggregate while only forwarding the data received; this property makes full use of the remaining energy of peripheral nodes. And the aggregation nodes hold on and wait for data collection to a certain amount before transmitting to its father node at once. While because the nodes in the first layer near the sink are always aggregation nodes, so the data packets transmitted from the one hop neighbors to sink are greatly decreased because of aggregation. Furthermore, it also decreases the energy consumption in this area.
The first step finished, and then we start the second. We search the tree from bottom to the top layer in the second step. If there exists a node j and it has a child node One time-slot One time-slot
In this way, all the nodes have been assigned time-slots. The pseudo code of the data aggregation scheduling is presented in Algorithm 4. It includes a Tsft_Set subfunction and a Tsft_Forw subfunction, which are shown in Algorithms 5 and 6, respectively.
We assume n denotes the number of nodes in the network. m denotes the number of nodes in an aggregation set. Firstly, we try to discuss time needed for a node to find an idle time-slot within an aggregation set. In a set, time required for sending all original data to the aggregation node is
Based on the above analysis, the time complexity of TSAN is
Figure 6 gives the node set T for each time-slot during which all the member nodes of T synchronously send packets to their corresponding parent nodes. For example, when
The node set T for each time-slot under different aggregate rates.
6. Performance Evaluation
In this section, compared with a non-round-up integer time-slot allocation approach named SDAS, the performance of the proposed MIDAS approach under different aggregation rates is evaluated. The aggregation rate of each sensor node is fixed to 0.15, 0.25, 0.3, and 0.5, respectively. The simulation is conducted on the platform of MATLAB 7.0 and the performance of the scheme is evaluated in a wireless sensor network with tree topology. And a child-parent relationship has been established. In each sample period, each node is sampled once and generates its original data packet synchronously at each sample initial time 0. The amount of information contained in an origin data packet is assumed to be 1 unit. And the number of aggregated data packets is calculated by (4). Table 3 shows the parameters and corresponding values in the network. Moreover, we assume the energy of sink is infinite and all the other nodes have the same initial energy 2 J. The energy cost only takes place in the case of receiving or transmitting data packet, which is calculated by (2) and (3). The energy utilization efficiency can be calculated by (11).
Network parameters.

6.1. Node Scheduling Time-Slot Assignment
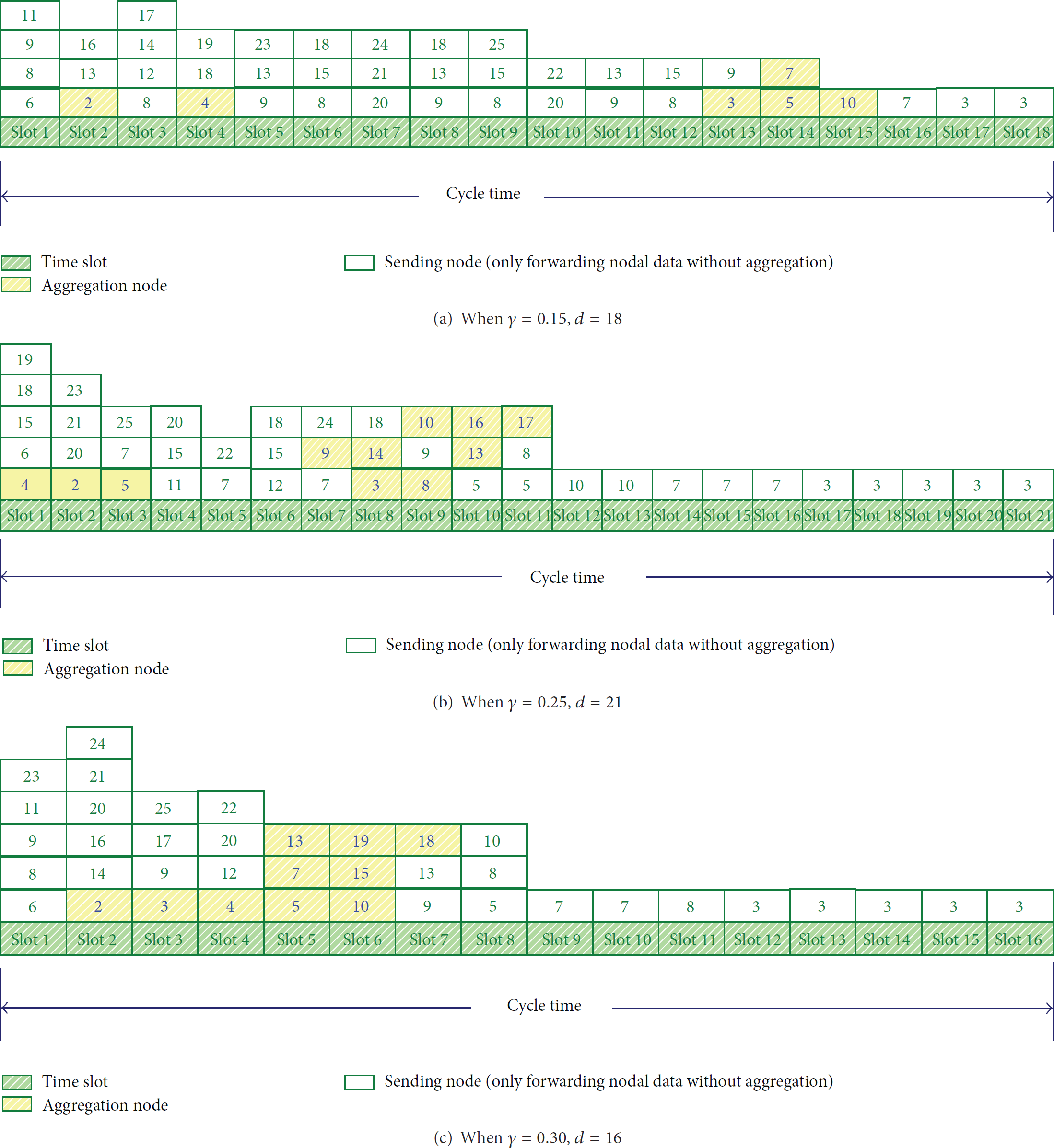
Figure 1 shows a randomly generated aggregation tree. Except the sink, distance from one node to its parent in the aggregation network is as shown in Table 4. Exploiting the proposed MIDAS, the result of node scheduling time-slot assignment of the aggregation tree shown in Figure 1 is presented in Table 5. The scheduling result is denoted by time-slots of each node to transmit. As can be seen in Table 5, each node has been assigned one slot or multislots. These time-slots of one node can be used for different purposes. For example, when the aggregation rate
Parent-child relationships and distances from child to parent node in the aggregation tree of Figure 1.

Node scheduling of MIDAS of Figure 1 under different aggregation rates.

Node scheduling of SDAS of Figure 1 under different aggregation rates.

6.2. Energy Utilization Efficiency
We compare the energy utilization efficiency property of the proposed MIDAS approach with that of SDAS.
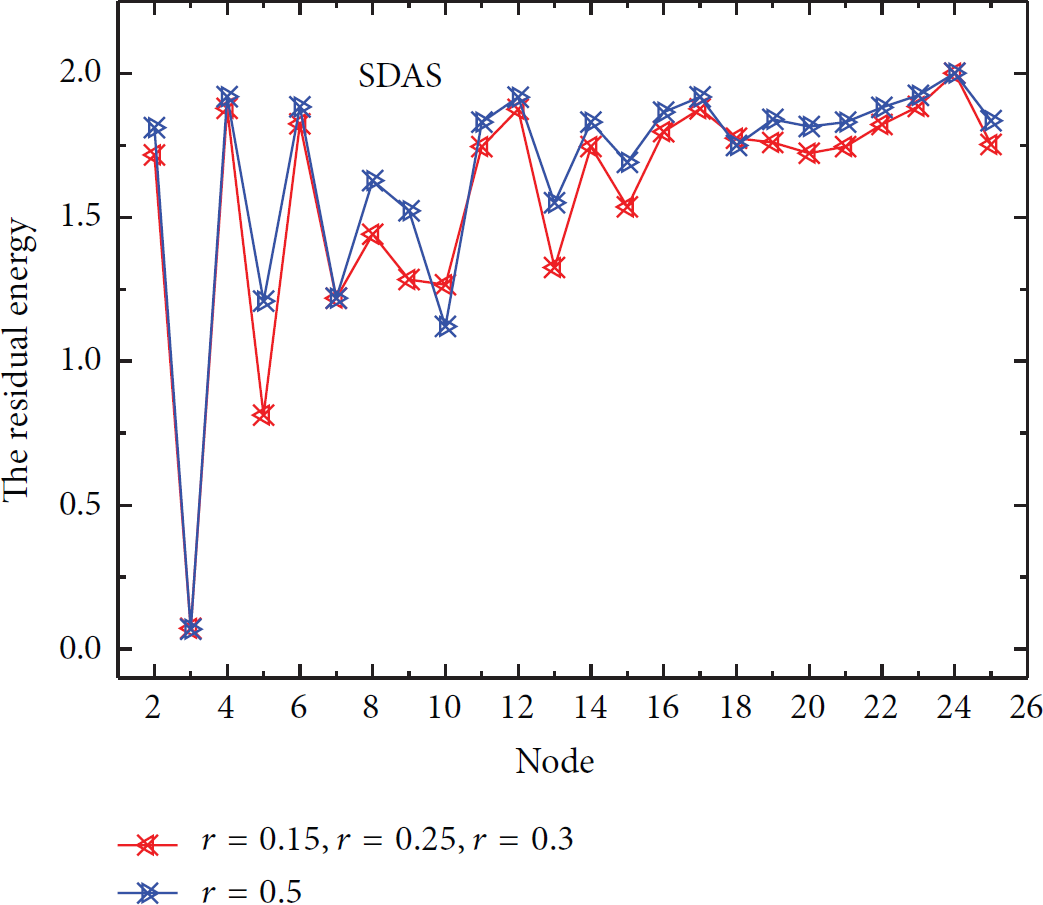
First, based on the result of node scheduling time-slot assignment presented in Section 6.1, we could obtain the residual energy of each node in network of Figure 1 when the network dies, which is shown in Figures 7 and 8, respectively.

The residual energy of the MIDAS of Figure 1.
The residual energy of the SDAS of Figure 1.
Also, we consider the case when the number of nodes in the network is increased to 100 randomly. The network parameters and aggregation scheduling algorithm are the same as the ones above. Figures 9 and 10 show the residual energy of each node by running the two algorithms, respectively.

The residual energy of the MIDAS with 100 nodes.

The residual energy of the SDAS with 100 nodes.
We can see that there is an obvious fluctuation characteristic in Figures 7 and 9. The nodes that consume more energy are not always in hotspot when the network dies. Energy dissipation is larger for most sensors in the middle layer of network, during the entire execution of the data transmission. For example, node 10 and node 13 in Figure 7 consume more energy. But in Figures 8 and 10, it can be seen that when the network dies, the nodes which consume more energy are always in the area near the sink under no matter what aggregation rate. This means that the energy consumption is larger in the area near the sink but is smaller in the area far from the sink. From Figures 7–10, we can see that our MIDAS approach can make full use of the remaining energy of peripheral nodes than SDAS.
Second, we compare the energy utilization efficiency of our MIDAS approach with that of SDAS under the different aggregation rates and different network scales. Simulations are conducted on the network with nodes of 25, 50, 75, and 100, respectively. The results are shown in Figures 11, 12, 13, and 14, respectively.

The comparison of the energy utilization efficiency under 0.15 aggregation rate.
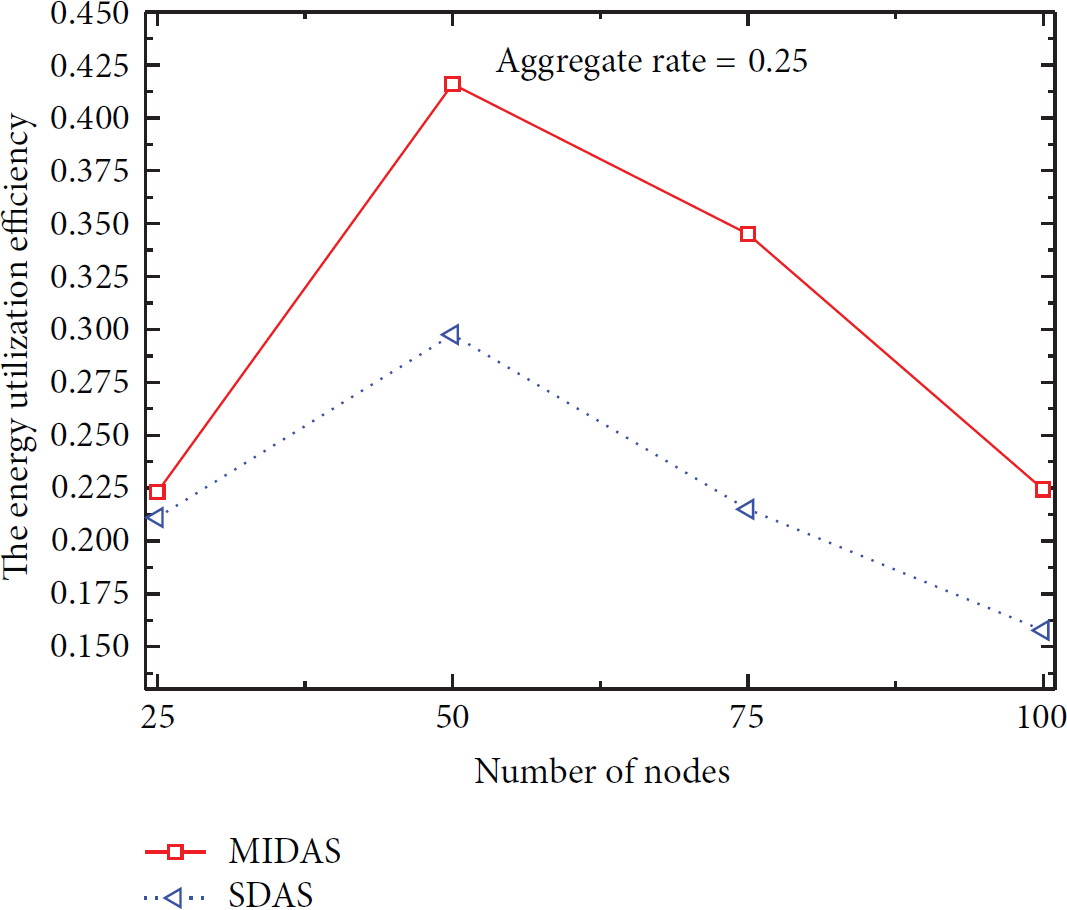
The comparison of the energy utilization efficiency under 0.25 aggregation rate.

The comparison of the energy utilization efficiency under 0.3 aggregation rate.

The comparison of the energy utilization efficiency under 0.5 aggregation rate.
Figures 11, 12, 13, and 14 compare the energy utilization efficiency of the network by using the two algorithms when the number of nodes varies. It can be seen from the figure that the energy utilization efficiency of the proposed MIDAS approach outperforms that of SDAS significantly. The energy utilization efficiency of MIDAS algorithm is mostly about 25%–45%, but that of SDAS algorithm is mostly about 15%–25%. The energy utilization efficiency of MIDAS algorithm is improved by 30% compared with the SDAS algorithm. This is because some nodes in the middle layer consume more energy for transmitting more data packets. Thus the residual energy of these nodes decreases when the transmission data packets increase. Therefore, the remaining energy far away from the sink is fully utilized, which increases the energy utilization efficiency of the network.
From Figures 7–14, we can see that our MIDAS approach can make full use of the remaining energy of peripheral nodes than SDAS so that performance of our method is better than that of SDAS in the energy utilization efficiency.
6.3. Network Lifetime
The network lifetime is an important metric to evaluate our approach. We compare the network lifetime of the proposed MIDAS approach with that of SDAS under the different aggregation rates and different network scales. Figures 15, 16, 17, and 18 show the comparison of network lifetime under the two scheduling approaches, respectively.

The comparison of the network lifetime with 25 nodes.

The comparison of the network lifetime with 50 nodes.
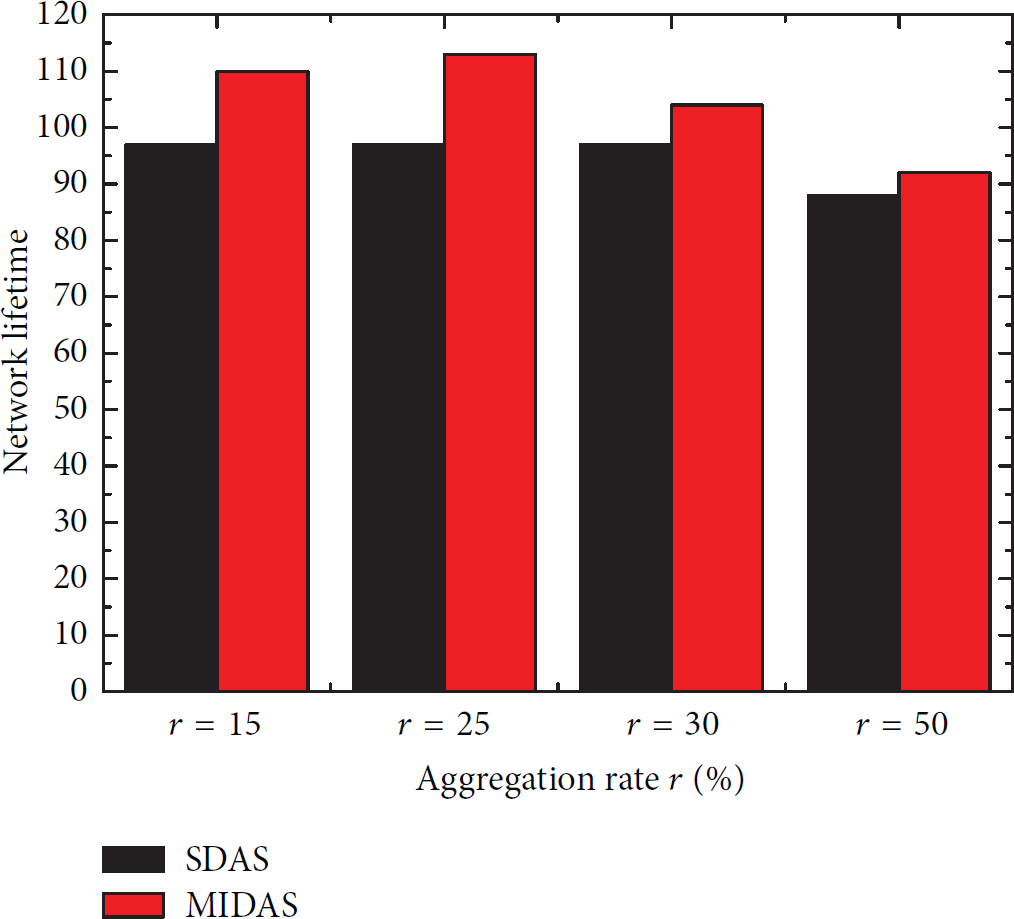
The comparison of the network lifetime with 75 nodes.

The comparison of the network lifetime with 100 nodes.
From Figures 15–18, we can see that the proposed MIDAS approach has a better performance in the aspect of network lifetime. The network lifetime of MIDAS is improved by 20% compared with that of SDAS under the same aggregation rate and the same network scales. This is because the proposed MIDAS approach has the ability to reduce the number of receiving and sending data packets near the sink for decreasing the energy consumption in this area by selecting reasonable nodes to aggregate. The aggregation nodes hold on transmission and accumulate their data before sending them to sink at once. Consequently, the energy consumption is reduced because the data needed to be scheduled in the network is reduced. This property is important since it prolongs the network lifetime by avoiding early energy depletion of sensors. Moreover, the improvement of network lifetime will be larger with the increase of the aggregation rate. This is because the number of data packets gathered by the sink decreases when the aggregation rate of nodes increases.
7. Conclusion
This paper focuses on the data aggregation scheduling combining time-slot and variable aggregation rate. Based on the aggregation model and the given aggregation rates, we proposed an efficient aggregation approach, which includes two coupled parts: aggregation set construction and an aggregation scheduling algorithm. The proposed approach can not only minimize the number of receiving and sending data packets in hotspot but also reduce the number of aggregated packets in network for better scheduling performance in network lifetime. Furthermore, it is also essential to increase energy utilization efficiency of the nodes in the middle layer by exploiting the remaining energy of peripheral nodes. Our simulation results verify the effectiveness of the MIDAS scheme. The dual goals of improving the network lifetime and increasing the energy utilization efficiency are simultaneously achieved.
In this paper, we focus on the fact that data aggregation rate is equal for every node. It would be interesting to study the algorithm extending to the case that nodes may have different data aggregation rates.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China (61272150, 61379110, and 61472450), Ministry Education Foundation of China (20130162110079 and MCM20121031), the National High Technology Research and Development Program of China (863 Program) (2012AA010105), the National Basic Research Program of China (973 Program) (2014CB046305), the Hunan Province Education Science Project (XJK015CXX006), and Central South University of Forestry and Technology Youth Fund Project (QJ2011010B).