
Abstract
Context-aware recommender systems generate more relevant recommendations by adapting them to the specific contextual situation of the user and have become one of the most active research areas in the recommender systems. However, there remains a key issue as how contextual information can be used to create intelligent and useful recommender systems. To assist the development and use of context-aware recommendation capabilities, we propose a graph-based framework to model and incorporate contextual information into the recommendation process in an advantageous way. A contextual graph-based relevance measure (CGR) is specifically designed to assess the potential relevance between the target user and the items further used to make an item recommendation. We also propose a probabilistic-based postfiltering strategy to refine the recommendation results as contextual conditions are explicitly given in a query. Depending on the experimental results on the two datasets, the CGR-based method is much superior to the traditional collaborative filtering methods, and the proposed postfiltering method is much effective in context-aware recommendation scenario.
1. Introduction
Recommender systems [1] are popular tools for assisting customers in navigating through huge archives and alleviating the side effects of information overload in big data era. Most of the recommender systems focus on mining associations between users and items (movies, music, Web information, goods, etc.) and a few works consider the context which the items are associated with [2]. However, in ubiquitous computing scenario, users can access and exchange information at anytime, anyplace, and in any way, and context-awareness is the fundamental objective of ubiquitous computing [3]. User preferences may be changed by switching contexts (such as time, location, surrounding people, emotion, devices, network conditions, etc.) and solely relying on the user-item association does not lead to a valid recommendation. For instance, some users prefer the morning instead of noon to be recommended appropriate news; some users in the tourist are likely to be recommended suitable surrounding restaurants or shopping malls; and some users prefer to watch romantic movies at a theater if they are together with boyfriends/girlfriends. Consequently, the effectiveness of recommendations will be affected if these contextual factors are not considered into the recommender systems. Context-aware recommender systems (CARS) generate more relevant recommendations by adapting them to the specific contextual situation of the user and have gradually become one of the most active research areas in the recommended systems [2].
Nowadays, there are three recognized paradigms for incorporating contextual information into the recommendation process: contextual prefiltering, contextual postfiltering, and contextual modeling [2, 4–6]. Among them, prefiltering is particularly attractive due to a straightforward justification: when context matters, use in the recommendation process only the data acquired in the same contextual situation of the target user, because only this data is relevant for predicting user preferences. However, prefiltering has not always been the best choice. Its major limitation is the difficulty to obtain enough ratings in all possible contextual conditions to build a strong and applicable prediction model [2, 7–9]. On the contrary, postfiltering modeling and contextual modeling can directly exploit available contextual factors to enrich data used for prediction, increasing in turn the effectiveness of the recommendations. Nevertheless, how to model contextual factors into a recommendation process and how to combine different strategies of CARS are still challenging tasks, and many issues are yet to be taken up. To cope with this issue, we propose a unified graph-based contextual modeling framework to incorporate contextual information in an advantageous way. A contextual graph-based relevance measure and a probabilistic postfiltering strategy are designed to facilitate the development and use of context-aware recommendation capabilities. Experimental results against two real-world datasets show the merits of all the proposed approaches in context-aware recommendation.
The rest of the paper is structured as follows. Section 2 introduces our models and the corresponding recommendation approaches for CARS. In Section 3, experiments against two datasets from different domains are conducted to watch the effectiveness of the proposed methods. Section 4 reviews related works and makes some discussions. Finally, we conclude the works and point to future directions.
2. The Proposed Methods
2.1. Graph-Based Contextual Modeling
CARS address modeling and predicting user tastes and preferences by incorporating existing contextual information into the recommendation process as explicit additional categories of data. These long-term preferences and tastes are generally expressed as ratings and are modeled as the function of not only items and users, but also the context. Adomavicius et al. [2] formally define the recommending process in CARS as
Distinct from building a prediction model, we examine the context-aware recommendation as a searching problem to find interesting items for a user given a context graph. Formally, suppose
A matrix representation of contextual user-item interaction.

Considering a random search that starts from node i in G, the search iteratively transmits to its neighborhood j with the probability that is proportional to the edge weights 
A contextualized data graph adheres to the schema of G. In the data graph, given the source node i, the target node j and the relationship type L of an edge, the transitivity matrix is initialized as follows:

With respect to the types of edges L and the weights
In the scenario of recommendation, to estimate the likelihood of an unseen item 
(1) Add all elements in U, I, A and C as graph nodes to G and assign an unique index for each node; (2) Add edges to G and assign an type label L for each edge; (3) (4) (5) (6) Get the edge type L and the weight (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) Compute (24) (25) (26) (27) (28) (29) (30) (31) Compute (32)
2.2. Context-Aware Postfiltering
With respect to the CGR, all contextual information and attributes of users or items can be taken into account in estimating user-item relevance. However, there remain some significant issues not considered. On one hand, the rating information which explicitly represents users’ preferences to items is not exploited. On the other hand, it is very difficult for the CGR model to deal with the query in which context factors are explicitly specified. To cope with these problems in CARS, we further submit a postfitering strategy. Given an instance of the context factors 

3. Experiments
3.1. Datasets
We use two datasets from different domains to evaluate the presented methods. The first one is the LDOS-CoMoDa, which is specially designed for context-aware personalization research [14, 15]. The dataset comprises 2296 rating records from 121 users to 1232 items, accompanying contextual factors. Content items are movies, while the item consumption device is a personal computer with a web-based application to acquire the user's context [14]. Each record contains 30 variables including a user, an item, a rating, 12 context factors, 4 attributes of users, and 11 attributes of items. Context factors associated with ratings include time, daytype, season, location, weather, social, endEmo, dominantEmo, mood, physical, decision, and interaction. Also each context factor may have multiple discrete values, amounting to 49 context conditions. For example, there are three values (Working day, Weekend, and Holiday) as for the daytype conditions and seven values (Alone, My partner, Friends, Colleagues, Parents, Public, and My family) with respect to the social condition. Other variables are general user attributes (age, sex, city, and country) and movie attributes (director, movieCountry, movieLanuage, movieYear, genre1, genre2, genre3, actor1, actor2, actor3, and budget).
The second dataset is scripted from http://www.tripadvisor.com/ which is a tourism website that advises trips, locations, and activities for users and contains a social component, which allows lots of elements to be reviewed [16]. The dataset is about hotel reviews and consists of 4669 ratings from 1202 users to 1890 hotels [9]. The attributes of users are state and timezone and the attributes of hotels are city, state, and timezone. And there is only one context, trip type, assigned to each rating showing the types of trips that the user suggests for this hotel. For this context, the user can select a subset of five possible values: Family, Couples, Business, Solo travel, and Friends. The statistics of both datasets are presented in Table 2, where we can see that the TripAdvisor dataset is considerably sparser than the LDOS-CoMoDa dataset.
The statistics of datasets.

3.2. Performance Metrics
Along with the progress of recommendation techniques, various metrics have been applied to measure the accuracy of recommendations, including statistical accuracy metrics and decision-support measures. Since we focus on recommending top-N items instead of rating prediction of items, Precision@N, Recall@N, and nDCG@N are selected to evaluate the recommendation accuracy.
Given a rank list of recommended items, Precision@N is the fraction of recommended items that are relevant in the top-N position as follows:



3.3. Evaluated Methods
UPCC and IPCC: the methods are the classical user-based collaborative filtering and the item-based collaborative filtering [1] and adopt the Pearson correlation coefficient (PCC) to define the similarity between two users or two items.
SVD++ [17] and CAMF [18]: SVD++ is a well-known latent factor model that comprises an alternative approach to collaborative filtering with the more holistic goal to uncover latent features that explain observed ratings. CAMF is an extension of classical matrix factorization (MF) approach for taking into account contextual information in the rating prediction. Similar to SVD++, it is also induced by SVD on the user-item ratings matrix. Learning the prediction models for both of them is solved using stochastic gradient descent. We fix dimension of latent factors as 20; other parameters are optimized to realize the best predicting performance.
CGR. Candidate items are recommended to the user according to their CGR-based relevances. All available information in contextual graph G is considered; however, for simplicity, we let
3.4. Experimental Results on Contextual Modeling
In this section, we conduct experiments to observe the recommendation performance of graph-based contextual modeling approach. Under this case, each query has no prescribed context conditions to prefilter or postfilter the recommended candidates. The LDOS-CoMoDa dataset is randomly divided into the training dataset and the test dataset by a ratio of 80% : 20% and the TripAdvisor dataset is divided into two corresponding parts by the ratio of 70% : 30%. Since we do not focus on the cold-start problem of recommendation, new users and new items in the test dataset are not considered during the recommendation process. Statistics of training dataset and refined test dataset are presented in Table 3.
The statistics of training and test datasets.

Firstly, we observe the recommendation accuracy of the CGR using five separate schemes of context graph. By this, we can identify which of the components work best for the task of top-N item recommendation. The results are presented in Figures 1 and 2. ALL simultaneously considers contextual information, attributes of users and items and use data of users to items. ALL-UC-IC corresponds the case where contextual information are not considered; namely,

Recommendation accuracy of CGR using different graphic schema on the LDOS-CoMoDa dataset.

Recommendation accuracy of CGR using different graphic schema on the TripAdvisor dataset.
Next, we compare the CGR with other baseline methods. We are focused on top-10 and top-20 recommendations, as users are more concerned about the candidates being at the front of the recommendation list. Experimental results on both datsets are presented in Figure 3. For the LDOS-CoMoDa dataset, the CGR model significantly outperforms UPCC, IPCC, SVD++, and CAMF in all accurate metrics, and it improves them by at least 80% in all performance metrics. Similar trends are observed in the TripAdvisor dataset, where the CGR model obviously beats all the others. In particular, it outperforms them by at least 200% in all performance indicators. Since the TripAdvisor dataset is much sparser than the LDOS-CoMoDa dataset, we think that CGR-model is stronger than traditional CF-like recommenders and more suitable to cope with the problem of data sparsity. On one hand, CGR-based models perform in a more superior way when data is sparse. On the other hand, it offers an easier way to integrate various contextual factors to improve recommendation performance, which is still thought as a challenging task in other ways.

Recommendation performance comparison between the CGR and the baseline methods.
3.5. Experimental Results on Context-Aware Postfiltering
In this section, we did the experiment with the postfiltering model for CARS. For this, we reuse the training and the test datasets provided in Table 3. Each query in this experiment is linked to a context condition, and the context factors associated with a pertinent item must match the context condition given in the query. Context factors considered for the LDOS-CoMoDa dataset are daytype and social, which are two important factors affecting a user's choice for watching a movie. The context factor took into account for the TripAdvisor dataset is only TripType. By splitting items using selected context factors, we further obtain 225 queries in the LDOS-CoMoDa test dataset and 1102 queries in the TripAdvisor test dataset. The average numbers of relevant items per query are correspondingly 1.01 and 1.22. Obviously, every context-aware query only has about one relevant item. We study recommendation effectiveness of evaluated methods with or without postfiltering strategies. The results are presented in Table 4, where the best values for every indicator are underlined. Since the number of relevant items per query is extremely small, we consider the recall to evaluate recovery ability of recommenders.
Recall performance of different recommenders in combination with or without postfiltering strategy.
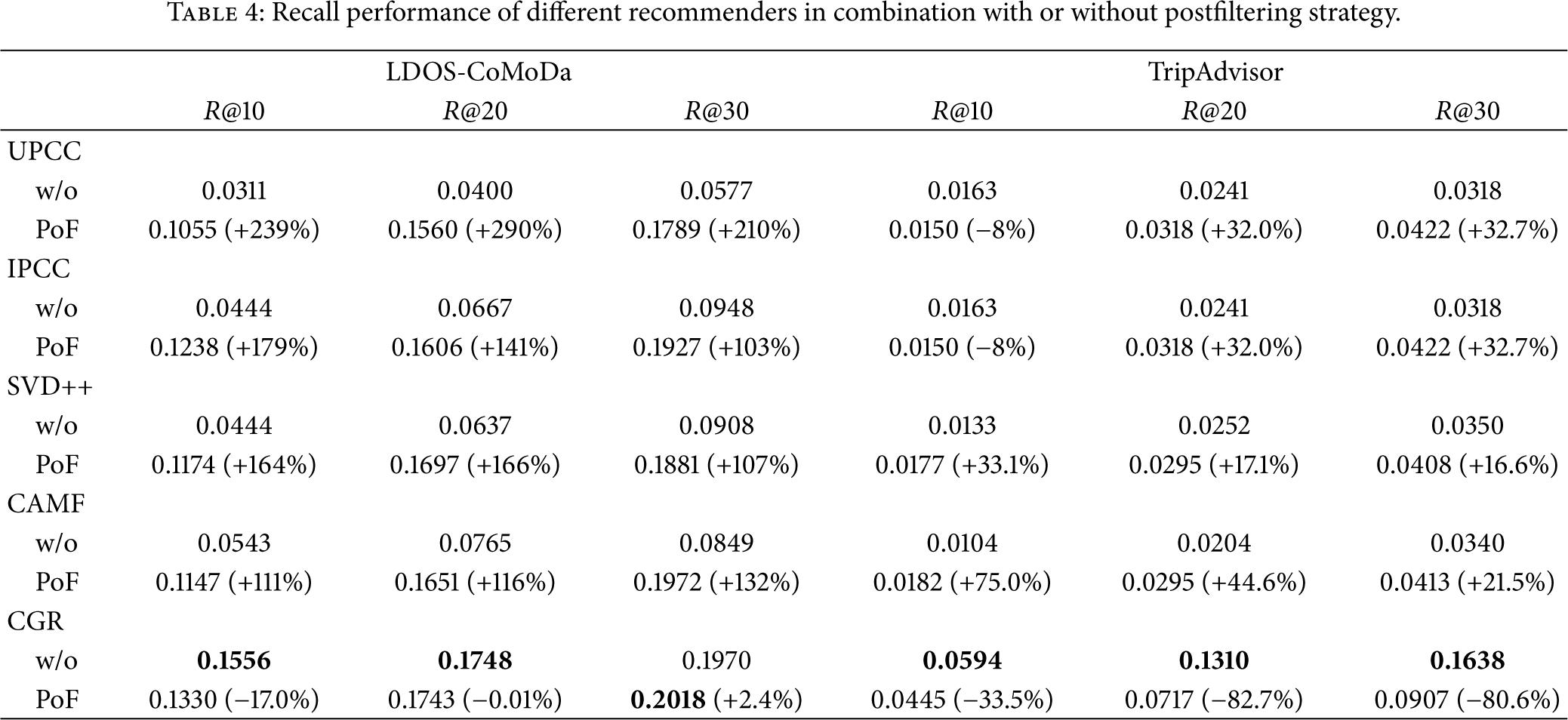
As for the case, without using postfiltering (w/o), we can see that the CGR model largely improve all the other models on both datasets. This outcome is very consistent with prior experimental results (see Figures 1 and 2). UPCC, IPCC, and SVD++ achieve comparable performances on both datasets under this case. It is worth emphasizing that CAMF is much better than UPCC, IPCC, and SVD++ in terms of R@10 and R@20 on the LDOS-CoMoDa dataset, showing its merits in context-aware recommendations. As for using postfiltering (PoF), significant improvements are observed in four CF-based methods against both datasets. The gains reach to at least 103% across all indicators on the LDOS-CoMoDa dataset and at least 16% in terms of R@20 and R@30 against the TripAdvisor dataset. However, the case for CGR model is very unique; combining post-filtering in it degrades the recall of recommendations particularly in the TripAdvisor dataset. Therefore, it is not suitable for the CGR to exploit the PoF strategy directly.
3.6. Experimental Results on Hybrid Model
Since directly combining the PoF strategy with the CGR model reduces the quality of recommendations, we suggest a linear combination of a CGR-based and a CF-based relevance measure between u and i, aiming at having both worlds. It is shown as follows:


Recall of the hybrid model against LDOS-CoMoDa dataset.
4. Related Works
Context-aware recommender systems represent an increasingly active and highly problem-rich research area, especially for pervasive computing environments, where individual users consuming various products or services are always associated with rich contexts. A lot of existing research on CARS addressed different aspects of the problem, such as general-purpose algorithms, evaluation protocols, and domain-specific engineering. Instead of providing a detailed survey of CARS, we only think of the algorithmic principles most pertinent to our approaches. As for a recent survey on CARS and the discussion of probable directions, users can refer to the work [2]. For the comparisons of different CARS, users can refer to works [4–6].
From the algorithmic perspective, there are currently three recognized paradigms for incorporating contextual information into the recommendation process: (i) contextual prefiltering: context is used for selecting the relevant set of rating data before computing predictions. For contextual prefiltering, many recommendation models, such as collaborative filtering and matrix factorization, can be directly utilized before or after computing predictions [2]. Prefiltering is particularly appealing due to its straight-forward and flexibility of justification. Some strategies have been proposed, such as splitting ways [7], context relaxation [9], and semantic filtering [8], to acquire more pertinent data for predicting user preferences in the same contextual situation of the target user. (ii) Contextual postfiltering: context is used to adjust predictions generated by a context-free 2D prediction model. Distinct from prefiltering, the reranking strategies are required for the recommendation list already obtained. (iii) Contextual modeling: contextual information is directly incorporated in the prediction model, usually by generalizing the 2D prediction model to an n-dimensional one. As for contextual modeling, more complex algorithms are typically explored. Tensor decomposition [19] aims to factorize the tensor over user, items, and all categorical context variables directly to improve prediction accuracy. Nonetheless, with the increased contextual factors, efficiency becomes the bottleneck of the method [20]. In contrast, Baltrunas et al. present a novel MF-based context-aware recommendation algorithm [18], which models the interaction of contextual factors with item ratings introducing additional model parameters. The proposed solution provides comparable results to the tensor decomposition based approaches, with the merits of smaller computational cost. However, incorporating contextual factors into existing CF-based or MF-based algorithms is always a challenging task, due to the inherent limits of scalability and flexibility of these algorithms.
Another kind of approach similar to us is graph-based, which incorporates contextual information into recommender systems in a flexible and scalable way. Graph-based methods can mitigate data sparsity problem utilizing rich contextual information [10, 11, 21, 22]. However, presented graph models are not grounding on a unified modeling framework. Also these domain-specific models have not been tested across different scenarios of applications. Reporting to them, our works design a general-purpose framework to facilitate the development and use of context-aware recommendation capabilities. We put forward a unified graph-based contextual modeling framework to incorporate contexts in the prediction model and specially design the CGR measure to estimate the relevance between the target user and the items. Also, we put forward a probabilistic postfiltering strategy to improve the effectiveness of context-aware recommendation. In addition, we proved that the newly proposed methods can work with additional methods to continue to improve the recommendation performance.
5. Conclusions and Future Works
We have proposed a graph-based framework for incorporating contextual information in the recommendation process. Also, we present a probabilistic reranking strategy to filter recommendation consequences given the contextual conditions. Experimental results have illustrated that all the proposed approaches are helpful to facilitate the development and use of context-aware recommendation capabilities. In addition, our proposed model can be viewed as a component and entered into a hybrid model to enhance effectiveness of CARS.
Some issues have yet to be investigated in the future. At first, we want to examine proposed methods on additional context-aware datasets and compare them with more powerful counterparts. We currently utilize the contextual graph in a simplified manner as we do not recognise on the importance of different contextual factors and relationships. In the subsequent phase, we propose using machine-learning algorithms to determine the importance of semantic relations (including contextual factors) in the recommendation and then automatically assign weights to these relations in the contextual graph. In addition, since not all information produces positive effects in context-modeling, feature selection will be used to get rid of weak features.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work is supported by the Special Funds for “Middle-aged and Young Core Instructor Training Program” of Yunnan University, the Applied Basic Research Project of Yunnan Province (2013FB009, 2014FA023), the Program for Innovative Research Team in Yunnan University (XT412011), and the National Natural Science Foundation of China (61472345). The authors are grateful to the anonymous reviewers for their constructive comments and suggestions which contribute substantially to the improvement of this paper.