
Abstract
Existing work that schedules concurrent transmissions without collisions suffers from low channel utilization. We propose the Optimal Node Activation Multiple Access (ONAMA) protocol to achieve maximal channel spatial reuse through a distributed maximal independent set (DMIS) algorithm. To overcome DMIS's excessive delay in finding a maximal independent set, we devise a novel technique called pipelined precomputation that decouples DMIS from data transmission. We implement ONAMA on resource-constrained TelosB motes using TinyOS. Extensive measurements on two testbeds independently attest to ONAMA's superb performance compared to existing work: improving concurrency, throughput, and delay by a factor of 3.7, 3.0, and 5.3, respectively, while still maintaining reliability.
1. Introduction
Due to the broadcast nature of wireless communication, access to the shared wireless channel has to be coordinated to avoid interference. There are generally two ways to achieve this, contention-based [1–4] and TDMA-based [5–8]. Contention-based protocols are easy to realize, but their performance can be highly dynamic and unpredictable owing to collision and random backoff, especially when node density is high and traffic load is heavy. This explains the prevalence of TDMA-based protocols in scenarios where quality of service (e.g., high throughput, high reliability, and low delay) has to be provided. For instance, the WirelessHART [9] and ISA SP100.11a [10] standards defined for industrial monitoring and control are both TDMA-based.
Conflict graph has been used to model wireless interference between neighboring nodes [11]. In a conflict graph, a node represents a contention entity. It can be either a node or a transmission link in the original network. A link between two nodes exists if data transmissions of the two represented contention entities interfere with each other according to an interference model (e.g., the Physical-Ratio-K model [12]). Once we acquire scheduling for a conflict graph, it is straightforward to translate it to the corresponding wireless network. From now on, graph is synonymous with conflict graph.
To avoid collision, a series of protocols have been proposed to schedule concurrent transmissions without conflict in multihop wireless networks. In the Node Activation Multiple Access (NAMA) protocol [5], a node only accesses the channel if its priority is higher than all of its conflicting neighbors’, where the priority is a hash function of its unique ID and the current time slot. While NAMA ensures that no two nodes transmit simultaneously if they interfere with each other, it can lead to severe concurrency loss and channel underutilization. Figure 1 illustrates such an example. In the conflict graph below, the number inside each node represents its priority. There is a link between two nodes if their transmissions collide. According to NAMA, only node with priority 7 can be active although nodes with priorities 1, 2, 3, and 4 can transmit as well without causing collision.

NAMA's concurrency loss.
Given the growing spectrum deficit that resulted from ever-increasing demands and fixed amount of spectrum, we aim to squeeze the most capacity out of the limited spectrum. And we propose the Optimal Node Activation Multiple Access (ONAMA) scheduling protocol that activates as many nodes as possible while ensuring collision-free scheduling. It formulates the scheduling problem into finding a maximal independent set in the conflict graph. In graph theory, an independent set is a set of nodes in a graph, none of which are adjacent. An independent set is maximal if adding any other node makes it no longer an independent set. ONAMA includes the distributed maximal independent set (DMIS) algorithm, which identifies a maximal independent set (MIS) of a graph given all node priorities, calculated the same way as NAMA does.
NAMA can compute the schedule for each slot on the fly because it requires no packet exchange. By contrast, it takes multiple rounds of packet exchange for DMIS to find the schedule (i.e., MIS) for a slot. What is worse, the wireless channel is susceptible to packet loss. If ONAMA also computes the schedule on the fly, it introduces significant delays for data delivery, especially in large networks. To reduce delay incurred by MIS computation while activating as many nodes as possible, we decouple the computation of MIS from data transmission by precomputing it in advance. When a certain slot comes, ONAMA simply looks up the precomputed MIS on the fly and activates a node if and only if it is in the MIS. To further reduce delay, we organize the precomputation of MISs for consecutive slots in a pipeline.
Contributions of This Paper. (1) We develop a distributed scheduling protocol ONAMA that attains maximal activation in a multihop wireless network while causing no collision, even if the network is dynamic. It greatly enhances channel spatial reuse compared to the state of the art. (2) We devise a novel technique called pipelined precomputation to address the excessive delay in basic ONAMA. (3) We implement ONAMA on extremely resource-constrained TelosB [13] motes using TinyOS [14]. Evaluation in two independent testbeds has verified that it increases concurrency by a factor of 3.7, increases throughput by a factor of 3.0, and reduces delay by a factor of 5.3 compared to the existing work while maintaining reliability.
Organization of This Paper. Section 2 details the ONAMA protocol. We evaluate it comprehensively in Section 3. Section 4 discusses related work. We wrap up the paper by drawing some conclusions and pointing out some future directions.
2. The ONAMA Protocol
We elaborate on the design and implementation of the ONAMA protocol in this section. First we introduce the baseline version of ONAMA, namely, the distributed MIS (DMIS) algorithm, to compute the MIS of a graph in a fully decentralized way. Next, we reduce DMIS's excessive delay by a novel approach called pipelined precomputation. Finally we tackle some challenges in implementing ONAMA on resource-scarce embedded devices.
We assume time on all nodes is synchronized and divided into slots. This can be attained by, for example, running a time synchronization protocol [15]. We also assume each node has a unique ID.
2.1. Distributed MIS
Inspired by the observation that NAMA can severely underutilize the channel, we decide to activate as many nodes as possible while still ensuring that no two neighboring nodes are active together. In other words, we activate a maximal independent set of a graph in each slot through the following distributed MIS algorithm. Even though it resembles some other existing distributed MIS algorithms in appearance, especially the FastMISv2 algorithm [16], it is essentially different from them to factor in the peculiarities of wireless sensor networks, that is, limited bandwidth, memory, and computational power.
In DMIS, a node stays in one of three states below at any given time:
UNDECIDED: it has not decided whether to join the MIS or not. ACTIVE: it joins the MIS. INACTIVE: it does not join the MIS. Node v exchanges nodal states with its neighbors. If node v's priority is higher than all its ACTIVE and UNDECIDED neighbors’, it enters the MIS by marking itself ACTIVE; conversely, if any of its higher priority neighbors is ACTIVE, it marks itself INACTIVE. Node v proceeds to the next phase only if its state is UNDECIDED.
Initially, all nodes are UNDECIDED. In any slot t, each node computes the priority of itself and its neighbors according to
When no node is UNDECIDED, the algorithm terminates.
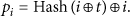
Theorem 1 shows that DMIS does terminate in finite phases.
Theorem 1.
DMIS terminates in finite phases.
Proof.
Given a graph G and distinct priorities for all its nodes, in the first phase, there are a set of nodes
Analogous to complexity analysis in [16], it is easy to prove that DMIS terminates in
Theorem 2.
The set
Proof.
We prove the theorem in two steps.
We prove this by contradiction. Suppose The independent set When DMIS terminates, a node is either ACTIVE or INACTIVE.
The resulting MIS is the set containing all ACTIVE nodes, which are to be activated in slot t. It is noteworthy that exchanged nodal state does not include priority, which is computed locally even for neighbors’.
2.2. Pipelined Precomputation
One salient feature of NAMA is that it requires no packet exchange to compute a schedule and can thus be called on the fly. In a TDMA setting, a node can call NAMA a subroutine at the beginning of a slot to instantaneously determine if it should be active in that slot. The idea of doing the same for DMIS is enticing, but the ability to do so proves to be elusive. This is because, unlike NAMA, running DMIS requires multiple phases and each phase incurs significant delay mainly due to contention to access the shared channel and unreliable channel in step 1. The resulting excessive delay for data delivery is detrimental for a wide range of time-sensitive applications.
To reduce DMIS's delay while retaining its high concurrency, we decouple it from data transmission by precomputing MIS of current slot M slots ahead of time. M is chosen such that DMIS converges within M slots, at least with high probability. Ideally, M is set as the product of the number of phases it takes for DMIS to complete and the number of slots needed for every node to exchange its nodal status with all its neighbors in each phase. To determine the former, we log the conflict graphs during runtime and execute DMIS over them offline to see how many phases are needed for its completion. The latter depends on the control signaling scheme and qualities of links between a node and its neighbors. In reality, M is also bounded by available memory as we will elaborate in Section 2.4.
In slot t, DMIS starts computing MIS for future slot
Figure 2 shows an example of the proposed precomputed pipeline in action when M is 4. The x-axis denotes time in slot and the y-axis denotes the slot whose MIS is being computed. The computation of MIS for slot 4 starts at slot 0 and continues in slots 1, 2, and 3. In slot 4, MIS for this slot has been precomputed and is ready for immediate activation. Similarly, MIS for slot 5 is ready at slot 5, MIS for slot 6 is ready at slot 6, and so on. In slot 3, MISs for the upcoming slots 4, 5, 6, and 7 are being computed simultaneously.
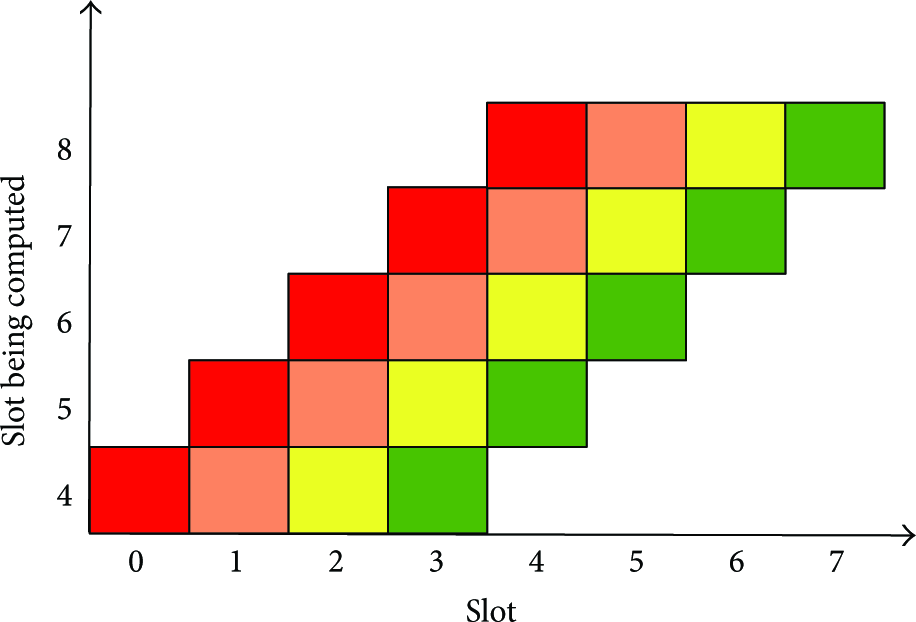
Pipelined precomputation.
2.3. Dynamic Graph
A graph changes over time as nodes join or leave the network and links establish or break. This change confuses DMIS because it assumes the graph remains static before it converges. We solve this issue by a snapshot-based approach. Specifically, when starting to compute the MIS for a future slot
Putting all building blocks together, we present the ONAMA protocol in Algorithm 1.
/*
call
/* exhange nodal states with my neighbors; compute priorities for myself and my neighbors using (1); and UNDECIDED neighbors set my state as ACTIVE; neighbors is ACTIVE set my state as INACTIVE;
2.4. Implementation Issues
A typical embedded device is equipped with extremely limited memory. For instance, a TelosB [13] mote has only 10 KB of RAM. Implementing ONAMA on such resource-constrained devices poses an additional challenge that is not found on resource-rich ones. To overcome this challenge, we expose several key parameters for fine tuning to let upper layer trade off between memory usage and performance. There are two places in ONAMA that can expend significant amount of memory, especially when the network is large.
First, each node maintains a table containing all its potential neighbors with size L. To store graph snapshot for each slot, a node needs 1 bit for each node in its neighbor table, indicating whether they interfere or not. It thus costs each node
Second, in step 1 of a phase in DMIS, a node exchanges states with neighbors by sending and receiving control packets, which can piggyback upper layer payload as well if space permits. We further divide each slot into S subslots, out of which one is reserved for data packets and the rest are reserved for control packets. Only one data or control packet can be transmitted by a node in each subslot. In total, each node stores
3. Evaluation
3.1. Methodology
We test ONAMA as a component of the PRK-based scheduling (PRKS) protocol. PRKS [15] is a TDMA-based distributed protocol to enable predictable link reliability based on the Physical-Ratio-K (PRK) interference model [12]. The PRK model marries the amenability to distributed protocol design of the Ratio-K model (i.e., interference range = K ∗ communication range) and the high fidelity of the signal-to-interference-plus-noise ratio (SINR) model. Through a control-theoretic approach, PRKS instantiates the PRK model parameters according to in situ network and environment conditions so that each link meets its reliability requirement after convergence. As stated in Section 2, PRKS essentially defines a conflict graph for a given wireless network: a node in the graph denotes a link with data transfer in the network, and a link exists between two nodes in the graph if the corresponding links in the network interfere with each other according to the PRK model and its instantiated parameters. It is noteworthy that even though the underlying network is (semi)static, the conflict graph is dynamic due to the constantly changing PRK model parameters. Under the condition that link reliability is ensured, PRKS schedules as many nodes as possible in the conflict graph, which is exactly what ONAMA intends to do. Besides ONAMA, PRKS contains many other components such as link estimator, controller, forwarder, time synchronization, and logging. The runtime interactions and resource sharing between ONAMA and other components of PRKS can cause undesirable effects that are not manifested when running ONAMA in isolation. By integrating ONAMA as a part of complex applications like PRKS, we can test the robustness of its design and implementation under dynamic conflict graphs.
To demonstrate the benefits of ONAMA, we compare the following two PRKS variants.
PRKS-NAMA: PRKS running on top of NAMA. PRKS-ONAMA: PRKS running on top of ONAMA.
At the beginning of a time slot, every node calls the NAMA or ONAMA component to decide whether any incident links shall be active in this slot. We measure their performances in two sensor network testbeds, NetEye [17] and Indriya [18]. Indriya is a wireless sensor network deployed across three floors of the School of Computing at the National University of Singapore, while NetEye is a wireless sensor network testbed on the third floor of the Department of Computer Science at Wayne State University. In both testbeds, we set M, G, and S to be 112, 16, and 10, respectively.
Network and Traffic Settings. In NetEye and Indriya, we choose each node with probability of 0.8 and 0.5, respectively, and the resulting set of nodes forming a random network. NetEye deploys 130 TelosB motes in a grid with every two closest neighboring motes separated by 2 feet. The random network is generated by using a subset of the 130 motes in experiment, in particular, using each node in NetEye with a probability of 0.8. Similarly, nodes in Indriya are chosen with a probability of 0.5. For each chosen node A, another node B (also in the random network) is chosen such that the packet delivery ratio (PDR) of the link from A to B is at least 95% in the absence of interference. For each link, the sender transmits a 128-byte packet to the receiver every 20 ms. Data transmission power is fixed at −25 dBm, that is, power level 3 in TinyOS.
3.2. Measurement Results
NetEye Testbed. For various PDR requirements, Figure 3 shows the mean concurrency (i.e., number of concurrent transmissions in a time slot) of PRKS-NAMA and PRKS-ONAMA, as well as a state-of-the-art centralized scheduling protocol iOrder [19], which also activates as many links as possible while ensuring that each link meets its PDR requirement. Not only does PRKS-ONAMA significantly increase concurrency over PRKS-NAMA by up to 270%, but also it achieves a concurrency equal or close to that of iOrder despite its distributed nature. This clearly demonstrates the effectiveness of DMIS in ONAMA to activate more links simultaneously. It is worthwhile to note that though ONAMA seems to outperform iOrder in some regions, they are the same statistically speaking.
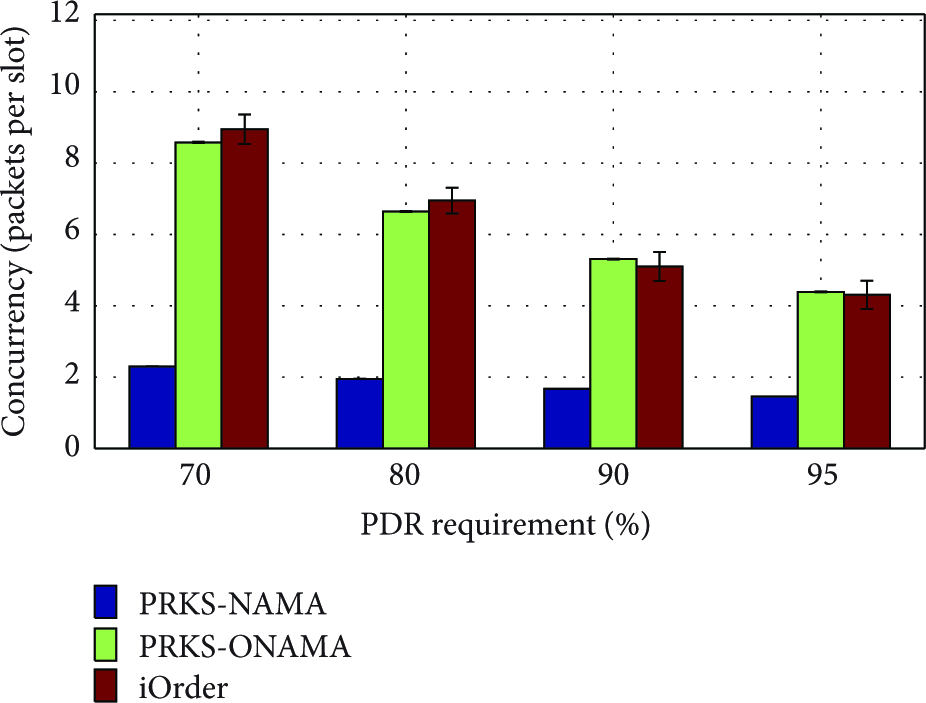
Mean concurrency in NetEye.
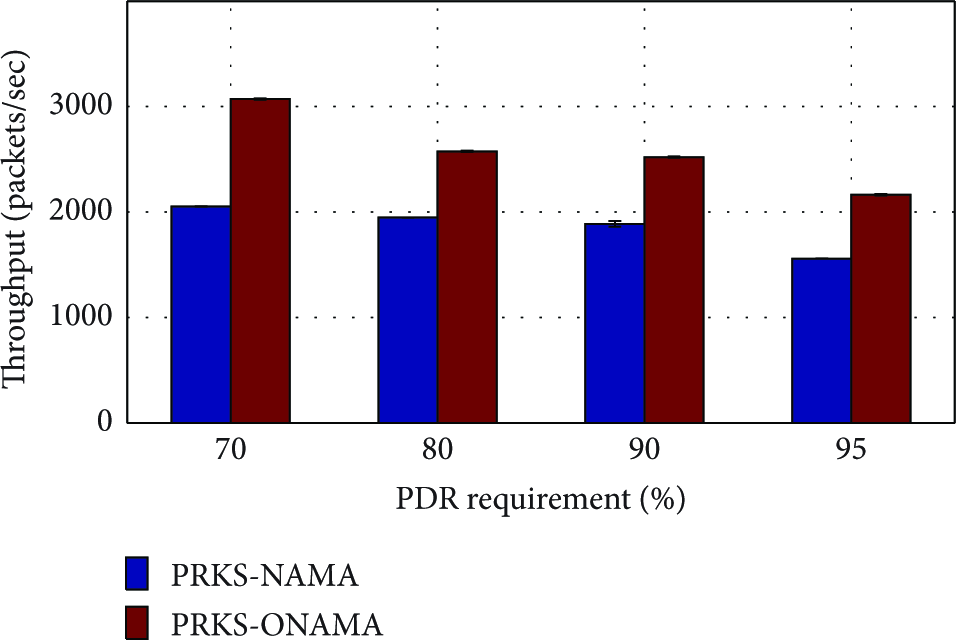
Figures 4 and 5 show the boxplots of PDR in PRKS-NAMA and PRKS-ONAMA for different PDR requirements, respectively. We see that even though PRKS-ONAMA improves concurrency and channel reuse enormously, it still guarantees that link PDRs meet requirements as PRKS-NAMA does. Because of higher concurrency without PDR sacrifice, PRKS-ONAMA's throughput is expected to be higher than PRKS-NAMA's as verified by Figure 6. Specifically, PRKS-ONAMA's throughput is 3.0, 2.9, 2.7, and 2.5 times PRKS-NAMA's when the PDR requirement is 70%, 80%, 90%, and 95%, respectively. We also note that as PDR requirement increases, throughputs in both protocols decrease due to lower concurrency. Figure 7 shows that PRKS-ONAMA reduces the mean delay of PRKS-NAMA by a factor of 5.3, 4.6, 4.0, and 3.8 when the PDR requirement is 70%, 80%, 90%, and 95%, respectively, where the delay is defined as the difference between the packet transmission time and reception time. This significant improvement is due to both DMIS and pipelined precomputation in ONAMA. Specifically, with a larger concurrency from DMIS, a node has more transmission opportunities. Given the same PDR requirement, ONAMA has more chances to transmit than NAMA and thus delivers data faster. In addition, ONAMAs pipelined precomputation does not require computing transmission slot on the fly as NAMA does; it simply determines to be active or not according to the precomputed states.

Packet delivery ratio (PDR) of PRKS-NAMA in NetEye.

Packet delivery ratio (PDR) of PRKS-ONAMA in NetEye.

Mean throughput in NetEye.
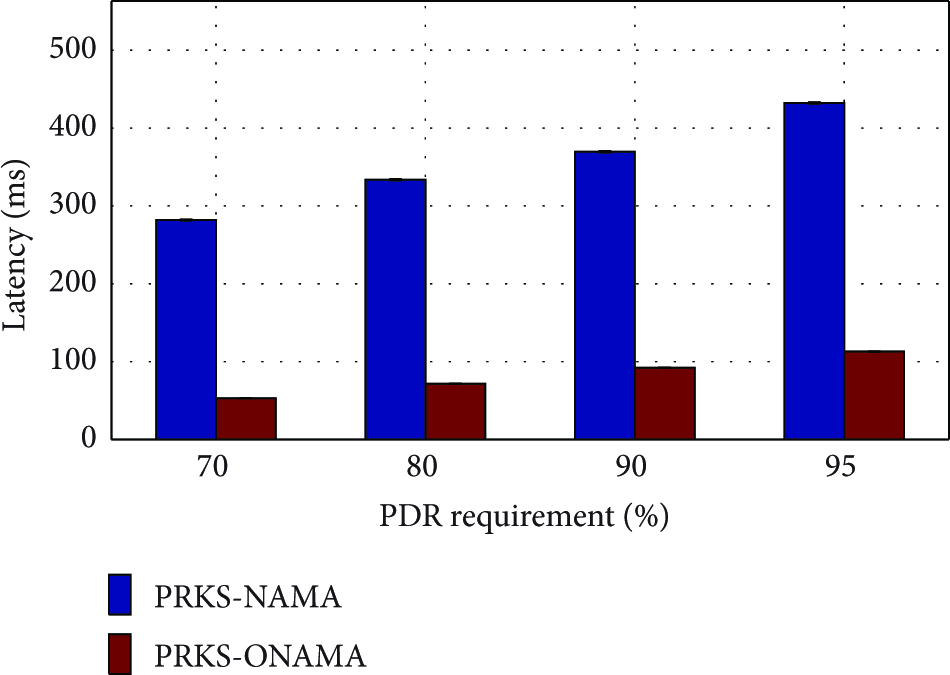
Mean delay in NetEye.
Indriya Testbed. Figures 8 and 9 show the link PDRs of PRKS-NAMA and PRKS-ONAMA under different PDR requirements in Indriya, both meeting their requirements as in NetEye.

Packet delivery ratio (PDR) of PRKS-NAMA in Indriya.

Packet delivery ratio (PDR) of PRKS-ONAMA in Indriya.
Figures 10, 11, and 12 show the mean concurrency, mean throughput, and mean delay of both protocols under different PDR requirements in Indriya, respectively. We see similar relative performance as in NetEye but the degree of improvement is smaller. For instance, PRKS-ONAMA's throughput is only 1.5, 1.3, 1.3, and 1.4 times PRKS-NAMA's when the PDR requirement is 70%, 80%, 90%, and 95%. This is because links in Indriya are sparser and a larger portion of them is already activated using NAMA. It is also worthwhile to note that though ONAMA seems to have larger concurrency than iOrder in some regions of Figure 10, they are the same statistically speaking.

Mean concurrency in Indriya.
Mean network throughput in Indriya.

Mean delay in Indriya.
4. Related Work
There are a plethora of protocols to schedule transmissions without collisions in ad hoc networks, such as NAMA and HAMA, to name a few. In Node Activation Multiple Access (NAMA) protocol [5], each node generates a unique priority by hashing and only accesses the channel if its priority is higher than those of its one-hop and two-hop neighbors. It achieves collision-free scheduling but suffers from low channel utilization as some nodes are not activated even when their activations cause no collision. Hybrid Activation Multiple Access (HAMA) protocol [20] builds upon and improves NAMA by activating noncontending entities, both nodes and links, whenever possible; thus, it utilizes channel more efficiently. Unfortunately, it requires radios capable of code division multiplexing. In contrast with HAMA, ONAMA fully utilizes channel without additional requirement on radios.
Orthogonally, plenty of work identifies MIS in a distributed fashion [4, 21], with the FastMISv2 algorithm in [16] being the closest to our work. Akin to DMIS in ONAMA, FastMISv2 also runs in multiple phases; in each phase, FastMISv2 includes a node in the MIS only if its priority is higher than those of all its neighbors, which are excluded from the MIS. There are quite a few critical distinctions, though. (1) Priority is calculated from a pseudorandom number generator (PRNG) with generally different seeds on different nodes, not from a common hash function. A node obtains its neighbor's priority by packet exchange, unlike in DMIS where a node computes its neighbor's priority directly, which expends precious channel resources. Additionally, a new priority is generated from PRNG in each phase, which consumes large amount of MCU time on embedded devices, while DMIS only generates priority once before the first phase. (2) Designed for generic distributed settings, FastMISv2 ignores control signalling and does not address the unique challenge posed by unreliable wireless channel. By contrast, ONAMA tackles the challenge explicitly in control signalling by incorporating wireless characteristics. (3) FastMISv2 does not handle the long delay incurred by MIS computation, making it unsuitable for delay-sensitive applications. (4) Lastly but importantly, FastMISv2 assumes a static graph and fails if the graph changes over time.
Finally, unlike all the aforementioned existing work that is evaluated in simulation at best, ONAMA is implemented on resource-limited devices and verified over two real-world testbeds.
5. Conclusion
In this paper, we propose the ONAMA protocol that schedules maximal number of concurrent transmissions without collisions in a multihop wireless network. ONAMA has two pillars: a distributed MIS algorithm tailored to wireless characteristics and the pipelined precomputation technique to reduce DMIS's long delay. Extensive experiments on two testbeds, each with 127+ nodes, have independently shown that it increases concurrency by a factor of 3.7, increases throughput by a factor of 3.0, and reduces delay by a factor of 5.3 compared to the state of the art, while still catering to links’ reliability requirements. Not limited to PRKS, ONAMA can be used as a primitive for other applications that require distributed MIS activation. Moreover, pipelined precomputation can be a general technique employed by other distributed applications, where some information is needed imminently but obtaining it requires a considerable amount of time. One of the future directions is to investigate power control mechanisms to further improve the performance of ONAMA.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This work is supported in part by NSF awards CNS-1136007, CNS-1054634, GENI-1890, and GENI-1633.