
Abstract
Wireless Sensor-Actor Network (WSAN) usually consists of numerous sensor nodes and fewer actors, and the connectivity of interactors is critical to the whole network. Due to the hash deployed environments and limited energy supply, actor nodes may fail and impact the performance of the whole network. Since the failure of a cut-vertex will disrupt connectivity and divide the topology into disjoint segments, most of the previous researches have already considered this scenario. However, the impact of an abruptly actor's failure to the network will be far more than that. This paper focuses on the problem of an actor's failure and gives a more comprehensive view of the faulty actor, that is, not only restricts to the cut-vertex. Length-Aware Topology Reconfiguration Algorithm (LTRA) is proposed on the basis of two vital definitions named as length impact index (LII) and vertex cut set (VCS). LTRA is a hybrid method which selects a best candidate for each actor (if it has) and then initiates in a distributed manner. Main idea of this approach is that candidate will move to replace the faulty one once the failure occurs. In addition, the candidate is selected from one-hop neighbors of each actor. Finally, performance of LTRA is validated by extensive simulation experiments.
1. Introduction
Nowadays, tremendous applications of Wireless Sensor-Actor Networks (WSANs) have been drawing the increasing attention of many researchers [1], such as urban search and rescue, battlefield surveillance, forest fire detection and containment, and underwater surveillance. A typical WSAN is a network with the hierarchical structure, which is composed of lots of sensor nodes and fewer actors. Sensor nodes can probe the ambient conditions and transmit the collected data to one or multiple actors for further processing and transmitting. Actors are movable nodes and primary in charge of collecting data from sensors.
Generally, actors are utilized to connect the sink node and sensing dots. Connectivity would be the bottommost requirement to ensure the availability of a network; thus the connectivity of interactors network is essential. That is, actors should keep connectivity with others all the time. Nevertheless, due to the hash deployed environments and limited energy supply (mostly powered by battery), actors are prone to failure. As we all know that, the failures of some critical actors will affect the performance of the whole network. For instance, if some cut-vertexes are out of service, connectivity could not be maintained any more. Most of the existing approaches only considered the failure of an cut-vertex, such as DARA [2], PDARA [3], PCR [4], VCR [5], DCR [6], and AFDR [7].
Indeed, once a cut-vertex fails, the interactors interaction may cease. However, the impact of an abruptly actor failure to the network will be far more than that. For example, given a circle graph with some actors on the arc and a single actor at the center, the central actor can connect to other actors directly. Although this central actor is not a cut-vertex, the absence of it will prolong the link length between others observably. On the other hand, there is another kind of actors whose failures may disturb the robustness of interactors interaction. More specifically, those actors are not cut-vertexes in themselves, but their failures generate new cut-vertexes in the network. These two special cases will be discussed in Section 4. In addition, since we focus on the interactors graph, we use the actor and node alternatively to simplify the description hereafter.
This paper investigates the tolerance of the actor failure in WSANs from a general perspective. Similar to some of the previous researches, here we focus on the problem that only single actor has failed, and we primary concern the following two categories of actors. Firstly, those actors whose failures prolong the link length among other actors, such as cut-vertexes. Secondly, those actors whose failures generate new cut-vertex which may effect the robustness and cause cascaded failures in WSANs. Here, we regard the recovery issue as an optimization problem when an actor is failed and prefer utilizing an adjacent actor to replace the faulty one. In this study, our contributions can be summarized as the following four aspects.
We give a more comprehensive view on the disabled actor and indicate that the failed node will not only be restricted to the cut-vertex. Then we do some analysis of the two categories of actors we will concern. Dealing with actors belong to the first category, we propose a novel parameter named as length impact index (LII) which can reflect the impact of the link length between other actors when an actor is out of service. Dealing with actors belong to the second category, we formally define the vertex cut set (VCS) and propose a method to judge whether the failed actor belongs to BVCS (Binary-VCS) or not. One faulty cannot be ignored if the failed one is in BVCS. In addition, when we choose the candidate of each actor, the chosen one also needs to be judged. We propose a novel algorithm named LTRA (Length-Aware Topology Reconfiguration Algorithm) to handle the problem of an actor failure; we also validate its correctness and reliability via abundant simulations.
The rest of this paper is organized as follows. Related work is reviewed in Section 2. In Section 3, we describe the considered system model and highlight the implications of actors failure on network topology. Then, two categories of actors are investigated, and the LTRA is also proposed in Section 4. Further, the algorithm is analyzed in Section 5. Validation experiments and performance analysis are provided in Section 6. Finally, we give a conclusion of this paper in Section 7.
2. Related Work
In this section, we will review the related work briefly. In recent years, the issue of connectivity restoration has been well studied in Wireless Sensor Networks (WSNs) and WSANs; many studies focus on restoring the broken WSANs network caused by single actor failure, which is summarized in [9, 10]. Generally, according to the functional principle, existing schemes on tolerating node failure can be classified into two primary categories: proactive and reactive solutions.
Proactive solutions rely on the availability of redundant resources that can make up for the lost node(s). A significant concept is the k-connectivity, which means that there are at least k disjoint paths between any pair of nodes, and hence it can tolerate the failure of
Different from the proactive solutions, reactive approaches initiate the recovery process once the failure is detected. One of the most popular reactive methods is exploiting node’ repositioning to repair a partitioned WSAN and it has been deemed as an effective strategy in most of recent literatures [2–7, 12]. The main idea of these approaches is to replace the failed node with one of its neighbors or move its neighbors inward to autonomously mend damaged topology in the vicinity. For instance, DARA [2] pursues a coordinated multiactor relocation in order to reestablish communication links among disjoint actors. That is, once an actor fails, DARA will choose the best backup node move to replace the faulty one. The candidate among neighbors of the failed node is selected based on its degree, distance between the failed node and the nodes ID, respectively. Similar to our LTRA, DARA also considers the scenario that only one actor has failed. Nevertheless, DARA only focuses on the failure of cut-vertex, which may still ignore some critical nodes like mentioned before. In addition, DARA requires that all the actors need to aware 2-hop neighbors’ information to identify whether an actor is a cut-vertex or not. Moreover, Akkaya et al. [3] propose a connected dominating set (CDS) based algorithm named as PDARA. The approach was executed gradually; the first step is to identify whether the failure of a node causes partitioning or not; once the partitioning happens, the connectivity restoration process needs to be initiated with its dominatee or one of the neighboring dominators. The overall goal is to localize the scope of the recovery and minimize the movement overhead imposed on the involved actors.
As discussed above, both DARA and PDARA utilize one of the neighboring nodes to replace the failed one. However, they do not evaluate the absence of the candidate, if the movement damages the connectivity, the restoration process will work in the iteration pattern until the whole network is connected. Thus, cascaded movement is applied to sustain network connectivity. In this paper, cascaded movement is utilized to deal with several special cases. Unlike the DARA and PDARA in which the candidate is required to move to the location of failed actor, another notable work on connectivity restoration named as RIM is proposed by Younis et al. [12]. They have avoided the position of failed node and proposed a local recovery process by relocating the neighbors of the faulty node. The main idea of RIM is that each adjacent node of the failed one moves “
3. S ystem Model and Problem Statement
We consider a WSAN which is composed by sensors, actors, and a single sink node. The moveable actors are operated as cluster heads or relay nodes to transmit information gathered by sensors, and hence actors are more critical to the whole network. This paper only investigates the impact of single actor failure and analyzes the influence through two categories of actors. It is assumed that the sensors are stationary; they could reach the actors directly or over multihop paths. Since the scope of sensors is pretty large, we also assume that there must be lots of paths to provide the connectivity between sensors and actors, and those paths will not be affected if some actors have to change their positions. We are also assuming that actors are powered by limited batteries, and all have same communication range R. Such an assumption is usually valid since actors will be homogeneous in most applications of WSANs. Moreover, upon deployment, actors are assumed to discover each other and form a connected interactors network using some of the existing strategies such as C2AP [13].
As we all know that, the loss of an actor may cause serious or nonserious break to the performance of a network according to its position. Different from most of previous researches, we primary concern two categories of actors failures as we have explained in the introduction. The failure of an actor in the first category will affect link length between others. For instance, in Figure 1(a), the failure of

(a) Illustration of first category of actors in simple interactor network. Nodes
On the other hand, once the second category of actors has failed, robustness of interactor network should be affected. Let us consider two specific nodes A and B in Figure 1(b). Although they are not cut-vertexes, simultaneous failure of these two nodes could even separate the topology into two isolated blocks. We could observe that if node A has failed, node B will become a new cut-vertex, vice versa. Since the new generated cut-vertex may be out of service quickly under the constraint of much heavier workload, the failure of such an actor will impact the robustness of whole interactor network seriously. Similarly, we temporarily name the set of those actors like A and B as category 2.
In this study, we assume that no simultaneous nodes failure will happen, and all the transmission is on the basis of an ideal signal propagation model. In addition, the presentation of LTRA focuses on the algorithmic part of the self-restoration without considering the link layer issues.
4. Length-Aware Topology Restoration Algorithm
LTRA is a self-healing algorithm to reduce the impact caused by the failure of an actor, no matter whether the connectivity is hold or not. Actually, the algorithm we proposed here initiates only when the failed actor belongs to those two categories as we described above. Thus, the most important thing is to distinguish which type of the lost one belongs to. Since we should reduce the influence of initial failure via topology reconfiguration, in this section, we formally give a definition of LII, which could reflect the significance of each actor to the network topology. In addition, we also propose a crucial definition named as vertex cut set (VCS) refers to actors in category 2.
4.1. Definition of LII
Before analyzing how LTRA works, it is important to point out the impact of node's failure to the topology. As shown in Figure 1(a), assuming node
The main idea of LII is to notarize the length of the shortest path between any pair of actors in the interactor network. For example, although the failure of node
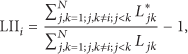
It is clearly that if node i is on the shortest path from node j to k, the failure of i will increase the link length between j and k. Actually, the LII of each actor is the variation of average link length of interactors network before and after the failure of that actor. In addition, the shortest path can be achieved through the route discovery strategies in the existing works, for example, the deep-first-search (DFS) algorithms.
Lemma 1.
If
Proof.
At first, we could exclude leaf nodes and cut-vertexes according to the assumption. Actually, if a node is on the shortest path between arbitrary pair of nodes and it is not a cut-vertex, there must be other routes to link these two nodes. As shown in Figure 2(a), node O is a intermediate node from P to Q. Then, let us take a view of Figure 2(b), in which

(a) Illustration of several paths between P and Q, any two paths will form a loop. (b) Illustration of four-membered ring. (c) Illustration of five-membered ring and link length between P and Q will be 3 if R is failed.
In large scale WSANs, actors are prone to form loops with at least 5 nodes, and hence the failures of actors in those loops are tended to appear and need to be taken into account.
4.2. Dealing with Faulty Actor in Category 1
We assume that once original topology has formed, the LII of each actor is determinate. Each actor needs to compare the LII with its one-hop neighbors and choose the one with smallest LII as its best-candidate (backup). However, if an actor has the smallest LII when comparing to its neighbors, we temporarily note that it has no candidate. In addition, if there are many candidates with the same minimum LII, we could choose the most suitable one among them through some extra parameters, such as the nodes degree and their distance to the faulty node. To simplify the analysis, we use the distance as the final judge criterion, if the actor gets the minimum distance to the failed node among those candidates whose LIIs are all minimum, it would be the best one to replace the faulty node. Precisely, a shorter distance to the failed node could save more energy in the movement of replace process and hence prolong the life time of the relocated actor.
Once a failure occurs, the candidate will move and replace the faulty one. Thus, every actor also needs to aware of the backup of itself while the whole network initiates.
4.3. Definition of VCS
Considering an undirected graph

In (2), V and E represent the vertex and edge set.
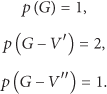
It is obvious that no matter which one of
4.4. Dealing with Faulty Actor in Category 2
In this section, we focus on the failure of actors in category 2; this kind of actors’ failure does not destroy the connectivity directly. More often than not, they will lead to cascaded failure, which means that some other actors may be out of service due to heavier workload and faster energy exhaustion. Failure of an actor in category 2 generates a new cut-vertex; that is, there is a one-to-one correspondence between such a failure and generation. And now the most pressing problem is how to identify those actors.
Lemma 2.
Actors in category 2 all belong to Binary-VCS (BVCS).
Proof.
According to the definition of VCS, Lemma 2 is clearly established.
There is a feasible solution to gain VCSs [14], in which authors tried to judge whether the submatrix of adjacent matrix is a quasidiagonal matrix with the elimination of some nodes. If it is true, the removed set of nodes is a VCS of the given graph. However, it will cause too much computation overhead to determine the attribute of each submatrix and may not suit our method. Therefore, in this section, we propose a strategy to find all the actors in category 2 based on the definition of VCS.
Lemma 3.
Given a certain actor-actor connected graph G, if node A failed and the number of cut-vertexes in graph

Lemma 4.
If node
Proof.
From Lemma 2, we know that all the actors in category 2 come in pairs. Combining this observation with Lemma 3, Lemma 4 would be naturally formed. Thus, once the interactors topology is confirmed, steps to find out all the actors in category 2 can be represented as Algorithm 1.
(1) Given an inter-actors graph G, and Then, obtain it's cut-vertex set which named as (2) Assuming leaf nodes in set L, thus all the actors belong to category 2 are in an alternative set (3) For every node (4) Calculate the new cut-vertex set (5) if (6) actor i belongs to category 2, and node (7) end if (8) end for
Actually, despite those cut-vertexes and leaf nodes, the scale of nodes in category 2 is limited. When the network launches, each actor should aware whether it belongs to category 2 or not. For simplicity, we name the set of actors in category 2 as BVCS.
4.5. Implement of LTRA
LTRA executes a partial topological restoration when an actor is out of service. Actors will periodically send heartbeat messages to their neighbors to ensure that they are functional and can report changes to the one-hop neighbors. Therefore, missing heartbeat messages can be used to detect the failure of actors. An actor is purported to failure if its neighbors lose the heartbeat message for two sampling periods. According to the analyses above, we find that the most critical step of LTRA is to select the candidate. Obviously, only actors in category 1 and BVCS are necessary to be concerned.
When the network initiates, sink node gathers the information of each actor and finds candidates for those actors who need to be concerned and then notifies the result through broadcasting. Once a failure is detected in the neighborhood, if the faulty actor has a backup node, the candidate will move to replace it. Synthesizing actors in category 1 and BVCS, the major steps of LTRA are expressed in Algorithm 2.
(1) Given an inter-actors graph, calculate the LII of each actor and judge whether actors belong to category 2 or not; (2) If node (3) The adjacent node minimum backup node of i; (4) if some candidates have the same LII (5) The actor which is hithermost will be selected; (6) end if (7) else (8) if neighbors’ (9) This failure would be ignored; (10) else (11) The adjacent node the minimum as the backup node of i; (12) end if (13) end if (14) Every actor need to communicate with its backup node and confirm the relationship with it; (15) When the failure appears, backup of the failed actor will move to replace it, and the performance of inter-actors network holds;
Primitively, backup node of each actor is elected (if it has) according to LTRA, the codes from line 1 to line 13 have represented this process. When the failure happens, the candidate only needs to replace the failed actor. For example, actor
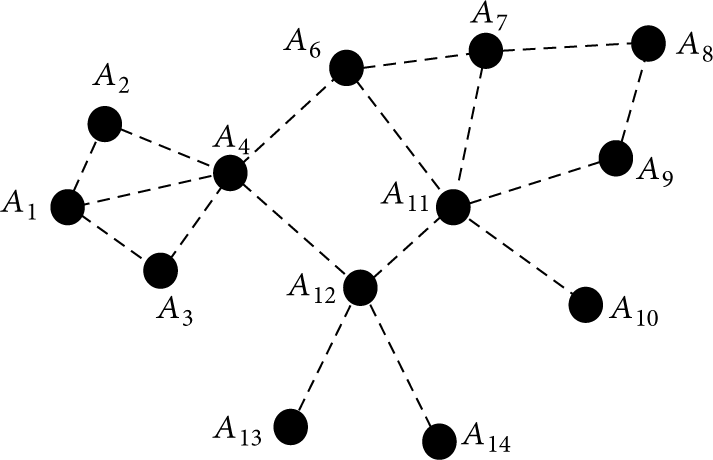
How the LTRA works after the failure of node
4.6. Rare Cases of Restoration
Although LTRA can deal with the most of situations, there are still few rare cases that need to be concerned. One of the most classical scenarios is that one-hop neighbors of the failed actor are all cut-vertexes; movement of anyone will disrupt the connectivity. Thus, cascaded movement is needed. The selection of candidate of faulty node is also according to the factor of distance. When the cut-vertex starts to move, the backup of it initiates as well. In addition, the scenario that neighbors of the failed actor are all in BVCS also needs cascaded movement. Next, four basic cases are represented in Figure 4.

Illustration of four rare cases.
According to the types of faulty actor and its neighbors, we name these four cases as C-C, C-B, B-B, and B-C, respectively. In (a), supposing node 3 has failed, then node 4 moves to replace 3, and node 5 moves to replace 4 in a cascaded manner. This case is named as C-C, because of the faulty node and its neighbors are cut-vertexes. Then, if node 7 in (b) is disabled, nodes move in a cascaded manner as indicated by the arrows. Since node 7 is a cut-vertex and its one-hop neighbors belong to BVCS, this case is named as C-B. Similarly, (c) denotes the case of B-B, in which the failed node 5 belongs to BVCS and its neighbors are also in it. (d) represents the case of B-C; if node 4 has failed, its neighbors node 3 and node 6 are cut-vertexes. Since
Actually, those typical cases are basically referred to as two issues: the first one is the failed node which must be replaced and the second is the backup of faulty node which is also critical. Although it is hard to deal with these cases, the probabilities of their occurrences are very small in actual network.
5. Algorithm Analysis
In this section, we will do some property analysis of our algorithm. Generally, the major step of LTRA is how to find a best candidate of each actor (if it has). This is a hybrid method consisting of two aspects: backup selection and replacement initiation. Now, we give a brief comparison of LTRA with some previous algorithms which refer to three parameters: type of faulty node, information maintained by node, and the working pattern. Result is shown in Table 1.
Comparison with previous algorithms.

In our algorithm, the candidate selection process needs to compare the LII of each actor with its one-hop neighbors, and everyone should also know the category of its adjacent neighbors. Thus, LTRA only requires that each actor maintains the information of one-hop neighbors. Further, we also discuss the message complexity of LTRA.
Theorem 5.
The message complexity of LTRA is
Proof.
The calculation of LII depends on information gained by sink node in which the communication overhead of whole network is
Remark 6.
Considering the number of actors is limited, the message complexity of LTRA would be acceptable in most cases. As we know that the message complexity of DARA and RIM is
Theorem 7.
The maximum travel distance of a node in LTRA is “R,” where R is the actor radio range.
Proof.
In LTRA, we adopt an adjacent neighbor to replace the faulty actor; even in the rare cascaded movement, every actor is replaced by its backup. And hence, the maximum travel distance of a node in LTRA is “R.”
6. Performance Evaluation
6.1. Simulation Settings
In this section, we wish to study how LTRA affects the overall performance of the interactors network numerically when the failure of an actor occurs. We evaluate the performance of LTRA by comparing them with two foregoing approaches named as the distributed actor recovery algorithm (DARA) [2] and the recovery through inward motion (RIM) [12]. Without loss of generality, we suppose that the LTRA starts from a random deployed graph. As explained above, DARA pursues to minimize the total distance traveled by the involved actors in order to limit the overhead incurred by the movement and chooses the candidates based on the node degree and the proximity to the failed actor. Meanwhile, RIM opts to reduce the distance of the individual nodes which have to travel by scheduling that all the adjacent neighbors need to move toward the faulty actor until
The simulations are performed on the Matlab 2010(b), and simulation parameters are summarized in Table 2. In addition, we set the actors which are randomly distributed and the original interactors network is also assumed to be connected. Since LTRA opts to minimize the number of actors involved into relocation process and limit the travel distance by electing the nearest neighbor, the following metrics are utilized to measure the performance of LTRA in terms of recovery (optimization) overhead.
The number of relocated nodes indicates the number of nodes involved in the relocation process. This metric could reflect the scope of topology changes during the execution of LTRA and assess the real-time performance of LTRA. Total travel distance of relocated nodes implies the total travel distance of those which need moving to replace the failed actor. Obviously, longer travel distance will lead to lager delay due to the limited moving velocity of actors. Furthermore, since the traveling will cause significant energy consumption, total travel distance could impact the residual energy of relocated actors which relates to the network lifetime closely. Thus, total travel distance of relocated nodes is a critical metric to measure the performance of LTRA.
Simulation parameters.

Moreover, with a view to the random failure model, we firstly investigate the possibility that the failed actor belongs to which category. Most of the previous literatures focus on the failure of cut-vertex; however, some other cases need to be considered are ignored, that is, other actors in category 1 and BVCS. Therefore, the probability distribution of failed actor is obtained among four varieties.
6.2. Numerical Results
Firstly, we do some simulations to see the probability distribution of the faulty actor under the random failure model. Simulation results are shown in Figure 5; the number of deployed nodes in two configurations is 50 and 80, respectively. There are four categories of the failure named as I, II, cut-vertex, and BVCS, in which I denotes the set of actors with zero LIIs and II represents those actors in category 1 except cut-vertexes. It is clear that the failures of cut-vertexes are only a small part of the whole scenarios, and more than 50% of the failures occur with the impact to the average length of interactors network. In addition, failures of actors in BVCS also exist; they need to be taken into consideration although the scope is limited. In Figure 5(b), we observe that the probability of failures in category II becomes larger along with the increase of scale of network. Since the more number of actors in a fixed area will lead the network to become more intense and hence more loops between actors are formed, the scale of actors in category 1 (without cut-vertexes) is naturally bigger.

(a) Probability distribution of an actor failure with 50 initial actors. (b) Probability distribution of an actor failure with 80 initial actors.
Then we compare the performance of the foregoing two metrics between LTRA, DARA, and RIM. Generally, all the evaluation results are averaged based on 20 different runs. Figure 6(a) compares the total distance moved by all the relocated actors of LTRA, RIM, and DARA. Figure 6(b) expresses the impact of network size (i.e., the number of deployed actors) on the numbers of relocated actors under these three algorithms. This simulation scenario is based on a fixed communication range
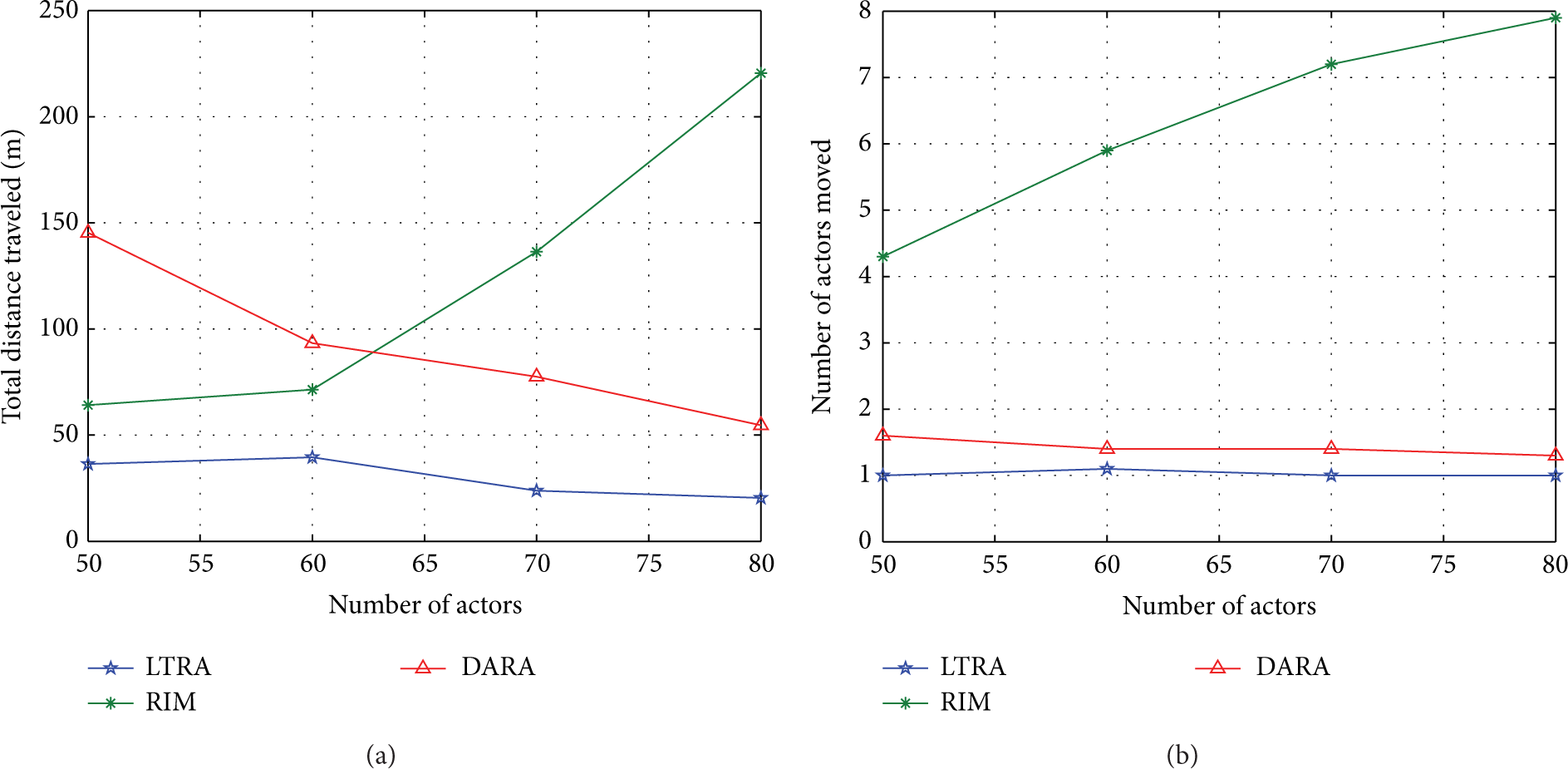
(a) Comparison of the total distance traveled by actors under LTRA, RIM, and DARA, where the network size is changing and the communication range is fixed as
Further, we valuate the impact of varying communication range on the total traveled distance and number of relocated actors. The number of randomly deployed actors is fixed as 50. Intuitively, smaller R indicates smaller distance between actors; all of the LTRA, DARA, and RIM perform well when R is set as 100 m. However, the overhead of them will keep increasing with R. In fact, as shown in Figure 7(a), the total traveled distance under LTRA is increasing with the communication range slowly. Moreover, since LTRA only needs moving one candidate to replace the failed actor in most cases, the total travel distance will be smaller than the communication range. Figure 7(b) shows the number of relocated actors altering with the communication ranges; similar to the graph shown in Figure 6(b), LTRA could accomplish the self-healing process with minimum involved actors.

(a) Comparison of the total distance traveled by actors under varying communication range with fixed network size. (b) Effect of varying communication range on the number of relocated actors with fixed network size.
Therefore, LTRA is able to reduce the impact of actor failure to the interactors network, and it outperforms the DARA; RIM refers to the following metrics: number of relocated nodes and total travel distance of relocated nodes.
7. Conclusion
The problem of topology reconfiguration from an actor failure in Wireless Sensor-Actor Network is studied in this paper. We have divided the failure of an actor into two major categories and presented two definitions named as LII and VCS. We have also proposed LTRA that engages to recover from a stochastic failure by topology reconfiguration in the partial region. Actually, LTRA could be regarded as an optimization approach because of the fact that the faulty actor will not restrict to cut-vertex. It should be noted that we only consider the failure of single actor and primary concern the interactors network in this study. Further, we will investigate the failure of multiple actors in our future work.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported by the Natural Science Foundation of Jiangsu Province (no. BK2012803), Doctoral Program of the Ministry of Education of China (no. 20113219110028), and the Advantage Discipline Construction Project for University of Jiangsu Province.