
Abstract
In delay tolerant networks (DTNs), multiple-copy routing is often adopted to improve the probability of successful message delivery but causes more traffic loads. The excessive increase in multiple messages copies often exhausts the network resources and deteriorates its performance significantly. To solve this problem, a mobility similarity-based routing (SBR) algorithm is proposed in this paper. On one hand, destination similarity is used to help the message carrier node find the appropriate relay nodes with the higher opportunity to meet the destination node in order to improve the delivery ratio. On the other hand, carrier similarity is adopted to avoid sending the same copy to the nodes with mobility similarity so as to reduce the number of message copies. Furthermore, inspired by the law of diminishing marginal utility in economics, a buffer management scheme based on the message transmission status is proposed. Experimental results show that the proposed SBR routing algorithm combined with the buffer management scheme can improve the delivery ratio and has the lower overhead ratio compared to other routing algorithms.
1. Introduction
Delay tolerant networks (DTNs) [1] are mobile wireless networks that experience frequent partitions. In DTNs, there may never exist a fully connected path from a source to a destination. The basic assumption on stable end-to-end path of routing protocols is invalid. Many real-world network scenarios fall into this paradigm, such as vehicular ad hoc networks [2], sensor networks for wildlife tracking and habitat monitoring [3], pocket switched networks [4], and mobile social networks [5].
In DTNs, communication is mainly dependent on the node mobility, which plays an important role in overcoming the lack of end-to-end path. The storage-carry-forward (SCF) routing paradigm is used to deliver messages in the challenging environments. Specifically, if a node receives a message from an encountered node, it stores and carries the message until another communication opportunity arises. Depending on the method whether the message carrier node keeps or removes the forwarded message, there are two classes of routing scheme in DTNs: single-copy routing [6] and multiple-copy routing [7].
As the primary purpose of DTN routing is to select some proper relaying nodes to guarantee that the message will be forwarded to the destination, the DTN routing protocols usually use the multiple-copy scheme to provide high delivery ratio. But the multiple-copy schemes cause tremendous network overheads. How to achieve high delivery ratio and maintain low overheads at the same time is the most important research issue for multiple-copy routing.
Moreover, the routing schemes are usually designed only from the viewpoint of single message and do not consider the problem of the usage of the whole network resources. Many proposed routing schemes for DTNs assume that nodes have infinite buffer space and ignore the contention for buffer space in network nodes. In practice, the nodes have limited buffer space in many wireless networks. Even if a node has large buffer space, it may share only a limited small part with external traffic when acting as a relaying node. Thus, how to manage buffer space significantly affects the performance of multiple-copy routing protocols, especially in the environments where intermittent connectivity and long latency require the data to be stored for a long period throughout the network.
In this paper, we firstly propose a similarity-based routing algorithm in DTNs. Two mobility similarity metrics are adopted, that is, destination similarity and carrier similarity, to choose the next relay node. The destination similarity refers to the mobility similarity between an intermediate node and the destination. The carrier similarity refers to the mobility similarity between the message carrier node and its encountered node. In addition to using the destination similarity to improve message delivery probability, the carrier similarity is also adopted to control the message delivery overheads. On one hand, since the node with high destination similarity has more opportunities to encounter the destination node, the message carrier node will choose these nodes as relaying nodes. On the other hand, the message carrier node will not replicate the message to the nodes with high carrier similarity because these nodes may have the mobility pattern similar to the message carrier node.
Secondly, inspired by the law of diminishing marginal utility in economics, we propose a buffer management scheme for the routing algorithm [8]. This law shows that as a user increases consumption of a product, there is a decline in the marginal utility that user derives from consuming each additional unit of that product. Thus, it is not good to generate excessive redundant copies for a single message because this will occupy very large buffer space of nodes and will restrict the opportunity of other messages to access the buffer space when buffer overflow happens. In contrast, in our proposed scheme, we estimate the status of a message, for example, the total number of its copies in the network and its dissemination speed, and perform buffer replacement and scheduling accordingly. Messages that have a larger estimated number of copies and faster dissemination speed are dropped prior to other messages in the event of buffer overflow or are forwarded after other messages. In this way, the proposed solution provides better fairness among messages and hence improves the overall performance.
The major contributions of this paper are listed as follows. A novel similarity-based routing (SBR) algorithm is proposed. To the best of our knowledge, no previous studies have exploited the carrier similarity in designing routing protocols in DTNs. A buffer management scheme, including message replacement and scheduling, is proposed for the routing algorithm. Extensive simulation experiments are conducted on map-based mobility model and random waypoint (RWP) mobility model. The results demonstrate that the proposed routing algorithm combined with the buffer management scheme can achieve the higher delivery ratio and has a relatively lower overhead ratio compared to other routing schemes.
The rest of this paper is organized as follows. Section 2 reviews the previous work on routing and buffer management in DTNs. Section 3 presents a similarity-based routing algorithm. Section 4 proposes a buffer management scheme based on the message transmission status. In Section 5, the routing algorithm with buffer management scheme is evaluated through simulation experiments. Finally, Section 6 concludes the paper.
2. Related Work
This section overviews state-of-the-art DTN routing protocols and buffer management issues.
2.1. Single-Copy Routing
Direct transmission is the basic approach in single-copy routing. The source node sends the message to the destination node directly. Predict and relay (PER) routing [9] used the probability distribution of future contact times to choose the next relay node. Recently, social characters have been explored to design routing protocols in DTNs. MobySpace routing [10] constructed a high-dimensional Euclidean space upon mobility patterns. The nodes that have the mobility pattern similar to the destination are appropriate to act as relay nodes. SimBet [11] routing exploited ego-centric centrality and its social similarity to choose the better carriers for the final destination. In [12], social selfishness was introduced into DTN routing and a social selfishness aware routing (SSAR) algorithm was proposed for the collaborative environment. Whatever the routing metric used, however, single-copy routing faces the reliability problem that the message is not sent to its destination when the single message copy is discarded by the relay node.
2.2. Multiple-Copy Routing
The multiple-copy routing protocols inject multiple copies of a message to provide reliable delivery. As one of the earliest DTN routing protocols, the epidemic routing [13] floods the message throughout the network and thus greatly increases the message delivery ratio. However, the node resources, such as buffer space, bandwidth, and energy, seriously restrain the epidemic routing performance. To address this problem, many approaches have been adopted to reduce the overheads and improve the overall network performance. Based on the method of controlling the overheads, the multiple-copy routing schemes can be further separated into three classes: coding-based [14–17], quota-based [18–20], and utility-based [21–24].
In the coding-based algorithms, a message is divided into a set of code blocks. Destination node can reconstruct the original message when it receives a sufficiently large number of code blocks. In [14], Wang et al. combined erasure coding and replication-based routing schemes to increase the network throughput. Tsapeli and Tsaoussidis [15] combined the probabilistic routing with erasure coding to enhance the robustness of the erasure-coding based forwarding in worst-case delays and small-delay scenarios. In [17], Altman et al. exploited linear block-codes and rateless random linear coding to solve the problem of optimal transmission and scheduling policies with two-hop routing under memory and energy constraints.
In the quota-based routing schemes, the fixed number of message copies is inserted into the network. Thus, the constant overhead is maintained. Spyropoulos et al. [18] proposed two different methods, that is, Source Spray and Wait (SS&W) and Binary Spray and Wait (BS&W), for allocating message copies. In [19], Nelson et al. used the encounter-based metric for optimization of message allocation. Elwhishi et al. [20] proposed a self-adaptive contention aware routing protocol SAURP, which makes forwarding decision based on the utility function value of the encountered node regarding the destination and the number of message copy tokens.
In the utility-based routing schemes, each node maintains a defined utility for destination. The utility can be a function of encounter history between nodes, node resources, and so forth. Lindgren et al. [21] used the past encounters to predict the probability of future encounters. Grasic et al. [22] made a little modification to the routing metric calculations in Prophet which can improve its performance. Ramanathan et al. [23] presented a variant of epidemic routing PREP, which prioritizes messages based on costs to destination, source, and expiry time to decide whether the message is deleted or reserved when it faced the situation of insufficient resources. In [24], Balasubramanian et al. treated DTN routing as a problem of resource allocation and proposed a heuristic approach to maximize the specified performance metrics, but it requires high computation cost.
2.3. Buffer Management
Generally, since the main reason of message loss is the buffer overflow [25–27], various congestion control schemes are proposed [28–30]. In DTN, how to design buffer management schemes becomes very important for the multiple-copy routing performance.
Some buffer management strategies can be performed independent of the underlying routing algorithm. In the Epidemic-IMMUNE routing protocol [31], three buffer management strategies including drop-tail, drop-head, and source-prioritized drop-head were examined. It was shown that appropriate buffer management schemes have great effects on delivery performance. In [32], Krifa et al. proposed a distributed algorithm based on the estimated global information to optimize the delivery ratio and the average latency.
Some other buffer management strategies have been proposed for specific routing algorithms. In [33], Lindgren and Phanse used the delivery predictability metric defined in Prophet routing protocol to decide which message is forwarded first. They evaluated various combinations of queuing policies and scheduling strategies for Prophet protocol. In [34], Erramilli and Crovella designed scheduling and replacement algorithms based on the message priority that is defined in delegation forwarding routing algorithm [35]. In [36], Rashid et al. proposed a buffer management policy, which takes message sizes into account.
Compared to the above solutions, our approach integrates both routing protocol and buffer management strategy. The appropriate relay nodes are chosen by considering the carrier similarity and destination similarity at the same time. Moreover, the messages are replaced and scheduled based on the number of copies and dissemination speed. In this way, our approach achieves higher delivery ratio and lower overheads.
3. Similarity-Based Routing Algorithm
In this section, the system model is presented. The basic definitions and notations that will be used throughout the rest of the paper are also introduced. Then mobility similarity metrics used for routing decision are defined. The design of similarity-based routing algorithm is presented in the end.
3.1. System Model
The network consists of N mobile nodes, each of which has a unique ID and belongs to one community. Each node in the network has the same buffer size and the same transmission range. The probability of moving to other communities from the local community is the same. The global knowledge about nodes’ mobility is unknown to every node in the beginning. Every message generated in the network has a Time-to-Live (TTL) value. The source node and relay nodes will drop message and their copies when their TTL expires. For a given message, there are one source node, one destination node, and
The contact time is defined as the time interval in which two nodes are within their communication range. The intercontact time is defined as the time interval in which a node pair is not within its communication range. The interdropping time is defined as the time interval in which a single message or its copies are dropped.
Because the transmission time is neglectable compared to the intercontact time, the transmission time is often ignored in other studies. Some studies indicated that many popular mobility models, like random waypoint, random walk, and community-based model, have such a property where the intercontact time of mobility model is exponentially distributed or has exponential tail [37, 38]. We also consider that the intercontact time follows exponential distributions. The interdropping time of messages is mutually independent and identically distributed random variables, with an exponential distribution.
3.2. Mobility Similarity Metrics
Nodes with similar characteristics of the mobility pattern are discovered in designing routing metrics in DTNs [10, 11]. Some previous studies have exploited mobility similarity as routing metric, but they only considered the destination similarity. It is argued that the nodes having the similar mobility pattern with the destination can enhance the delivery ratio and reduce the communication cost. However, from the viewpoint of message carrier node, if the encountered nodes have similar mobility pattern with the message carrier node, then they would not be good relaying nodes. Thus, we propose the carrier similarity to control the overhead of multiple message copies.
Carrier similarity is measured as the proportion of the same history encountered nodes between the message carrier node and the contact node. If a node has high similarity with the message carrier node, it will have similar mobility scope. The node will not be appropriate for diffusing message far away. The message carrier node will hold the messages by itself. In contrast, if a node has low similarity with the message carrier node, it will be capable of disseminating messages far away. Thus, the node is a good potential relaying node. Let

Destination similarity measures the number of the same nodes encountered by a node and the destination node. If a node has high similarity with the destination, it may have a higher chance to meet the destination. For a given node i, the destination similarity is defined below:

3.3. Similarity-Based Routing Algorithm
Here we propose the similarity-based routing algorithm, with the aim of bringing a concise concept of behavior similarity into DTN routing. Similarity-based routing combines carrier and destination similarity to make routing decisions. There are two intuitions behind this algorithm. Carrier similarity could control the number of flooding message copies and avoid missing the good relay node. Destination similarity could improve forwarding efficiency.
Each node maintains an encounter node vector (
Node contacts are represented as an
Each node also maintains a summary vector. An entry in summary vector is composed of four items, including message ID, replication number, message TTL value, and initial message TTL value. The summary vector is used to update the forwarding status of a message. It is exchanged when two nodes are encountered. When a node receives a new message, a new entry is added in the summary vector. When the node discards a message, the corresponding entry in the summary vector remains in the node until the TTL value of that message expires.
Because the sizes of the encounter node vector and the summary vector are very small compared to a message, the overheads of the encounter vector and the summary vector are not considered.
The routing algorithm is outlined in Algorithm 1. It represents the communication process when message carrier node i meets the potential relaying node j. They exchange some information of their encounter history used for computing routing metrics like Epidemic. Node i calculates the similarity with node j.
deliverMsgs(j)
exchangeEncountersVector(j, nv) updateSimilarity( ) exchangeSummaryVector( ) replicateMsgs(j, messages)
forwardMsgs(j, messages)
updateSummaryVector( )
If the carrier similarity utility between node i and node j is below the predefined carrier similarity threshold
4. Buffer Management Scheme
Although multiple-copy routing can improve the probability of delivery rate, it also inevitably brings more traffic into the network. When the node buffer overflows, the network performance decreases sharply. To overcome this problem, we propose a buffer management approach, which exploits messages transmission status in the networks to decide the priority of message replacement and scheduling.
4.1. Message Transmission Analysis
The dissemination of messages in the network is modeled from the perspective of an individual message m. The nodes that hold message m or its copy in the networks are called infected nodes; other nodes are called uninfected nodes. Let x and s denote the number of infected nodes and uninfected nodes, respectively, at a given time. Thus, the total number of the network nodes can be written as




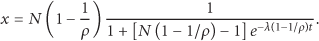



Note that, in the case of buffer management, the number of infected nodes is not greater than the total number of nodes in the network. Therefore, there is an upper bound to the probability for each single message. For this reason, we get

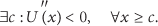
Formula (12) implies that the concavity of
From the above analysis, we can obtain that messages with a large number of copies in the network have much more transfer opportunities. These messages will have relatively higher probability to reach their destination nodes. When we control the increasing number of these messages, the lost utility is limited at a low level. For a single message, it decreases their delivery probability but brings more transfer opportunities for messages that have fewer copies in the network. The increased utility of these messages is greater than the decreased utility of messages that have more copies in the networks. Therefore, it will improve the overall performance.
4.2. Buffer Replacement Scheme
Because of intermittent connectivity in the network, a node could not get the accurate global status about a particular message. It can use statistical learning to estimate the dissemination status of a message when nodes are encountered. We introduce two metrics to measure the priority of a message, including the number of message copies and the dissemination speed of a message. A message that has a smaller replication number is assigned a higher priority. If messages have the same replication number, the message with the lower speed of dissemination is assigned a higher priority.
Let
Here, we describe the process of learning the replication number of a single message. The initial value of replication number is set to 1 when a new message is generated in the network. When node i that carries message m meets node j that does not carry message m, the replication number of message m is processed in the following two cases. One case is that node j is selected as a relay node for message m. If node j does not contain any information about message m, the replication number of message m is set to The other case is that node j is not selected as a relay node for message m. When node j does not contain any information about message m, the replication number of message m is set to
When different messages have the same estimated replication number, we use the Rate metric to describe the dissemination speed of a message. According to the path explosion phenomenon, once a message reaches the destination, there are a number of near-optimal paths to the destination. Therefore, more message copies can exist in the networks. Path explosion occurs much faster among the higher contact rate nodes than the lower contact rate nodes. The Rate metric can reflect the nodes contact rate from viewpoint of a message. This metric is defined as follows:

The node will accept a new message if it has enough free buffer space. Otherwise, the node will compare all the messages in its buffer with the new one according to the priority discussed above. Message with a lower priority will be discarded. The algorithm MTSBR is shown in Algorithm 2.
msg = minPriority(messages in Buffer deleteMessage(msg) deleteMessage(msg) Buffer.freeSize += msg.size
4.3. Buffer Scheduling Scheme
A set of messages that are determined by routing protocol should be forwarded to a better intermediate node. We call these messages Ready Set (RS). Ideally, message carrier node will transmit all of them to the relay node. Unfortunately, not all the messages could be transmitted due to finite bandwidth or unexpected interruptions. It is important for a node to decide the order in which the messages are transmitted. Meanwhile, routing protocol does not consider whether the relay node has enough buffer space to hold these messages. Obviously, bandwidth and node energy are wasted when transmitted messages are dropped due to buffer overflow. It is also important for a node to decide which messages should be forwarded to relay node. To address these problems, we propose MTSBS scheduling scheme that is outlined in Algorithm 3.
Sending
Sending
Sending M to node j
Sending (
Firstly, MTSBS sorts messages in RS in a descending order according to their priority. In all cases, the message with higher priority will be forwarded. Secondly, MTSBS will choose which messages to forward to relay node. If the lowest priority of messages in RS is greater than the highest priority of messages in the peering node, then the node forwards all the messages. If the highest priority of messages is lower than the lowest priority in the peering node, the node will only forward messages that the peering node could contain in its free buffer. In other cases, node merges the message list in RS and peering node. Then it sorts the merged list and selects the top messages that their buffer occupancy is close to the buffer capacity. These messages residing in the local node are forwarded to relay node.
5. Performance Evaluation
We compare the performance of the proposed SBR algorithm against the following three routing algorithms (Epidemic [13], Prophet [21], and ProphetV2 [22]) in DTNs using the ONE [39] simulator.
Epidemic [13]. Messages are flooded to all the encountered nodes. It uses the DO (Drop Oldest: message that has the shortest TTL value is dropped first) and adopts random strategy for message replacement and scheduling, respectively. It is the benchmark that was used for performance analysis and comparison in the previous works.
Prophet [21]. This is a mobility-based approach in DTNs. It calculates the routing metric by using the history of node encounters and transitivity. A message is forwarded to a node that has a higher estimated delivery predictability for a specific destination node than the current message carrier node. It also uses the DO replacement strategy and adopts GRTRMax for message scheduling. GRTRMax forwards messages in descending order of delivery predictabilities.
ProphetV2 [22]. It redefines the transitivity update equation and direct encounter update equation in Prophet.
In this experiment, we also evaluate SBR with different buffer management schemes. SBR-1 denotes SBR routing algorithm with DO replacement and random scheduling scheme. SBR-2 represents SBR algorithm with HBD (History Based Drop) [32] replacement and random scheduling scheme. HBD is a distributed message replacement scheme based on the estimated global information about messages to optimize the specific metric. SBR-3 represents SBR algorithm with our proposed buffer management scheme.
We compare the performance of these algorithms in terms of message delivery ratio, overhead ratio, and average delay.
Delivery ratio is defined as the ratio of the number of delivered messages to the total number of sent messages.
Overhead ratio is the average number of relays used for one delivered message. As the size of a summary vector is very small compared to a message, the overhead of the summary vector is not considered.
Average delay refers to the mean of time from messages generation to their copies first received by the destination nodes.
5.1. Experimental Settings
Two mobility models, that is, a map-based mobility model and RWP mobility model, are used to evaluate the performance of routing protocols.
Under the map-based model, we use the default map in ONE, which consists of a 4500 m × 3500 m area. The map-based scenario is shown in Figure 1. Each labeled circle in the map represents the node, which belongs to a specific group. In order to investigate the impact of different number of groups, we compare these routing algorithms with 3 and 4 groups, respectively. We set

Map-based scenario.
Under the RWP model, the simulation area is 1 km × 1 km. Nodes are randomly distributed in the field. Nodes have an average moving speed of 1.34 m/s and the pause time of a stop is uniformly distributed in
For the two simulation models, each node uses an ideal communication module and has a communication range of 10 m. The transmission speed of nodes is 2 Mbps. Simulation time is 4 hours to ensure that the nodes can form the steady mobility pattern and the stable simulation results can be achieved. A new message with TTL is generated every 15 seconds. The size of messages is 1 KB.
5.2. Experimental Results
Varying Buffer Size. Figures 2 and 3 reveal the impact of buffer size on the performance of routing algorithms in the 3- and 4-group conditions under the map-based mobility model, respectively. In the two scenarios, pedestrian groups have 40 nodes in each group. Their buffer size varies from 100 to 600 KB. As the results in the 3- and 4-group conditions show a similar trend, we only discuss the results for the 3 groups’ condition.

Map-based (3 groups): influence of buffer size on performance.

Map-based (4 groups): influence of buffer size on performance.
Figure 2(a) shows that the delivery ratio becomes larger as the buffer size increases. Epidemic floods more copies in the networks, so it has the lowest delivery ratio when the node buffer space is very small. As expected, ProphetV2 significantly outperforms Prophet in the map-based mobility model, because ProphetV2 can deal with the problem that nodes come together and repeatedly exchange their sets of delivery predictabilities. SBR limits the flooding and improves the delivery probability. As for the buffer management schemes, MTSBR could guarantee the transmission efficiency as it incorporates network status to make decision. When the buffer overflows, MTSBR drops messages that have the most copies. Although HBD and DO take the number of message copies into consideration, they do not care about dissemination capacity of messages. Since DO considers only the number of message copies in a local view and does not incorporate network status, SBR-3 has a higher delivery ratio compared to SBR-1 and SBR-2.
It can be seen from Figure 2(b) that three SBR algorithms have the lower overhead ratio than Epidemic, Prophet, and ProphetV2. Epidemic replicates message to any encountered nodes. When the node buffer space is very small, more message copies are discarded and retransmitted. So it causes the higher overhead ratio. Prophet and ProphetV2 only replicate messages to the encountered nodes that have a higher delivery probability. SBR algorithms can alleviate traffic to some extent because they are able to control the number of message copies by comparing the carrier similarity between encountered nodes. SBR-3 has the lowest overhead ratio among all the SBR algorithms. The MTSBR replacement scheme could reduce the number of retransmissions. It could partially avoid dropping messages that is in the beginning stage of dissemination. MTSBS will decide which messages to transmit. The scheduler considers the buffer constraint and will not transmit the messages that will be dropped in the next intermediate node. So it has a relatively low overhead ratio.
Figure 2(c) shows that the average delay of all the routing algorithms decreases. When the buffer size increases, more message copies will be saved in the nodes’ buffer. The message copies will have more opportunities to arrive at the destination node. Therefore, the message delay will decrease. SBR algorithms performance in terms of average delay remains acceptable, especially SBR-3 algorithm.
Figure 4 shows the impact of buffer size on the performance of routing algorithms under the RWP mobility model. Epidemic gains a significant benefit from increased buffer size. It has the lowest average delay when the buffer size exceeds 200 KB in this experiment. SBR algorithms still have the high delivery ratio when buffer space is small, especially SBR-3 algorithm. These results show that our approach can choose appropriate relay nodes with lower overhead. The average delay is also acceptable. The RWP mobility model does not provide predictable mobility patterns that Prophet and ProphetV2 can leverage. So the difference between their performances is not great like that in group conditions.

RWP: influence of buffer size on performance.
Varying Number of Nodes. Figures 5, 6, and 7 depict the impact of the increasing number of nodes on the performance of different protocols. The number of nodes in each group varies from 20 to 50 under the map-based mobility model. Under the RWP mobility model, the number of nodes varies from 60 to 150.

Map-based (3 groups): influence of the number of nodes on performance.

Map-based (4 groups): influence of the number of nodes on performance.
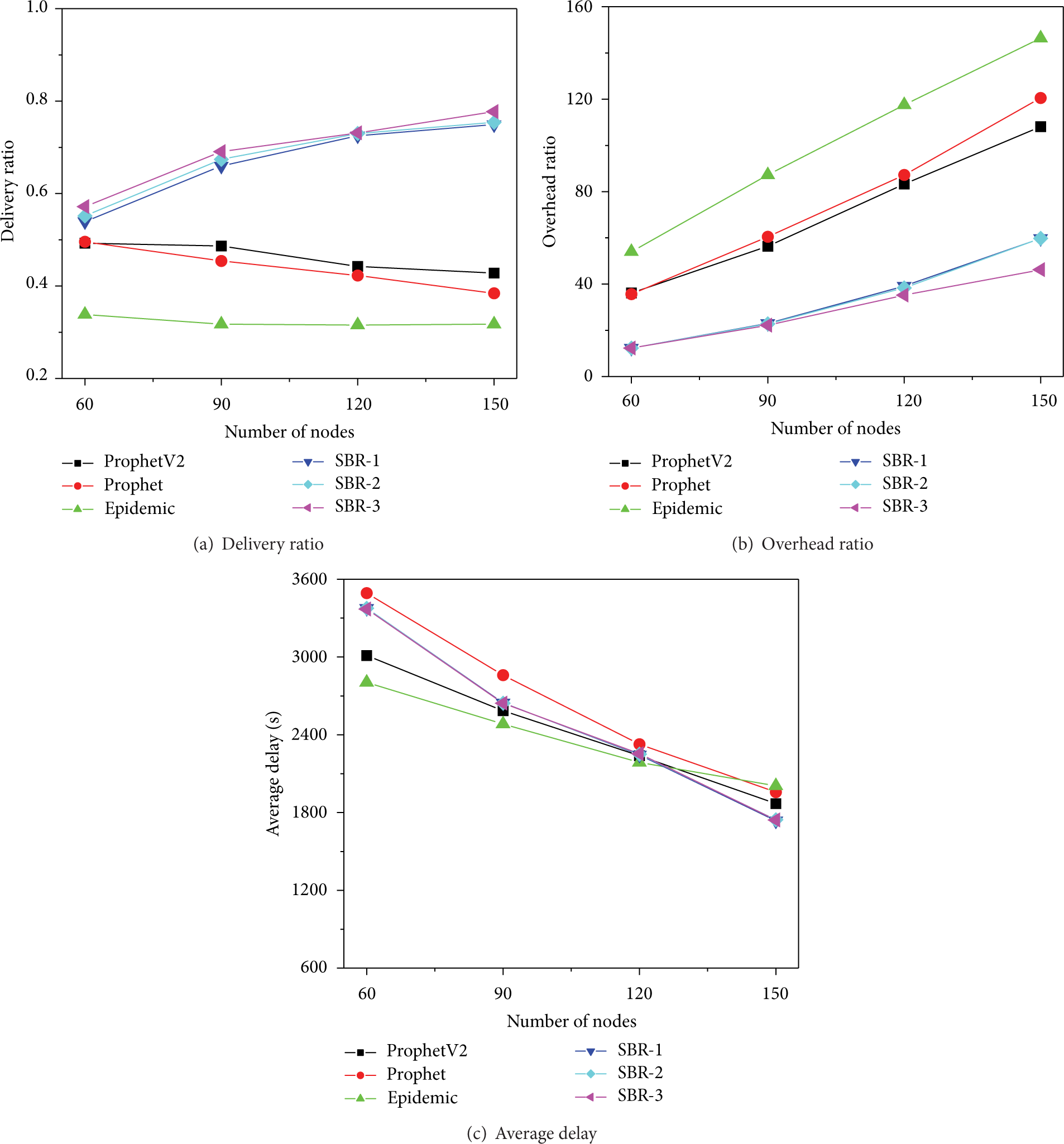
RWP: influence of the number of nodes on performance.
Figure 5(a) reveals that the delivery ratio does not fluctuate much when the number of nodes increases in each group. For the heavy traffic, buffer contention will become more serious when the number of nodes increases even if the routing protocols adopt the controlled flooding scheme. Since SBR uses message transmission status to manage the buffer space, it has a higher delivery ratio. When the number of network nodes increases, the estimate of the global information in HBD becomes more difficult. It has less impact on routing than MTSBR. Thus, SBR-3 has higher delivery ratio than SBR-2.
Figure 5(b) shows that as the number of network nodes increases, the transmission opportunities are also increased. As more message copies are sent in the network, the buffer contention becomes more serious, thus resulting in the increasing overhead ratio. The effect of buffer management scheme for SBR becomes obvious. MTSBR limits further spread of messages that might have a large number of copies, and MTSBS could reduce unnecessary transmissions caused by buffer overflow. Therefore, the increase of overhead ratio in SBR-3 is low.
It can be seen from Figure 5(c) that the average delay of all the routing algorithms decreases. Because more nodes participate in the relay activity, more forwarding opportunities arise. It can alleviate the impact of forwarding limitation of SBR algorithms, Prophet, and ProphetV2. It is worth noting that Figure 6 reveals the performance trends similar to those in Figure 5.
Figure 7 shows the results under the RWP mobility model. Communication opportunities arise when the node density increases. We can see from Figure 7(a) that SBR algorithms have relatively higher delivery ratio than other algorithms when the number of nodes increases. Figure 7(b) shows that the overhead increases when the number of nodes increases. But SBR algorithms can control the number of disseminated messages by carrier similarity to some extent. Our proposed buffer management scheme can further alleviate message retransmission, so SBR-3 has the lowest overhead ratio. In Figure 7(c), we can see that SBR algorithms also have good performance in terms of average delay.
Similarity Threshold Analysis. Here, to analyze the impact of similarity threshold

Comparison of performance under different similarity threshold.
6. Conclusions
The existing routing protocols in DTNs have considered only the similarity of mobility patterns between the relaying nodes and the destination nodes. In this paper, we take into account the similarity of mobility patterns between the message carrier node and its encountered nodes and propose a similarity-based routing protocol, which uses different similarity as the condition of replication or forwarding. Moreover, we estimate the replication number and spreading speed of messages using encounter history. The message with a smaller replication number and lower speed of dissemination is assigned the higher priority. Furthermore, we propose a buffer replacement scheme MTSBR and a scheduling scheme MTSBS according to the priority. Simulation results show that our routing protocols combined with the buffer management schemes outperform the existing routing protocols in terms of delivery ratio and overhead ratio in guaranteed delay.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This project is supported by the National Natural Science Foundation of China (Grants nos. 61103204, 61273232, and 61402541), the Humanities and Social Science Youth Foundation of Ministry of Education of China (Grant no. 13YJCZH110), the Construct Program of the Key Discipline in Hunan Province, the Scientific Research Fund of Hunan Provincial Education Department (Grant no. 12C0768), the Major Science and Technology Research Program for Strategic Emerging Industry of Hunan (Grant no. 2012GK4054), the Open Funding of Science and Technology on Information Transmission and Dissemination in Communication Networks Laboratory (Grant no. ITDU14010/KX142600017), and Postdoctoral Funding of Central South University and Changsha Bohua Technology Co., Ltd., China.