
Abstract
When data owners publish their data to a cloud storage, data integrity and availability become typical problems because the cloud servers are never trusted. To address these problems, researchers proposed the Proof of Retrievability (POR) protocol which allows a verifier to check and repair the data stored in the cloud servers. Based on the POR protocol, the network coding technique is commonly applied to increase the efficiency in data transmission and data repair. However, most previous schemes neither consider a practical scenario nor use the network coding efficiently. In this paper, a lightweight network coding-based POR scheme, called MD-POR (Multisource and Direct Repair for Proof of Retrievability) is proposed. Unlike previous schemes, the proposed MD-POR scheme allows multiple clients who have different secret keys to participate in the scheme. Moreover, the MD-POR scheme supports the direct repair feature in which a corrupted data can be recovered by the servers without burdening the clients. The MD-POR scheme also supports public authentication feature in which a third party auditor is employed to check the servers, and the client is thus free of the responsibility of periodically checking the servers. Furthermore, the MD-POR scheme is constructed based on a symmetric key setting.
1. Introduction
Since data is increasing exponentially, database owners trend to publish their data to storage providers called clouds in order to reduce the burden of data storage and maintenance. Clients can thus access, manage, and share their data from anywhere via the Internet. However, such service providers are untrustworthy and present three basic challenges to data security: (i) integrity, (ii) availability, and (iii) confidentiality. In confidentiality, there are two research approaches: the cryptographic approach (e.g., RSA) and the information-theoretic approach (e.g., secret sharing scheme). Compared to the cryptographic confidentiality approach, the information-theoretic confidentiality approach achieves a security level determined by a threshold. We choose the information-theoretic approach because our security analysis derives purely from information theory. In this paper, we deal with integrity, availability and information-theoretic confidentiality.
To check the cloud servers, researchers proposed the Proof of Retrievability (POR) protocol [1–3] that enables the servers (provers) to demonstrate to the verifier whether the data stored in the servers is intact and available and enables the clients to recover the data when an error is detected. Based on the POR protocol, the integrity and availability assurance are mainly based on three techniques: replication [4], erasure coding [5], and network coding [6–9]. In the replication technique, the client stores file replicas in each server. When a corrupted server is detected, the client uses one of the healthy replicas to repair it. However, the drawback of this technique is high storage cost because the client must store a whole file in each server. Erasure coding technique is then applied to reduce the storage cost. Erasure coding allows the client to store file blocks in each server redundantly instead of file replica as replication. However, when the corrupted data is repaired, the client has to retrieve the entire original file before the client generates new coded blocks. Therefore, its computation and communication costs are increased during data repair. Network coding technique is then applied to improve the efficiency in the data repair. The main advantage of network coding is that the client does not need to retrieve the entire file before the client generates new coded blocks. Consequently, in this paper, we focus on the network coding technique. Our goal is to construct a network-coding POR which satisfies the following aims. Practical scenario: the system should consist of multiple clients, each client keeps a different secret key. This is because in many distributed storage systems today such as Dropbox, each client has a personal data; and hence, each client should use his own secret key to satisfy integrity and confidentiality. Lightweight: firstly, the clients should be free of two heaviest tasks: periodically checking the servers and repairing the corrupted servers. Secondly, the system should be constructed in a symmetric key setting which is a well-known lightweight cryptography rather than an asymmetric key setting.
Network Coding-Based POR Schemes. A few notable network-coding PORs were proposed. Dimakis et al. [10] were the first applying network coding to the distributed storage system. Li et al. [11] proposes a tree-structure data regeneration for the network coding to optimize network bandwidth by using a maximum spanning tree. Chen et al. [12] then adapted the scheme of Dimakis et al. to propose the Remote Data Checking for Network Coding-based distributed storage system (RDC-NC) scheme which provides an elegant data repair by recoding encoded blocks in healthy servers during repair. Cao et al. [13] applied the Luby transform (LT) code for reducing the computation cost because the LT code is a special network code which works in the finite field of order two and only uses exclusive-OR (XOR) operation. Chen et al. [14] proposed the NC-Cloud scheme to improve the cost-effectiveness of repair using the functional minimum storage regenerating (FMSR) code and lighten the encoding requirement of storage nodes during repair. However, all these schemes cannot hold our aims. These system models only have a single client. Furthermore, the check and repair phases in these schemes bring a lot of burden to the client because (i) the client has to periodically check the servers and (ii) when a corrupted server is detected, the healthy servers provide their blocks to the client; the client then has to verifies them, computes the new blocks, and sends these new blocks to the new server. Le and Markopoulou after that proposed the NC-Audit scheme [15] in which a third party auditor is employed and is delegated the responsibility to check the servers instead of the client. The authors also discussed a new repair mechanism in which the new server can compute the new blocks by itself without the need of the client. We call that mechanism as direct repair. Unfortunately, their direct repair is not completed because they mainly focused on how to prevent the data leakage from the third party auditor. Furthermore, their scheme is constructed in an asymmetric key setting and does not deal with multiple clients.
Contribution. In this paper, a new network-coding POR named as MD-POR is proposed. To the best of our knowledge, we are the first to propose a symmetric key setting-based direct repair for the POR; furthermore, the proposed MD-POR scheme also supports multiclient and public authentication. Direct Repair. If a corrupted server is detected, the healthy servers are required to provide their coded blocks directly to the new server instead of sending these coded blocks back to the client. Afterwards, the new server verifies the coded blocks it received and computes the new coded blocks for itself without disturbing the client. This mechanism can reduce the communication cost and the burden for the client. Multiclient. To enable multiple clients, our method does not simply duplicate the process of a single client to multiple parallel processes for multiple clients. Instead, in the proposed MD-POR scheme, the processes of multiple clients are mixed together without loosing the data confidentiality of individual clients. To enable such a multiclient setting, we employ the InterMac technique [16] which was proposed for network scenario. The InterMac technique allows multiple sources to send their packages to the network using different secret keys and allows the recipients to verify the packages they received. Symmetric Key Setting. The MD-POR scheme uses only secret keys without any public key, unlike an asymmetric key setting. Public Authentication. Not only the client but also any entity who has a given information can check the cloud servers while learning nothing about the secret key of each client. We employ a third party auditor (TPA) on behalf of the clients to check the servers periodically. By delegating the responsibility of checking the servers to the TPA, the clients are free of the burden of checking the servers. Otherwise, for the nonexistence of TPA, the clients have to periodically check the servers, and the public authentication feature cannot be supported because only the clients can check the servers. Although the MD-POR scheme supports public authentication, our method does not use an asymmetric key setting.
Organization. The system model, the backgrounds of the Proof of Retrievability, the network coding technique, the InterMac technique, the notations, and definitions are described in Section 2. The adversarial model is presented in Section 3. The MD-POR scheme is proposed in Section 4. The security analysis and efficiency analysis are given in Section 5 and Section 6, respectively. The performance evaluation of the MD-POR scheme is shown in Section 7. The conclusion and future work are drawn in Section 8.
2. Preliminaries
2.1. System Model
The system model of the MD-POR scheme is depicted in Figure 1. There are three types of entities. Clients: these entities have data to be stored in the cloud and rely on the cloud for data storage, computation, and maintenance. These clients can be either enterprises or individual customers. Cloud servers: the cloud servers are managed and monitored by a cloud service provider to accommodate a service of data storage and have significant and unlimited storage space and computation resources. In the cloud storage service, the clients can store their data into a set of servers in a simultaneous and distributed manner. Third party auditor (TPA): this entity is delegated the responsibility to check the servers on behalf of the clients. The TPA is assumed to be trusted to perform the task of periodically checking the servers.
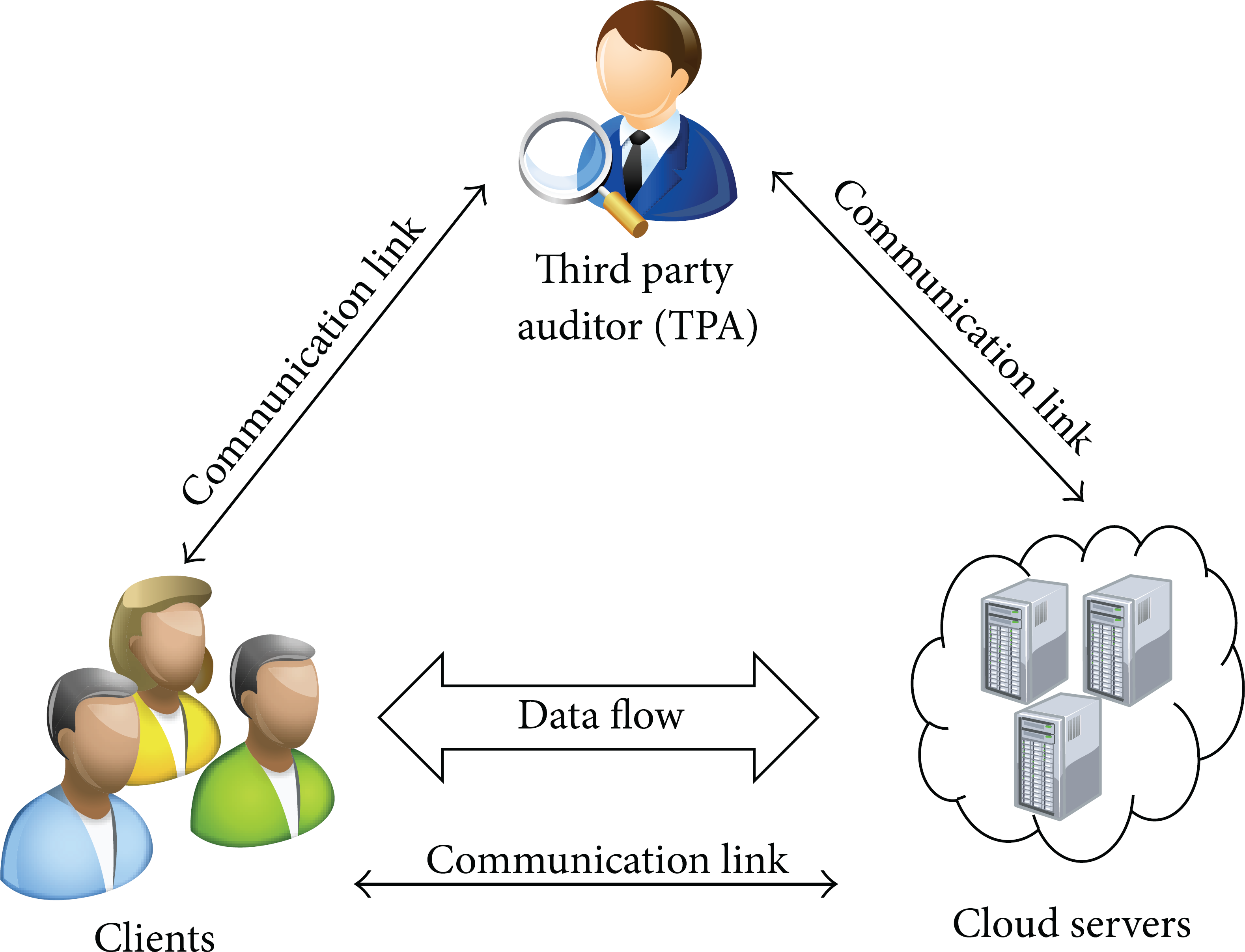
System model.
Originally, the system model which consists of only the client and the servers without the TPA is enough for data check. To enable the public authentication feature, the TPA is employed with an assumption that the TPA is a honest-but-curious entity. Several previous papers also use the same assumption of the TPA, for example, [15, 17–19].
2.2. Proof of Retrievability (POR)
To check the servers, researchers proposed the Proof of Retrievability (POR) [1–3] which is a challenge-response protocol between a verifier (client) and a prover (server). The POR has four phases as follows.
To be suitable for our system model, we modify the POR such that the verifier is the TPA and there are multiple clients as follows.
2.3. Network Coding
Network coding [6–9] is commonly used in network transmission to obtain a good trade-off in term of bandwidth and data repair. Network coding is proposed firstly for the network scenario. It then is applied to the distributed storage system scenario.
Fundamental Concept. In the network scenario, suppose that a source node C wants to send its message to a receiver node R. Before transmitting, C breaks the message into m blocks

These augmented blocks are then sent as packets to the network. When an intermediate node I in the network receives t packets, I will generates t coefficients, linearly combines t packets using the generated coefficients, and transmits the result to its adjacent nodes. Consequently, the receiver node R can receive combinations of all augmented blocks. R can recover m augmented blocks using any set of m combinations. Suppose that R receives m packages
Application in Distributed Storage System. In the network scenario as described above, there are multiple types of entities: source node, intermediate nodes, and receiver node. However, when the network coding is applied to the distributed storage system scenario, there are two types of entities: a client and servers. Suppose that a client has the original file F which consists of m file blocks (

From three augmented blocks
2.4. InterMac
Before describing how the InterMac works, we explain why it is used in our proposed MD-POR scheme as follows. We consider a network in which multiple sources are simultaneously supported and each source owns a different secret key. The data of each source cannot be checked alone. Instead, each source uses the secret key to compute an additional information which is Message Authentication Code (MAC) for each data block. A MAC is also called as tag. Each source then transmits the packets consisting of the data blocks and the corresponding tags to the next adjacent node in the network. A node in the network will linearly combine the received blocks and the homomorphic tags. Herein lies the difficulty of the task: when a recipient node receives a packet, how can this node verify the received linear blocks based on the linear homomorphic tags without any information about any of the secret keys. The traditional methods, that is, MAC or HMAC, are inadequate to solve this task. Some recent schemes related to this problem have been proposed, for example, [21–23]; unfortunately, they all use an asymmetric key setting, which is not our aim.
The InterMac technique [16] is a suitable technique to generate such secret keys for multiple sources. The characteristic of this technique is that the key of the source
Construction. Let
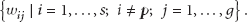
In other words,
The null space of

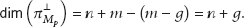
Let
Eventually, a key set
2.5. Notations and Definitions
Throughout this paper, the list of notations and definitions is given in Notation section.
3. Adversarial Model
In the MD-POR scheme, only the clients are trusted because they are the data owners. The following entities are untrusted and considered to be adversaries: attackers outside the system; the cloud servers in the system; the TPA in the system (the TPA is assumed not to collude with the servers. We explained about this assumption in Section 2.1).
Concretely, the adversaries can perform the following the attacks.
3.1. Mobile Attack
This attack is performed by an adversary
3.2. Curious Adversary
This attack is performed by the TPA or a new server. In the check phase, the TPA is given a key κ which is constructed from all the secret keys of the clients. In the repair phase, a new server is given another key
3.3. Response Forgery
This forgery is performed by the servers. In the check phase, the verifier checks all the servers to ensure that they are not corrupted. Each server has to send a response to the verifier in order to demonstrate that the server is healthy. However, a checked server may forge the response to deceive the verifier. If the forged response from the adversarial server satisfies the verification, that server can pass the check phase.
3.4. Pollution Attack
This attack is performed by the servers. The purpose of this attack is to break the linear independence of the encoded blocks. In a network, if a node is malicious and forward invalid package, receivers then obtain multiple packets and cannot tell which of their received packets are corrupt. In other words, the purpose of this attack is to inject invalid packets to prevent data recover. In the POR, this attack happens when a malicious server uses correct data to pass the check phase but then provides invalid data in the repair phase. For example, the client encodes the augmented blocks
4. The Proposed MD-POR Scheme
Before describing the proposed MD-POR scheme in detail, the technical roadmap is depicted in Figure 3. The file blocks are used to generate the augmented blocks. Then, the augmented blocks are combined with random values to compute the keys. Meanwhile, the augmented blocks are linearly combined into the coded blocks using the network coding. Finally, the coded blocks are tagged using the keys. The coded blocks and the tags are the outputs. The network coding is used because it is related to the repair feature (Section 2.3). The InterMac is used because it is related to the multiuser feature (Section 2.4). Both the network coding and the InterMac are constructed based on linear combinations; therefore, they are suitable to combine together in the proposed scheme.

Technical roadmap.
Let

Each client
The proposed MD-POR scheme is now described in detail via each phase of the POR as follows.
4.1. Keygen
4.1.1. Keys for the Clients (Keygen1)
Each key

Using the InterMac (Section 2.4), a key set
4.1.2. Dynamic Keys for a New Server (Keygen2)
When a repair phase is executed, the new server will be given a key

The set consists of

Since
Let
4.2. Encode
Step 1.
Each client

Step 2.
Each client
compute coded block: compute tag:
Step 3.
Each client
compute coded block: compute tag:
4.3. Check
The TPA is assigned the check responsibility. The TPA uses the key
combine coded blocks: combine tags: TPA computes TPA verifies:
Correctness of the Verification (∗). Consider

As described in Section 4.1.1 (Keygen 1), the property of
4.4. Repair
Suppose that the server
Step 1.
Each server
combine coded blocks: combine tags: send the package consisting of
Step 2.
The new server
Given compute check
Step 3.
The new server
new coded blocks new tags
Correctness of the Verification (
5. Security Analysis
5.1. Security against Mobile Adversaries
To prevent mobile adversaries, a data repair threshold is given as follows.
Theorem 1.
The original files
Proof.
Each server

5.2. Security against Curious Adversaries
The following theorem gives the probability of the adversary to recover the secret keys and shows that the probability is negligible.
Theorem 2.
The secret keys of the clients are secured from the TPA and the new server.
Proof.
The TPA checks h servers (
5.3. Security against Response Forgeries
After controlling
Theorem 3.
The advantage of a forgery adversary to pass the check phase is
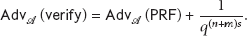
Proof.
To be able to generate
The advantage of
5.4. Security against Pollution Attack
Suppose that the server

The different thing is that the advantage of
We also consider a stronger adversary
6. Efficiency Analysis
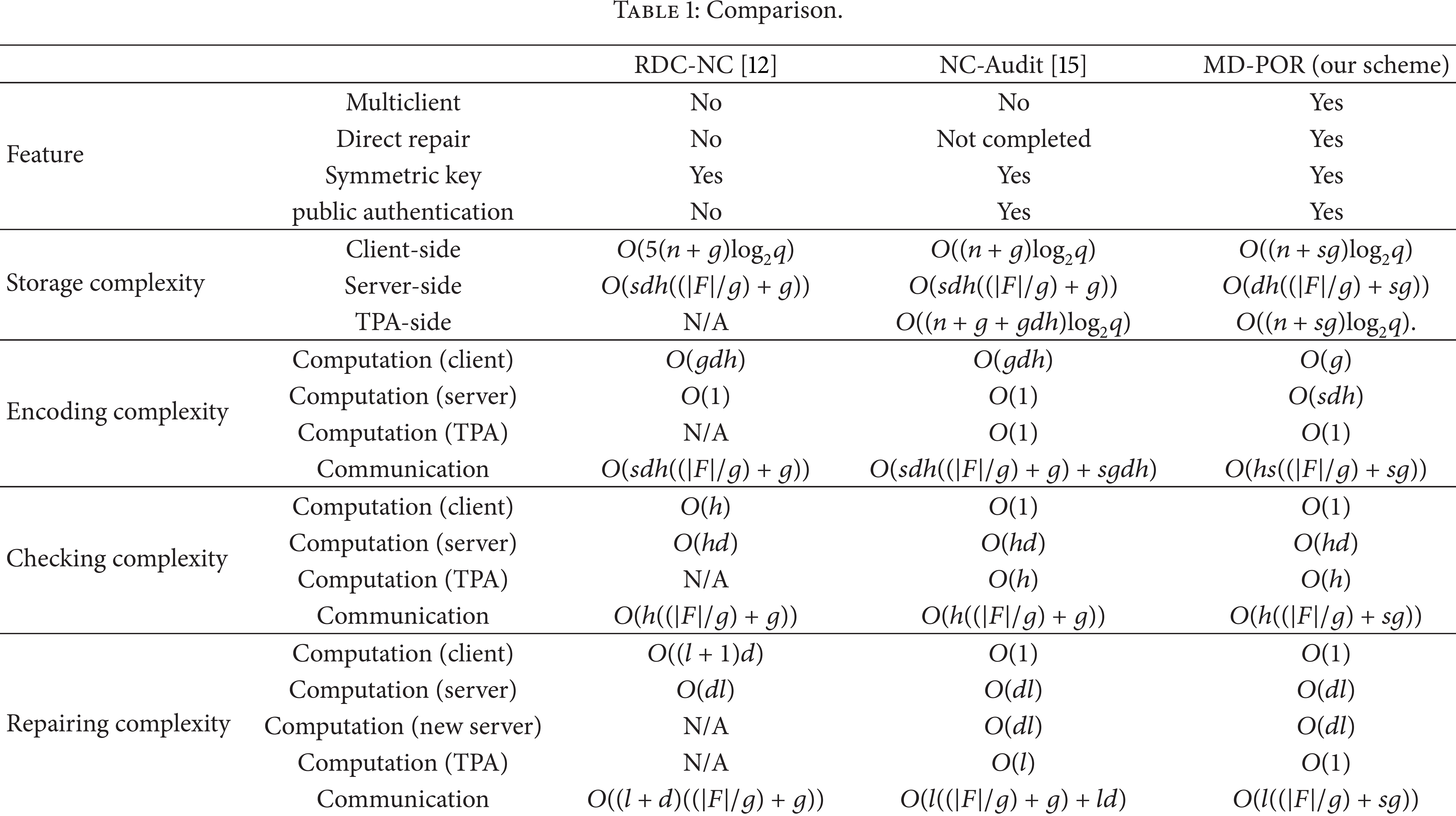
Table 1 compares the features and efficiency of the proposed MD-POR scheme with some previous schemes. The RDC-NC [12] and NC-Audit [15] schemes are chosen for the comparison because they have the same scenario as the MD-POR scheme at most. One notable thing is that because the RDC-NC and NC-Audit schemes only consider a single client unlike the MD-POR scheme, we assume that s clients participate in the RDC-NC and NC-Audit schemes so that the comparisons are fair. However, these s clients in the RDC-NC and NC-Audit schemes can only perform in parallel instead of simultaneously combination as the MD-POR scheme. That parameter s in the RDC-NC and NC-Audit schemes does not affect the checking and repairing complexity because only one client can check and repair the servers. That s only affects the storage cost on server-side and the communication cost of the encode phase in the RDC-NC and NC-Audit schemes.
Comparison.
6.1. Storage Cost
6.1.1. Client-Side
In the RDC-NC scheme, because the client keeps five secret keys in
6.1.2. Server-Side
The size of a file block is
6.1.3. TPA-Side
The RDC-NC scheme does not have a TPA. In the NC-Audit scheme, the TPA not only keeps a key in
6.2. Encoding Cost
6.2.1. Computation on Client-Side
In the RDC-NC and NC-Audit schemes, during the encode phase, each client combines g augmented blocks (which is
6.2.2. Computation on Server-Side
In the RDC-NC and NC-Audit schemes, the servers do not need to do anything and only need to receive the coded blocks computed by the clients. The cost in these schemes is thus
6.2.3. Computation on TPA-Side
In the RDC-NC scheme, the TPA does not exist. In the NC-Audit and MD-POR schemes, the TPA does nothing during the encode phase; and the costs are thus
6.2.4. Communication
In the RDC-NC scheme, the client creates
6.3. Checking Cost
6.3.1. Computation on Client-Side
In the RDC-NC scheme, the client receives the aggregated coded block from each of h servers and verifies each of them using his/her secret key; the cost is thus
6.3.2. Computation on Server-Side
In all three schemes, each of h servers combines its d coded blocks to send the result (an aggregated coded block) back to the verifier. The verifier is the client in the case of the RDC-NC scheme and is the TPA in the case of the NC-Audit and MD-POR schemes. The cost in all three schemes is
6.3.3. Computation on TPA-Side
In the RDC-NC scheme, the TPA does not exist. In the NC-Audit and MD-POR schemes, the TPA verifies the aggregated coded block which is accommodated from each of h servers. Each verification only takes one operation. The cost in the NC-Audit and MD-POR schemes is
6.3.4. Communication
In the RDC-NC and NC-Audit schemes, during the check phase, each of h servers sends its aggregated coded block to the client. The size of that coded block is (
6.4. Repairing Cost
6.4.1. Computation on Client-Side
In the RDC-NC scheme, in the repair phase, the client firstly has to check pollution attack in l coded blocks which are provided from l healthy servers (which is
6.4.2. Computation on Server-Side
In the RDC-NC scheme, each of l healthy servers is required to combine its d coded blocks. Therefore, the computation cost on the server-side is
6.4.3. Computation on TPA-Side
The RDC-NC scheme does not have a TPA. In the NC-Audit scheme, the TPA has to check pollution attack in l provided coded blocks (which is
6.4.4. Communication
In the RDC-NC scheme, each of l healthy servers sends an aggregated coded block whose size is
In summary, although the MD-POR scheme supports many heavy features, its cost of the whole scheme is still better than the previous schemes. Let
7. Performance Evaluation
This section evaluates the computation and communication performances of the proposed MD-POR scheme to show that it is applicable for a real system. A program written by Python 2.7.3 is executed using a computer with Intel Core i5 processor, 2.4 GHz, 4 GB of RAM, and Windows 7 64-bit OS. The length of the prime q is set to be 160 bits. The number of clients is set to be 5 (
The experiment results are observed with three sets of computation performance and a set of communication performance by varying the file size of each client. The computation results are depicted in Figure 4 (encode), Figure 5 (check), and Figure 6 (repair). The communication result is depicted in Figure 7 (encode, check, and repair).
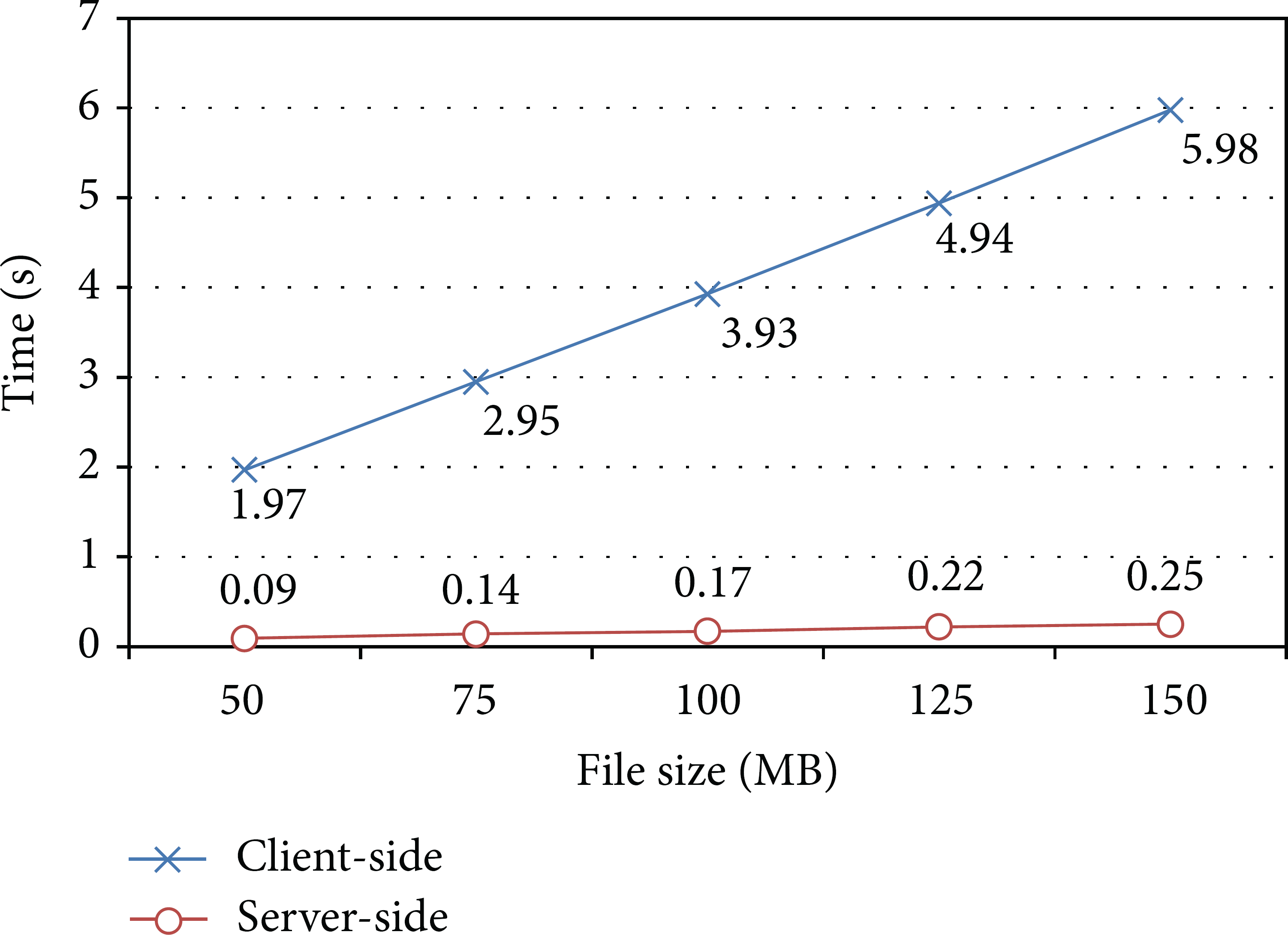
The computation time performance of the encode algorithm.

The computation time performance of the check algorithm.

The computation time performance of the repair algorithm.

The communication time performance.
Computation Performance. The experiment results reveal that the computation time increases almost linearly as the file size increases, and each graph has a different slope. Only the computation time of TPA-side in the check phase is almost constant. In the encode phase, the slopes of increment in the graphs of client-side and server-side are approximately 0.04 and 0.002, respectively. Therefore, if the file size is 1 GB, the computation time on client-side and server-side is estimated as 41 seconds and 2 seconds, respectively. Note that the encode phase only is executed one time in the beginning; meanwhile, the check phase is executed many times during system lifetime and the repair phase is executed once a corruption is detected in the check phase. Consequently, the check and repair phases are more important than the encode phase. In the check phase, the slopes of increment in the graphs of server-side and TPA-side are approximately 0.0005 and 0, respectively. Therefore, if the file size is 1 GB, the computation time on server-side and TPA-side is estimated as 0.52 seconds and 0.02 seconds, respectively. Similarly, in the repair phase, the slopes of increment in the graphs of healthy server-side and new server-side are approximately 0.0005 and 0.0014, respectively. Therefore, if the file size is 1 GB, the computation time on healthy server-side and new server-side is estimated as 0.52 seconds and 1.47 seconds, respectively.
Communication Performance. The MD-POR scheme is performed with the bandwidth of 300 Mbps. The experiment results reveal that the communication time increases almost linearly as the file size increases, and each graph in Figure 7 has a different slope. The slopes of increment in the graphs of the encode phase, the check phase, and the repair phase are approximately 0.048, 0.008, and 0.006, respectively. Therefore, if the file size is 1 GB, the communication time of the encode phase, check phase, and repair phase is estimated as 49.27 seconds, 7.86 seconds, and 5.83 seconds, respectively. In addition, the size of the response from each server is given as follows. The response size of 50 MB, 75 MB, 100 MB, 125 MB, and 150 MB file size is 13 KB, 19 KB, 26 KB, 32 KB, and 38 KB, respectively. Therefore, if the file size is 1 GB, the response size is estimated as 264.87 KB.
The above results indicate that the computation and communication performances are very fast even when the file size is 1 GB.
8. Conclusion and Future Work
In this paper, a network coding-based POR scheme named MD-POR has been proposed. The MD-POR scheme supports multiclient, symmetric key-based direct repair and public authentication features. Moreover, the MD-POR scheme can protect against a strong adversary who can perform mobile attack, curious attack, response forgery, and pollution attack. Furthermore, the efficiency analysis based on the complexity theory shows that although the MD-POR scheme supports many features, its costs are not bad compared with the previous schemes. The experiment results reveal that the computation time increases as the file size increases. However, the graphs show that the slope of increment for the MD-POR scheme increases merely. Future work is invested to implement two previous RDC-NC and NC-Audit schemes in order to compare with the MD-POR scheme. This paper have implemented only the MD-POR scheme to show that its computation cost is applicable for a real system.
Footnotes
Appendix
Notations
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This study was partly supported by Grant-in-Aid for Young Scientists (B) (25730083) and CREST, JST.