
Abstract
This paper presents a compressive-sensing- (CS-) based video codec which is suitable for wireless video system requiring simple encoders but tolerant, more complex decoders. At the encoder side, each video frame is independently measured by block-based random matrix, and the resulting measurements are encoded into compressed bitstream by entropy coding. Specifically, to reduce the quantization errors of measurements, a nonuniform quantization is integrated into the DPCM-based quantizer. At the decoder side, a novel joint reconstruction algorithm is proposed to improve the quality of reconstructed video frames. Firstly, the proposed algorithm uses the temporal autoregressive (AR) model to generate the Side Information (SI) of video frame, and next it recovers the residual between the original frame and the corresponding SI. To exploit the sparse property of residual with locally varying statistics, the Principle Component Analysis (PCA) is used to learn online the transform matrix adapting to residual structures. Extensive experiments validate that the joint reconstruction algorithm in the proposed codec achieves much better results than many existing methods with consideration of the reconstructed quality and the computational complexity. The rate-distortion performance of the proposed codec is superior to the state-of-the-art CS-based video codec, although there is still a considerable gap between it and traditional video codec.
1. Introduction
1.1. Motivation and Objective
In wireless sensor network, with the constraints of limited processing capabilities, limited power/energy budget, and information loss [1], it is challenging for video sensors to encode and transmit these big-data video sequences by using the traditional video codec (e.g., H.264/AVC [2] and HEVC [3]), and therefore various video-codec schemes have been developed to provide a low-complexity but high-compression encoder, in which Distributed Video Coding (DVC) [4, 5] and Compressed Video Sensing (CVS) [6, 7] attract more attention. For the video coding in wireless sensor network, the CVS is potentially more suitable because its theoretic foundation, compressive sensing (CS) [8], ensures the simultaneous sampling and compression of each video frame by optical devices (e.g., CS-MUVI [9] and CACTI [10]). Currently, lots of CVS schemes are trying to realize a codec to code measurements of video sequence into bits, but their rate-distortion performances are still far from satisfactory.
The first objective of this paper is to design a CS-based video codec framework for wireless sensor network. In particular, based on the existing excellent works of CS, each step is crafted from original video sequences to bits and inverse, and we also discuss (1) how to design quantization of measurements for reducing the quantization error and (2) how the prediction structures of decoding affect the performance of joint reconstruction. Another objective of this paper is to propose an efficient reconstruction algorithm for further improving the rate-distortion performance of codec. As an important characteristic of video sequence, the interframe correlation will be exploited in the reconstruction of video frames.
1.2. Related Work
The basic elements of CVS scheme include random measurement, quantization of measurements, and reconstruction. Because of the huge amount of video data, the random measurement must be implemented frame by frame, in which the block-based random matrix [11] and structurally random matrix [12] are often used due to their small memory requirement, low complexity, and high universality. For the majority of CVS schemes [13, 14], the measurements are not quantized. The uniform scalar quantization can be occasionally used, such as in [15, 16], but it results in a poor rate-distortion performance. Recently, the more concerns are put on quantized CS [17–20], and some specific quantizers for measurements were designed to improve the recovery performance, such as DPCM-based quantizer [19] and binned progressive quantizer [20]. The existing reconstruction strategies can be divided into three categories: frame-by-frame reconstruction [6, 7], volumetric reconstruction [21, 22], and joint reconstruction [14, 23, 24]. The frame-by-frame reconstruction regards video sequence as a series of independent video frames, and the still-image recovery algorithm is exploited to reconstruct each frame. This strategy neglects the interframe correlation, which results in a poor reconstruction performance. The volumetric reconstruction regards video sequence as three-dimensional (3D) signal and uses a fixed 3D basis (e.g., 3D DWT and 3D DCT) to reconstruct the whole video sequence or certain video clip. However, it is not a practical strategy because the huge memory and high computational complexity are required at the decoder side. The joint reconstruction is derived from the decoding strategy of DVC, and each video frame is reconstructed with the aid of Side Information (SI), which is interpolated by Motion Estimation (ME) and Motion Compensation (MC). This method not only guarantees the small memory and low computational complexity by single-frame reconstruction but also exploits the motion information between adjacent frames in the reconstruction by using SI. Therefore, the joint reconstruction is the most promising approach among the above three kinds of strategies.
The joint reconstruction is used in the proposed CVS scheme, and it consists of SI generation and SI-based recovery. For the SI generation, it can be interpolated either by the Frame Rate Upconversion (FRUC) [25] techniques such as that in [13, 15] or by both the measurements and the neighboring frames of current frame such as those in [14, 24]. Generally speaking, the SI generated by measurements and neighboring frames has more superior performance than that generated by FRUC because the former can use the information of current frame to generate SI. After generating the SI, the SI-based recovery uses measurements to enhance the quality of SI. References [15, 26] resorted to the Wyner-Ziv codec [5] in DVC to realize the SI-based recovery; however, these recovery methods strongly rely on the encoder side in real time because they require encoder side via feedback channel to transmit measurements of current frame. Without the feedback channel, the SI-based recovery can still be performed by modifying the CS recovery model, such as in [13] that used the SI to modify initialization and stopping criterion of the GPSR (Gradient Projection for Sparse Reconstruction) algorithm. References [14, 23, 24, 27] proposed to recover the residual between the original frame and its SI. It is important for low latency of video communication to decode the video sequence with independence of encoder side, and therefore the methods based on the modified CS recovery model can make the CVS scheme more practical and flexible, especially for residual recovery used in [14, 23, 24]; its performance can be further improved by developing the more amenable CS recovery algorithm with the expectation that the residual is much more compressible than its original.
For the existing CVS approaches, the measurements of video frames cannot be efficiently compressed using quantization and entropy coding, which motivates us to develop the compression of CVS encoder. Importantly, the SI generation and residual recovery are improved, respectively, for guaranteeing the better performance of joint reconstruction. First, we design the architecture of CS-based video codec including encoder and decoder framework. In particular, a DPCM-based nonuniform quantizer is proposed to reduce the quantization error of measurements, and we also analyze the performances of various decoding predictive structures. Second, a joint reconstruction algorithm is proposed to improve the rate-distortion performance of codec. Specifically, combined with measurements of current frame, the temporal autoregressive (AR) model is used to generate its SI, and the quality of reconstructed residual is improved by using an adaptive orthogonal transform matrix learned online by Principle Component Analysis (PCA) [28].
1.3. Main Contributions
First, we present a CS-based video codec. At the encoder side, according to the statistical characteristic of measurements, we propose to replace uniform quantization in DPCM-based quantizer with nonuniform method. At the decoder side, we analyze the effect on reconstruction performance of various decoding predictive structures.
Second, we propose the joint reconstruction algorithm which consists of AR prediction and adaptive residual recovery. It motivates us to generate the SI of video frame that the AR model preserves the local structure of image better. To exploit the highly sparse property of residual, we use PCA to trace the locally varying statistics of residual.
The remainder of this paper is organized as follows. Section 2 provides a brief review of the CS theory and the comparison between CVS and traditional video codec. Section 3 presents the proposed CS-based video codec architecture. Section 4 describes the joint reconstruction algorithm including AR prediction and adaptive residual recovery. Experiment results are reported in Section 5 to evaluate the performance of the proposed video codec. Finally, the conclusion is made in Section 6.
2. Background
2.1. CS Theory
The CS theory builds on the groundbreaking study of Candès et al. [29] and Donoho [30], which asserts that one can accurately recover certain signals from far fewer samples or measurements than Nyquist rate. To make this possible, CS relies on three principles: sparsity or compressibility of signals, incoherent measuring, and optimal recovery, in which the sparsity or compressibility of signals is a necessary condition, the optimal recovery is the method to reconstruct original signal, and the incoherent measuring ensures the convergence of optimal recovery [31].
The mathematical formulation of CS is described as follows. Suppose


With development of the CS theory, it has already been applied in medical imaging, data communication, wireless sensor network, remote sensing, and so forth. For the wireless sensor network especially, each sensor cannot afford excessive computations, and the unstable wireless channel also requires that the output data from sensors have an antinoise performance. Exactly, the sub-Nyquist sampling of CS ensures a low computational complexity, and the inherence between measurements also increases the robustness to noise [32], which provides a good chance for applying the CS to data acquisition in the wireless sensor network.
2.2. CVS versus Traditional Video Codec
Traditional video codec (e.g., MPEG and H.264) uses the hybrid encoding framework, and its encoder performs the motion estimation to exploit the spatial-temporal redundancy existing in video signal. In general, its encoding complexity is about 5 to 10 times than its decoding complexity, and therefore the traditional video codec is suitable for some applications requiring one encoding and multiple repeated decoding, for example, video broadcasting, video on demand, and video storage [4]. However, due to the limited computation, memory, and energy of sensors, the wireless sensor network is inverse to the above applications, and it requires a low-complexity encoder but can tolerate a high-complexity decoder. The CVS system resorts to CS theory to transfer the majority of the complexity of video encoding to the receiver, and therefore it is more suitable for wireless sensor network than traditional video codec. In addition to offering substantially reduced encoding complexity, the CVS has many attractive and intriguing properties, particularly when we employ random measuring at the sensor. Random measurements are universal in the sense that any transform matrix can be used in the decoder, allowing the same encoding strategy to be applied in different sensing environments. Because the measurements coming from each sensor have equal priority, the random coding is also robust to bit errors; that is, one or more measurements can be lost or destroyed without corrupting the entire recovery [33].
3. CS-Based Video Codec Architecture
In this section, we describe the proposed CS-based video codec architecture in detail. The overall flow of this codec is shown in Figure 1. The input video sequence is firstly divided into several Groups of Pictures (GOPs) with the fixed length L, and then each

Overall flow of the proposed CS-based video codec architecture.
3.1. Encoder Framework
In the encoder framework whose block diagram is depicted as the dotted box marked by Encoder in Figure 1, the key frame is firstly split from the GOP, and others are regarded as the nonkey frames. Each
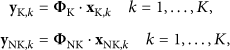
The DPCM-based quantizer in [19] uniformly quantizes the residuals between measurements of the consecutive blocks because the residuals with less redundancy can further reduce the bits of video frame. Figure 2 shows the histograms of residuals for the 2nd frame of Foreman sequence with CIF format and 30 fps at the different subrates; we can see that residual values are unevenly distributed, but the small values appear more frequently. For this statistical characteristic of residual, the uniform quantization is not good at decreasing the quantization errors of measurements, and instead the nonuniform quantization is a more proper method. The block diagram of DPCM-NQ is shown in Figure 3. For the mth measurement

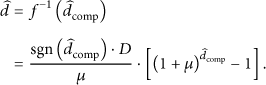

Histograms of residuals for the 2nd frame of Foreman sequence with CIF format at the different subrates: (a) 0.1, (b) 0.2, and (c) 0.3.

Block diagram of the DPCM-based nonuniform quantizer: (a) quantization and (b) dequantization.
Finally, the Huffman encoding is used to compress the quantized measurements into bits. To conveniently add various headers (such as IP header) required by wireless network protocols, these bits and some important decoding parameters should be packed into a packet according to a format shown in Figure 4. The different fields in the packet are defined below, and note that the decoding parameters are saved by positive integer unless otherwise mentioned.
Number Block size B: 8 bits—this provides the block size of video frame. Number Number Sequence number i of GOP: 16 bits—this field is used to uniquely identify the order of GOP in order to regroup video sequence at the decoder side. Length L of GOP: 8 bits—this field provides the fixed length of GOP. Bit depth b: 8 bits—this field is used to compute number Maximum measurement Data: the bits of measurements of each frame are saved in this field.

Packet format.
3.2. Decoder Framework
The block diagram of decoder framework is shown as the dotted box marked by Decoder in Figure 1. The key frame is reconstructed independently by only using these dequantized measurements





To exploit the interframe statistical dependencies, an efficient Predictive Structure (PS) is required to select the reference frames for joint reconstruction. In the PS, the key frame is called I frame due to the fact that no reference frames are available for prediction, and the nonkey frames are classified as the following two types: P frame using unidirectional prediction and B frame using bidirectional prediction. The PS starts from I frame, and a high-quality initial reference frame is helpful for improving the reconstruction performance of following video frames. Therefore, the I frame requires the higher subrate than P and B frames. For the joint reconstruction, B frame has more superior performance than P frame because the former can use the more temporal information to reconstruct video frame, and consequently inserting B frame into PS has the potential to achieve a substantial performance gain. Figure 5 illustrates the five different PSs when the length of GOP is 8, in which I, P, and B frames are combined in the different reconstruction orders. Each PS is a strategy to explore the interframe correlation; however, only the reasonable combination of I, P, and B frames then can significantly improve the rate-distortion performance of codec. The experimental results using the different PSs depicted in Figure 5 are shown in Section 5.6, which concretely analyzes the effect of these PSs on the performance of the proposed codec.

Five reference frame structures for temporal prediction when the length of GOP is 8: (a) PS1, (b) PS2, (c) PS3, (d) PS4, and (e) PS5. The number at the top-right of box represents the reconstruction order.
4. Joint Reconstruction Algorithm
Here, we propose a novel joint reconstruction algorithm, which consists of AR prediction and adaptive residual recovery. The AR model can well model the fact that a local area along temporal axis can be viewed as a stationary process [36], and therefore AR prediction can exploit local temporal correlation to improve the quality of SI. Similar to natural signal, the residual between original frame and its SI typically has locally varying statistics, and there exists no fixed transform matrix in which all blocks of residual exhibit sparsity [37], which motivates us to propose a PCA-based locally adaptive strategy to recover the residual.
4.1. Autoregressive Prediction
As shown in Figure 6, the AR model is used to describe the temporal correlation between pixels along the motion trajectories from the block

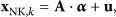

Equation (12) is not a realistic representation of



To control the







In the abovementioned AR model, it is essential to compute the Motion Vector (MV) from the block
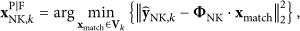


Relative positions of candidate MVs used in 3DRS.
4.2. Adaptive Residual Recovery
Without the original residual
To learn online the PCA transform matrix of each residual block, the framework of iterative shrinkage algorithm summarized in [43] is used to realize the adaptive residual recovery, which is presented as follows.
The Proposed Adaptive Residual Recovery Algorithm
Task. Find the optimal solution Initialization. Initialize Main Iteration. Increment j by 1, and apply these steps: PCA-Update. Compute the PCA transformation matrix Shrinkage. Compute Back-Projection. Compute
Stopping Rule. Stop when Output. The result
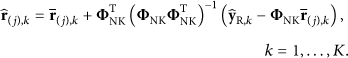
A high-quality initial residual estimate is helpful to promoting gradually the accuracy of PCA transform matrix based on iterations; and we also expect that the initialization of residual cannot introduce the excessive computations. Therefore, the initial estimate is computed by the Minimum Mean Square Error (MMSE) linear estimation used in [11]; that is,


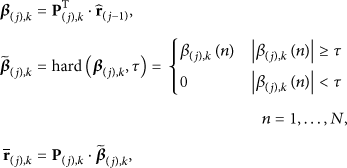
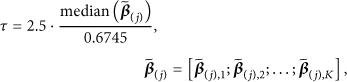

The implementation of PCA-Update is described as follows. At first, we pixel-by-pixel extract M samples
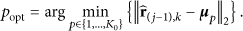
5. Experimental Results
In this section, various experiments are conducted to evaluate the performance of the proposed CS-based video codec. We use the nonquantization, AR prediction, and PCA-based adaptive residual recovery to improve the quality of reconstructed video frame, and therefore the above methods in the proposed CVS system are separated to verify their performance gains: (1) we compare the quantization errors of DPCM-based nonuniform quantizer (DPCM-NQ) with those of DPCM-based uniform quantizer (DPCM-UQ) proposed by [19]; (2) the encoding complexity of the proposed video codec is analyzed, and its encoding time is compared with those of H.264/AVC [2], HEVC [3], and DISCOVER [5]; (3) the performance of the proposed joint reconstruction algorithm is evaluated by using Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity (SSIM) [45], and the comparisons with some existing reconstruction algorithms [13, 14, 23, 24] are also presented; (4) the computational complexity of the proposed joint reconstruction is analyzed, and its reconstruction time is compared with those of the existing CS-based methods in [13, 14, 23, 24] and the decoder of traditional video codec H.264/AVC under the different frame resolutions; (5) the performance comparison is performed when the adaptive PCA matrix and fixed DCT and Daubechies-4 matrices [46] are applied into the residual recovery, respectively; (6) we discuss the effects of various PSs depicted in Figure 5 on the performance of the proposed video codec. Finally, the rate-distortion performance of the proposed overall video codec is evaluated from two aspects. On the one hand, we combine the proposed joint reconstruction and other CS-based algorithms in [13, 14, 23, 24] into our CVS system, respectively, and present the comparison among their rate-distortion performances. On the other hand, the rate-distortion curve of the proposed CVS system is also compared with those of H.264/AVC-Intra codec, DISCOVER, and CS-KLT video codec proposed in [16].
Four test sequences with CIF resolution of
5.1. Quantization Performances
The DPCM-Q and DPCM-NQ are, respectively, used in the proposed video codec to encode the first 100 frames of each test sequence, and the average quantization errors of these two quantizers on all test sequences are presented in Table 1. It can be seen that the quantization errors of DPCM-NQ are more smaller than DPCM-UQ at any subrate, and it decreases 58.90% on average over the DPCM-UQ, which benefits from the fact that nonuniform quantization is more suitable for the distribution of measurement residual. However, the DPCM-NQ pays also the price for reducing quantization error. Table 1 shows the average total execution time to encode each test sequence. It can be observed that the DPCM-NQ requires more time than the DPCM-UQ at any subrate, and it obtains 55.17% time gain on average compared to DPCM-UQ, which results from the fact that compression and expansion operations introduce some computations.
Performance comparisons of different quantizers.

5.2. Encoding Complexity
Due to nonstationary statistics of video sequence, it is not possible to accurately predict the number of operations required to encode each video frame, and instead we use the execution time of encoding video sequence to indirectly reveal the encoding complexity. The first 100 frames of each test sequence are encoded, respectively, by the proposed CS-based video codec, DISCOVER (available online at http://www.discoverdvc.org/), the H.264/AVC JM9.5 software (available online at http://iphome.hhi.de/suehring/tml/), and the HEVC HM10.0 software (available online at http://www.hevc.info/), in which our codec is written in MATLAB and others are programmed in C++. The test conditions are presented as follows.
Proposed codec and DISCOVER: insert one I frame every 10 frames. The proposed codec is configured with different subrates of nonkey frame (i.e., H.264/AVC and HEVC: the first configuration is All Intra with QP set to 27 (AI27), where all frames are encoded using I frame, and the second configuration is Low Delay (LD) with QP set to 27 (LD27), where only the first frame is encoded using I frame, and others are encoded using P frame.
Table 2 presents the encoding time of various video codecs under the above test conditions. We can see that the proposed codec requires much time as the subrate increases; however, it does not take more than 10 s even with a higher subrate; for example, the time to encode Mobile sequence requires only about 7.38 s when the subrate is 0.5. DISCOVER has a moderate encoding time, and it requires about 42.09 s on average to encode a test sequence. Regardless of AI27 and LD27, both H.264/AVC and HEVC take a long time; particularly LD27 configuration in HEVC has a heavy computational burden. Although these results have a weak comparability due to the tradeoff between encoding complexity and rate-distortion performance, it can be testified under the common test conditions that the encoder of proposed codec has a very low complexity when compared with H.264/AVC, HEVC, and DISCOVER. The Compression Ratio (CR) of all test sequences is also shown in the last row of Table 2; it can be seen that the proposed codec obtains the higher CR while reducing the encoding time, which is contrary to H.264/AVC and HEVC; however, the high CR only shifts the computational complexity from encoder to decoder. Besides, we can observe that DISCOVER has a high CR with the help of the feedback channel, but the existence of feedback channel increases the difficulty to its applications.
Encoding time of various video codecs.

5.3. Reconstruction Performances
Next, the performance of the proposed joint reconstruction algorithm is evaluated from objective and subjective views by comparing it with those of methods proposed by [13, 14, 23, 24]. We successively process 10 GOPs of length
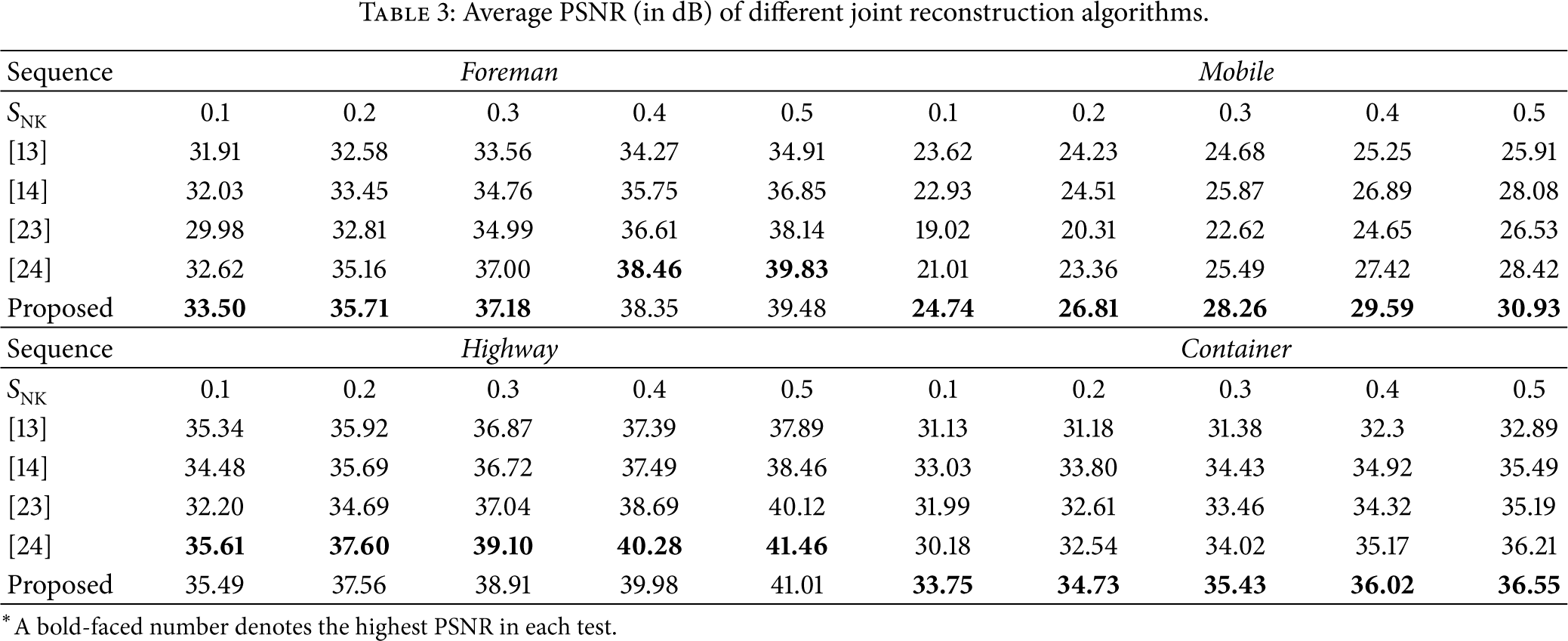
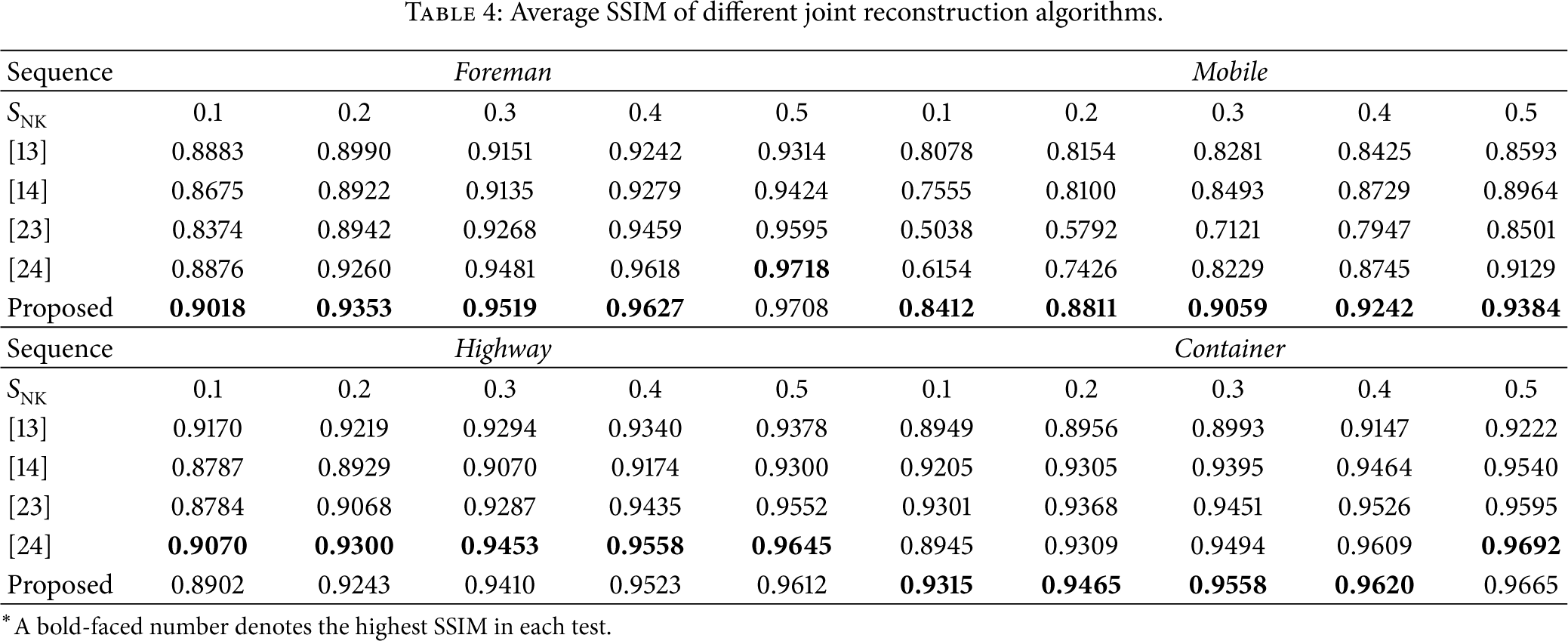
The average PSNR results reconstructed by various methods for each test sequence are provided in Table 3. It can be seen that the proposed method is very efficient for the highly textured Mobile sequence and the slow translational Container sequences; for example, when compared with the best one of these comparative methods, the proposed method improves the results by at most 2.85 dB and 1.00 dB for Mobile and Container sequences. For the Foreman sequence with moderate and large motions, the proposed method achieves the obvious PSNR gains at the low subrates, but it has about 0.2 dB loss at the high subrates when compared with [24]. However, the method of [24] obtains the PSNR gains of about 0.04–0.45 dB compared with our method for the Highway sequence with fast global motions. Similar results can also be achieved from the viewpoint of the SSIM, which can be observed in Table 4. We also visually assess some video frames constructed by different methods. Figures 8-9 show the reconstructed frames of Foreman and Mobile, at the subrate
Average PSNR (in dB) of different joint reconstruction algorithms.
Average SSIM of different joint reconstruction algorithms.

Visual comparison of the reconstructed 26th frame of Foreman by different methods (

Visual comparison of the reconstructed 46th frame of Mobile by different methods (
5.4. Reconstruction Complexity
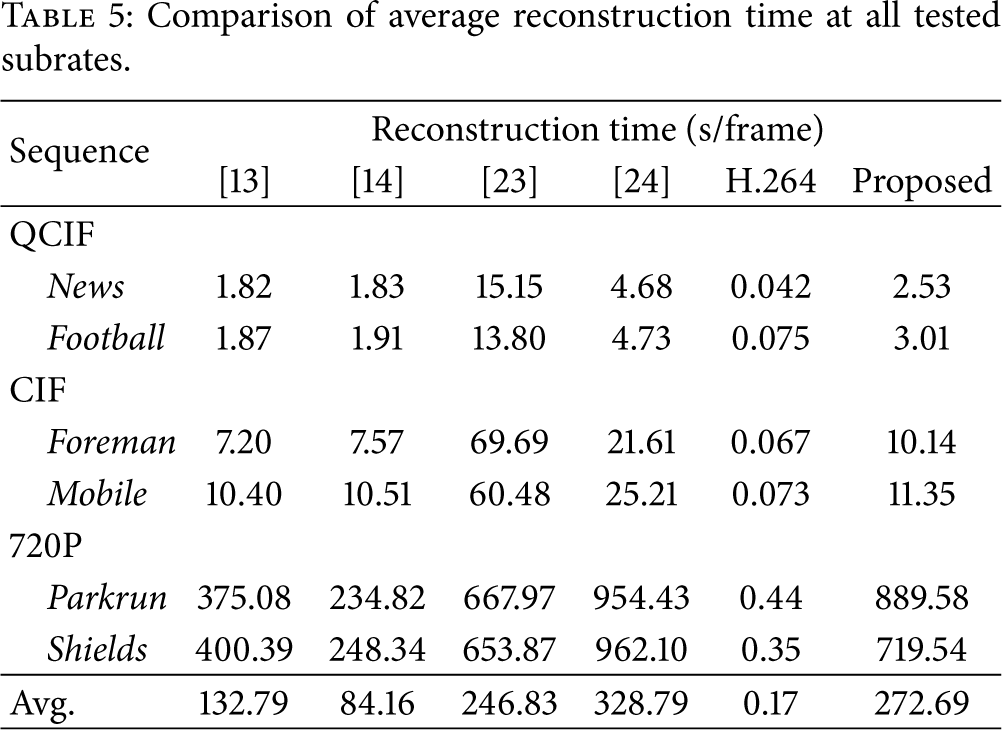
For the computational complexity of various methods, it can be seen from Table 5 that the proposed method has a moderate computational complexity; for example, its reconstruction time is only about half those of [24] for the sequences with QCIF and CIF format. We can also see that the reconstruction time of each algorithm increases as the resolution of video frame increases, especially for the sequences with 720P format; the proposed method has significant reconstruction time gains due to the sensitivity of PCA computations to large-scale signal. At the different resolutions, although some methods require shorter time than our method, there is a big reconstruction performance gap between them and ours. Therefore, taking full account of reconstructed quality and computational complexity, the proposed method has a better performance than other CS-based methods. Besides, we present the decoding time of H.264/AVC JM9.5 software with the configuration LD27, and it can be observed that the CS-based method has a heavy computational burden when compared with H.264/AVC, which verifies that the significant decrease of encoding complexity comes at the expense of increased decoding complexity.
Comparison of average reconstruction time at all tested subrates.
5.5. PCA versus Fixed Transform Matrices
In the proposed joint reconstruction, we recover the residual frame by using the PCA-based adaptive transform matrix. To verify the effectiveness of adaptive residual recovery, the GPSR algorithm [27] is provided with the fixed DCT and Daubechies-4 matrices, respectively, to recover residual of each frame, and their resulting average PSNR curves on all test sequences with CIF format are compared with that of adaptive residual recovery using PCA, which is presented in Figure 10. It can be seen that our adaptive PCA matrix has higher PSNR values than the fixed matrices at any subrate; particularly for the subrate of 0.3, the PSNR gain is about 0.35 dB when compared with DCT matrix, which indicates that the PCA matrix better explores the sparsity of residual due to its adaptivity to the local structures.
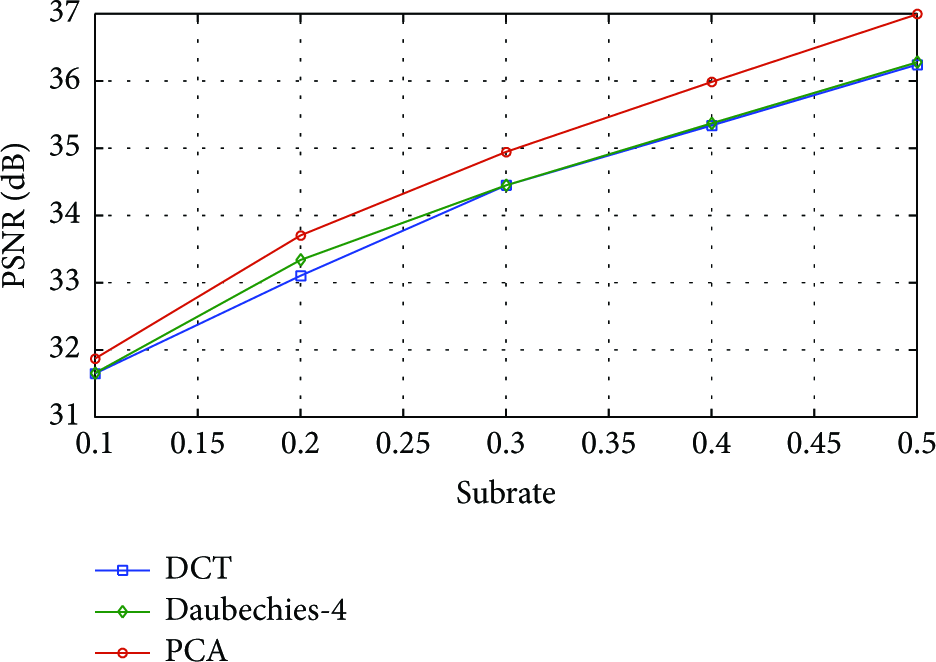
Average PSNR curves of the joint reconstruction algorithm when the residual recovery uses the different transform matrix.
5.6. Prediction Structures
In this subsection, we evaluate the decoding performance of the proposed CS-based codec under the five PSs depicted in Figure 5. The 10 GOPs of length L = 8 in each test sequence are reconstructed at the different subrates, and Figure 11 shows the average PSNR values and decoding time on all reconstructed test sequences under various PSs. It can be observed from Figure 11(a) that the PSNR value gradually rises as the number of B frames in PS increases; for example, when PS4 with all B frames is used, the PSNR gain can be up to 2.04 dB compared with PS5 without B frame. By the results of PS2 and PS3, we can see that the different predictive approaches of B frames have little impact on the reconstructed quality in a short time interval. From Figure 11(b) we can observe that PS4 requires the maximum decoding time among all PSs, and the decoding time will decrease along with reducing the number of B frames, which greatly attributes to the fact that B frame requires more computations than P frame because the former combines the previous and following reference frames to fulfill decoding task.
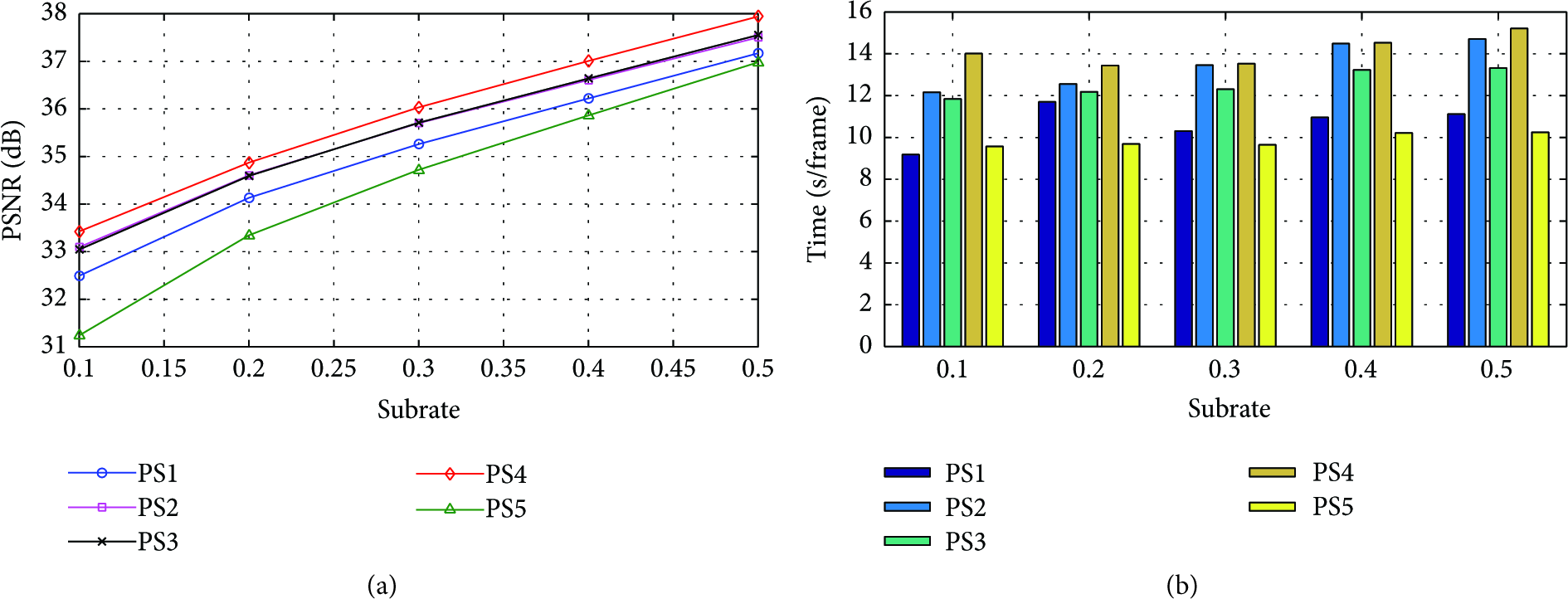
Decoding performance under various predictive structures: (a) average PSNR curves and (b) average decoding time.
5.7. Rate-Distortion Performances
The proposed joint reconstruction algorithm and other CS-based algorithms in [13, 14, 23, 24] are, respectively, applied into our CVS system, their rate-distortion curves on the CIF test sequences Foreman and Mobile are presented in Figure 12, and we can see that the CVS combined with the proposed method is superior to the most parts of bitrates compared to the one combined with the algorithms in [13, 14, 23, 24]. The superior rate-distortion performance of the proposed joint reconstruction greatly attributes to its desirable ability to generate the high-quality SI with AR prediction and thus enhance the sparsity of residual, and besides the PCA-based adaptive residual recovery also effectively corrects the errors between the SI and the original frame.

Figure 13 compares the rate-distortion performances, averaged over the first 100 frames of Foreman, Highway, and Container sequences, respectively, of the Intra coded results by the H.264/AVC JM9.5 software (H.264i), DISCOVER, the CS-KLT codec proposed by [16], and the proposed codec. For both DISCOVER and the proposed codec, the length L of GOP is set to 10, and the decoding prediction structure PS1 is used in the proposed codec. The CS-KLT codec implements ME and MC at the decoder by sparsity-aware reconstruction using interframe Karhunen-Loève Transform (KLT, which is equivalent to PCA) basis, and it exhibits the excellent performance among the existing CS-based video codecs. Note that the results of CS-KLT codec are directly taken from the order-10 decoding in [16]. From Figure 13, it is observed that the proposed codec is superior to the whole range of bitrates compared to the CS-KLT codec; for example, the highest PSNR gain can be up to 10.86 dB for Container sequence. Besides, the CS-KLT codec requires lots of computations; for example, its order-2 decoding time is about 332.81 seconds per frame on average, but our codec requires only about 10.77 seconds on average to decode one frame. It can be seen that these CS-based video codecs have inferior performance compared with H.264i and DISCOVER. For the H.264i, there are many computations to explicitly retain the information on each video frame at the encoder side, and it is easy to guarantee the efficient decoding performance with a light computational burden. With the help of the feedback channel, DISCOVER requires encoder to transmit parity bits of SI in real time when decoding each video frame, and therefore the reserved backward channel sells the decoding independence and time delay for the better rate-distortion performance. However, for the CS-based video codec, the simple encoding approach, realized by dimensionality reduction, captures implicitly all information into the measurements of each video frame, which causes the decoding to be an inverse problem, and consequently it is more difficult than H.264i and DISCOVER to improve the PSNR value as the bitrate increases.

Rate-distortion curves for H.264/AVC-Intra, DISCOVER, CS-KLT codec, and the proposed codec: (a) Foreman, (b) Highway, and (c) Container.
6. Conclusions
In this paper, we presented a CS-based video codec with a low-complexity encoder. The coding process starts by dividing the input video sequence into several GOPs. At the encoder side, each video frame in GOP is independently encoded by using block-based measuring, and then a DPCM-based nonuniform quantizer is used to quantize the resulting measurements of video frame in order to reduce the quantization errors of measurements. Finally, the Huffman encoding is used to compress the quantized measurements into bits, and these bits can be packed into a packet by a format. To fully explore the interframe correlation, a key frame with a high subrate can be inserted into each GOP, and other frames in GOP are encoded with the relatively low subrates. At the decoder side, the key frame is reconstructed by the still-image CS recovery algorithm, and it will offer a high-quality initial reference frame. For the nonkey frames, we proposed a novel joint reconstruction algorithm which consists of AR prediction and adaptive residual recovery. The AR prediction uses the local temporal correlation to accurately generate the SI of video frame, and the adaptive residual recovery learns online the PCA-based transform matrix adapting to residual structures to improve the reconstructed quality of residual. Besides, we also discuss the effects of various decoding predictive structures on the performance of joint reconstruction algorithm. Various experiments are performed to evaluate the performance of the proposed CS-based video codec from some perspectives, and their results demonstrated that the DPCM-based nonuniform quantizer used in our codec reduces effectively the quantization errors of measurements, a light computational burden is required at the encoder side of the proposed codec, and the proposed joint reconstruction algorithm has superior performance compared to many existing methods in both PSNR and visual quality. The rate-distortion performance of the proposed codec strongly outperforms that of CS-KLT video codec (one of state-of-the-art CS-based video codecs); however our codec still has the inferior performance when compared with the H.264/AVC and the DISCOVER. Therefore, in terms of future work, we will seek a more high-efficient joint reconstruction algorithm to further improve the rate-distortion performance of CS-based video codec.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China, under Grants nos. 61501393, 61202194, and 61471162, in part by Youth Sustentation Fund of Xinyang Normal University, under Grant no. 2015-QN-043, in part by the Key Scientific Research Project of Colleges and Universities in Henan Province of China, under Grant no. 15A520026, and in part by the Technology Research Program of Henan Provincial Department of Education (no. 12A520035).