
Abstract
A major fraction of multimedia stream contents tends to be redundant and leads to wastage of storage capacity and channel bandwidth. In order to eliminate surplus data, standard video compression algorithms exploit spatial and temporal correlation present in video sequence. However, in case of a multisensor network, intersensor statistical redundancy is the most significant factor in acquiring efficient link utilization as well as making resultant findings valuable to the end user. In this paper, an extension to our previously proposed scheme has been presented to accomplish performance goals of a multisensor environment. Standard MPEG codec has been used to accomplish distributed motion compensation in prespecified directions known as directional correlation. Video frame correlation has been estimated locally at the camera node as well as across different nodes, defined as node communication strategies. Further, receiver feedback assists in quality control after reconstitution by decoder assessment. Results estimated have been analyzed for saving ratios and multimedia quality. Results analysis illustrates increased gains in frame quality and compression saving, achieved through reducing node displacement from the reference node
1. Introduction
In recent era of deploying multimedia applications in distributed environment, advancements have been made in video compression algorithms to attain high transmission rates. Multimedia data constitutes rich audio and video patterns extensively redundant with useless repetitions. A digital video is a sequence of frames, normally presented at regular time interval so that human eye can perceive fluid motion. Each individual frame is an image with basic element called a pixel. A digital image is obtained by quantizing a continuous image in a two-dimensional frame.
Further, involving a third temporal dimension to a two-dimensional digital image t that denotes time gives a frame sequence as shown in the following:

Digitization of the spatial coordinates and of the amplitude called image sampling and gray-level quantization, respectively, results in high spatial and temporal correlation (spatio-temporal sampling). Encoding of these similarities is further carried out by registering the differences within a frame (spatial) and between frames (temporal). Spatial encoding is performed by exploiting the fact that the human eye is unable to distinguish fractional color differences than changes in brightness. Correspondingly, temporal compression takes into account the change in the pixel value from one frame to the next based on the interframe resemblance. At the root level, compression is carried out when an input video stream is analyzed from the viewer perspective and useless information is discarded. Bit codes are assigned to various video events; more frequent events are assigned; short length codes and long codes are associated with rare occurrences. The processing steps of signal analysis, quantization, and variable length encoding are collectively called video compression. Deploying video compression in a multisensor network is a critical task; sensor nodes require enormous care to design an optimum performance methodology due to inherent limitations of these tiny, energy constrained nodes. In a video sensor network, huge amount of multimedia data from large number of terminals requires significant link bandwidth. Normally, a video compression algorithm deployed on each video sensor independently; it involves eradication of temporal as well as spatial redundancy from each video sequence. However this still possesses great repetition due to intersequence statistical redundancy among the data load coming from different video sensor nodes. Eliminating this repetition leads to improved compression efficiency as well as link saving. Likewise efficiency is further assured by keeping the communication among the video sensor nodes at minimum.
The concept of distributed source coding (DSC) has been deployed in a number of ways to resolve performance issues of multisensor setup. In DSC, encoders are designed to be simple and fast, while a central decoder is deployed as an entity strong enough to do fast and efficient joint decoding. This encoder-decoder complexity encapsulation is the major essence of DSC concept. Previously, we proposed an idea as a blend of DSC methodology and an extension of a standard video codec MPEG for a multiterminal environment [1]. For experimentation purposes, a multicamera setup was deployed where camera sensor nodes in a wireless network were allowed to interact at different levels (communication strategies 1 and 2). In strategy 1, minimal interaction among the sensor nodes was allowed, while sensor nodes were allowed to interact more in strategy 2. These communication strategies were meant to exploit the frame temporal correlation. Communication strategy 1 was supported with maximum link saving and optimum reconstructed video quality.
In this paper, node interaction strategy 1 has been embedded with decoder feedback to further enhance video picture quality after being reconstituted. Receiver has been functionalized to assist in statistical quality estimation which is fed back to encoder to readjust the correlation as well as camera displacement parameters. This modification to the basic idea better achieves the performance objectives of a multiterminal environment, since node communication strategy 1 assures the minimum node interaction that reduces the power consumption and link saving is achieved. Moreover, improved video quality is another accomplishment that magnifies the algorithm productivity at lower bitrates.
This paper is organized as follows. Section 2 summarizes the related work and Section 3 provides theoretical background. The proposed methodology and results are discussed in Sections 3 and 4, respectively. Finally Section 5 concludes the idea with identification of future research directions.
2. Related Work
Domain of multiterminal video compression has remained a foremost target for research contributions.
About three decades ago, Slepian and Wolf introduced the idea of DSC with its practical limitations identified [2]. Later on, researchers made valuable additions to the basic idea through extensive experimentations in this domain. A number of practices are proposed to tackle various design issues of multiterminal video compression using DSC approach. In some methodologies [3–5], each encoder independently deploys the DSC approach to utilize temporal correlation for a single video sequence only. Such encoder designed is simple enough to get better error resilience. Likewise, some researchers suggest the scheme of image resolution to take advantage of intersensor statistical redundancy [6]. Images are encoded at low resolution while superresolution methodologies are used for reconstruction. However, estimating correlation between low resolution images results in the lowest coding gains that can better be achieved through deploying the theory of multiterminal source coding [2, 7, 8].
Other methodologies define multiterminal setup with some limitations on various settings of multisensor objects like camera; for instance, cameras are bound to be located along a horizontal line and field objects are assumed to be within some defined camera range. Others [9, 10] have defined a lower bound on a number of cameras for some video scene reconstruction. Some have considered camera sensors to be mounted to specific locations to compute correlation among sensors findings [11]. Researchers have also worked out the mathematical models for depth estimation at decoder ends. In [12], the idea of depth estimation has been proposed to compute correlation among camera sensor views. An approach based on Whyner-Ziv coding has encapsulated the concept of DSC as a simple and fast encoder is coupled with a computationally complex decoder [13]. This scheme has made use of image based rendering applications but has ignored the factor of camera position correspondence. Further, feedback approach has also been proven much productive in eliminating internode redundancy [14]. In such feedback approach, central decoder is designed to provide feedback to one of the encoders.
One of the remarkable contributions is the concept of MTVC (multiterminal video coding) [15, 16]. Numbers of ideas have been associated with this scheme; in their pioneer work, the idea of epipolar geometry has been applied to get node correlation. Subsequently, model-based approach has been recommended to estimate corresponding points of two node findings [17]. They have defined an MTVC framework which shows high performance gains at low bitrates. A remarkable effort is MATLAB simulation of epipolar geometry [18] that can better be utilized to compute epipolar lines and camera premises. One of the recent ideas proposed is the multiterminal video coding with the help of low-resolution depth camera [19]. Though it is a fresh idea, it acquires low performance gains.
Yang et al. presented their idea of two terminal video coding [20]. It exhibits multiterminal source coding of two correlated video sequences to save the sum rate over independent coding of both sequences. Previously, we have proposed a framework for multiterminal video coding by adapting standard video codecs [1]. That piece of work involves the idea of motion compensation among the data findings of different network nodes that resulted in irredundant data stream that was further compressed to achieve high compression ratios. The idea in this paper is the modification to one of the interaction strategies proposed earlier that has shown the optimum performance in the last experimentation supported through high quality gains and extensive link saving.
3. Proposed Methodology
The major essence of the DSC lies in the design of low complexity simple encoders deployed independently at each video sensor node (VSNo) and a computationally intense and complex decoder sufficient to make joint decoding of commutative bit stream coming out of a video sensor network (VSN). The list of performance constraints for a VSN nominates the lesser communication among the VSNos to be of most significance. The idea that we proposed earlier [1] introduced two ways of VSNo intercommunication. One of these has been proven to involve lesser interaction among VSNos to attain lower power consumption as well as better media quality. Such idea of minimum collaboration among VSNos has been extended in this paper with some modifications embedded in system core functionalities as well as an innovation of receiver feedback introduced.
3.1. Node Interaction Strategy
Being the better interaction scheme with valuable outcomes, communication strategy 1 has been chosen for further extension. The scheme describes VSNo interaction in a way that one node is initialized as the reference node

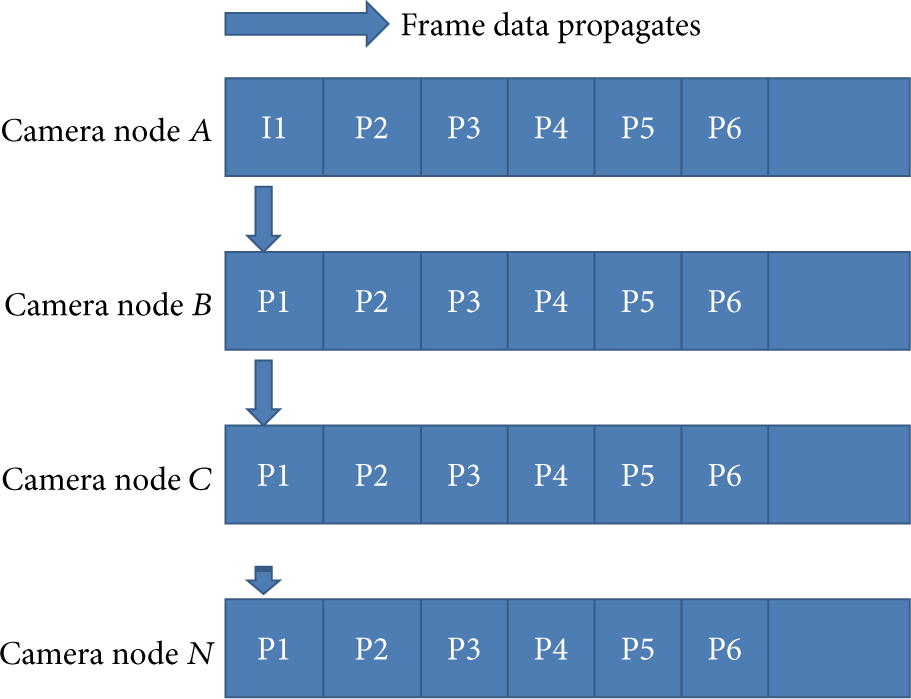
Node interaction strategy 1. Nodes exchange data of I-frames only.
3.2. Directional Correlation
Deploying the idea of multiterminal video coding through MPEG extension involves distributed motion compensation to compute internode correspondence among the dispersed camera nodes. This idea has been used to avail the benefits of nodes correlation as a function of their angle of vision (AOV) with respect to the scene captured.
The idea of directional correlation (DiC) elaborates the fact that higher degree of correlation is seen among the camera nodes placed in a specific frame of reference capturing the scene at a particular AOV. The mechanism of DiC begins with selection of a node as a reference node
While testing the idea of DiC, we use a camera grid, with each camera node placed at a precomputed displacement from
Figure 2 presents the algorithm processing steps. Encoder layer transmits the cumulative bit stream to central decoder for efficient decoding that assists in quality control through feedback loop. A multiterminal domain has been modeled as a collection of camera nodes facing a subject/scene at a specific AOV.

Algorithm processing steps describe distributed source coding implementation with individual system components interacting to process multiterminal video results.
3.3. Receiver Feedback Mechanism
Following the concept of DSC, all the encoder nodes encode their video sequences (locally) separately in accordance with internode communication whereas a single central decoder is designed for joint decoding of the cumulative bit stream on receiver end. This central decoder is functionally equipped with efficient decoding as well as quality estimation tool in order to maintain an optimum quality level for better reconstruction.
Frame quality is assessed against a threshold quality level, computed as peak signal to noise ratio (PSNR) given as the ratio of original source signal power to the power of noise induced. Quality levels laying on the threshold edge and below are reported to encoder layer on transmitter end to restore fluctuations. Encoder layer instantly responds to this feedback event through varying the nodes displacements with respect to
Decoder feedback events are categorized as severe quality alarms and slight alarm characterized by statistical measure of reconstructed video quality. Severe alarms are medicated through varying the angle of displacement where video sequences are captured for the new node position, acknowledged through decoder notification of quality improvement. Slight quality degradation may protrude as a result of channel noise or some missed frame while capturing. These quality alarms may well be eliminated through refreshing the reference information for current video interval; that is, instead of sending frame differences only, video frames are intracoded.
Besides, block matching algorithms (BMAs) parameters may undergo reconfiguration to pinpoint the finer details of distributed video frames. For instance, macroblock size is reduced to assure better matching and search space is broadened to facilitate exhaustive search for the best matching candidate block.
4. Experimental Results and Discussion
A variety of experiments have been conducted for in-depth assessment of proposed algorithm. Efficacy of the algorithm is analyzed through compression metrics like saving ratio (compression percentage, CP) and objective quality measures like mean squared error (MSE), PSNR, and so forth. PSNR is an objective quality metric used to measure the quality of reconstructed video frame. Higher values indicate better quality. It is computed via MSE, for instance, for two
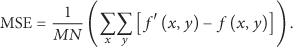
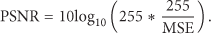

4.1. Data Set
Data set used in the experimentation exhibits a variety in background and foreground contents variation. Algorithm is fed with real time captured video samples reflecting stationary multiview images as well as image sequences with high motion contents. A subject face sequence was captured by three camera nodes implanted at variable displacements from the preselected
Video sequences captured were categorized in accordance with ascending the internode displacement, shown in graphical results identified through various threshold relations. Besides, camera nodes are also positioned to capture the scene with moving objects and stationary images from different AOVs. In other video samples, subjects were told to gesture slightly with moving hands to create minor variations in frame contents and vice versa.
4.2. Experimental Setup
Camera nodes are made to capture subject face sequences to assess performance of the proposed algorithm against finer details detection. Experimental setup comprises a grid of camera nodes, entrenched in a way such that each node is capturing the video scene with various AOVs characterized by certain parametric displacements from the reference point.
4.2.1. Reconstructed Video Quality
To evaluate the mechanism of DiC, face sequences are primarily chosen as the video samples. Figure 3 shows the video quality gain measured with respect to the camera node displacements from the
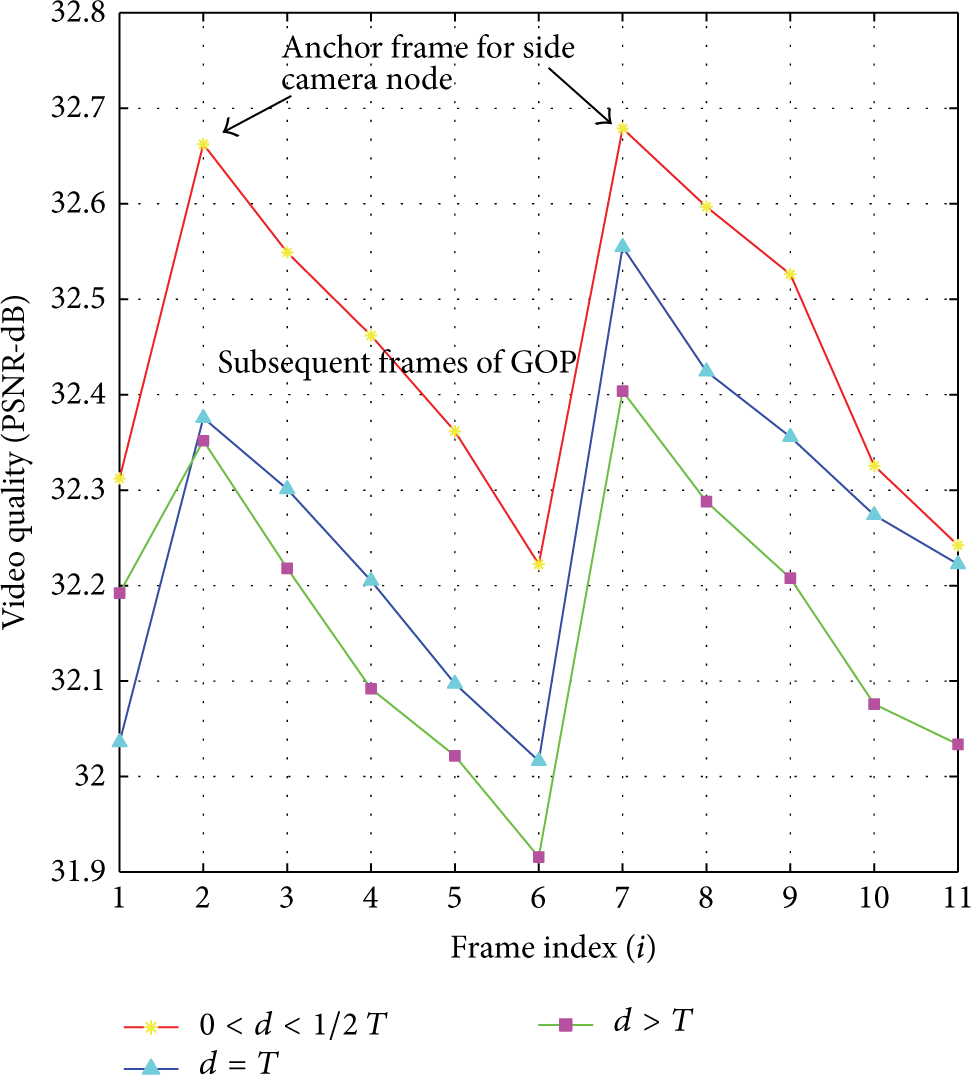
Quality of reconstructed video sequences for various node displacements (d) in accordance with maximum possible displacement for acceptable video quality (T).
Typical saw-tooth formation of the quality curve is apparent for sample video sequence. It is a snapshot of quality estimates for two GOPs of right camera node video sequence.
It indicates that, with the beginning of a GOP, first frame undergoes motion estimation using reference information from the
Figure 4 further demonstrates the visual quality of a face video sequence. It assesses the algorithm capabilities for detecting finer details in video picture with high degree of correlation available.

Video frames compared for visual perception with statistical quality estimation. The top row shows original frames and the bottom one represents reconstructed format.
4.2.2. Compression Saving Estimation
In this experiment, again camera nodes are placed at certain distances from the
We have constructed a three-terminal video setup in a way that two camera nodes were implanted at certain positions relative to the fixed
Saving ratio comparison.
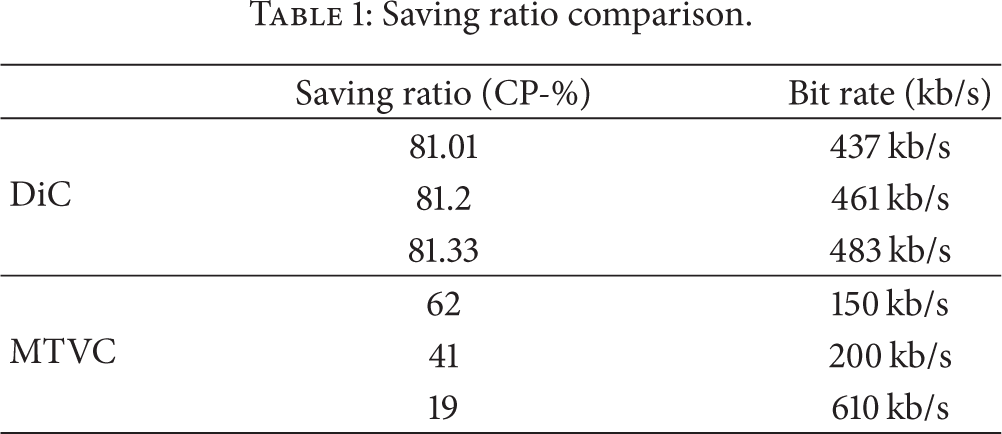

Comparative analysis of saving ratio versus node displacements.
MTVC results for 15-degree separation version are shown. According to Table 1, MTVC shows comparatively better saving at lower bit rates but it sharply drops at higher bit rates like 19% at 610 kb/s. For DiC results, three different camera positions are assessed and exhibit remarkable link saving. It can be seen that saving ratio tends to increase for closer camera positions but at the cost of network commodities (nodes closely spaced). Numerical values shown are average values for two GOPs. Here, sharp variations in CP for different camera displacements are not seen. Except the first frame of a GOP that is compensated through
4.2.3. Correlation Parameter Tradeoffs
To attain improved link savings, video frames of each side of VSNo are correlated with

Frame distortion as a function of macroblock size.
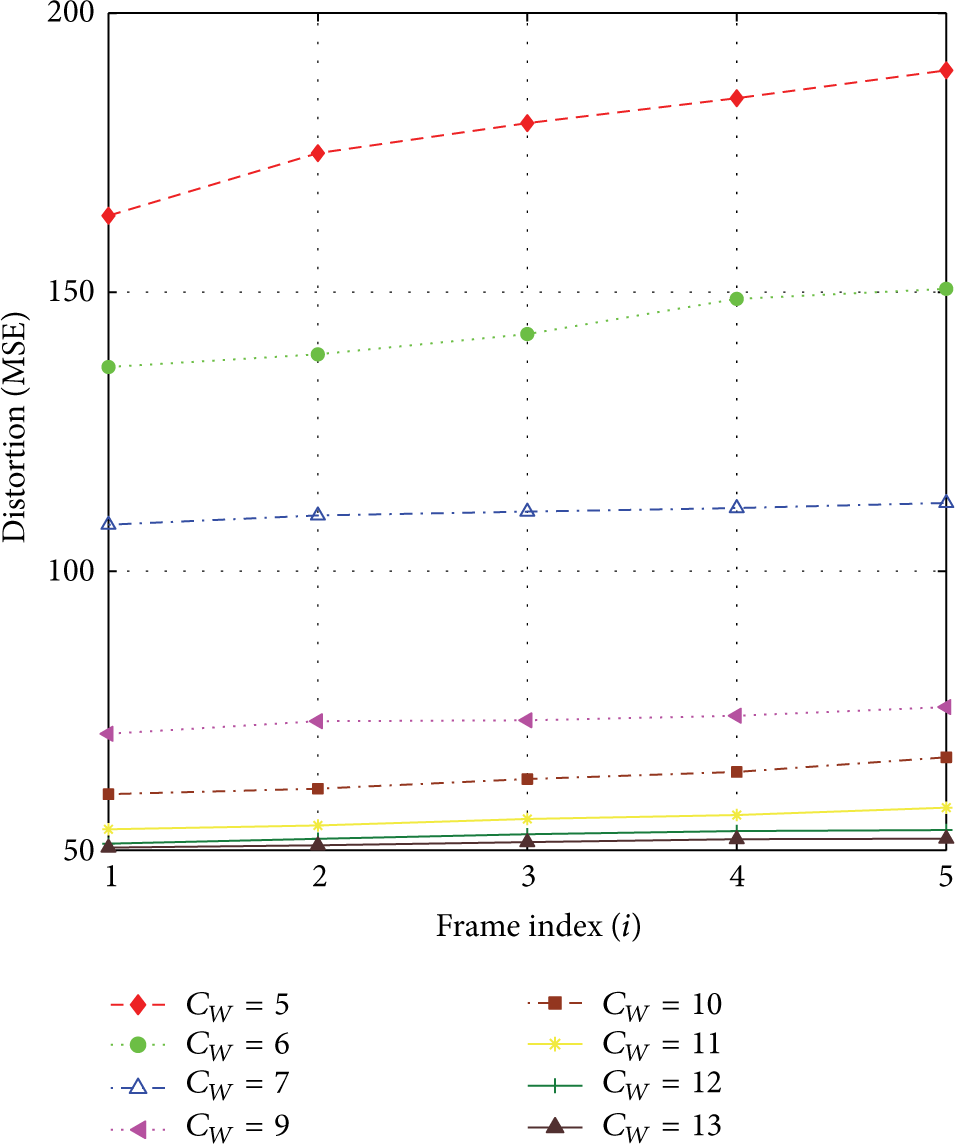
Frame distortion as a function of search space size.
Minimum distortion and better quality reconstruction are only possible with smaller block size but they add to computational cost. Analysis of search space size sets a threshold at higher
5. Conclusion and Future Work
Video processing in multiterminal domain has remained a food for thought for researchers. Various ideas have been proposed for focusing on different performance areas of video processing in distributed domain. One of these ideas is the implementation of standard MPEG codec in multicamera setup that we proposed previously, where nodes correspondence is computed through distributed motion estimation techniques. Idea proposed in this paper is based on MPEG implementation with new concepts of DiC and receiver feedback mechanism supported through extensive experimentations. Experimental outcomes reveal that DiC assures better quality and link saving. Moreover, receiver feedback assists in timely parameter adjustment for ultimate quality enhancement.
Footnotes
Conflict of Interests
The authors declare that they have no conflict of interests regarding the publication of this paper.