
Abstract
The paper addresses the problem of improving the accuracy of the measurements collected by a sensor network, where simplicity and cost-effectiveness are of utmost importance. An adaptive Bayesian approach is proposed to this aim, which allows improving the accuracy of the delivered estimates with no significant increase in computational complexity. Remarkably, the resulting cooperative algorithm does not require prior knowledge of the (hyper)parameters and is able to provide a “denoised” version of the monitored field without losing accuracy in detecting extreme (less frequent) values, which can be very important for a number of applications. A novel performance metric is also introduced to suitably quantify the capability to both reduce the measurement error and retain highly-informative characteristics at the same time. The performance assessment shows that the proposed approach is superior to a low-complexity competitor that implements a conventional filtering approach.
1. Introduction and Motivations
In the last years, sensor networks have started to be deployed for an increasing number of different applications [1]. The availability of low-cost commercial off-the-shelf nodes, fostered by significant advances in wireless communication technologies and size scaling of integrated circuits, has enabled the deployment of small low-cost sensor nodes with increased lifetime [2]. Typical applications are sensing/estimation of some parameters [3, 4] such as temperature, pollution level [5], electromagnetic exposure [6, 7], or field reconstruction [8, 9]. Such problems are particularly important in environmental monitoring [10], ecology [11], meteorology, agriculture, and related fields as reported in a number of case studies [12, 13]; see also [14] and references therein. More in general, sensing capabilities are currently regarded as a key enabler for smart applications in contexts as diverse as transportation systems [15–17], cyber-physical systems [18–20], and ad hoc networks [21] and in (opportunistic) applications like position estimation for location awareness [22–25]. Finally, interconnection of standalone systems can lead to advanced sensing capabilities, for example, in radar applications [26].
Both centralized and distributed approaches can be adopted to process the information collected through a sensor network [27]. In the centralized approach, data are sent to a fusion center (FC) performing the whole computation [28], while in the distributed one neighboring nodes cooperate in a peer-to-peer fashion until convergence [29, 30]. Regardless of implementation aspects, the goal can be formalized as an inference problem, based on sensor observations, about an underlying physical phenomenon. Clearly, observations are affected by errors introduced in the sensing/measurement process, for instance, due to thermal noise, atmospheric effects, and residual sensor calibration errors. This is especially true when data are collected through general-purpose devices, even smartphones, [31] instead of dedicated (expensive) sophisticated sensors. Therefore, techniques aimed at improving the accuracy of sensor measurements are highly desirable [32, 33].
Unfortunately, a peculiarity of sensor networks is that each sensor has quite limited power supply and computation capabilities; since advanced processing techniques cannot be often implemented with reduced effort, novel low-complexity approaches are needed to actually make sensor network applications feasible in most real-world contexts. As a matter of fact, systems designed to be effectively deployable have to face a number of practical difficulties; thus things are kept as simple and cheap as possible; this, however, may negatively have an impact on the final accuracy [12, 34]. In particular, a coarse granularity may be reported on reconstructed sensing maps, with resulting sharp edges between contiguous levels (as, e.g., in [16]). In other cases, values are averaged [5] or, if their spatial distribution is of concern, smoothed via suitable low-pass filters [35]. A simple moving average is often used in practice, which can be easily implemented as a correlation with a weight mask through a sliding window approach.
In this work, we propose a low-complexity Bayesian approach for improving the accuracy of the measurements, so that a more reliable value of the monitored field is obtained without the need for a sophisticated processing. We will show that, with other things being equal, few lines of code can be effective to improve the final accuracy if the information coming from other sensors is exploited in a cooperative way. The advantage of this approach is that the “filtering” procedure takes into account the statistical relationships in the data at hand. We consider a quite general observation model, where the measurement error is modeled through a Gaussian law. The latter is a versatile model for measurement errors and other random effects [36], supported by the central limit theorem (CLT). A Bayesian approach is used to estimate the value of the field by minimizing the mean squared error at each monitoring point. Different from conventional Bayesian techniques, which require full prior knowledge of the data distribution, we follow an Empirical Bayes approach [37], where the parameters of the prior (hyperparameters) are unknown. We derive their Maximum Likelihood (ML) estimator and show that it has a simple closed form amenable to practical implementation in low-cost devices. An application to spatial field monitoring and reconstruction is reported to highlight the performance improvement compared to a conventional “denoising” technique based on low-pass two-dimensional filtering (moving average).
The rest of the paper is organized as follows. In Section 2, we formulate the problem within the reference scenario. Then, in Section 3, we introduce the proposed filtering approach, which includes the derivation of the Minimum Mean Square Error (MMSE) estimator of the field and the Maximum Likelihood (ML) estimator of the hyperparemters. Besides the mathematical derivation, we provide also a scheme (and the corresponding algorithm's pseudocode) for practical application. In Section 4, we evaluate the proposed approach, showing that it can improve the estimation accuracy without significantly increasing the complexity. To better spotlight the ability to represent correctly specific characteristics of the monitored field, a novel metric is preliminarily introduced. Finally, Section 5 contains the conclusions of the work.
2. Problem Formulation
A general scenario is considered, where N sensor nodes observe a given phenomenon. We denote by


Reference scenario of a monitoring sensor network.
One can exploit the fact that sensors are deployed over a “continuous” field for monitoring purposes; hence, they measure a variable which represents a “sampling” of the underlying whole process. As a consequence, some correlation can be expected according to the spatial proximity (distance) between sensors. However, correlations are difficult to model exactly, since they require deep knowledge of the process at hand. Moreover, they are very site-specific and change with time. Complicated models, if available, require in turn computational-intensive techniques; conversely, as mentioned, simple approaches are needed in low-cost sensor networks.
To this aim, we propose modelling the relationships between the sensed points of the field by means of a prior distribution on the measurements with unknown hyperparameters. In particular, given the Gaussian model for

3. Empirical Bayes-Based Measurement Filtering
3.1. Minimum Mean Square Error Field Estimation
The conditional distribution of








Given the result above, the MMSE is obtained in a simple closed form as

3.2. Maximum Likelihood Hyperparameter Estimation
The joint probability distribution of the sensor measurements is obtained from (10) as
It is easy to verify that the expression between square brackets above is simplified as

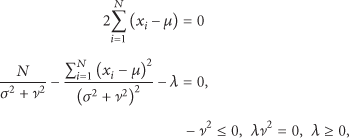




3.3. Practical Application of the Algorithm
The approach developed above can be applied in a straightforward way to a monitoring network deployed in a given area. A schematic representation is depicted in Figure 2, which details the scheme of Figure 1. Some of the nodes are exploded to indicate the local processing, which can be summarized as a function f of the local measurement and of the “state”


Schematic representation of the proposed estimation approach.
It is reasonable to expect that, except for small-area networks, nodes may not be able to communicate in a completely meshed way, but rather they have limited connectivity dictated by their communication range. For each node i, we can define the set of neighbors
Summing up, despite the lenghty calculation in Sections 3.1 and 3.2 (necessary for a rigorous derivation), the result is very handy and can be easily implemented in a few lines of code for a generic cluster as follows.
Pseudocode of the Proposed Algorithm
4. Performance Assessment
In this section, we show how the proposed approach can be used to improve the accuracy of a sensor network without significantly increasing the computational cost. We resort to simulations to control the ground truth; that is, we simulate the true value of the field (of some physical quantity, namely, temperature) plus additive noise that models measurement errors. Performance are assessed as function of the power of the noise, that is, the variance
4.1. A Novel Metric for Accuracy Evaluation
In order to reduce the error introduced in the measurement process, a smoothing filter is typically used. However, simple approaches actually used in real networks just rely on techniques that ignore the statistical properties of the data; in particular, data are often processed through a sliding window where measurements are low-pass filtered to reduce the disturbance, similarly to a basic image denoising algorithm. Although this approach provides reasonable results on average, it may negatively have an impact on the values that deviate from the mean. The latter are conversely the most interesting data in a number of monitoring applications, for instance, to detect extreme events. As a result, it is important to measure the ability of a smoothing approach to retain the low-probability characteristics of the monitored field.
On the other hand, an algorithm that focuses too much on extreme events tends to lose its ability to “denoise” areas where the field is almost stationary, that is, plateaux with very similar values that fluctuate just because of the intrinsic uncertainty introduced by the measurement process. To correctly evaluate the overall performance, thus, it is necessary that the performance metric takes into account both these conflicting objectives, that is, ability to retain low-probability values and ability to simultaneously ensure a satisfactory smoothing.
To this aim, in the following, we propose a novel compound metric based on a weighted version of the Frobenius norm. More precisely, denoting by

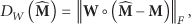
Based on the two metrics above, we propose the following compound metric:

The definition in (25) can be rewritten as the product of the distance between the real field and the reconstructed one in both the original and the transformed (weighted) spaces:
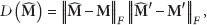
In Figure 3(a), we show a clarifying example: the true values of the field

Example of monitoring application scenario: (a) ground truth (matrix
We have applied the proposed Empirical Bayes approach to a sensor network deployed on the field shown in Figure 3(a). Following the cluster-based approach described above, we have run the algorithm on the noisy version resulting from the measurement process as function of the noise level
As mentioned, as competitor, we consider the conventional moving-average filter, which is a typical smoothing (“denoising”) technique, to improve the quality of sensed images [39]. Such an algorithm uses a spatial mask centered in each location
The result of the filtering for the case of Figure 3(c), which is related to

Result comparison for the proposed algorithm versus the moving average,

Values of γ for the different points of the field,
4.2. Numerical Results
It is worth noticing that the proposed Empirical Bayes approach leads to a better value of D, but it is also superior on
By increasing the noise level, it turns out that the proposed algorithm still outperforms the competitor and, furthermore, remains able to retain the highly informative (low-probability) values while ensuring a satisfactory smoothing of the noise. Results for

Result comparison for the proposed algorithm versus the moving average,

Values of γ for the different points of the field,
To investigate more thoroughly this point, we have evaluated how D varies with
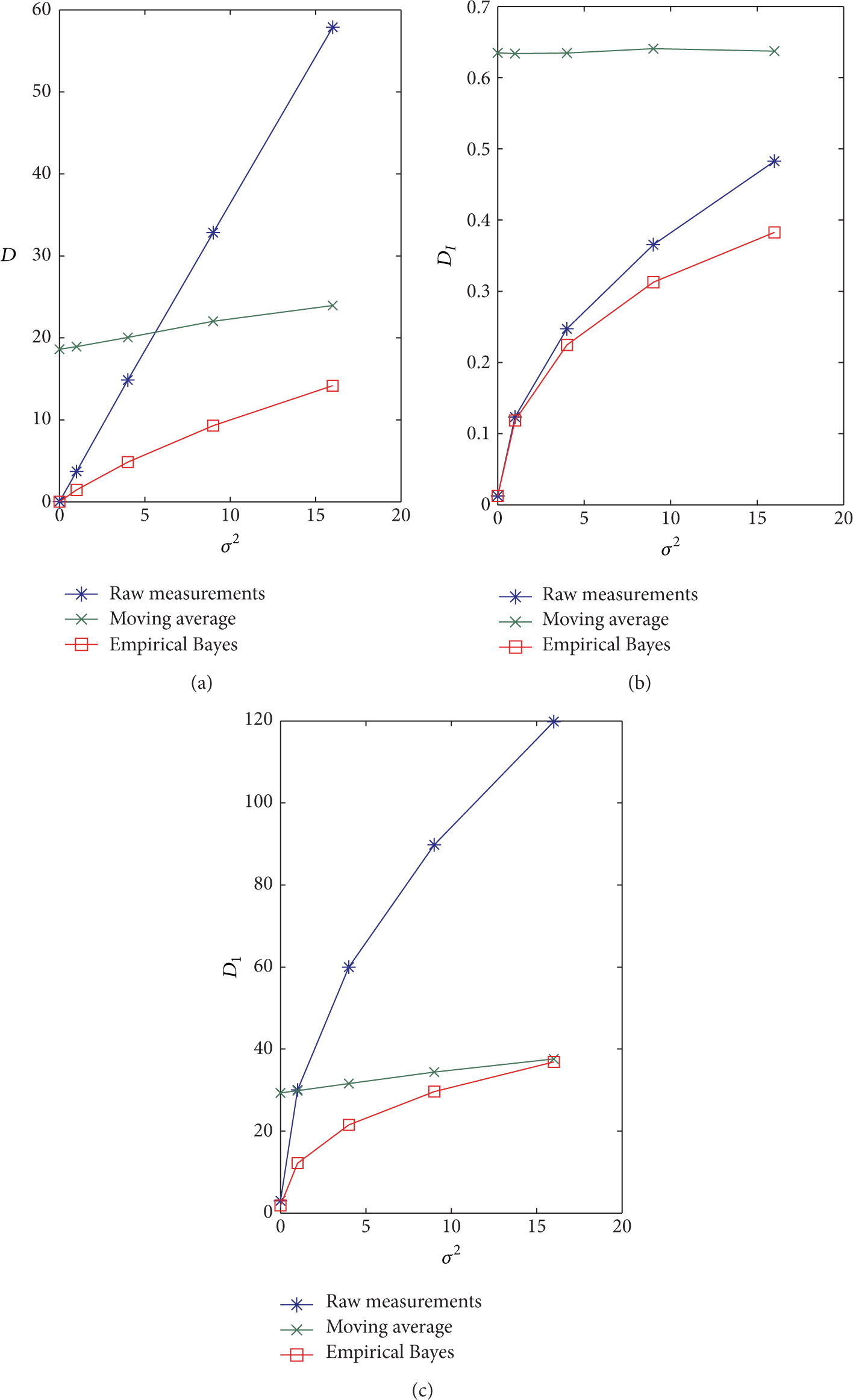
Comparison between the raw measurements, proposed Empirical Bayes algorithm, and the competitor algorithm (moving average): from (a) to (c), the metrics D,
Finally, the case of multiple “hot spots,” that is, multiple sources of far-from-average spikes is analyzed in Figure 9. In addition to the already observed properties of the proposed approach, which remain valid, here an additional feature can be observed in terms of resilience to masquerading effects. Indeed, when multiple sources of far-from-average events are present, conventional filtering techniques like the moving average do not have enough resolution power even for moderate noise level. This is due to the averaging of points in spatial proximity, so that sources not sufficiently separated become indistinguishable and collapse onto a same blurred blob (as in the top right corner of the field in Figure 9). Conversely, the proposed approach is able to detect all sources and also to maintain the proportionality in their intensity while ensuring denoising.
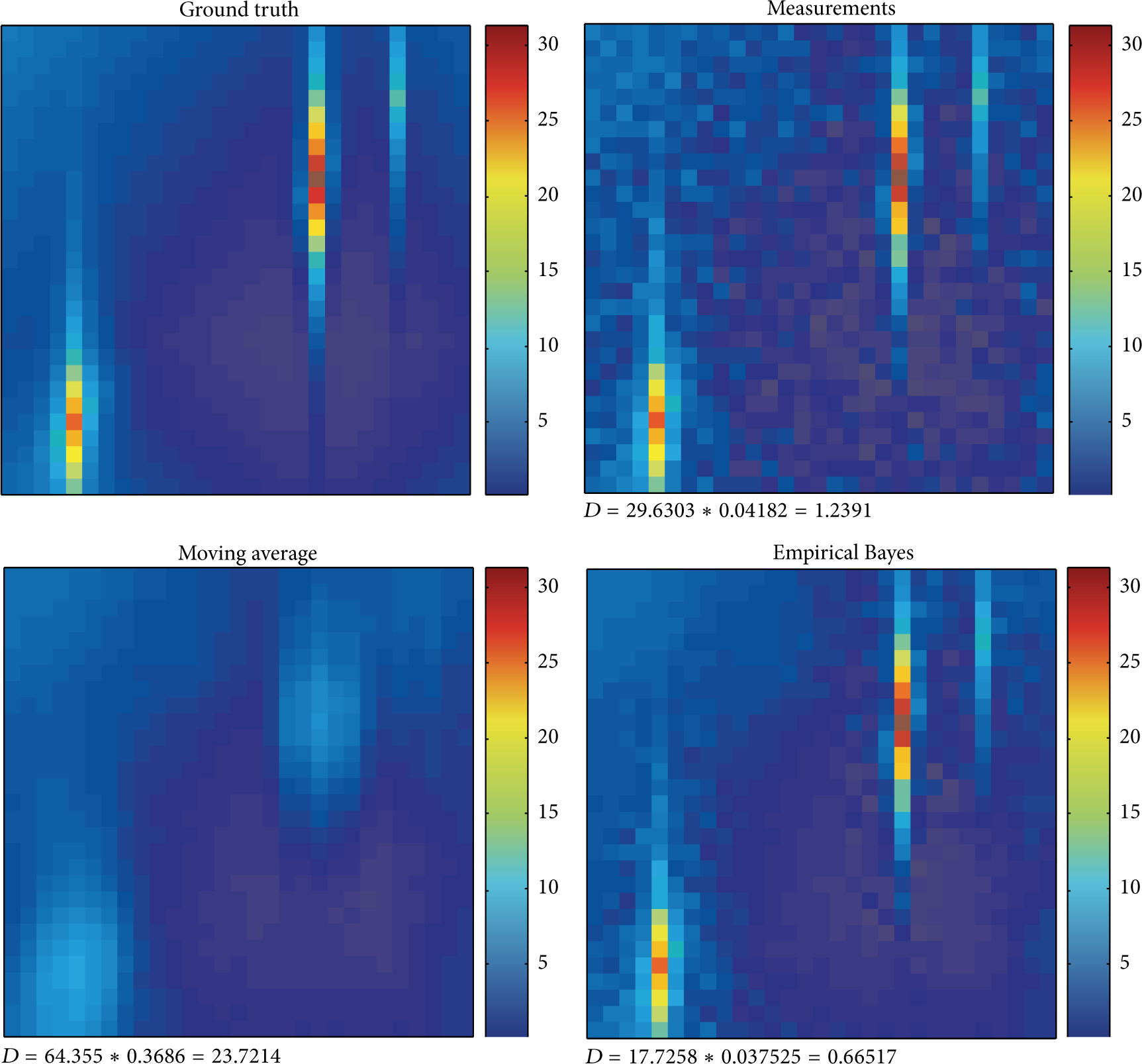
Result comparison for the proposed algorithm versus the moving average in case of multiple far-from-average events,
5. Conclusions
The problem of improving the accuracy of the measurements collected by a sensor network has been addressed. Aiming at simplicity and cost-effectiveness, which are of utmost importance in application contexts, where sensor networks are often deployed, a low-complexity automatic approach has been proposed, which does not require manual setting of parameters nor recalibration. By following an adaptive (Empirical Bayes) rationale, the algorithm is able to improve the estimation accuracy by leveraging cooperation between nodes. Remarkably, it can provide a “denoised” version of the monitored field without losing accuracy in detecting less probable values. Using a novel performance metric, the capability to both reduce the measurement error and retain highly informative characteristics has been quantified, revealing that the proposed approach can outperform conventional low-pass filtering.
Footnotes
Conflict of Interests
The author declares that there is no conflict of interests regarding the publication of this paper.