
Abstract
This paper introduces a consensus routing algorithm based on an availability function. Such a function obtains a consensus among a group of nodes by evaluating the idle time in the scheduler of each node, along with the general conditions of the network and determining the next step of the route. In this regard, the algorithm proposed here makes it possible to avoid flooding while reducing bandwidth use and keeping changes of the network only at a local scale.
1. Introduction
A Mobile Distributed System (MDS) is composed of some wireless devices, acting as nodes. Each node exposes not only a relative position with the rest of the mobile devices, but also a state, and it may act as a router: in a MDS, each node communicates with its neighbours not only as a sender or receiver, but also as a router, forwarding packets to nodes that are not within the transmission range of the sender [1].
Commonly, a MDS is described as a dynamic topology since it changes with the movement, entry, and exit of nodes within the range of the MDS. Such a dynamic behaviour makes it difficult to establish and maintain a communication route between two remote nodes, since all the nodes of such a route may not be available for routing at a later time. Traditional routing algorithms are not useful here, since they require knowledge about the network as a whole in order to determine any optimal route. Using a route discovery algorithm every time the topology changes requires constantly generating a global state of the MDS.
For performance purposes regarding the transmission of messages, routing algorithms need to be bandwidth efficient, spend as few resources as possible in the computation of a route, and reconcile conflicting goals such as dynamic adaptation and low resource consumption [2]. Routing algorithms are commonly described as part of routing protocols.
2. Related Work
There are studies about routing protocols in wireless networks, showing that these protocols can be classified into five main types: reactive, proactive, hybrid, hierarchical, and based on coordinates.
Reactive protocols perform on-demand route discovery by flooding the network and delaying packets until the routes are established. Examples of these protocols are [3], DSR [4], and TORA [5].
Proactive protocols maintain routes between all pairs of nodes. The network is flooded with information packets whenever there are changes in the topology but does not incur delays or overhead to display cover routes on demand. DSDV [6], OLSR [7], and WRP [8] are examples of proactive protocols. In general, proactive protocols present a good performance in static scenarios, while reactive protocols do so in mobile scenarios.
Whether reactive or proactive, in both types of protocols, flooding means that every node in the MDS sends all incoming packets to its neighbourhood, except those packets that must receive. Flooding is easy to implement. Nevertheless, it represents a brute force approach. Furthermore, it is inefficient in the sense that it tends to exponentially increase traffic until consuming all bandwidth of communication channels. Since flooding consumes a substantial amount of bandwidth, it is important to reduce the frequency of route discoveries and so network flooding [1].
Hybrid protocols have been proposed to overcome performance problems due to frequent route discovery attempts in on-demand routing protocols. These routing protocols incorporate both proactive and on-demand protocol features [9]. However, for each route request hybrid protocols do not wide-flood the network. It is difficult to balance between the cost of periodically exchanging route information (i.e., proactivity) and route discovery by controlled network flooding (i.e., reactivity) [10]. Other protocols such a geographical or bypass routing reduce the frequency of flooding by allowing a relay node to start a limited route discovery in the event of a route failure [3, 11], or employ local error recovery mechanisms [12, 13]. Hybrid protocols using either controlled flooding or local error recovery have focused on reducing packet drops and not efficiently using bandwidth during route recovery. However, multipath protocols require additional packet drops and delays due to the dependency on potentially stale routes from caches [1]. Hybrid protocols such as ZRP [14] and SHARP [10] achieve good performance across a wider range of scenarios by combining both reactive and proactive components. They divide the network into zones. Nodes maintain routes proactively within their zone by flooding topology changes within the zone. Routes between zones are discovered on demand with an optimised flooding mechanism [15].
Hierarchical and coordinate-based protocols do not flood the network. They use location-dependent addresses in routing. These identifiers can change with mobility and, in some protocols, with congestion and failures [16–18]. Therefore, these protocols use both a fixed identifier and a location-dependent address for each node and they usually require mechanisms to look up the location of a node given its fixed identifier [19]. These mechanisms reduce resilience to failures, introduce overhead, and increase complexity [15]. For example, LANMAR [17] and L+ [16] are hierarchical protocols, and GPSR [20] and BVR [18] are coordinate-based protocols.
Protocol VRR [15] combines aspects of proactive routing, establishing and maintaining routes without flood routing by combining the use of a logical ring and a physical map. VRR uses a scheme to identify nodes by a random number between 0 and a finite upper limit. This implies the need to have a mechanism for consensus to assign numbers to each node or the existence of a centralised node that is responsible for global identifiers. This restricts the scalability of the protocol.
Routing algorithms for ad hoc networks, such as AODV [3], TORA [5], and OLSR [7], are not useful to solve the problem of calculating a route between a pair of nodes without having a global state, since these algorithms do not take into consideration the status of the local scheduler within each node. Wormhole [21] and vector-based distance and link state [22, 23] algorithms cannot be used here, since they reserve a channel and keep it, but due to the dynamic topology, they do not seem to be a time-efficient option for route construction [24–28].
The WARP algorithm [29] focuses on repairing paths. WARP is reactive and is based on distance vector and detects when the position of the destination node has changed and it makes a spiral search engine around the old position, thus seeking a neighbour node that still maintains communication with the destination node. This algorithm requires a vector distance, which could be inconsistent.
Researches have developed consensus mechanisms for routing protocols. For example, in [30], the authors separate the delivery of the package into two different logical modes: a stable mode, which ensures that the route is selected only after arriving at an agreement that is reached by a state consisting of a global view, and a transient mode, which ensures high availability when a package finds a router that does not have a stable route, due to a fail in the link or because the algorithms are still calculating a stable route. The consensus algorithm is used to calculate a global state of the system, staring from the distributed snapshots that each autonomous system sent.
Opportunistic networks are similar to MDS. However, the routing algorithm used in this kind of networks is the Epidemic Routing [31]. This routing algorithm uses the mobility of nodes to propagate messages over the network: every time a node physically finds another node there is an exchange of distance vectors. Both nodes then compare and update their messages and vectors. This is a costly operation each time, since the network normally tends to have a large number of nodes. Thus, this protocol maximises the rate of message delivery, while minimising latency delivery. Nevertheless, this is costly in terms of bandwidth utilisation and processing on each node.
The algorithm “Adaptive Routing in Mobile Ad Hoc Networks Based on Decision Aid Approach” [32] chooses which routing algorithm is suitable depending on the current network conditions. This algorithm provides three algorithms to choose from: OLSR [7], DSR [4], and AODV [3]. It uses a voting algorithm. This assigns a weight to each node depending on the number of neighbour nodes that have a majority vote.
Consensus algorithms in distributed systems have been used successfully to problems where a team of agents must cooperatively compute logical vector function that returns a set of decisions depending on a set of input events. Agents have partial accessibility to the input events, very simple local computation and broadcast communication capabilities, and may be affected by failures. This issue involves reliable network information diffusion that can be achieved making use of techniques based on Robust Flooding [33]. For dynamic networks, [34] proposes a synchronous consensus model, in which at each round after the network topology it changes completely. It uses a variant connection model and a global clock to synchronise the rounds.
In [35] a consensus algorithm for opportunistic networks is proposed. Each node carries messages and propagates them through the network, using Epidemic Routing [31]. Disconnection of a node is not considered as a fault, but as an expected behaviour. It is expected to reach immediately the neighbourhood of the destination node. The algorithm requires a global view of the network.
Different modelling schemes may be approximated through bounded time delays. This effect can be modelling, for instance, by bounding sampling data to guarantee a transmission rate over a trigger protocol event. For example, the reactive protocol in [36] allows coping several varying time multiple sampling periods, such as current condition in this paper, by entering an artificial induced local delay which is directly related to a known sample data error that can be locally modelled through a proper local control design. In [37] the authors propose an event-triggered communication scheme. This generates the transmission events, utilising information about the system's outputs at a time-varying sampling period and the output error. In this work sampling is performed using a known and bounded time function for a local system on a global network guaranteeing the stability in an exponential response. The variable sampling function is global and its effects are local to each node to interact on this global network. The idea of local influence is used in CRA.
3. Contributions
Our goal here is to propose an algorithm for routing discovery, whose main objective is to reduce flooding. A Consensus Routing Algorithm (CRA) takes into consideration characteristics of the MDS, such as idle time in the scheduler, network's availability, mobility, and the distance between nodes. Idle time in the scheduler node is an important feature because if there is not enough time in node's scheduler to transmit a message then the path is broken. The proposal includes versions for static nodes and for mobile nodes.
The algorithm obtains a route through a dynamic topology, by establishing successive consensus among nodes. In a local group, each node obtains routing information from its neighbours while they have an active connection. This provides resilience to local changes of the dynamic topology: any change is kept at a local scale within the MDS; when some change occurs (a mobile node moving, entering, or exiting), it does not affect the overall state of the MDS, but it only affects the local group of the involved nodes. Thus, it is not necessary to recalculate the whole route, but only those groups of nodes affected by the change. The union of the local states of the nodes forms the local network status at a given time T.
In order to determine the cost of sending a packet between two nodes, routing metrics are defined in terms of how long it takes to deliver a packet over a given route. Normally, each routing algorithm has its own metrics, which assign a value to a route, based on a factor such as hop count, bandwidth, and link reliability [38].
The rest of this paper is organised as follows. Section 2 presents an overview of the CRA; Section 3 describes the experiments based on the case studies for one and two hops. Section 4 presents our results. And Section 5 provides conclusions.
4. The Consensus Routing Algorithm (CRA)
For the purposes of this paper, the CRA is analysed considering that the topology is “mobile”; that is, the topology changes through time.
For modelling a distributed system (MDS) with n nodes, consider the following parameters and variables:
Let node be a data structure per node that includes the following fields:
Unique ID per node. Axes x and y. Letting β be the field corresponding to idle time in the scheduler of a node when it acts as a router. Letting λ be the field corresponding to the load of every link between all pairs of directly connected nodes. A field that indicates whether a node can move through network. Let Let Let k be the total number of routing steps of a given route. Let l be neighbourhood with respect to a node, whose extension is presented in number of hops. Let Let Let Let A small percentage of nodes are mobile during the route search.

The CRA makes use of an availability function (

This availability function takes into consideration not only the parameters and variables described above, but also other relevant parameters of the MDS, such as the current available bandwidth per link (τ), the idle time in the scheduler of a node (Γ), and the number of hops between a particular pair of nodes (hops). The value obtained from this function is between 0 and 1, which indicates whether such a link is available to be part of the route. Notice that commonly
The algorithmic complexity of the CRA depends on the size of neighbourhood (l) and the degree of a node, that is, the number of nodes with which each node is directly connected (
The implementation of the CRA is based on a search tree, in which each branch is evaluated to choose the best candidate. As the number of nodes grows, the neighbourhood l of a node tends to grow. Thus, the search tree also grows in depth as the number of neighbours per node increases.
The CRA is developed for the MDS, through the following steps:
For this, Notice that while Calculate the numerical distances Determine the “degree of closeness,” or “level of agreement,” of all This function (known as “agreement indicator”) provides a value for the agreement of inputs In this function, the parameters p and q are used only for tuning purposes. The parameter q tunes the rate of roll-off of this function, while the parameter p is used to set the midpoint value of the function. This function is continuous and generates After obtaining the agreement indicator values for all of the input pairs ( This type of weighting directly indicates the influence of the agreement between any particular input and the other inputs on its weight value [40]. The output of the consensus is obtained using
The value of The node is named Finally, after several route discoveries, some node should have Every





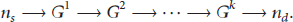
The objective of this routing algorithm is to consider local conditions. This will allow the nodes to decide a route based on such local, bounded conditions.
This routing algorithm makes use of a consensus algorithm to evaluate such local conditions, allowing “deciding” which neighbour node to use as router and thus going on building a route aiming to the destination node.
The CRA makes use of the concept of l-neighbourhood and achieves the purposes of avoiding a complete flooding of the MDS. The algorithm has been tested considering the number of hops as a parameter for defining the reach of the l-neighbourhood.
5. Experiments
Simulation experiments have been carried out with the CRA for a mobile topology, using a MDS of 100 nodes. These nodes were distributed based on a normal distribution.
All simulations have been implemented using Matlab. Note that, for each step of the route, the CRA is applied until the destination node is found or when a time-out condition is declared. Figure 1 shows CRA's behaviour in a network, where the source node (

Network used in this example.
Using this network, both algorithms (CRA and flooding) were executed with the following results. The results of CRA are presented in Table 1 and Figure 2. Table 1 shows (in time) construction step by step of a route between node A and node B. The first column displays the times CRA has been used before reaching the destination node. The second column shows location of each source node to the start of each execution of CRA. The winner path is shown in columns 2, 3, and 4; it is composed of 3 pairs of coordinates: the first pair of coordinates is the source node for corresponding round, and the second and third pairs of coordinates correspond to source node's direct neighbour and a neighbour of this, which has been evaluated before by CRA as the most suitable path. In round 4 destination node is reached. The total cost of this search is 5.93 units of availability function, and the total distance covered is 64.61 units.
CRA's results for searching a route from node placed at (87, 71) to destination node placed at (95, 89).


CRA's results for searching a route from node placed at
The data reported in Table 1 are depicted in Figure 2.
For comparison purposes, using the same network, source node, and destination node, the experiment was replicated using the flooding algorithm. The results are displayed in Table 2, where column 1 displays the number of rounds in which the result was obtained for the corresponding row. In this experiment, the flooding algorithm was run 2 times and 43 results were obtained, of which 7 are of round 1 and the rest of the latter. The route reaching the destination node consists of three nodes, but there were 41 extra parallel transmissions. The total cost of this search is
Flooding algorithm results for searching a route from node placed at (87, 71) to destination node placed at (95, 89).


Flooding algorithm results for searching a route from node placed at
6. Results
In the simulations that have been performed, the flooding algorithm established 44 connections while searching exhaustively the destination node, evaluating each link using an “availability function.” The total cost of the search was
It often happens that CRA presents a routing-loop, so that the destination node is not reached. In order to prevent the algorithm from reaching a state of completion, a number ξ that will limit the time that a node can be in a cycle before stopping the process is defined. Therefore, a flag is sent and the algorithm will terminate correctly.
The flooding algorithm does not consider the local conditions of a node, so that the choice of nodes belonging to the route is inefficient, in the sense that it is not ensured that these nodes are available to transmit, and this increases the probability of delays during the routing process.
7. Conclusions
The route obtained by the CRA is represented as a sequence of nodes with the best conditions for transmitting like a router and thus reducing the communication efficiency of such a route. By using a limited neighbourhood, the number of active connections is significantly reduced, particularly when compared with flooding. However, the flooding algorithm obtains a route in less time, but this route is more likely to be inefficient compared with the route calculated by the CRA.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
The authors would like to thank the financial support of PAPIIT UNAM INI00813 and CONACYT 176556 and technical assistance of Ing. Adrian Durán and Ing. Joel Durán.