
Abstract
Database applications in wireless sensor networks very often demand data collection from sensor nodes of specific target regions. Design and development of spatial query expressions and energy-efficient query processing strategy are important issues for sensor network database systems. The existing sensor network database systems lack the needed sophistication for the space calculation of the target sensor nodes; hence, unnecessary query/data transmissions are required between the sensor nodes and the server. This paper describes our spatial operations and energy-efficient query processing methods that are designed and implemented in our sensor network database system called
1. Introduction
Sensor networks are increasingly used in a wide range of modern applications, including disaster management, precision agriculture, healthcare, traffic management, and ecological monitoring as one of the most useful emerging information management systems [1–5]. In many earlier developments of sensor networks, sensor nodes were viewed as network components; therefore, they were designed mainly to propagate stream data over a network to the base-station using preinstalled data aggregation instructions from the network perspectives [6, 7]. From the data management perspectives, on the other hand, a sensor network is viewed as a real-world resource of time-variant data in a sense similar to a huge database reservoir. By grafting the traditional database management perspectives to the sensor network, sensor networks have become more functional in data processing so as to be able to serve a wider range of modern sensor network applications.
The typical procedure of query processing in a sensor network database system can be summarized as follows: (1) an application issues a query over to the sensor network; (2) the designated sensor nodes execute the query; and (3) data are aggregated along the topological alignment of networked sensor nodes back to the base-station, where the application processes them on the fly or stores them in a back-end database. A few works on sensor network database systems have been reported [8–12].
The sensor nodes in a wireless sensor network have battery limitation and consume more energy for query/data transmission over the networked nodes than for data reading at the nodes. Therefore, how to reduce (and balance) the energy consumption for query/data transmission is an important research issue. Query processing in wireless sensor networks exploits in-network processing methods and routing plans in an effort to minimize and balance the battery consumption during the course of query/data transportation [9, 10, 13].
Applications of database management in the sensor networks typically require data collection from the nodes of some geographical areas of interest as a target space, such as an area damaged by forest fire, an area designated as the peak, an area of a given coordinate, and areas of an abrupt increase in traffic, north of a certain point. Reducing the energy consumption in the wireless sensor network is an important issue to achieve efficient data reading operations at individual sensor nodes and maintain energy balance for the entire sensor network as well. The design and development of spatial query operations and associated query processing strategies are important issues in sensor network databases for achieving energy-efficient data management.
Spatial queries in sensor network databases often have multiple targeting structures, such as “read temperatures from the regions where the humidity is lower than 10% in the west slope of the mountain.” This query indicates the first target space as “the west slope of the mountain” and the next target space is formed according to the humidity readings from the sensor nodes in the first target area. It seems that this query is intended to monitor and predict a possible forest fire.
A few sensor network database systems have been designed [8–12]. However, for their limited spatial expressions, they require multiple query disseminations and data collections by issuing a query to select sensor nodes of the first target region (i.e., the west slope in the above example) and another query to collect data from sensor nodes of the second target region(s) with humidity lower than 10% in the example. In our proposed approach, on the other hand, a single query with spatial operations manages multiple targeting by using an in-network query processing method so that the identification of subsequent target region(s) is done at some intermediate nodes called lowest common ancestor (LCA) nodes without traversing to and from the base-station.
This paper presents our design and implementation of spatial operations and associated query processing algorithm in an effort to better support sophisticated demands of sensor network applications. We have designed spatial operators based on geometric parameters, such as Envelope, Nearby, Distance, and Direction, as well as binary spatial operators, such as Intersection, Union, and Difference in an attempt to extend our previous sensor network database SNQL [8, 14]. We also have developed our query processing method called LCA-based in-network query processing (in short, LCA-algorithm). We have defined a LCA node as one of the parent sensor nodes that minimally covers all the leaf nodes of the target region that participate in the query processing. At the LCA node, the new target region will be identified according to the data read from the nodes of the initial target region, and then the registered query at the LCA node is reformed and redisseminated for final reading without traversing to and from the base-station. Our proposed spatial query expressions and LCA algorithm together will efficiently reduce the query processing cost in the wireless sensor network.
The contribution of this paper is summarized as follows. We have extended our previous work on sensor network query language SNQL [8, 14] by incorporating various spatial operators, so that more sophisticated expressions of target space are made possible in our new system called We designed an efficient query processing strategy by employing the concept of lowest common ancestor (LCA), which implements an efficient in-network query processing for spatial query operations.
The rest of this paper is organized as follows. Section 2 introduces related works, and Section 3 describes the spatial operators. Section 4 explains the LCA-based in-network query processing algorithm. Section 5 explains the architecture of the
2. Related Work
Madden et al. have proposed TinyDB which is a distributed query processing system running on the Berkeley mote platform on top of TinyOS operating system [9]. It supports acquisitional query processing (ACQP) that has the features of when, where, and in what order the sensor nodes are sampled and which nodes should be included in processing a particular query. It also manages a semantic routing tree (SRT) to store a single one-dimensional interval, representing the range values beneath each of its children in each node. For example, when a query that has a spatial condition, such as “x-coordinate > 100”, arrives at a node, the node checks whether any child's x-coordinate range value overlaps the spatial condition of the given query. If so, it forwards the query down to the child nodes. Thus, SRT supports the efficient dissemination of queries and collection of query results over spatial conditions. However, since spatial expression is limited to disseminating a query only to target nodes with the coordinates in the query, multiple queries are needed if the intermediate query results are used as the conditions for the following queries as given in the aforementioned example.
Di Felice et al. have extended TinyDB to support the spatial expression of queries by means of the longitude and latitude of the nodes indicating their physical locations [15]. To apply spatial operation, the attributes of TinyDB are extended with longitude and latitude to create the preconditions for the georeferencing of the sensor nodes. The extended TinyDB enables the processing of some spatial operators, such as Distance, Inbox, and Beyondboundary. Among these operators, Inbox determines whether a node exists within a given envelope for identifying nodes in a physical space. For example, if one wants to read temperature from a rectangle
Kim et al. proposed Spatial TinyDB, which supports spatial data types and spatial operators by extending TinyDB by incorporating standard geospatial expressions proposed by the Open Geospatial Consortium (OCG) [16, 17]. The spatial TinyDB supports spatial data types, spatial relation operators, spatial analysis operators, and spatial trajectory operators. Their spatial data types are managed in seven types: Point, LineString, Polygon, PolyhedralSurface, MultiPoint, MultiLineString, and MultiPolygon. Also, eight spatial relation operators are given, such as Equals, Disjoint, Touches, Within, Overlaps, Crosses, Intersection, and Contains. Each relation operator receives two spatial objects and returns True or False as the output. Spatial analysis operators include six operators, such as Distance, Intersection, Difference, Union, Buffer, and Convexhull. Each receives two spatial objects and returns a new spatial object as the output. However, since the spatial data types are limited to expressing a region with the coordinates of area, it is not suitable to select an unfixed target region (e.g., the region where the humidity is lower than 10%), and thus it requires multiple queries if intermediate query results are used as the conditions for the following queries.
Yao et al. proposed the Cougar system, in which sensor data is periodically collected from the physical environment and is represented by time series [10, 11]. They proposed query processing over sensor data which are considered as a virtual relational database, so that a user can issue queries without knowing the physical characteristics of the sensor network. In Cougar, it is assumed that each sensor type has a standard abstract data type (ADT) representation which is used at all nodes. Sensors can be treated as ADT objects in query processing, and the user application manages a SQL-like interface through ADT. Here, the simplified schema of the sensor network database contains one relation R(loc point, floor int, s sensorNode), where loc is a point ADT that stores the coordinates of the sensor, floor is the floor where the sensor is located in the data warehouse, and sensorNode is a sensor ADT that supports the methods detectAlarmTemp(threshold). Here, the threshold is the threshold temperature above which abnormal temperatures are returned. For example, if one wants to generate a notification when two sensors within 5 yards of each other simultaneously measure an abnormal temperature, “SELECT R1.s.detectAlarmTemp(100), R2.s.detectAlarmTemp(100) FROM R R1, R R2 WHERE $SQRT ($SQR(R1.loc.x − R2.loc.x) + $SQR(R1.loc.y − R2.loc.y)) < 5” is issued. However, the location is stored in the front-end server for querying so that query processing takes place on the centralized database. Therefore, if intermediate query results are used as the conditions for the following queries, it also needs to disseminate multiple queries.
Shen et al. proposed SINA [12] which supports SQL-like query and script using a language called Sensor Query and Tasking Language (SQTL). This system is based on a spreadsheet database where each attribute is referred to as a cell, and it incorporates a hierarchical clustering mechanism. SQTL provides primitives for sensor hardware access (e.g., getTemperature, turnOn), location aware (e.g., isNeighbor, getPosition), and communication (e.g., tell, execute) primitives, as well as event handling. These scripts migrate from node to node depending on their parameters by the sensor execution environment (SEE) located in each sensor node. Then, the SEE examines all SQTL messages and performs the appropriate operation. For example, messages with “ALL_NODES” are rebroadcasted to every sensor node, and those with “NEIGHBORS” are forwarded only to nodes that are one-hop-away neighbours in the sensor network. As in these examples, location is used for primitive operations, such as forwarding messages. Therefore, spatial operation does not work efficiently when multiple targets are used.
Amongst the studies related to spatial query processing in sensor networks, some attempt to utilize spatial indexing for query processing. Soheili et al. suggested Spatial Index (SPIX), which applied R-Tree to sensor network [18]. In that, a sensor node forms Minimum Boundary Area (MBA) that includes the location information of itself and of its descendant sensor nodes along the routing pass and manages these in the form of R-tree. The MBA is used to determine whether the spatial query, once received from a higher-level node for sensor data collection within a given area, should be passed to the lower-level nodes. Li et al. proposed back forwarding method, which uses SPIX mechanism for disseminating query and rearranging mechanism for return route of the query result to base-station [19]. By restructuring return path dynamically for the query result, they reduced the energy cost of aggregating the query result. Park et al. suggested Sectioned Tree, which divides the entire network into several squares that form local sections and in which the head node of a section manages the MBR to determine whether to pass the spatial query [20]. Dyo and Mascolo investigated a solution to reduce the energy consumption for creation and management of spatial index [21]. They decomposed the entire network into a set of disjoint hierarchical square cells, where each cell consists of four smaller cells. Then, they placed the cluster heads at fixed coordinates to reduce the algorithms and communications required to search for cluster heads. Our index management scheme is also MBR-based algorithm for query processing as given in Section 5.2. The minimum boundary rectangle (MBR) of subtrees for each sensor node is used for determining to pass the query down to the child nodes when the target space overlaps MBR of subtrees. No matter how index is managed, they lack the needed capability of managing multiple targeting in a single query if intermediate query results are used as the condition for finding the target space in the subsequent queries as given in the aforementioned example.
Sensor Network Query Language (SNQL) and its query processor use SQL-like language structure and various query processing functions running over Android [8, 14]. It is designed to support instant queries, continuous queries, and event-based queries. SNQL implements various querying operations to reduce the energy consumption of sensor nodes by minimizing the amount of transactions in query/data propagations among sensor nodes while maintaining the computing capability. For example, conditional branching query provides a case-based branching mechanism in that the collection of sensor data is dynamically set based on the data values of the designated sensor nodes. The node-selection query supports a percentage-based node-selecting mechanism by WITHIN-clause for choosing only a certain number of participating nodes rather than using all nodes. Location-aware event detection query provides specification of the event monitoring region and the target region of sensor nodes from which the notified types of sensor data are collected through in-network query processing. Despite its sophisticated language expressions and query processing methods, the SNQL still lacks the needed capability of spatial query operations, and thus it suffers from the same inefficiency for spatial querying as other sensor network databases.
3. Spatial Operators for
3.1. Design of
Space
In this section, the spatial operators of
The

The point of a location is also regarded as a type of a

Formation of
Based on the feature of
3.2. Space Identification Operators
3.2.1. Envelope (Condition(s))
The Envelope operation will result in a group (or groups) of sensors forming geometric space(s) together satisfying given condition(s). For example, a query: “find the space of sensor nodes where the temperature is above 30 degrees” is expressed by Envelope (temp > 30).
The procedure of Envelope operation is given in Algorithm 1. N denotes an arbitrary sensor node; the child node of N is defined as
(1) (2) create (3) (4) merge envelopes created from (5) add (6)
3.2.2. NearBy (
,
,
,
)
The NearBy operation creates and returns the geometric space of the nearest node to the specified target location in the form:

NearBy (10, 10, 20, 20).
As shown in step 1 of Figure 3, nodes whose subtrees include the given coordinates will receive and register the query of NearBy (10, 10, 20, 20). Thus, the query is passed along node-1 to node-6. On the other hand, node-7 to node-10 do not receive the query since node-5 and node-6 did not send the query because their subtrees do not include the given coordinates. In step 2, node-4 forms
The procedure of NearBy operation is given in Algorithm 2. This operation receives coord (i.e., coordinates of a target location) as an input and returns a set of geometric space
(1) create (2) (3) find the nearest envelope to coord among (4) set the nearest envelope to (5)
3.2.3. Distance (Envelope(s), Range Value)
The Distance operation identifies a geometric space for range value from a designated geometric space. As mentioned in Section 3.1, it is to be noted that a point of location is also expressed as a
As shown in step 1 of Figure 4, node-5 as a LCA node identifies two

Distance (Envelope (temp > 30), 10 m).
The procedure of the Distance operation is given in Algorithm 3. This function receives a set of geometric spaces
(2) ra // a range value
(1) (2) Set envelope of (3) (4) (5)
3.2.4. Direction (Envelope(s), Direction Value)
The Direction operation identifies and returns a geometric space outside designated space in the given directions: NORTH, SOUTH, EAST, WEST, and their mixed orientations as well. For example, a query: “find the space of sensor nodes that are located in the WEST of some space where the temperature is above 30 degrees” is expressed by Direction (Envelope (temp > 30), WEST).
Figure 5 illustrates the operation. In step 1, node-5 as a LCA node identifies

Direction (Envelope (temp > 30), WEST).
The procedure of Direction operation is given in Algorithm 4. It receives a set of geometric spaces
(2) D // a direction value
(1) (2) (3) ε (4) create (5) (6) ε (7) create (8) (9) ε (10) create (11) (12) ε (13) create (14) (15) (16)
3.3. Set Operators
Set operators are designed to identify the sensor nodes of target spaces by using two operand spaces. With this facility,

Procedure of producing multiple constituent subspaces.
3.3.1. Intersection ((s1, s2)∣Envelope(s), Envelope(s))
The Intersection operation takes two operand spaces either explicitly specified by space-IDs or implicitly specified by two return values (i.e.,
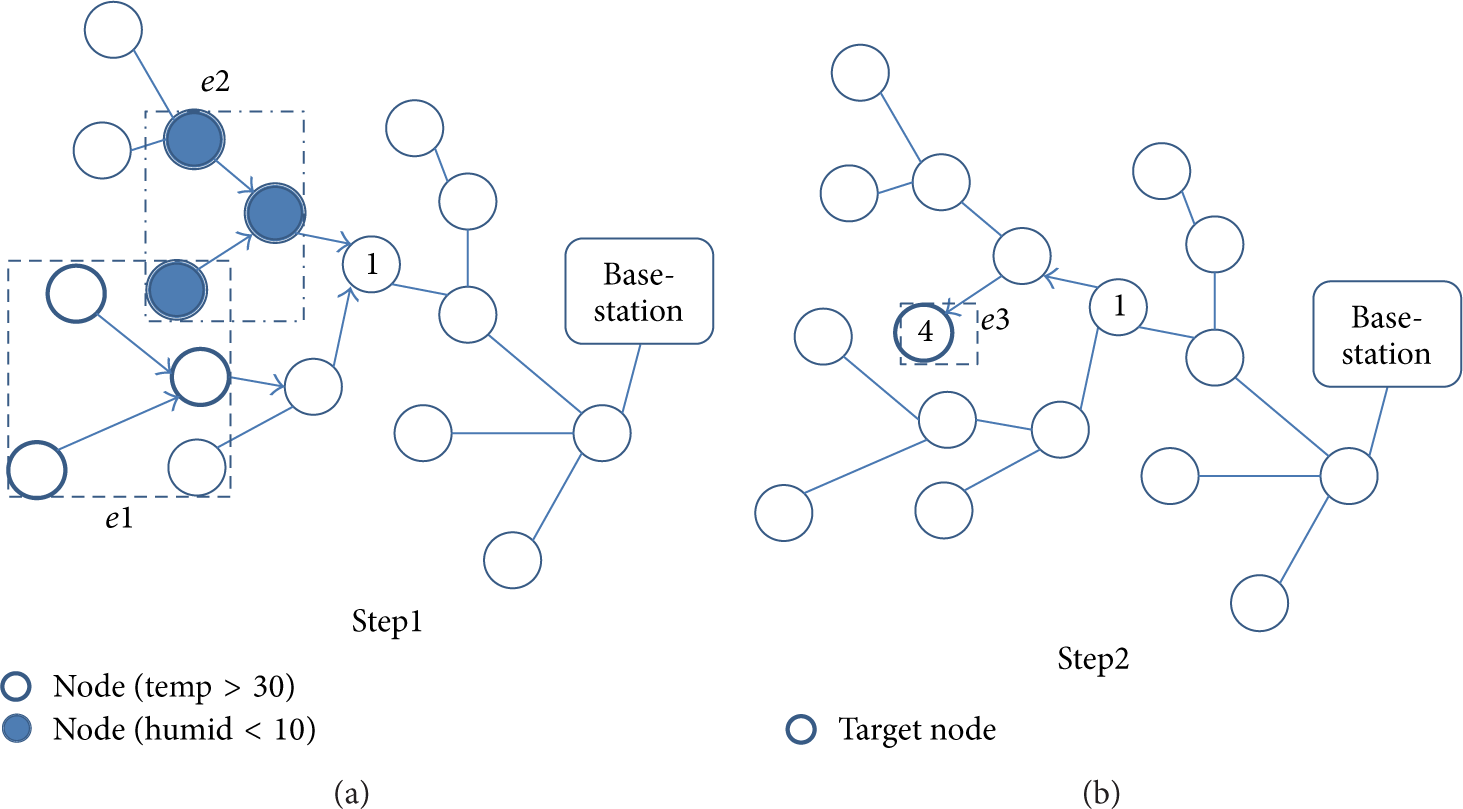
Intersection (Envelope (temp > 30), Envelope (humid < 10)).
3.3.2. Union ((s1, s2)∣Envelope(s), Envelope(s))
The Union operation takes two operand spaces either explicitly specified by space-IDs or implicitly specified by two return values (i.e.,
Union (Envelope (temp > 30), Envelope (humid < 10)).
3.3.3. Difference ((s1, s2)∣Envelope(s), Envelope(s))
The Difference operation takes two operand spaces either explicitly specified by space-IDs or implicitly specified by two return values (i.e.,

Difference (Envelope (temp > 30), Envelope (humid < 10)).
The procedure of Set operation is given in Algorithm 5. This function receives op_name (i.e., operator name),
Spatial operators in SNQL+s.

(2) (3)
(1) (2) (3) (4) create intersect envelope (5) create (6) create (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) remove redundant envelopes from (17)
3.4. Spatial Expressions in
In this section,
To add spatial operators to the SNQL [8, 14], the expression in the WHERE-clause and WHEN-clause is extended as described in Algorithm 7. More specifically, <SpatialFunc> is added to <SQLSimpleExp> of <Expression> so that the spatial operators previously explained can be used. <SpatialFunc> consists of <Envelope>, <NearBy>, <Distance>, <Direction>, <Intersection>, <Union>, and <Difference>. <Envelope> is expressed as a combination of attributes (e.g., temperature), operators (e.g., “>”, “<”, or “=”), and constants. <NearBy> is expressed as integer values representing the coordinates x and y. <Distance> expresses the operator selected from the elements of <SpatialFunc> and a constant indicating the distance. <Direction> expresses the operator selected from the elements of <SpatialFunc> and a constant indicating the direction. <Intersection> consists of combinations of <SpatialFunc> entities used to obtain the intersection. <Union> consists of combinations of <SpatialFunc> entities used to obtain the union area. <Difference> consists of combinations of <SpatialFunc> entities used to obtain the difference area. <envelope>, <attribute>, <operator>, and <constant> are fundamental attributes, whose descriptions are thus not necessary.
4. LCA: In-Network Query Processing Algorithm
Sensor network queries often involve multiple phases of data reading in a single query task. The example query given in Section 1 “read the temperatures from the regions where the humidity is lower than 10% in the west slope of the mountain” involves two separate tasks: (1) read the humidity values from all the nodes in the west slope and (2) read the temperature values from the nodes in spaces where the humidity values are below 10%. In the existing systems, this operation would require two traversals between the base-station and the target nodes of the designated spaces.
Our proposed query processing algorithm enables the multiple phases of querying tasks to be handled by an in-network node called lowest common ancestor (LCA) node. The LCA node is one of the intermediate parent nodes which distributes the query to more than two child nodes for the first time and minimally covers all the child nodes of the target space. It has been designed to play the role of in-network query reformation and redissemination for the multiple reading tasks. This query processing algorithm will efficiently reduce the energy consumption of wireless sensor nodes incurred by unnecessary transmissions of multiple queries/data between the base-station (i.e., root node) and the target nodes.
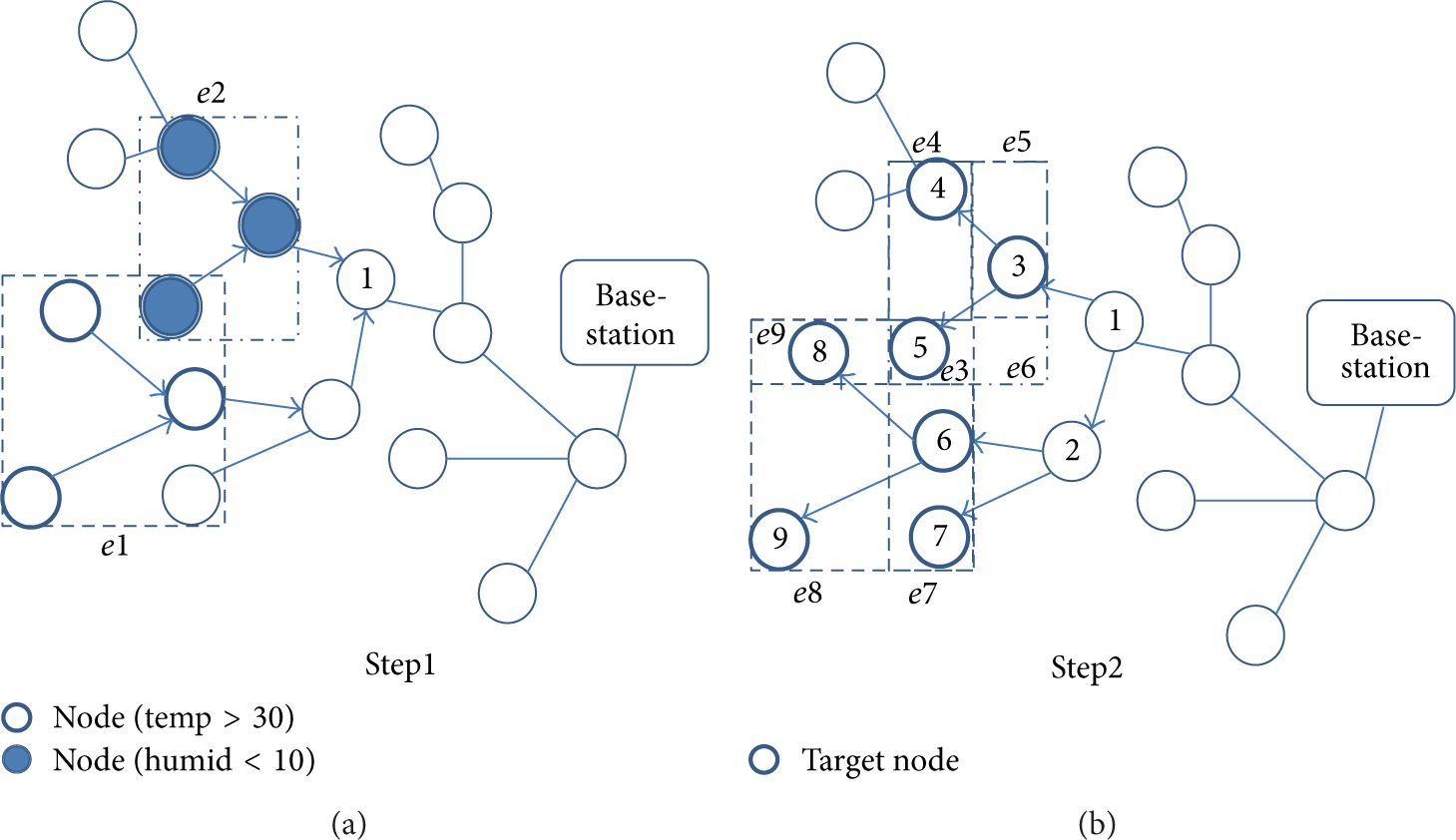
The procedure of finding the LCA node is as follows. Each node along the query path manages two parameters (
Figure 10(a) illustrates how a LCA node is determined for the example query to the first target space. N01, as the base-station, receives the query and the Planner of Query Processor finds N02 as the receiver node toward the target space. Here, since N01 does not have a parent,

In-network query process with LCA node.
In Figure 10(b), the LCA node carries out a query task for data collection from the final target nodes (i.e., the nodes with humidity values lower than 10% within the initial target space). For this, the LCA node plays the key role of identifying the final target nodes and redisseminates the subsequent query task to the nodes (i.e., temperature reading).
The procedure of LCA operation is given in Algorithm 8. This function receives
(2) #
(1) ∣∣ (# (2) reform the registered query with envelopes receive from child nodes (3) (4) (5) (6)
5. Architecture
5.1. Overview
This section describes the architecture of our sensor network database system. It consists of functional components of the base-station as the
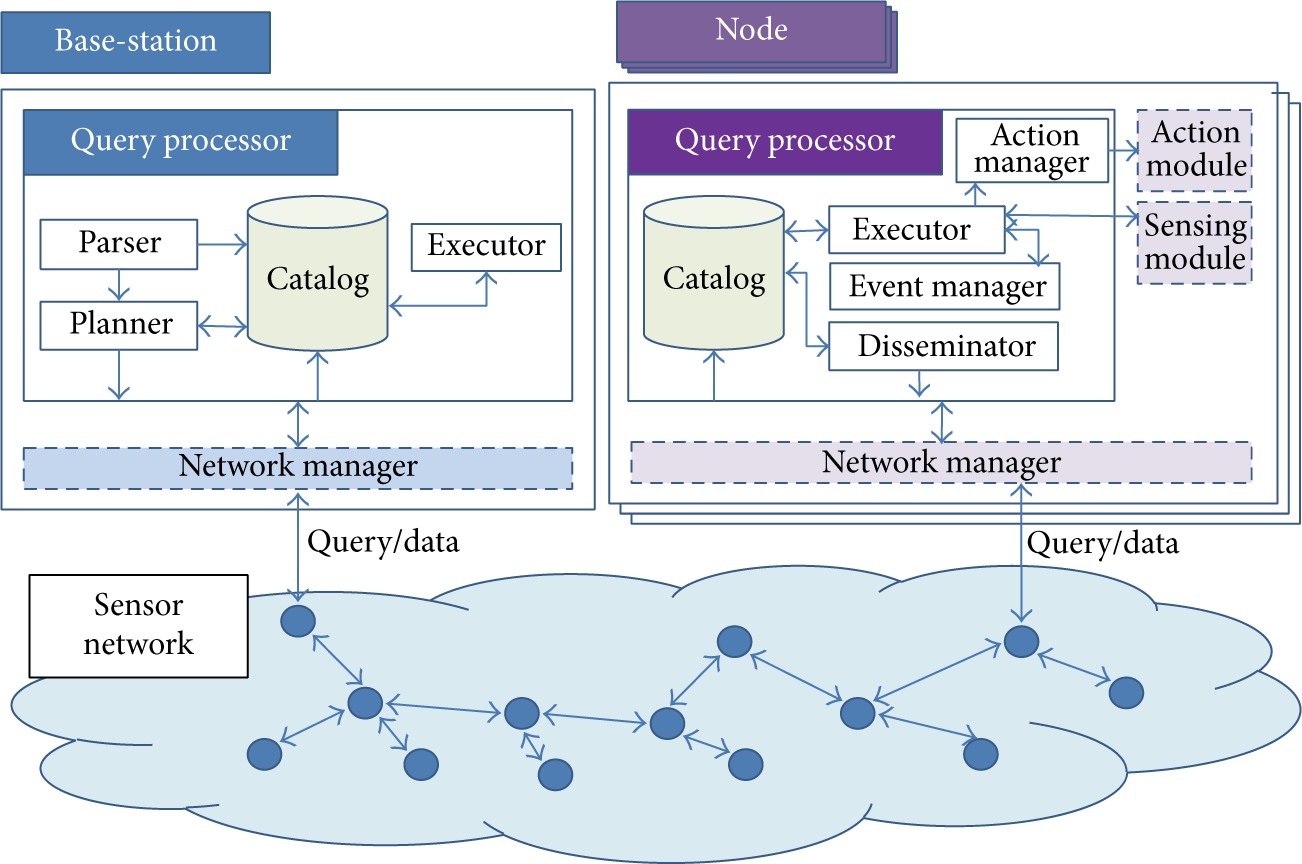
System architecture of sensor network database using
5.2. Metadata Management
The metadata of

An example of managing metadata.
6. Performance Evaluation
6.1. Test Data and Environment
In this section, the performance of our proposed spatial query processing strategy is evaluated based on the energy efficiency. We used the Intel Berkeley Research lab data [22] to generate random sensing data as follows: normal distributions with a mean of 22.07 and a standard deviation of 3.662 for temperature data; a mean of 39.29 and a standard deviation of 7.162 for humidity data; and a mean of 390.87 and a standard deviation of 534.39 for illumination data. The number of nodes is set to 10000, and the sampling count of each node is set to 1000. Energy consumption of sensor network is caused by transmission, reception, processing, and sensing of queries and data [9]. Table 2 summarizes the simulation parameters.
Simulation parameters.

All the experiments were conducted with a simulator which was programmed internally in Java and was extended version of our previous work [8, 14, 23].
6.2. Experiments and Results
The efficiency of LCA-based spatial operations is evaluated by two experiments for two typical spatial operations of multiple targeting: operation for identifying intermediate target region and operation for targeting multiple regions, respectively.
Experiment 1. A test query for identifying a new target region according to the data result from the initial target space.
In this experiment, we measured the amount of energy consumption for two different query processing methods: one with LCA-based spatial operation and the other without the operation. This is measured by varying the distance of target region from the base-station as shown in Figure 13.

Area of target nodes varying the position of region.
The query used for this experiment is as follows.
“Get NodeID and light value of nodes from the intersecting area between an area with temperature above T°C and another area with the humidity below H% within the area of
The above query is expressed in
Multiple queries are needed when spatial operations with LCA algorithm are not supported as in SNQL [8, 14] as follows: ① SELECT NodeID, x, y FROM sensors WHERE ② SELECT NodeID, x, y FROM sensors WHERE ③ SELECT NodeID, light FROM sensors WHERE
The base-station will calculate the intersecting areas from the results of query ① and query ② and then obtains the NodeID and light value from query ③.
The multiple query executions to identify intermediate target regions and the extra spatial operation (i.e., INTERSECT) at the base-station will consume energy and give application designer an extra programming overhead. On the other hand,
Figure 14 shows the result of the experiment. Obviously, as the distance of target region from the base-station increased, the number of intermediate nodes to send the final query results to the base-station also increased. Moreover, the gap of energy consumption between two curves becomes larger as our spatial operators with LCA-based processing algorithm effectively reduce multiple query/data transmissions between the base-station and querying nodes.

Varying the position of target region.
Experiment 2. A test query for identifying multiple target regions.
In this experiment, we observe the amount of energy consumption by varying the number of target regions (denoted by the number of target regions:
The query used for this experiment is as follows.
“Get NodeID and light value of nodes in the area of
Multiple queries are needed when spatial operators with LCA-based query processing algorithm are not supported as in SNQL [8, 14] as follows: ① SELECT NodeID, light FROM sensors WHERE ② SELECT NodeID, light FROM sensors WHERE
The multiple query executions in sending the queries to multiple target regions will consume energy and give application designer an extra programming overhead.
The above query is expressed in
It is to be noted that our proposed set-theoretic spatial operations returns multiple regions to minimize the ratio of irrelevant sensor nodes in the target region (refer back to Section 3.3).
Figures 15(a), 15(b), and 15(c) show how the number of target regions affects the performance of two different query processing methods. Given three different ratios of participating nodes in target nodes as selectivity factor

Cumulative energy consumption varying
Summarizing the above performance evaluation, our proposed spatial query operators in
7. Conclusion
Since the sensor nodes in wireless sensor networks are deployed typically in a wide range of geographical regions, the geometric characteristics of nodes (such as topology, distance between nodes, and upwards/downwards directivity) will have to be closely considered for various applications. Obviously, application will require reading sensor data of some regions of interest as target spaces of queries. Well-designed spatial query operations will achieve energy efficiency for the sensor nodes and the entire network as well. Existing query languages of sensor network databases lack needed sophistication of specifying target regions and energy-efficient query processing strategies.
In this paper, the operators applicable to sensor networks were referred among the widely used standard GIS operators and interpreted to suit the sensor network environment. Then, these were categorized into space identification operators and set operators, followed by the suggestion of
We have designed LCA-based query processing algorithm for various spatial operations. With the algorithm, unnecessary query/data transmissions between the base-station and the sensor nodes of target regions are avoided by using the notion of LCA nodes. The performance evaluation of our proposed scheme implemented in
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This research was supported by the R&D Program supervised by the Institute for Information & Communications Technology Promotion (IITP), Korea (IITP-2014-044-041-002).