
Abstract
Recent years, the studies of link prediction have been overwhelmingly emphasizing on undirected networks. Compared with it, how to identify missing and spurious interactions in directed networks has received less attention and still is not well understood. In this paper, we make use of classical link prediction indices for undirected networks, adapt them to directed version which could predict both the existence and direction of an arc between two nodes, and investigate their prediction ability on six real-world directed networks. Experimental results demonstrate that those modified indices perform quite well in directed networks. Compared with bifan predictor, some of them can provide more accurate predictions.
1. Introduction
Network is an effective and efficient tool to describe real-world complex systems [1, 2], such as social, biological, traffic, and information systems, where nodes represent individuals, proteins, airports, web pages, and so forth and links denote the relations and interactions between them. The study of complex networks is an important growing field that attracts lots of attention from different branches of science. While making great efforts to understand the structural features and evolutionary mechanism of networks, scientists gradually realize that the inaccuracy and incompleteness of data sets is a significant obstacle to the research [3, 4]. To address this issue, link prediction algorithms have been adopted to extract the missing information, identify spurious interactions, and reconstruct network.
The problem of link prediction aims at estimating the likelihood of the existence of a link between two nodes in a given network based on the observed links [5], and it has a wide range of applications in the real-world. For example, in online social networks, very likely but not-yet-existent links can be recommended as promising friendship, which can help users in finding new friends; in biological networks, compared to blindly checking all possible protein-protein interactions, accurate prediction of the most likely existent ones can dramatically reduce the experimental cost; in e-commerce, with the help of recommendation systems, sellers enhance their sales by watching customers' purchases and recommending other goods to them in which they may be interested [6]; in security domain, link prediction methods could be used to assist identifying groups of terrorist or criminals [7].
Since the link prediction problem is relevant for various domains, lots of algorithms have been proposed to solve it. The most widely used link prediction indices are the local similarity measures [8–12], for example, Common Neighbors, Jaccard index, Adamic-Adar index, and Resource Allocation index, which only require consideration of the local structure of the networks. They are favored for low complexity, low time consumption, and relatively high accuracy especially when the network is highly clustered [13].
Algorithm based on statistical inference is another branch in the study of link prediction, in which some organizing principles of the network structure, like hierarchical organizations or community structures, are often presupposed [7, 14, 15]. Using Bayes theorem, people can infer the underlying structure from observed network and take advantage of the knowledge to reliably identify both missing and spurious interactions. Usually, the performance of this type of method is more accurate and robust, but it has an obvious drawback—the high computational complexity makes it infeasible for large-scale networks.
All the algorithms mentioned above are designed for undirected networks. However, in the real-world asymmetric interactions are widespread such as worldwide web, food web, neural network, email network, and citation network. Unfortunately, there has been little research focusing on how to identify missing and spurious interactions in directed networks. Until very recently, a new mechanism for the local organization of directed networks, potential theory, has been proposed [16]. Combining the potential theory with the clustering and homophily mechanisms, bifan structure which consists of 4 nodes and 4 directed links is deduced to be the most favored local motif structure and could be used directly as a well-performed missing link predictor in directed networks.
In this paper, we focus on the link prediction problem in directed networks. Our contribution is twofold: (1) Instead of proposing a brand-new directed link predictor, we make the best of classical prediction indices of undirected networks. We extend the most representative measures to directed version, to meet the requirement of predicting both the existence and direction of an arc between two nodes. (2) To investigate the performance of these modified indices, we design simulation experiments on five real biological and technological directed networks, the results of which vividly demonstrate their prediction ability.
The remainder of this paper is organized as follows. In Section 2, we describe the link prediction problem in directed networks and the standard metric for performance evaluation. Then, we present how the adapted indices work in asymmetric networks and access their prediction ability in Sections 3 and 4, respectively. Finally, the conclusion is drawn in Section 5.
2. Problem Description and Evaluation Metric
Given a directed network
To evaluate the algorithmic performance, the observed links E is divided into two parts: the training set
We adopt metric AUC [17] (area under the receiver operating characteristic curve) to quantify the prediction accuracy. It evaluates the predictor performance according to the whole list and can be interpreted as the probability that a randomly chosen missing link (i.e., a link in

Similarly, the link prediction algorithm can also be used to identify spurious interactions. In this case, the task is changed to score all the observed links in E and rank them in an ascending order; then the top ranked links are suspected as the most likely spurious interactions. To test the algorithmic performance,
In a word, for both predicting missing links and identifying spurious links cases, the higher the AUC value is, the better the prediction algorithm works.
3. Directed Link Predictors
In this section, we first review some classical prediction indices for undirected network and present how to extend them to directed version.
(1) Preferential Attachment (PA). This is a basic link prediction algorithm corresponding to the preferential attachment phenomena in many real-world networks [18, 19]. Preferential attachment means that the more connected a node is, the more likely it is to receive new links. Nodes with higher degree have stronger ability to grab links added to the network. So PA index defines that the probability that a link will connect i and j is proportional to the number of their neighbors; that is,

In directed networks, taking the link direction into consideration,

Actually, the meaning of (3) is quite straightforward: from the perspective of information dissemination, the more outgoing neighbors of i imply the more channels to get the message out; the more incoming neighbors j attracts, the stronger its ability to gather information, so it is more likely to build a connection from i to j.
(2) Common Neighbors (CN). The common neighbors refer to the nodes that are connected with both i and j. This concept is very important that nearly all the local similarity measures are based on it.
Triadic closure principle in social network analysis states that if two people A and B have a common friend C, they are very likely to be friends too; thus these three nodes form a closed triangle ABC. For undirected networks, it is natural to assume that the more common neighbors two nodes share, the more similar they are and the more likely to build a connection between themselves. So the CN index is defined as


However, in directed networks, adjacency matrix


As shown in Figure 1, from the analysis of geometry, CN indices could be interpreted as the number of triadic closure in undirected networks, while in directed networks this index measures the formation of feedforward structure.

Geometric interpretation of CN index in different networks. (a) Triadic closure; (b) feedforward structure.
In fact, (7) is not the only way to extend CN index. Other alternative indicators include the following.
Co-citation index: Bibliographic coupling index: Feedback structure:
From Figure 2 we can see that co-citation index and bibliographic coupling index cannot present different judgement for

Alternative indicators for CN index.
(3) Stochastic Block Model (BM) [14]. Stochastic block model is one of the most general network models, where nodes are partitioned into groups and the probability that two nodes are connected depends only on the groups to which they belong.
In undirected networks, given a block model
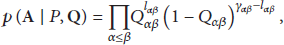

In directed networks, the interaction between two nodes are no longer reciprocal, which implies that the underlying matrix
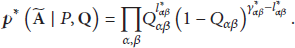
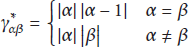

Among all the link prediction measures for undirected networks, the above three indices are chosen to be adapted for the following reasons. Firstly, the design philosophies of them are different from each other, and they all have their own advantages. CN index follows the nature intuition and has wide range of applications in practice. PA index reflects the mechanism of rich-get-richer and is superior for its least information requirement, while BM method takes into account network community structures, rests on solid mathematical foundations, and returns excellent results. Secondly, those three indices are fairly representative, so their modification methods are enlightening and could be extended to other indices. For example, inspired by the modified CN index, other local similarity measures can also be extended in a similar way. Table 1 illustrates a few common local similarity indices and their corresponding extensions.
Some local similarity measures and their corresponding extensions for directed networks.

To analyze the performance of those modified measures, next we introduce bifan predictor as a comparison index. Bifan structure is found to be quite widespread in real-world [20] and proven to be a well-performed predictor for directed networks.
(4) Bifan Predictor [16]. The potential theory is proposed as a microscopic organizing principle for directed networks, which assumes that each directed link corresponds to a decrease of a unit potential and subgraphs with definable potential values for all nodes are preferred. Combining the clustering and homophily mechanisms with potential theory, it is deduced that bifan subgraph is the most favored local structure in directed networks (see Figure 3).
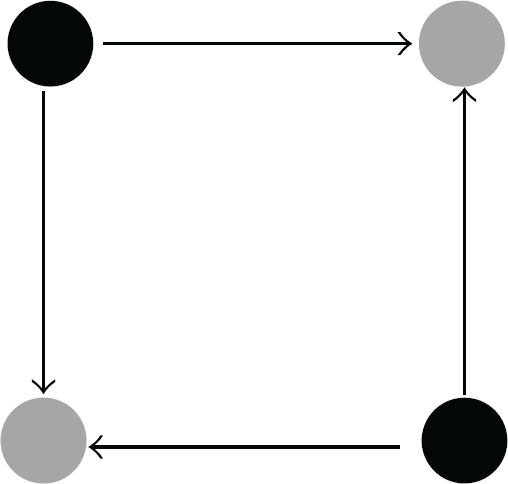
Bifan structure consists of 4 nodes and 4 directed links. All the links are equivalent to each other and nodes are of two different potentials—the potentials of two black nodes are a unit higher than that of the grey ones.
This special structure could be directly used as a link predictor, with the assumption that a link that can generate more bifan subgraphs is more significant and is thus of a higher probability to appear. So the bifan index is determined by how many bifan subgraphs that link 
4. Result
4.1. Data Sets
Our experiments are carried out on five real-world directed networks drawn from biological and technological fields. Those networks are pretty representative and are often employed in simulation experiments to validate the effectiveness of the proposed scheme. (i) FoodWeb1 (FW1) [21]: a network of food web represents the predator-prey relations between 69 species living in Everglades Graminoids during wet season. (ii) FoodWeb2 (FW2) [22]: a network of food web consists of 97 species living in Mangrove Estuary during wet season. (iii) FoodWeb3 (FW3) [23]: a network of food web consists of 128 species living in Florida Bay during wet season. (iv) C. elegans (CE) [24]: it is the neural network of the nematode worm C. elegans, in which an edge joins two neurons if they are connected by either a synapse or a gap junction. (vi) Political blogs (PB) [25]: it is a directed networks of hyperlinks between weblogs on US political blogs.
For convenience, we eliminate all the loops and multiedges of the above networks. The basic topological features of these five networks are summarized in Table 2.
The basic topological features of the five directed networks.

4.2. Experimental Results
In this section, we investigate the prediction ability of the indices presented in Section 3. Comparisons of algorithms' accuracy are displayed in Figures 4 and 5. The x-axis denotes fraction

Experimental results for extended local similarity indices.

Experimental results for different kinds of measures.
4.2.1. Comparison of Local Similarity Measures
Figure 4 illustrates the experimental results for 10 extended local similarity indices. It is worth noting that PA index, which is regarded as the worst predictor in undirected networks, surprisingly performs quite well in the experiments. It outperforms all the other local similarity measures in identifying both missing and spurious links. Hence the relatively good prediction ability together with the least information requirement makes PA index more competitive in directed networks.
Note that when applied in finding missing links, the performance of other nine local similarity measures based on common neighbors is nearly the same, especially in CE and PB networks. It is because all these extended indices are on the basis of feedforward structure, if and only if there are some “transit nodes” between i and j; the score of arc
4.2.2. Comparison of Different Kinds of Measures
In Figure 5, we choose PA and CN as representatives of local similarity measures and compare their performance with BM and bifan. It is obvious that when applied in finding missing links, BM outperforms CN and PA and works even better than bifan predictor in most networks. The advantage of BM to others is usually remarkable except for network PB, in which the performances of BM, bifan, and PA nearly keep pace with each other. This outcome demonstrates that community structure also plays an important role in directed networks. Compared with other three measures utilizing only the local structure information, BM index which takes advantage of the organizing principles of the whole network could get more accurate prediction results.
Figure 5 also shows that the prediction accuracy of all four indices decline with the increases of f, but the rate of decrease is varying. Compared with the linear decrease of CN index, the trend of AUC for others is slowly downward until it reaches a “turning point,” after which the remaining links in
As is illustrated in Figure 5, in identifying spurious interactions, BM and bifan are the two best predictors which are followed by PA, while CN index still has the worst overall performance as before. Note that, for each index, different from the results in finding missing links, AUC values are relatively high and are basically not changed with the increases of f. However, high accuracy is not sufficient for spurious link detection algorithms. If just a few unexpected important links are incorrectly removed, the structural and dynamical properties of the network may change dramatically [26]. So when applied in identifying spurious links, the prediction indices should be evaluated meticulously; however this problem is beyond the scope of this paper.
5. Conclusion
This paper studied how to identify both missing and spurious interactions in directed networks. We have showed how to extend classical link prediction indices to directed version, making them able to predict both the existence and direction of an arc between two nodes. Simulation experiments on five real-world directed networks have vividly demonstrated the prediction ability of those modified measures.
The purpose of this paper is not to present a better directed link predictor, but to give an example of how to use the valuable knowledge of undirected networks to solve the problems in directed networks. For directed networks, the direction of links is a double-edged sword. It provides additional valuable information for link prediction but also leads to greater difficulty—how to determine the direction of the unknown links is a tough problem. The extended CN index made use of the asymmetric similarity to determine the link direction, while BM benefited from asymmetric likelihood of the linkage between groups. In brief, asymmetry is the key. However, prediction methods based solely on asymmetry are incomplete, and other natures of the directed networks should be taken into consideration. For example, in neural networks and some technological networks, information or resources are often collected by basal nodes, transmitted through directed links, and delivered to top nodes eventually. Such kind of macroscopic flow direction may help to determine the unknown link direction.
On the other hand, each prediction index has its own advantages and is suitable for different kind of networks. How to choose the most appropriate algorithm according to the features of the networks is also a problem worth study.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
The work is supported by Basic Research Project of National University of Defense Technology and the Open Fund from HPCL no. 201403-01.