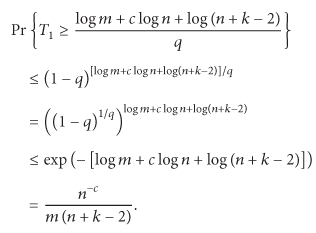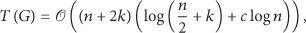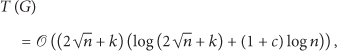Gossiping of a single source with multiple messages (by splitting information into pieces) has been treated only for complete graphs, shown to considerably reduce the completion time, that is, the first time at which all network nodes are informed, compared with single-message gossiping. In this paper, gossiping of a single source with multiple messages is treated, for networks modeled as certain structured graphs, wherein upper bounds of the high-probability completion time are established through a novel “dependency graph” technique. The results shed useful insights into the behavior of multiple-message gossiping and can be useful for data dissemination in sensor networks, multihopping content distribution, and file downloading in peer-to-peer networks.
1. Introduction
Data dissemination is a fundamental issue for information diffusion in networks [1–5]. Gossiping (a.k.a. rumor spreading) is an effective way of data dissemination: imagine the situation where a rumor arises in town and people undertake gossiping-based actions to spread the rumor among the population [6]. There are two atomic types of gossiping protocols: “pull”: an uninformed node selects a message it has not possessed and requests it from a randomly selected neighboring node, and “push”: an informed node selects a message it possesses and sends it to a randomly selected neighboring node.
Gossip-based algorithms are promising solution for many of the next generation networks, due to their simplicity, robustness, flexibility, and scalability. Existing applications are numerous, such as consensus and averaging in sensor networks [7, 8], ad hoc message routing [9], peer-to-peer file distribution [10], and information diffusion in social networks [11, 12]. Extended versions of the basic gossiping protocol include algebraic gossip [13] and geographic gossip [14], but they have additional overheads on message complexity and geographic knowledge, and in this paper our attention is focused on the basic gossiping protocol.
Most analytical works on gossiping have dealt with high-probability bounds of the completion time. Supposing a static and connected network, the completion time of a gossiping protocol is the first time at which all nodes are informed. Several important classes of network topologies have been analyzed for gossiping of a single source with a single message, including complete graphs [6], general graphs and hypercubes [15], random graphs [15, 16], random geometric graphs [17], graphs with edge expansion [18], and graphs with vertex expansion [19]. Besides, gossiping of all sources each with a different single message has been considered in [10, 20].
On the other hand, the gossiping type of a single source with multiple messages has been treated in [10], for complete graphs. In practice, the multiple messages may be obtained by splitting a file into multiple units. It has been shown in [10] that, compared with single-message gossiping, gossiping with multiple messages significantly reduces the completion time. Complete graphs lack geometry and enable direct message passing between any two nodes. In this paper, we are hence motivated to study gossiping with multiple messages on more structured graphs. Networks with various types of structure are more general and realistic than complete graphs, and the studies on structured graphs bring in new challenges and insights into the gossiping problem. The key question we seek to answer is how much benefit message splitting brings in when the message passing is restricted by the network topology.
In this paper, we focus on a “sequential pull” protocol in which each node attempts to pull its desired messages sequentially following an indexing order. Our contributions are as follows.
We develop a novel “dependency graph” analysis technique for gossip spreading and leverage it to establish a high-probability upper bound of the completion time for line graphs. In a nutshell, our result indicates that, in a line graph of n nodes and with k messages, the high-probability completion time scales at most like as both n and k grow large, inferior to that for complete graphs [10], which is , but still drastically superior to that without message splitting [17], which is .
We apply the result for line graphs to several other network topologies, including ring graphs, general graphs with given diameter and maximum degree, grid graphs, and random geometric graphs.
We carry out numerical experiments to corroborate our analytical results.
The remaining part of this paper is organized as follows. In Section 2 we describe the sequential pull gossiping protocol. In Section 3 we establish the high-probability upper bound of the completion time on line graphs. In Section 4 we treat other classes of network topologies. In Section 5 we present numerical results. Finally Section 6 concludes this paper.
2. Pull-Based Gossiping Protocol
In general, a connected static network is represented as an undirected graph consisting of a set of nodes V and a set of edges E. Every node in V wishes to obtain an entire copy of a file, which has been split into multiple units, each of which as a message for gossiping. A pair of nodes may communicate directly with each other if and only if the nodes are connected by an edge in E. Time is slotted and a message can be transferred from a sender to a receiver within a time slot, which is called round throughout this paper. For each node, if a message is obtained in round t, it may send that message to one of its neighbors since round ; when obtaining all messages, a node is said to be informed, otherwise uninformed.
Similar to that in [20], we describe the protocol of pull-based gossiping with multiple messages by a random walk following a Markov chain. Initially, a single source node in G is endowed with k messages, indexed as . In each of the following rounds, every uninformed node u selects a message it has not possessed and contacts a neighbor v in its neighbor set with probability or contacts no neighbor with probability . If v is contacted by u and does possess the requested message, then u obtains that message successfully. If the messages are requested sequentially in order by every node, that is, each uninformed node always pulls the message with the smallest index it has not possessed, the gossiping protocol is called “sequential pull” with multiple messages [10]. Note that “sequential pull” may be an appropriate restriction in certain applications (e.g., with streaming/real-time nature), in which messages need to be sequentially accumulated for content reconstruction.
In particular, for a line graph , in which n nodes indexed as are sequentially placed from one endpoint to the other, the gossiping protocol can also be described as follows. Without loss of generality, assume that the endpoint node 1 is the source node. In each round, each uninformed node u pulls the message with the smallest index it has not possessed from its neighbor with probability . Throughout this paper, we focus on the case where , . Note that “gossiping with multiple messages on line graphs” can be leveraged to model the content distribution process of a multihopping data dissemination problem for sensor networks or for ad hoc networks; for example, see Section 5.
In the subsequent analysis, the main attention is paid to the completion timeT, which is the first time when all nodes in G are informed. Our goal is to establish a high-probability upper bound of T, that is, a quantity such that T does not exceed it with probability at least , for some constant , for any sufficiently large n.
3. Upper Bound of Completion Time on Line Graphs
In this section, we derive a high-probability upper bound of the completion time on line graphs, by a novel “dependency graph” technique. To the best of our knowledge, this technique has not been identified or used for analyzing gossiping in the literature. The result for line graphs, in company with complete graphs [10], reveals the potential benefit for message splitting to accelerate content distribution. Complete graphs and line graphs may be viewed as two extreme cases of graph topology, in that complete graphs have “no geometry” without message-passing constraints and line graphs have the “strongest geometry” with the most stringent message-passing constraints. Importantly note that the message dissemination process through gossiping protocols itself does not depend on the network topology; however, our analysis of the completion time is focused on a specific class of graphs and thus has the knowledge on the network topology.
3.1. Gossiping with Single Message
Before treating gossiping with multiple messages, we consider the single-message case, which provides a baseline for the multiple-message case to compare with.
Lemma 1.
Consider a line graph of n nodes and a single message, and let T denote the first time when all nodes are informed. For any , choose ; then one has, for all n,
Remark 1.
We see that as , and hence the high-probability upper bound of the completion time T is for a file with unit size. So, given a file with size of k units to be distributed on the network without message splitting, the completion time would be .
In order to prove Lemma 1, from [17, Lemma 4.3] (for a line graph, the completion time of gossiping with a single message is of the same magnitude for both “pull” and “push” based protocols), we can set , which is able to be done by choosing . In the following, we present a detailed proof of Lemma 1, since [17, Lemma 4.3] is only stated for the “push-” based single-message case and its proof is absent.
For , let denote the time that node i needs to successfully pull the message from node after node succeeds; then . Due to the memoryless nature of the gossiping process, , are independent and identically distributed (i.i.d.) random variables, and all of them obey the geometric distribution with parameter q.
Let , be m independent Poisson trials such that and , for all . Then, we have
since the event of means that at most Poisson trials have succeeded (i.e., with ) within m trials.
Let and (the value of might not be an integer, but it does not affect the magnitude of the asymptotic upper bound of gossiping's completion time), from (2) and Chernoff Bound [21, Theorem 4.5], we have
Take a step ahead and set ; then the minimum of is able to be obtained by . Therefore, the proof is completed.
3.2. Gossiping with Multiple Messages
If a file with size of k units is split into k messages and the sequential pull-based gossiping protocol is implemented, then each node may send messages to its neighbors without waiting until obtaining the entire file. This is the key idea to leverage message splitting for accelerating content distribution. In the following, we establish an upper bound of the completion time for this case.
Theorem 2.
Consider a line graph of n nodes and the protocol of sequential pull-based gossiping with k messages, and let T denote the first time when all nodes are informed. Denote and call it the degree of parallelism. Then one has, for all ,
Remark 2.
We see that a high-probability upper bound of the completion time in the multiple-message case is when both n and k are large enough. Recall that, in Section 3.1, the completion time with single-message gossiping without message splitting scales like . So we observe that the potential benefit by message splitting can be significant. For example, if , then the completion time without message splitting scales like , but with message splitting it scales like .
On the other hand, a high-probability upper bound of the completion time for complete graphs has been obtained in [10], and it scales like with n nodes and k messages (in [10] the bound is in fact derived when both “pull” and “push” operations are implemented in the gossiping process). It is no wonder that gossiping on complete graphs is much more efficient than on line graphs since there is no communication constraint when all nodes can directly communicate with each other, and such a performance gap is clearly revealed in the difference between the scaling behaviors.
The fundamental reasons on the superiority of the multiple-message gossiping with message splitting over the single-message gossiping without message splitting can be explained as follows. When a file with size of k units needs to be transmitted, each node can only send data to its neighbors after receiving the entire file in the single-message case. However, in the multiple-message case, the file can be split into k messages and each node can send messages to its neighbors without waiting until obtaining the entire file. The parallelism that neighboring nodes can simultaneously obtain different parts of a file can help to accelerate the content distribution.
Before proving Theorem 2, we introduce the key concept of “dependency graph” for gossiping with multiple messages.
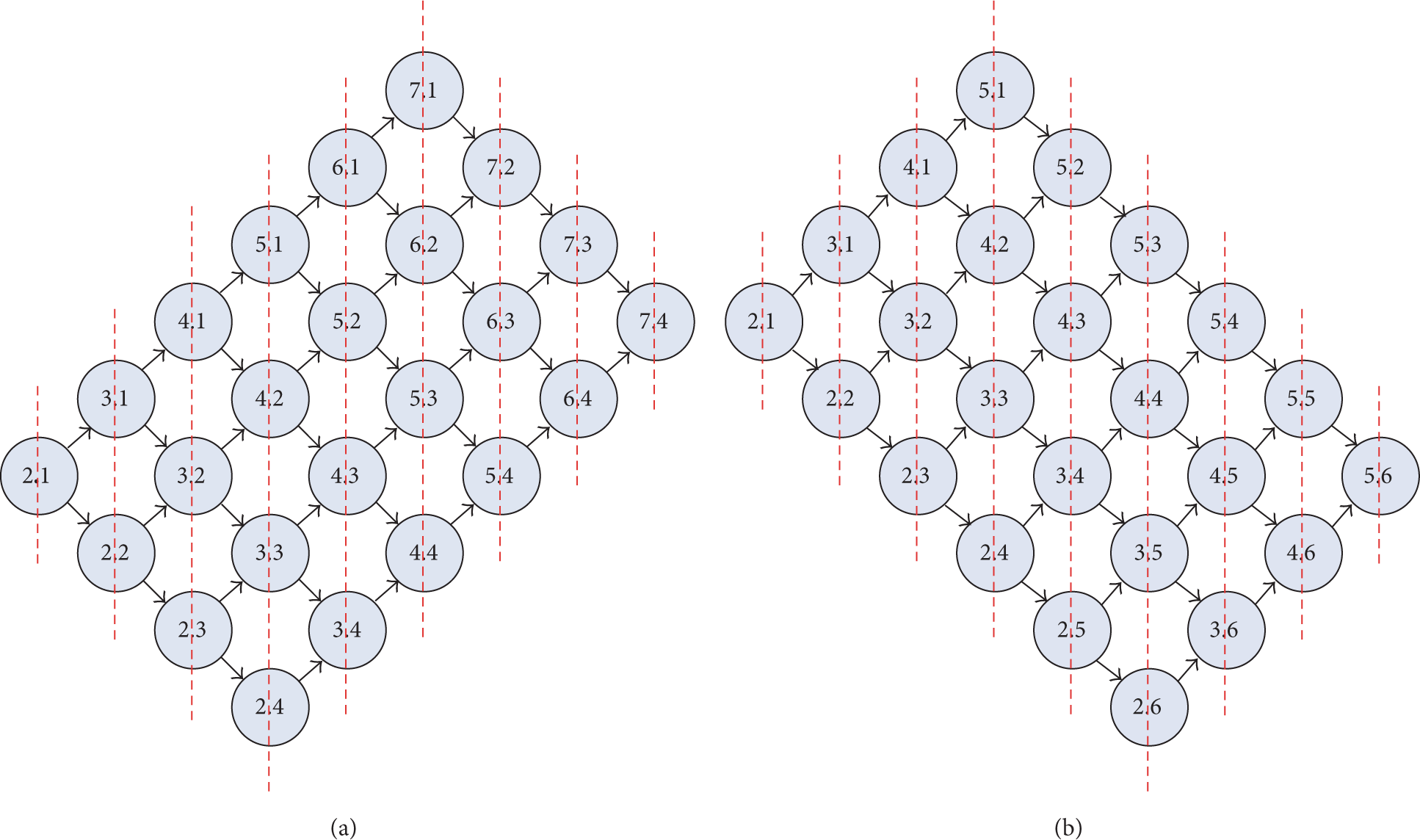
(1) Dependency Graph (See Figure 1). For and , let denote a node-message pair which indicates the event that node i is pulling message j. We say that a node-message pair is realized if the node has obtained the message. We may thus construct a directed graph whose nodes are all the node-message pairs and call it the dependency graph since it describes the dependency among all the node-message pairs. Specifically, for , it has (at most) two incoming edges, from and , respectively, meaning that node i can start to pull message j immediately after both events and are realized. Take Figure 1 for example: the event has to be realized in the first place; for each of the remaining node-message pairs, it can be realized only after its predecessor pairs, that is, the pairs directing to it, have already been realized.
Illustration of the dependency graph of all node-message pairs. (a) End-to-end length of line graph is greater than the number of messages . (b) End-to-end length of line graph is smaller than the number of messages .
For the dependency graph, we group the node-message pairs into multiple groups, so that two pairs and are in the same group if and only if . For a line graph of n nodes and k messages, we thus have groups, indexed by the node-message-index-sum from 3 to . Note that a group has at most node-message pairs and the quantity is called the degree of parallelism.
Now consider a genie-aided gossiping schedule, which is based on the sequential pull-based gossiping protocol in Section 2, so that a genie enforces that only after all the node-message pairs in group s have been realized, the gossiping processes for the pairs in group can start, for each . Apparently the resulting completion time T in the genie-aided schedule is stochastically not smaller than the actual completion time. In the following, we will first upper-bound the time for the node-message pairs in a group to be realized, and with that, we will prove Theorem 2 subsequently.
(2) Completion Time for Each Group
Lemma 3.
Consider the genie-aided gossiping schedule described above, and let denote the time for all the node-message pairs in a group to be realized. Then, for all ,
Remark 3.
We see that a high-probability upper bound of the completion time for each group is when both n and k are large enough. In the following, we will see that the total completion time for the multiple-message case is the summation over all these groups and the quantity in the term of (5) is the union bound factor for the summation.
Let denote the first time when a node-message pair is realized; that is, a node successfully pulls its desired message. Since a node's attempt to pull from the predecessor node occurs with probability q in the gossiping protocol, we have (the value of might not be an integer, but it does not affect the magnitude of the asymptotic upper bound of )
Now, taking the union bound over all the node-message pairs in one specific group completes the proof, since each group has at most m node-message pairs and the realizations of those pairs are mutually independent.
(3) Completion Time for Gossiping on Line Graphs. We are now ready to prove Theorem 2.
First, consider the case where . In the dependency graph (see, e.g., Figure 1(a)), all node-message pairs are grouped as
Similarly, for the case where (see, e.g., Figure 1(b)), all node-message pairs are grouped as
For both of these two cases, note that there are totally groups and that the number of node-message pairs in each group is at most m. Using Lemma 3, we know that, in each group, all the node-message pairs are realized within time with probability greater than .
Since in the genie-aided schedule the gossiping processes are executed group by group sequentially, with groups, we have
Eventually, taking the union bound leads to the fact that (9) holds with probability greater than , and thus the proof of Theorem 2 is completed.
4. Completion Time on Several Structured Networks
In this section, we extend the result for line graphs to several other classes of network topologies. The analysis of line graphs is instrumental for establishing completion time bounds for other classes of graphs; see, for example, [15, 17]. We define as the high-probability completion time of gossiping with multiple messages on network graph G, if all nodes obtain all messages within rounds with probability at least for some constant and fixed constant , for any sufficiently large n.
For a connected network of n nodes with maximum degree , assume that each node u pulls messages from any of its neighbors with equal probability ( is the degree of u). In order to apply Theorem 2, consider the shortest path from the source node to another node u, denoting the length of the shortest path by . Along this shortest path, in each round, each node pulls message from its predecessor node with probability at least . So, from Theorem 2, the completion time for node u to obtain all the k messages is upper-bounded by , with probability at least . In the following, we apply the result to serval classes of graphs.
(1) Ring Graphs. A ring graph of n nodes can be simply divided into two equal-length line graphs each of length , and its maximum degree is . Therefore, we have the following corollary.
Corollary 4.
For a ring graph of n nodes, the sequential pull-based gossiping protocol with k messages behaves like
for any .
(2) General Graphs with Fixed Diameter and Maximum Degree. For a general connected graph with diameter d and maximum degree , a high-probability upper bound of the completion time in the single-message case is [15]. Now, for any arbitrary node in the network, from our discussion above and Theorem 2, the completion time for that node to obtain all the k messages is upper bounded by , with probability at least . Taking the union bound over all the n nodes in the network hence leads to the following corollary.
Corollary 5.
For a general graph of n nodes with diameter d and maximum degree , the sequential pull-based gossiping protocol with k messages behaves like
for any .
(3) Grid Graphs. For a grid graph of n nodes on a lattice, by setting and in (11), we have the following corollary.
Corollary 6.
For a grid graph of n nodes on a lattice, the sequential pull-based gossiping protocol with k messages behaves like
for any .
(4) Random Geometric Graphs. A random geometric graph is constructed by placing n nodes independently and uniformly at random in square , where any pair of two nodes are connected by an edge if and only if their Euclidean distance is at most r. From [17], the diameter of the largest connected component of is and all nodes have degree smaller than when . Therefore, the following corollary follows by setting and in (11).
Corollary 7.
For a random geometric graph with , under the sequential pull-based gossiping protocol with k messages, the high-probability completion time of the largest connected component in behaves like
for any .
5. Simulations
In this section, we carry out experiments to validate our analytical results against the sequential pull-based gossiping with multiple messages. We treat a multihopping data dissemination problem for sensor networks or for ad hoc networks, in which the content distribution can be exactly modeled by a multiple-message gossiping process on line graphs as well.
Consider a multihopping network, where a source node wishes to spread a file with size of k units to a destination node . The file is equally split into k messages, indexed as . Suppose the routing path from to is known and consists of n nodes. These nodes are sequentially indexed as from the source to the destination. Time is slotted and a message can be transferred from a sender to a receiver within a round. In each round, each uninformed node u requests the message with the smallest index it has not possessed from its neighbor . All the communications between neighbors are assumed to fail with probability , since there may be wireless error or the requested nodes may be busy. The protocol overhead is assumed to be encapsulated by physical-layer design, which is not considered herein. Recall the gossiping protocol described in Section 2, and then we see that this multihopping data dissemination can be exactly modeled by a multiple-message gossiping process on a line graph.
During our experiments, we let the multiple-message gossiping process be run for 1000000 times and record the completion time. The line graph consists of n nodes, and one endpoint is endowed with k messages. The successful probability q of communications from senders to receivers is 0.5 for all experiment runs. The pseudocode of the simulation using the multiple-message gossiping protocol is presented in Algorithm 1.
Algorithm 1: Gossiping(G; k; q).
fordo
Initialization: a node in G is informed at round .
while not all nodes in G are informed do
.
for each uninformed node udo
u selects a neighbor v from its neighbor set with probability .
u selects a message with the smallest index it has not possessed.
u attempts to pull the message i from the neighbor v.
ifv does possess ithen
u becomes informed at the beginning of round .
end if
end for
end while
Record the completion time T.
end for
The simulation results on gossiping's completion time are demonstrated in Figures 2 and 3, where the theoretical results are also presented and all the curves are plotted in the log-log scale. In Figure 2, k is fixed to be 100 and n ranges from 50 to 150; and in Figure 3, n is fixed to be 100 and k ranges from 50 to 150. In both figures, the curve of “” presents the theoretical completion time of the naive gossiping without message splitting, the curve of “” presents the theoretical completion time of the multiple-message gossiping predicted by Theorem 2, and the curve of “gossiping” presents the maximum value of the completion time recorded from our experiments. From the simulation results, we see that the benefit by message splitting is significant for accelerating data dissemination, and the upper bound of the multiple-message gossiping protocol established in Theorem 2 is validated as well. However, there is still gap between the analytical upper bound and the simulated completion time. It is an open issue to find a tighter upper bound of the completion time for gossiping with multiple messages on line graphs.
Log-log plot of gossiping's completion time versus node number (, ).
Log-log plot of gossiping's completion time versus message number (, ).
6. Conclusions
In this paper, we have investigated the problem of gossiping with multiple messages on structured networks so as to shed insight into the behavior of the multiple-message gossiping. We have developed the “dependency graph” analytical technique and further derived an upper bound of the high-probability completion time on line graphs. The potential benefit has been revealed for message splitting to accelerate content distribution through networks, and the result for line graphs has also been further extended to several other classes of network topologies.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
The work has been supported by National Basic Research Program of China (973 Program) through Grant 2012CB316004, SRFDP and RGC ERG Joint Research Scheme through Grant 20133402140001, National Natural Science Foundation of China through Grant 61379003, and the 100 Talents Program of Chinese Academy of Sciences.
References
1.
SelvakennedyS.SinnappanS.An adaptive data dissemination strategy for wireless sensor networksInternational Journal of Distributed Sensor Networks200731234010.1080/155013206010677252-s2.0-34248163113
2.
BoldriniC.ContiM.PassarellaA.ContentPlace: social-aware data dissemination in opportunistic networksProceedings of the 11th ACM International Conference on Modeling, Analysis, and Simulation of Wireless and Mobile Systems (MSWiM '08)October 200820321010.1145/1454503.14545412-s2.0-63449110577
3.
GaoW.CaoG.User-centric data dissemination in disruption tolerant networksProceedings of the 30th IEEE International Conference on Computer Communications (INFOCOM ’11)April 2011Shanghai, China3119312710.1109/INFCOM.2011.5935157
4.
LiZ.XieG.HwangK.LiZ.Churn-resilient protocol for massive data dissemination in P2P networksIEEE Transactions on Parallel and Distributed Systems20112281342134910.1109/TPDS.2011.152-s2.0-79959702172
5.
ZhaoH.ZhuJ.Efficient data dissemination in urban VANETs: parked vehicles are natural infrastructuresInternational Journal of Distributed Sensor Networks201220121115179510.1155/2012/151795
6.
FriezeA. M.GrimmettG. R.The shortest-path problem for graphs with random arc-lengthsDiscrete Applied Mathematics198510157772-s2.0-002182592610.1016/0166-218X(85)90059-9MR770869
7.
TangJ.DaiS.LiJ.LiS.Gossip-based scalable directed diffusion for wireless sensor networksInternational Journal of Communication Systems201124111418143010.1002/dac.12242-s2.0-81255134321
8.
HuangZ.HuangQ.To reach consensus using uninorm aggregation operator: a gossip-based protocolInternational Journal of Intelligent Systems201227437539510.1002/int.215282-s2.0-84857636905
9.
VahdatA.BeckerD.Epidemic routing for partially connected ad hoc networks2000CS-200006Duke University
10.
SanghaviS.HajekB.MassoulieL.Gossiping with multiple messagesIEEE Transactions on Information Theory20075312464046542-s2.0-5154909075310.1109/TIT.2007.909171MR2446928
11.
LindP. G.Da SilvaL. R.AndradeJ. S.HerrmannH. J.Spreading gossip in social networksPhysical Review E: Statistical, Nonlinear, and Soft Matter Physics200776303611710.1103/PhysRevE.76.0361172-s2.0-34848869973
12.
ChierichettiF.LattanziS.PanconesiA.Rumor spreading in social networksTheoretical Computer Science2011412242602261010.1016/j.tcs.2010.11.001MR2828337ZBL1218.680422-s2.0-79954897828
13.
DebS.MédardM.ChouteC.Algebraic gossip: a network coding approach to optimal multiple rumor mongeringIEEE Transactions on Information Theory20065262486250710.1109/TIT.2006.874532MR22385552-s2.0-33745154114
14.
DimakisA. D.SarwateA. D.WainwrightM. J.Geographic gossip: efficient averaging for sensor networksIEEE Transactions on Signal Processing20085631205121610.1109/TSP.2007.908946MR24511582-s2.0-40749127156
15.
FeigeU.PelegD.RaghavanP.UpfalE.Randomized broadcast in networksRandom Structures and Algorithms199014447460MR113843510.1002/rsa.3240010406
16.
ElsässerR.On the communication complexity of randomized broadcasting in random-like graphsProceedings of the 18th Annual ACM Symposium on Parallelism in Algorithms and Architectures (SPAA '06)August 20061481572-s2.0-33749567945
17.
BradonjićM.ElsässerR.FriedrichT.SauerwaldT.StaufferA.Efficient broadcast on random geometric graphsProceedings of the 21st Annual ACM-SIAM Symposium on Discrete Algorithms (SODA '10)201014121421
18.
SauerwaldT.On mixing and edge expansion properties in randomized broadcastingAlgorithmica2010561518810.1007/s00453-008-9245-4MR25765342-s2.0-73349116553
19.
GiakkoupisG.SauerwaldT.Rumor spreading and vertex expansionProceedings of 23rd Annual ACM-SIAM Symposium on Discrete Algorithms (SODA'12)201216231641
20.
ShahD.Gossip Algorithms2009Now Publishers
21.
MitzenmacherM.UpfalE.Probability and Computing: Randomized Algorithms and Probabilistic Analysis2005Cambridge University Press