
Abstract
Several studies present methods to economize energy in wireless sensor networks (WSNs) which is one of the most confining resources in these systems. This paper presents a bioinspired, cellular automata (CA) based model for constructing data trees that connect all nodes with a sink node. Nonetheless, the proposed model takes into consideration not only the proximity between two nodes but also their remaining available energy. Consequently, by avoiding nodes with nearly depleted energy sources, the life time of the network can be prolonged. The plasmodium of Physarum polycephalum is the inspiration for the proposed model, as it has proved its robustness in graphically expressed problems. Moreover, CAs are able to encapsulate the parallel dynamics of the model and, thus, achieve a very fast execution.
1. Introduction
Data acquisition in regions which are wider than the active radius of any sensing device is possible with WSNs. The fact that WSNs are effective solutions for these kinds of applications is based on advances in production of hardware components and specialized robust communication protocols. Some of these applications are located in urban environments, while others have military use [1] or are located in hostile, hard-to-reach terrains, like forests or underwater. A node of a WSN is, usually, a simple sensor-based system that is capable of basic communication. In order to keep the cost low and given the fact that there are large amounts of nodes, there are many restrictions in the nodes’ resources. These restrictions apply on computational abilities, limited communication range, and battery capacity [2]. As a result, several techniques [3] have been proposed to make the best out of the given resources, based on the application requirements. One of the methods, attracting lots of attention, is energy efficiency optimization and fair energy consumption in nodes along the network, in order to prolong its lifetime.
The plasmodium (vegetative life cycle phase) of Physarum polycephalum, also known as slime mould, has displayed its computational abilities, basically, in geographical represented problems [4–6] and lately has been used in several other problems [7, 8]. Moreover, it is interesting that the computational abilities are inherent to its behavior and can be considered as the result of distributed decision making, due to the fact that the plasmodium lacks a central nervous system.
When inoculated in an environment with distributed sources of food, the slime mould tries to span all sources of food, yet, optimizing its energy spent in scouting the space and transportation of nutrients and metabolites. The Physarum builds protoplasmic networks that closely approximate spanning trees on the sources of nutrients.
A spanning tree of a finite planar set is a connected, undirected, acyclic planar graph, whose vertices are points of the planar set; every point of the given planar set is connected to the tree (but no cycles or loops are formed). The tree is a minimal spanning tree when the sum of its edge lengths is minimal. Original algorithms for computing minimum spanning trees are described in [9, 10]. Hundreds, if not thousands of papers, were published in the last sixty years, mostly improving the original algorithms or adapting them to multiprocessor computing systems.
There are some “unconventional” solutions of the spanning tree problem. Spanning trees can be approximated by random walks, electrical fields, social insects, and reaction-diffusion chemical systems [11–13]. None of these unconventional algorithms, however, offered an experimental realization. In [14] we proposed an algorithm for computing a spanning tree of a finite planar set based on formation of a neurite tree in a development of a single neuron. The algorithm used spreading of neuron processes and competition between different processes for marked sites of a space was utilized.
The algorithm proved to be valuable in implementation of spanning tree building strategies with the slime mould P. polycephalum [15]: data points, to be spanned by a tree, were represented by oat flakes and the slime is inoculated at one of the flakes. The slime mould propagates along gradients of chemoattractants emitted by oat flakes and spans them with a network of protoplasmic tubes. Subject of infrequently duplicated links, which is normal for results produced by a living computing substrate, the trees approximated by slime mould matched those developed by classical algorithms. An example of constructing an Euclidean spanning tree is shown in Figure 1. Planar data set is represented by oat flakes (on a nonnutrient agar gel) placed in sites “a” to “g.” The slime mould is inoculated in site “a.” In first 12 h of experiment the slime mould recovers from stress of inoculation and propagates from “a” to “b.” In next 12 h the slime mould follows gradients of chemoattractants emitted by flakes “d” and “c” and colonizes them.

Snapshot of experimental laboratory construction of a spanning tree with live slime mould P. polycephalum. Planar data points are represented by flakes “a”–“g.” The slime mould is inoculated in the site “a.” The snapshot is taken 24 hours after inoculation.
Nonetheless, the plasmodium of P. polycephalum is not only used in biological experiments but also has inspired software [16, 17] and hardware based [16, 18] algorithms for graphically expressed problems.
The routing problem in a WSN is an example of graphically expressed problem. Provided that the nodes collect data from their local regions and in given time intervals, these data have to be collected, processed, and interpreted. That is the role of a specialized node, normally located in one of the borders or on the center of the total target area, named sink node or base station. All nodes propagate their data to the sink either directly, when they are closely located, or using other nodes as intermediate hops. Consequently, the problem of constructing a communication tree for aggregating data emerges that must be optimized in terms of energy. This problem is proved to be NP-complete [19].
In this paper, we propose a model of designing a data aggregation tree in a WSN, based on the computing abilities demonstrated by the plasmodium of P. polycephalum. The model is designed using CAs as a mathematical tool to represent the local dynamics realized in the plasmodium of P. polycephalum. Consequently, the parallel nature of the algorithm is fully utilized with the use of CA theory. The remainder of this paper is organized as follows. Section 2 describes some related work presented in the field. In Section 3 the basics of CA theory are presented and in Section 4 the proposed model is described. Finally, Section 5 illustrates the results of the model and Section 6 concludes the paper.
2. Related Work
In the literature there are many studies investigating energy efficiency in WSNs. One method of prolonging the lifetime of a sensor network, that is usually tested, is the dynamic scheduling of the nodes’ transmission between active and inactive states. In [3], several mechanisms are surveyed and categorized depending on the networks’ design assumptions and objectives.
Another technique of economizing energy in WSN is the design of a data tree used as a routing guide. The design of a data tree is focused on minimizing the communication energy costs of the network. In [19], the authors describe the problems of constructing a data aggregation tree with minimum energy cost, prove its hardness, and propose some approximation algorithms. More specifically, the authors conclude that this problem is NP-complete.
Nonetheless, as some scientists use bioinspired models to tackle problems that cannot be solved by conventional methods, the same may be applied for problems found in WSN. More specifically, in [20] a Physarum inspired algorithm is proposed. The authors tackle the problem of minimal exposure path in WSN, meaning the identification of the path through the sensors deployment field from one target point to another, such that the sensors have the least coverage of the traveled path. In other words, the authors use insights from the mathematical model presented in [21], to optimize the process of finding the worst-case coverage path in the area of the network.
3. Cellular Automata Basics
So far, Physarum's computation behavior was often compartmentalized different behaviors, in an attempt to simplify the huge overall modeling task, providing, for example, different representations and mechanisms of growth, movement, internal oscillations, and network adaptation. The different modeling approaches have, also, various implementations, from the purely spatial CA models to mathematical representations of flux canalization, oscillatory behavior, two-variable Oregonator model of Belousov-Zhabotinsky (BZ) medium, and path length as found in literature [16–18, 20–27].
In this paper, we are taking advantage of the inherent parallelism and the ubiquitous modeling properties of CA for modeling slime mould. CAs were originally proposed by von Neumann [28] as formal models of self-reproducing organisms. Following a suggestion by Ulam [29], von Neumann adopted a fully discrete approach, in which space, time, and even the dynamical variables were defined as discrete. CAs can be considered as dynamical systems in which space and time are discrete and interactions are local. They have been applied to many real problems in physics, chemistry, biology, or geology and, also, to computational or artificial problems.
In this section a formal definition of a CA will be presented [16]. In general, a CA requires a regular lattice of cells covering a portion of a d-dimensional space; a set a rule
In the above definition, the rule
The neighbourhood of cell
CAs have sufficient expressive dynamics to represent phenomena of arbitrary complexity and at the same time can be simulated exactly by digital computers, because of their intrinsic discreteness; that is, the topology of the simulated object is reproduced in the simulating device. CA can be considered as excellent computational objects, per se, because they show us how to generate and manage complexity using very simple rules of dynamical transitions [31, 32]. CAs are ubiquitous: they are mathematical models of computation and computer models of natural systems [31–34]. CAs research is an interdisciplinary field, whose general goal might be summarised as the quest for theoretical constructs, computational solutions, and practical implementations of novel and powerful models of discrete world [30–36]. The CA approach is consistent with the modern notion of unified space-time. In computer science, space corresponds to memory and time to processing unit. In CA, memory (CA cell state) and processing unit (CA local rule) are inseparably related to a CA cell [16, 17, 27]. Models based on CA lead to algorithms which are fast when implemented on serial computers, because they exploit the inherent parallelism of the CA structure [16–18, 26, 27]. Furthermore, they can easily handle complicated boundary and initial conditions, inhomogeneities, and anisotropies.
4. Bioinspired Cellular Automata Based Routing Model
In biological experiments, when the plasmodium is introduced to an exploring region in a starting point (SP), it starts searching for nutrients. As with other eukaryotic organisms, the P. polycephalum plasmodium exhibits patterns of guided movement (taxes) towards/away from sources of stimulation. Typically, slime mould is stimulated in experimental situations by providing a number of spatially distributed chemoattractant nutrient sources (NSs) towards which it will migrate (chemotaxis). This is thought to be actualised by a vast distributed array of membrane-bound sensor proteins, most likely metabotropic G-protein coupled receptors [37], which stud the surface of the plasmodium and respond to the detection of chemoattractant ligands by initiating intraplasmodial chemical signaling cascades which either stimulate or suppress metabolic and transcriptional processes [38]. This, in turn, drives tip growth in the direction of the highest nutrient density by initiating pseudopodium formation (directed actin cytoskeleton assembly, membrane synthesis, etc.). Plasmodial sensing is continuous, pan-directional, and multisensorial (optical, temperature, etc.) and the actions of each receptor occur concurrently.
Via the combined action of amoeboid tip-growth and contraction of muscle proteins which shuttle the contents of the cytoplasm in the direction of movement, the plasmodium forms a network of tubular structures between all NSs, as illustrated in Figure 2, which typically assumes a highly optimised topology [5]. When being at rest, the fluid contents of the cytoplasm oscillate rhythmically, distributing internalised food, organelles, and intraplasmodial chemical signalling compounds. Thus, fluid movements within the plasmodium are subjected to dynamically optimizing alternations.
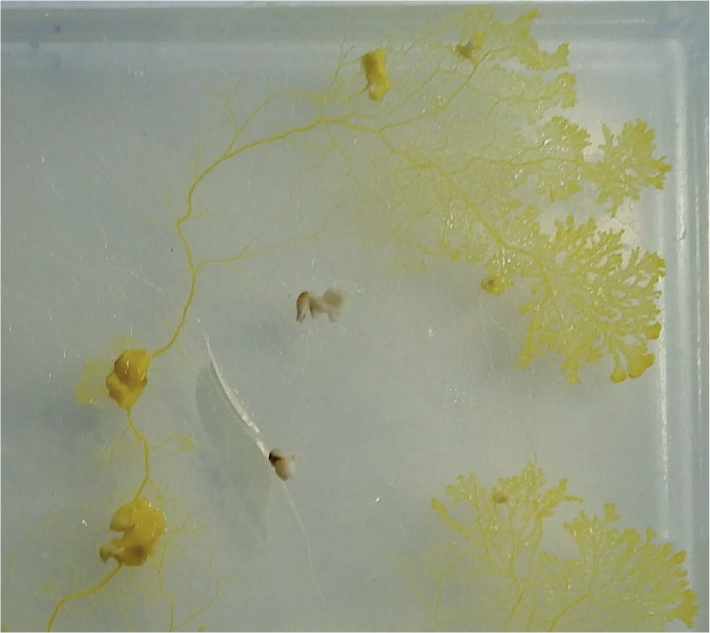
Plasmodium of P. polycephalum cultivating on a 2% nonnutrient agar gel. Note the tubular topology of the network as it links multiple nutrient sources (oat flakes).
As a result, there is an apparent analogy in the biological experiments using P. polycephalum [6] with the construction of data trees in WSN. The way that the plasmodium spans over all available NSs can guide the connectivity of each node to the next hop. NSs can represent the available sensor nodes. SP can be considered as the sink node that receives all the sensed data. Moreover, the tubular network designed by the plasmodium is representing the wireless connection between nodes. The available remaining energy in each node can be considered with respect to the amount or quality of NSs and, thus, optimization of the network in terms of energy efficiency can be achieved. That will insert an energy factor to the route designing method, in conjunction with the proximity factor. The procedures of the model and the way the energy residue is considered are described here.
Note here that, for the purpose of the presented model, the networks studied are subjected to certain design assumptions. Firstly, we assume limited sensor energy supply and an objective of maintaining a long lifetime of the network. Despite that, the sink node, base station, is regarded as a different mode node, in order to gather all data. Moreover all the nodes, other than the sink, are arranged in a nonhierarchical network; that is, they have the same functionality and role. Nonetheless, the placement mechanism of the nodes is not constraining for the model presented. Thus it can be used in randomly or uniformly distributed nodes. The nodes are considered to be stationary along all the sensing intervals. Finally, the sensing area and transmission range are sufficient to inquire coverage and connectivity for the targeted applications.
The locations of the nodes must be known for the process of the model. Consequently, the locations have to be either predefined for the deployment of the nodes or obtained by using a global positioning system (GPS) for every individual node. However, the inclusion of GPS hardware to every node will increase the total installation cost. Nevertheless, there are studies [39] that present approaches for accurately localization of the nodes of a WSN, using only connectivity information.
Software and hardware models [16–18, 26, 27] were used to produce computerized results comparable to the networks constructed by the plasmodium in the laboratory experiments. As a result, a modified model based on these models can be used to construct data trees in WSNs in reasonable time periods. As the model is based on CA theory, the area of the laboratory experiment, that will be simulated, is defined as a square grid, divided into identical square cells. These cells are categorized into four groups: available and unavailable space for exploration by the plasmodium, nutrient sources (NSs), and starting points (SPs).
The model is using the Moore neighborhood which for the cell
The first procedure of the model is setting some parameters and acquiring the topology of the experiment. The topology of the sensor nodes may be predefined or can be obtained by GPS or other techniques, as described previously. The parameters that need to be set are: the length of the CA grid (which can take any integer value), the parameters of the diffusion equations for “Physarum mass” ( the minimum the consumption ( the attraction of Physarum ( the threshold of “Physarum mass” (
The procedure that follows the initialization is the application of diffusion equations for PM (1) and CHA (4) parameters for 50 time steps in all the cells of the lattice that represent the available space. Equation (1) represents the exploration of the available space by the plasmodium which is affected by chemoattractants. Equation (4) represents the diffusion of chemoattractants from the NSs in the available space. Equations (2) and (5) depict that the parameters





Having applied the diffusion equations for 50 time steps, the operation of designing the tubular network takes place, if the parameter
However, if no NS reaches the value of
That way a bioinspired optimized network is designed using only the distances between the NSs or the sensor nodes. Nonetheless, in order to insert the factor of energy residue to the algorithm, the last procedure is appropriately modified. In detail, when a sensor node reaches a critical energy residue, namely, having not enough energy to transmit the data of other nodes as an intermediate hop, it notifies the base station for its state. As a result, when the NS that represents the node whose threshold of residue energy is surpassed is covered with the value of
5. Model Results
In order to evaluate the efficiency of the resulting networks of the bioinspired CA based model, randomly deployed distributions of 20, 40, and 60 nodes are evaluated. For the data collection process, a sink is located in the east border of the WSN for each of the three distributions. In Figure 3 the aforementioned distributions are depicted; namely, the black dot illustrates the location of the sink node and the blue dots illustrate the locations of the sensing nodes. The topologies of the nodes are used as input for the model, with the sink node represented as the SP and all the other nodes represented as NSs. Furthermore, the initial parameters set for the model are illustrated in Table 1.
Parameters’ values for the CA model.


Examples of WSNs to evaluate the proposed model with (a) 20, (b) 40, and (c) 60 sensor nodes randomly distributed.
The results of the model after 1500 time steps for the three WSNs are illustrated in Figure 4. The resultant data tree, having the sink node as a root, is developed based only on the distances between the nodes. In specific, each node is connected with a single edge with the nearest node that, after appropriate number of hops, is connected with the sink node.
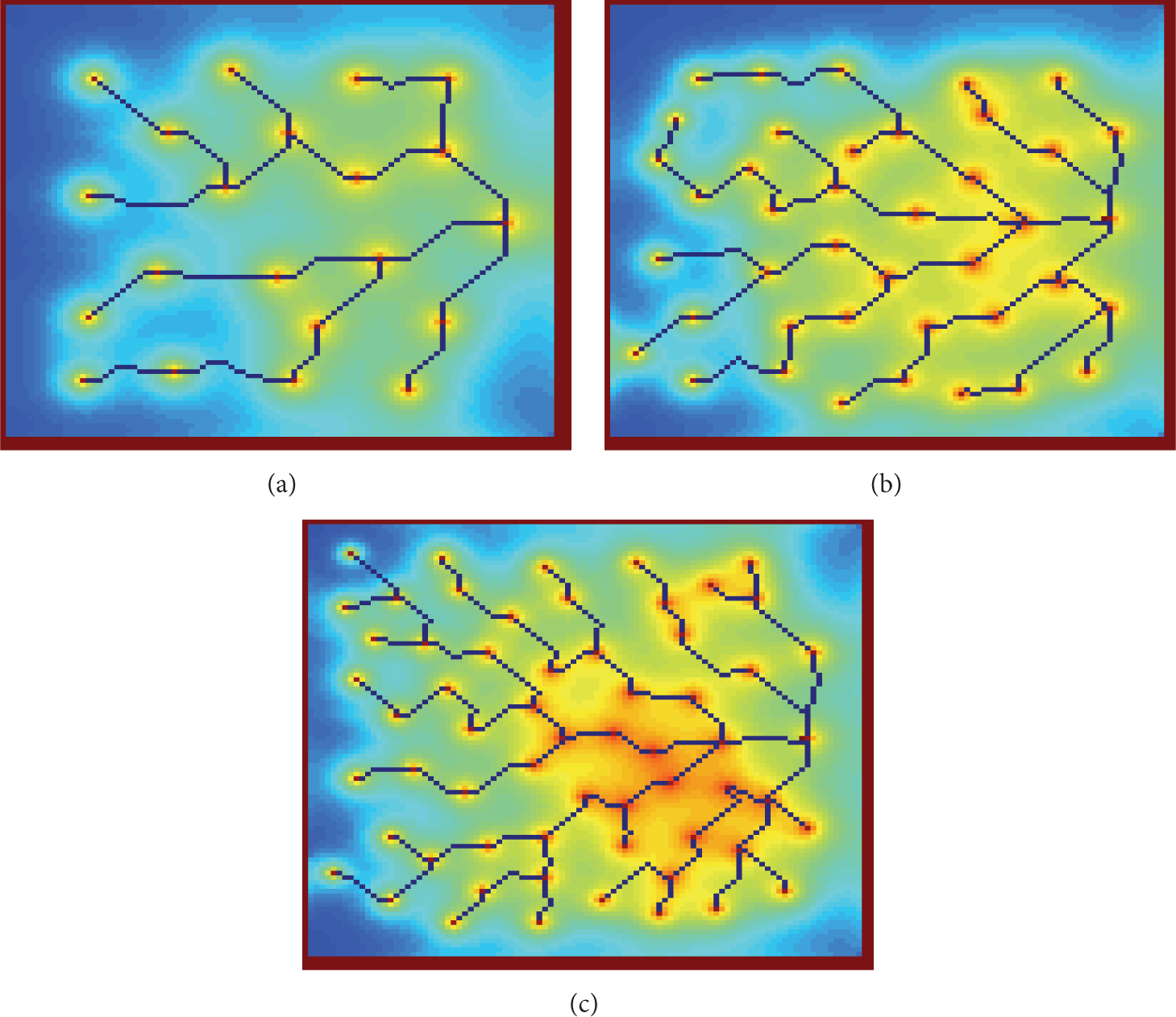
Results provided by the proposed model for networks with (a) 20, (b) 40, and (c) 60 sensor nodes after 1500 time steps.
It is noteworthy that despite the increasing density of the sensor nodes, the data tree is drawn after 1500 time steps for all the examples of WSN depicted in Figure 3. To the best of authors’ knowledge, the execution time of the existing routing algorithms for WSNs [40] is depending on the number of the nodes. On the contrary, the execution time of the proposed model is determined by the CA grid dimensions which can be retained while the number of nodes increases. Only when the amount of nodes is not appropriately represented by the current CA grid, its expansion is considered necessary.
To examine the model's response to the existence of a node with lower energy residue than the threshold, the WSN with 20 nodes is examined and the results are illustrated in Figure 5. For each instance, the node that has energy residue lower than the threshold is indicated with a red arrow. It can be observed that the aforementioned node is connected with its next hop but is not an intermediate hop for any other node. On the other hand the connections of the other nodes are rerouted around the node with low energy residue. Moreover, the most interesting fact is that changes occur deeper in the data tree. What is more intriguing is that these changes are not delivered by a centralized algorithm, but from the distributed computations occurring throughout the grid of CA.
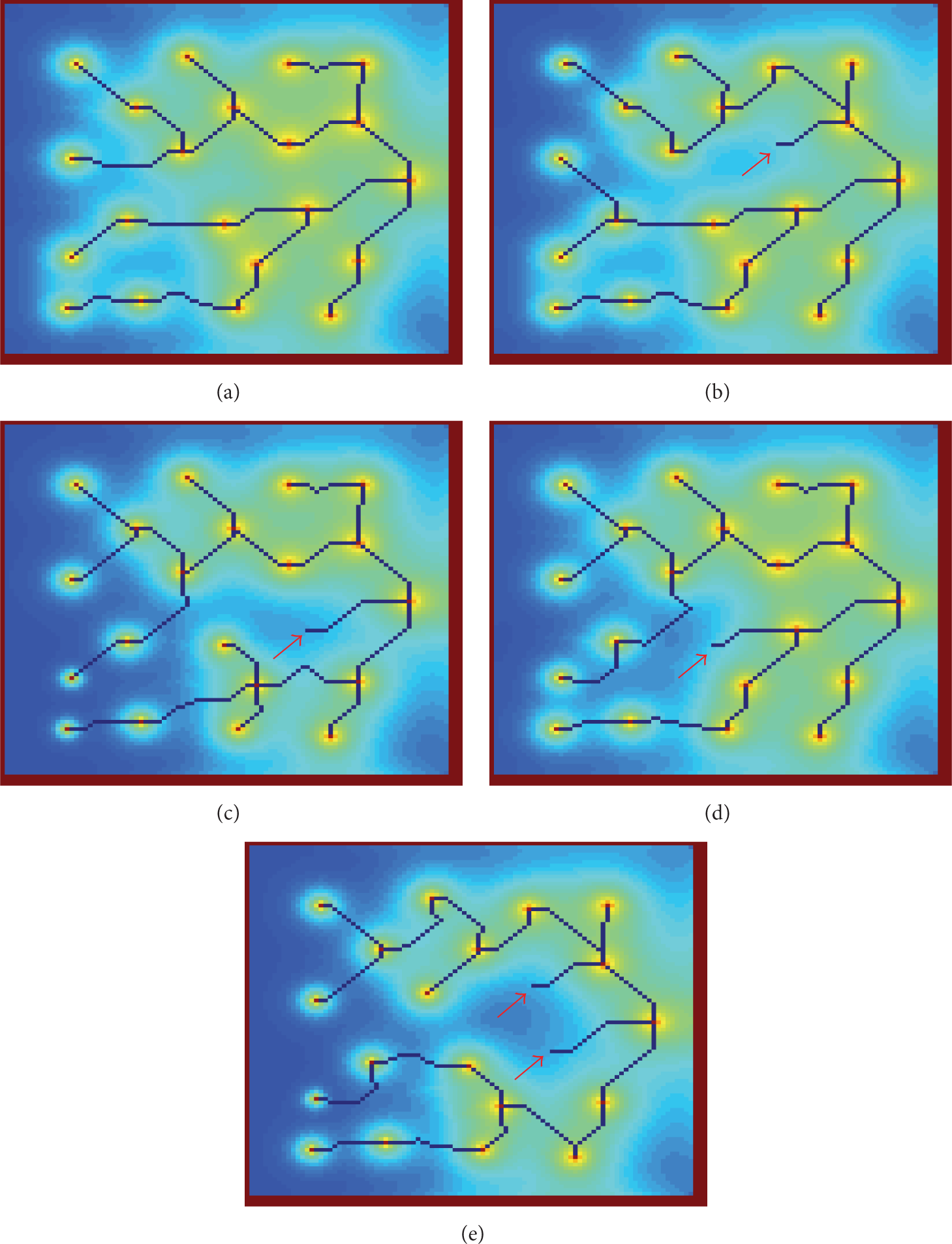
Results of the algorithm on the WSN with 20 sensor node randomly distributed, (a) with all nodes having energy over the threshold, (b), (c), and (d) with one node, indicated with red arrows, having lower energy than the threshold and (e) with two nodes having lower energy than the threshold.
Finally, the resulting data tree designed by the model, when two nodes have energy residue lower than the threshold is depicted in Figure 5(e). These two nodes are indicated in Figure 5(e) with two red arrows. Despite the fact that two out of the four directly adjacent to the sink nodes have nearly depleted their energy sources and have to be bypassed, the model designs a tree routed around the low energy nodes.
6. Conclusions
One of the most confining factors in WSNs is the energy consumption, as the networks are deployed in hostile, hard-to-reach terrains, and their energy source; mainly batteries cannot be recharged or replaced. Thus, many techniques target energy optimization of the networks, in order to maintain a long lifetime. Moreover, if sensors transmit data packets guided by a tree, they economize computational costs for retaining routing tables. Consequently, here we propose a bioinspired, CA based model to design a data tree for a WSN that takes into consideration energy residue and the nodes’ proximity.
The inspiration of the model has been the plasmodium of P. polycephalum that has proved its computational capacity in several problems. Based on our previously presented [16–18] studies, a CA model is presented that takes advantage of the similarity between the behavior of P. polycephalum spanning distributed NSs and the concepts of constructing data trees in WSNs. Moreover, an alternation to our previous models enables bypassing the nodes with low energy residue as it should be done in WSNs to prolong their lifetime.
Furthermore, as routing algorithms have to be executed frequently, namely, every time the network is subjected to energy changes, the algorithm's execution time and power consumption are of paramount significance. Given that the proposed model is based on CA, it can be easily implemented on dedicated hardware that is more power efficient compared to general purpose processing units. Moreover, regardless of the fact that the required diffusion steps are plenty, the hardware implementation of the algorithm [16, 17] produces a fitting solution for any real-time application. More specifically as debated in [17], implementing the algorithm in hardware circuitry takes full advantage of its parallel nature and, thus, significantly accelerates its execution.
Note that, although there are no experiments presented here with denser sensor networks, the applicability of the model to such networks is trivial. The model draws the appropriate connections for denser networks without any change in the algorithm, while the execution time is burdened only due to the inevitable larger CA lattice. The longer execution is a result of the fact that the simulated plasmodium will need more time to reach from one border of the lattice to the other. As illustrated in the previous section, experiments with variable number of nodes, but with the same grid dimensions, need the same time steps to provide final results. However, when the model is implemented in hardware and runs in parallel mode, the deceleration of the execution will have considerably less impact on its execution time period.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.