
Abstract
Pervasive computing is converging with cloud computing which becomes pervasive cloud computing as an emerging computing paradigm. Users can run their applications or tasks in pervasive cloud environment in order to gain better execution efficiency and performance leveraging powerful computing and storage capacities of pervasive clouds through task migration. During task migration, there are possibly a number of conflicting objectives to be considered when making migration decisions, such as less energy consumption and quick response, in order to find an optimal migration path. In this paper, we propose a genetic algorithms- (GAs-) based approach which is effective in addressing multiobjective optimization problems. We have performed some preliminary evaluations of the proposed approach which shows quite promising results, using one of the classical genetic algorithms. The conclusion is that GAs can be used for decision making in task migrations in pervasive clouds.
1. Introduction
Pervasive cloud computing is a converged computing paradigm, by leveraging powerful computing and storage capacities of cloud computing [1]. In order to realize the pervasive cloud computing functionalities to improve the processing and storage capabilities of small devices, task migration [2] is an important feature of pervasive clouds which migrates computing intensive tasks or high-volume-storage-demanding tasks to backend powerful nodes.
There are a number of task migration solutions proposed so far [3], such as OSGi-PC proposed in [4, 5] and CloneCloud [6]. These approaches focus on different aspects of application execution in pervasive cloud environments, including resource and service discovery mechanism, and application partition and tasks migration. But none of these proposed solutions provide a good solution for decision making on task migration in pervasive clouds. These solutions could not provide a scalable approach for obtaining optimal migration paths while tasks migrate, especially in a possibly large problem space like a smart transportation management application.
Genetic algorithms are one of the most successful computational intelligence branch, which can potentially work for a large-scale multiobjective optimization problems. Therefore, in this paper we propose a genetic algorithms-based approach for task migration in pervasive clouds which can be used to make decisions on how to assign tasks to cloud nodes. We have performed some preliminary evaluations to our approach in terms of performance and made comparison with some other decision making strategies.
The remainder of the paper is organized as follows. We introduce task migration in pervasive clouds and the design of our GAs-based approach in Section 2. Next, Section 3 presents how genetic algorithms are used in decision making for task migration problem. Section 4 evaluates the implementation that shows our approach can perform acceptably. Related work is described in Section 5. Section 6 concludes the paper and outlines the future work.
2. Task Migration and Design of GAs-Based Approach
2.1. Task Migration Overview
Tasks may need resources that are not available to them in their current location. Task migration in pervasive clouds is to reallocate these tasks to resource-rich computing nodes in the cloud environment before their execution. During the execution period, it may adjust running nodes of some tasks according to tasks’ execution contexts. In task migration, one user application may be divided into some tasks following certain rules, so that the complex application can be executed in a distributed way. In order to ensure that the tasks can be executed correctly, task migration involves status, data and file transmission, and returning execution results back.
A further reason for migration may be that less power is used in mobile devices if tasks are offloaded. Although mobile device is becoming more powerful, the resource demanding surpasses this trend, for example, computing and resources of intensive applications including rich media applications such as photo and video editing and synthesis, scene recognition, object recognition, and image search [7]. This makes mobile applications becoming more and more complicated [8, 9], which requires enhancing user experiences and response time utilizing backend powerful devices.
2.2. Choosing Cloud Simulation Platform
Real pervasive clouds environment and tasks execution in it are very complex. Alternatively, we choose a simulation tool CloudSim [10] which makes it possible to evaluate migration strategies prior to software development. CloudSim is a generalized and extensible framework that enables seamless modeling, simulation, and experimentation of emerging Cloud computing infrastructures and application services. CloudSim framework models computing entities, cloud services, user tasks, and user tasks’ executions are simulated by CloudSim.
Using CloudSim to do simulation, we focus on tasks’ execution and obtain test data without taking into account low level details related to cloud-based infrastructures and services. There are certain computing nodes-VMs and user tasks-Cloudlets. After specific simulations, we can obtain each task's running time on all of the VMs.
2.3. Genetic Algorithms and GA Frameworks
Genetic algorithms [11] are used to obtain optimized solutions from a number of candidate solutions. GAs are inspired by evolutionary theory: weak and unfit species are faced with extinction by natural selection, and the strong ones have greater opportunity to pass their genes to future generations via reproduction [12]. Compared with other classic or optimization methods, GAs have it specific advantages in terms of its broad applicability, ease of use, and global perspective [13]. They are particularly useful to for single-objective and multiobjective problems which are difficult or impossible to get an exact solution [14]. So we choose it as our decision making algorithm.
In GA terminology, a solution is called an individual or a chromosome. A chromosome corresponds to a unique solution in the solution space. GAs operate with a collection of chromosomes, called a population, and use two operators to generate new solutions from existing ones: crossover and mutation. There are many GAs proposed, such as NSGA-II [15] and MOCell [16].
In our implemetation, we choose to use Java based GA frameworks. There are some popular implementations, such as JGap [17, 18], ECJ [19] and JMetal [20]. When compared with JMetal's counter-parts, the design of JMetal has a good separation of concerns in terms of its easiness for applying different GAs after a problem is abstracted. Therefore, JMetal is chosen as the GA framework in our approach.
The overall decision-making process is as follows: firstly CloudSim is used to model the computing nodes of the testing cloud environment and user tasks. Then some simulations are conducted to collect tasks execution information, which is the time array which shows all the time taken by each task run on all VMs. And then this time information is used in JMetal where GAs will give optimized solutions for task allocation. Figure 1 shows the overall design process, and the working flow of GAs-based decision making for task migration is shown in Figure 2.

Overall process design of GAs-based approach.
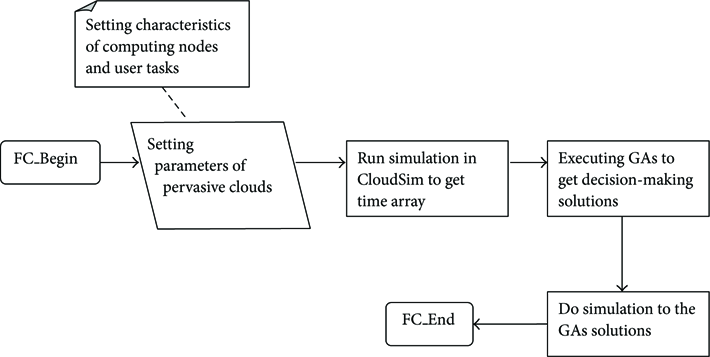
Flow diagram of decision making for task migration.
In the following section we will describe how the GAs-based approach finds optimized solutions to the task migration problem. The definition of task migration problem with GAs and the algorithm execution process are explained. And we will also discuss another two decision making policies used for task assignment.
3. GAs-Based Approach Implementation
3.1. Task Migration Scenario
Suppose we have the following hypothetical scenario: there are 28 user tasks and 12 computing devices which have specific processing ability. This will be considered as one of the examples which is discussed in detail in this paper. Considering the features of CloudSim, user tasks are modeled as cloudlets and computing devices are a series of VMs which belong to specific hosts in the cloud. We assumed there are two hosts and the former 6 VMs are allocated in Host1 and the others are in Host2 which has more powerful process capability and stable network. Cloudlet characteristics include the length of the instruction set which is related to computing process time and input files’ size and output files’ size which have effect on data transfer time. VM characteristics are MIPS (million instructions per second) which describe its process speed, the number of CPUs, and the bandwidth which are related to communicate speed, RAM, VM size, and so on. Cloudlet characteristics, VM characteristics, and the network environment, the three factors, determine the initial total execution time of tasks in one VM together.
To test our decision making approach, we assume task characteristics and VM characteristics as shown in Tables 1 and 2. In Table 1, “CloudletID” is the identification of the cloudlet while “CLengt” is how many instructions in the cloudlet, “CISize” and “COSize,” are the size of input and output files for this cloudlet. In Table 2, “HostID” shows which host the vm is allocated. We can find how many million instructions in one second the vm can process with the “Mips” and “PesN” is the cpu number and “Size” indicates the size of the virtual machine.
Cloudlets characteristics.

VMs characteristics.

Table 3 shows the two hosts information, in which “HostID” is the ID number identifying a specific host. “Datacenter” means which data center the host belongs to, and there are only one data center “HostDatacenter” we created. “Bw” stands for the bandwidth characteristic of the host. “Pes” is how many CPUs the host has and “Mips” is the total process capability.
Hosts characteristics.

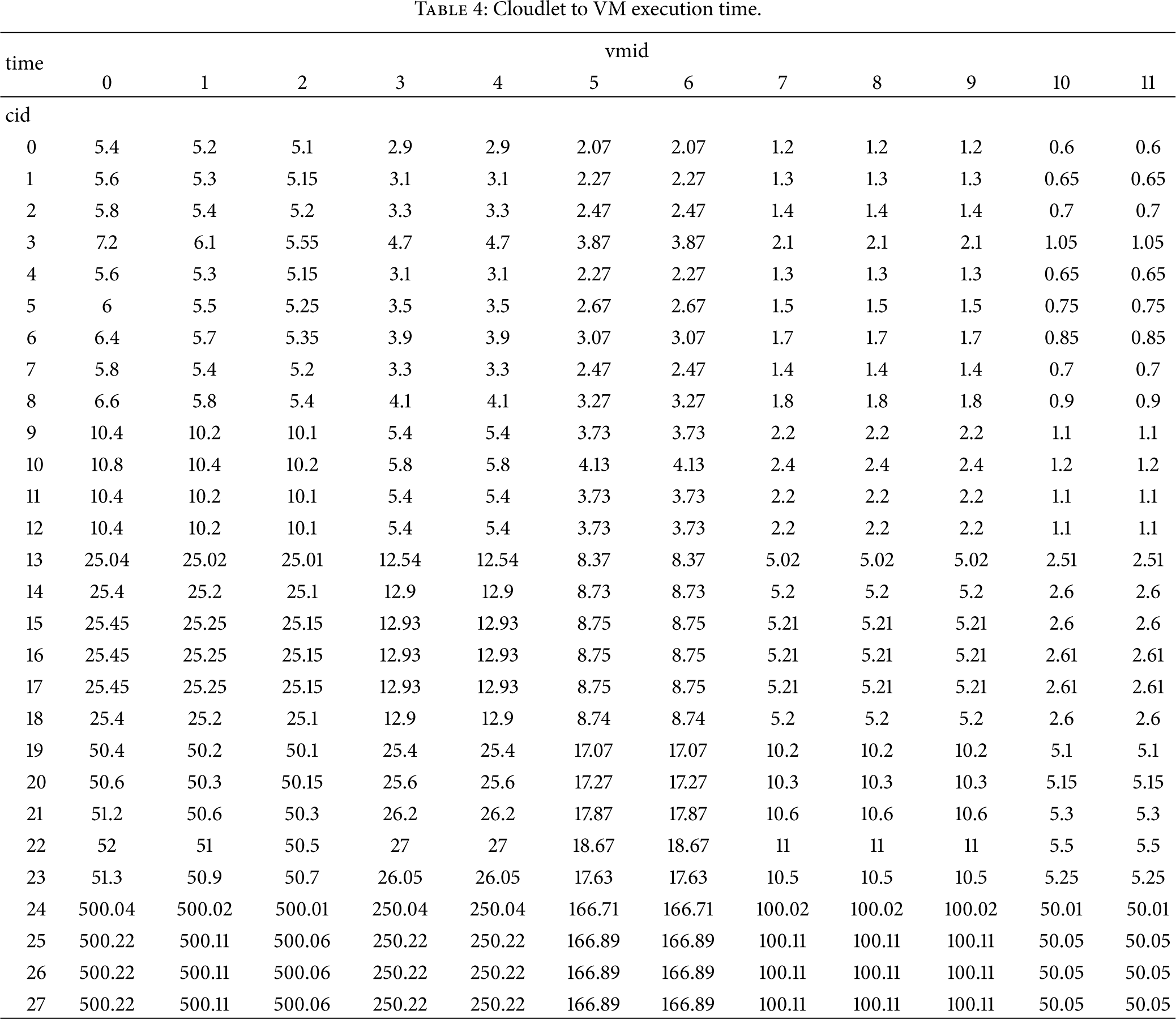
As illustrated previously, we have 28 cloudlets and 12 VMs. For each cloudlet, it can be allocated to any of the 12 VMs. So there will be
Cloudlet to VM execution time.
The decision making for task migration aims at getting the best allocation scheme which can make the system have the maximum processing efficiency, so that the cloud system can finish all the tasks with the minimum time consumption, in our case. This process may also involve the optimization for energy consumption, for security and privacy, and even all of them together. This combined optimization work will be done in our future work later on.
3.2. Problem and Optimization Objectives Formulation
In pervasive clouds environment, computing nodes are running in parallel. In other words, all the VMs in CloudSim start in the same time. And then they begin to process the tasks (cloudlets) assigned to themselves. But when more than one cloudlet is assigned to one VM, they will be executed one by one. Another important thing about task execution in pervasive clouds is that there are files transfer between VMs when task migrates which takes time. But when there are more than one cloudlet that are executed in the VM, only the first one's file transfers consume time, because the following file transfer in tasks can be done during the execution of the first cloudlet.
This process needs to calculate the predicted finish time of each VM. The time is the sum of execution time of all tasks assigned to the VM. In other words, it is the finish time of the last task allocated in the vm. For example, for a given VM i, the predicted finish time is i represents the sequence number of a VM with the scope of
If the start time of clouds system is 0, then at time
In order to get optimized solutions as task migration decision, we choose these solutions which have the minimum finishing time T. This is the objective of the task migration problem.
3.3. Chromosome Encoding and Fitness Evaluations
A chromosome corresponds to a unique solution in the solution space. GAs can typically make use of booleans, real numbers, and integers to encode a chromosome [20]. The representation of chromosome in our case is using integer (starting from 0) sharing the idea of [21]. That is to say, we are using a integer vector
3.4. Testing Environments and Parameter Settings for Evaluations
In our evaluations, JMetal 4.5 is used and the classical GA NSGAII is chosen as a concrete algorithm. Algorithm parameters setting in our implementation includes the maximum evaluations, the cross over probability, and the mutation operator, as shown in Table 5.
Parameters for NSGA-II.

As choosing integer chromosome, so Single point cross-over, Bit flip mutation, and Binary tournament2 operators are selected drawing on the experience of [22]. Reference [14] talks about how the operators work to make a change to the chromosome in GAs.
4. Evaluation and Discussion
From Table 4 we can see that time consumption is different for different cloudlets running on the same VM, and the same task takes different time to finish its execution in different VMs. Analysing the execution of tasks in vms, it is clear that the faster the VM is, the less execution time a task takes. The bigger a task (more instructs and bigger files) is, the more time it consumes. And with better network (high bandwidth), the data transfer time is reduced. This is consistent with our theoretical and actual situations.
4.1. Greedy and Simple Policies
In order to compare the performance of NSGA-II with other algorithms, we choose both greedy policy and simple allocation method for comparisons. Greedy policy is an extension to CloudSim and simple allocation method is included in the original CloudSim framework. Simple allocation method is a sequential allocation policy: all tasks are assigned to a group of virtual machine in order. The first task is assigned to the first VM, the second to the second, and so on. When all the virtual machine has been assigned one task, then the second round will start, and we assign next task to the first VM. In greedy policy, a matrix time will be defined to describe execution time for all tasks. Time
4.2. Result Evaluation
In order to verify and evaluate each allocation policy, we did simulations in CloudSim. The results are shown in Tables 6, 7, and 8, respectively.
NSGAII-based approach.

Greedy policy based approach.

Simple allocation method.

From these three tables, we can find that the scheme obtained from GAs-based approach takes 100.21 time units to finish all of 12 tasks while the other two schemes take 100.32.1 and 530.41 time units. So GAs-based approach can do the best decision and make the system have the fastest execution efficiency. According to the GAs-based scheme, user tasks can be finished as fast as possible and therefore users can have better experience and can be more satisfied.
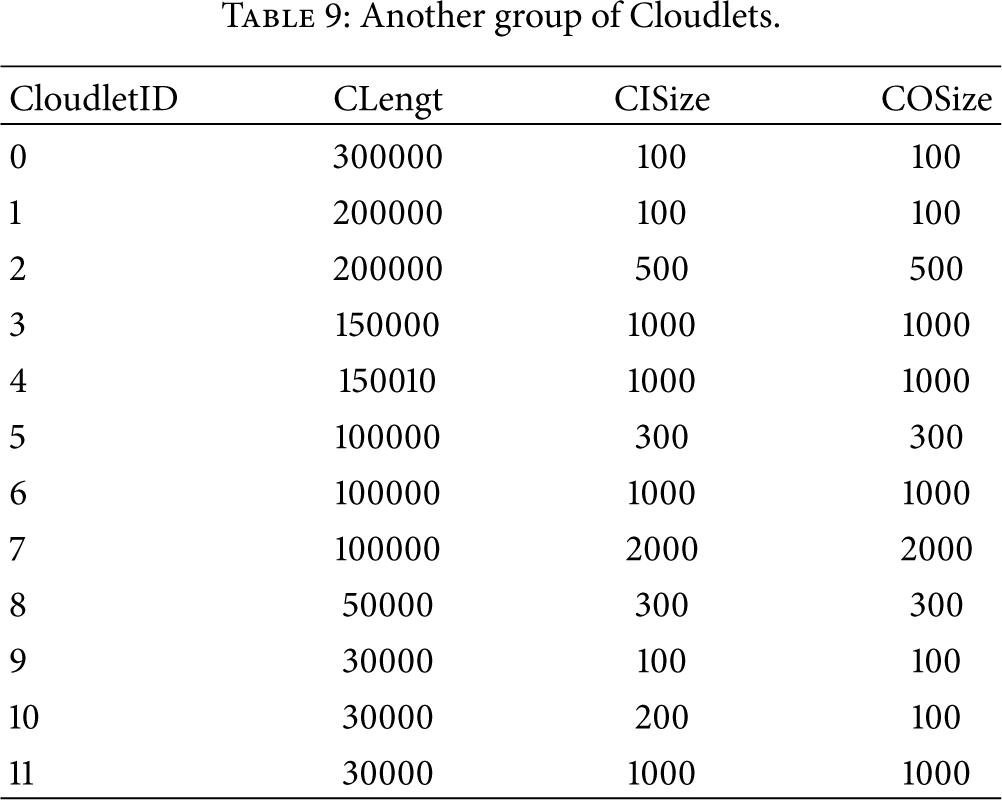
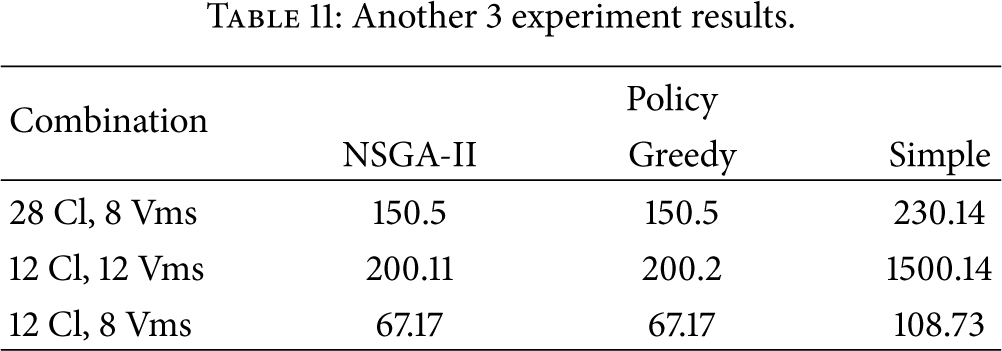
In order to be more persuasive and trusted, we add another set of tasks which contains 12 cloudlet and another group of vms which consist of 7 VMs as test data as shown in Table 9 and in Table 10. So in total we can have four combinations. Except for the aforementioned scenario discussed in detail (28 cloudlets and 12 VMs), we have another three experiments: experiment one where 28 cloudlets are allocated to 7 VMs, experiment two where 12 cloudlets are allocated to 12 VMs, and experiment three where 12 cloudlets are allocated to 7 VMs. The results with 3 different allocation policies are shown in Table 11. With the total four results, we can see that GA decision can obtain better allocation scheme. This indicates that choosing genetic algorithm as decision making algorithm for task migration is efficient to some extent.
Another group of Cloudlets.
Another group of VMs.

Another 3 experiment results.
5. Related Work
Task migration is becoming popular with the development of cloud computing. It aims at getting better execution of user applications or tasks. Reference [23] developed an offloading inference engine that can do efficient partitioning of applications. The offloading inference engine dynamically partitions the application, and offload part of the application execution with data to a powerful nearby surrogates. This allows the application to be delivered in a pervasive computing environment without significant fidelity degradation or expensive application rewriting.
MAUI (mobile assistance using infrastructure) [24] is an architecture where mobile program code can be offloaded to powerful infrastructure. MAUI decides at runtime whose methods should be remotely executed, driven by an optimization engine that achieves the best energy savings possible under the mobile device's current connectivity constrains. It uses integer linear programming to do the optimization which may incur quite some overhead as pointed by [24]. Instead the GA-based approach can be quite efficient as evaluated in [22].
CloneCloud [6] is a system automatically migrating mobile applications dynamically to cloud. It uses remote cloud resources and partitions application at thread level to obtain fine granularity and flexibility. The basic idea of CloneCloud is rewriting the program. At runtime, it will choose threads to do migration, the rest will still be executed locally. Integer linear programming is also used to obtain optimization migration paths which may have high performance overhead.
There are also some GAs-based approaches proposed in task scheduling and migration in mobile cloud computing. In [25] the author proposes a new concept “universal mobile service cell” (UMSL) as the abstraction for mobile cloud computing. And then USML is choosen as scheduling unit instead of tasks or processes in order to have high level of abstraction to shield the heterogeneity and distribution of mobile cloud compuying systems. Then GAs are selected to schedule USML cells to the adaptable nodes on the cloud in accordance with adaptable time under transaction logic constraint in order to achieve high efficiency, flexibility, and reliability.
In [26] the author proposed an improved generic algorithm as scheduling algorithm in cloud computing in which Min-Min and Max-Min scheduling methods are merged. The scheduling algorithm is used to get proper and efficient utilization of the resources in system. It also uses CloudSim as a simulator to evaluate the algorithm performance. A genetic algorithm based technique for task level scheduling in Hadoop MapReduce is described and evaluated in [27]. The tasks execution time assigned to certain processors is predicted and then GAs are used to make optimized decision for scheduling the entire group of tasks in the job queue. It aims to get a shorter make span for jobs from a holistic view.
6. Conclusion and Future Work
Decision making for task migration is one of most important issues in pervasive clouds computing. There is scarce reported work providing decision making policies, for example, considering the characteristics of user tasks and cloud environment. In this paper, we proposed a genetic algorithms based approach for obtaining optimized tasks allocation scheme. The optimized solutions can be used to enable effective allocation strategies, and then in the actual running, system can make use of the chosen allocation scheme to execute user tasks. The whole process is evaluated and it was shown that our approach is feasible with acceptable performance. Due to the limitations in CloudSim, currently the evaluation is simplified and in the future the approach will be extended with a real test bed which will be ready soon [5].
Currently we consider task execution time, input, and output data sizes of the tasks and the bandwidth of network, accordingly choose time consumption characteristic of task execution, and make tasks allocation decision on its basis. We are planning to consider other characteristics such as energy consumption, resources requirement in decision making process, and test this approach with our pervasive cloud environment [4, 5]. Pervasive cloud environment is changing continually with time and tasks’ situations are also different during the execution. In the future, we hope to make the decision dynamically according to cloud environment and user tasks’ status with the help of a context-awareness framework.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
The research in this paper is jointly supported by the National Natural Science Foundation of China (Grant nos. 61309024 and 61402533) and also the Natural Science Foundation of Shandong Province (Grant no. ZR2014FM038), “Key Technologies Development Plan of Qingdao Technical Economic Development Area.” Weishan Zhang has been supported by the start-up funds for “Academic Top-Notch Professors in China University of Petroleum.”