
Abstract
Backpressure based scheduling has revealed remarkable performance in wireless multihop networks as reported in a lot of previous work. However, its lack of consideration on energy use efficiency is still an obstacle for backpressure based algorithms to be deployed in resource-constrained wireless sensor networks (WSNs). In this paper, we focus on studying the design of energy efficient backpressure based algorithm. For this purpose, we propose a gradient-assisted energy-efficient backpressure scheduling algorithm (GRAPE) for WSNs. GRAPE introduces a new link-weight calculation method, based on which gradient information and nodal residual energy are taken into account when making decisions on backpressure based transmission scheduling. According to the decisions made by this new method, packets are encouraged to be forwarded to nodes with more residual energy. We theoretically prove the throughput-optimality of GRAPE. Simulation results demonstrate that GRAPE can achieve significant performance improvements in terms of energy use efficiency, network throughput, and packet delivery ratio as compared with existing work.
1. Introduction
Backpressure algorithm was proposed by Tassiulas and Ephremides in [1] and it has been proven to be throughput optimal. Backpressure algorithm is purely queue length based and it works in a way such that packet transmission scheduling decisions are made based on queue backlog differentials between neighboring nodes. Recently, design of efficient backpressure algorithms has attracted a lot of attention and much work has been done in this area. On one hand, backpressure based algorithms have many remarkable advantages; for example, they can achieve adaptive resource allocation and support to dynamic stateless load-aware routing and scheduling and simplicity. On the other hand, they also have some deficiencies such as large end-to-end (E2E) delivery delay, high queueing complexity, and centralized computation mode, which largely affect their usage in practice. Recently, much progress (e.g., [2–20]) has been made for supporting efficient and practical backpressure based scheduling and routing in various networks and application scenarios. However, how to enable practical backpressure based scheduling in a wireless sensor network (WSN) is still far from being well studied.
WSNs are often considered to be resource constrained where energy use efficiency is in general a great design concern for network protocols to be useful in such networks. Although existing work (e.g., [2, 4, 10]) has made certain progresses in enabling efficient backpressure based scheduling in a WSN, lack of consideration on energy use efficiency is still a big issue in their usage. To ease the understanding of the issue that backpressure based scheduling faces in this aspect, here, let us take a look at the operational process taken by classical backpressure scheduling algorithm. In the classical backpressure algorithm, per-flow queues (or per-destination queues as used in some work) are required to be maintained for each node in the network. At each time slot, the algorithm works to activate a set of noninterference links whose link-weights yield a global maximal sum to transmit packets. The link-weight is assigned to be the maximal flow-weight and the flow-weight is equal to the differential of corresponding flow's queue backlogs between the link's two endpoints. In such a way of transmission scheduling, packets are always pushed away from network hot-spots (by the so-called back pressure), no matter whether such transmissions lead to routing detours or even loops. One advantage of such backpressure based scheduling is that the capacity of the whole network can be fully utilized. However, long E2E packet latency is often observed. Furthermore, lack of consideration on energy use efficiency when making decisions on next hop selections in such algorithms results in poor network lifetime performance.
In this paper, we focus on studying the design of energy-efficient backpressure based scheduling algorithm for WSNs. For this purpose, we propose a gradient-assisted energy-efficient backpressure scheduling algorithm (GRAPE). GRAPE introduces a new link-weight assignment method, according to which a link's weight is determined by not only the differential between its two endpoint nodes' queue backlogs but also the recipient's residual energy status as well as their gradient difference. In GRAPE, packets are encouraged to be forwarded to neighbor nodes with more residual energy and lower gradients. We present the design details of GRAPE and then theoretically prove its throughput-optimality. Extensive simulation results demonstrate that GRAPE can yield significant performance improvements in terms of energy use efficiency, network throughput, and packet delivery ratio performance as compared with existing work such as the classical backpressure algorithm [1], enhanced dynamic back-pressure routing algorithm (EDR) [3], and min-hop routing.
The rest of this paper is organized as follows. Section 2 briefly reviews related work. Section 3 presents our system model. In Section 4, we first introduce how the classical backpressure algorithm works and then introduce the motivation behind our work in this paper via some simulations. Finally, we present the design details of GRAPE and further prove its throughput optimality. Extensive simulation results are presented in Section 5. In Section 6, we conclude this paper.
2. Related Work
Recently, much progress has been made in the design of efficient backpressure based scheduling algorithms for wireless multihop networks. Existing work in this field can be divided into two types: one is aimed at reducing the path lengths and thus reducing the E2E packet delay another is aimed at improving the queueing structure kept at nodes and thus improving the scheduling performance. Next, we will briefly review typical work belonging to either type.
Some existing backpressure based algorithms/protocols (e.g., [2–6, 10]) work to reduce the chance of using long or detour routes. BCP [2] is a backpressure based data collection protocol for WSNs. In BCP, backpressure based routing decisions are made based on queue backlog differential and also estimated link rates. Furthermore, BCP uses a routing-loop-punishment factor for avoiding routing loops. Furthermore, a LIFO (Last-In-First-Out) queue structure is adopted, which can help reduce the average E2E delay. BCP demonstrates good E2E performance comparable to the well-known collection tree protocol (CTP) [21], especially for networks with mobile elements. In [3], Georgiadis et al. proposed an enhanced dynamic backpressure routing algorithm (EDR). In EDR, decisions on routing and scheduling are made by taking the hop-distance to destination into account. In EDR, for instance, a neighbor node closer to the destination node may have higher probability to be chosen as the next hop forwarder than a remote node when the former has equal or even higher queue backlog than the latter. The flow weight assignment in EDR can help reduce certain routing detours and is also helpful in reducing energy consumption to certain extent due to the preference to shorter paths. Similar strategies can also be found in [4], where several factors including link capacity and network external arrival rates are considered into the routing decision making process. In [5], Ying et al. proposed a protocol that combines backpressure algorithm and shortest-path routing, which minimizes the average path length determined by backpressure based routing and thus reduces the average E2E delay. In [6], Maglaras and Katsaros proposed a layered backpressure routing algorithm. The main idea is similar to the gradient based routing in WSNs; that is, nodes are divided into layers based on their hop distances to the sink node and data packets are encouraged to be sent from nodes at higher layers to nodes at lower layers. In [10], Jiao et al. proposed an anycast based backpressure scheduling algorithm for WSNs, in which anycast based backpressure scheduling is realized in the RTS-CTS handshaking process among neighbor nodes in a localized manner. In this algorithm, packets are restricted to be forwarded to neighbor nodes with lower gradients.
Some existing backpressure based algorithms/protocols (e.g., [7–9]) choose to use new queue structures to replace the commonly used per-flow or per-destination queues for reducing the queueing complexity as well as the average E2E delivery latency. In [7, 8], a novel per-neighbor queue structure was proposed. This new queue structure enables nodes to only maintain one forwarding queue for each neighbor, which exhibits low average-case E2E delay and also low queueing complexity. In [9], Ying et al. proposed a cluster based backpressure algorithm, according to which each node keeps two types of queues, that is, one for the gateway node for each destined cluster and another for nodes in the same cluster. In this way, the cluster based backpressure routing largely reduces the number of queues required to be kept at each node.
There also exist some other algorithms (e.g., [12–18]) that attempt to improve the practicality of backpressure algorithms. For example, in [12], an adaptive redundancy technique for backpressure routing was introduced, in which replicas are generated and sent as regular packets for reducing the E2E delay under low load conditions, while traditional backpressure routing is still used under high traffic load conditions. In [18], interflow network coding was introduced and integrated with backpressure scheduling, in which network coding gain is utilized for assisting backpressure based transmission scheduling and thus reducing the E2E delay. However, these algorithms often cause some overhead during their operational phase, which are not desirable for a resource constrained WSN. In this paper, we aimed at designing energy-efficient backpressure based algorithm for a WSN. To the best of our knowledge, this is the first attempt in this aspect.
3. System Model
In this paper, the WSN under study can be modeled by graph
3.1. Queue Dynamics and Stability under Classical Backpressure Algorithm
Before introducing how our algorithm works, let us first introduce how the queues in the classical backpressure algorithm in [1] evolve. The classical backpressure algorithm requires each node
At the beginning of each time slot, external data traffic of each flow is injected into the network via the source node of the flow. For example, the dynamics of queue backlog of flow f, where

Furthermore, as traffic always leaves the network layer when they reach their destination(s), for the destination of a flow f (denoted by

A network's stability is defined via the dynamics of queues in the network; that is, we can call that a network is strongly stable when for all

3.2. Flows and Queue Dynamics in a WSN
The status of flows in a WSN is quite different from those considered in most previous backpressure based algorithms. For example, there exists a common assumption in the study of backpressure based algorithms; that is, flows are long-lived and data sources are fixed. However, this assumption does not hold in a WSN, where each sensor node may start to generate packets or stop at any time, especially in some environment monitoring applications wherein sensors sample the environment and send collected data to the sink upon the occurrence of particular events. Furthermore, as in many cases, these sensing packets should be served equally and they all have a common destination, that is, the sink node in the network. Thus, all data packets in a WSN can be considered to belong to the same flow and managed by only using one flow-specific queue at each node (this is also straightforward from the perspective of per-destination queue structure). The source of such a flow is a node set which includes all sensor nodes in the network. As a result, we rewrite the queueing dynamics equations for a WSN as follows.
At the beginning of each time slot, external data traffic may enter the network via any sensor node. For a sensor node a, the dynamics of its queue backlog are as follows, where

Furthermore, the sink's queue backlog will always equal to zero; that is,
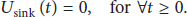
We call that a WSN is strongly stable when for all

4. GRAPE: Motivation, Design, and Analysis
In this section, we first introduce how the classical backpressure scheduling algorithm works. We then bring some experimental results that motivate our work in this paper. Finally, we propose the design details of GRAPE and further prove its throughput-optimality.
4.1. Classical Backpressure Scheduling
The classical backpressure algorithm in [1] works as follows. First, it assumes that time is slotted. At the beginning of a time slot t, each link


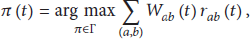
4.2. Motivation
Energy use efficiency is a big issue for backpressure based algorithm to be used in a WSN. In backpressure based transmission scheduling, packets are always forwarded away from network hot-spot (pushed by the so-called backpressure), which is consequently very helpful for balancing the network load and fully utilizing the network capacity. However, such routing and scheduling do not consider whether a routing selection decision in this way leads to routing detours or even loops, which often consumes more energy for packet delivery than shortest paths.
To present a clear understanding regarding this, we next present a simulation based comparison between the classical backpressure algorithm (referred to as BP) and min-hop routing (i.e., each node always chooses a next-hop forwarder from its neighbor nodes which are closer to the sink than itself, which is referred to as Min-hop) in terms of their energy use performance in a WSN. In the simulations, a WSN constituent of 99 sensor nodes and one sink node is used, where the network topology is randomly generated. Link capacity is set to one. The initial energy of each sensor node is assigned to 200 J, and the sink has infinite energy. Sending and receiving a packet cost 1.6 J and 1.0 J, respectively. Each simulation lasts 1000 time slots. Either algorithm's energy use performance was evaluated under different flow arrival rates (i.e., 0.5, 1, and 1.2 packets/slot) and in terms of the following two measures: the death time of the first dead node in the network and the survival ratio of nodes when a simulation comes to the end. From the results in Tables 1 and 2, it is seen that the classical backpressure algorithm performs much worse than the gradient based routing algorithm in terms of energy use efficiency. Under BP, the node survival ratio is extremely low, which reveals the backpressure based algorithms' unsuitability for WSNs. To the best of our knowledge, no work has been done regarding how to improve the energy use performance of back pressure based algorithms in a WSN. In this paper, we take the first step towards this direction. Specifically, we try to answer the following two questions:
How to suppress the use of unnecessarily long routes in backpressure based routing selection. How to select nodes with abundant residual energy to undertake forwarding tasks while still preserving backpressure algorithm's throughput-optimality.
The death time (slot) when the first node dies.

The survival ratio of nodes when the simulation terminates.

In the next, we present the design details of GRAPE and explain how it addresses the above issues.
4.3. Algorithm Design
In GRAPE, besides nodal queue backlog status, the following two new factors (i.e., each node's gradient information and also its residual energy) are introduced into the backpressure based scheduling decision making process. In this paper, the gradient associated with a node is its hop distance to the sink node and the introduction of this factor is to encourage packets to travel along shorter routes. The introduction of nodal residual energy status is to enable backpressure scheduling to be energy aware when selecting next hop nodes. For this purpose, a new link-weight calculation method is presented as follows.
Specifically, in GRAPE, the weight of a link is no longer simply equal to the queue length differential between the two end nodes of the link as shown in (8). Instead, a new link-weight is assigned as follows:
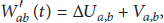
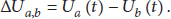

After determining the link-weight for each link in the network, data packets can then be scheduled to transmit over a link 
The optimal solution to (13) yields the optimal schedule and its computation needs to be done in a centralized manner and has high computational complexity of at least O(
4.4. GRAPE's Throughput-Optimality
In this section, we provide a theoretical proof regarding the throughput-optimality property of GRAPE.
First, for a WSN, we can substitute (11) and (12) into (10), and accordingly we have
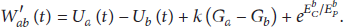
Then, we rewrite (14) in the following form:
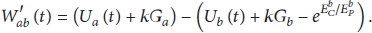

For each forwarding queue kept at sensors in the network, its dynamics meets the following expression:
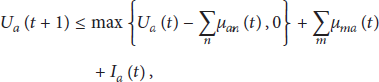

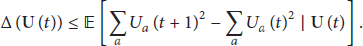
Based on the fact that 
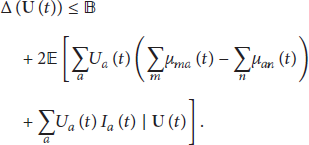


5. Performance Evaluation
In this section, we conduct extensive simulations to evaluate the performance of GRAPE by comparing it with several other existing algorithms including the classical backpressure algorithm (referred to as BP) [1], the enhanced dynamic back-pressure routing algorithm (EDR) in [3], and the min-hop routing algorithm (referred to as Min-hop). Next, we will first introduce our simulation settings and then present the simulation results.
In the simulations, we generated a random topology with 100 nodes located within a 500 × 500 square area. The communication radius of each node is 100. In the network, a randomly chosen node acts as the sink node in the network and all other nodes are sensor nodes. Packets can be injected into the network via any sensor node where packet arrival follows a Poisson process with arrival rate λ. In the simulations, we will present comparison results under different packet arrival rates λ, where λ varies with the following values: 0.5, 0.8, 1.0, 1.3, and 1.5. To estimate different algorithms' energy use performance, each sensor node is assigned by 200 J initial energy, and the sink is assigned by infinite energy. Sending and receiving a packet cost 1.6 J and 1.0 J to a node, respectively. Each simulation lasts for 1000 slots. We use two metrics to exhibit the energy use efficiency between different algorithms, that is, the death time of the first dead node and number of dead nodes, which are widely used metrics for measuring network life time and nodal energy usage efficiency in existing work.
Figure 1 shows the simulation results when network link capacity is set to one. Figures 1(a) and 1(b) compare the energy use performance by different algorithms, where Figure 1(a) shows the numbers of dead nodes under different algorithms when the simulation terminates and Figure 1(b) compares the death times of the first dead nodes by different algorithms, respectively. From these two subfigures, it is seen that GRAPE outperforms other backpressure based algorithms (i.e., BP and EDR) in terms of energy use efficiency, which validates the high energy use efficiency of our new link-weight calculation method used in GRAPE. However, Min-hop can still outperform GRAPE in some cases. The reason is that Min-hop restricts packets to be transmitted from nodes with higher gradients to those with lower gradients. It forbids the use of any longer alternate paths other than shortest paths. Thus, it can have higher energy use performance than backpressure based algorithms including GRAPE, since backpressure based algorithms leverage alternate routes to fully utilize the network capacity, which is a key feature of backpressure based scheduling and can cause more energy consumption. Figures 1(c) and 1(d) demonstrate the network throughput and packet delivery ratio performance by different algorithms. It is clearly seen that GRAPE outperforms Min-hop in terms of these two measures especially as the traffic arrival rate is increasing. This is due to adaptive backpressure based routing's capability in fully utilizing alternate routes. Figure 1(e) compares the average queue length performance under different algorithms. It can also be seen that, due to better throughput performance of GRAPE, the average queue length under GRAPE is lower than the other three algorithms as traffic arrival rate increasing. Here, note that when flow arrival rate is 0.5, the average queue length by GRAPE is higher than Min-hop. The reason is that backpressure based algorithms always need some time to form queue based gradient in the network to act as back pressure for pushing packets to go. As a result, when flow rate is low, packets may need to stay at a node and wait for a longer time than that when arrival rate is high, which result in longer average queue length. This phenomenon is called the slow-startup problem of backpressure based scheduling in [4]. For more details please refer to [4]. Furthermore, we compared the link use efficiency by each algorithm, which is defined by the number of links being activated in each time slot. Average link use efficiency equals to the average number of links being chosen into the schedule set generated by an algorithm per time slot, which is an important metric for estimating a backpressure based algorithm's scheduling efficiency. As shown in Figure 1(f), GRAPE has higher link use efficiency than other algorithms due to its higher energy use efficiency (since in our simulation, nodes that had exhausted their energy will no longer participate in any transmissions). Furthermore, it should be noted that Min-hop always activates much less links per time slot than backpressure based algorithms. This is because Min-hop forces packets to be transmitted along shortest paths. As a result, in some hot-spots, few links can be activated due to contentions in medium accessing opportunities. This is helpful for saving energy but cause reduced network capacity.

Performance comparison of various algorithms on a randomly generated 100-node topology when link capacity equals one.
Figure 2 compares the performance of different algorithms when network link capacity was set to five. In Figure 2, it is again seen that GRAPE outperforms the BP and EDR in terms of energy use efficiency, throughput, packet delivery ratio, average queue length, and link use efficiency. Furthermore, it has comparable energy use performance to Min-hop as shown in Figures 2(a) and 2(b).

Performance comparison of various algorithms on a randomly generated 100-node topology when link capacity equals five.
6. Conclusion
Energy use performance is always a big design concern for backpressure based routing and scheduling to be useful in a resource-constrained wireless sensor network. In this paper, we proposed GRAPE, a gradient-assisted energy-efficient backpressure scheduling algorithm for WSNs. In GRAPE, besides queue backlog differentials, gradient information and nodal residual energy are also jointly considered into the transmission scheduling decision making process and accordingly a new link-weight calculation method was designed, according to which packets are encouraged to be forwarded to nodes with more residual energy and via shorter paths. We present the detailed design description of GRAPE and further theoretically prove its throughput-optimality. Extensive simulations results show that GRAPE significantly outperforms existing algorithms in terms of energy use efficiency, packet delivery ratio, and throughput.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China under Grant nos. 61501125, 61502018, 61531006, and 61372105 and Natural Sciences and Engineering Research Council (NSERC) of Canada (Discovery Grant 293264-12 and Strategic Project Grant STPGP 397491-10).