
Abstract
The vision of the Internet of Things (IoT) includes large and dense deployment of interconnected smart sensing and monitoring devices. This vast deployment necessitates collection and processing of large volume of measurement data. However, collecting all the measured data from individual devices on such a scale may be impractical and time-consuming. Moreover, processing these measurements requires complex algorithms to extract useful information. Thus, it becomes imperative to devise distributed information processing mechanisms that identify application-specific features in a timely manner and with low overhead. In this paper, we present a feature extraction mechanism for dense networks that takes advantage of dominance-based medium access control (MAC) protocols to (i) efficiently obtain global extrema of the sensed quantities, (ii) extract local extrema, and (iii) detect the boundaries of events, by using simple transforms that nodes employ on their local data. We extend our results for a large dense network with multiple broadcast domains (MBD). We discuss and compare two approaches for addressing the challenges with MBD and we show through extensive evaluations that our proposed distributed MBD approach is fast and efficient at retrieving the most valuable measurements, independent of the number sensor nodes in the network.
1. Introduction
Several technological advancements in hardware design enable IoT application scenarios with very dense deployments of sensor nodes. Researchers are designing tiny radio-on-a-chip communication devices with processing and communication capabilities. These low-power wireless devices can also be powered from the energy scavenged from ambient radio waves [1]. Several market studies project that trillions of things will soon be connected to the Internet [2]. In a large-scale dense network, the amount of collected data will therefore be enormous and it becomes necessary to extract only the information that is relevant to further processing [3]. For example, in some cases, it maybe required to alert the occurrence of certain features in a timely manner.
In this work, we tackle the problem of feature extraction in a dense IoT application. (An earlier version of this work was published in the proceeding of DCOSS 2014, DOI: 10.1109/DCOSS.2014.29. This work considered a single broadcast domain (SBD), where all nodes are located within the same transmission range.) We define feature extraction as the process of determining certain features such as peaks, boundaries, and shapes in the distribution of a physical quantity.
While feature extraction may not be an issue for a low density network (e.g., tens of sensor nodes), it is still a challenging problem for a high density network. In applications requiring measurements with a high spatial granularity, covering even a small area (e.g., one square meter) may require hundreds to thousands of sensor nodes. Some examples of densely deployed sensing nodes, where features of one or more physical quantities need to be monitored frequently, are sleep monitoring for health-care applications [4], smart surfaces for aviation systems [5], and fruit monitoring in agriculture industries [6].
Figure 1 presents an example distribution of the measurements of a physical quantity (e.g., temperature or pressure values). As shown, the distribution has three distinct regions of activity that require detection and evaluation. Such a dense sensor network for measuring a physical quantity, called a field, would involve deploying one sensor node to measure each data point in the distribution. The regions of activity, called active regions, are those where the values measured by sensor nodes are of interest.
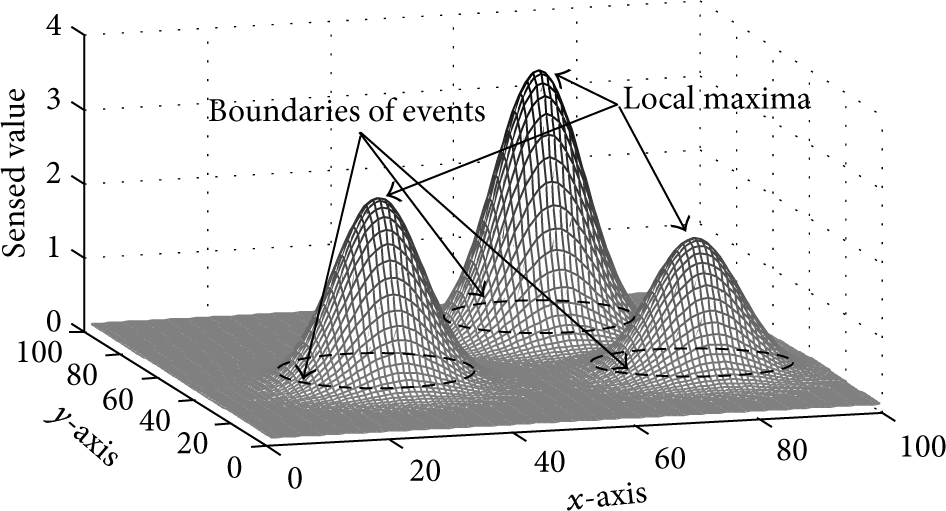
An example of a 2D physical quantity field with 10,000 sensor nodes. Each data point corresponds to a value sensed by an individual node.
One naive way to identify active regions would be to collect readings from all sensor nodes and process them centrally. This is usually inefficient since typical channel access techniques do not scale well with an increase in number of nodes. It is therefore advantageous to devise techniques that identify active regions irrespective of the density of the network.
Computing even simple aggregate quantities such as extrema (minimum or maximum) is not trivial for a dense network as it may require collecting data, in the worst case, from all nodes [7] (even if some sort of spatial subsampling is employed [8]). Dominance-based or binary-countdown MAC protocols help in finding the minimum value in constant time [9–11], provided that all nodes reside in a single broadcast domain (SBD). Furthermore, finding peaks and their boundaries in a distributed network, where each data point is measured by individual sensor nodes, is computationally expensive, is time-consuming, and typically does not even scale linearly with respect to network size.
In [3], we first proposed a set of feature extraction techniques for an SBD and established that finding the local extrema is a challenge in an SBD even after the global maximum is known. Once the global maximum is identified in constant time, we proposed a few transforms that nodes employ on local data, which helps in identifying other peaks (local maxima) and their boundaries in the spread of the physical quantity being measured. Our proposed transforms, referred to as augmenting functions, allow the identification of local extrema in constant time. We showed that, instead of collecting all data as in the naive case, these augmenting functions retrieve the most valuable sensor nodes’ measurements that result in fewer number of measurements being collected.
In this paper, we present the design, implementation, and evaluation of a set of distributed algorithms to extract certain features of a physical quantity in a dense sensor network. We enhance our preliminary work published at [3] with the following new contributions:
We propose a new distributed algorithm (dubbed ripple-based) to extend the process of obtaining global extrema in an MBD dense network. Since finding global extrema is the main building block in the proposed augmenting functions, this extension enables the applicability of these functions for MBD networks. We modify an existing clustering approach [12] to obtain the global extrema for MBD networks and compare the novel ripple-based approach with the classical cluster-based approach and evaluate their efficiencies. We design a simulation model to analyze the impact of relevant network parameters (e.g., communication range in wireless medium) on the functioning of the ripple-based approach.
This paper is organized as follows. An outline of other works related to our approach is given in Section 2 after a brief introduction on the dominance-based approach. The architecture and the system description based on an aggregate quantity function are provided in Section 3. Afterwards, we introduce various augmenting functions that are used to transform the sensor value such that local extrema or boundaries in various directions become the global extremum. In Section 5, a brief explanation of the clustering approach is given, followed by a novel approach, called ripple-based, to obtain the global extrema in an MBD network. This approach is fully distributed and exploits concurrent transmissions of dominance-based protocols. In Section 6, the evaluation of proposed augmenting functions is given together with a comprehensive comparison on the cluster-based and the ripple-based approaches for MBD networks.
2. Background and Related Work
Detection of events in sensor networks is a major application domain and a very broad topic. There are different approaches to address the problem of boundary detection in dense sensor networks. To the best of our knowledge, this is the first boundary detection technique that utilizes dominance-based MAC protocols. To this end, first we provide a detailed explanation of this MAC paradigm and explain how to compute an aggregate value (e.g., global
2.1. Dominance-Based Approach
This work is inspired from dominance-based or binary-countdown protocols [9] implemented for wired networks in the widely used CAN bus [10] as well as its wireless version, called WiDom [11]. The major reason for using a dominance-based MAC protocol is its scalability and constant time-complexity even for very dense networks. In this work, we focus on time-complexity and we do not enrich our dominance-based MAC protocol with sleep states or other energy-saving mechanisms; thus, the current state of the protocol is ready to be used in critical applications where energy issues are not the main focus of the scenarios.
In dominance-based MAC protocols, each node is associated with a priority value that is used to resolve the medium contention. All nodes “simultaneously” start a conflict resolution phase which we refer to as tournament (depicted in Figure 2), by transmitting synchronously their priority values bit-by-bit, starting with the most significant one, while simultaneously monitoring the medium. The medium must be devised in such a way that nodes will only detect a “1” value if no other nodes are transmitting a “0.” Otherwise, every node detects a “0” value regardless of what the node itself is sending. For this reason, a “0” is said to be a dominant bit, while a “1” is said to be a recessive bit. Therefore, low numbers in the priority field of a message represent high priorities. If a node contends with a recessive bit but hears a dominant bit, then it will refrain from transmitting any further bits and will proceed only monitoring the medium. Since the medium acts as a logical

Tournament in dominance/binary countdown protocols.
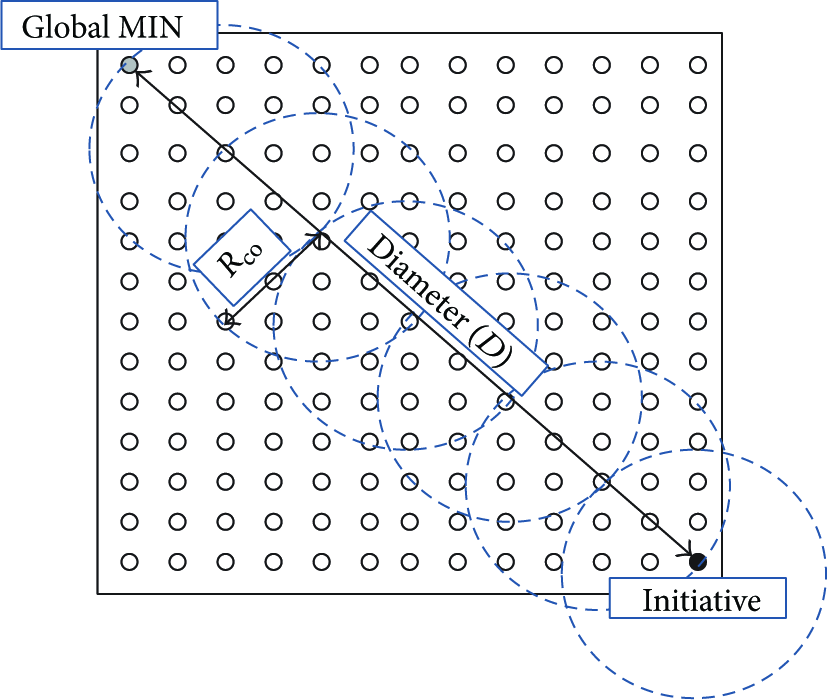
By using sensed physical quantities (like temperature or acceleration) as the message priority, various aggregate quantities can be obtained in dense networks. For instance, the minimum of sensed value (
In fact, simultaneous transmissions are a key to the time-efficiency of dominance-based MAC protocols. With carrier-sense or time-division based MAC protocols, computing
The process of finding
2.2. Boundary Detection
The problem of boundary detection and determining the extent of an event in sensor networks has been investigated in [8, 16–19]. Chintalapudi and Govindan presented localized edge detection techniques based on statistics, image processing, and classification [16]. Nowak and Mitra described a method for hierarchical boundary estimation using recursive dyadic partitioning [8]. They developed an inverse proportionality relation between energy consumption and the mean-square error in boundary detection and showed that their method is near-optimal with respect to this fundamental trade-off. Another hierarchical boundary estimation is proposed in [19] where a contiguous 2D shape of an event is found with a threshold-based boundary detection.
Other schemes represent the boundary of an event or the signal landscape of a sensor network compactly using in-network aggregation [20–24]. Gandhi et al. studied the problem of monitoring the events of sensor networks using sparse sampling [21]. However, their algorithm requires the prior knowledge of the event geometry (e.g. circle, ellipse, or rectangle) for computational efficiency. Similar method has been explored in [23], which utilized a regression-based spatial estimation technique to determine discrete points on the boundary. Ham and Rodriguez present a distributed boundary detection based on in-network aggregation in which only sensor nodes that identify a boundary transmit their observation to the remote station [24]. To that end, they first applied a Delaunay triangulation to determine the neighbors of each node and then generate boundary segments between neighboring sensors. However, this algorithm cannot be known as a fully decentralized approach since the two steps mentioned above should be done centrally through a remote station.
There are also contour-based methods for deciding the type of an event [25, 26]. They consider energy-efficient techniques to construct and incrementally update a number of 2D contour maps in a sensor network. Another field of research involving detecting holes and topological features in a sensor network is presented in [27, 28]. In these approaches, local connectivity graphs are used to infer static features of an event and require the involvement of all the nodes in the network. By contrast, our approach is quite different from the above-mentioned techniques, as we exploit an underlying dominance-based MAC protocol for very sparse spatial sampling through a strategic selection of sensors.
3. System Model
We consider a sensor network where each sensor node has a unique identifier, i, and measures a particular physical quantity,
The collection of all the sensor values across the total sensed area is referred to as a field (Figure 1). Each data point in the field corresponds to a true (or nonfaulty) sensor reading value, sensed by an individual sensor node at its physical location. The spatial granularity and the size of the field are directly correlated to the distribution of the nodes and their spread. We also define active region as a physical area populated by sensor nodes that sense some activity. The overarching goal of our approach is to find location, boundaries, and shape of an active region, which we referred to as features, in the physical environment. For illustrating our approach and its evaluation, we generated various sample fields by a summation of 2D Gaussian functions (explained in the appendix).
Function

The choice of
Function
4. Feature Extraction Using Augmenting Functions
In this section, we describe in detail a set of augmenting functions that can extract an approximate but faithful representation of various features in the field by applying simple transforms on the sensor values.
We show that this process can be done with a limited number of broadcast messages or flooding in case of SBD or MBD, respectively.
4.1.
Distance Augmenting Function
As described earlier, a global maximum value in a sensor field can be easily found applying function
We demonstrate the process of finding an adjacent local minimum with a simple 1D Gaussian field example, shown in Figure 3. Using this example we show that, by utilizing the augmenting function over the input signal, the adjacent local minimum becomes the global minimum.

An example of augmented function
In this example, the field consists of three peaks and the highest peak (the global maximum) lies in the center. Finding the spread of this global maximum is not trivial as the global minimum point can be one of those sensor nodes near the borders of the field. It is important to suitably modify the process of identifying the extrema such that a local minimum adjacent to a peak (adjacent valley) can be found. For this purpose, we observe that an adjacent valley should have a low value and its distance from the peak should also be small. Hence, each value in the field is transformed (multiplied) with the distance from the peak. With this transformation, the points located farther from the peak are associated with higher values (compared with its sensed value) and only points with lowest sensed value and smallest distance from the peak can become the global minimum in the augmented field. It is possible that this global minimum is a point in an adjacent valley. The boundary of this peak is found with just two rounds of executing
For 2D Gaussian fields, the 1D approach described above can be directly applied. Different active regions of the field are found by excluding the sensor nodes lying inside the identified active region from participating in the next rounds. The process of finding active regions is shown in Algorithm 1. Initially, function
( ( ( ( ( ( ( ( ( ( ( (
Each sensor node uses function
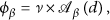

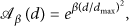
Finally, by finding the global minimum over
4.2.
Vector Augmenting Function
Our second augmenting function is used for cases where we are interested in finding a boundary around the whole active region. This approach can be used for a range of applications such as crowd monitoring for smart cities or sleep monitoring for health-care. In this approach, if we assign larger values of ϕ to sensor nodes that lie on the boundary of an active region, then the result of applying the
The vector augmenting function,


By using
The working of this approach is outlined in Algorithm 2. The algorithm explores the region by choosing random directions defined in a set
( ( ( ( ( ( ( ( ( ( ( ( ( (
If two angles lead to the same point, it means that any angle over the arc confined by these two angles would result in that point. Thus, this arc can be filtered out from further investigation. Figure 4 shows an example where two angles of
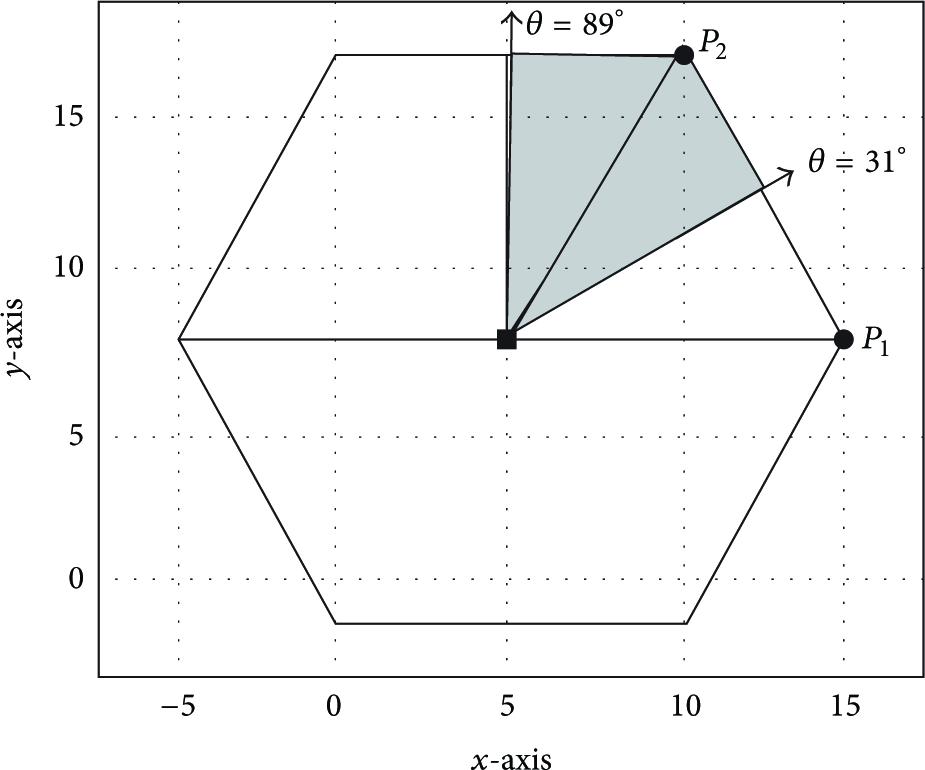
An example of boundary detection for a hexagonal-shape event.
More iterations of the algorithm leads to more accurate boundaries, but at the cost of more resource consumption. We show in Section 6 that, with the above filtering strategy, we are able to reduce the number of dominance rounds, while still building a good description of the active region. The worst case for our algorithm happens when the event boundary looks like a perfect circle where new directions will always give new points (considering a very dense deployment of sensors and a marginal extension of
4.3.
Joint Augmenting Function
As described earlier, the distance augmenting function
To find the boundary of an active region with noncircular distribution, we devised a new augmenting function,

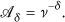

An example of boundary detection around the peaks with nonuniform distribution.
5. Computing Global Extrema in MBD Networks
In this section, we address the challenge of computing
5.1. Cluster-Based Approach
In the clustering approach, proposed in [12], a topology discovery algorithm is first executed to partition the network such that all nodes in each partition are in the same broadcast domain (Setup phase). Then, at runtime, nodes within the same cluster find the minimum sensor reading and communicate these values to their cluster leaders. The cluster leaders form a collection tree with root at the leader node where the query for computing
The high-level pseudocode of the cluster-based approach is given in Algorithm 3. A minimum virtual dominating set (MVDS), as introduced in [29], has been considered during the setup phase. With MVDS, it is possible to divide the network into several clusters where the nodes in each cluster form an SBD. The cluster leaders (known as black-nodes in MVDS) are responsible for collecting
( ( ( ( ( ( ( (
Cluster-based approach: (a) cluster formation and black-node tree (
The leader node uses this topology information to schedule the activation time of each cluster to avoid any collision between neighboring nodes that reside in different clusters. To make this approach more efficient, we utilize a heuristic that was proposed for the register interfering graph (RIG) problem [30] to find the chromatic number Δ for concurrent active clusters. However, unlike the RIG problem, in our case the number of available colors is not known in advance. This is the number of registers in RIG problem, k.
Function
( ( ( ( ( ( ( ( ( ( ( ( ( (
5.2. Ripple-Based Approach
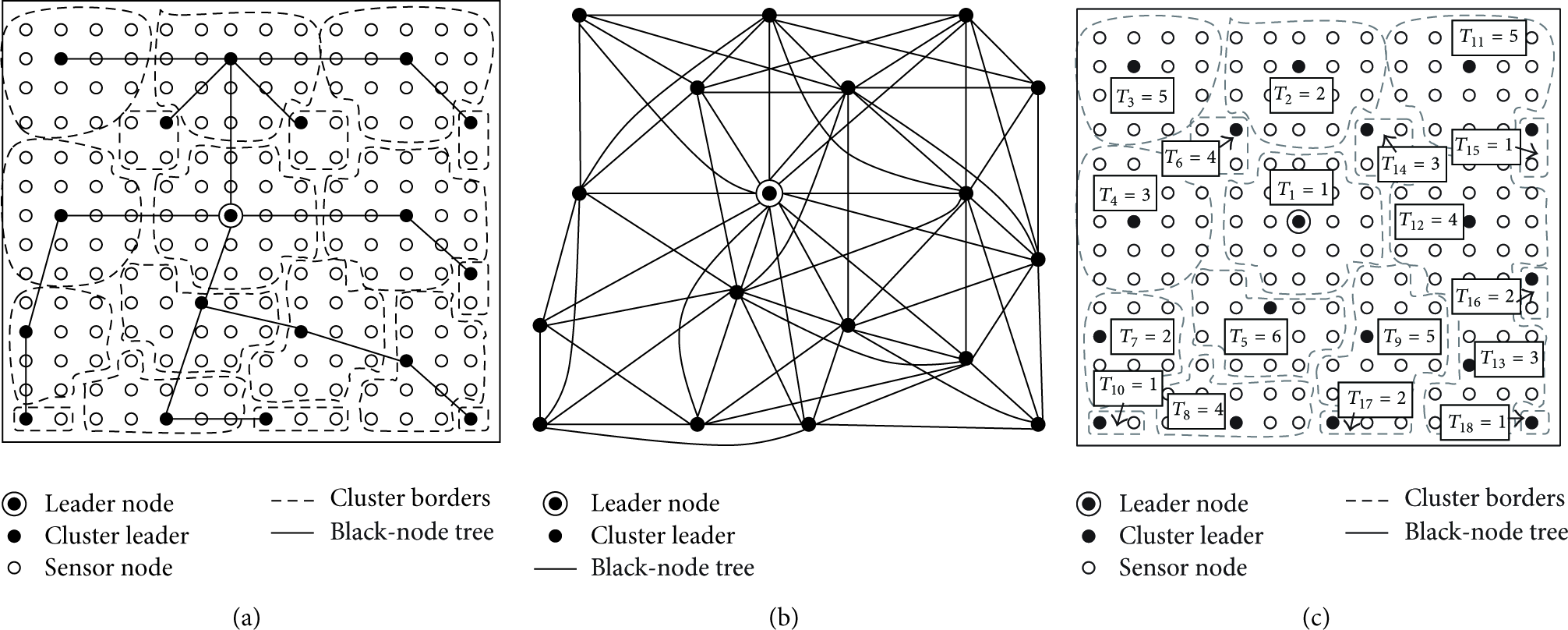
The ripple-based approach aims at eliminating the setup overhead in the cluster-based approach and mitigating the initialization cost by using a distributed algorithm to compute the global extrema. It uses the concurrent transmission property of the dominance-based protocol to find the
( ( ( ( ( ( ( (
Ripple propagation throughout the network: (a) an initiator sensor node that signals start of a tournament. Sensor nodes within the communication range of this node then perform one tournament; (b) nodes participating in the previous tournament become initiator nodes in this round; (c) and (d) ripple moves toward the border of the network; and (e) all sensor nodes are activated.
To compute the global
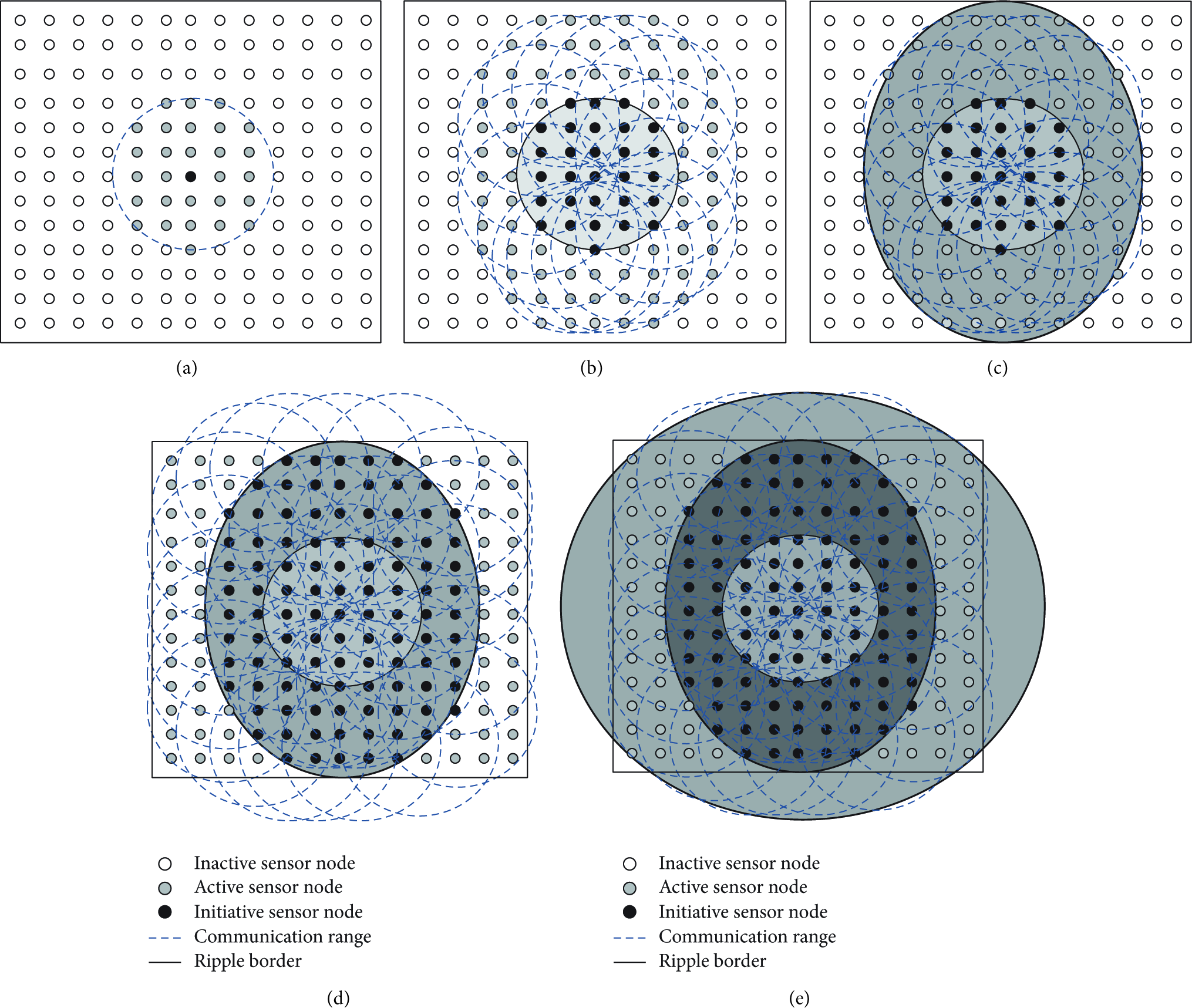
An example of the worst case scenario to determine the required number of tournaments (
The
Figure 9 shows an example of computing

Compute
Figure 9(b) shows the result of finding
However, the multihop protocol described above can suffer from the hidden terminal problem. As dominance-based protocols allow nodes to listen to
To elaborate, consider three sensor nodes

Example of hidden terminal problem during a tournament execution (we assume three priority bits): (a) network topology, (b) execution of tournament that leads to an error in node
To avoid this problem, we consider two slots for each bit transmission as proposed in [32]. The first slot is dedicated for the bit transmission itself and the second slot is dedicated for the retransmission of the bit detected during the first slot. If the current bit of a sensor node is dominant, there is no need to retransmit this bit for the second time, but if the bit is recessive and the sensor node detects a dominant bit during the transmission slot, it retransmits a dominant bit in the following retransmission slot (see Figure 10(c)). This bit-level redundancy solves the problem and leads to the correct perception of
6. Evaluation
We evaluated our proposed approaches in different simulated scenarios by considering the following three metrics.
Number of Rounds. A sensor node gets channel-access permit to broadcast a message in one round of execution of
Accuracy. It represents the fraction of sensor nodes that declare themselves to be located in the active region(s)
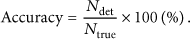
In cases where the detected area is larger than the actual active region, (
Execution Time. It is the time needed to extract different features according to the proposed augmenting functions and is computed as

We first show the process of computing
6.1. Computing the Execution Time of
Function,
As stated earlier, the application of
To have a precise computation of a tournament round, we consider the timeouts given in [33]. As illustrated in Figure 10, to solve the hidden terminal problem in the ripple-based approach, it is needed to send each bit twice during the tournament. Considering
Table 1 shows the number of referenced tournaments along with the time needed to find the global extremum in an MBD network. In this computation, we took into account the time needed to aggregate data in case of cluster-based approach, as well as the time required for flooding the local information of the winner in the ripple-based approach. However, in both cases we assume the best case scenario. For data aggregation through the black-node tree, we first compute the maximum degree d of the cluster interfering graph (see Figure 6(a)). To prevent any collision, it is considered that we need to have at least d time slots to collect data in the leader node. The duration of the time slot is considered to be the time needed to transmit a
Computation time of
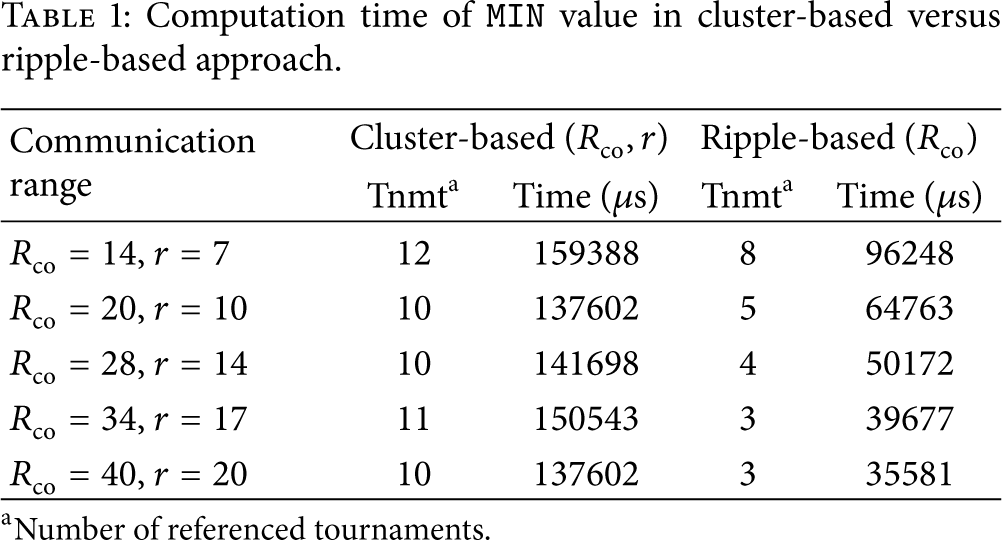
For the ripple-based approach, we compute the flooding time according to the theoretical lower latency bound given in [35]. Given that nodes transmit concurrently, the theoretical lower latency bound in a network with size h hops is
As expected, increasing the communication range results in faster computation of
It should be mentioned that the given time for both approaches is slightly optimistic. In cluster-based approach, we do not consider the extra overhead imposed by the setup phase for cluster formation and similarly in ripple-based approach; we have used the lower bound of the flooding delay as in [35]. Note that, in the cluster-based approach, not all sensor nodes become aware of
6.2. Identifying the Active Regions
We considered the same network settings as described in the previous subsection, with size of
In each round of execution, after finding the global maximum, all the sensor nodes compute local values of
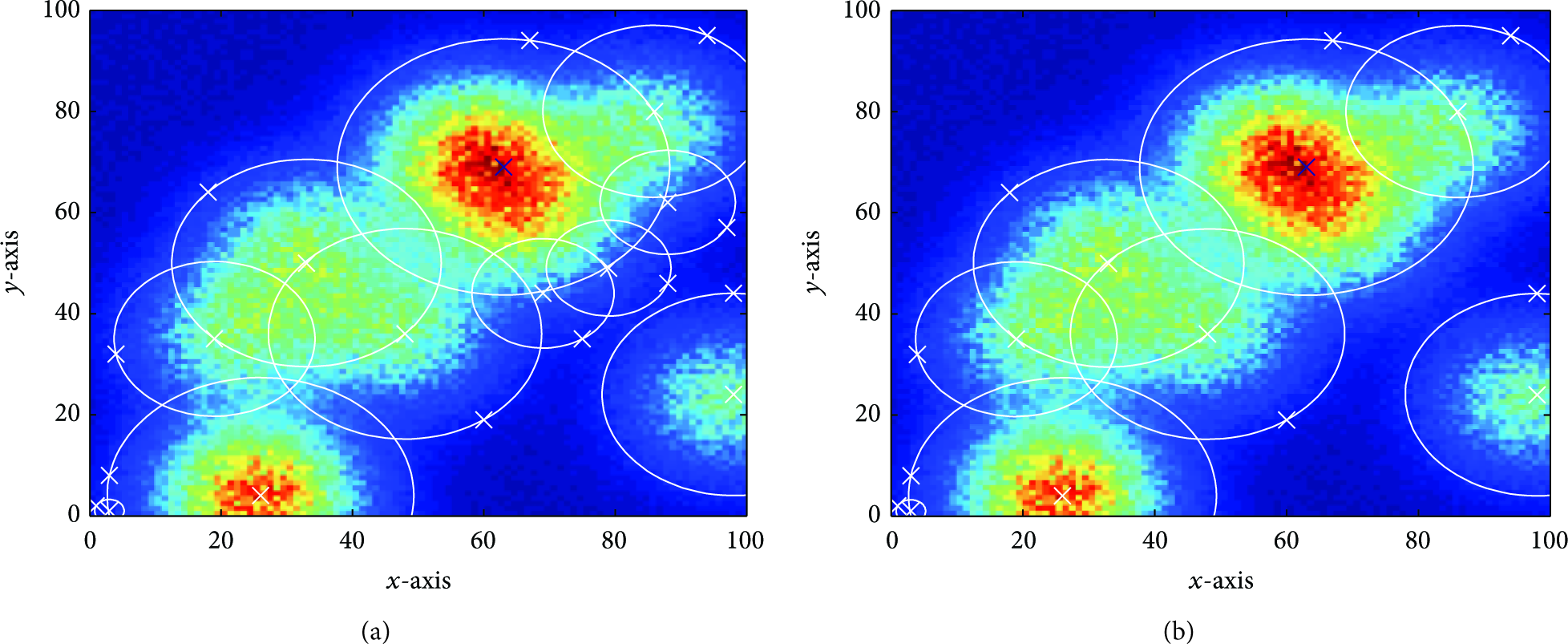
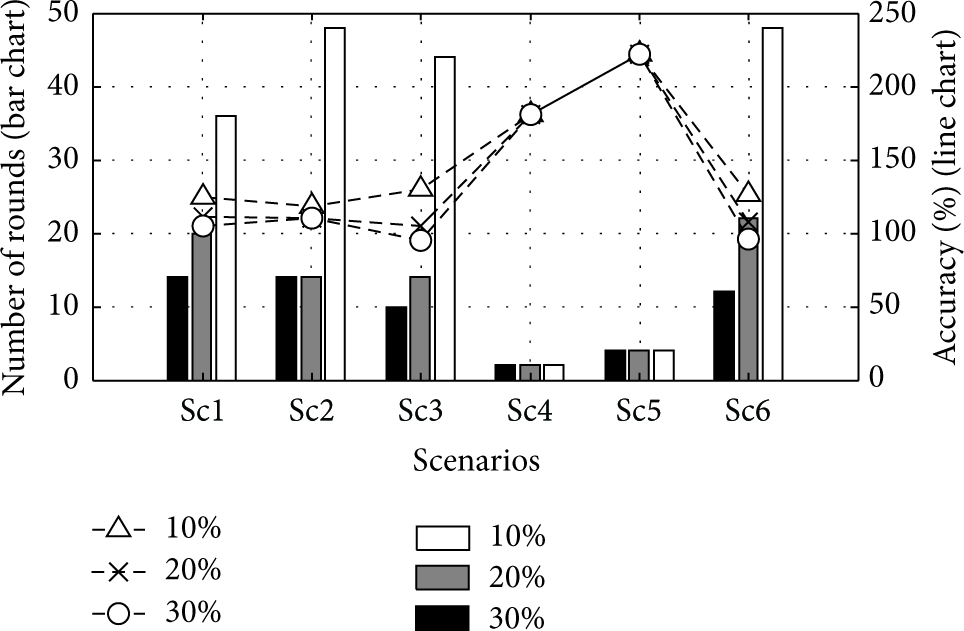
The effect of termination threshold,
Figure 12 shows number of rounds and the corresponding obtained accuracy for different threshold values. We believe that the property of the field plays an important role in the number of required rounds and the accuracy of the detection. In some scenarios, increasing the termination threshold reduces the number of rounds as well as the overestimated area. This happens for scenarios sc1, sc3, and sc6, where the active regions can overlap. However, for scenarios sc2, sc4, and sc5, where either few active regions exist or the active regions are far apart, the number of rounds and accuracy remain almost the same for all termination conditions. The existence of isolated peaks in the field results in identifying all active regions by a fixed number of circular sections. The high value of overestimation in sc4 and sc5 is due to the steepness of the peak in the field. This steepness causes an overestimation in the filtering radius which in turn leads to much larger (squared) overestimation of the circle's area.
The number of rounds and the accuracy of active region estimation in different scenarios for various
We found that the choice of the exponential coefficient β in our given heuristic (4) affects the overestimation of active regions. In fact, coefficient β impacts the relative weight of distance from the peak with respect to the value of the field at a given point. Choosing an optimal value of β is not possible without the prior knowledge of the field, but the order of β can be chosen based on the size of the field such that a proper trade-off between the sensor value at a given sensor node and its distance from the peak is maintained. Particularly, β should be chosen such that the impact of distance can be pronounced compared to the distance normalization (
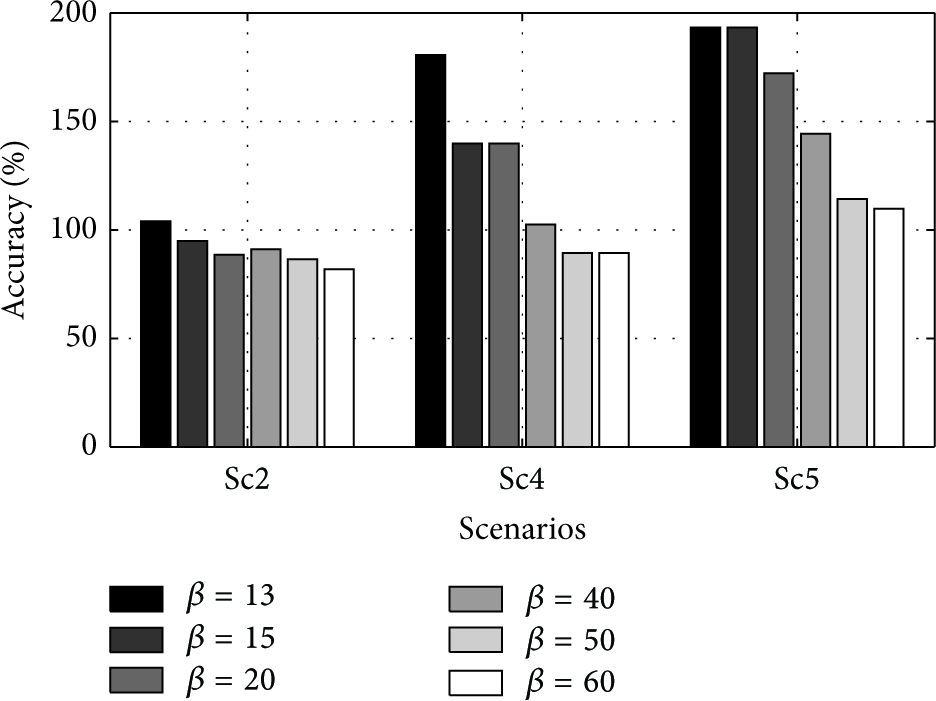
The effect of β on the accuracy.
Figure 14 shows the time it takes to detect the location of active regions by

Execution time of
6.3. Convex-Hull around Active Regions
For evaluating the convex-hull technique described in Section 4.2, we convert the field to a binary field by thresholding, such that a sensor node's value is
Figure 15 shows the accuracy of our second technique in terms of average percentage of coverage area by running the simulation over
The number of rounds for
Increasing the marginal extension angle, ϵ, still provides a satisfactory coverage area estimation, while reducing the number of messages. We tested the performance of our proposed algorithm with different marginal extension angles in all the mentioned scenarios. As shown in Figure 16, by increasing ϵ, the number of rounds decreases, since by enlarging the angle, more search space is filtered out and consequently less packets are needed to be broadcast.
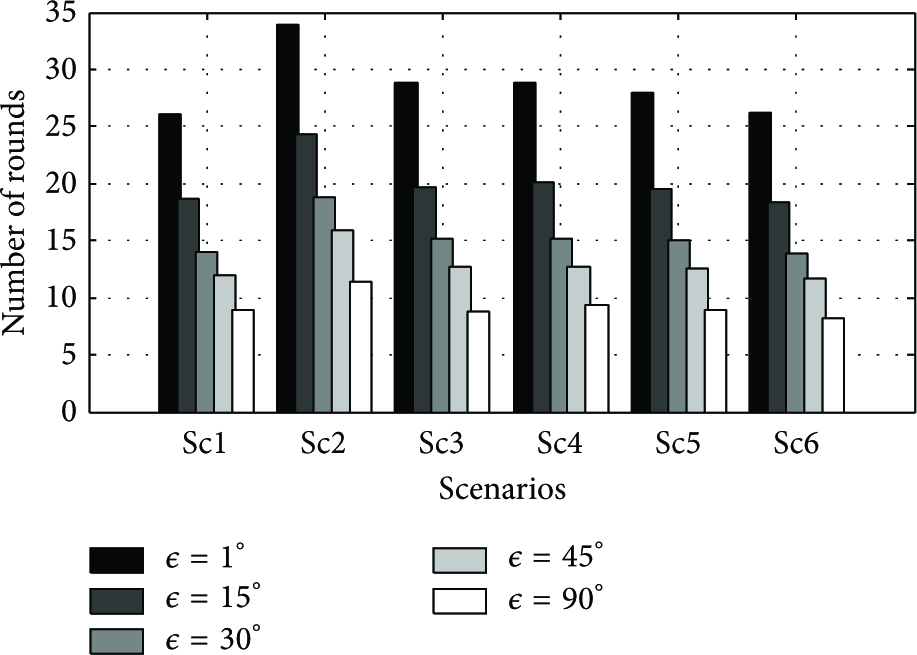
The number of rounds in
However, increasing ϵ might diminish the performance of the algorithm in terms of estimated coverage area. Figure 17 shows the performance degradation by increasing the ϵ up to
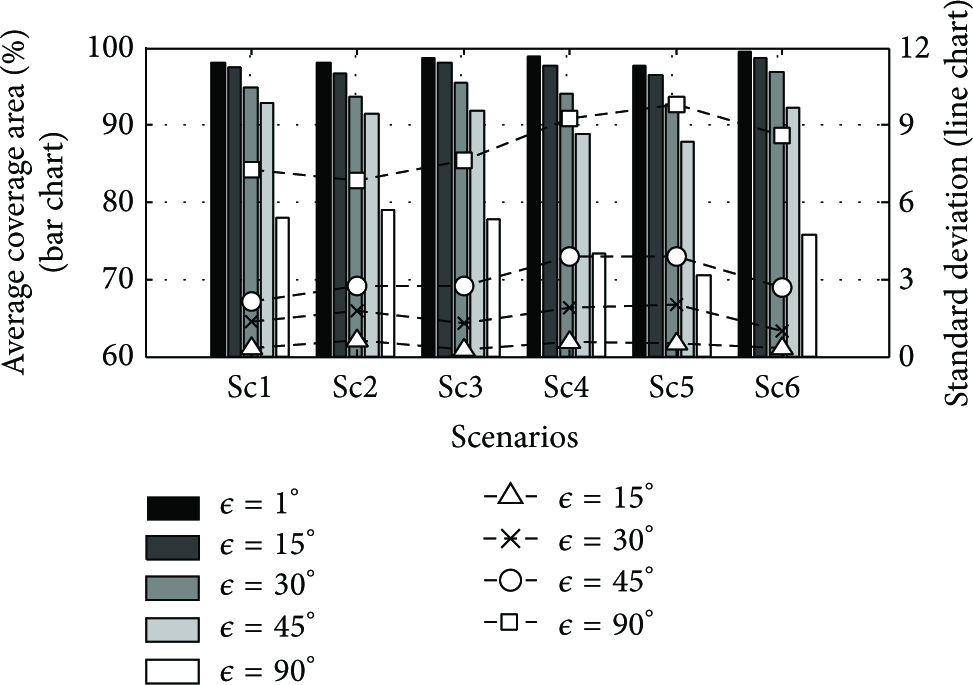
The average of estimated coverage area with different marginal extension angle, ϵ, and its standard deviation.
Figure 18 shows the execution time of vector augmenting function
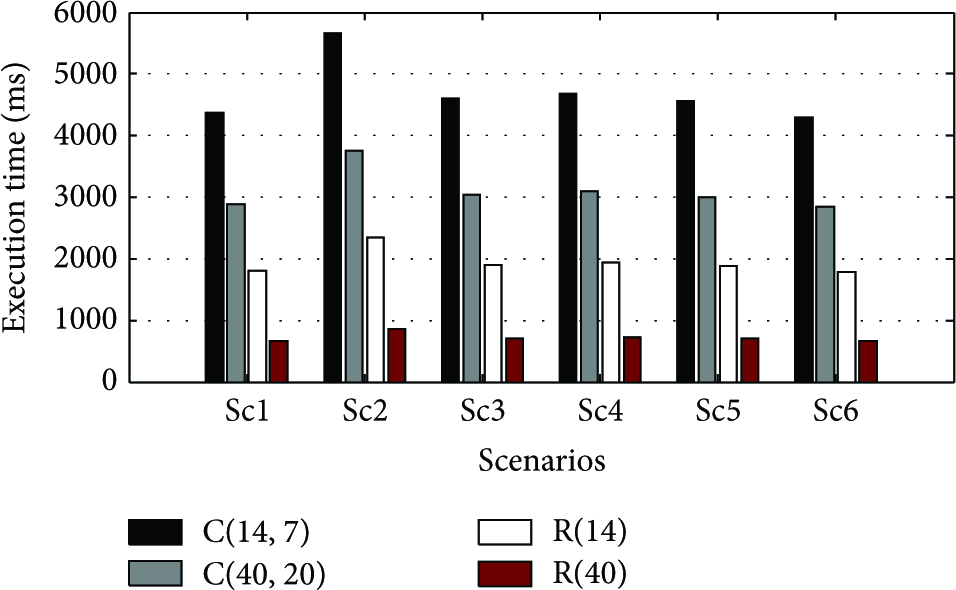
Execution time of
6.4. Noncircular Active Regions
As discussed in Section 4.3,
Figure 19 shows the comparison of the performance of distance augmenting function with the joint augmenting function. For scenarios where a number of active regions lie very close to each other, the number of rounds required by

Comparison of vector augmenting function and joint augmentation is shown in Figure 20. It is evident that the combined approach helps in demarcating different active regions while

We further examined the cluster-based and ripple-based approaches to compare the time needed to extract different features according to the augmenting functions given in Section 4 for a single scenario. Figure 22 shows the elapsed time for different augmenting functions

The computation time of various feature extraction techniques (
6.5. The Impact of Network Density
Finally, we compared our techniques under various network densities. As our techniques only depend on collecting the global extrema of various augmenting functions, the results indicate that increasing the network density has almost no impact on the number of rounds. Figure 23 shows the number of rounds required in each technique with respect to the network size. The slight variation in the number of rounds is due to the effect of termination condition in

The impact of density on the performance of each technique for scenario sc2.

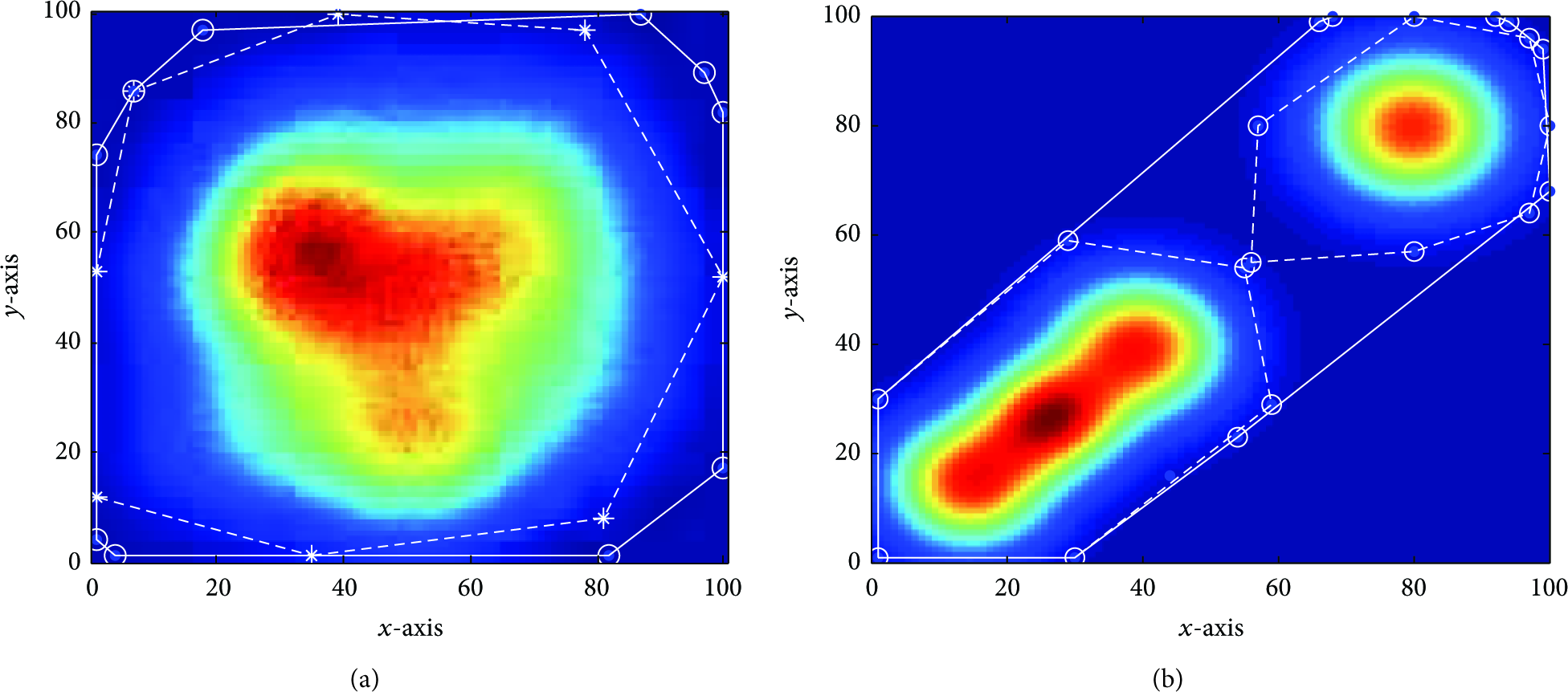
Six scenarios with different active regions; each sensor node sets the value of

Six scenarios with different active regions; solid lines show the boundary computed by our algorithm with
6.6. Alternative Flooding Approaches
Many emerging cyber physical systems need mechanisms to share and process data among all devices in the network. The ripple-based approach, proposed in this work, is one of such mechanisms, in the sense that it computes an aggregate quantity over all the devices. Chaos [36] and Low-Power Wireless Bus (LWB) [37] are two other examples of such mechanisms that build their data collection or dissemination capabilities based on the Glossy protocol [35].
Since we aim at obtaining an efficient and scalable algorithm with low time-complexity, we compare the performance of different flooding approaches based on execution time and scalability. Chaos outperforms LWB in terms of completion time [36]. In fact, Chaos is able to collect small amounts of data, such as a
7. Conclusions
Low-Power Wireless Sensor networks enable many emerging applications that need thousands of sensor nodes for control and monitoring. In this paper, we presented a set of techniques that identify various features in the distribution of sensed physical quantities over a dense deployment of sensor nodes. With such simple yet effective modifications, we can obtain the location and shapes of active regions with a number of messages proportional to the properties of the field. Our feature extraction techniques are efficient in the sense that they collect data from just the sensors that have more effective information for revealing the status of the monitored area.
We then proposed a fully distributed approach to make our feature extraction scale with large dense networks, where sensor nodes lie in a multiple broadcast area, and compared our method with the traditional clustering approach.
There are two main directions for our future work. The first involves investigating the temporal behavior of the extracted features, that is, developing efficient algorithms to detect and predict an evolving spatial active region. This may require detection of change dynamics and implement them within the feature extraction algorithm. The second direction leads towards the implementation of the algorithm itself. An experiment is required, using a test bed, to implement a dense sensor network to observe a phenomena and verify the results here. Along with this line, improvements to the proposed feature extraction algorithm would be required, by developing a proper synchronization algorithm for the MBD network, in order to increase its reliability. Furthermore, the limitations imposed by communication medium may also have to be considered.
Footnotes
Appendix
Abbreviations
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was partially supported by the North Portugal Regional Operational Program (ON.2-O Novo Norte), under the National Strategic Reference Framework (NSRF), through the European Regional Development Fund (ERDF), and by National Funds through FCT (Portuguese Foundation for Science and Technology), within Project no. NORTE-07-0124-FEDER-000063 (BEST-CASE, New Frontiers); by National Funds through FCT and by ERDF (European Regional Development Fund) through COMPETE (Operational Programme “Thematic Factors of Competitiveness”), within Projects nos. FCOMP-01-0124-FEDER-037281 (CISTER), FCOMP-01-0124-FEDER-020312 (SMARTSKIN), and FCOMP-01-0124-FEDER-028990 (PATTERN); by FCT and the EU ARTEMIS JU under Grant no. 621353 (DEWI); and also by FCT and ESF (European Social Fund) through POPH (Portuguese Human Potential Operational Program) under PhD Grant no. SFRH/BD/67096/2009.