
Abstract
Due to the characteristics of a MANET, none of the existing solutions for service discovery work well in decentralized mobile environments. In this paper, we propose a collaborative self-governing privacy-preserving wireless sensor network architecture to address the issue of service discovery in MANET environment. The proposed architecture is able to dynamically adjust the working modes between directory-based and directory-less modes according to the network status of a MANET. The dynamic network status of a MANET is monitored by a wireless sensor network. Two location optimization algorithms are developed for topology control and the preservation of user location privacy. Simulation results show that the proposed architecture can greatly improve the performance of service discovery.
1. Introduction
With the booming development of the Internet, more and more services are deployed on the web. Hence, the need for service discovery mechanisms is becoming increasingly urgent. Much research attention has been drawn to the designing of service discovery mechanisms. Meditskos and Bassiliades [1] developed a web service discovery framework using OWL-S advertisements. Junghans et al. [2] provided a review of formalisms for semantic web service discovery and developed distinct formalisms to describe functionalities and service requests. The proposal presented by Santhana and Balasundaram [3] employed k-means clustering to address the problem of web service discovery. In addition, service discovery methods which deal with functional and nonfunctional properties of services were also extensively studied [4]. Some techniques for web service discovery were contributed in the form of a patent [5]. In general, the service discovery could be conducted in three styles: reactive way, proactive way, and hybrid way. In reactive way, a user node which has a need of some kind of service issues a service query. Other nodes which received the service query may answer it by issuing a service reply. The nodes which answer the service query could be a directory node, service node, or user node. In proactive way, service information is periodically advertised by service nodes. Both directory nodes and user nodes will receive the service advertisements. If a user node which has a potential need of service happens to receive an appropriate service advertisement could directly use the service information, rather than issuing a service query to search service information.
Generally, the reactive way only generates network traffic when there is a need. To some degree, this leads to as less message overhead as possible. During the query process, the original service query might be forwarded by a node which is unable to answer it. In order to avoid flooding the whole network, it is necessary that a subtle time-to-live (TTL) value should be set. Here, the dilemma is that a small TTL value will limit the transmission range and then brings bad influence in the service discovery, while a large TTL value will expand the transmission range and then floods the query to a wide area. Since service nodes do not actively issue service advertisements in reactive way, both the latency and the failure rate of the service discovery are high. Similarly, the TTL value of periodic service advertisements should be cautiously selected in proactive way. Moreover, in order to mitigate the flooding effect caused by periodic service advertisements, the frequency of service advertisement should be elaborately tuned. As service nodes periodically issue service advertisements no matter whether there is a need for service information, both the latency and the failure rate of the service discovery in proactive way are lower than that in reactive way. However, this in turn constantly imposes a certain amount of message overhead on the whole network. As both the reactive way and the proactive way have advantages and disadvantages, the hybrid way combines the two complementary ways. However, since disadvantages of both ways are introduced, how to achieve a tacit cooperation of the two ways is challenging.
In this paper, we propose a collaborative self-governing privacy-preserving wireless sensor network (WSN) architecture for dynamic service discovery in MANET environment. Our model is based on the famous Chord protocol and could operate in both directory-based mode and directory-less mode. The WSN which consists of directory nodes greatly facilitates the service discovery. The topology control for the WSN is conducted through local location optimization and global location optimization. The location privacy of a user is preserved based on a direction-probing algorithm used in the local location optimization. The key function of our model is the autonomic mode switch between the directory-based mode and the directory-less mode.
The rest of this paper is organized as follows. Section 2 provides the related works about service discovery architectures and discusses the existing problems. Section 3 elaborates our collaborative self-governing privacy-preserving service discovery architecture. In Section 4, we evaluate the proposed model by simulation and present a detailed analysis of the simulation results. Section 5 concludes the paper and highlights the future work.
2. Review of Service Discovery Architectures
Traditionally, service discovery architectures are classified into two types: directory-based architecture and directory-less architecture.
2.1. Directory-Based Architecture
In directory-based architecture, a directory structure could be implemented either in centralized manner or in distributed manner.
For a centralized directory, all service information is stored in the same place. All services in the whole network should be registered with a centralized repository. At the same time, the centralized repository is responsible for all service queries. Examples of centralized directory are as follows: the service location protocol (SLP) [6] suggested by IETF, the Jini technology [7] developed by Sun Microsystems, the salutation protocol [8] proposed by IBM, the universal plug and play device architecture (UPnP) [9] specified by Microsoft, the Bluetooth service discovery protocol [10] presented by Bluetooth consortium, the secure wide-area service discovery service (SDS) [11], and the intentional naming system (INS) [12]. Generally speaking, a centralized manner means attractive simplicity, inevitable single point of failure, poor scalability, and weak mobility. On the contrary, a distributed manner indicates certain complexity, robustness, good scalability, and strong mobility. Taking the characteristics of a MANET environment into consideration, we hold that the distributed manner is preferable. Hence, we omit the details of the above centralized directories and focus on the instances of distributed directory.
For a distributed directory, the problem of wide-area service discovery needs to be focused on. There are two aspects to the concept of wide-area service discovery: one is the replication of service registration, and the second is the forwarding of service query. Since directory agents reside in various locations, the service registrations they received are usually different. Then, each directory agent only knows about a portion of service information in the whole network. If there is no replication scheme in a distributed directory, service information is only locally available around the particular directory agent with which it was registered. Rather, a distributed directory with a replication scheme enables the communication among directory agents. By replication of service information, each directory agent becomes aware of all services registered in the whole network. Suppose there is a distributed directory which does not support replication of service registration. For the purpose of improving the success rate of the service discovery, it is reasonable that a service query which could not be answered locally should be forwarded to another directory agent. This operation relies on a forwarding scheme provided by the distributed directory. Recently, a considerable amount of work has been done on the distributed directory. Based on the organization of the directory agents, distributed directory could be divided into four categories: backbone-based [13–15], cluster-based [16–19], DHT-based [20, 21], and other distributed directories [22, 23].
Kozat and Tassiulas [13] provided a virtual backbone which facilitates the registration and search of services. The virtual backbone is constructed by a subset of nodes in the network, and these nodes compose a dominating set. Though there is no replication scheme, nodes belong to the backbone forward service queries to each other when they cannot be answered locally. However, there is a flaw that the destination of the forwarding operation is random. The proposal [14] presented by Sailhan and Issarny remedied the flaw by forwarding an unsolved service query to the nodes which are expected to possess the corresponding service information. The selection of destination to which a service query is forwarded is based upon the exchange of profiles among directory agents. The protocol [15] proposed by Koubaa and Fleury aimed to build a backbone which could cover all service information in the whole network. Nevertheless, as only a service provider is allowed to join the backbone, it is likely that an integral backbone might be broken down into several isolated parts. In this case, the global communication of the backbone is cut off. Consequently, the disposal of service queries is crippled.
Klein et al. [16] presented a semantic overlay of hierarchical service rings. A service ring is composed of a cluster of service providers and is considered to be a directory, since the functions of accepting service registration and answering service query are contributed in the form of a service ring. Although replication is not supported, a service ring forwards a service query which it is unable to answer. Klein and König-Ries [17] proposed that services are dynamically organized into multilayer clusters. The authors make an assumption that there exists a common ontology which could be used to describe the services within the whole network. Upon receiving a service query, a node checks its leaf-level cluster. If the service query cannot be answered, higher-level clusters are examined in the pursuit of a suitable service. It is worth mentioning that nodes are clustered based on the physical proximity and the semantic proximity [16, 17]. Schiele et al. [18] suggested that clusters are formed according to the similarity of mobility patterns. A clusterhead is always ready to answer service queries. The remaining nodes in a cluster go to sleep when idle. Tyan and Mahmoud [19] presented a service discovery approach which clusters the nodes according to physical proximity. A gateway of each cluster plays the role of a directory. Wide-area service discovery is feasible since an unsolved service query could be forwarded to another gateway.
As mentioned above, when a replication scheme is not present, an unsolved service query should be forwarded to other nodes. However, it is not easy to determine an appropriate destination for an unsolved service query. Unlike backbone-based and cluster-based models, an exciting feature that the DHT-based approaches inherently possess is hash techniques which could facilitate the provision of location information. Seada and Helmy [20] developed a rendezvous-based architecture. The basic idea is that the whole network is divided geographically and each geographical area is responsible for a portion of service information in the network. Service information is mapped to a geographical area according to a hash-table-like mapping scheme. A part of nodes within a geographical area are selected to maintain the mapped information. Since the hash function used by service query is the same as the hash function used in the mapping of service information, the proper forwarding destination of a service query could be readily obtained by a directory agent. Sivavakeesar et al. [21] described a mechanism which is similar to the approach proposed in [20] except for the fact that the mapped information is handled by all nodes within a geographical area.
Other approaches which do not involve backbone, cluster, or DHT techniques are also notable. Lee et al. [22] presented a service discovery and delivery protocol called Konark. The proposed method is decentralized and targeted at a MANET environment. Under a pure peer-to-peer design, each node in the network has a database which stores the service information provided by other nodes. Jeong et al. [23] developed an ad hoc name service (ANS) system for IPv6 MANET to facilitate the service discovery and name-to-address resolution. It is assumed that each node could be configured with a site-local scoped IPv6 unicast address by ad hoc stateless address autoconfiguration [24, 25].
2.2. Directory-Less Architecture
As a MANET environment is born with no infrastructure, it is argued that a directory-less architecture is more appropriate than a directory-based architecture [26]. However, there is an important distinction between a directory-less architecture and a directory-based architecture: there are no directory agents in a directory-less architecture. Namely, there are only user agents and service agents in the whole network. The missing of the organization and maintenance for directory agents reduces the complexity of service discovery architecture: user agents issue service queries and service agents issue service advertisements. Though service queries are generated on demand, the number of replicates of a service query during the forwarding process could become very large. Furthermore, in order to achieve a decrease in latency and an increase in service availability, the number of service advertisements is also considerable. In this case, a pursuit of good service discovery performance might be prone to bring about a serious flooding problem.
Much research attention has been drawn to the operations of service queries and service advertisements. Chakraborty et al. [27] proposed a group-based service discovery (GSD) protocol for pervasive environment. In general, the protocol consists of two components. The first component is a P2P caching scheme dealing with the spread of service advertisements. A node stores the received service advertisements in a local database called service cache. A least-remaining-lifetime cache replacement policy is used to update the cache. The second component is a group-based intelligent forwarding strategy for regulating the forwarding of service queries. In specific, an unsolved service query is just forwarded to the nodes which possess matching service information. The determination of destination nodes is based on the information contained in the service cache. The reply info caching enhanced flexible forward probability (RICFFP) service discovery protocol presented by Gao et al. [28] also consists of two parts: reply info caching (RIC) and flexible forward probability (FFP). The RIC is a technique similar to the P2P caching scheme in [27]. In particular, a node could cache the service information in a received service reply. For a received service query, if there exists a match in the cache, the service query could be answered conveniently. The essence of the FFP is that the forward probability of a service query is in reverse proportion to the number of hops it has already traveled. Nedos et al. [29] introduced an optimal forwarding mechanism for service advertisements. By monitoring the neighbors, a node merely forwards the received service advertisements to a part of its one-hop neighbors. Therefore, the broadcasting of service advertisements is turned into several unicasts. Nidd [30] set the target application environment to single-hop short-range wireless systems. For each node, the broadcasting of service advertisements is scheduled to take place at regular intervals. The task of scheduling is performed by an exponential back-off algorithm. The dissemination strategies proposed by Campo et al. [31] and Lee et al. [32] are similar that they both cache service information contained in received service advertisements. Moreover, only service advertisements which are not expired and have not been seen recently are broadcasted.
2.3. Problems
As the directory-based architecture and the directory-less architecture are complementary, hybrid architecture is another option for service discovery in a MANET environment. For a node in hybrid architecture, if there is no directory agent within its radio range, both service advertisements and service queries are sent in the same way of directory-less architecture. Otherwise, service information contained in service advertisements is registered with directory nodes. Service queries could be answered by both directory agents and service agents. Though a great deal of research has been done to the above three types of service discovery architectures, it is still controversial that which one is superior to the other two. It is recognized that the difficulty of comparison is largely due to the characteristics of a MANET environment. For instance, the nodes in a MANET might possess various degrees of mobility. Moreover, both the velocity and the moving direction of a node are unpredictable. The regular communication among nodes in the whole network should not be interrupted by the node mobility. Since a MANET is self-organized, there are no constraints on the joining and leaving of a node. The appearance of a new participator or departure of an existing participator could bring a significant change to the network topology. Again, the communication in the whole network should not be influenced.
Considering a MANET with directory-based architecture, the TTL value of service query should at least guarantee that a service query could arrive at a directory node. If the frequency of service query is low, the message overhead introduced by service registration and directory maintenance is likely to surpass the message overhead brought in by service advertisement with a directory-less architecture. For directory-less and hybrid architectures, large TTL values of both service query and service advertisement could improve the performance of service discovery. However, there is a compromise between flooding problem and performance enhancement. When there are a large number of service queries, a directory-less architecture has to increase the number of service advertisements. But since both service query and service advertisement are simply broadcasted, a risk of network congestion still could not guarantee a satisfactory performance of service discovery. Ververidis and Polyzos [33] pointed out that it could be useful to develop a flexible architecture which is able to adjust its parameters and working modes between directory-based and directory-less modes according to the status of a MANET.
3. A Collaborative Self-Governing Privacy-Preserving WSN Architecture for Dynamic Service Discovery
3.1. Network Model
3.1.1. Nodes
In our architecture, there are three possible roles for a mobile node: service provider, service requestor, and service directory. In order to perform the operations which facilitate the service discovery process, the above three types of nodes are equipped with three key components service agent (SA), user agent (UA), and directory agent (DA), respectively. For the sake of simplicity, in the remainder of this paper, we refer to service provider nodes, service requestor nodes, and service directory nodes as SAs, UAs, and DAs, respectively. To facilitate the presentation of our model, we consider a MANET consists of DAs, SAs, and UAs. In addition, there is a WSN composed of all DAs.
3.1.2. Directory Agent
Each DA is a wireless sensor node. DAs offer a place storing service information and SAs register service information with DAs. Then, DAs answer the service queries issued by UAs based on the service information they have. The existence of DA is to improve the effectiveness of the service discovery architecture. The WSN constituted by all the DAs is based on Chord [34]. Chord is a scalable distributed lookup protocol which has been applied to service discovery [35–37]. The most important operation that Chord provides is mapping a given key onto a node. By consistent hashing, each data item could be associated with a unique key. The
3.1.3. Unified Service Information Management
Our service discovery architecture employs a unified service information management scheme. It is necessary that all DAs, SAs, and UAs which participated in the architecture are aware of the scheme. In particular, there is a list of properties which is used for profiling a service. Each property has a number of values. We denote the list of properties and values by L and all nodes in the network have knowledge of this list. For example, a property called scope may indicate the application domain of a service, such as search engine, news archive, and anonymous FTP. We assume that there exists a predetermined list of properties and the corresponding values. The properties are denoted by set
Definition 1.
By description of a service we mean the character string
Then, we know that there are totally
Service description.
3.2. Directory-Based Mode
In directory-based mode, all DAs in the MANET form a Chord network. All nodes in the MANET are mobile. SAs register their service information with DAs. A service query issued by a UA is handled by DAs.
3.2.1. Service Registration and Deregistration in WSN
For service registration, the service information submitted to a DA consists of three parts: description of the service, ID of the service provider (e.g., company name), and URL for accessing the service. Note that only a complete service description can be used for service registration. There are 32 bytes to accommodate the ID of service provider. Though the HTTP protocol does not stipulate the maximum length of a URL, we limit it to a maximum of 2048 bytes. The format of service registration is shown in Figure 2.
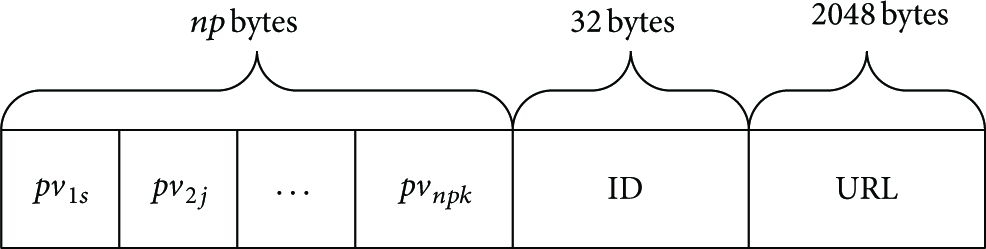
Service registration.
Since the WSN is based on Chord, we denote the identifier space of the Chord network by
In our model, we use the SHA-1 [43] as the consistent hash function to generate keys for both DAs and services. We denote the hash function by
3.2.2. Key Generation and Searching in WSN
In unstructured P2P network, the searching based on a keyword is feasible. However, the consistent hashing of filename in structured DHT prohibits such operation in Chord. As a result, only the approach of exact match works. The inverted index proposed in [44] employs the mapping of
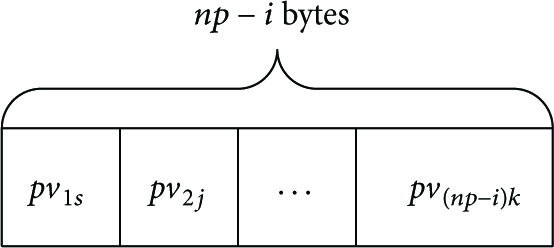
When there is a potential need of certain service, several interested values are selected from the list L by a UA. Then, a service query with the same format as a service description is sent to a DA. Upon receiving a service query, a DA first checks whether there are missing values for properties. For a complete description, the DA which received the service query simply appends the IDs of service providers known to it and hashes the character string composed of the description and the ID. Then, the DA searches the obtained keys. However, it is very likely that values of some properties are missing due to uncertainty. Consequently, we have an incomplete description. For i missing values, each one is filled by several most popular values queried in the past. We denote the number of most popular values by
After the filling operation of the original incomplete description, we have
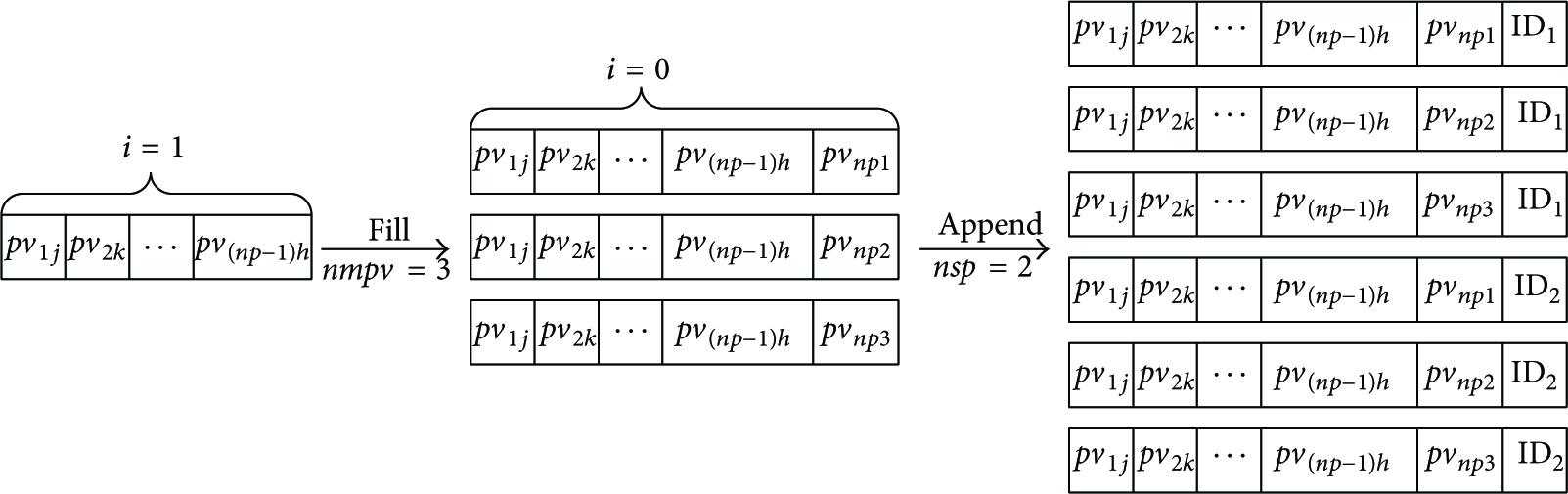
Filling and appending.
3.2.3. Topology Control and Function Tuning for WSN
Since DAs are mobile in directory-based mode, the mobility has a strong impact on the topology of the WSN. Moreover, the unpredictable node failures also exert influence on the topology of the WSN. In our model, the topology control for WSN consists of two parts: local location optimization and global location optimization.
The local location optimization (LLO) is performed between a DA and the UAs which are communicating with the DA. For an individual DA, we divide its 360-degree radio range into six equal adjacent areas:
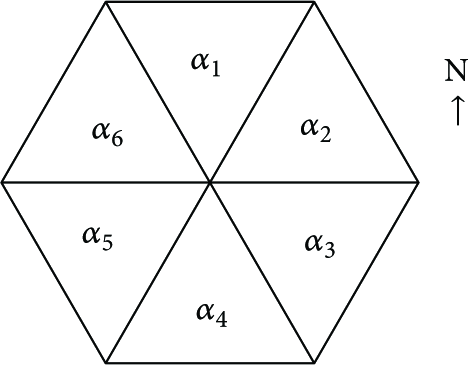
Six areas.
The two salient features of the local location optimization are privacy preservation and energy conservation. As a long communication distance requires more energy for radio transmission, it is beneficial that the communication distance between a DA and a UA could be shortened once they get in touch with each other. In our model, the result of a service query is sent to a UA by the original DA it queried. This procedure makes the shortening of communication distance even more important. Since the mobile nodes are equipped with omni-directional antennas, a DA has no idea of where a UA is and therefore is unable to determine a correct moving direction. For the sake of privacy protection, a UA is unwilling to share its location in any form (e.g., GPS coordinates). To address this problem, we develop a direction-probing algorithm to determine a moving direction for a DA. As shown in Figure 5, this algorithm contains a four-step movement:

Four-step movement.
Considering a DA whose original location is
Moving direction determination.

When there are several UAs which are communicating with the DA, the desired moving directions related to different UAs might be various. Generally, it is considered that the energy consumption is in direct proportion to the communication distance. Hence, in order to reduce the total energy consumption, the sum of distances between the DA and each UA should be as small as possible. Considering two UAs
Direction-Probing
(1) original signal intensity (2) (3) (4) (5) signal variation (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25) (26) (27) (28) (29)
The global location optimization (GLO) is performed between DAs and it is based on the direction-probing algorithm described in the local location optimization. Other than local location optimization, the global location optimization concentrates on topology maintenance.
As a DA in the WSN has a maximum transmission range, in order to keep the connectivity of the WSN, the relative positions among the DAs should be carefully controlled. The global connectivity of the WSN could be decomposed into several groups of connectivity. In particular, we develop a connectivity maintenance algorithm to maintain the local connectivity of three DAs. Considering an individual DA which is denoted by
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25) (26) (27) (28) (29) (30) (31) (32) (33) (34) (35) (36) (37) (38) (39) (40) (41) (42) (43)
As energy conservation is a critical issue in WSN for DAs and network life, we develop a function tuning algorithm based on the remaining energy of a DA. Moreover, this algorithm also assists the topology maintenance. We denote the remaining energy of
Energy statuses and descriptions.

When
As described above, when the status of a DA changes from normal to low, there is only one function that is removed, namely, the local location optimization. All the remaining functions of a DA are operational in three statuses: normal, low, and alert. The function of global location optimization is removed when the status of a DA changes to serious. Hence, this function tuning algorithm significantly assists the connectivity maintenance. The detailed function tuning algorithm is illustrated in Algorithm 3.
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18)
3.3. Directory-Less Mode
In directory-less mode, all DAs in the MANET are stationary. However, they still keep forming a Chord network. Other nodes in the MANET are mobile, namely, UAs and SAs. Though the WSN based on the Chord protocol still exists, there are no topology control and key searching based on the Chord network. Thus, the directory-less mode is much simpler than the directory-based mode. For DAs and SAs, the service registration is operational as before. This is done to get prepared for a mode switch. The mode switch between the directory-based mode and directory-less mode is detailed later in Section 3.4. In classic directory-less architectures, there are only UAs and SAs. Hence, there is no so called relaying function associated with DAs. The service discovery is only conducted based on service queries issued by UAs and service advertisements issued by SAs. In our model, the DAs provide relaying function for service queries, service advertisements, and service replies. Moreover, since DAs possess a large amount of service information, a DA could issue a service reply to answer a service query based on the service information it has (service information it originally knows and service information it learns through the relaying). For the purpose of mitigating the flooding problem and improving the performance of service discovery, we develop a two-hop zone scheme for the directory-less mode.
3.3.1. Two-Hop Zone Scheme
For a node 
Similarly, a two-hop neighbor 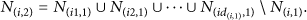
By the definition of a two-hop neighbor, the number of two-hop neighbors of node 
Note that node 
Thus, node
For an individual node
Premise 1. Let
Node
We denote the total number of service records contained in the service advertisements received by node 
For each one-hop neighbor of
If node 
Node 
Node
Suppose the TTL value of the received service advertisements is under Poisson distribution

In our two-hop zone scheme, node 
The universal node 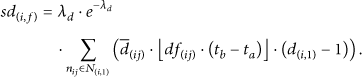
Combining (5) and (10) we have the total number of service records forwarded by node 
Then, (6) could be rewritten as
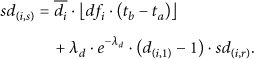
That is to say, each one-hop neighbor of node
When node
We denote the total number of service queries sent by node 
Suppose node 
In our two-hop scheme, we stipulate that a service query contains exactly one service request. Hence,
For the service queries received from other nodes, node
Suppose the TTL value of the received service queries is under Poisson distribution

We consider all the service queries sent to node 
Suppose that node 
Then, (13) could be rewritten as

Compared with service advertisement and service query, the number of service replies is small in nature. In general, the occurrence of a service reply is unpredictable and irregular. It is actually meaningless to impose restrictions on the sending frequency of a service reply. Moreover, in order to improve the performance of service discovery, we do not assign a specific upper bound to the initial TTL value of a service reply. A service reply uses the path information contained in the corresponding service query. The service replies designated to node
We denote the total number of service replies sent by node 

Besides sending its own service replies, node 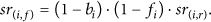
Combining (19), (20), and (21), the total number of service replies sent by node 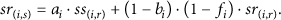
3.3.2. Level of Connectivity
In order to facilitate a further investigation of the two-hop zone scheme, we propose a novel method to calculate the level of connectivity for the whole network based on the two-hop zone scheme. In the first place, we formulate the level of connectivity of two arbitrary nodes under the two-hop zone scheme. For two arbitrary nodes

Node relationships under the two-hop zone scheme.
In Figure 6(a), node 
In Figure 6(b), the number of hops between node 
In Figure 6(c), the number of hops between node 
In Figure 6(d), the number of hops between node 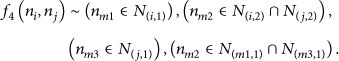
In Figure 6(e), the number of hops between node 
More complex situations can be decomposed and modeled through the iteration of different cases illustrated in Figure 6.
The level of connectivity between node 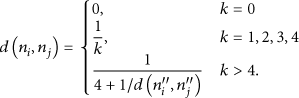
For
In the case of 
Suppose the set of nodes which node 
For N nodes in the whole network, there exist 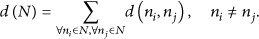
Theoretically, a sufficiently large value of R could result in a situation that there always exists a path between two arbitrary nodes, irrespective of the magnitude of N. With the increase of R, the value of
3.4. Autonomic Switch between Two Modes
In order to facilitate the information updating and network status gathering in the WSN, we introduce a monitoring token which is kept passing around the Chord network. The autonomic switch between the directory-based mode and the directory-less mode is based on the network status gathering. By a round, we mean that the monitoring token is transmitted by all the DAs once. The current mode of the service discovery architecture is indicated by a flag called MODE, and its value is DA-BASED or DA-LESS. In addition, the monitoring token contains two lists: the SA list

Monitoring token.
Though the unified service information management scheme described in Section 3.1.3 stipulates that all nodes in the MANET have knowledge of the properties and values of services, the DAs initially have no idea of any SAs. Thus, we use the monitoring token to perform the information updating associated with SAs. In general, the appearance of a new SA is accompanied by service registration initiated by the SA. For a DA which received a service registration, it updates local database with the service information. When the monitoring token arrives at the DA, the DA checks whether the SA list of the monitoring token contains the SA of the service registration. If the SA already exists, the DA did nothing for the SA. Otherwise, the DA adds the SA to the SA list of the monitoring token. Meanwhile, the DA checks whether there are unknown SAs. The local database is updated with the information of SAs which are unknown to the DA. That is to say, when the monitoring token arrives at a DA, the DA initiates a two-way update about the information of SAs. When an existing SA is about to leave the MANET, it issues a logout message to an arbitrary DA within its radio range. The DA which receives the logout message first removes the service information associated with the SA in the local database. When the monitoring token arrives at the DA, the DA marks a logout flag in the SA list for the SA. During the transmission of the monitoring token, other DAs become aware of the logout of the SA through the two-way update and remove the service information associated with the SA in their local databases. When the monitoring token arrives at the DA next time, the DA issues a logout acknowledgment to the SA. As long as the SA receives the logout acknowledgment, it could leave the network freely and there is no need to logout again. Although there is no topology control and key searching based on the Chord network in the directory-less mode, the transmission of the monitoring token is still operational. Thus, the two-way update, service registration, and SA logout are also performed normally. The detailed information updating procedure is shown in Algorithm 4.
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25) (26) (27)
Besides information updating, the monitoring token also plays another vital function: network status gathering. A DA in the WSN senses the local network status in its vicinity. The information of local network statuses is gathered by the monitoring token, and then a high-level overview of the network status is revealed. This overview of the network status facilitates the autonomic switch between the directory-based mode and the directory-less mode. Suppose our service discovery architecture is under the directory-less mode. If the frequency of service query decreases, the frequency of service advertisement should be decreased accordingly. However, if the frequency of service query keeps decreasing significantly, a switch to the directory-based mode is needed. Now, assume our service discovery architecture is under the directory-base mode; if the frequency of service query increases, the frequency of service advertisement should be increased. If the frequency of service query keeps increasing significantly, a switch to the directory-less mode is needed.
In particular, each time the monitoring token arrives at a DA, if the DA realizes that the frequency of service query it perceived locally is beyond a threshold
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21)
4. Numerical Results
4.1. Experimental Environment and Simulation Parameters
For the purpose of evaluating our model, we develop a MANET platform which is based on the NS-2 [45]. All simulation results are obtained on HP with Inter Core2 Q9550 2.83 GHz, 4 GB RAM with Debian 2.6.32-48squeeze1 (Linux version is 2.6.32-5-686) and gcc 4.3.5 (Debian 4.3.5-4).
In our platform, the number of DAs in the WSN is 32. The identifier space of the underlying Chord network is
Information of the 32 DAs.

For a DA 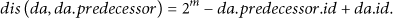
Otherwise, we compute the distance between them by

We define the responsibility ratio of 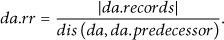
As shown in Figure 8, the responsibility ratios of the 32 DAs are marked as blue crosses and the linear regression equation of them is drawn in red. The responsibility ratios of most DAs are within the range of

Responsibility ratio of 32 DAs.
4.2. Performance Criteria
Though there are various criteria which are used to evaluate the effectiveness of service discovery architectures, we adopt three fundamental criteria: service availability, message overhead, and delay. Each of these criteria is presented below.
4.2.1. Service Availability
Gao and Ma [48] considered that the service availability is the probability that a service is available. It is formulated as the ratio of the number of times a service responds to a user request to the number of total requests made by the user. This definition is targeted at the evaluation of user experience toward a known service. However, the service availability in our model aims to evaluate the performance of service discovery. Thus, we define the service availability from another perspective. In particular, we introduce the service availability of a single node and the service availability of the network. Since service queries and service replies are flowing through all nodes in the network (including UAs, SAs, and DAs), we define the service availability of a single node as the ratio of the total number of incoming service replies to the total number of outgoing service queries. Considering a node 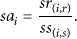
Then, the service availability of the network is defined as
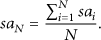
4.2.2. Message Overhead
The concept of message overhead mainly concerns two types of messages: service queries and service replies. In order to improve the performance of service discovery, both the two kinds of messages are duplicated to a certain extent. Specifically, a service query is duplicated for the purpose of reaching more nodes. While a service reply is duplicated in another way, since there are several copies of service queries, it is rational that there may appear several service replies which are originated from various nodes. As service replies are generated in response to the received service queries, we hold that normal service replies should not be considered as message overhead. Thus, we hold that the message overhead should be measured by the portion of service queries which are duplicated redundantly. We denote the number of service queries issued by node 
Then, the message overhead of the network is defined as
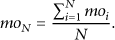
4.2.3. Delay
The response time is a prominent factor of a harmonized user experience. In practice, the delay is greatly concerned by many users. In our model, the delay perceived by a UA consists of two parts: the processing time and the transmission time. Since we do not focus on the relationship between the processing time and the transmission time, we measure the delay in all. Though the number of service queries issued by node 
Then, the delay of the network is defined as
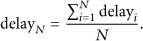
4.3. Experimental Results and Analysis
The two characteristics of the directory-based mode are energy conservation and function tuning. Both characteristics concentrate on prolong the network lifetime for the WSN. In practice, as certain applications require all the nodes are operational, the network lifetime may mean the time period before the first node failure due to energy exhaustion. However, in most applications, the network lifetime means the time period before a number of the nodes in the network exhaust their energy. Notable topology management schemes have been proposed for energy conservation issues, such as [49–51]. However, a major assumption of these schemes is high density of sensors. In order to investigate the performance of our model, we compare it with the approach proposed by Pan et al. [51]. The simulation result shown in Figure 9 indicates a slightly better performance of our model.

Operational nodes versus time step.
As shown in Figure 9, both percentages of the operational nodes for the two models decrease with the increase of time step. In our experiments, we assume that the percentage of failed nodes which indicates the end of the network lifetime is 50%. Note that this percentage is just used for the comparison between our model and Pan et al.'s model. In fact, our model is able to operate normally even when there are few nodes left in the network. The percentage of the operational nodes falls below 50% around
Now, we consider our directory-based mode alone. For three fixed values of the frequency of service query

Service availability versus time step.
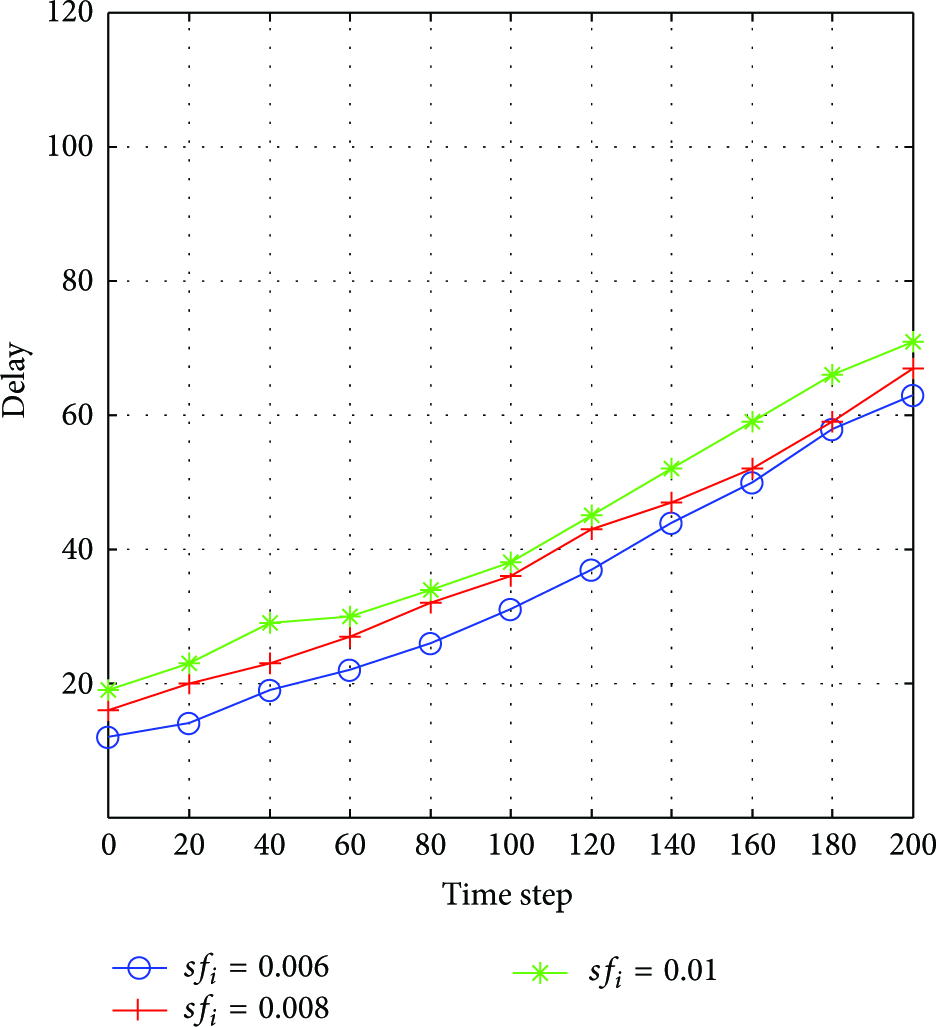
Delay versus time step.
As shown in Figure 10, the values of service availability of the network for
As shown in Figure 11, the values of delay of the network for
For the directory-less mode, we adopt a fixed setting of
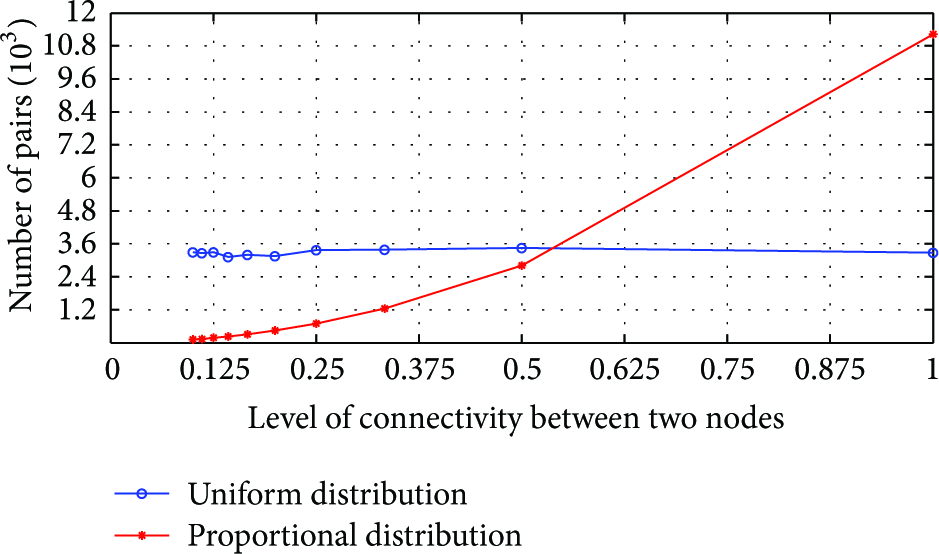
Number of pairs for 10 levels of connectivity.
As previously described, the mode switch between the directory-based mode and the directory-less mode is triggered by the percentage of locally overloaded DAs. Essentially, a local overload for a DA is caused by excessively frequent service queries. In order to investigate the mode switch of our model, we conducted extensive simulations to find an empirical threshold of the frequency of service query. Finally, we learned that the empirical threshold of the frequency of service query is
Figure 13 shows the service availability of the network under the two distributions. When

Service availability versus frequency of service query.
As shown in Figure 14, the delay of the network monotonically increases with the increase of the frequency of service query when
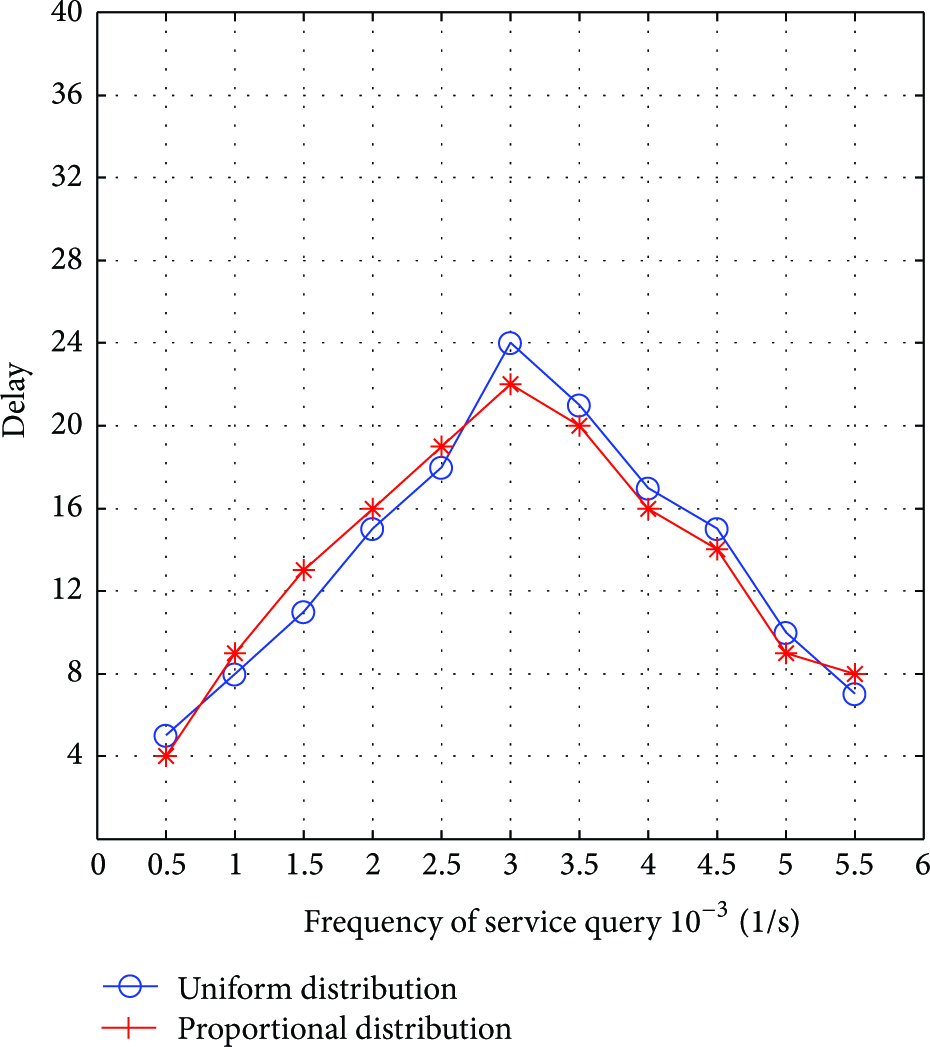
Delay versus frequency of service query.
As shown in Figure 15, when

Message overhead versus frequency of service query.
Through the experimental results shown in Figures 13–15, it can be observed that the mode switch function of our model could significantly improve the performance of service discovery in terms of service availability, message overhead, and delay.
5. Conclusions
With the increasing need for flexible service discovery architectures for service discovery in MANET environment, we propose and evaluate a collaborative self-governing privacy-preserving wireless sensor network architecture. The proposed architecture is based on the Chord protocol and focuses on location optimization and energy conservation. The key function of the architecture is that it provides an autonomic mode switch between the directory-based mode and the directory-less mode. In order to evaluate our model, we developed a MANET platform and conducted extensive simulations regarding three critical criteria concerning service discovery: service availability, message overhead, and delay. The simulation results indicate that the autonomic mode switch between the directory-based mode and the directory-less mode greatly improves the performance of service discovery in terms of the above three criteria. One open issue is how to effectively determine an empirical threshold of the frequency of service query.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
The authors would like to thank the anonymous reviewers for their constructive comments on this paper. This work is supported by Program for the Key Program of NSFC-Guangdong Union Foundation (U1135002), Major National S&T Program (2011ZX03005-002), National Natural Science Foundation of China (60872041, 61072066), the Fundamental Research Funds for the Central Universities (JY10000903001, JY10000901034, K5051203010), and the GAD Pre-Research Foundation (9140A15040210HK61).