
Abstract
Human action recognition in wireless sensor networks (WSN) is an attractive direction due to its wide applications. However, human actions captured from different sensor nodes in WSN show different views, and the performance of classifier tends to degrade sharply. In this paper, we focus on the issue of cross-view action recognition in WSN and propose a novel algorithm named discriminative transferable sparse coding (DTSC) to overcome the drawback. We learn the sparse representation with an explicit discriminative goal, making the proposed method suitable for recognition. Furthermore, we simultaneously learn the dictionaries from different sensor nodes such that the same actions from different sensor nodes have similar sparse representations. Our method is verified on the IXMAS datasets, and the experimental results demonstrate that our method achieves better results than that of previous methods on cross-view action recognition in WSN.
1. Introduction
Recent advances in wireless communications and electronics have encouraged the advent of massively distributed wireless sensor networks (WSN) [1, 2]. The WSN consists of a large number of small, low cost, and low power sensor nodes, which collect and disseminate environmental data [3]. WSN has a wide range of applications, such as surveillance systems, guiding systems, biological detection, habitat, agriculture, and health monitoring [4, 5]. Video surveillance in WSN is an attractive direction which leads to lots of researches [6, 7]. In this case, each sensor node is a surveillance camera. Human action recognition is a key technique of video surveillance in WSN, which has been widely studied over the past several years. A large number of approaches have been proposed to make action representation more discriminative, such as space-time pattern templates [8], 2D shape matching [9, 10], trajectory-based representation [11], optical flow patterns [12], spatiotemporal interest points [13, 14], and attribute-based methods [15]. In the bag-of-words (BOW) model framework, methods which extract features using spatiotemporal interest points have shown promising performance. These methods are relatively robust to illumination variation, background changing, and noise, because they do not rely on preprocessing techniques, for example, trajectory tracking or motion detection. Moreover, another kind of methods [16–18] inspired by this model exploits the spatial and temporal contexts as another type of feature for describing interest points. These approaches are effective for recognizing actions observed from similar views, but when human actions captured from different sensor nodes in WSN show different viewpoints, their performance tends to degrade sharply. It is because the same action looks very different when observed from different sensor nodes (views). Therefore, action models learned using labeled samples in one sensor node are less discriminative for recognizing actions in a different sensor node. The intuitional approach is training a separate classifier for each sensor node, but there are too many sensor nodes in WSN leading to lack of labeled samples.
A large number of approaches have been proposed to address the problem of action recognition captured from different sensor nodes in WSN (also called cross-view action recognition). Some of these approaches employ some existing techniques, such as geometric constraints [8], body joints detection and tracking [19, 20], and 3D models [21, 22]. For instance, Rao et al. [20] presented a view-invariant representation of human action to capture the dramatic changes in the speed and direction of the trajectory using spatiotemporal curvature of 2D trajectory. Nevertheless, the above approaches rely either on body joints detection and tracking or alignment between views which are limited in practice. Junejo et al. [23, 24] explored a self-similarity matrix of action sequences, which was high stability under view changes. Chen and Grauman [25] proposed to form a 3D appearance tensor indexed by pose examples, viewpoints, and image positions, which can infer unseen view examples.
Recently, transfer learning approaches are employed to address cross-view action recognition. Farhadi and Tabrizi [28] generated split-based features in the source view using maximum margin clustering and then transferred the split values to the corresponding frames in the target view. Liu et al. [26] learned a cross-view bag of bilingual words using corresponding pairs. Then, the action videos are represented by bilingual words in both views. Li and Zickler [27] assumed that there is a virtual path connecting the source view with the target view. Each point on this virtual path is defined as a virtual view. Then, several virtual views are sampled to form a single long feature that is robust to view variations. Zhang et al. [29] sampled all the virtual views on the virtual path and integrated them into an infinite-dimensional feature. Correspondingly, a virtual view kernel is proposed to measure the similarity between two infinite-dimensional features.
In this paper, we propose a novel approach for cross-view action recognition in WSN by learning discriminative transferable sparse coding (DTSC). We consider the actions observed simultaneously in both source and target views with labels (corresponding pairs) and each sensor node corresponds to one view. The target of our approach is to train a model using a small amount of corresponding pairs in the source view and test the model in the target view. For making the DTSC suitable for recognition, the sparse representation is learned with an explicit discriminative goal. Concretely, the discriminative power of sparse coefficients depends on twofold. First, the sparse coefficients should well represent the actions using the corresponding subdictionary. Second, the product value between the sparse coefficient and subdictionary from different class is expected to be zero. To this end, we add a constraint on both sparse coefficients and subdictionary.
In the implementation of training process, we first construct a separate dictionary for each view utilizing k-means algorithm and represent action videos using bag-of-words (BOW) model. Although each pair of videos captures the same action from two views, the feature representations of an action in the two views are different. It is because each action is built on its own dictionary independently. In order to transfer knowledge from one view (sensor node) to another one, we simultaneously learn the dictionaries from different views such that the same actions from different views have similar sparse representations. The main idea is illustrated in Figure 1.
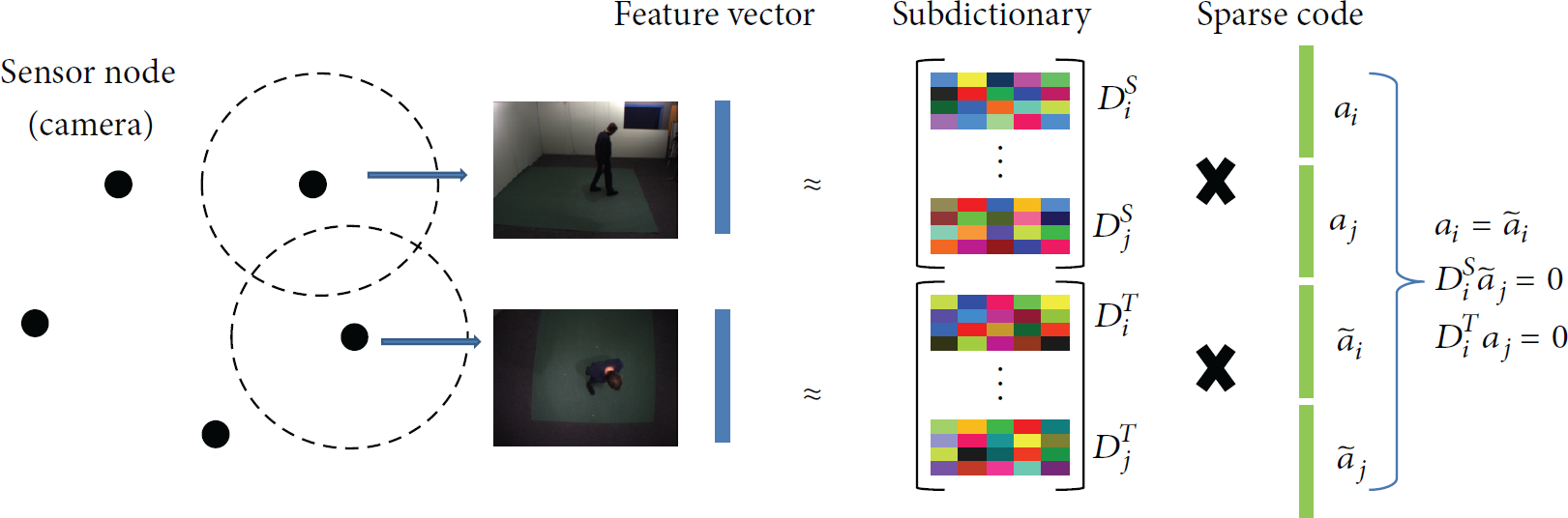
Learning discriminative transferable sparse coding in WSN. We force the same actions from different sensor nodes to have similar sparse representations and expect the product value between the sparse coefficient and subdictionary from different class to be zero.
The rest of this paper is organized as below. We review the sparse coding method in Section 2. Then, we present our DTSC algorithm in Section 3. Section 4 shows the experimental results which outperform the state-of-the-art methods on the IXMAS multiview dataset. Finally, in Section 5, we conclude the paper.
2. Sparse Coding
Sparse coding (or sparse representation) is a powerful tool for statistical signal processing, and it has already been widely applied in many fields [30, 31]. The success of sparse coding largely owes to the fact that natural signals are intrinsically sparse in some domain. This model sparsely encodes a signal over an overcomplete dictionary and classifies the signal based on its coding vector. Sparse coding modeling of data assumes an ability to describe the signals as a linear combination of a few atoms from an overcomplete dictionary.
For a signal

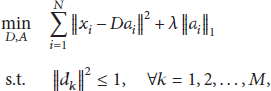
3. Discriminative Transferable Sparse Coding
The sparse coding, however, is unsuitable for cross-view action recognition in WSN. First, sparse coding is an unsupervised learning algorithm which neglects the discriminative information among action categories. Second, sparse coding is not robust to view variance because the feature representations of an action in the two sensor nodes are significantly different. To overcome these drawbacks, we propose a novel coding strategy named discriminative transferable sparse coding (DTSC). We expect that the sparse coding coefficients not only possess discriminative power, but also are similar for the same action in different views.
3.1. Sparse Coding Based on Discriminative Learning
Let

3.2. Sparse Coding Based on Transfer Learning
Another goal of our DTSC is to transfer knowledge from one sensor node (source view) to another one (target view) using corresponding pairs. We force each pair of videos of the same action observed from the source and target views have the same sparse coefficient. To this end, we construct different subdictionaries for each class in different views. Thus, the sparse coding based on transfer learning is formulated as


3.3. Solution of DTSC
The optimization of DTSC model can be conducted by alternatively optimizing

This is a linear regression problem with

parameters λ, ρ (1) Fix solve (2) Fix
3.4. Feature Representation
In the training stage, we learn a subdictionary
4. Experimental Results
4.1. Dataset and Low-Level Feature Extraction
We verify our DTSC on the IXMAS multiview action dataset [22], which consists of eleven daily-life actions, such as kick, point, and cross arms. Each action is performed three times by twelve actors and observed from five different views including four side views and one top view, where each view corresponds to one sensor node.
For fair comparison, we extract the same low-level action descriptors as [26, 27]. Specifically, we first extract the local feature, that is, the spatiotemporal interest points proposed in [13]. To detect the interest points, a 2D Gaussian filter and then a 1D-Gabor filter are applied to an action video, and the interest points are detected at the local maximum response. We extract up to 200 cuboids from each action video. Each cuboid is represented by a 100-dimensional descriptor learned by PCA. These descriptors are further quantized to 1000 codewords by k-means clustering and each action video is represented by a histogram using bag-of-words model [34]. To complement the local feature, we then extract global shape-flow feature [35]. Specifically, three channels features are extracted from each frame: horizontal optical flow, vertical optical flow, and silhouette. Then PCA is again used to reduce the dimensionality. Descriptors from neighboring frames are concatenated with the current frame descriptor to incorporate temporal information. The histogram vector is built over 500 quantized codewords. Finally, for each action video, we concatenate the local and global features to form a 1500-dimensional feature vector.
4.2. Pairwise Cross-View Recognition in WSN
Our algorithm is evaluated on all possible pairwise view combinations. For an accurate comparison to [26, 27], we follow the same leave-one-action-class-out strategy for choosing the orphan action which means that each time we only consider one action class for testing in the target view. The final results are reported according to average accuracy for all action classes in each view. It is noticeable that the orphan action class is not used to train the dictionary and establishes corresponding pairs. The corresponding pairs are randomly chosen from the training samples and these pairs account for 30% of the nonorphan samples. We set
Table 1 lists the recognition accuracy for all possible source-target view combinations. We compare our DTSC with the method without transfer learning [26, 27]. Note that we omit the accuracy of [28, 36], since they report lower results than [26, 27] in most view combinations. Some conclusions can be drawn from Table 1. First, our DTSC outperforms all five possible target views with varying source views on average recognition accuracies, which can be seen in the last row of Table 1. Second, the method without transfer learning performs very poorly and the recognition accuracy of most combinations is less than 50%, while our DTSC achieves very high accuracy which demonstrates the effectiveness of transfer learning. Third, our algorithm obtains the highest recognition accuracy in all the 20 view combinations. It is because our DTSC not only is able to transfer knowledge between views (sensor nodes), but also possesses discriminative power.

4.3. Influence of Parameters Variances
We further evaluate the performance of the proposed DTSC with respect to λ and ρ in (5) which control the sparsity of the coefficient vector and the importance of discrimination. From Table 2, the experimental results indicate that when
Cross-view action recognition accuracy (%) under different λ and ρ.

5. Conclusions
In this paper, we propose a discriminative transferable sparse coding approach (DTSC) for cross-view action recognition in WSN. The proposed DTSC simultaneously considers the discrimination and transferability of sparse representation. For the sake of discriminative sparse representation, we expect the product value between the sparse coefficient and subdictionary from different classes to be zero. To learn the transferable sparse representation, we force the same actions from different sensor nodes to have similar sparse coefficients. The experimental results demonstrate that our method achieves better results than that of previous methods in cross-view action recognition in WSN.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work is supported by the National Natural Science Foundation of China under Grant no. 61401309 and no. 61202327 and the Doctoral Fund of Tianjin Normal University under Grant no. 5RL134 and no. 52XB1405.