
Abstract
In mobile sensor networks (MSN), actuated sensors collaborate with each other in some predefined missions. The collaboration requires application-level coordination based on a strongly connected underlying network, which is often in an infrastructure-free ad hoc manner. The particular network topology provides flexibility as well as vulnerability to the potential applications of MSN; for example, the connectivity can be easily jeopardized if the network is partitioned into disjoint segments from the failure of some critical sensors. In this paper, a critical sensor determination and substitution (CSDS) strategy is proposed to address the important problem of network partitions in mobile sensor networks (MSN) due to the failure of particular sensors. CSDS utilizes a graph-theoretic method to locally identify critical sensors with 2-hop neighboring information. Then, an efficient backup sensor selection algorithm is proposed to monitor the critical sensors and, if necessary, substitute it in order to eliminate the partitions in MSN. The main contribution of our proposed work is that CSDS requires the relocation of only one sensor in each partition elimination process, so that the impacts on the primary missions of the MSN are minimized. Experimental simulations are conducted to evaluate the correctness and effectiveness of CSDS.
1. Introduction
Last decade we have witnessed a rapidly growing development in mobile sensor network (MSN) based on its enormous potential applications in a variety of scenarios such as terrain exploration, environmental monitoring, and remote measuring [1]. As an effective substitution of human, MSN often works in harsh environments where many potential risks, for example, mechanism malfunction or intentional sabotage, can be expected. The vulnerable topology of the ad hoc network based sensor system can be easily jeopardized due to the failure of some sensors caused by the potential risks. In particular, if the failed node is a critical sensor, for example, a cut-vertex, the network will be partitioned into a few disconnected segments. In this case, intersensor communications will not be possible for all sensors to deliver a timely response to critical missions, which may further cause fatal consequences to the applications [2]. Therefore, an efficient partition elimination, also called connectivity restoration [3] method, is pivotal to guarantee the successful execution of certain missions for MSN.
To date, many connectivity restoration schemes have been proposed; please refer to [3] for a comprehensive review on this topic. When the MSN is deployed into a remote area, where manually moving sensors are not applicable, a feasible way to restore the connectivity is to substitute the failed sensor by autonomously relocating the healthy ones. Both centralized [4] and decentralized [5] methods are designed in order to fulfill this objective. We argue that decentralized methods are rather a natural choice due to the distributed and autonomous characteristic of most MSNs. Typically, the restoration process involves a series of actions, including cut-vertices determination, backup sensors selection, and sensor relocation [6]. Contemporary schemes often focus on the connectivity restoration with multiple sensors. However, the sensors' current tasks are often neglected. When relocating sensors, most connectivity methods simply adopt direct movement, that is, the backup sensor moves directly towards the failed sensor [7], while other methods use potential function based controller to navigate the movements of sensors [8]. These methods, however, assume that all sensors in the network are free to be relocated in case of connectivity restoration.
Whether by cascaded movements or by potential force driven movements, it is often required to move several sensors just to restore single failure. It is argued that if a sensor rests in a spot, it may stay there for a reason; for example, it is occupied by a particular mission. It would not be feasible to move it just for reconnecting the network. Therefore, minimizing the number of sensors moved in connectivity restoration is important for task-oriented applications of MSN. To address this problem, a critical sensor determination and substitution (CSDS) strategy is proposed to eliminate partitions in mobile sensor networks (MSN) due to the failure of a critical sensor. First, a graph-theoretic method is designed to locally identify critical sensors with 2-hop neighboring information by computing the Laplacian matrix of a local spanning subgraph. Then, an efficient backup sensor selection algorithm is proposed to monitor the critical sensors and, if necessary, substitute it in order to eliminate the partitions in MSN. A preliminary version of this work was presented in [9].
The main contribution of our proposed work is to guarantee all partitions caused by the failure of a critical sensor are eliminated by moving only ONE backup sensor, as long as a noncritical sensor exists. Therefore, the negative impacts on the primary missions of the MSN are minimized. Theoretical analysis and experimental simulation studies are provided to verify the correctness and evaluate the performance of the proposed CSDS.
The outline of this paper is as follows. Section 2 presents the related work and motivations. The problem is then formulated in Section 3. In Section 4, we present the cut-vertices determination and backup selection algorithms in detail and provide the analytical results of CSDS. The results and discussions for CSDS simulation are provided in Section 5. Finally, Section 6 concludes the paper.
2. Related Work
2.1. Graph and Network Optimization
Connectivity restoration belongs to the basic problem of network optimization and resilience, which is rooted in graph theory and its application in networks [10]. The basic concept of connectivity restoration is to find the optimal backup node and/or optimal backup location in which the backup replaces the failed one in order to achieve the objective of restoring connectivity. Meanwhile, some secondary objective, for example, minimizing the impact on topology, or reducing nodes' degree, may be pursued. Such a problem is similar to the problem of service facility location, that is, locating a central facility in a network so as to minimize the sum of distances from the sources to it; the distance reflects the associated flow volume and/or cost of the paths [11]. Service facility location can be further classified as two main problems, that is, “p-median problem” and “p-center problem,” according to different objectives. In [12], a distributed algorithm is proposed to locally compute the near-optimal p-medians in linear time, which is proved to be suitable for online calculation in dynamic and large-scale networked systems. Other objectives may be also pursued in service facility location problem. In [13], the multicovering emergency service facility location problem is investigated, and a mathematical programming model is proposed to minimize the sum of expected disaster losses and the total costs of emergency service facilities. Deploying/choosing service facility within the network may naturally cluster the network into several subgraphs, with the facility being the cluster head to provide various services to the subnet. An adaptive clustering approach is proposed for autonomic systems in [14], and a unique feature of self-healing is achieved by recalculating near-optimal cluster head in case of component failures or congestion, for example, failure of links. Both service facility location and self-healing clustering problem can be applied to the problem of network resilience with certain variation. However, for this work, we focus on the fast restoration of the network connectivity rather than network optimization, and the failure of network is caused merely by the failure of node.
2.2. Direct Movement for Connectivity Restoration
The distributed connectivity restoration with respect to the failure of single cut-vertices has been extensively investigated [4–8, 15–19]. Both direct movement and potential force based movement are implemented. The direct movement can be further divided into block movement [2] and cascaded movement [15] methods according to their different patterns. In [2], several algorithms were proposed for achieving a 2-connectivity fault-tolerant configuration in multirobot networks by moving a subset (block) of mobile robots. Block movement can maintain the topology within the subset but requires a significantly large movement distance. To overcame this drawback and reduce the number of sensors moved, the cascaded movement method that only moves a set of necessary nodes for restoration is employed. In [7], Abbasi et al. presented a Distributed Actor Recovery Algorithm (DARA) to address the 1- and 2-connectivity restoration in wireless sensor and actor network (WSAN) with 2-hop neighboring information, DARA selects the backup candidate according to its node degree and distances, and then the selected nodes move to substitute the failed actor and their parental nodes in sequence. A more effective cascaded movement method was introduced in [15], which also added an effective mechanism to determine the cut-vertices of network proactively by identifying a Connected Dominating Set (CDS) using Dai's approach [16] with 2-hop neighboring information. By selecting the dominatee and best available dominator node, the number of sensors moved in the restoration is further reduced. Considering the impact of topology change on network performance, Least-Disruptive Topology Repair (LeDiR) algorithm was recently reported in [17], unlike other methods, LeDiR selecting a candidate node for restoration based on the partial view of network topology via a routing table. Recently, a localized hybrid timer based cut-vertex node failure recovery approach was proposed in [18] to ensure the timely restoration of MSN by allowing multiple failure handlers; cascaded movement is also adopted to relocate the associated sensors. In [19], with 1-hop neighboring information, the distributed partitioning Detection and Connectivity Restoration (DCR) was designed to identify the criticality of sensors and select the backup node based on the principle of “Guardian nomination.” The movements of sensors also follow the cascaded movement.
2.3. Potential Force Based Movement
Recently, potential force based methods [20–25] are widely exploited and proved to be very effective methods to redeploy mobile sensors and robots for achieving primary goals, for example, global connectivity, coverage, or fault-tolerance. The potential forces based methods are very attractive because of their effectiveness in creating a reactive behavior that provably avoids collisions with neighboring agents during reconfiguration. In [20], Zavlanos and Pappas proposed a hybrid control system that consists of a market based control strategy and a potential force based motion controller. The control system utilized potential force to achieve the main objective of maintaining global connectivity. The connectivity control system can reduce redundant communication links while preserving connectivity based on local estimation of spanning subgraph. Such problem is also addressed by a centralized potential force based controller in [21]. In [22], Mi et al. proposed a self-organization technique known as Distributed Link Removal Algorithm (DLRA) that aims to maintain connectivity in mobile sensor networks while reducing the redundant links, limiting the sensor nodes actuation and avoiding collisions. The redeployment of the mobile sensors is also by potential force based functions. However, the main drawback for these strategies is the well-known local minima problem [26]: interacting with the primary task of the mobile sensors (e.g., moving to a destination, creating a formation), potential forces can create undesired asymptotically stable configurations that prevent the sensors from reaching the desired configuration.
Another solution to navigate the mobile sensors is to use a distributed potential function based motion controller. A k-hop neighboring information based connectivity restoration framework, named HERO, was presented in [8], and the proposed method includes a potential function to drive the backup sensor to its destination while avoiding intersensor collisions. Due to the nature of the potential based controller, a relatively large number of sensors are employed in the connectivity restoration. The major problem of the contemporary schemes is the participation of multiple sensors in restoration process, which may not be possible in certain missions. This paper presents a novel solution to restore connectivity by moving only one backup sensor.
3. Preliminaries and Problem Formulation
3.1. System Models
For an initially connected sensor network with M actuated mobile sensors, encode the intersensor network in terms of an undirected graph
Definition 1 (connectivity).
An undirected graph
Definition 2 (1-hop neighbors).
Define j as the 1-hop neighbor of i; that is,
Definition 3 (2-hop neighbors).
Define k as the 2-hop neighbor of i; that is,
3.2. Algebraic Definitions of Connectivity
Denote

We further define the adjacency matrix

The powers of the adjacency matrix of a graph are closely related to network connectivity, which can be captured with the Laplacian matrix

Furthermore, let
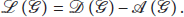
It is widely acknowledged that
Theorem 4 (see [27]).
Let
The second smallest eigenvalue
3.3. Main Objective
Based on the aforementioned background, the main objectives of this work can be described as follows.
Assume that the network has a nonuniform deployment topology with randomly deployed sensors, and each sensor knows its own location and periodically exchanges status information with its 1-hop neighbors and gathering information of 1- and 2-hop neighbors.
Main Objectives. The main objectives are as follows: (1) locally determining the critical sensors of the network based on 2-hop neighboring information, (2) selecting the best available backup sensor for each critical sensor so that (3) upon the failure of the critical sensor the connectivity of the network by relocating ONLY the backup sensor was restored, and further partitions of the network can be avoided.
4. Restoring Connectivity with Backup Sensor
The principle of our design is to proactively assign noncritical backup sensors to the critical sensors. Compared to the reactive methods, proactive selection of backups is beneficial for the timely execution of the restoration process, because the backup sensor can start the restoration immediately after the failure of a critical sensor. In this section, a critical sensor determination and substitution (CSDS) algorithm is proposed to determine the criticality of the sensors and select the best available backups with the aid of only 1- and 2-hop local neighboring information.
4.1. Critical Sensor Determination
Cut-vertices in a graph can be accurately determined in a centralized manner if the network-wide information is provided. However, it is not possible to accurately determine the cut-vertices with only local information. However, we manage to determine the noncritical sensor with confidence and mark others as critical; that is, if a sensor is marked as noncritical, it is not definitely a cut-vertex, whereas if a sensor is marked as critical, it may still be a global non-cut-vertex in
Step 1 (initialization).
Sensors collect neighbor's information by periodically exchanging heartbeat messages with their 1-hop neighbors. The heartbeat message must contain sensor's ID, geographic position, and one-hop neighbor set
Step 2 (determination).
Based on
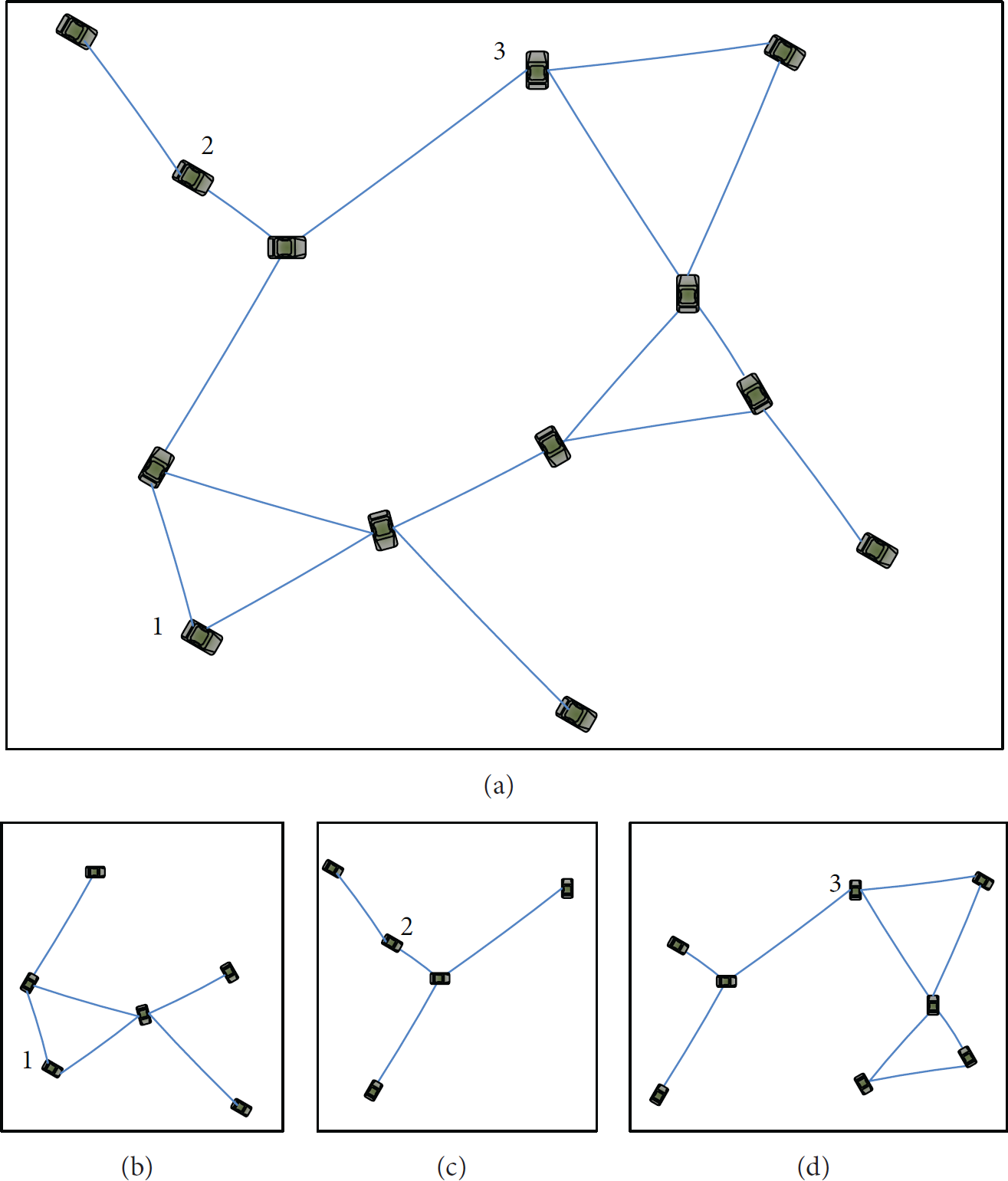
Example of the initial graph in (a), spanning subgraph in (b), spanning subgraph in (c), and spanning subgraph in (d).
Step 3 (notification).
If a sensor i determines itself as a critical sensor, it will inform all of its one-hop neighbors; that is,
Step 1. Receiving heartbeat messages from one-hop neighbor and collecting 2-hop neighbor information. Constructing Step 2. (1) (2) (3) SpanningGraph( (4) Return (5) (6) EigenValue( (7) (8) Critical(i) = false (9) (10) (11) Step 3. (12) (13) (14) Send CriSen(i) to every (15) (16) (17) (18) Send (19)

Sequence diagram of the critical sensor determination algorithm.
4.2. Backup Sensor Selection and Connectivity Restoration
Backup selection of best available sensors is based on the criticality, hop-count, and Euclidean distances of their neighbors. The following criteria should be met when a critical sensor chooses its backup.
Case 1.
If a critical sensor i receives more than one
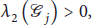
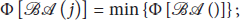
A very interesting yet crucial fact is that a noncritical node may become critical upon the failure of other nodes, and any movement of it may cause further partition of the network. This can be seen from Figure 3. As shown in Figure 3(a), upon the failure of the critical sensor 1, sensor 2 turns out to be a critical sensor while it was initially noncritical, and the movement of sensor 2 may cause further disconnection between sensor 3 and sensor 4. However, as shown in Figure 3(b), relocating sensor 2 to the exact position of the failed sensor 1 will not affect the global connectivity. The explanation of these interesting phenomena is straightforward: by substituting a failed critical node with a noncritical node, the final topology of the graph can be viewed as the initial topology without the noncritical node, that is, the failure of the noncritical node. Thus the global connectivity is maintained. The aforementioned fact is of great importance and entitles us to use just one sensor to restore the connectivity rather than use cascaded and potential based movements of a group of sensors.

An example of an initially noncritical sensor 2 becomes a critical vertex when sensor 1 fails, (a) the initial topology, and (b) the updated topology after sensor 2 restored the connectivity.
Case 2.
If a critical sensor i receives none
Case 3.
In case a critical sensor i does not receive any
(1) (2) (3) (4) Backup(i) = j, inform j (5) (6) (7) TTL = TTL + 1 # (8) (9) waiting for (10) (11) (12) Subgraph( (13) (14) Send (15) (16) (17) go to (2) (18) (19)
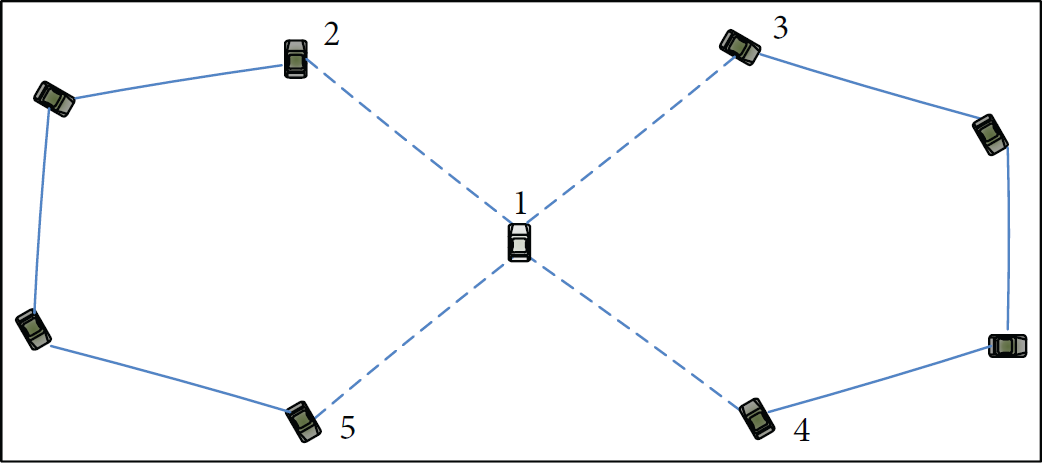
An example of a topology contains only critical sensors.

Sequence diagram of the backup sensor selection algorithm.
The designated backup sensor is responsible for monitoring the status of its parental critical sensor. If it is a 1-hop neighbor of the critical sensor, the failure of the critical sensor can be easily detected from the missing of heartbeat messages. Otherwise, if the backup sensor is 2 hops away from the critical sensor, the critical sensor should unicast the heart-beat message to it. If any of the heartbeat messages misses for more than a tolerant time period, the restoration process will be initiated.
Since cascaded movement is not required in CSDS, a simple node relocation method will be sufficient to drive the backup sensor to the position of the failed critical sensor in order to restore the connectivity. A straightforward solution is to utilize a target potential force

4.3. Algorithm Analysis
To verify the correctness and efficiency of CSDS, we introduce the following theorems.
Theorem 5.
In the worst case, the total movement distance (TMD) in CSDS is
Proof.
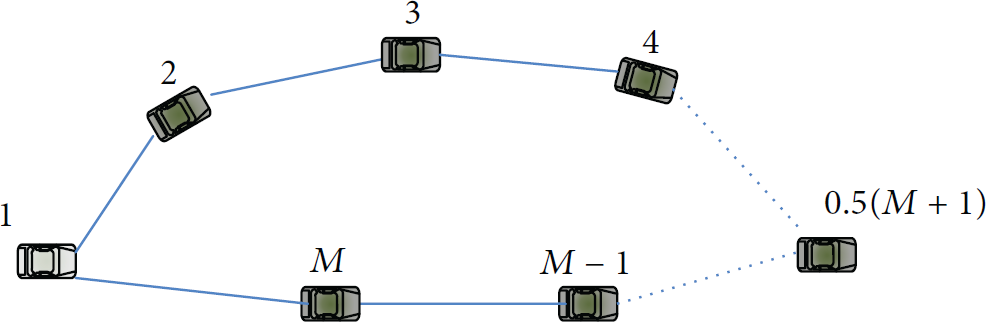
The worst case topology for TMD is a line topology as in Figure 6, and the distances between each pair of neighbors are equal R. The failed sensor must be right in the center of the line; otherwise, a closer backup (either sensor 1 or sensor M) will be located first, and its TMD is smaller than the TMD in the worst case. Therefore, (1) if M is even, then the worst case TMD occurs when the failed sensor ID is
The worst case topology in terms of TMD.
CSDS outperforms some of the well-known methods in terms of TMD, as shown in Table 1. In addition, with cascaded movement, the maximum number of sensors moved in the worst case amounts to nearly all of the sensors in the entire network. CSDS, on the other hand, ensures that only one sensor moved regardless of the network topology.
Comparisons of different methods.
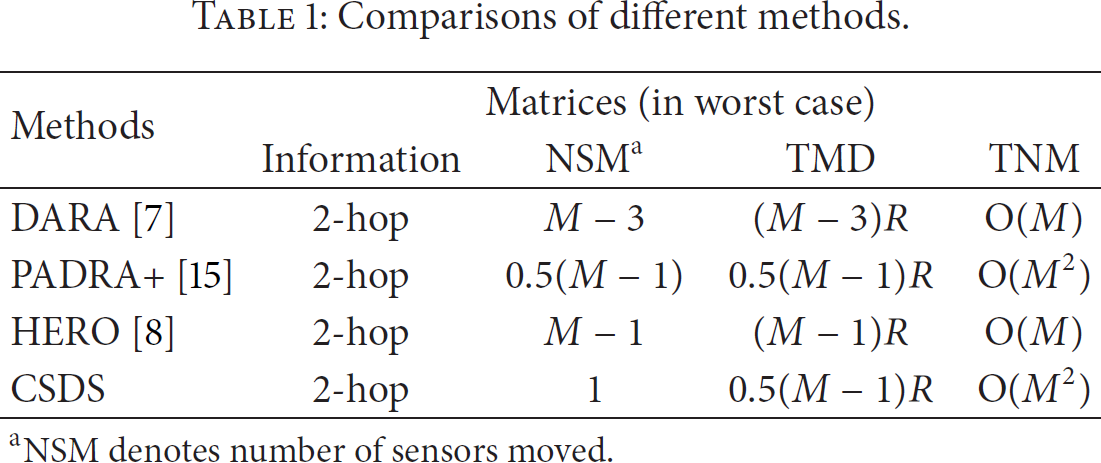
aNSM denotes number of sensors moved.
Another important metric that is measured in partition elimination is the message complexity of the algorithm, which indicates its scalability in large-scale networks. The message complexity is often measured by the total number of messages (TNM) in each execution loop of the algorithm. For CSDS, we have the following theorem.
Theorem 6.
The message complexity of CSDS is
Proof.
The message complexity refers to the maximum quantity of generated messages of all sensors in the worst case with respect to number of mobile nodes. First, since CSDS requires 2-hop neighboring information in critical sensor determination, there are a total of
The worst case topology in terms of TNM.
In fact, CSDC may need to locate a remote sensor as its backup due to its requirement of only one sensor to be moved for the partition elimination. Then, a relatively higher message complexity is inevitable, as can be seen from Table 1. However, the worst case topology is extremely unlikely in a typical uniform randomly distributed MSN, and the critical sensors are expected to locate a backup within a few hops. This phenomenon can be clearly observed in experimental simulation, which will be discussed in the next section.
5. Experimental Simulations
5.1. Simulation Scenarios and Performance Metrics
In the simulation scenarios, an initially connected MSN is randomly distributed into 1000 m × 1000 m area of interests. During the simulation, a random possible cut-vertex fails at a given time point. Each simulation is run for 50 different network topologies and the results were based on the average performances. We choose the NSM, TNM, and TMD as the performance matrices to evaluate the overall efficiency of CSDS against other popular methods. We adopt DARA, HERO, and PADRA+ as the baseline approaches to compare with the proposed CSDS, due to their similarity of using two-hop neighboring information in the restoration process.
5.2. Results and Discussions
Before presenting the performance evaluation of CSDS, a simulation study is conducted to show the possibility of 1-hop and 2-hop backups; that is, among the critical sensors in a randomly distributed network, how many of them have a backup from their 1-hop or 2-hop neighboring sets. The results shown in Figure 8 indicate that CSDS guarantees a high possibility that the critical sensor can locate a backup within 2 hops, which is important since it can effectively reduce the message cost by avoiding searching through the networks. Meanwhile, when the network becomes denser, the number of critical sensors is rapidly decreased; thus, there is an even higher possibility to locate a 1-hop backup sensor.
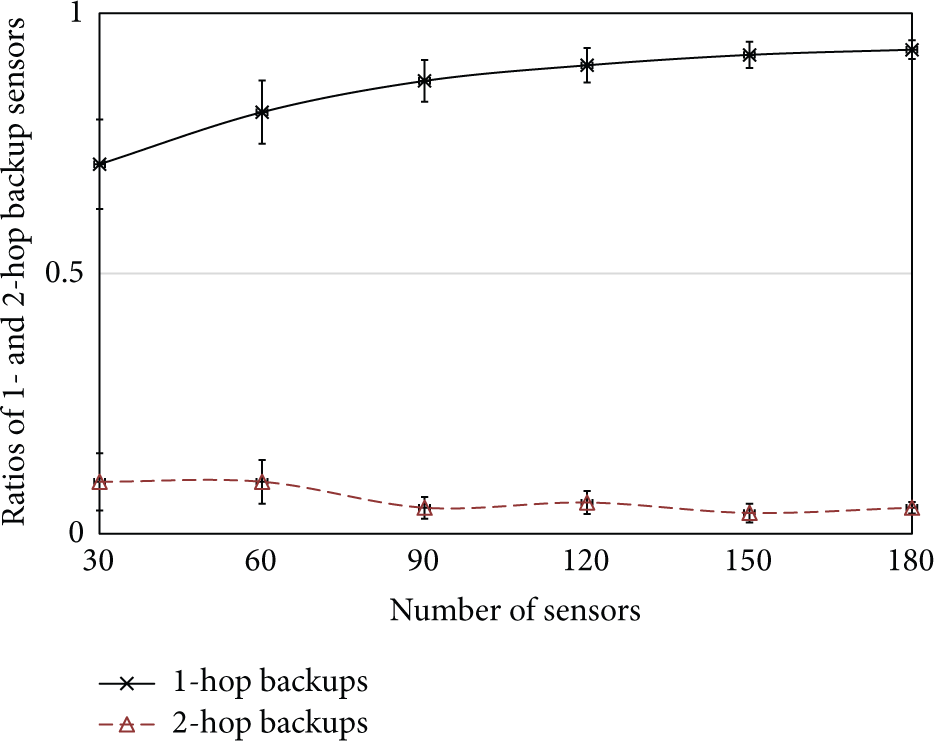
Ratios of 1- and 2-hop backup sensors with increased density.
The results of NSM are shown in Figure 9(a). Only 1 sensor is involved in a restoration process for CSDS. Meanwhile, the NSM for PADRA+ is around 2.5, due to its computing of CDS and the cascaded movement scheme. The NSM for DARA is around 4, and an even higher NSM can be observed for HERO due to its attractive potential function that causes smaller movements of a relatively large number of sensors. The NSM for HERO becomes at most 7 with the increased density of the network.

Comparative studies. (a) Number of sensors moved with increased density, (b) total number of messages with increased density, and (c) total movement distances with increased density.
Furthermore, the TMN of CSDS is shown in Figure 9(b). Since the message complexity for CSDS is
As an important factor to evaluate the efficiency of the partition elimination, the results of TMD are shown in Figure 9(c). Comparing with cascaded and potential function based movement pattern, direct relocation of only 1 sensor can effectively reduce the TMD regardless of the topology and density of the networks. As is validated in the simulation study, the TMD of CSDS is smaller than that of the HERO, PADRA+, and DARA and is further reduced as the density of the network is increased. The TMD of CSDS can be as small as nearly 50 meters when the number of sensors reaches 180, which validates that the backups are almost always selected from the 1-hop neighbor sets.
6. Conclusions
To minimize the impacts on the network structure and sensor's current tasks, a partition elimination strategy CSDS, which moves only one sensor during a restoration process, is presented in this work. CSDS is fully distributed and requires only local information of 2-hop neighbors. Consisted of a graph-theoretic based critical sensor determination algorithm and an effective backup sensor selection algorithm, CSDS can restore the disconnections of the network caused by the failure of a cut-vertex immediately. Experimental simulation studies verify that, with a slightly higher message cost, CSDS can improve the efficiency of connectivity restoration in terms of total movement distance and maintain the layout of the sensor system by moving only one mobile sensor.
Future work will consider the network optimization prior to the disconnection of network or during the connectivity restoration process by implementing clustering algorithms and dual descent approach [30]. More realistic system and environment models will also be considered so that the connectivity restoration methods can be more suitable in the real-world applications.
Footnotes
Conflict of Interests
The authors declare no conflict of interests.
Acknowledgments
This work was supported by the National Science Foundation of China (Grants nos. 61272432, 61370092, and 61472033), Hubei Provincial Department of Education Outstanding Youth Scientific Innovation Team Support Foundation (T201410), and Fundamental Research Funds for the Central Universities (TW201502).