
Abstract
A multimodel based range query processing algorithm is proposed to solve the information collection task for the CPSs, which utilizes multiple probability models to depict the data distribution of a sensor node. The execution of the multimodel based algorithm consists of two phases, which are the preprocessing phase and the query processing phase. During the preprocessing phase, multiple models are constructed for each node according to their historical data. During the query processing phase, a suitable model is selected from the multiple models with the help of a sampling based algorithm, which is used to process the query. As the multimodel based algorithm needs to sample data from the network, it can waste energy more than that of the single model based algorithm in some cases, which does not sample data from the network. The cost of the multimodel based and single model based algorithm is analyzed. A cost model based algorithm is proposed to select a better algorithm to process a query from the two algorithms. Experimental results show that the cost model based algorithm can save 13.3% energy consumption more than that of the single model based algorithm.
1. Introduction
Cyber-physical systems (CPSs), which consist of computing devices and embedded systems such as distributed sensors and actuators, integrate computation, communication, and control with the physical world [1]. The tasks, running on the CPSs, involve close interactions between the cyber world and the physical world. Extracting knowledge from the physical world is an important task for the CPSs. Some useful information is collected from the physical world firstly and then analyzed to extract knowledge. Wireless sensor networks (WSNs) [2–5] are usually used to fulfill the information collection task, which is transformed into some kinds of queries for the WSNs [6–10].
The range query is one of the most important types of queries to collect information from the WSNs. For instance, a range query is sent to the sensor network distributed in a forest, asking for the places where the temperature lies in
Some existing methods have been proposed to solve the range query in the WSN, which can be classified into two classes. The first class is the data centric storage based algorithms, such as GHT [11], DIM [12], comb-needle [13], double ruling [14], and energy-aware algorithm [15]. The data centric storage algorithms define different types of events for the data collected by sensors. Each type of events is stored in a particular node called event storage node in the WSN. When a node detects an event, it transmits the data of the event to the event storage node. A range query, transformed to a query for an event, is sent directly to the event storage node and answered by the node. The event defined in the data centric storage algorithm is very rigid, which means the users can only ask for the result of a range defined by the event. So these algorithms do not fit for the query asking for the result of any range.
The second class is the local storage based algorithms, such as [16–19]. For the traditional local storage based algorithms [16, 17], the data collected by a sensor is stored in its local storage. The queries are sent to each node and the nodes satisfying the query return their results to the user. The problem of the traditional algorithm is that all nodes need to return their results to the sink whether they satisfy the query or not, which consumes a lot of energy. In [19], a probability model is used to process the range query. The probability model is used to estimate the probability that each node satisfies the query. Only if the probability of a node, satisfying the query, is above a threshold, the node is considered as a result. With the help of the probability model, nodes do not return any result to the sink for a range query. There are two problems for the algorithm. The first one is the algorithm can only give an approximate answer to a query. The second one is it is hard to determine a threshold balancing the efficiency of energy consumption and the accuracy of the query result.
In this paper, we propose a multimodel based algorithm to solve the range query in the WSN, which is a local storage based algorithm. Compared with the other local storage based algorithms, our algorithm has the following advantages. First, our algorithm constructs multiple probability models. With the help of these probability models, only the most relevant nodes among all nodes need to transmit their results to the sink, which saves more energy than the traditional local storage algorithms. Second, our algorithm can give the precise answer to the range query with minimum energy consumption. The multimodel based range query processing algorithm proposed in this paper is composed of 3 steps:
probability model construction; sampling based model selection; model based query processing.
The probability model construction algorithm first constructs multiple probability models for each node in the WSN. By clustering the historical data collected by the nodes, m subclasses are constructed and each node builds a probability model according to the data of its own in a subclass. With the help of the multiple probability models, the query processing algorithm can select the more accurate model to describe the data distribution for the current condition than that of the single model based algorithm.
Multiple probability models have been constructed for each node in the WSN. For a particular range query, there must be a method to select a suitable probability model for each node to process the query. In this paper, a sampling based algorithm is proposed to fulfill this task. Some typical nodes are selected by a preprocessing algorithm. Then the sampling based algorithm collects the data from these typical nodes to determine a suitable model for a query.
Combining the model selected by the sampling based model selection algorithm with the real data sensed by a node, the model based query processing algorithm can minimize the energy consumption of processing a range query. While the performance of the multimodel based algorithm is not the best in all cases, we analyze the cost of the multimodel based algorithm and propose a range query processing algorithm augmented with the cost model, which selects a suitable query processing algorithm for a range query according to the cost model. Experimental results show that the cost model based algorithm can provide the accurate answer with 13.3% energy consumption less than that of the single model based algorithm.
The contributions of this paper are as follows. First, a multimodel based algorithm is proposed to solve the range query in the WSN, which utilizes multiple probability models to improve the accuracy of the data distribution function and saves the energy consumption of the algorithm. Second, the energy consumption of the multimodel based algorithm is analyzed and a query processing algorithm augmented with the cost model is proposed to save energy in most cases. Third, extensive experiments were done to verify the efficiency of the proposed algorithms.
The rest of the paper is organized as follows. Section 2 introduces the multimodel based range query processing algorithm. Section 3 analyzes the cost model of the multimodel based algorithm and proposes the query processing algorithm augmented with the cost model. Section 4 evaluates the performance of the proposed algorithms on real dataset. Section 5 briefly discusses the related work and in Section 6 we draw the conclusion.
2. The Model Based Range Query Processing Algorithm
2.1. Probability Model Construction
First, multiple probability models are constructed for each node in the WSN based on the historical data collected from each node. Let N be the set of all nodes in the WSN and let
The data collected by a node is a random variable, which can be described by a probability distribution function (PDF). The PDF of a random variable is usually hard to calculate, but it can be estimated by a histogram. A histogram is a representation of tabulated frequencies, erected over discrete intervals (bins), with an area equal to the frequency of the observations in the interval. The total area of the histogram is equal to the amount of data.
The vectors belonging to the ith subclass
In the same way, a probability model can be constructed for each node based on the vectors in each subclass. If the historical data set H is divided into m subclasses, m probability models are constructed for each node. The ith probability model of a node
Given a range

2.2. The Typical Node Selection Algorithm
Multiple probability models have been constructed for each node in the WSN. For a particular range query, there must be a method to select a probability model for each node to process the query. In this paper, a sampling based method is proposed to fulfill this task.
Firstly, some typical nodes are selected from the WSN. Before sending a range query to the WSN, the sink samples data from the typical nodes. Based on the data sampled from the typical nodes, a suitable probability model
Let

Definition 1 (data range).
The data range of a node
The range
Theorem 2.
The x and y of a data range are integers.
Proof.
As there are m subclasses, the node
Definition 3 (candidate node).
If an intersection
For example, in Figure 1, there are two nodes

Illustration to data range and candidate node.
In Figure 1(a), the intersection
In Figure 1(b),
The typical node selection algorithm needs to prepare some parameters with the help of a preprocessing algorithm. The preprocessing algorithm first calculates the m data ranges
(1) (2) calculate the m Data Ranges (3) (4) (5) calculate all the intersections (6) (7) (8) find the node (9) put (10) (11) construct the MCN by selecting the unique nodes from all (12) (13) (14) (15) (16)
For example, Figure 2 shows that there are two nodes
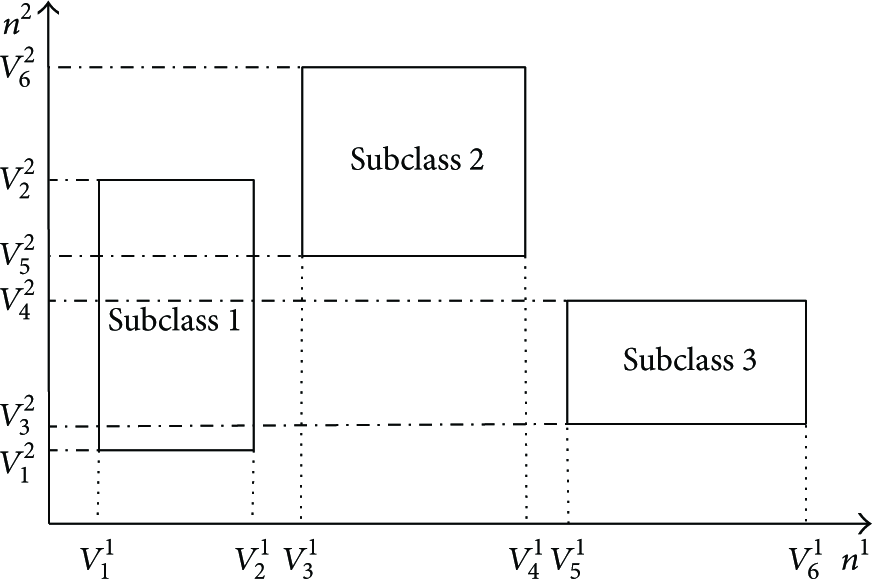
Illustration to the preprocessing algorithm.
Based on the definitions and the
(1) (2) sort the nodes in the MCN according to their counters in descending order (3) select the node with maximum counter from MCN (4) add the selected node (5) set (6) remove the selected node from MCN (7) remove all the pairs in the list of the selected node from I (8) remove all the pairs in the list of the selected node from the list of the other candidate nodes (9) subtract the counter of a candidate node in MCN by 1 when a pair is removed from the node's list (10) (11)
For example, after sorting,
2.3. Sampling Based Model Selection and Model Based Query Processing Algorithms
The model based query processing algorithm for a range query works as follows. A node
To save energy, the model selection algorithm does not sample data from all typical nodes at the same time. We sort the nodes in T according to their counters in descending order. The model selection algorithm samples data from one node in the typical node set at a time from the beginning. Only when the sampled data cannot determine a model, the data of the next typical node is sampled. Initially, the candidate model set, represented as
(1) set the candidate model set CM to (2) sort the nodes in T according to their counters in descending order (3) (4) sample data (5) (6) (7) remove i from CM (8) (9) (10) (11) break (12) (13) (14) (15) (16) (17) construct the vector (18) construct a partial center vector (19) set the (20) (21) (22) (23) (24) (25) (26) (27) (28)
After the sink selects a suitable probability model for a range query, it sends the index of the model together with the range query to all the nodes in the WSN. When a node
We calculate two probabilities that the data of the node satisfies the range query and use the larger one as the final probability, because the model constructed by a subclass of data of a node is not more accurate than the general model. For example, the multimodel based range query processing algorithm uses two models and a general model to depict the temperature of a room. One model depicts the distribution of the temperature from 7:00 A.M. to 9:00 A.M. and another model depicts the distribution of temperature from 9:00 A.M. to 11:00 A.M. The general model depicts the distribution of the temperature from 7:00 A.M. to 11:00 A.M. If the query range is from 8:00 A.M. to 10:00 A.M., neither of the two models can depict the distribution of the temperature more accurately than the general model. By comparing the probabilities calculated by the selected model and the general model, we guarantee that the final probability is not worse than that of the general model.
When
(1) (2) (3) (4) (5) (6) put (7) (8) (9) broadcast the query and the (10) collect answers from the nodes in the network (11) (12) put ID of node (13) (14) remove the ID of node (15) (16)
(1) extract the (2) (3) (4) (5) send a negative answer containing the ID of the current node to the sink (6) (7) send a positive answer containing the ID of the current node to the sink (8)
3. Cost Analysis of the Multimodel Based Range Query Processing Algorithm
The multimodel based query processing algorithm is not always efficient for all range queries, because it must sample data from the typical nodes first and then collects the results from these nodes. While the single model based algorithm directly collects data from the nodes, the multimodel based algorithm may consume more energy than that of the single model based algorithm. We construct the cost model to estimate the energy consumed by the multimodel based algorithm and the single model based algorithm. By comparing the cost consumed by the two algorithms, we can select a better one to process a query. In this paper, we use the number of messages transmitted by an algorithm to represent the energy consumption.
3.1. Cost Analysis of the Single Model Based Algorithm
Before analyzing the cost of the multimodel based algorithm, we present a single model based algorithm. In the single model based algorithm, a node
The energy cost for the single model based query processing algorithm
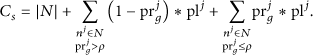
3.2. Cost Analysis of the Multimodel Based Algorithm
We analyze the cost consumed by the multimodel based algorithm. The cost of the multimodel based algorithm is composed of two parts. The first part is the energy cost by the sampling phase, represented by

If there are m models in the multimodel based range query processing algorithm, there are altogether
The probability that a model is determined by the jth typical node is

Let

The first part of formula (6) is the number of messages by which the sink broadcasts the range query throughout the network. The second part of formula (6) is the expectation of the energy cost by which the sink receives answers from the nodes in the WSN. As the sink has received the data from the typical nodes at the sampling phase, the typical nodes do not transmit their data to sink at the query processing phase and
As each model is constructed by the vectors contained by a subclass, the number of vectors belonging to a subclass can be used to estimate the probability that the corresponding model is chosen. The larger the number of vectors contained by a subclass is, the higher the probability, that data sampled from the typical nodes belongs to the data range of the subclass, is. Let

Let

The energy cost of the multimodel based query processing algorithm

3.3. Range Query Processing Algorithm Augmented with the Cost Model
The query processing algorithm augmented with the cost model, given in Algorithm 6, works as follows. The sink estimates the costs
(1) estimate the cost (2) estimate the cost (3) (4) (5) (6) (7)
4. Performance Evaluation
In this section, four experiments were done to verify the performance of the algorithms proposed in this paper. There are three factors that influence the performance of the multimodel based range query processing algorithm, which are the probability threshold ρ, the number of models m, and the coverage threshold σ. In the first three experiments, we test the influence of these factors on the multimodel based algorithm. In the last experiment, we compare the performance of the single model based algorithm, the multimodel based algorithm, and the query processing algorithm augmented with the cost model. The performance of the algorithms is measured by the energy consumption of these algorithms, which is the number of messages transmitted. We adopt the data set collected from 34 sensors deployed in the Intel Berkeley Research lab [20] in our experiments. There are 54 sensors in the data set. As a lot of data of some sensors is lost in the data set and our algorithm needs plenty of historical data to construct probability model, we only select 34 sensors from them. We randomly assign an integer number to each node as its number of hops to the sink, which is used to calculate the energy consumption of each of query processing algorithms.
4.1. Evaluation of the Probability Threshold
In this subsection we evaluate the influence of the probability threshold ρ on the performance of the single model based algorithm (SMA) and the multimodel based range query processing algorithms (MMAs). In this experiment, we change the probability threshold ρ of the algorithms from 0.5 to 0.8. The number of models m and the coverage threshold σ of the MMA are fixed to 4 and 0.8. The sink sends queries with different ranges to the WSN. 10 queries are generated for each range. Figure 3 shows the energy consumption of the SMA and MMA corresponding to different ρ, respectively. The x-axis is the query range sent by a user and y-axis is the number of messages transmitted by the query processing algorithm, which is the average of the number of the messages to process the ten queries for each range.

Influence of ρ on the different algorithms.
The experimental results in Figure 3(a) show that, with the increasing of the ρ, the cost of the SMA increases. The SMA with
4.2. Evaluation of the Number of Models
In this subsection we evaluate the influence of the number of models m on the performance of the MMA. In this experiment, we set the number of models m of the MMA to 4, 6, and 8. The probability threshold ρ and the coverage threshold σ of the MMA are fixed to 0.6 and 0.8. The sink sends queries with different ranges to the WSN. 10 queries are generated for each range. Figure 4 shows the energy consumption of the MMAs corresponding to different m. The x-axis is the query range sent by a user and y-axis is the number of messages transmitted by the MMA, which is the average of the number of the messages to process the ten queries for each range.

Influence of m on MMA.
The experimental results show that the algorithm with
4.3. Evaluation of the Coverage Threshold
In this subsection we evaluate the influence of the coverage threshold σ on the performance of the MMA. In this experiment, we set the coverage threshold σ of the MMA to 0.8, 0.7, and 0.6, respectively. The probability threshold ρ and the number of models m of the MMA are fixed to 6 and 0.6. The sink sends queries with different ranges to the WSN. 10 queries are generated for each range. Figure 5 shows the energy costs of the MMA corresponding to different σ. The meaning of the x-axis and the y-axis is the same as the first two experiments.

Influence of σ on MMA.
The experimental results show that the energy consumption of the algorithm with
4.4. Comparisons of Energy Consumption
In this subsection we evaluate the performance of the query processing algorithm augmented with the cost model, represented as CMA. In this experiment, we first evaluate which algorithm the CMA selects for different query ranges. Figure 6 shows the results. When the query range is 2, CMA selects the SMA to process the query with

Per. of algorithm selected by CMA.
In the second experiment, we compare the energy consumption among the three kinds of algorithms. The parameter for the SMA is

Comparison among SMA, MMA, and CMA.
The experimental results show that, when the query range is 2, the MMA1 consumes more energy than SMA. The CMA1 selects SMA as the algorithm to process the query, while the MMA2 consumes less energy than SMA when query range is 2. The CMA2 also selects SMA as the algorithm to process the query, which wastes the energy. For other kinds of query range, the energy cost of the CMA is less than that of the corresponding MMA. Compared with the SMA, the MMA1 can save about
5. Related Work
The DIM [12] divides the whole network into a lot of zones and embeds a k-d tree-like index in the network. There is only one node in each zone, which acts as the index node of the zone. With the k-d tree-like index, events with comparable attribute values are stored nearby and the DIM can fulfill the range query easily. In the comb-needle algorithm [13], when a sensor detects an event, it distributes the data of the events to the nodes in the vertical direction within h hops around it. If a query is sent to the sensor network along multiple lines in the horizontal direction and the distance between any two neighboring lines is smaller than h hops, the query will be transmitted to the event storage node and get the results. The double ruling algorithm [14] distributes the data of the events around the network in a circle. The query also traverses the network in a circle. The double ruling algorithm guarantees that the circle of the query can intersect with all circles of the queried events. The work in [21] constructs a single dimensional address space of sensor nodes through a zigzag traversing such that geographically near nodes are located near in the linear address space. The multidimensional query is transformed into a single dimensional data space using Hilbert space-filling curves. The work in [22] builds a distributed k-d tree based index structure over sensor network and proposes a dynamic programming based methodology to control the granularity of the index tree in an optimized approach. The work in [23] proposes a bloom filter based algorithm to reduce the number of messages transmitted during the procedure of query processing. The work in [24] proposes the bloom filter based approximate algorithms, which can save the energy even further. The work in [25, 26] considers the security problem of the range query. The work in [25] presents a novel spatiotemporal cross-check approach to ensure secure range queries in event-driven two-tier sensor networks. The work in [26] employs the order-preserving symmetric encryption and a novel data structure called authenticity and integrity tree to preserve authenticity and integrity of query results.
6. Conclusions
In this paper, a multimodel based query processing algorithm is proposed to solve the range query problem. The cost model of the multimodel based query processing algorithm is analyzed and a range query processing algorithm augmented with cost model is proposed to save energy even further. The experimental results show that the cost model based algorithm can save
Footnotes
Notations
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported by a grant from the National Natural Science Foundation of China (nos. 61100032, 61202142), Joint Funds of the Ministry of Education of China and China Mobile (no. MCM20122081), the National Key Technology R&D Program Foundation of China (no. 2013BAH44F00), and the Fundamental Research Funds for the Central Universities (nos. 2010121070, 2010121072, and 2013121030).