
Abstract
In this paper, an adaptive speech streaming method is proposed to improve the perceived speech quality (PSQ) of voice over wireless multimedia sensor network (WMSNs). First of all, the proposed method estimates the PSQ of the received speech data under different network conditions that are represented by the packet loss rates (PLRs). Simultaneously, the proposed method classifies the speech signal as either an onset or a nononset frame. Based on the estimated PSQ and the speech class, it determines an appropriate bit rate for the redundant speech data (RSD) that are transmitted with the primary speech data (PSD) to help reconstruct the speech signals of any lost frames. In particular, when the estimated PLR is high, the bit rate of the RSD should be increased by decreasing that of the PSD. Thus, the bandwidth of the PSD is changed from wideband to narrowband, and an artificial bandwidth extension technique is applied to the decoded narrowband speech. It is shown from the simulation that the proposed method significantly improves the decoded speech quality under packet loss conditions in a WMSN, compared to a decoder-based packet loss concealment method and a conventional redundant speech transmission method.
1. Introduction
Because of the rapid development of low power and highly integrated digital electronic technologies, wireless multimedia sensor networks (WMSNs) are capable of retrieving audio and/or video streams as they interconnect sensor nodes equipped with multimedia devices such as cameras and microphones. Accordingly, they provide a wide range of potential applications needed to access audio or video data in real time such as environmental monitoring, human tracking, and security systems [1, 2]. However, it is difficult to guarantee seamless audio or video quality because those multimedia data are usually generated at a much higher bit rate than other sensor data. Furthermore, the reliability of transmission over WMSNs is apt to be degraded due to various resource constraints in WMSNs, compared to other networks [3, 4]. Thus, the quality of service (QoS) of multimedia streaming over WMSNs has become even more important. Specifically, applications of voice over WMSN (VoWMSN) require a minimum level of perceived speech quality (PSQ) [5–7].
To improve the PSQ of voice applications, various speech streaming methods have been proposed for use on IP networks. These methods are typically classified into either sender-based schemes or receiver-based schemes. Sender-based schemes consist of a collection of packet loss protection methods that provide error-robust transmission methods such as interleaving, forward error correction (FEC), and redundant speech transmission (RST) [8–12]. On the other hand, receiver-based schemes consist of a collection of packet loss concealment (PLC) methods that compensate for lost speech signals using substitutable signals, for example, silence, previous good speech, or regenerated speech according to the analysis-by-synthesis criterion [13–16]. However, these two schemes can complement each other. That is, sender-based schemes are robust to higher packet loss rates (PLRs) because they often use redundant information to recover lost signals, which results in increased transmission bandwidth. Receiver-based schemes do not need to increase the transmission bandwidth because they conceal lost signals without using redundant information from the sender side; however, it is hard to prevent rapid PSQ degradation under high PLRs. It was also reported in [5] that in VoWMSN applications the receiver-based scheme could accommodate higher bit rates of speech coding under low PLR conditions, whereas the sender-based scheme was suitable for dealing with lower bit rates under high PLR conditions.
To take advantage of both schemes, a new method has been proposed in [17], which transmitted redundant speech data (RSD) adaptively according to the estimated PSQ under the current PLR condition and determined a suitable RST mode. On the basis of the mode, it generated bitstreams of primary speech data (PSD) and RSD using a scalable speech coder so as to maintain the equivalent transmission bandwidth. A lost speech signal was then recovered using the RSD for a high PLR. As a result, this method provided the improved overall PSQ under various PLRs within equivalent transmission bandwidth. Despite the advantages, this method suffered from degraded PSQ when the speech signal bandwidth changed from wideband to narrowband due to the decreased bit rate of PSD by assigning more bit rate to RSD. To overcome this problem, the proposed method in this paper incorporates an artificial bandwidth extension (ABE) technique [18] to the decoded narrowband speech to prevent the quality of the decoded speech from being degraded by the bandwidth deficiency of speech. In addition, a PSQ estimation method is proposed for the determination of an appropriate RST mode as well as the speech classification.
The remainder of this paper is organized as follows. Section 2 describes the overall procedure and packet flow of the VoWMSN, which employs the proposed adaptive speech streaming method. Then, Section 3 proposes an adaptive speech streaming method for VoWMSNs. Section 4 evaluates the performance of the proposed method and compares it with those of a decoder-based PLC method and a conventional RST method. Finally, Section 5 concludes this paper.
2. Voice over WMSN Based on Adaptive Speech Streaming
2.1. Overall Structure
Figure 1 shows a block diagram and packet flow for a VoWMSN system that employs the proposed adaptive speech streaming method. As the speech signal,

Block diagram and packet flow of a VoWMSN system employing the proposed adaptive speech streaming method.
Meanwhile, at the receiver side,
2.2. RTP Payload Format
As mentioned above, the proposed adaptive speech streaming method can use an indicator for scalable bit rate speech coding. To deliver the estimated PSQ from the receiver side to the sender side, there should be a reserved field to accommodate the transmission of both the estimated PSQ and the RSD bitstream. To this end, the RTP payload format defined in IETF RFC 4749 [19, 20], which is shown in Figure 2(a), is modified as shown in Figure 2(b).

Comparison of RTP payload formats: (a) the format defined in IETF RFC 4749 and (b) a modified format for the proposed method.
As shown in Figure 2(a), the “
On the other hand, in the modified RTP payload format, two fields (such as FT = 12 and FT = 13) are added for indicating the RSD bitstream and the estimated PSQ, respectively, as shown in Figure 2(b). Moreover, the main field for speech frames (as in Figure 2(a)) is split into three fields representing the PSD bitstream, the RSD bitstream, and the estimated PSQ, respectively.
3. Proposed Adaptive Speech Streaming Method
3.1. Speech Quality Estimation
The proposed adaptive speech streaming method begins by estimating the PSQ because the PSQ is a good indicator of both the current PLR and the bit rate of speech coding. To this end, the ITU-T Recommendation P.563 [22] is employed in this paper as an objective PSQ assessment method in order to monitor the PSQ of VoWMSN, and it estimates the PSQ as a mean opinion score (MOS) without using a reference speech signal. The proposed method requires that the PSQ estimate should be done in real time, thus the ITU-T Recommendation P.563 needs to be modified to have low-delay requirements, which is referred to as a nonintrusive perceived speech quality assessment (LD-QA) method in this paper.
Figure 3 shows an overall structure of the PSQ estimation method using three processing stages such as the preprocessing stage, the distortion estimation stage, and the perceptual mapping stage. To take into account various distortion factors during speech streaming, the model also combines three processing modules in the distortion estimation stage, which is based on the ITU-T Recommendation P.563. The first module models the vocal tract as a series of tubes with abnormal variations for degradation modeling and estimates the linear prediction coefficients (LPCs) within a certain range expected for a natural speech signal. The second module reconstructs a clean reference speech signal from the degraded speech signal and then evaluates the difference between the reconstructed clean speech and the degraded speech signal. The third module identifies and estimates specific distortions expected to be encountered in transmission channels.

Overall structure of the PSQ estimation method using three processing stages, where the distortion estimation stage is based on the ITU-T Recommendation P.563.
In the perceptual mapping stage, the distortion effects estimated in the distortion estimation stage are linearly combined to estimate an MOS, which is denoted by
On the other hand, the proposed LD-QA method modifies the second stage so that the distortion effects are modeled using a minimal amount of speech data. In particular, each pitch mark in the first module of the second stage is extracted once every frame, where the frame size is 64 ms long, and the second module is also applied once every frame. In addition, the distortion-specific parameters for noise detection, temporal time clipping, and robotization are updated once every frame using speech signals of 500 ms, 64 ms, and 1 s long, respectively. Consequently,
3.2. Artificial Bandwidth Extension
When the estimated PLR is high, the bit rate of the RSD should be increased by decreasing the bit rate of the PSD, which is realized by changing the bandwidth of the PSD from wideband to narrowband. In this case, an ABE technique is used to overcome the performance degradation of the seamless PSQ by extending the bandwidth of speech signals from narrowband to wideband to improve the speech quality of the narrowband speech.
Figure 4 shows a block diagram of the ABE technique operated in the modified discrete cosine transform (MDCT) domain [18]. In this figure, if the RST mode is 2, narrowband speech,

Block diagram of an artificial bandwidth extension technique applied to decoded narrowband speech.
3.3. RST Mode Decision and Bit Rate Assignment
In the proposed adaptive speech streaming method, the PSQ is estimated at the receiver side using the LD-QA method and then it is sent back to the sender side to make the RST mode decision. Figure 5 shows a block diagram of the RST mode decision based on the speech class and the estimated PSQ in the proposed method.

Block diagram of the RST mode decision based on the speech class and the estimated PSQ in the proposed adaptive speech streaming method.
First, each frame is classified into one of six different classes, namely, silence/background noise, stationary unvoiced, nonstationary unvoiced, speech onset, nonstationary voiced, or stationary voiced [23]. Next, a preliminary experiment is carried out to investigate the relationship between each class and the RST mode under different PLR conditions. Consequently, it is found that the RST mode is most sensitive to the speech onset class. Thus, the proposed adaptive speech streaming method decides only whether or not the nth frame is primarily made up of speech onset, such that

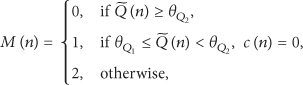
Figure 6 shows several bit rate assignments for the PSD and RSD bitstreams according to different RST modes,

Bit rate assignment according to different RST modes.
4. Performance Evaluation
To demonstrate the effectiveness of the proposed adaptive speech streaming method, a VoWMSN system was created using the ITU-T Recommendation G.729.1 as a scalable speech coder as shown in Figure 7. In fact, the proposed method and other speech streaming methods were implemented in the application layer. For the evaluation, input speech signals were sampled at 16 kHz and encoded using the ITU-T Recommendation G.729.1 speech encoder at a bit rate of 32 kbit/s. The bit rate assignment for the PSD and RSD bitstreams according to different RST modes was performed as shown in Table 1. In addition,
Bit rate assignment according to different RST modes, where


Structure of a VoWMSN system employing different speech streaming methods implemented in the application layer.
To compare the performance of the PSQ estimation within the equivalent transmission bandwidth, two conventional speech streaming methods were implemented: a decoder-based PLC method [21] and an RST method [10]. The decoder-based PLC method encoded speech signals using the ITU-T Recommendation G.729.1 encoder at 32 kbit/s with no RSD bitstream, and the conventional RST method also encoded speech signals using the ITU-T Recommendation G.729.1 encoder at a fixed bit rate of 16 kbit/s with an RSD bitstream of 16 kbit/s. In this experiment, 48 speech utterances were taken from the NTT-AT speech database [24], where each speech utterance was approximately 4 s long and was sampled at a rate of 16 kHz. Each utterance was filtered using a modified intermediate reference system (IRS) filter, followed by automatic level adjustment [25]. To evaluate the quality of the decoded speech for each method, scores of wideband perceptual evaluation of speech quality (WPESQ) were measured as defined by the ITU-T Recommendation P.862.2 [26]. For the simulation of WMSN conditions, the Gilbert-Elliot (GE) channel model [25] was used to simulate the packet loss conditions because it is able to characterize the fading of a wireless network [6, 27, 28]. In this paper, burst PLRs were generated from 0 to 25% at a step of 5% using the GE model. Note that the mean and maximum burst packet losses were measured at approximately 1.5 and 4 packets, respectively.
Figure 8 compares the WPESQ scores (in MOS) of decoded speech processed using different speech streaming methods under different PLR conditions. As shown in this figure, the WPESQ score of the proposed method was better than those of the conventional methods. In other words, the proposed method improved average WPESQ score by as much as 0.55 and 0.2 MOS, compared to the decoder-based PLC method and the RST method, respectively.

Comparison of WPESQ scores measured in MOS for three different speech streaming methods under burst PLR conditions ranging from 0 to 25%.
5. Conclusion
In this paper, an adaptive speech streaming method was proposed to improve speech quality of a voice over wireless multimedia sensor network (WMSN). To this end, the proposed method first classified each frame of input speech signals as either an onset frame or a nononset frame. Next, it estimated the perceived speech quality (PSQ) of the received speech data under packet loss conditions. On the basis of the estimated PSQ and the speech class, the proposed method determined an appropriate bit rate for the redundant speech data (RSD) that was transmitted with the primary speech data (PSD) to assist the speech decoder in reconstructing the speech signals for a lost frame. In particular, an artificial bandwidth extension technique was applied to the narrowband speech decoded when the estimated packet loss rate (PLR) was high. The effectiveness of the proposed method was demonstrated by implementing a voice over WMSN system employing the proposed method. A performance evaluation indicated that the proposed method significantly improved the decoded speech quality relative to the conventional methods under different PLR conditions ranging from 0% to 25%.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported in part by the National Research Foundation of Korea (NRF) grant funded by the government of Korea (MSIP) (no. 2015R1A2A1A05001687), by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF-2009-0093828), and by the MSIP, Korea, under the ITRC (Information Technology Research Center) support program (IITP-2015-H8501-15-1016) supervised by the IITP (Institute for Information & Communications Technology Promotion).