
Abstract
Data prioritization problem is paramount for distributed publish/subscribe infrastructure to the timely delivery of real-time events since a large number of low priority events may clog the channel thereby causing high priority events to get delayed. The challenge raised for the event-based middleware in large-scale distributed system such as vehicular ad hoc networks is that event priority determination engine must be efficient and scalable in terms of priority rule size and event throughputs. This paper proposes an innovative approach based on Bloom filter and event discretization. A Bloom filter data structure is used to store the rule instances and their priorities. The complex rule evaluation is reduced to set membership testing as queries on Bloom filters. The time complexity of data prioritization is constant and independent of the number of priority rules. As event discretization signatures can be cached, this approach is cache friendly in nature. The previous computation results can be cached in overlay network nodes and reused to improve the system throughputs and determination time. We have evaluated our proposed approach and the results show a significant performance improvement.
1. Introduction
With the advent of ubiquitous sensor-rich environments and location-based services, distributed event-based systems with the publish/subscribe communication paradigm have been gaining popularity [1, 2]. For example, in vehicular ad hoc networks (VANETs), the applications logics are triggered by various events from geographically distributed sources. In expressway monitoring system of VANETs, the sensing data of vehicles are published continuously and the vehicle information system may subscribe to different data based on the vehicle's location.
With the increasing popularity of distributed event-based systems (especially the publish/subscribe systems) and the adoption in mission critical areas, performance and scalability issues are becoming a major concern [3, 4]. The performance and scalability of the event-based middleware used to process real-time event data will be crucial for the successful adoption of such applications. Flexible and efficient events routing mechanisms are paramount for the improvement of user experience. Publish/subscribe systems must support a large number of geographically distributed publishers and subscribers. Efficient communication between these brokers is paramount.
Data of different importance are transported in the same communication infrastructure. Large number of low priority events may occupy much bandwidth of event brokers and incur delivery delay of time sensitive data. We propose event delivery on-time rate (EDOR) metrics to measure system performance. Prioritized multiqueue approach is a natural choice to improve the system performance under given system resources. However, the effectiveness of this approach depends on the performance and scalability of event priority determination engine (PDE).
A naïve implementation of priority rule matching might check each rule against event instance values. But this naïve approach performs poorly in large-scale system [5]. The performance of priority determination engine is dependent on the number of rules in the system. Since each condition of the rules needs to be checked on the fly, this naïve approach is cache-unfriendly and may perform poorly under geographically distributed environment. A cache-friendly approach may alleviate the load of PDE dramatically and achieve significant improvement of system performance in terms of the speed of priority determination and event delivery on-time rate (EDOR).
Another naïve priority policy is that event producer can determine the priority of events. Under this policy, the priority is determined by different event producers. If most events are labeled as high priority, the system cannot benefit much from the priority mechanism. We need global policy for resource scheduling in the overlay network.
The design issues of efficient and scalable priority determination engine (PDE) are addressed in this paper.
In this paper, we present an innovative PDE design based on Bloom filter and event discretization. First, the speed of priority determination is independent of the number of rules in the system. Second, this approach is cache friendly. The system can handle large number of events in geographically distributed deployments.
The results in this paper are an improved and extended version of our conference paper in IEEE SCC 2012 [6]. The major extensions in this work are the following. First, the model is refined and expressed more accurately. Second, more related works are explored. Third, the discretization algorithm is detailed, which provides a much more thorough description compared to the preliminary results in [6]. Finally, the evaluation methods and results are introduced in this paper.
2. Related Work
Data Prioritization. The internet services require soft real-time constraints, for example, 300 msec latency [7, 8]. For some applications, a 100 msec increase in latency can affect its user experience significantly. Experiments of Amazon and Google [9] demonstrated that latencies at hundreds of milliseconds could already result in significant financial loss. The absence of traffic prioritization causes latency-sensitive data stream to wait behind latency-insensitive data stream. Events are useful, if and only if events are delivered within its deadline. Recent research works [7, 8, 10] addressed this issue under datacenter environment and the solutions are mostly focused on transport layer protocols. In the cross-layer approach, named DeTail, the solution depends upon applications to properly specify data priorities based on how latency sensitive they are [7].
The presence of data prioritization can alleviate this issue significantly. Our system [11] introduces data prioritization into application layer, that is, publish/subscribe overlay network. In the overlay system, the prioritizations of application data can be handled by publish/subscribe infrastructure. However, if the overhead of prioritization is too high, the solution is not affordable for most soft real-time applications. These online applications require fast data prioritization services. Low latency and high throughput under geographically distributed environment are demanded for the data prioritization engine. At the same time, it should be scalable in terms of priority rule size.
Rule Matching. Rule matching engines have been intensively studied in the past decades. The most famous algorithm is Rete, which was proposed by Charles L. Forgy at Carnegie-Mellon University in the 1970's [5, 12]. Rete algorithm has become very widely used; it is the basis of OPS5, CLIPS, and numerous commercial rule-based tools.
Techniques used in expert and rule-based systems support expressive predicate languages [12] but are unable to scale up to process millions of Boolean expressions. Most of the traditional rule-based systems used in expert systems focus on language expressiveness and their expected sizes are assumed to be less than thousands of Boolean expressions. The latest Rete implementation declared that the scale can be up to 100 K rules with millions of objects and is at least 500 times faster than the original Rete [13, 14]. Although advances in the implementation of knowledge-based expert systems have provided substantial performance improvements, the rule matching speed in large-scale systems with millions of Boolean expressions under severe time constraints for example, submillisecond, is still an open issue.
Many innovative approaches have been proposed to address fast rule matching against millions of Boolean expressions [15–18] recently. The rule matching performance has been improved significantly. But all these algorithms scale linearly with respect to the number of matched Boolean expressions [15]. These algorithms focus more on top-k matching Boolean expressions [15, 17, 18].
Compared with Rete and the aforementioned works, our approach focuses on the scalability and provides an innovative solution on rule matching engine design under distributed computing environment. Our approach is focused on the scalability of online query speed of event priority rule matching at the cost of offline large rule instance database maintenance and cache management on broker nodes.
3. Model Description
3.1. System Model
The publish/subscribe system can be classified by architecture as centralized publish/subscribe system and distributed publish/subscribe system [19]. As the increasing scale of event-based systems, the distributed publish/subscribe system attracts more attention from both industry [20] and academia [21].
A generic publish/subscribe system (often referred to in the literature as event service or notification service) is composed of a set of broker nodes distributed over a communication network. These nodes form an overlay network, which is a logical network built on the physical network. The links between nodes are paths in the physical network.
Formally [22] the distributed publish/subscribe system can be represented as a 5-tuple
The overlay topology of publish/subscribe network is shown in Figure 1. Client can be publisher or/and subscriber. Each client is connected to only one of the brokers in the system. The broker that is connected to client is called the access broker from network view and is also called home broker with respect to that client. The brokers that route events between brokers are called event router or inner broker.
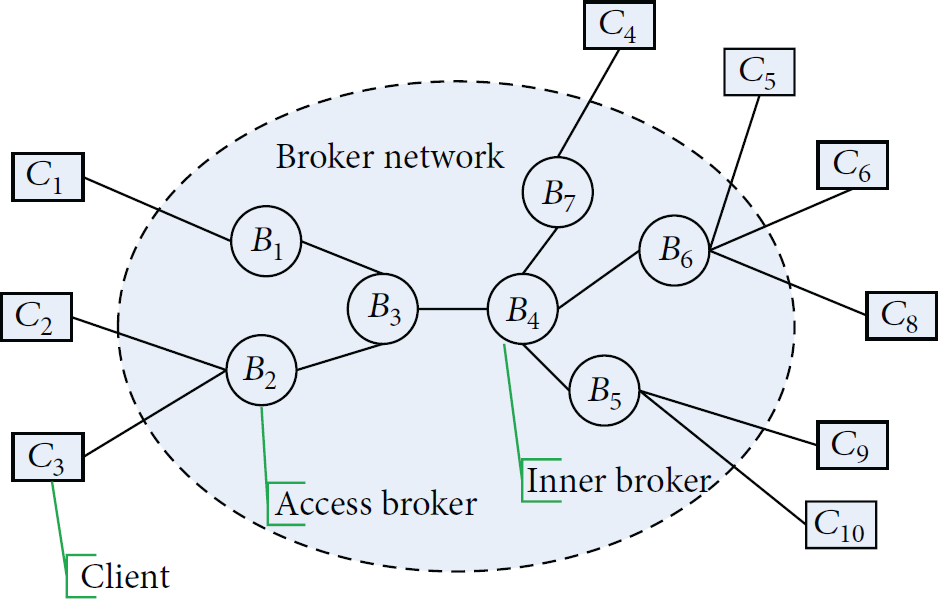
System architecture of distributed publish/subscribe overlay network.
3.2. Event Model
Publish/subscribe based event models were first introduced in the data and business domain as complex event processing [1]. Each event is described by a set of attributes,
The tuple
Let E be the set of all events published in the system. An event
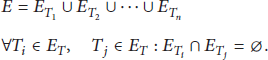
For each event schema, the attributes vectors that determine the event priority are called priority signature vector. Let
We distinguish two types of attributes: continuous variables and discrete variables. In our approach, the attributes with continuous value must be refined into discrete values with proper granularity. The attributes with discrete value also may be refined into proper granularity per application requirements. The discretization procedures can be defined by applications per business requirements.
3.3. Priority Rule Model
The triple consisting of attribute, operator, and set of values is referred to as a Boolean predicate. A conjunction of Boolean predicates is a Boolean expression. A priority rule can be modeled as a set of Boolean expressions. The rule is expressed as a disjunction of Boolean expressions. For a given priority, there may be a set of priority rules specified by applications.
The set of values in all Boolean predicates composed the metadata of the priority rule. An expressive set of operators are supported: relational operators (
For example, given event schema of coal mine monitoring data, which is defined as
Boolean predicates
The rule set for given priority can be modeled as a set of Boolean expressions, which are the union of the Boolean expression sets for the priority rules of the given priority. The general format of priority Boolean function for a set of rules can be formalized as
We define the normal model of priority rule as a disjunction of Boolean expressions and each Boolean expression is defined as a conjunction of Boolean predicates.
The transformation from nature language rule specification to normal expression is another research topic in requirement engineering, which is not addressed in this paper.
Given an event instance,
In this simple example, we observe that the four condition tests denoted by Boolean predicates can be reduced to two attributes in event priority signature vector. We also observe that in condition tests on Boolean predicates
3.4. Assumptions and Design Goals
Our design has been guided by assumptions that offer both challenges and opportunities.
The system shall support large-scale system running under geographically distributed environment. The speed of priority determination is paramount to ensure real-time event to be delivered timely. The performance shall be scalable with the scale of condition tests in rules and the traffic of events in overlay network. The problem of priority determination can accept false positive if the false rate can be controlled under the acceptable rate. Large amounts of condition tests in priority rules are actually defined by small number of event signature attributes. The condition tests in rules can be expressed as set membership query problem. The priority rules mostly are expressed as some attribute suffice some condition (in particular set, less than or greater than specified threshold value). The condition tests are not likely as complex as the pattern match problem in artificial intelligence area. The set of event types is known in advance.
Our design goals on PDE focus on the following aspects.
The PDE should strive to maximize the number of events that satisfy their deadline to contribute to application throughput. The PDE should be able to accommodate to burst tolerance to improve the peak load: redefines the peak loads at which the publish/subscribe system can operate without impacting the user experience.
To achieve these design goals, we propose our approach: summary instance.
4. Solution
The basic ideas of our approach are composed of two main principles. First, make online query on event instance as simple as possible. The time consuming procedures should be done offline. Second, exploiting the power of cache on each broker node to reduce network round trip may bring much room for performance improvement.
4.1. Overview
To accommodate the aforementioned principles, it would be best that the computation time of query is simple and independent of the number of condition tests in rules and query can be answered by lookup local cache as long as possible. The key ideas of our approach are rule instantiation, event (attributes) discretization, and caching-friendly signature-based rule matching mechanism under distributed event environment.
As shown in Figure 2, the rule matching engine is decoupled as two parts, offline rule instantiation and online query on event instance matching. The offline part is named rule instantiation engine (RIE). The online part is named priority determination engine (PDE).

Architecture of event priority rule matching engine.
Rule instantiation process tries to represent the event priority rule set as a set of instances. If event priority is queried on this set directly, the computation time involved in performing the query is dependent on the number of the elements in set R. To reduce the computation time, the rule instance set R is stored with Bloom filter data structure. The computation time of query on Bloom filter is independent on the size of rule instance set R. Furthermore, the amount of storage required by the Bloom filter for each element in set R is independent of its length. By employment of Bloom filter, the online query of event priority is reduced as two-hash function computation on event signature; refer to next section on Bloom filter theory.
4.2. Preliminary
In order to keep this paper self-contained, this subsection presents a concise introduction on Bloom filter.
After the Bloom filter is proposed in 1970s [25], it is first used in database communities. This technique has gained popularity in network applications with the emergence of the Internet [26].
A Bloom filter is a simple, space-efficient randomized data structure for representing a set of strings compactly for efficient membership querying. It outperforms other efficient data structures such as binary search trees and tries as the time needed to add an item or check whether an item belonging to the set is constant irrespective of the cardinality of the set.
At first, we present the mathematics behind Bloom filters concisely. A standard Bloom filter for representing a set
The query process is similar to programming. To check whether an item y is in S, we generate k hash values with
To accommodate the deletion operation on Bloom filters, Fan et al. proposed the idea of counting Bloom filters [28]. In a counting Bloom filter, each entry in the Bloom filter is not a single bit but rather a small counter. When an item is inserted, the corresponding counters are incremented; when an item is deleted, the corresponding counters are decremented. To avoid counter overflow, we choose sufficiently large counters [26, 27]. The analysis from [26, 28] reveals that 4 bits per counter can suffice requirements of most applications.
To accommodate membership queries of dynamic sets, Guo et al. proposed dynamic Bloom filters (DBF) [29]. Further improvements on scalability problem of Bloom filter are addressed by scalable Bloom filter (SBF) [30].
In order to reduce the need for computation of possibly large number of different hash functions, the authors of [31] have shown that only two hash functions are necessary to effectively implement a Bloom filter without any loss in the asymptotic false-positive probability.
4.3. Rule Instantiation Engine Footnotes
RIE (rule instantiation engine) is designed to program the event priority determination rules into a set of Bloom filter structures. RIE transforms abstract priority determination rules into concrete instances and generates Bloom filter based summaries of the large data set on rule instances per each priority. In this section, we show how RIE works.
4.3.1. Rule Instantiation Process
First, we explain how RIE transforms rules into a set of rule instances with a simple example.
Consider event schema and rule description as follows.
Event schema is defined as Rule set
The first rule means that if the incoming event data are generated from locations in set
The second rule means that if the incoming event data are generated from locations in set
Event priority signature vector can be inferred as
The attribute
The set
Each rule instance is an element in rule instance space (IS), which is defined as
We can deduct the instance representation format for rule R as follows.
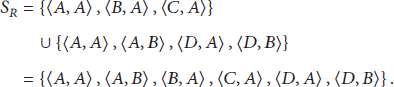
The duplicated instance
It is obvious that
The key data structures are described in Figure 3 and Algorithm 1.
(1) Predicate: 〈attribute, operator, value〉. (2) Operators: OperatorEnumerator (3) BE: a list of predicates, which is ordered by event attributes. For example, shall be formalized as (4) Rule: a list of BEs (5) RuleSet: a list of rules (6) VecSig: signature vector is a list of attributes involved in priority rules logically. In this basic design schema, there is only one signature vector for each priority per event schema. The vector is initialized as bit vector with zero. If the attribute appeared in Boolean expressions, the corresponding bit is set to (1). (7) Discretizer: two types of hash table are defined. (8) Signature for event instance: byte block structured as 〈Event Type ID, Discretizer ID, an array of discretized attribute value in event instance〉

Data structure of signature vector and attribute discretizer.
The procedure on rule instantiation process is described as in Algorithm 2. First, transform the condition tests as set membership determination with proper granularity,
(1) generate BE list for RuleSet (2) (3) Get the attribute ID in predicate (4) Set the bit in signature vector to (1) (5) (6) (7) predicates table 〈attribute ID, (8) (9) (10) Add set (11) (12) Merge discrete sets on the same attribute by set intersect operation in predicates table (13) Generate the rule instance set (14) Store the rule instances in set (15)
(1) (2) (3) ContinousDiscretizer cd = p. attribute.discretizer; (4) (5) (6) (7) (8) ; //do nothing (9) (10) S.insert(item.id); //false positvie rule are introduced (11) (12) S.insert(item.id); (13) (14) (15) (16) (17) (18) S.insert(item.id); (19) (20) S.insert(item.id); //false positvie rule are introduced (21) (22) ; //do nothing (23) (24) (25) … //other operators (26) (27) (28) DiscreteDiscretizer dd = p. attribute.discretizer; (29) (30) (31) (32) (33) S.insert(item.id); //false positvie rule are introduced (34) (35) (36) (37) (38) (39) ; //do nothing (40) (41) S.insert(item.id); (42) (43) (44) … //other operators (45)
Given
Our framework draws a schema of the discretizer, which can be customized by applications. The discretizer divides the domain of the attribute value into several ranges or discrete sets and these ranges or sets shall be disjoint with each other; that is, for all
The signature vectors for event schema are generated in Algorithm 2. The signature vectors are used for event signature generation procedure in Section 4.4. The structure of signature vector is shown in Figure 3.
4.3.2. Hash Computation on Instance Set
For each element in
If event types share the same set of Bloom filters, event type identification shall be programmed into signature to ensure the uniqueness of each signature in the Bloom filter. Event type identification is a unique string to distinguish event types. An alternative design choice is that each event type has its own set of Bloom filters for priority determination.
Different event discretizers will make the rule instance different even for the same event schema. If there are multiple discretizers defined by various applications, the discretizer identifier shall be contained in rule instance structure. An example is shown in Table 1.
Example for rule instance structure.

4.3.3. Update the Computation Results into Bloom Filters
For each priority, one bit vector is dedicated for the summary of rule instance set
4.4. Priority Determination Engine
The PDE discretizes event instance values to generate the signature of priority and determine event priority by query rule database, which is represented by a group of Bloom filters. When multiple rules match the same event, the engine shall choose the high priority result.
4.4.1. Event Priority Signature Generation in Access Brokers
The generation of event priority signature is based on the same priority signature vector and corresponding discretizer. The interaction procedure between broker node and PDE service is shown in Figure 4.

Event priority determination procedure.
Consider signature and discretizer as follows:
While the access broker receives a published event, the broker need generates the event signature. The signature generation algorithm is shown in Algorithm 4 (line (1)–line (7)). The signature is initialized in line (1). Assume that event type ID is “ETID0001” and discretizer ID is “DISC01,” the signature is represented as
(1) Initialize signature with event type ID and discretizer ID (2) (3) (4) (5) add id into signature (6) (7) (8) Query BF-based rule DB with signature to determine the event priority
Assume that event instance
For discrete attribute, the discretizer does nothing by default. In this example,
(1) (2) traverse discretizer (3) (4) (5) traverse discretizer (6)
For continuous attribute, the discretizer performs line (1) to line (3) in Algorithm 5. In this example,
The third attribute is not in signature vector; this attribute has no effect on signature generation as line (3) in Algorithm 4.
In this example, the final signature is represented by
4.4.2. Query Bloom Filter with Signature
Based on hash computations on event instance signature string, PDE queries the BF-based rule DB to determine the event priority. PDE returns the priority flag to the access broker.
4.4.3. Caching Query Result in Access Brokers
Since a large amount of event instances may share the same signature, the round trip time in the network may be saved by caching the hot signatures in local broker. The main memory access time is typically less than 100 ns. Even the round trip time in the same datacenter is about 500,000 ns. The round trip time in wide area network may be over 100 ms, which is about 6 orders of magnitude of main memory reference time. The saved time on network round trip may speed up the determination of event priority significantly.
4.5. Discussion on Discretization
The discretization can be flexibly defined by applications per business requirements. The basic principle is false positive.
False Positive. For numeric value attribute a, the corresponding discretization set is defined as
The definition of computation granularity on specific attribute
For discrete attributes, the discretizer is optional. It means that the discretizer can be composed of dummy (do nothing) functions. It is up to application requirements. If the original granularity of attribute value set is too fine, applications can plug in a customized discretizer to achieve proper granularity.
Performance. The traverse of continuous discretizer can be improved by binary tree search. As it is trivial, we do not discuss it in detail.
The traverse of discrete discretizer can be avoided in most cases since there is no discretizer for discrete attribute by default. The employment of discrete discretizer can reduce the rule instance space size at the cost of computation efforts in Algorithms 3 and 5, which increase the computation time of signature generation procedure.
4.6. Analysis on System Performance
System performance analysis is divided by online query (interactions between access broker and PDE) and offline rule instance summary building (RIE module).
4.6.1. Online Query Performance
The computation is broken into two parts as shown in Algorithm 4.
The first part is signature generation. The computation complexity depends on two system parameters: the size of the priority signature vector and corresponding attribute discretizer. Assume that the priority signature vector is
The discretization result of
The second stage computation is query on rule set Bloom filters. The query computation complexity is
Therefore, the computation complexity of online query is
The computation of signature generation depends on the size of the priority signature vector and corresponding attribute discretizer. Since these discretizers can work in parallel, the speed of signature generation depends on the slowest discretizer. It would not be the bottleneck in practice.
In PDE, the main part of query computation time is two-hash function computation of the signature string [31].
To keep the cache fresh, the update on rule instances shall be notified to access brokers. The cache management procedure has no impact on the online query speed.
4.6.2. Offline Building and Maintenance of Rule Instance Database Based on Bloom Filters
Although offline work is not time sensitive, we also need to evaluate the efforts on rule instance database building. We want to know how to minimize the efforts on building instance database.
The basic idea of rule instantiation process is presented in Algorithm 2.
The upper bound of rule instance set size is the cardinality of rule instance space set. The applications shall choose priority signature vector to make the size m as small as possible. The attribute discretizer shall choose proper computation granularity to make the size of
Minimizing the offline computation at middleware layer is the subject of ongoing work. A more efficient implementation requires further exploration. The goal is to reduce rule instance space size dramatically without introducing significant impact on online query performance.
For rule maintenance efficiency, the delta rule change shall be processed efficiently. The cache shall be managed efficiently. These works will be addressed by future works.
5. Evaluations
In this section, we evaluate the query performance and scalability of summary instance (SI) approach with simulations. The experiments were run on an Intel Xeon Dual-core E5645 2.4 GHz machine with 8 GB of memory, of which 6 GB is allocated to the JVM.
5.1. Data Set
To evaluate the performance of the summery instance based priority determination engine, we generate rule set with Boolean expressions ranging from 100 K to 1000 K. Lacking the benchmarks and real application data, the rule data set and event data set were generated by a workload generator which produces the data randomly by selecting values from given value ranges. The value ranges can be specified in the configuration of data generator application.
5.2. Matching Algorithm
The brutal-force approach is an exhaustive algorithm that scans and evaluates all BEs one by one for each assignment. We call this approach SF in the following experiments. We compare our approach SI with SF approach in the following experiments.
5.3. Experiment Results
In this section, we explore the impacts on matching time from workload size, workload distribution, and matching rate of event data set. Then, we evaluate the false-positive issue in SI algorithm.
Workload Size. We evaluate the impacts of workload size on the matching algorithms. Figure 5 illustrates the comparison results for SF and SI algorithms under varying rule set size. The rule set size varies from 100 K to 1 M. The matching time of SF algorithm increases linearly with the workload size as shown in Figures 5(a) and 5(b). The matching time of SI algorithm is nearly constant as shown in Figures 5(a) and 5(b). SI algorithm illustrates impressive scalable performance. SF algorithm performance will degrade with workload increases. The simulation results are consistent with our theoretical analysis.

Varying workload size.
Workload Distribution. The effects of workload distribution are shown in Table 2 by comparing the performance of event matching under uniform distribution workload and Zipf distribution workload. The SF algorithm is sensitive to workload distribution in data set. From experiment results in Table 2(a), the Zipf distribution workload introduces about 50% matching time increases in SF matching algorithm compared with uniform distribution workload. The SI algorithm is robust with the workload distribution. There are no significant matching time increases in different workload distribution. Since the time precision of the computer system is 100 milliseconds and the size of event data set is 10,000, the precision of matching time per event is about 0.01 milliseconds. The raw performance data of SI algorithm are illustrated in Table 2(b). The variance can be ignored considering the time precession in our experimental environment. The final results are shown in Table 2(c). The variance of performance is nearly zero.
Workload distribution impacts.

Event Set Matching Rate. We consider the effects of matching rate of event data set. If one event instance does not match any rule in rule set, the SF algorithm needs to go through all rules in the rule set. From intuition, the average event matching time will increase if matching rate in event data set decreases.
From Figure 6, we can see that the performance of SF algorithm is sensitive to the matching rate of event set. As the matching rate of event set increases, the average matching time per event decreases. The matching time decrease linearly with the matching rate of event data set.

Varying matching rate of event set.
We can see that the performance of SI approach is robust with varying matching rates with different workloads. The experiment results under uniform workload are shown in Figure 6(a). The experiment results under Zipf workload are shown in Figure 6(b). The matching time is nearly constant under varying matching rates and different workloads.
False-Positive Issue Evaluation. An important property of SI algorithm is the false-positive rate. We explore the false-positive issue in this experiment.
There are two kinds of false-positive sources: Bloom filter query process and discretization process. The discretization process is defined by applications and can be adjusted at application layer. This paper focuses on platform layer. The discretizer design and optimization is out of the scope of this paper. An automatic adaptive mechanism is promising to optimize the false-positive rate and computation efforts. This optimization issue is out of the scope of this paper. We need to address this issue in an independent paper.
We set up controlled experiments to evaluate the impacts of Bloom filter configuration on false-positive issue. We also verify that no false negative happened to support the theory analysis results.
The test data set are designed as follows. The false positive of discretization process can be avoided by generating event data set and rule data set from predefined ranges based on definition of discretizers.
We use a simple example to illustrate data set construction principles. The attribute discretizer are defined as
In this experiment, the event data set and rule data set are generated randomly with the constraints without introducing false positive in discretization process. The event data set size is 10 K. The event instances are uniformly distributed in the given ranges. The rule set size is 10 K. The rule parameters are randomly selected from the given ranges.
The experiment results are shown in Table 3. The Bloom filter false-positive rate varies from 0.001 to 0.5, as shown in the BF-FPR (Bloom filter false-positive rate) column in Table 3. The data in matched column and unmatched column are from SF algorithm. These two columns illustrate the accurate rule matching results. The 4th column (SI result) shows the approximate rule matching results by SI algorithm. The parameter of Bloom filter impacts on the rule matching results, namely, FPR (False-Positive Rate), are shown in column 5 in Table 3.
False-positive rate evaluation in SI algorithm.

False positive rate in SI algorithm with different Bloom filter parameters.
Since priority determination problem is not bothered with low false-positive issue, SI algorithm is very suitable for this kind of applications.
5.3.1. Summary on Evaluation
SI algorithm outperforms SF algorithm with 2–5 orders of magnitude. It demonstrated significant scalability with workload size and stable performance with different workload distribution and various event data sets with varying event matching rates. In addition, it also illustrates acceptable false-positive rate. Therefore, it is a suitable approach providing scalable and robust priority determination service.
6. Conclusion
Information representation and query processing are two core problems of event-based distributed systems such as VANETs. In design problem of event priority rule matching engine, the two core problems are the rule representation and event instance priority determination. Rule representation means organizing rule policy information according to some format and mechanism, making information operable by the corresponding method. Query processing means making decisions about whether an event instance with a given attribute value belongs to a given set.
To speed up the online query in distributed event-based system, we introduce the rule storage schema based on rule instantiation method with Bloom filter technique. This approach leverages offline efforts to increase the online query speed. This paper draws a fundamental framework for this approach.
The key features of our approach are the following:
scalability: performance of rule matching is independent of the number of rules in the system, because an important property of Bloom filter is that the computation time involved in performing the query is independent of the number of strings in the database provided the memory used by the data structure scales linearly with the number of strings stored in it, efficiency: the signature approach is cache friendly and works very efficiently under large-scale distributed environment. Large amount of event instances do not need to occupy the bandwidth of the rule match engine, false-positive rule matching: the false rate is acceptable by adjusting parameters of Bloom filters.
Our approach is promising to provide an efficient scalable design for event priority determination problem in large-scale distributed event-based systems. This approach is also applicable for many rule matching scenarios with severe time constraints for large rule sets.
Footnotes
Disclosure
A preliminary version of this paper appeared in IEEE SCC 2012, June 24–29, Honolulu, Hawaii, USA.
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
We express our thanks to anonymous reviewers who checked our paper for their insightful and constructive comments. This work was supported by National Grand Fundamental Research 973 Program of China under Grant no. 2013CB329605; National Natural Science Foundation of China under Grant no. 91124002; Chinese Universities Scientific Fund (BUPT2014RC0701); Transformation Project of Scientific and Technological Achievements in Henan Province (2014) no. 142201210009; Key Project of Science and Technology in Henan Province (2014) no. 144300510001.