
Abstract
In the ubiquitous network environment where numerous devices are connecting each other, it is believed that security will play an important role in overall network management. And the wireless sensor network (WSN) is commonly considered to be one of such networks prone to a wide range of attacks due to its inherent characteristics. For the sound operation of WSN, it is important to block malicious connections from the network as early as possible. This paper proposes a novel approach to real-time monitoring of network by using the sequential KNN voting. When connection data is sequentially recorded on the log, the final result of ongoing behavior is predicted probabilistically with only partial data, which iterates consecutively as additional connection data are accumulated to the log. Once this predicted probability reaches certain preset threshold value for possible network intrusion, then we can do some preventive actions for this ongoing connection. The value of this research lies in that the eventualities are predicted at the early stage of connection with partial information available. Since the prediction uses sequential KNN voting, the accuracy of our approach can be even more enhanced as with the volume of log grows.
1. Introduction
With the growing utilization of various ubiquitous networks such as mobile, cloud computing, and even sensor devices, security issues become more important than ever, which leads to the development of Network Intrusion Detection System (NIDS) [1, 2]. NIDS aims at providing the security in existing data networks by identifying unauthorized use, misuse, and abuse of computer system [3]. One of the widely used approaches to NIDS is anomaly-based NIDS (A-NIDS) originated by Denning [4]. A-NIDS is usually conducted by the following manners including parameterization, learning, and classification so as to investigate characteristics in network parameters to distinguish anomaly from normal network connections. Research methodologies to investigate such characteristics can be categorized into three groups: statistical based, knowledge based, and machine learning based methodologies [5].
This paper focuses on machine learning based approach for network intrusion detection, especially K-nearest neighbors (KNN) which is one of the most popular data-mining techniques. The original application of KNN tries to find similar historical cases to each network connection and then determines the result of this new case as the majority of KNN decides. Like this, most of machine learning based methodologies including KNN are conducted in such a reactive way, which identifies the status of each case based on full information of entire parameters. Although they can diagnose the status effectively, it is only after the situation has already occurred. In that circumstance, only reactive corrections can be done afterwards. We can block the malicious connection after the intrusion is detected with conventional KNN approach, but we cannot be sure how much damage has been done by the intruder during that time. If we can block such malicious access proactively even before the connection is established stably by using real-time and partial information, then network security will be enhanced quite a lot.
In this paper, we define a novel viewpoint on network monitoring, especially for the real-time monitoring with sequential data acquisition during the entire steps of connection establishment. Unlike the conventional approaches where the decision is deferred until all of network data are collected at the end of connection, our approach proposes a real-time monitoring method to represent the ongoing status of network connection and provides a proactive warning for possible intrusion. To realize this, we formulate the sequential KNN voting approach under the assumption about the incremental acquisition of network connection data. As an attempt for connecting to network goes along, possible results of this ongoing case are predicted based on the partial data gathered during that time by investigating attack types in partial-dimensional KNN. As the monitoring goes on, possible results are also updated by incorporating additional connection data. If the probability of intrusion exceeds certain predetermined threshold, a proactive warning is generated to notify the eventualities. Through experiments conducted with a well-known network intrusion dataset, we examined the applicability of proposed approach and analyzed the performance of our proactive warning system.
The rest of this paper is organized as follows. Section 2 presents several related works about NIDS and KNN-based approaches for intrusion detection. Section 3 provides details on the proposed real-time monitoring approach and its sequential KNN voting method. In Section 4, we discuss and analyze the results of experiments conducted in a hypothetical monitoring scenario using UCI data. Additionally, some operational considerations were discussed for actual application of proposed approach in Section 5. Finally, conclusions and future works are summarized in Section 6.
2. Background
2.1. Related Work
Machine learning techniques have been applied successfully to various industries, since they can be conducted without experts' knowledge, and differentiated methods can be selected according to the characteristics of application domains [6]. Several techniques also have been widely adopted in A-NIDS. Stein et al. integrated decision tree classifier with generic algorithm for feature selection to categorize normal cases and attack cases more effectively [7]. Luo and Bridges suggested association rule mining integrated with fuzzy theory to consider the uncertainty [8]. Ponomarchuk and Seo proposed a lightweight and efficient method for intrusion detection against data flow from wireless sensor networks by adopting fuzzy inference [9]. Bringer and Chabanne developed the fuzzy keyword search method for private identification in cloud computing [10]. Lippmann and Cunningham suggested neural network based intrusion detection, which was combined with keyword selection to improve the accuracy [11]. Support vector machine (SVM) is also one of the most popular techniques. Mukkamala et al. compared the performance of neural networks based, and SVM based, systems for intrusion detection and demonstrated that both techniques could be used to establish efficient and highly accurate classifiers for network intrusion detection [12]. Eskin et al. extended the original use of SVM to the unsupervised method for unlabeled intrusion learning [13].
Our proposed approach has adopted and extended the original application of KNN technique into the KNN voting rule. For each new case that is composed of connection attributes, similar historical cases are retrieved by sorting the distance in the finite dimensional vector space, each of which has the final value corresponding to the actual result type. Then, by the rate of each result type among retrieved neighbors, the target value of sample case is determined. Because the construction of classifier is not needed, KNN is easy to use when there are frequent updates in the training data [14]. Liao and Vemuri developed intrusion detection system to classify program behaviors by integrating KNN and text categorization as the feature selection method [14]. Li and Guo proposed transductive confidence machines for K-nearest neighbors for active learning based feature selection method [15]. Kuang and Zulkernine developed combined strangeness and isolation (CSI) measure as the similarity criteria to find nearest neighbors [16]. Adetunmbi et al. integrated KNN with the rough set theory to extract significant features to distinguish attack types [17].
2.2. Research Motivation
Lots of previous studies have focused on the performance improvement of A-NIDS, like speed or accuracy, by constructing hybrid classification models and integrating them with feature selection methods. So far, conventional viewpoint about real-time approaches has usually implied the prompt detection of network intrusion when the connection data are completely acquired with full attribute set. In those approaches, the responses are deferred until all attributes are gathered, and the decisions are usually final.
In our approach, we introduce different point of view on the real-time monitoring: the sequential acquisition of connection data and continuous change of nondecisive decisions up to certain preset threshold value is exceeded. Let us suppose the following situation. When an entity tries to connect to network, the relevant attributes are generated and recorded sequentially along the protocol for connection establishment and its behavior characteristics afterwards. And then its final result, whether it is normal or abnormal, is determined by considering the full data and the status of system at the end of connection. Because conventional A-NIDS approaches mainly target the completely filled dataset as the input vector, in which all attributes are present, they are fundamentally hard to cope with missing attributes in the meantime. Consequentially, they cannot help waiting until the ongoing connection is completed so that, from our perspective of real-time concept, they are hard to provide genuine real-time monitoring.
Although the accurate detection of intrusion has been one of the most significant research issues, its prediction is also important, especially when the partial information at the initial phases of network access is available only. This serves as the research motivation of our approach for the development of sequential KNN voting. In the proposed approach, at each monitoring time, the unrecorded attributes are assumed by referring archived logs of similar cases, which are combined with the ongoing log so as to make virtual progresses after this time. Then, a number of probable progress logs (predicted patterns) are generated, and subsequently the final result is predicted probabilistically with the rate of each result type that is classified by the original use of KNN-based A-NIDS.
3. Sequential KNN Voting for Intrusion Prediction
3.1. Overall Procedure
Figure 1 shows the overall procedure of the sequential KNN voting for network intrusion prediction. Generally, a case for network connection is defined as a set of attributes corresponding to its transferred contents and traffic features. Let us suppose that each of these attributes is generated sequentially during an instance of connection that goes along, and then the final result of that instance is determined definitely based on the entire set of attributes recorded up to the end of connection. In this situation, the proposed approach aims to predict the final result of ongoing instance based on the partial data, before all of attributes are recorded at the end of connection.

The overall procedure of real-time monitoring of network connection.
In build-time, it is assumed that historical logs are already archived and then collected in a data warehouse for the given network's connection. In run-time, monitoring system captures every meaningful activity from a new instance that tries to connect to network and archives them into log as corresponding attribute value. Each time a new attribute value enters into log, the sequential KNN voting is conducted to predict its possible final results by scrutinizing the ongoing log of a new instance through a set of recorded attributes, which estimates the probability of achieving each result type. This procedure is iterated continuously as monitoring goes on until the probability of certain result type exceeds preset threshold value, or until the completion of the instance's log. If the real-time alert for the progress of suspicious instance is given to network administrator as probability value, then it will be much helpful to understand the behavior of connecting entity and thus do a proactive action.
3.2. Preprocessing
In the course of network connection, the monitoring system continually observes generated attributes. After the end of connection, the result type of completed case is diagnosed by experts or classifiers. For example, the result type can be normal, abnormal, or one of several attacks. Such diagnosed case is archived into the data warehouse in the form of a historical log. Historical
3.3. Real-Time Monitoring
At the monitoring time t, the ongoing log of an instance is composed of recorded attributes
First, the proposed approach retrieves historical logs similar to

The distance in t-dimension represents the degree of similarity between historical
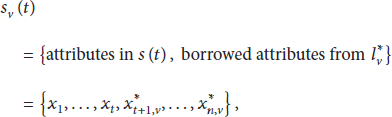
Then, for the given assumed patterns
Finally, the real-time indicator

As the monitoring progresses while the attributes are further gathered in real-time, above procedure is repeated to update the probability
To help the understanding of overall procedures, a simple example is illustrated in Figure 2. Let the log database in the data warehouse be constructed with total of 104 cases. Each case records several attributes with 0 or 1 value, and the possible outcome is just good and bad types only. The number of actual occurrences for each result types is given in parentheses for each case. If the real-time gathering of attributes progresses in the pattern of

An illustrative example for sequential KNN voting algorithm.
4. Experiments
4.1. Dataset Description
To demonstrate how the proposed approach can be applied to real-time monitoring of network connections, we conducted experiments with the well-known network intrusion dataset. As an experimental dataset, we adopted one of the famous network intrusion datasets, KDD Cup 1999 Data, from UCI Machine Learning Repository [18], which were used for the 3rd International Knowledge Discovery and Data Mining Tools Competition. It corresponds to the supervised dataset: each case is composed of raw TCP dump data for a local area network, and the true target value includes “bad” connections called intrusions (or attacks) and “good” normal connections. The network connection is represented as a set of sequential TCP packets having starting and ending times, between which the data flows from source address to target address following protocol standards. Each connection is labeled either as normal or as one of attack types. More details for this dataset can be found in the following URL: “http//archive.ics.uci.edu/ml/datasets/KDD+Cup+1999+Data”.
4.2. Experimental Design
In our experiment, the original data is modified in order to verify the proposed approach. Generally, attack types can be categorized into four groups: DOS (Denial of Service), R2L (Remote to User), U2R (User to Root), and probing. Most importantly, several previous researches have pointed out that most of DOS and probing attacks tend to show sequential patterns in attributes, unlike R2L and U2R attacks [19, 20]. Therefore, on this basis, we conducted our experiments on three target values including normal connection, DOS attack, and probing attack. The used dataset was composed of 30,000 cases including 20,000 normal cases, 5,000 DOS attack cases, and 5,000 probing attack cases, which were extracted randomly from the original dataset.
The preprocessing of the extracted dataset was conducted as follows. Among overall 42 attributes composing each connection log (precise descriptions of them can be found in the URL given above), we filtered out 10 trivial attributes that did not carry much weight with determining the target value of connection. Then, for 32 attributes, 1-of-c coding was fulfilled to transform categorical values to continuous values for the calculation of distance between connection logs. Finally, the scale of attribute values is standardized for each attribute x by normalizing with its expected value
For robust evaluation, a cross-validation was performed by 5-fold experiments. We divided 30,000 logs into 5 groups. Then, in each experiment, one group was used as the target instances of the real-time monitoring that progress sequentially, and the other four groups were used as historical logs in data warehouse, which were iterated five times.
The real-time monitoring aims at visualizing the real-time estimator of the probability that ongoing log will be completed abnormally, especially with the result of attack types. During 32 sequences that the log goes along and the attributes are recorded periodically, the real-time monitoring and sequential KNN voting are also conducted iteratively. Therefore, there exist 32 monitoring times
4.3. Results
Figure 3 shows the monitoring results for normal and attack types. The probability

Real-time monitoring results for normal and attack types.
Among attack logs in Figure 3(a), we further investigated the probability of being completed as each of attack types. Figure 4(a) shows the probability

Real-time monitoring results for DOS and probing attack types.
From the above results, we could conclude that the proposed method makes it possible to predict the final result type before its actual completion, by continuously monitoring the trend of the indicators. Therefore, a proactive warning of attack can be provided before its actual occurrence, if

Change of estimated probability for 4 types of monitoring results.
Figures 5(a) and 5(b) show the two types of monitoring results for normal network access. As is illustrated in Figure 5(a), over the entire progress, the warning is not needed for this case, and the proposed method did well with no warning. By contrast, in Figure 5(b), the proactive warning was issued at time
With the above results in mind, we can say that it is necessary to determine the optimal threshold value for accurate proactive warning. Therefore, to set a proper level of threshold, we further investigate the result with varying threshold values that range between 0 and 100% and compare the accuracy with the reactive warning strategy of the conventional KNN approach.
Figure 6 summarizes the accuracy of proactive warning and reactive warning. Figure 6(a) shows the accuracy of the proactive warning according to the threshold value that is provided before actual completion

The accuracy change of proactive warning compared with that of reactive warning.
4.4. Discussion
Most of conventional approaches for network intrusion detection mainly consider that the connection occurs instantly so that all of the connection data are collected and recorded in a short time period. Therefore, the concept of real-time usually has implied the speed of classification over the entire dataset available. In our approach, however, we suggest a novel concept of real-time that there exists a considerable time interval between the acquisitions of respective connection data. In this environment, the conventional approaches cannot help but wait until all attributes of connection data are collected. It is needed to represent the genuine real-time status of ongoing log even with the partial data under this environment.
By experiments, we have demonstrated that the proposed approach has abilities to probabilistically predict the final result by assuming prospective progresses. Although there is no order in the generation of connection data in the original KDD Cup dataset, we assumed an order that was generated randomly for each experiment. With the experiment result, we can conclude that, whether a connection is intrusion or not, we can predict the final result based on only the partial data with some uncertainties. However, it should be noted that the performances like accuracy or proactiveness of warning absolutely depend on the characteristics of the given dataset.
It is quite natural that the prediction based on the partial information is less accurate than the detection based on the full information. However, although it brings in some inaccuracies, it can be more helpful to provide preventive warning for undesirable results. Interestingly enough, our experiment shows the opposite result: the reactive warning is slightly less accurate than the proactive warning. In this case, we guess that additional attributes that are gathered at the latter times of connection may have played as noise which disturbs the accuracy of detection. And this kind of noise can possibly be induced into the connection attributes in real situations by the intension of intruder to penetrate the security system.
If there is certain evident sequence in the order of attribute generation, the proactiveness, how proactively the warning is provided, will be important as much as the accuracy. The proactiveness affords administrator to prepare to eventualities that have not occurred yet. Additionally, cost parameters according to the types of error should be considered too. Such performance indicators should be investigated more precisely to determine the optimal threshold for each application domain.
5. Operational Considerations
Issues on Complexity. Generally, the network monitoring system continuously scans through the huge data stream in real-time, which leads to the needs of methods to deal with big data. But maybe even more important is extracting the real value of information and realizing it in a more efficient way by reducing the computational complexity such as time and space. Therefore, researchers recently have focused on applications of data-mining techniques and machine learning algorithms, as well as their extensions to be appropriate for the real-time operations to handle the big data.
To realize the proposed approach by integrating the extended computation method and KNN, two kinds of nearest neighbor search should be carried out. The first one is the extraction of t-dimensional KNN, which searches a number of historical samples similar to the ongoing log by calculating t-dimensional Euclidean distance. The second one is the extraction of KNN for each assumed progress. Such complexity owing to several times of nearest neighbor search can be reduced by adopting approximate nearest neighbor search algorithms [21]. To search nearest neighbors, it is needed to calculate distances from all historical samples and sort out the results with distance. To reduce such operational overheads, the tree data structure is applied to the approximate NN search, in which the NN search space for the query point is restricted by organizing historical samples in advance. Different tree structures can be adopted according to historical distributions as well as their characteristics, such as KD tree and BBD tree. However, there exists the tradeoff between search time and accuracy, which should be considered sufficiently and evaluated based on experiment.
Issues on Performance. Fundamentally, for both of reactive and proactive warning strategies, the most important performance measure is accuracy. The proactive warning cannot help being less accurate than the reactive warning, because it is conducted based on the partial information at early stages of network connection. But, the practical performance should be considered by evaluating the costs incurred from type I and II errors. The reactive warning concerns the already occurring intrusion, but the proactive warning concerns the possible intrusion predicted upon the completion. Therefore, for false and missing warnings, their costs after errors can be different, respectively.
Another measure for the proactive warning strategy is the proactiveness, which means how many states are saved until the warning is provided before the actual completion. The final aim of the proactive warning is making sure the intrusion does not happen, rather than the notification of already occurring intrusion. If the implication about the possible occurrence of intrusion is provided earlier, the administrator can have time to keep an eye on the doubtful connection so as to block the access proactively or request additional certifications for connections. In the case of reactive warning, the proactiveness equals zero.
Issues on Maintenance. According to learning types and characteristics of dataset, data-mining techniques are divided into two groups: supervised and unsupervised techniques. The supervised technique, such as KNN, SVM, and decision tree, uses true target values, true result of each historical sample, in the training dataset in order to learn rules to separate samples by their target values. Thus, it aims to classify a new sample according to the target value, especially one of already known result types of normal or fault. The unsupervised technique, like clustering and local outlier factor, does not need any target values. Frequent patterns similar to each others are considered as normal and relatively infrequent patterns are considered as abnormal. Thanks to such characteristics, they are applied to the detection system in differentiated purposes so that the former corresponds to fault detection and the latter corresponds to outlier detection.
Fundamentally, the detection system using such techniques commonly needs update to reflect current properties in new samples by relearning the updated training dataset. In case of supervised learning, new types of faults that have not been observed in historical data are updated as new target values. In case of unsupervised learning, the scope of frequent patterns is updated by reflecting the frequencies of new samples. Thus, the proposed approach using KNN as the supervised technique also should be updated periodically to relearn current samples especially for new types of normal and fault data.
6. Conclusions
In this paper, we have proposed a novel approach to the real-time monitoring of ongoing network connection to predict eventualities before actual completion. To predict the final result based on partial data beforehand, we have formulated the sequential KNN voting approach with predetermined warning threshold. In order to demonstrate the real-time feature of proposed approach, experiments were conducted with KDD Cup dataset and the performance of proactive warning was examined. The real-time indicator, the estimated probability for possible result type, could predict the actual result type probabilistically before the completion of connection establishment. It can be used to block abnormal connections proactively rather than to wait until their actual completions. It is also helpful for administrators to understand the ongoing status of connection.
There still remain some future works to be done to enrich proposed approach. First, the proactive warning strategy needs to be improved for the determination of threshold value. It should incorporate cost and benefit analysis considering error types as well as proactiveness. Second, the performance can be improved by integrating with feature selection methods or approximate neighbor search algorithms. Finally, additional performance studies with latest traffic data can be worthwhile to verify the validity of proposed approach for specific application domains.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.