
Abstract
The semantics of UTop-k query is based on the possible world model, and the greatest challenge in processing UTop-k queries is the explosion of possible world space. In this direction, several optimized algorithms have been developed. However, uncertain databases are different in data distributions under different scoring functions, which has significant influence on the performance of the existing optimizing algorithms. In this paper, we propose two novel algorithms, MSSUTop-k and quick MSSUTop-k, for determining the minimum scan scope for UTop-k query processing. This work is important because before UTop-k query processing is started, users hope to know in advance how many and which tuples will be involved in UTop-k query processing. Then, they can make a balance between result precision and processing cost. So, it should be the prerequisite for answering UTop-k queries. MSSUTop-k can achieve accurate results but is relatively more costly in time complexity. Oppositely, quick MSSUTop-k can only achieve approximate results but performs better in time cost. We conduct comprehensive experiments to evaluate the performance of our proposed algorithms and analyze the relationship between the data distribution and the minimum scan scope of UTop-k queries.
1. Introduction
Sensor networks have widespread range of applications these days, such as industrial process monitoring and control, personal health monitoring, environmental monitoring, and moving object tracking. The view of sensor network as a distributed database and the sensor node as a table is being widely accepted by the database community. However, data readings collected from sensors are often inevitably imprecise, and thus they are called uncertain data in academic circles. The uncertainty in the sensed data can arise from multiple sources, including measurement errors due to sensing instruments, transmission delay, and discrete sampling of measurements. Therefore, it is necessary for the sensor database to record the imprecision and also to take it into account when the sensor data is processed. Handling the uncertainty in the data raises great challenges in almost all aspects of sensor data management.
UTop-k query is a crucial application in uncertain database and attracts a lot of attentions in academic circles. UTop-k query answer is a tuple vector with the maximum aggregated probability of being Top-k across all possible worlds. Let us take the uncertain databases in Table 1 as an example. Table 1(a) is a database storing the velocities of vehicles measured by radar. Each reading is associated with a confidence level associated with the corresponding measuring or statistic error. Exclusiveness rules are prior knowledge and are derived from the specific application. In this example, event
Example of uncertain databases and UTop-k results.
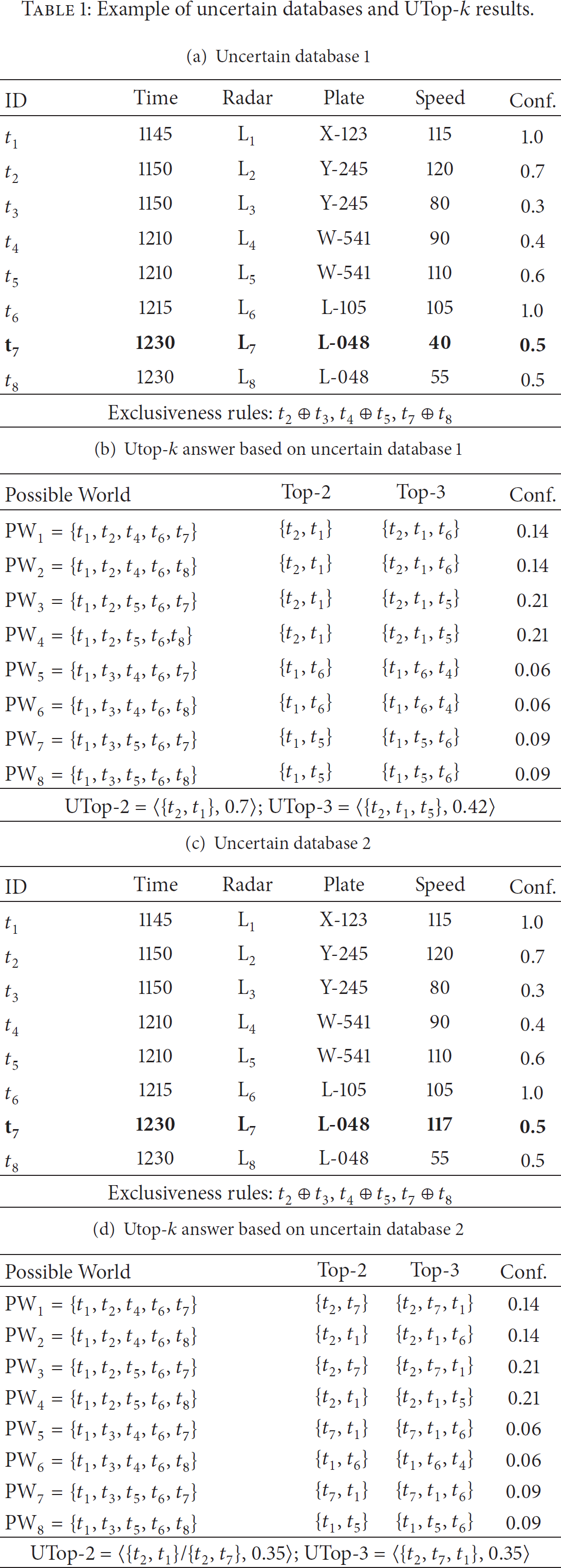
Given an uncertain database as Table 1(a), according to the definition of UTop-k [1], the UTop-2 answer is
Basically, we can use the naive algorithm to process UTop-k queries, in which the possible world space is comletely produced and then the aggregated probability of each UTop-k answer can be obtained. However, the naive algorithm is prohibitively expensive in space and time cost. Actually, in many cases we can achieve the Utop-k answers by reading part of the uncertain dataset. Let us examine the possible world space in Table 1(b). The UTop-2 answer candidates are
In this paper, we propose two different methods to determine scan scope of tuples for UTop-k query processing. According to the minimum scan scope for accurate result, users can make a balance between the result precision with processing time cost. Towards this end, our contributions are summarized as follows:
We propose our basic MSS4UTop-k algorithm for determining the minimum scan scope when UTop-k queries are handled. MSS4UTop-k can obtain the exact minimum scan scope. In order to promote the efficiency in scan scope determination, we study some special cases in uncertain dataset and propose the algorithm of Quick MSS4UTop-k. It enlarges the minimum scan scope but can perform better than MSS4UTop-k in time cost. We conducted an extensive experimental study on real uncertain dataset to test the performance of our algorithms. At the same time, we analyze the relationship between the data distribution and the minimum scan scope.
2. Problem Definitions
UTop-k semantics is based on the model of possible worlds [1]. Assume that there is a user-specified scoring function
Definition 1 (UTop-k query).
Let
Definition 2 (X-tuple bucket B).
X-tuple [2] bucket consists of one or more alternatives, where each alternative is a regular tuple exclusive to the others according to the exclusiveness rules derived from applications. Therefore, given an uncertain database
Tuples in uncertain dataset D can be divided into two categories: (1) tuples with probability 1, which is called deterministic tuples, and (2) tuples with probability less than 1. Tuples in the first category appear in all possible worlds deterministically, while those in the second category appear in some of possible worlds at their own probability. Furthermore, we can divide the tuples into subsets according to the exclusiveness rules. Each deterministic tuple compose a subset itself, and the mutually exclusive tuples are organized into one X-tuple bucket. Then, the uncertain dataset can also be denoted as
Definition 3 (UTop-k minimum scan scope
).
Given an uncertain database
Obviously,
In this paper, we aim at determining
3. Related Work
Top-k queries in deterministic database is always a hot topic in academia, and several efficient methods for optimizing Top-k queries have been proposed [3–5]. However, in recent years it is noticed that physical data is usually uncertain and/or fuzzy [6–11]. The marriage of Top-k and uncertain data starts a novel research issue: Top-k queries in uncertain database. There are several semantics of Top-k queries in uncertain database: UTop-k [1], U-kRanks [1], PT-k [12], PKTop-k [13], Expected Ranks [14, 15], and other recent research works in [16–20].
In this paper, we focus on the semantics of UTop-k. The work in [1] is the first to introduce the definition of UTop-k. It proposed the OptUTop-k framework for UTop-k processing as well. Its basic idea is based on the following two assumptions: (1) tuples in uncertain database is accessed one by one sequentially; that is, no random access is allowed; (2) the global exclusiveness rules are unknown in advance. OptUTop-k maintains a priority state queue which is ordered on probability. Then, it reads tuples one by one sequentially. Each time when a new tuple arrives, the top state in the priority state queue will be extended into two new states, with the newly seen tuple and without the newly seen tuple. By searching all possible states, OptUTop-k can obtain the most probable top-k answers.
Another important work in UTop-k processing is introduced in [21]. The basic idea in [21] is based on the following two assumptions: (1) tuples in uncertain dataset are ordered according to the scoring function; (2) the global exclusiveness rules are known in advance. Based on these two assumptions, the optimizing framework reads the tuples one by one in sequence of scores. Each time when a new tuple arrives, the possible world space will be produced based on all seen tuples. This procedure repeats until the scan depth is reached. Then, the Top-k candidate set in the possible worlds with the highest probability is the final UTop-k answer.
Our work in this paper is different from the two works above. Firstly, they are different in preconditions. Our work is based on the following two assumptions: (1) the global exclusiveness rules are known and (2) the whole uncertain dataset can be traversed in advance; that is, N is known. The justification for our first assumption is that the exclusiveness rules come from applications, and with the help of domain experts we can translate this prior knowledge into user-defined constraints in database at the very beginning. The justification for our second assumption is that uncertain data is usually stored in RDBMS, in which traversing a table is a common operation. Secondly, they are different in goals. The two works above aim at optimizing UTop-k processing. However, we view our work as a prerequisite step for UTop-k processing. We emphasize that before we start any optimized algorithm, we must determine the necessary scan scope in uncertain database for processing UTop-k query; that is, how many and which tuples are necessarily involved for query processing? It is important because in some cases all the uncertain tuples may be involved in answering UTop-k queries. In such scenarios, any effort seeking for precision results will lead to failure, and the approximate algorithms are the best (or say the only) choice.
Scoring function is another interesting research point in rank queries. Soliman et al. [22] notice that in many cases users cannot precisely specify their scoring functions, which means that in such scenarios the scoring function is uncertain or incomplete. This work is different from ours for two aspects: (1) they are different in data model. In the work of [22], data is determined, while the scoring function it is uncertain. Therefore, they model their data with traditional database (deterministic database). Oppositely, in our work, we assume that data gathered from application field is with uncertainty, while the scoring function is determined. Researchers are inclined to make use of probability database and possible world model to describe uncertain dataset. (2) They are different in query semantics. Soliman et al. set their focus on the “uncertain/incomplete scoring functions” in Top-k queries. The question is that “Can we adopt a score function with weight ranges and partially specified weight for different data sources to capture the preferences of users so as to give them a personalized Top-k result?”. Furthermore, they analyze the sensitivity of the computed order with respect to changes in weights. In our work, we aim at the semantic of UTop-k over uncertain data. The most challenging problem in processing UTop-k queries is the explosion of possible world space, which makes it unfeasible for its quite expensive cost in processing time. However, in our paper we demonstrate that in many cases not all tuples in uncertain database are necessarily involved in answering UTop-k queries. So, we set our goal to conclude that “which is the minimum necessary scan scope of tuples in uncertain data for UTop-k query processing?”. In summary, although these two works are both about “uncertainty” and “Top-k queries,” they are essentially different.
Besides, query result evaluation and data cleaning are always an attractive research problem in the field of uncertain data management. Given the data uncertainty, a query answer is inherently inexact. Paper [23] puts forward the measurement method of the ambiguity of the query results. If users are not satisfied with the quality of query answer, a cleaning process will be launched. Ideally, all X-tuples should be cleaned. However, this cleaning process is limited by power resource, bandwidth, budget, successfulness, and so on, which makes it an optimization problem for users. Xu et al. [24] set their focus on the problem of automatically selecting an extractive summary from entire set of objects as its representatives. Practically, objects may have multiple uncertain attributes. So, paper [24] proposes a general framework that models the information contained in objects and optimizes a probabilistic coverage property of the summary. Although all these works are based on uncertain data, their research point is not about the semantic and processing of UTop-k queries.
4. MSS4UTop-k Framework
In this section, we will introduce our algorithms to determine the minimum scan scope for UTop-k query processing in uncertain databases. In most cases, k is far less than N. It implies that some of, or maybe most of, tuples have no influence on any Top-k candidates. According to this basic idea, we believe that some of tuples in uncertain dataset can be safely pruned when UTop-k query is processed. Then, the remaining part is the minimum scan scope. The challenge is that how we can distinguish those “useless” tuples.
4.1. Phrases of MSS4UTop-k
MSS4UTop-k has three phrases: first, we traverse the uncertain dataset, group the tuples in
4.1.1. Initializing the Representative Tuple Set
First, as we mentioned in Section 2, we assign all the tuples in

When a UTop-k query is initiated, we first locate the kth element in
4.1.2. Extending the Representative Tuple Set
We start to traverse
Case 1.
We meet a deterministic tuple
Theorem 4.
Assume that
Proof.
Since
According to Theorem 4, a deterministic tuple

Case 2.
We meet a tuple with probability less than 1; that is,
In this case, the bucket
Case 2.1 (
Case 2.2 (
Extension Start Principle. If Extension Principle. Extension Stop Principle 1. If Extension Stop Principle 2. If, Extension Stop Principle 3. If, Extension Stop Principle 4. If the end of
Besides Cases 2.1 and 2.2, there are still another situation which is between the best one and the worst one, more than one tuple whose score is larger than
In the above cases, we listed all of the possible situations of

The extension of
4.1.3. Determine the Minimum Scan Scope
After being extended,
The uncertain dataset The parameter k; The reduced uncertain dataset (1) Initialize: (2) Re-organize (3) for (each (4) (5) (6) end for // (7) Sort (8) (9) (10) for ( (11) if ( (12) continue; (13) else (14) if ( (15) continue; (16) else (17) while ( (18) (19) if (Pr( (20) break; (21) else (22) if (( (23) break; (24) else (25) (26) end if (27) end if (28) end while (29) end if (30) end if (31) end for //the extended (32) for ( (33) (34) end for // (35)
4.1.4. Correctness
In this section, we will prove that the
Theorem 5.
Assume that the original uncertain dataset is
Proof.
Case 1 (

Case 2 (
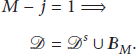

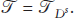

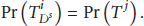
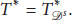
Case 3 (

In this section, we describe our basic MSS4UTop-k algorithm in detail. Considering the different features of original uncertain dataset, the efficiency of MSS4UTop-k varies. In next section, we will introduce a variation of the MSS4UTop-k algorithm, called Quick MSS4UTop-k. The goal of Quick MSS4UTop-k is to balance the accuracy of minimum scan scope and the efficiency of MSS4UTop-k.
4.2. The Quick MSS4UTop-k Algorithm
In the basic MSS4UTop-k algorithm, we traverse
Given a uncertain database
(i) Phrase 1 (determine
(ii) Phrase 2 (determine
(iii) Phrase 3 (determine
Compared with that in the basic MSS4UTop-k algorithm,
The uncertain dataset The parameter k; The reduced uncertain dataset (1) Initialize: (2) Re-organize (3) for (each (4) (5) (6) end for // (7) Sort (8) (9) (10) while ( (11) if ( (12) (13) end if (14) (15) (16) end while // (17) for ( (18) (19) end for // (20)
5. Experiments and Analysis
We built our framework on a 3.4-GHz Pentium IV PC with 8 GB main memory. Both the MSS4UTop-k and quick MSS4UTop-k algorithm are implemented in Java and based on the database MySQL5.5. We conducted extensive experiments for two goals: (1) to examine how data distribution and the parameter k affect the minimum scan scope for UTop-k processing; (2) to examine what the performance of the MSS4UTop-k and quick MSS4UTop-k algorithm in time consumption is.
5.1. Methodology
Data Set. Our experiment is based on the statistics that describes the driving profiles in expressway of thousands of drivers. It is derived from G15-Expressway Vehicle Speed Monitoring Database. G15 is 387 kilometers long totally, along which there are 13 vehicle speed measurement stations. Each of the measurement stations is equipped with speed detecting radar and HD cameras. When a vehicle passes by, its instant speeds as well as the license plate and timestamps will be recorded and transmitted back to the center database. The upper speed limit of G15 is 120 KM/h for small/medium-sized motor vehicles and 100 KM/h for large-sized vehicles.
Traffic insurance companies use the statistical data derived from the Expressway Vehicle Speed Monitoring Database to illustrate the driving profile of drivers. They group speed values of a car according to three predefined ranges: (1) ≥130 for small/medium-sized motors and ≥110 for large-sized vehicles. Speeds in this area mean an extremely dangerous driving behavior: (2) (120, 130) for small/medium-sized motors and (100, 110) for large-sized motors. Speeds in this area mean a dangerous driving behavior: (3) ≤120 for small/medium-sized motors and ≤100 for large motors. Speeds in this area mean a normal-driving behavior. So, given thirteen records of a car, the insurance company will calculate the average speed and frequency at each range; then they obtain a driver's driving profile. For example, Table 2 is the speed records of a car on G15. According to Table 2, the driver's profile is
An example of speed records.

We use the records on September 22, 2010, in our experiment. We choose the day of September 22, 2010, because the weather was nice and traffic was flowing smoothly on that day. Studies indicate that under these two conditions a driver's driving habit will not be influenced by other drivers. In addition, on G15 the shortest distance between two neighbored monitoring stations is 2.5 KM, which means that the thirteen speed records in dataset for each vehicle can be regarded as being independent. Actually, there were totally 53,717 vehicles that ever ran on G15 on September 22, 2010. We picked out 4823 vehicles of them according to the following two principles: (1) Each vehicle must finish a complete single trip on G15 and (2) its thirteen licence plate photos must be clear enough to be accurately recognized. Next, We use the speed records of these 4823 vehicles to generate the statistical data of driver's driving profile, as depicted in Table 3.
Description of experiment data.
The subdataset
Methods and Evaluation Metrics. From the detailed description in Section 4, we can see that data distribution and the value of k are the two key metrics for determining the minimum scan scope for UTop-k queries. So, we test our proposed algorithm MSS4UTop-k and quick MSS4UTop-k in this paper on various datasets with different data distributions: (1) pure uncertain dataset, which is totally composed of uncertain data, and (2) mixed uncertain dataset, which is composed of uncertain data and deterministic tuples. In each of our experiments, we describe the data distribution first. Then, we measure the ratio of the minimum scan scope to the whole dataset; that is,
5.2. Experiment Results
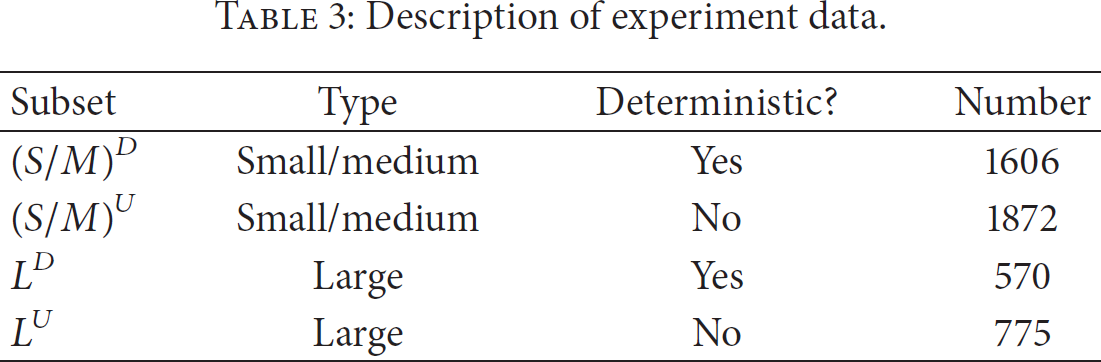
5.2.1. Pure Uncertain Dataset:
We combine the subdatasets

Data distribution, minimum scan scope, and time cost of MSSUTop-k and quick MSSUTop-k on pure uncertain dataset.
Result Analysis. Theoretically, the scenario in Figure 4(a) is the worst case because a large amount of tuples will be involved in Top-k query processing, even if the value of k is very small. This is proved in Figure 4(b). For example, when
5.2.2. Mixed Dataset 1:
We conducted our second experiment on the mixed uncertain dataset

Data distribution, minimum scan scope, and time cost of MSSUTop-k and quick MSSUTop-k on mixed uncertain dataset 1.
Result Analysis. When k is small, this scenario is the same as scenario 1; that is,
5.2.3. Mixed Dataset 2:
In our third experiment we employ another mixed dataset
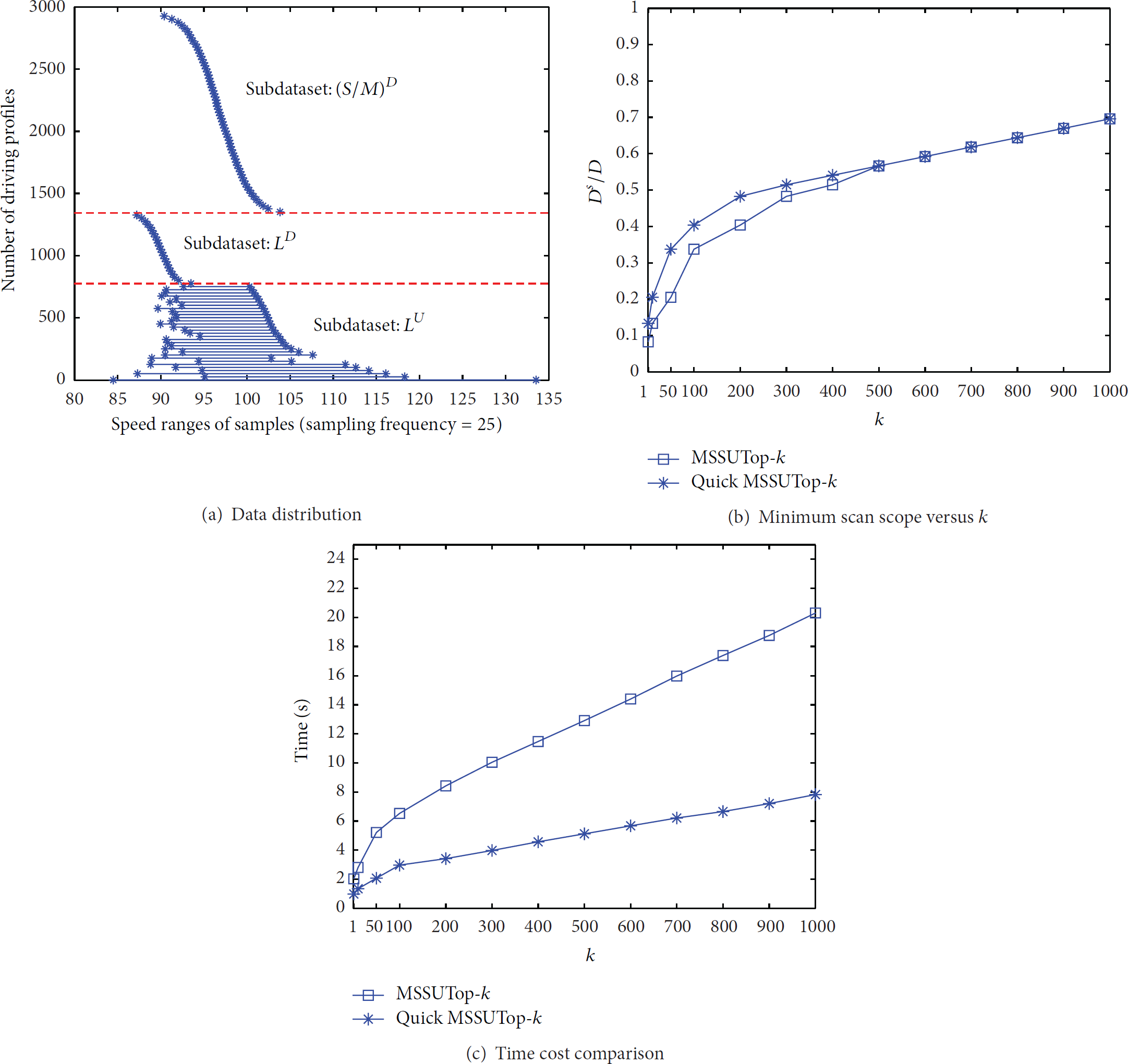
Data distribution, minimum scan scope, and time cost of MSSUTop-k and quick MSSUTop-k on mixed uncertain dataset 2.
Result Analysis. Theoretically, there will be fewer tuples to be involved in UTop-k query processing in this case. The reason is when the deterministic tuples disseminates in the uncertain tuples, the Extension Stop Principle 1 is more inclined to be satisfied. It is proved by Figure 6(b). Initially, when k is small, the Extension Stop Principles 1, 2, and 3 are all valid. So, the ratio of minimum scan scope to the whole dataset is quite smaller than that of the other two cases above. When
5.2.4. Other Scenarios
Actually, there are
6. Conclusions
In this paper, we introduce two novel algorithms MSSUTop-k and quick MSSUTop-k for determining the minimum scan scope of UTop-k queries in uncertain databases. We test the performance of the proposed algorithms through extensive experiments based on real dataset. In addition, by analyzing the relationship between the minimum scan scope for processing UTop-k queries and the data distribution of various of uncertain dataset, we know that the ratio of minimum scan scope to the whole uncertain dataset varies dramatically because of different data distribution. It demonstrates that this work should be the indispensable prerequisite for UTop-k processing. By the work in this paper, given a uncertain dataset and k, users can determine exactly in advance how many tuples and which tuples will be involved for processing UTop-k queries. Then, they can make a balance between the result precision and processing cost and then choose a proper optimized solution according to the computing resources they have.
Footnotes
Notations
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This research is supported by the National Natural Science Foundation of China under Grant no. 61173027 and the Fundamental Research Funds for the Central Universities (N140404006).