
Abstract
Most of the mobile phones have GPS sensors which make location based service (LBS) applicable. LBS brings not only convenience but also location privacy leak to us. Achieving anonymity and sending private queries are two main privacy-preserving courses in LBS. A novel location privacy-preserving method is proposed based on Voronoi graph partition on road networks. Firstly, based on the prediction of a user's moving direction, a cooperative k-anonymity method is proposed without constructing cloaking regions which may lead to efficiency decline in continuous query. And then, a query algorithm is proposed without providing any user's actual location, replaced by continuous anchor sequence, to LBS provider. This algorithm can work out precise results according to candidate sets returned by LBS provider and it also solves uneven distribution problem in SpaceTwist. Performance analysis and experiments show that our method achieves a preferable tradeoff between QoS and location privacy preserving; it has obvious advantages compared with other methods.
1. Introduction
Nowadays, GPS sensors are available on many smart phones, which can report accurate location of a user, and location based service (LBS) has been widely used. Query service for places of interests (PoIs) based on a user's location is one of the most frequently used service types in LBS, such as nearest neighbor queries and range queries. Typical query is “get K nearest restaurants around me” and “get all restaurants within the scope of R kilometers,” respectively. And a user may send a snapshot or a continuous query request [1] according to his current moving condition. For all these query methods ask a user to provide his actual locations before getting query service. But it leads to a deep-going privacy exposure as the location data is leaked due to the correlation between location information and user's identity, hobbies, home address, and other privacy data. The location privacy must be protected effectively in the process of LBS.
There are 3 kinds of privacy in LBS, location privacy, query privacy [2–5], and identity privacy [6]; we focus on location privacy preserving. How to cloak a user's location has been widely studied [7–13] and most of them choose a central server to achieve k-anonymity for users. The architecture of location privacy preserving in LBS is central or centerless. In Figure 1, the centerless architecture has two kinds of entities: users and LBS providers (LSP), but in this architecture privacy-preserving burden is heavy at the user end. The central architecture is added with a central server (CS) providing stronger privacy-preserving methods. Location k-anonymity normally adopts the latter architecture to construct cloaking regions at CS end, as shown in Figures 1 and 2, a user sends his actual location to a CS, and the anonymity module of CS obscures the location before sending the query to LSP; the untrusted LSP cannot get any user's precise location. But constructing cloaking regions for each user causes lots of burden and low success rate of anonymity when CS confronts with a large number of anonymity requests.

A central/centerless architecture.

Continuous cloaking regions.
In view of that defect, Chow et al. [14] have proposed P2P cooperative anonymity method without CS. In that method, the head node which comes from users organizes other users to form an anonymity group without constructing any cloaking region. It is a simple structure but too much burden for a user to be a head node, and the users’ credibility is hard to guarantee.
However, using snapshot cloaking region is not security in continuous query because adversaries are supposed to get the distribution of users and cloaking regions all the time, so when a user constructs continuous cloaking regions for a user, as shown by the solid line rectangles in Figures 2(a)–2(c), the intersection A of three regions is the actual user using anonymity service. To solve this problem, researchers have proposed lots of methods for continuous query [15–24], such as constructing continuous minimum cloaking regions [15–17], as shown by the dash line rectangles in Figure 2.
But constructing continuous regions needs to find neighbor users who have similar moving trend and makes sure most of them will not depart from the cloaking regions. That increases the difficulty of constructing and has a side effect which restricts the users in a small specified region. Query with these regions requires processing function of imprecise coordinates at server end, too. Moreover, most of these methods are based on Euclidean space, not based on the actual road networks.
There are other protecting methods, such as dummies [25, 26], using pseudo locations instead of actual location. These methods have the defects of imprecise query results or too much overhead. Lung Yiu et al. [27] have proposed SpaceTwist which gets candidate sets of PoIs from LSP. SpaceTwist achieves comparatively accurate query result. Gong et al. [28] and Huang et al. [29] have, respectively, improved SpaceTwist. We also consult SpaceTwist to make it applicable for continuous query with an anchor sequence. The main contributions and innovations of this paper are as follows.
Considering the defects of constructing continuous cloaking regions, we propose a location privacy-preserving method without any cloaking region. We use Voronoi graph partition for the first time to divide road networks into cells, which facilitates the prediction of a user's moving direction, and a user's registration algorithm to CS is proposed with the help of Voronoi partition. When a mobile user registers to a CS, he has a high accuracy to an appropriate one. After registration, a cooperative anonymity algorithm at CS end is proposed. This algorithm satisfies each user's k-anonymity degree.
We propose an accurate query algorithm, which is called Singoes running on CS, without providing any user's actual location to LSP. Singoes takes fixed anchors between two cells to replace the user's actual locations in continuous query and get precise query results using anchors. According to the returned candidate PoIs from LSP, Singoes deduces precise results by expanding demand space again. This algorithm also solves the problem of PoIs uneven distribution in SpaceTwist. As we know, we have found the problem for the first time.
2. Related Work
In order to provide strong location privacy preservation at the data generated end, Gruteser and Grunwald [7] have proposed k-anonymity to obscure a user's actual location. After that lots of location privacy-preserving works have been presented [8–14, 24], Chow et al. [10] and Li and Zhu [13] have proposed partition method for cloaking region, and Xue et al. [2] have proposed cloaking region constructing method in road networks, which is appropriate for practical situation. Chow et al. [14] have proposed a P2P cloaking algorithm without a CS. We take these ideas as a reference in this paper.
The above researches were proposed in a static situation; Dewri et al. [17] make a formal analysis on the privacy leaking problems in continuous LBS, which points out that the static protecting method is not appropriate for mobile situation. Now most works are caring about dynamic privacy preserving. Pan et al. [15] take users’ moving speed and direction as affecting factors and a distortion function is defined to measure the temporal query distortion of a cluster in continuous queries, and they also have proposed a method which maintains maximal cliques to deal with location-dependent attacks [16]. Lee et al. [18] have proposed a grid-based cloaking region creation scheme for continuous LBS, and Wang et al. [19] consider the similarity of velocity and acceleration as factors to construct cloaking regions. Pingley et al. [23] use dummies to protect privacy in continuous query; this method does not need a trust third party. Hashem et al. [20] have presented a mobile K nearest neighbor query against overlapping rectangle attack in continuous query. In road networks, Palanisamy et al. [21] and Yang et al. [24] have proposed location protecting methods in continuous query, which have more practical significance.
In the aspect of using dummies to achieve privacy preserving, Hong and Landay [25] use a significant object to replace a user's location, but the query result is not accurate enough. Reference [26] sends several dummies accompanied with actual location to LSP to get query results, which brings extra burden to LSP. Based on these researches, Lung Yiu et al. [27] have proposed SpaceTwist running on user side, LSP performs INN (Incremental Nearest Neighbor) searching process for PoIs and returns the candidate sets to the user, and the user works out the accurate results himself. But SpaceTwist has not achieved k-anonymity, so Gong et al. [28] and Huang et al. [29] have proposed improved methods. And there is still an issue in SpaceTwist which can be improved.
As shown in Figure 3, we cite the figure of SpaceTwist to specify the issue that can be improved. There are 3 courses in SpaceTwist, a user staying at q takes
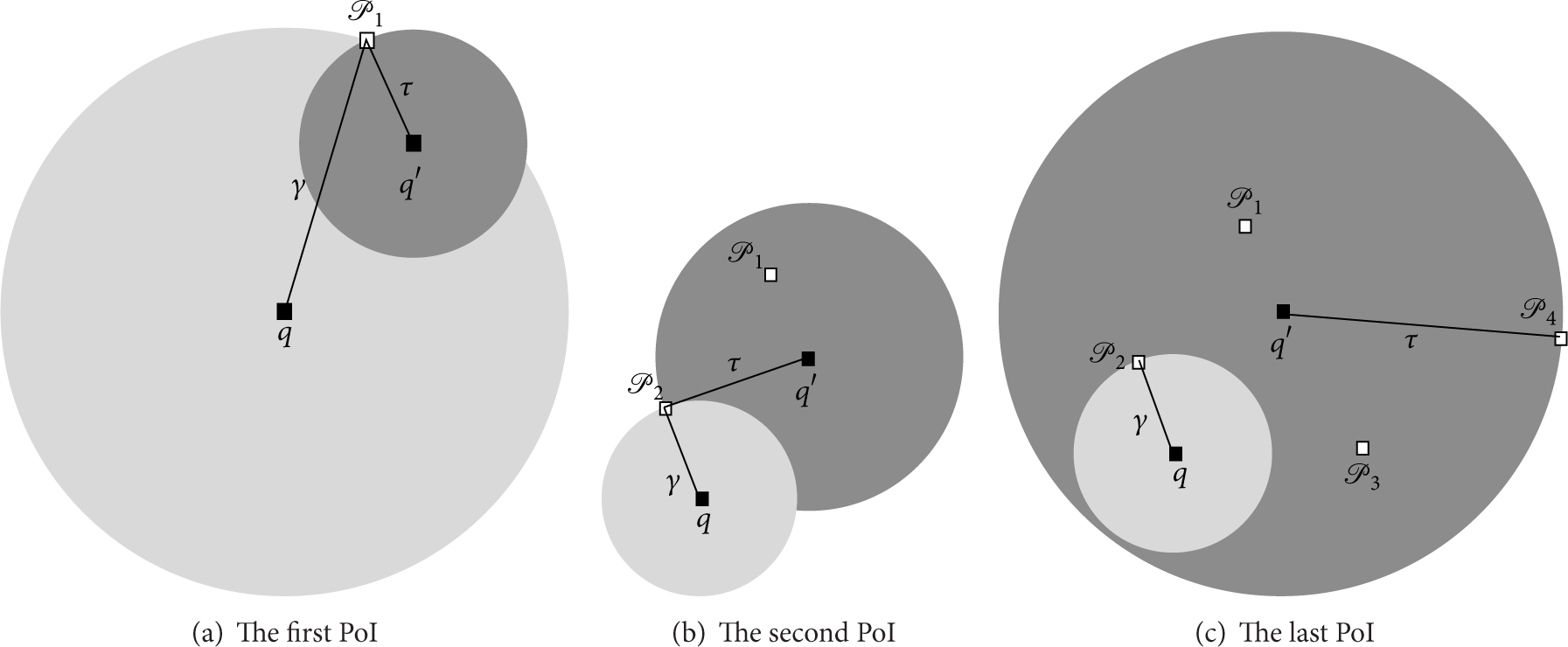
Query processing instance [27].
The above process has a problem called PoIs uneven distribution. After
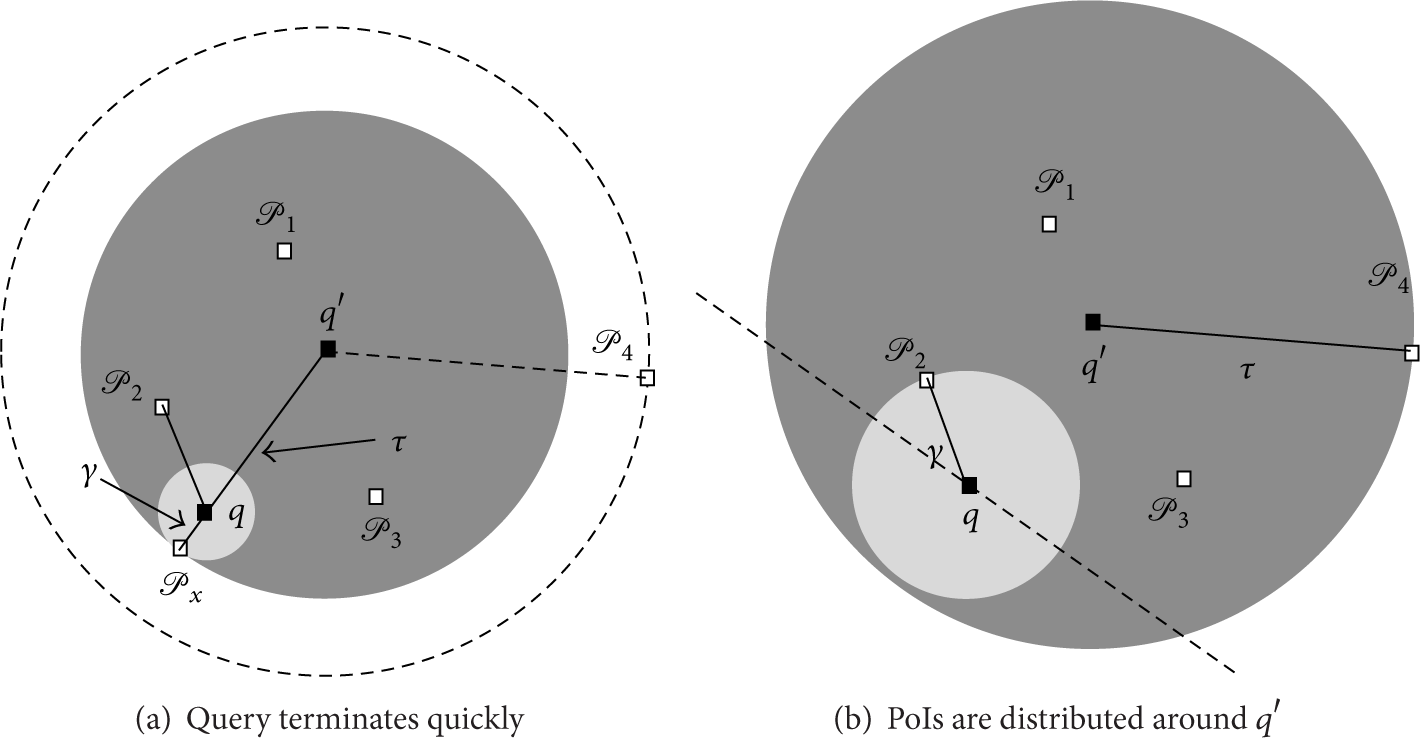
Uneven distribution problem.
3. Relevant Knowledge
In this section, we will introduce system structure, cooperative k-anonymity, and road network partition based on Voronoi graph.
3.1. System Structure
The structure of privacy-preserving method contains three parts: as shown in Figure 5, a mobile user is denoted as
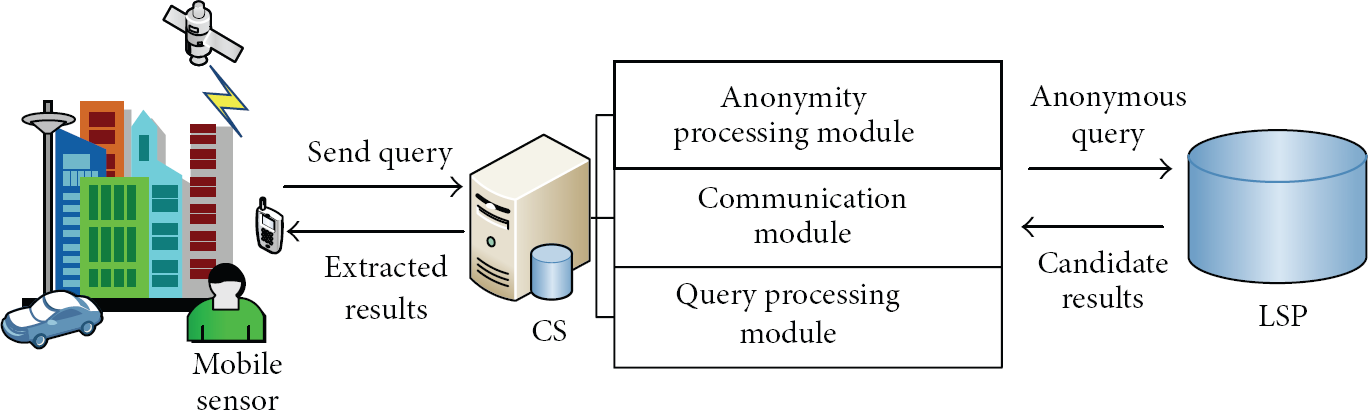
System structure.
There are also adversaries who aim to find a user's actual location and a correlation between a user identifier and a query request. We suppose that an adversary has three abilities:
3.2. The Concept of Cooperative Anonymity
Anonymity method can be divided into single anonymity and cooperative anonymity; for example, constructing cloaking regions for each user is single anonymity, and cooperative anonymity is different users sharing one cloaking region. The sharing idea decreases CS's burden. In this paper, we do not construct cloaking regions but organize users to form a cooperative anonymous group just like a P2P anonymous group [14, 29]. But the P2P cooperative method has to select a user as a cluster head, which is not suitable for energy constrained mobile users. So we modify this method and add powerful CS to organize users in its cell to achieve cooperative k-anonymity. Cooperative k-anonymity in this paper should meet the following two criterions.
Each user belongs to a sole cooperative group.
A cooperative k-anonymity group meets any user's k-anonymity degree.
3.3. Road Network Division Based on Voronoi Graph Partition
Voronoi graph [30] is a geometry of flat space; as shown in Figure 6, it is a way of dividing space into a number of regions. A set of spots is specified beforehand and for each spot there will be a corresponding region consisting of all points closer to that spot than to any other. One way is connecting all CSs around CS1 with dash line segments and doing perpendicular bisectors to all these line segments. The polygon with connected bisectors is a Voronoi cell.

Voronoi graph partition.
Similarly, we choose places to deploy central servers (CSs); the deployment follows 3 criterions.
A CS is deployed in crowded and traffic convenient places, which insures a lot of users in its cell avoiding constrained space identity attack. Users help CS to transmit messages.
The distance between neighbor CSs meets
The connected paths of neighbor cells are not less than a threshold
After a certain density deployment of CSs, we divide the entire area Ω using Voronoi graph partition into many cells centered with different CSs. Each cell is used to achieve cooperative anonymity. The Voronoi graph partition is defined as follows.
Definition 1 (Voronoi graph partition).
The spots of
The whole city area can be denoted as
4. Cooperative Anonymity and Continuous Query with Anchors
There are 3 phases in our method: initialization phase, cooperative k-anonymity phase, and continuous query PoIs with anchors phase. After initialization phase, a user registers to a CS and sends his request of joining in a cooperative anonymous group, CS organizes k users to form a cooperative k-anonymity group according to their moving trends and sends k queries to LSP, a user's identity is removed, and his actual location is replaced by continuous anchors in the query procedure. After registration, a user should report his latest locations to a CS periodically to achieve continuous query until he gets in a new cell or finished a query. In query phase, the CS takes its own location and a neighbor CS location which the user is heading to as two elementary anchors and chooses other continuous anchors in the line segment between them. Then CS sends each snapshot query of continuous query request with an anchor which the user has not passed yet. In a snapshot query, CS performs algorithm Singoes to compute results for a user according to candidate sets returned from LSP.
4.1. Initialization Phase
A Trust Authority (TA) picks appropriate CSs’ deploying locations according to the 3 criterions and generates Voronoi graph partition cells. Then TA sends road segments and neighbor CSs situation of each cell to the corresponding CS; the details will be discussed in Section 4.2. Any CS can verify validity of a user's pseudonym [31].
A

Repartition of a cell.

Road networks Voronoi graph.
Definition 2 (repartition of a cell).
If a user's location meets
As shown in Figure 7, a user in a convinced region of a cell is certainly in the cell, such as C, and in an excluding region, the user is certainly not in the cell, such as D, and in an unconvinced region, a user has both situations, such as A and B.
4.2. Registration and Cooperative k-Anonymity Phase
In road networks, registration and anonymity are affected by user's moving direction, so we specify a cell prediction method first.
4.2.1. Road Networks Voronoi Graph Partition
Direction prediction is important to all the following procedures. We consider a user is in restrained road networks; his moving direction is affected by roads. The Voronoi graph partition is on the road networks, as shown in Figure 8. In initialization phase, TA marks all the roads with numbers according to its sole actual road name, the same road may go through several cells, and the roads are directed connected graph and form road networks. Then TA sends two tables to every corresponding CS,
Definition 3 (Tablecsi1).
The road segments table is denoted as
As shown in Figure 8, in a cell
Definition 4 (Tablecsi2).
All the neighbor CSs of a cell are in
As shown in Figure 8, a neighbor
The correlation of
4.2.2. Next Neighbor Cell Prediction
Although there are roads constraints, a user always chooses the paths which most of its road segments approximately point to his destination, or else the user will not get to his destination. And most of his history velocity vectors, constrained by the roads, have the same feature. CS uses Formula (1) to predict the weights of each neighbor cell for a user according to his registering message

After the registration for a user, CS checks the road number which the user travels on by reverse geocoding techniques and computes
The prediction result also affects the anchors selection in continuous query. It also can be used to plan routes for users. The connecting paths of next cell are deduced by Definitions 3 and 4; CS can select the best one for a user according to path length and road congestion situation.
4.2.3. User Registration
A user will receive several neighbor CSs broadcasting messages
As shown in Figure 7, according to repartition,
(1) (2) (3) (4) time, old messages (5) compute (6) (7) discard all the other messages (8) (9) discard (10) (11) compute (12) (13) register to (14) (15)
Algorithm 1 is only suitable to static or slow users, but when a user moves quickly, such as B in Figure 8, if he moves upward of the figure and registers to
(1) (2) (3) (4) (5) compute (6) (7) discard all the other messages (8) (9) discard (10) (11) (12) (13) compute moving direction and from (14) (15) discard (16) // prediction results from CS he had just registered to, referring to Section 4.2 (17) compute // are 0.6 and 0.4 respectively (18) (19) (20) (21) compute (22) (23) register to (24) (25)
After successful registration to a CS, a user will report his latest locations periodically to the CS and drop broadcasting message from it until the user gets out of the cell or registers to next cell. If a user is in an unconvinced region, he has a probability to enter into a neighbor cell, so prediction to the next cell is significant; the prediction has two factors, as shown in Line 17: one is the current moving direction of the user himself, the other one is cell prediction results from CS he had just registered to, referring to Formula (1), and the former one we have not discussed yet, and it is a little complicated that we divide it into 3 cases.

Mobile user's current direction estimation.
In conclusion, only the users in an unconvinced region need to predict next cell by computing
4.2.4. Cooperative Anonymity Algorithm
After receiving registrations from users, CS organizes them to form several cooperative k-anonymity groups which meet each member's k-anonymity degree in a group. As discussed before, cooperative k-anonymity is just like the way P2P achieves anonymity, and the function of cluster head is undertaken by a CS. As shown in Algorithm 3,
(1) according to Formula (1), (2) (3) (4) (5) (6) whose anonymity degree meets (7) (8) (9) (10) (11) (12)
In Algorithm 3, Lines 3–5 pick users who have the same next neighbor cell to form the group; Lines 6 and 9 make the constructed group satisfy each user's anonymity degree. The combination in Line 10 guarantees quality of anonymity service. After successful anonymity, CS removes users’ identities and sends the group of queries to LSP with continuous anchors instead of any user's actual location. An item of query is denoted as
4.3. Query Phase
4.3.1. Anchor Picking
When a user has gotten out of one cell he will enter into another cell inevitably. Therefore, a user picks anchors according to the cell prediction result in continuous query. The anchor sequence is generated by two elements: one is the location of

An anchor sequence with three anchors for
4.3.2. Query Algorithm
CS picks an anchor from anchor sequence to replace user's location and send a snapshot query of a continuous query request [23]. The anchor is the one which the user has not passed in his anchor sequence. So CS asks a registered user to report his latest location in a continuous query procedure. When LSP receives a query, it uses the anchor to perform an INN search. After candidate results are returned from LSP, CS uses Algorithm 4 to work out each snapshot query result which is precise KNN PoIs to a user. We propose Algorithm 4 at CS end consulting SpaceTwist, but SpaceTwist has the uneven distribution problem we have specified in Section 2. We will solve this problem to make PoI results distribute around a user but not around the anchor. We call Algorithm 4 the “Singeos.”
(1) (2) the anchor sequence (3) the registered central server generates a min heap (4) insert K pairs of query into (5) // initialize radius of demand space (6) (7) Send INN search request to LSP with anchor (8) (9) PoIs from LSP (10) (11) (12) (13) update (14) // expand demand space and don't change (15) (16) PoIs from LSP (17) (18) (19) update (20) terminate INN search request (21) (22)
As proposed in [27], SpaceTwist terminates when supply space covers the demand space, as shown in Figures 3(c) and 4(a). That is why the PoIs are around anchor
As shown in Figure 3(c), when

K nearest neighbor PoIs query for a user.
After finishing a snapshot query with an anchor, the other PoIs will not be discarded, because the user may get closer to these PoIs in next snapshot query of the same continuous query request with anchor sequence. As shown in Figure 10(c), because a snapshot anchor is always picked in front of user, when a user is at q and heading to anchor
4.3.3. Brief Summary
The procedure of our method is as follows.
After initialization, a user who has LBS query request registers to a CS according to his current location and cell prediction results from previous CS. If he registers to a CS for the first time, he will use Algorithm 1 to achieve registration. Then CS predicts the next cell for him according to his history velocity vectors and current direction; CS also returns the prediction results to the user to help him achieve next cell registration. After registration the user should report his latest location and CS constructs a cooperative k-anonymity group for users, and then CS sends a group of queries to LSP with anchors. Each anchor for a user is generated according to the CS locations of his current cell and next cell. At last, CS performs Singoes to compute KNN PoIs for the user according to PoIs candidate sets returned from LSP. For each snapshot query belonging to a continuous query request, CS always picks an anchor in front of the user to ensure the query quality according to Singoes.
4.4. Performance Analysis
4.4.1. Analysis of Anonymity Procedure
Accuracy of Prediction and Registration. Cell prediction is affected by a user's history velocity vector and the current direction. A user always chooses a path in which most of its road segments approximately point to his destination; otherwise the user will not get to his destination. And most of his history velocity vectors, constrained by the road, have the same feature. Since CS's neighbor cells are not many, the direction range of each neighbor cell around the user is obvious; prediction with angular separation has a high success rate. According to Algorithm 2, only the user who is in an unconvinced region needs to predict his next cell, and the prediction has a high success rate. It is a rare event that the user changes his direction in an unconvinced region since the road constraints. According to criterion
Success Rate of Cooperative k-Anonymity. CSs are picked in crowed locations around by lots of users. After Voronoi partition, global map with U users uniform distribution is divided into b cells, each cell containing about
Anonymity and Query Security. Suppose users are distributed uniformly; if an adversary knows n users distribution in a cell, a user will be identified with a probability

Our method does not utilize cloaking regions so there are no overlapping region attacks. A trusted CS provides anonymity of each query from the same user, and most of the users in a cooperative anonymous group querying with anchors only indicate that these users have passed the cell. An adversary cannot know any user's actual location or the correlation with any query. The m queries from the same user are mutual independence, so the information entropy of a continuous query is
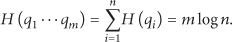
So our method achieves a less information release which increases an adversary's uncertainty.
Deployment Cost. Constructing a Voronoi graph depends on a large number of CS deployments, which brings cost increasing. That is a defect of our method. But comparing with mobile communication base station whose deployment generally follows shouting distance about 1000 m, our method is acceptable. Distribution service from CSs helps to reduce service bottleneck. And CS can be embedded and maintained as a part of communication base station.
4.4.2. Analysis of Query Procedure
Query Efficiency. Suppose PoIs are randomly distributed on a 2-dimensional space; CS can obtain K PoIs if it searches a circle no more than a radius of γ, so PoIs on a unit area can be computed as

The fewer PoIs in
Query Accuracy. CS uses a user's actual location to work out KNN PoIs according to returned candidate sets; in Singoes Line 14, demand space expands again and keeps it radius γ unchanged, and demand space covers K PoIs at least that time, so even if there are no other PoIs found in the following procedure, K PoIs in the demand space can be found in 100% success rate, which guarantees finding KNN results around a user.
Fixed Anchor. There are many ways to generate anchors; most of them are generated randomly and temporarily. But the anchor sequence in our method is generated only by two neighbor CSs, and other anchors are restrained on the line segments between them; the anchors are not many since the user is moving fast from one cell to another, so the anchors are picked from the integer division points of the line segment; most users may use the same anchor in the anchor sequence, so the anchor is nearly fixed. And the advantages of fixed anchor are as follows.
An anchor which is related to a CS's location is near to users; it guarantees a high efficiency of continuous query as we have just discussed.
Different users pick the same fixed anchors and make adversaries confused; it is much more difficult for them to relate a query with a user.
Fixed anchor queries are sent to LSP; LSP can use cache to store same queries with fixed anchors, which decreases searching database operations compared with random anchors.
5. Experiments
We discuss 4 main metrics in LBS: anonymity success rate, average response time, data traffic, and accuracy of query results. And the affecting factors of metrics are users amount U, user's anonymity degree k, and PoIs number K. The experiments run on different data sets. Comparative experiments of anonymity and query followed.
5.1. Environment Preferences
Simulation experiment is running on Windows 7, CPU is 3.5 GHz Intel Core i7 processor, and RAM is 16 GB. The algorithms are written by Java. We use two data sets, one is a real data set from BGN (http://geonames.usgs.gov/index.html), denoted as GDS, and it includes 169553 PoIs. The other one is simulated data set (http://iapg.jade-hs.de/personen/brinkhoff/generator/), denoted as TBS, and this data set is generated by widely used Thomas Brinkhoff Generator which is based on road networks of Oldenburg in Germany; it generates a city area about 24 km × 27 km. The bandwidth between CS and users is 3 Mbps. CS gets a data package of 128 bytes from LSP each time. Removing 40 bytes package head, if a PoI costs 8 bytes, a package contains at most
Parameters and defaults.

5.2. Experiments on Different Data Sets
We estimate anonymity success rate, average response time, average packages amount, and accuracy of query results as the number of LBS users increasing on dataset GDS and TBS. Anonymity success rate is the ratio of users achieving anonymity and all LBS users. Response time is the time cost during anonymity and query PoIs, packages amount is sending and receiving packages during response time, and accuracy of query results is the rate of precise PoIs in a KNN query result and K; that is, if 10 NN query results are PoIs of
As shown in Figures 11-12, as LBS users are increasing, anonymity success rate is gradually increasing, maintaining ratios more than 80%, and users achieve anonymity effectively and timely. The average response time declines gradually in Figure 12; there are more messages to deal with when confronting with more users; the average response time would have increased, but CS does not construct cloaking regions, and more users make CS facilitated to form cooperative anonymity groups quickly and the PoIs are quickly found with fixed anchors in LSP's cache; therefore the average response time declines and keeps stable at 0.3 seconds.
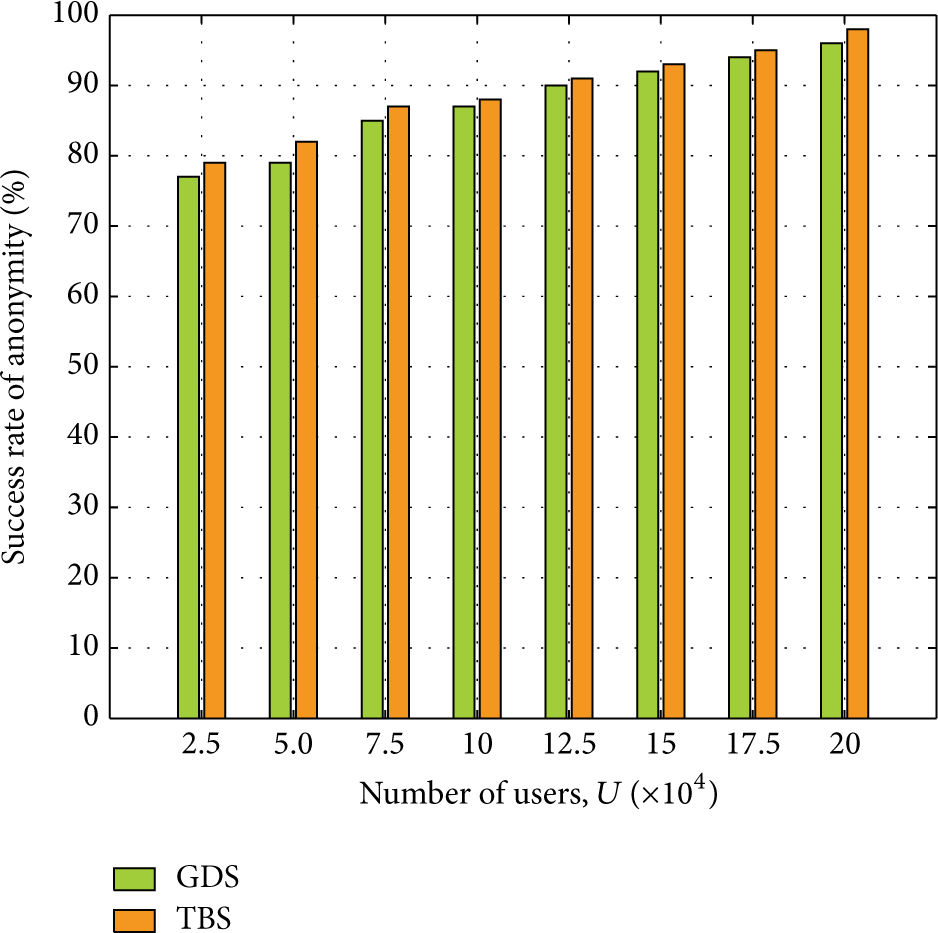
Success rate of anonymity.

Average response time.
As shown in Figure 13, although packages increase as the number of users increases, average packages maintain stable, because users achieve anonymity by forming anonymity groups instead of constructing continuous cloaking regions; most of them send the request once in a cell until they get out. In the other hand, packages of query for PoIs are increasing, because Singoes needs to search more area via LSP to get KNN PoIs to a user, and the communication between CS and users increases more, as shown in Figure 14.

Average packages of anonymity.

Average packages of query.
As shown in Figure 15, the accuracy of query result maintains steady. That is because Algorithm Singoes guarantees the demand space covers K PoIs in the second expansion and the radius of demand space keeps unchanged; then LSP gradually returns candidate PoIs to Singoes; when the supply space covers the demand space, the searching procedure terminates. Due to the reliability of LSP, all the PoIs which a user queries for are found in the unchanged demand space, so it is easy for Singoes to find the precise K nearest neighbor PoIs in the candidate set around the user who is the center of the demand space.
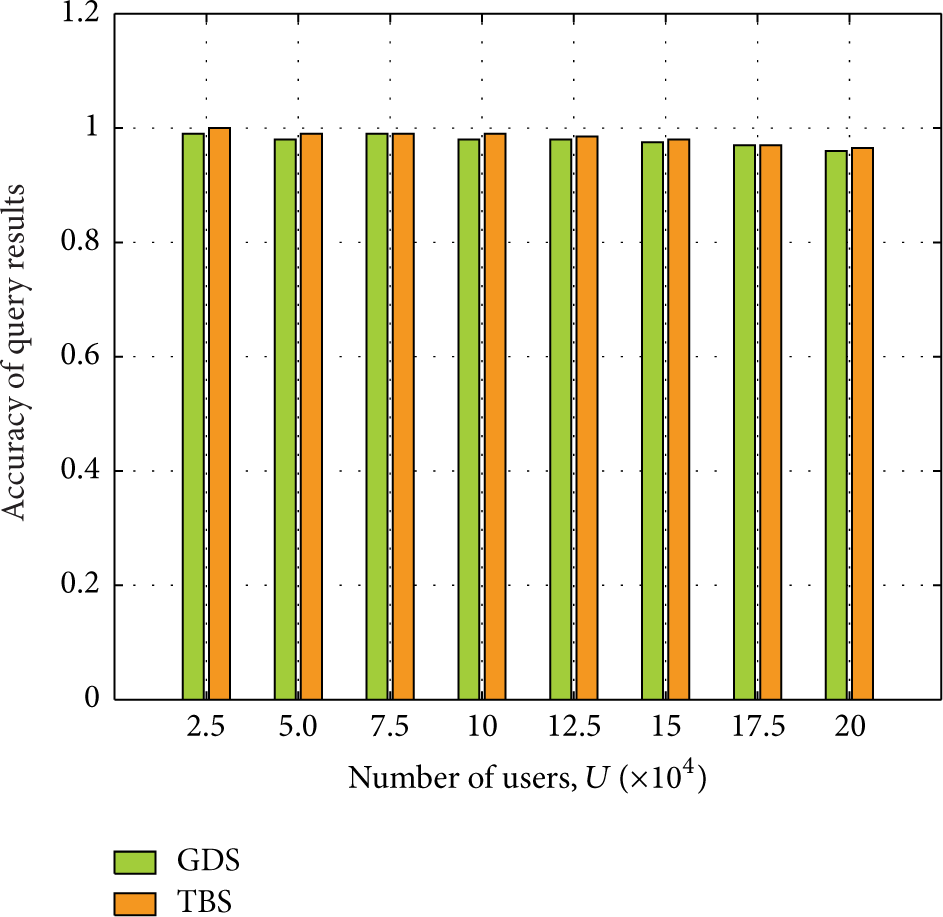
Accuracy of query results.
5.3. Comparative Experiments of Anonymity
The comparative experiments are carried out on simulation dataset TBS. Firstly, we compare Casper

Average packages of anonymity as U is increasing,
Large anonymity degree of users means more users are needed to achieve k-anonymity; as shown in Figure 17, packages are increasing as k becomes larger. The packages of our method are less than the other two, because CS organizes k registered users to form anonymous groups in low communications. But the success rate of anonymity will decline as k is increasing. From Figures 16-17, we conclude that average packages of our method will maintain stable even if U and k vary.
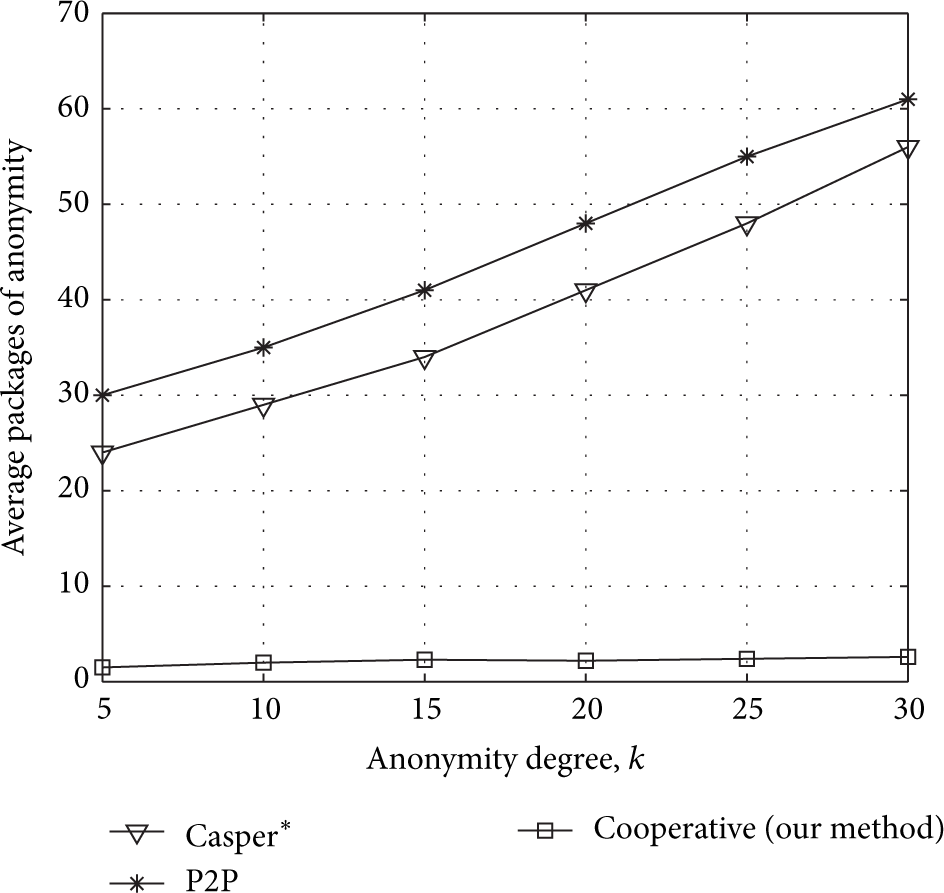
Average packages of anonymity as k is increasing,
5.4. Comparative Experiments of Query
We compare SpaceTwist [27], PrivacyGrid [32], P2P [14] with our query algorithm Singoes in the query procedure. SpaceTwist and our method both use anchors to query for PoIs. But Singoes uses fixed anchors in every snapshot of the same continuous query request. SpaceTwist runs on user end; Singoes runs on CS. The other two methods PrivacyGrid and P2P query for PoIs both with cloaking regions.
Figure 18 shows that the average packages of query will increase in two algorithms, because both of them have to search more area, which have to return more PoI candidate sets. And in Figure 19, PrivacyGrid has similar packages communication when U is less than 100 thousand, and Singoes's communication cost is lower than it when U is growing larger. P2P has more packages increasement than the other two methods, because the cluster head has to transmit PoIs to each user when U is growing larger.
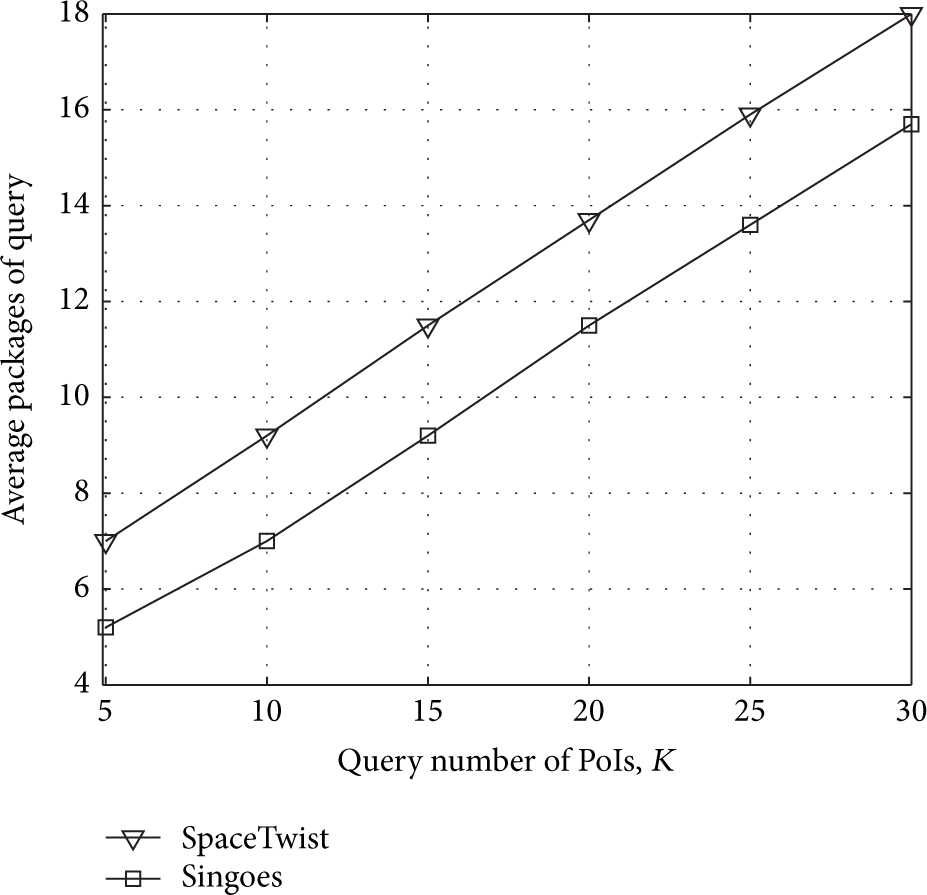
Average packages of query, compared with SpaceTwist.

Average packages of query, compared with PrivacyGrid and P2P.
In continuous query, Singoes does not discard returned PoIs which are filtered once in KNN query; most of these PoIs in front of the user are used for the next snapshot queries, which makes a snapshot query terminate as soon as KNN PoIs are found. So packages of Singoes are less than SpaceTwist. In Figure 20, as fixed anchors are picked, LSP will store these PoIs around frequently used anchors in cache, which significantly reduces searching time at LSP end, so the average query time of Singoes does not have a significant growth.

Average time of query: K varies from 5 to 30.
PrivacyGrid and P2P are both higher than Singoes in Figure 20; their query time is growing as K increases, especially PrivacyGrid which has to construct cloaking regions for each user, and querying with the cloaking regions leads to the time delay, so the query time cost of Singoes is better than these methods.
6. Conclusion
We propose anonymity algorithm and query algorithm to achieve location privacy preserving. Based on Voronoi graph partition on road networks, we propose cell predicting method as a precondition. In anonymity procedure, CS need not construct cloaking regions for each user, which reduces time and communication cost. And then we propose query algorithm Singoes referring to SpaceTwist, which solves the PoIs uneven distribution problem in SpaceTwist. It uses fixed anchor sequence to issue every snapshot query of the same continuous query request. That protects a user's actual location, and any adversary is hard to associate a query request with a user. The precise query results of KNN PoIs are obtained around a user's actual location. Performance analysis and experiments show that our method achieves QoS of query for PoIs and location privacy preserving. It has better performances compared with other methods.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This research is supported by a grant from National Natural Science Foundation of China (nos. 61170241 and 61472097), the Fundamental Research Funds for the Central Universities (HEUCFZ1105), Specialized Research Fund for the Doctoral Program of Higher Education (no. 20132304110017), Excellent Youth Foundation of Heilongjiang Province in China (no. JC 201117), and Science and Technology Research Project of Heilongjiang Education Department (nos. 12513049 and 12541788). The authors also thank the anonymous reviewers and the editors for their valuable comments.