
Abstract
Self-localization is one of the key technologies in the wireless sensor networks (WSN). Some traditional self-localization algorithms can provide a reasonable positioning accuracy only in a uniform and dense network, while for a nonuniform network the performance is not acceptable. In this paper, we presented a novel grid-based linear least squares (LLS) self-localization algorithm. The proposed algorithm uses the grid method to screen the anchors based on the distribution characteristic of a nonuniform network. Furthermore, by taking into consideration the quasi-uniform distribution of anchors in the area, we select suitable anchors to assist the localization. Simulation results demonstrate that the proposed algorithm can greatly enhance the localization accuracy of the anonymous nodes and impose less computation burden compared to traditional Trilateration and Multilateration.
1. Introduction
When we monitor a great forest in a dry weather, we would like to know which trees are more likely to catch fire. These localization problems are also important in environment detecting, animal tracker, wisdom agriculture, and so on. Now with the wild deployment of wireless sensor networks (WSN), we can do these monitoring and detecting jobs with WSN. And during this process, the first thing we should do still is to get the location of WSN node itself, and then we could know where the events happened.
Based on measuring the distance between the nodes or not, we can classify the self-localization algorithms to range-based and range-free. As compared to the range-based algorithm, the range-free algorithm has many advantages, including simpler hardware, lower power consumption, and more power in noise resistance. But the main disadvantage of range-free algorithms is big errors. The localization error and communication range between nodes have same order of magnitude, which could be a few tens of meters. If we can improve the localization accuracy, it will be better for many implementations. For example, when we monitor the geologic structure by WSN, higher localization accuracy could lead us to build a road on a solid ground but not the place with a sandpit underground which is only 10 meters away. Similarly, if we can point out which tree is the nest of the pest, we do not need to spray poison pesticides to the whole hillside. So we can see that precise localization will help us to achieve the real sense of precise control.
There are numerous classical range-free localization algorithms such as DV-Hop, convex programming, MDS-MAP, and DHL. Generally, the range-free algorithm can be divided into three steps.
Estimate the distance between the sensor node and sink node. Calculate the localization of the sensor node with Trilateration. Optimize the result we get in the last step with iterative method.
Within these three steps, there are two main approaches to improve the precision of range-free localization algorithm. The first is increasing the precision of distance estimation. As in literature [1], it was studied on nonuniformly distributed WSN. Based on the hop count to the anchor, the network was divided into three areas as CR (Concentric Ring), CG (Centrifugal Gradient), and DG (Distorted Gradient). In each area, different method was used to reduce the error of the distance estimate. In [2], the authors think that the normal Gaussian probability density function cannot be used to estimate the distance between sensor nodes and anchors in two-dimensional random distribution networks. And the author proposed the biggest distance estimate method based on the greedy algorithm. In [3], the authors study the expected hop count in different WSN which has different parameters. Based on these analyses, authors deduced the mathematical expression of the hop count. With this method, it can greatly enhance the estimation precision of the distance between the sensors to the anchors. Another way to promote the localization precision is increasing the number of the iterations within Step 3. With this method, the distance error will be decreased, but at the same time it will increase the complexity of algorithm and the amount of calculation. Furthermore, it is hard to predict the right number of iterations, so the uncertainty of the result will increase. For these reasons, it is restricted to use iterations in practice [4].
Unlike the approaches as showed above, we pay more attention to Step 2: calculate the localization of the sensor node with Trilateration localization algorithm. In general, Trilateration-localization or Multilateral-localization method will be used here. We found that even we work hard to get a more accurate estimate value of the distance, but if we use some bad anchors in Trilateration or Multilateration, the result would be still far away from perfect. On the contrary, even the distance estimate is not perfect if we choose the right anchors in calculation method and then the result would be better. But now the key problem is which anchors are the right anchors? What we do is try to figure out what a right anchor is and how to select them from the total anchors. With the help of these right anchors in calculation method, we can improve the performance of localization algorithm.
As we know, Trilateration has small algorithm computation. On the other side, in this method only the three main anchors’ information is used, so it is difficult to promote the localization precision. But if we use more anchors’ information to promote the precision of localization, then more computing resources will be required. Reference [5] indicates that the error of the distance estimate will increase with the increase of the hop count. Reference [6] explained that we can promote the localization precision by deleting some anchors which have large errors. Reference [7] shows that the precision of unknown nodes is affected by spatial distribution of the involved anchors. The more the uniformity of the anchors distributed is, the more accurate the result will be. The simulation result of [8] also shows that the uniform distribution of the anchors can greatly improve the positioning performance.
This paper proposed a grid-based linear least squares (LLS) self-localization algorithm. The algorithm will fully consider the character of the nonuniformity networks and uses the grid method to select the anchors. In this algorithm, we will delete the anchors which have bigger error and bad distribution and at the same time choose the appropriate anchors to make the distribution of the anchors be more even. Simulation results show that our algorithm has higher localization accuracy and has lower computational cost, compared to the traditional Trilateration and Multilateration.
2. Grid-Based Linear Least Squares (LLS) Self-Localization Algorithm
References [5–8] show that Multilateration has higher localization accuracy because Multilateration involves more anchors in localization method and uses least squares estimation to decrease the influence of the errors. But as the number of the anchors increases, Multilateration needs more bandwidth to transmit data and more computation and energy consumption. Furthermore, in range-free localization algorithm, the error of the distance estimate will increase as the hop count ascends. Therefore, using more anchors in localization means that we are likely to involve more anchors which have larger distance estimated errors. These errors will seriously influence the localization accuracy. As we know, the uniformity of the anchors distribution has a very important effect on the localization accuracy.
In summary, the numbers and distribution of the anchors are the key factors to improve the precision of self-localization. Therefore, we can select a part of the anchors which have small error and proper position through deleting the anchors with bigger errors and bad distribution. With this process, we can promote the localization precision and decrease the calculation and energy consumption. Meanwhile, this is helpful to prolong the life-time of WSN.
We at least need three anchor nodes for locating in 2D orientation as shown in Figure 1(a). But, due to distance measurement errors, the intersection of the localization circle of the three anchor nodes is not a point but an area, as shown in Figure 1(b). Then, the problem of promoting the accuracy of localization is transformed into the problem of making the area as small as possible. About this problem, we use the proof proceeding of [9] and promoted it to multianchor nodes cases.
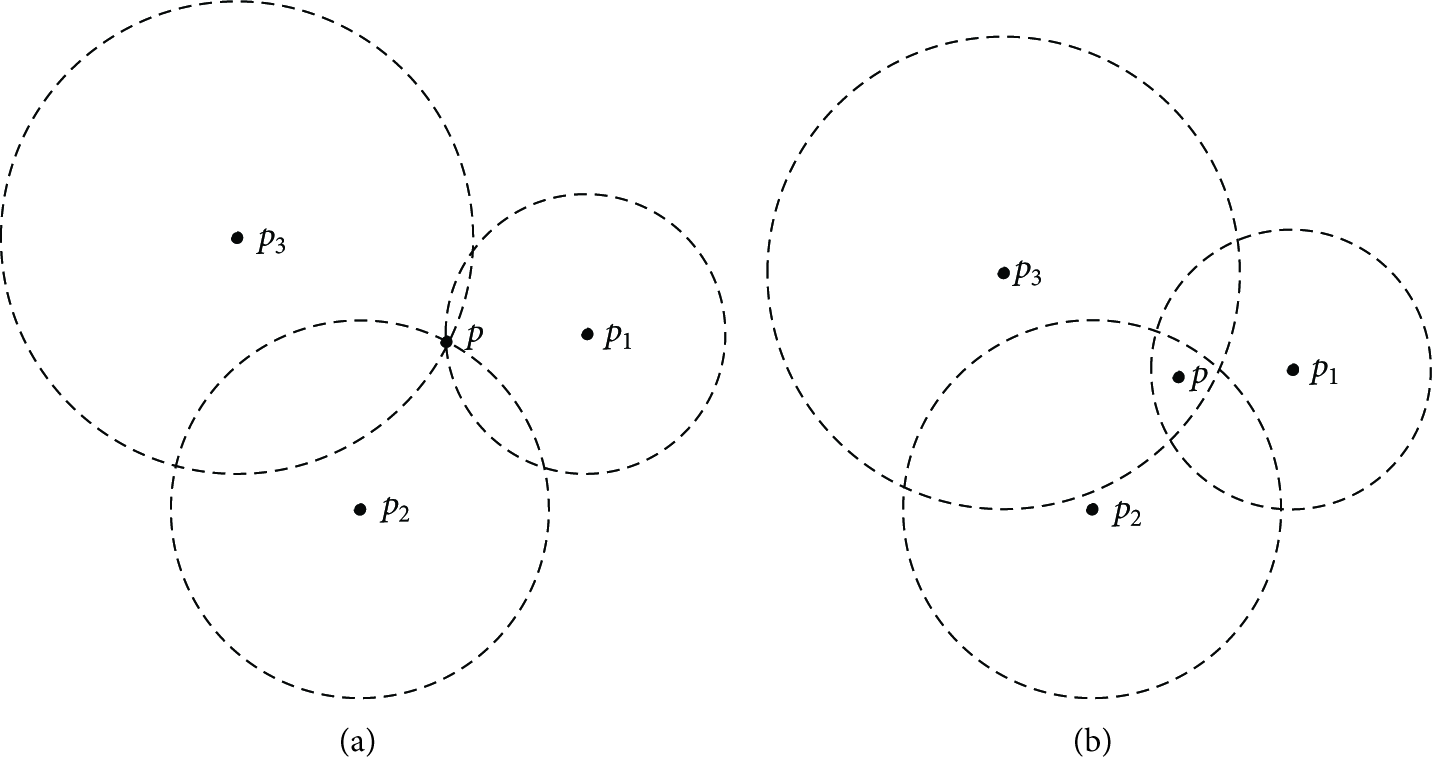
Error area in localization with three anchor nodes.
However, in Trilateration or in Multilateration, it at least needs three anchor nodes to locate the unknown node in 2D orientation, as shown in Figure 1(a). But, due to distance estimation error, the intersection of the localization circle of the three anchor nodes is not a point but an area, as shown in Figure 1(b). Then, the problem of improving the accuracy of localization is transformed into the problem of making the overlap area as small as possible. To this problem, we use the idea of [9] and promote it into multianchor nodes cases.
To simplify the problem and without loss of generality, we first assume that the distance estimation error between every anchor and unknown node is independent. And the localization error of the anchor itself is much less than the distance estimation error between anchor and the unknown node in range-free system, so we will neglect the position error of the anchor. Under normal circumstances, the distance error is much less than the distance between the anchor and the unknown node, so we only use a simple constant to express the distance error.
We first analyze the condition which only has three anchor nodes. We assume the three anchor nodes as
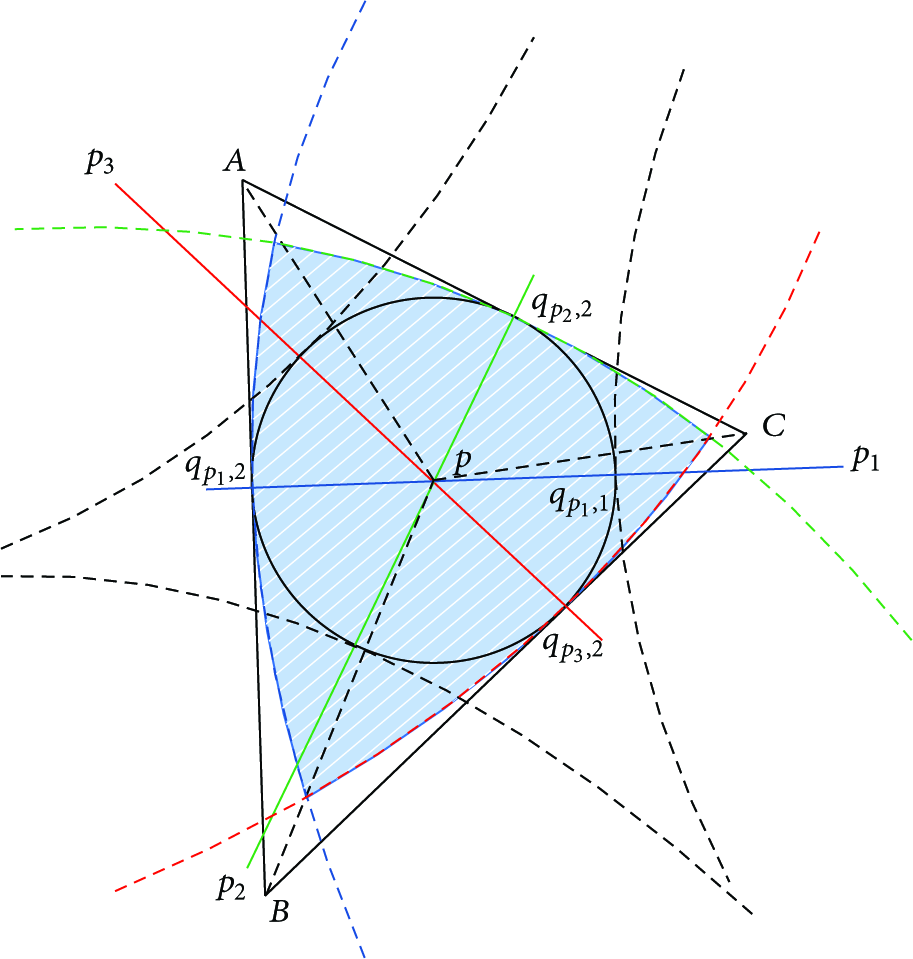
Analysis of location error.
As

Because

The equality will hold up if
Similarly, when we use more anchors in node self-location, the area of circumscribed polygon

Like before, the area
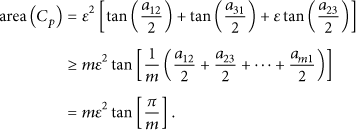
With the derivation process of the formulas, we can see that the localization error will be the minimum if and only if the angles which are formed by adjacent anchors and the unknown node are uniformly distributed. The major research of this paper is to study how to select the appropriate anchors to form such even angles and make the location error minimum at last. To solve this problem, we introduce a dynamic grid template to choose the right anchors for the unknown node. Anchors that have been chosen will evenly distribute to the unknown node. This process will improve the localization precision.
Based on this idea, we propose a grid-based linear least squares (LLS) self-localization algorithm. This algorithm still estimates the distance based on the hop count, so we do not need to change the hardware structure of the sensor nodes and the transmit process. So there should be minimal impact on existing systems. On this basis, we will still use Multilateration to localize the unknown nodes. But, in the process of selecting anchors, we will not choose total anchors whose packets the unknown nodes can receive. Alternatively, we delete the anchors whose hop count to the unknown nodes is larger than threshold
In this paper, we call the nodes that need to be localized as unknown node, nodes which know their location and can help the unknown nodes to be localized as anchor nodes. Neighbor nodes are the nodes involved in one node's communication range. Current node means the node is being localized.
This algorithm is divided into 5 steps.
Estimate the distance between unknown node and anchors. Make up grid and filter anchors. Determine the grid unit of the unknown node. Generate a set of the anchors which have even distribution to unknown node. Localize the unknown node by the linear least square method.
Step 1 (estimate the distance between the unknown nodes and anchors).
There are many algorithms to get the distance between the unknown node and anchor. In order to make the result comparable, we use distance estimate method of DV-Hop all the time. DV-Hop is one of distributing localization algorithm sets, APS, which is proposed by Dragos Niculescu of Rutgers University. In DV-Hop, distance is estimated based on the hop count between anchor and unknown node. At first, it uses Distance Vector Algorithm or something like it to obtain the hop count from every unknown node and anchor to every anchor. Then, every anchor will calculate its own average distance of each hop based on the coordinates and the hop count to the other anchors, as shown in

In formula (5),
Step 2 (set up the grid and filter the anchors).
For the unknown node, it could know the hop counts between the anchors and itself, after getting the information of the anchors. Then we can delete the anchors whose hop count to the current node is bigger than threshold


We can see that every unit of the grid is a square with each side of length R. And, as we know, if there are too many anchors in a unit, the accuracy of localization will be affected. So we choose the anchor with minimum hop to the unknown node as the representative anchor of the unit, and if more than one anchor has the same minimum hop count, we will only choose one anchor randomly.

Set up the grid and get the grid location of the unknown node.
Step 3 (determine the grid unit of the unknown node).
After setting up the grid, we need to determine the grid unit of the unknown node. Only if we know which grid unit the unknown node is located in, we can choose the appropriate anchors to form even distribution. In this paper, we draw on the idea of Min-Max localization algorithm and calculate the Min-Max range of every anchor based on the hop count from the anchor to the unknown node. Then choose a grid unit randomly among the overlapping area of every anchor's Min-Max range as the grid unit of current unknown node. The points of this process are shown in Figure 3(b).
Step 4 (generate uniformly distributed anchor set).
In this step, we choose the uniformly distributed anchors from the rest of the anchor set and used the unknown node as the center. Here we use a kind of mask.
As shown in Figure 4, we first generate a square mask with each side of length Count the number of anchors in every part. In order to ensure if there are enough anchors to be used in localization, we set that the minimum number of anchors that have been needed in localization process is Count the minimum number of anchors in the part set, Set1: While if else if While if else if Recollect the part set as Set3: Choose T2 anchors with less hop count from original anchors directly.

Grid and mask.
Step 5 (locate the unknown node by the linear least square method).
While the unknown node gets the location information from enough anchors, we can use some kind of localization algorithm to calculate the position of the node. In Trilateration, the localization algorithm only needs the information of three anchors. Similarly, in Multilateration, the algorithm needs more than three anchors. From this sense, Trilateration is a particular case of Multilateration.
In general, to reduce the position error in localization process, the linear least square method is used to determine the location of the unknown node in Trilateration and Multilateration. When the variance of the estimated distance between the unknown node to the anchors is known, we can use WNLS (weighed nonlinear least squares) to get the maximum likelihood solution of the unknown node's location coordinates. Else, if we cannot obtain the variance of the estimated distance or the errors which are independently identically distributed, then we can convert WNLS to NLS (nonlinear least squares). The most frequently used solution of NLS is Steepest Descent and Gauss-Newton and so forth. But all these methods have huge calculation and need high-precision initial value to avoid getting in the local optimal solution. In order to simplify the algorithm and decrease the calculation, we usually transform the NLS into linear least squares in practice. This method chooses one distance equation as reference equation. Other equations subtract this reference equation and then form
According to the application environment of using the range-free localization algorithm, the above LLS algorithm has usually been used to calculate the location of the unknown node. The detail of the algorithm is described below. Set the coordinates of the unknown node as

Because of the existent of distance-estimated error, complete linear equations can be described as


3. Simulation
At first, we divide the simulation scenarios into two kinds: uniform scenario (Scene 1) and nonuniform scenario (Scenes 2, 3, and 4). In all scenarios, 500 sensors were deployed in a 2D field (500 m * 500 m), and the sensor's communication range is 50 m. Anchors were randomly selected, and we assumed every node can receive packets from every anchor. The thresholds were set as
Scene 1. The sensors are uniformly distributed.
Scene 2. As shown in Figure 5, in order to simulate nonuniform scenario, we divide the scenario into four regions and set the ratio of nodes for each region as 1 : 3 : 1 : 3

Simulation scene.
Scene 3. The ratio of the nodes is 1 : 5 : 1 : 5
Scene 4. The ratio of the nodes is 1 : 7 : 1 : 7 =
3.1. Localization Accuracy
Definition. Normalization position error
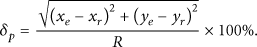
For convenience, the proposed algorithm in this paper will be expressed as LLS + GRID.
Figure 6 showed the performance of LLS + GRID, Trilateration, and Multilateration, while the number of anchors accounts for 5% and 10% of total nodes in Scene 1. We can see that, in uniform scene, no matter how the proportion of the anchor is, localization precision of LLS + GRID and Multilateration is much better than Trilateration. While the proportion of the anchor is 5%, using LLS + GRID algorithm there will be 79.89% sensor's location error less than 40% R, and this number is 2.6% greater than Multilateration. While the proportion of the anchor is 10%, under same setting, the advantage of LLS + GRID will be 5.9%. Thus, we can see that the performance of LLS + GRID is slightly better than Multilateration and much better than Trilateration in uniform scene.

Performance of localization algorithm in uniform network.
Figure 7 illustrates the performance difference between these three localization algorithms in nonuniform scenes. From the vertical, the figures show the comparisons of proportion of the located node as a function of normalization localization error in different nonuniform scene. From the horizontal, the figures show the relation of these two parameters for different proportion of anchors.
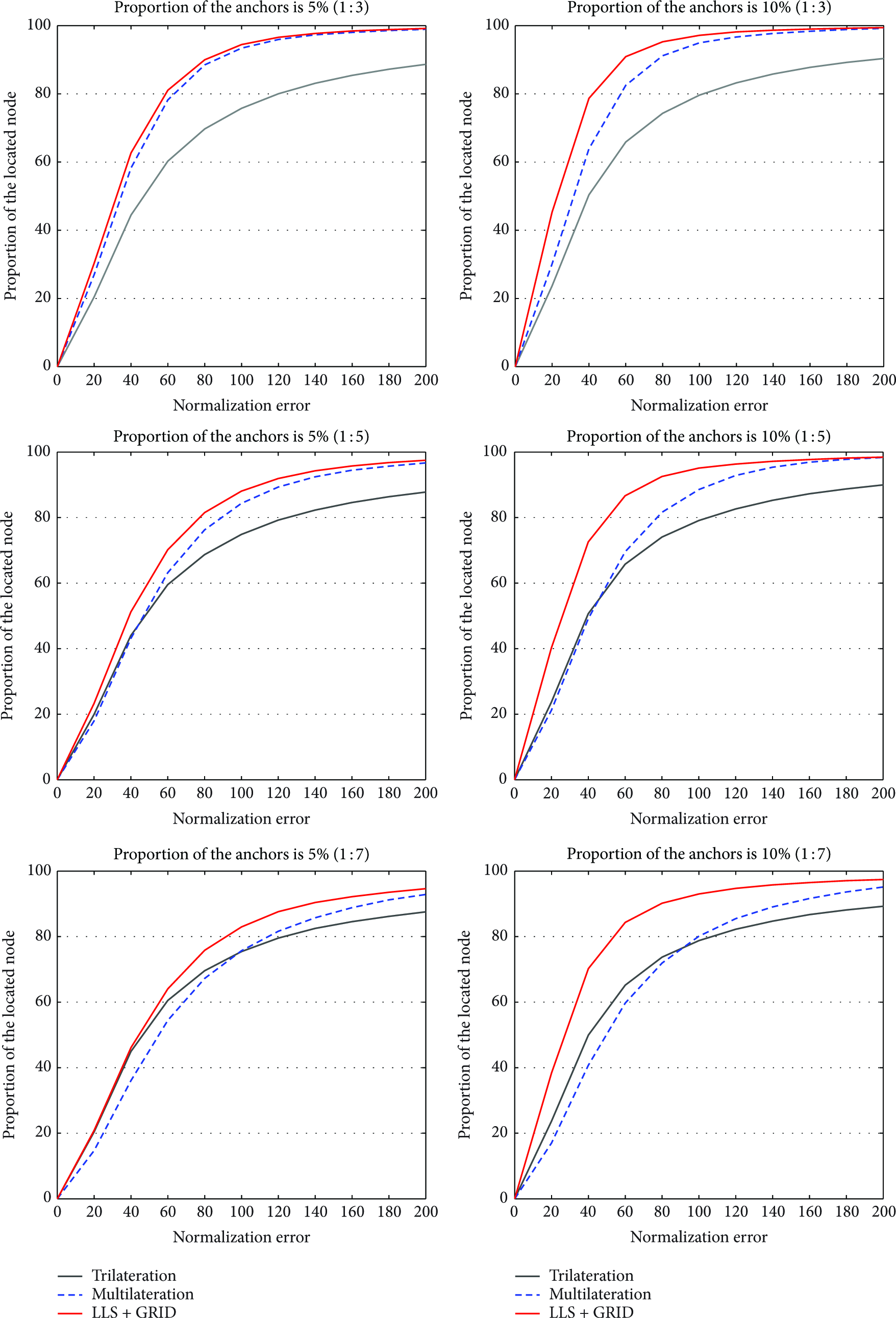
Performance of localization algorithm in nonuniform network.
All the simulation results show that, no matter how heterogeneity of the network is, the LLS-GRID is better than Trilateration and Multilateration. For example, while the percentage of the anchor is 10% and heterogeneity of the network is 1 : 3, for LLS-GRID, the number of the nodes whose location error is less than 40% R is 14.76% more than Multilateration. Similarly, this value is 22.4% and 29.47% more than Multilateration when the heterogeneity degree is 1 : 5 and 1 : 7.
In conclusion, the performance of Multilateration algorithm is unstable with the increase of heterogeneity degree of the network. The same is true for Trilateration. But LLS + GRID algorithm is more stable in these scenes. While the percentage of the anchor is 10% and the heterogeneity degree of the network increases from 1 : 3 and 1 : 7, comparing the number of nodes whose location error is less than 40% R, the location precision of LLS + GRID algorithm only decreases 8.43%, but for Multilateration it is 23.14% decreased. Therefore, we can see LLS + GRID algorithm has more adaptability to the environment.
3.2. Computation
LLS-GRID algorithm only adds a process of choosing anchors before localization, and therefore the amount of calculation of LLS-GRID algorithm and LLS algorithm is similar.
Assume that each unknown node receives n anchor's packet for localization after mask method. We can approximately estimate the amount of calculation based on the times of multiplication and addition in formula (6).
Figure 8 illustrates the calculation of LLS-GRID, Trilateration, and Multilateration in different scenarios. From Figure 8, we can see that the calculation of Trilateration is always the smallest in every scene. This is because Trilateration only needs three anchor's packets in localization process. Similarly, the calculation of Multilateration algorithm is always the biggest. This is because Multilateration needs every anchor's packets in localization process. For LLS-GRID algorithm, the calculation is slightly increased than Trilateration but significantly decreased than Multilateration. From Figure 8's result, as the percentage of the anchor is 5% and 10%, the calculation of LLS-GRID is 44% and 72% smaller than Multilateration. So this shows that LLS-GRID algorithm is very stable for every scene, whether in uniform network or nonuniform network. In a word, LLS-GRID algorithm can improve localization accuracy while reducing the calculation cost.

The calculation of localization algorithms.
4. Conclusion
This paper proposes a novel grid-based linear least squares (LLS) self-localization algorithm in WSN. The result of simulation indicates that this algorithm effectively solved the problem of localization precision and computation complexity. This algorithm does not require changing the structure of hardware and the protocol structure. The localization precision of LLS-GRID is vastly superior to Trilateration and Multilateration. Meanwhile, the calculation of the algorithm is only equivalent to 30%~40% of Multilateration. In addition, it is more stable than Multilateration. So this grid-based LLS algorithm can greatly extend the application range of range-free localization method.
Footnotes
Conflict of Interests
The authors declare that they do not have any commercial or associative interest that represents a conflict of interests in connection with the work submitted.
Acknowledgments
This research was supported by the National Natural Science Foundation of China 61373177, The Foundation of Northwest University ND14041, National Natural Science Foundation of China 61170218, Project National Key Technology R&D Program 2013BAK01B02, and Scientific Research Plan Projects of Shaanxi Education Department 2013Jk1153.