
Abstract
Revealing the structural features of social networks is vitally important to both scientific research and practice, and the explosive growth of online social networks in recent years has brought us dramatic advances to understand social structures. Here we proposed a community detection approach based on user interaction behavior in weighted dynamic online social networks. We researched interaction behaviors in online social networks and built a directed and unweighted network model in terms of the Weibo following relationships between social individuals at the very beginning. In order to refine the interaction behavior, level one fuzzy comprehensive evaluation model was employed to describe how closely individuals are connected to each other. According to this intimate degree description, weights are tagged to the prior unweighted model we built. Secondly, a heuristic community detection algorithm for dynamic network was provided based on the improved version of modularity called module density. As for the heuristic rule, we chose greedy strategy and merely fed the algorithms with the changed parts within neighboring time slice. Experimental results show that the proposed algorithm can obtain high accuracy and simultaneously get comparatively lower time complexity than some typical algorithms. More importantly, our algorithm needs no a priori conditions.
1. Introduction
Research of complex networks has a wide attraction of scientific research. Some scholars focus on semantic network [1] which means a form of human knowledge relationships [2, 3], and some other researchers obtain algorithms for community detection, which is a fundamental problem in network analysis. Detecting communities is of great importance in sociology, biology, and computer science, disciplines where systems are often represented as graphs. This problem is so complex that we did not find a satisfying solution by far, despite the huge effort of a large interdisciplinary community of scientists working on it over the past few years [4].
Traditional methods treat community detection as graph partitioning and clustering problems. Kernighan-Lin (KL) algorithm [5] is an early proposed graph partitioning based method, which uses greedy strategy to optimize the divided structure according to the edges between communities; the evaluation function is defined as the number of edges in the two communities minus the number of edges connecting them. KL algorithm can divide target network into specific size subsets, but the number of subsets is needed a priori. As KL algorithm, the majority of graph partitioning methods require too much prior knowledge, and most variants of the graph partitioning problem are NP-hard. More importantly, the partitioning results usually consisted of clusters with similar size. Taking all these shortcomings into consideration, graph partitioning algorithms are not fully suitable for detecting communities in big social networks [6].
Unlike graph partitioning methods, clustering does not need much prior knowledge, so clustering based methods can be more effective for community detection. For example, hierarchical clustering algorithms are known as suitable approaches to be used to detect communities in social networks. Social networks naturally have hierarchical structures, which mean networks with hierarchical structure may display several levels of grouping of the nodes. Small clusters are contained within large ones, which are in turn included in larger ones, and so on [7]. Some clustering algorithms try to divide a target network naturally into many parts based on the similarity and intensity of each node, and these works can be classified into two kinds: aggregation algorithms and divisive algorithms. For example, the Newman fast algorithm [8] is a typical aggregation method based on greedy strategy, mainly focusing on the network with numerous vertices. Typical divisive algorithm is as method [9], which treats the network as a huge community and then divides it step by step. The GN algorithm proposed by Girvan and Newman [10] is another example of divisive method. The main idea is to remove the edges with maximal betweenness [11], which provides a rule of edge detection for the small community in the network.
Except for traditional methods, community detection in weighted, directed, or dynamic networks is also widely discussed separately. Few works took these features together into consideration, and, comparing to the research on unweighted and undirected networks, no significant achievements had been made. Most networks in real world can be seen as heterogeneous ones because the nodes have different characteristics and the relationship between two nodes usually means different influences to them. In fact, heterogeneity of nodes can be represented in weighted, directed network models. On the other hand, dynamic network analysis had drawn a lot of attention in the past few years. As we know, a dynamic community detection method was firstly proposed by Hopcroft et al. [12]; it divided the dynamic network into several static parts and then obtained the hierarchy clustering results with the method of cosine similarity. They selected relatively slightly changed parts from the results as natural communities, and dynamic network evolution was studied on the above bases. Chakrabarti et al. [13] tried to analyze dynamic network via continuous iteration; the concepts called snapshot quality and history cost were proposed in this work to satisfy both of the following: “clustering results should keep pace with the current network topology as far as possible” and “the results should minimize the difference between the clustering processes.” In order to understand the dynamic of social network structure, Shan et al. build a mathematical model [14], and an incremental identification method is also proposed, which analyzes the nodes incrementally rather than just redivide all nodes in the network, to improve actual operation efficiency of the algorithm. Ning et al.'s work is also a valuable attempt [15]; they put forward the incidence vector concept to present the dynamic process of the network through incrementally updated characteristic value system. Chen et al. approach a novel multiobjective algorithm for detecting communities in dynamic networks, which provides a solution to keep a balance between accuracy and efficiency [16]. In Yu et al.'s work, a feasible algorithm for the identification of overlapping modules in PPI networks is proposed, which detects communities with more flexibility [17].
As we can see, excellent research works had been done on community structure detection; however, the existing algorithms either need too much a priori knowledge or are not good enough to handle complex network models. The research on weighted, directed, and dynamic networks may provide us more ways to understand real networks. And designing fast and reliable network community detection algorithms will continue to be the attractive area for us in the future.
On the other hand, with regard to community detection methods, quality functions are very important, because an algorithm needs a stopping criterion. Nowadays, the most commonly known function is called network modularity [18], which represents one of the first attempts to achieve a first principle understanding of the clustering problem, and it embeds in its compact form all essential ingredients and questions, from the definition of community to the choice of a null model and to the expression of the strength of communities and partitions [4]. Because of this, we are going to employ modularity in this paper to evaluate the division results and we take online social network as our target network; a detailed analysis on the dynamic process of how an online social network evolves will be shown.
The rest of this paper is organized as follows. In Section 2 we build a weighted social network based on interaction behavior analysis of online social network. Section 3 gives a community detection algorithm for dynamic directed weighted networks. Section 4 compares our method with well-known algorithms through experiments. Finally, Section 5 makes the conclusions.
2. Social Network Weighted Method Based on User Interaction Behavior Research
When studying network structure, we first focus on the interactions between individuals and define an approach to weight the edges to involve more online social network information into our network model. We assume that edge weights represent the interaction intensity between nodes, which will reflect both the existing parameters in physical world and calculating features defined by ourselves. The calculating features will reveal the underlying characteristics of online social networks. For a network containing complex social relationships such as similarity and intimacy, we try to transform one or more of the interactive attributes to be weights, to measure the intimacy between users. The method employed a weight with fuzzy synthetic evaluation model according to the interaction of followers and the frequency of interaction over a period of time. The theoretical basis of weighting method is fuzzy comprehensive evaluation method [19], which transforms qualitative evaluation to quantitative evaluation according to the fuzzy membership degree theory. For short, it is a method to provide an overall evaluation to objects which are restricted by multiple factors with fuzzy comprehensive evaluation on multiple factors [20].
In dynamic online social networks, such as Facebook [21] and microblog [22], the behaviors, for example, “comment,” “forward,” “like,” and “at,” can reflect the proximity between users during a period of time. In our comprehensive evaluation method, we select level one comprehensive evaluation model [23] as the method to measure the relationship. Here we assume B as the collection of user behaviors:

It is crucial to allocate the weight for the above factors. The weights of the behaviors are confirmed by statistical methods. The data used in the paper comes from NLP laboratory of Beijing Institute of Technology which collects data of Sina Microblogs in recent two years [22]. The dataset contains 1.5 million users and 50 million microblogs. There are 86,341,256 interaction behaviors, including 21,510,466 “comments,” 36,538,478 “like,” 23,299,712 “forward,” and 4,992,600 “at.” So we can easily figure out the proportion shown as the following vector A and the member of A is the proportion of each kind of interactions:

Then we assume a

Here n represents the total number of users x followed and
Evaluation of user x's behaviors.

Matrix R for user x can be calculated as follows:

Then we explain the evaluation model with Figure 1, which is generated from nodes of Sina Microblog. We take user 003 as an example; detailed information can be discovered in Table 2.
Statistics of user 003.


The network of test example.
We can calculate the evaluation matrix 
If we calculate all the data according to the above method, we can get the matrix as follows:

Finally, we can get level one comprehensive evaluation model 
The result represents the weight value of “at” behavior from user 003 to the three neighboring users, that is, 0.1138, 0.1040, and 0.7822.
3. Community Partition Algorithm for Dynamic Directed Weighted Networks
This paper proposed an algorithm which needs no a priori conditions, the algorithm firstly set up heuristic rules of the dynamic changes of the social network based on the basic nature of community structure and employed an improved module density function D combined with weighted network to ensure the accuracy of the algorithm [24].
We give some basic definitions which will be used in the remaining part.
For directed weighted network


The second function also has two variants as shown in the following:


Then we define 
In order to deal with the affection of direction factor in the network, we can assume a node i with high out-degree and low in-degree, while node j is on the contrary. Obviously, if there is an edge between node i and node j, the direction of the edge is most possibly from node i to node j. Similarly, if there is an edge from node i to node j, the module density of the community will be greatly influenced, which means that node i prefers to be a member of community
So in the paper, we use a parameter β 
So we can calculate the module density following formula 14. To make the structure of the new community 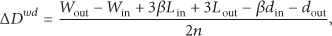
In our daily life, we can easily find that if a person is my friend, he or she will most probably be my friend's friend. So we prefer to set the node i to be a member of the original community. Thus, we put forward the principle combining with heuristic greedy strategy: for any node i in the network, we prefer to put it into community which contains the most neighbors of node i. It has two key points: greedy selection property and optimal substructure.
Our algorithm deals with directed and weighted networks. However, for a real network, it is almost impossible for the degree of all nodes to be even. Then, the structure of the network is an undirected and unlooped graph with a corresponding matroid. The greedy strategy is one of the situations of the matroid, so the idea based on module density with greedy strategy is reasonable.
There are mainly 4 kinds of reasons that will cause the dynamic variety of real networks. We can conclude them as follows.
(1) Adding a Node
(2) Deleting a Node
(3) Adding an Edge
(4) Deleting an Edge
A dynamic community changes its structure in accordance with the above four situations, and in most cases the first and the third situations often occurred, while the second and the fourth situations are very scarce.
3.1. Analysis of Community Structure Variations
The four changing situations of a dynamic community result in the structure of community evolving, too. In the network we confronted in real life, there are only six cases when a community structure changes.
(1) Community Generation. New nodes are added to a network dynamically, and these nodes may form a new community as shown in Figure 2(a).

The six changes of a community.
(2) Community Extinction. Nodes of a community are removed gradually, and finally the community disappeared as shown in Figure 2(b).
(3) Community Expansion. The community will expand when many new nodes or edges are joined as shown in Figure 2(c).
(4) Community Decrease. The community will decrease with the removing of part of nodes or edges and it makes the community smaller and smaller as shown in Figure 2(d).
(5) Community Combination. Two communities are merged into one community dynamically as shown in Figure 2(e).
(6) Community Split. A community is split into two or more communities dynamically as shown in Figure 2(f).
It can be easily proved that the changing results are among the above six situations.
3.2. Algorithm Description
We analyze the four possible dynamic behaviors and design the algorithm as follows.
(1) Adding a Node. When the new node has no connection with any other nodes, it will be a new independent community. If the new node has connection with other nodes, we put the node into the community which can get the highest gain in module density. The pseudocode of the algorithm is designed as shown in Algorithm 1 (
// If Update Else For existing communities, put v into each of them Do Calculate End For c = get the maximal Update
(2) Deleting a Node. If the degree of the removed node is 1, just delete the edge connected to the node; otherwise, delete all the edges connected to the node and reassign the neighbor nodes of the deleted node to the community which can achieve a higher module density. If the connected edges are all within the community, just keep the neighbor node in the original community. The pseudocode of deleting a node is given as shown in Algorithm 2.
If (node v's degree is 1) Else While (Node v's neighbor is not 0) do End while End if Put the nodes in S into the considered best community which has the maximal Update
(3) Adding an Edge. When the new node i and node j belong to the same community (
When a new edge
If (node i and node j are new nodes) then Update Else if ( If ( Update Else Node v = Move v to the new community For all neighbors of v Put it into the best community which has the maximal End for Update End if End if End if
(4) Deleting an Edge. When the nodes i and j of an edge come from different communities
When the two nodes (i and j) of the removed edge belong to the same community
When the two nodes (i and j) of the removed edge come from different communities
Thus, we get the idea from GN algorithm [15], which regards the community
If ( Else if (the degree of either i or j is 1) then Else if (node i and node j don't belong to the same community) then Else Int z = Get the betweenness of If (z is the top n biggest betweenness of the network) Put other nodes into the considered best community which holds the maximal End if End if Update
Then we analyze the time complexity of every step in the algorithm.
(1) Initialization. Initialize N nodes and at most N communities, which takes the time complexity of
(2) Iteration. Iterations take place for k times, and for each iteration, the maximal
(3) Modification. Algorithm 1 to Algorithm 3 (described in Section 3) are simple linear calculation on given variables, which takes time complexity
The total time complexity is
From the reckoning above, we can get that the time complexity of the algorithm is
In reality, the iteration time will be acceptable for most networks, so the algorithm will be efficient. The more obvious the community structure especially will be, the less the iteration time will be needed and the more efficient the algorithm will be. However, if the community structure is not clear, the community detection algorithm will make no sense all the same.
4. Experiment and Analysis
In this section, we carry out the experiments by using Sina Microblog dataset with 5,000 users. And we establish four networks with 100, 500, 1000, and 5000 nodes, respectively. To show the results conveniently, we choose some representative nodes to build a small network. Then we compare the efforts with other algorithms.
Firstly, to confirm the value of β, we do the experiment with different network scale (dataset size). When the experiments end, we choose the value of β when the community obtains the maximum value of module density. The results are shown in Table 3.
Relation between β and module density.

From Table 3, we can conclude that, in most cases when the value of β is 0.65, the module density will reach the maximal value. Thus, we choose the approximate value of
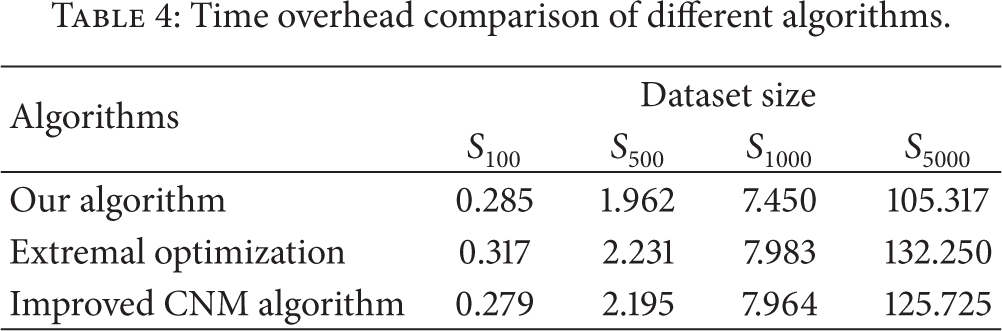
Comparing with extremal optimization algorithm [25] and improved CNM algorithm [26], we do experiments to get the time overhead and the module density. The comparison results are listed in Tables 4 and 5.
Time overhead comparison of different algorithms.
Modularity comparison of different algorithms.

From Tables 4 and 5, we can conclude that the algorithm in this paper outperforms in time consuming compared with extreme optimization and improved CNM algorithm as an increase in network scale [26].
To demonstrate the high quality of the divided results, we can evaluate the module density of the algorithms. Figure 3 shows the changing tendency of module density when network scale increases, which discloses that the larger the network scale, the bigger the module. Module density reflects the divisive quality of network, so the proposed algorithm is suitable for large scale network.

Changing tendency of module density.
The above experiments have presented the results in static networks. So we randomly add four behaviors of dynamic network variations (described in Section 3) to compare with the other algorithms. The adjustment of the community is based on increments of the network and it is locally conducted, even in the most complex situations; the time expenses of the algorithm can be neglected, and the results are shown in Figure 4.

Changing tendency of modularity.
We can conclude that during the process of changes, all the module density values of the three algorithms have a bit of fluctuation but just in a small range relatively (from 0.26 to 0.37), and the algorithm in this paper always maintains the highest module density value after a certain time (time = 4.5 s) in dynamic network as shown in Figure 4.
In brief, the algorithm in this paper can achieve better results compared with the extremal optimization and improved CNM algorithm.
5. Conclusions
A weighted approach based on user interaction behavior and module density based communities detection algorithm for online social networks are provided in this paper, which are suitable for dynamic social network modeling and community detecting, considering the characteristics of the social network and the shortage of the most current community partition algorithm. According to the real-time and dynamic characteristics of the social network, we first weighted the network edge based on the user's behaviors and then combined the following methods to design a new community partition algorithm: the strategy of greedy heuristic rules improves module density function D in terms of the characteristics of the weighted and directed network, which is employed to derive the standard measure function for estimating community detection and dynamic rules in real social network. The algorithm can obtain very high accuracy and low time complexity without any a priori condition. Moreover, the complexity only depends on the number of iterations, namely, the clarity of the community structure of network, regardless of the scale of the network, so it is suitable for dynamic and large scale network analysis.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This work is supported by the Central Universities Fundamental Research Funds of China under Grant no. N120317003.