
Abstract
There is an increasing interest in using video sensor networks (VSNs) as an alternative to existing video monitoring/surveillance applications. Due to the limited amount of energy resources available in VSNs, power consumption efficiency is one of the most important design challenges in VSNs. Video encoding contributes to a significant portion of the overall power consumption at the VSN nodes. In this regard, the encoding parameter settings used at each node determine the coding complexity and bitrate of the video. This, in turn, determines the encoding and transmission power consumption of the node and the VSN overall. Therefore, in order to calculate the nodes' power consumption, we need to be able to estimate the coding complexity and bitrate of the video. In this paper, we modeled the coding complexity and bitrate of the H.264/AVC encoder, based on the encoding parameter settings used. We also propose a method to reduce the model estimation error for videos whose content changes within a specified period of time. We have conducted our experiments using a large video dataset captured from real-life applications in the analysis. Using the proposed model, we show how to estimate the VSN power consumption for a given topology.
1. Introduction
Technology advances in communications have enabled the implementation of pervasive computing applications that share the vision of small, inexpensive, distributed, and robust networked devices that can gather and process context specific information on behalf of the users. In this regard, wireless sensor networks (WSNs) [1] that can monitor different types of physical phenomena and are able to provide a diverse set of context data to interested clients can be used as the basis architecture for such implementation. While WSN was originally used to monitor physical measurement of the environment such as temperature and humidity, recent trends show that WSNs may successfully be used in a wide range of other applications, including monitoring the condition of public structures such as bridges [2], surveillance of access hatches [3], monitoring of indoor asbestos [4], healthcare [5], and habitat monitoring of seabird or fish [6, 7]. Furthermore, with the availability of more advance sensor nodes, we witnessed an increasing number of studies investigating the use of sensor network platforms for intelligent environments [8], intelligent green service in the Internet of Things [9], and smart homes [10]. Some of these applications require the sensor network to provide multimodal information in the form of multimedia streams, such as images or video [11]. For this reason, video sensor networks (VSNs) have attracted a lot of research attention in the past decades. The low cost and flexibility offered by VSNs provide an interesting alternative to several existing video monitoring technologies [12, 13]. Studies on different VSNs applications have been reported in the literature [14–16].
Key research areas in VSNs are discussed in [11, 17], while [18] puts significant attention on sensor coverage, [19] details quality of service (QoS), and energy consumption is covered in [20–22]. However, since VSNs usually have limited energy resources, the issue of energy efficiency becomes one of the most important design aspects in VSNs. In a common WSN that operates on scalar data, energy efficiency is entirely dependent on the data transmission process [1, 23–25]. On the contrary, video processing requires extensive resources in encoding the video and transmitting the encoded video stream. The encoder parameter settings used by the VSN nodes affect the coding complexity and bitrate of the video. The coding complexity and bitrate of the encoder in turn determine the encoding and transmission power consumption of the video node. In order to improve the VSN operation efficiency, an in-depth study of energy consumption trade-offs in a VSN is thus necessary.
Among the existing video coding standards, H.264/AVC is the most widely used video encoder in the consumer market [26, 27]. In the context of VSN, Ahmad et al. [21] studied the required energy for encoding and transmitting video content in the case of using H.264/AVC encoder. Unfortunately, the number of encoding configuration settings considered in that study is limited. By including more encoder settings than those used in [21], the authors in [22] proposed a table that includes different combinations of coding complexity and bitrates, producing compressed videos with almost similar quality in terms of peak signal to noise ratio (PSNR). A model to estimate the coding complexity and bitrate of an H.264/AVC-based VSN was proposed in [28].
In this paper, we modeled the coding complexity and bitrate of the H.264/AVC encoder in a VSN, based on the encoder parameter settings used. In order to proceed, we need to mimic a real-life setting of a VSN deployment and capture a large amount of real-life content which we used in our analysis. From this large dataset, some videos were used as the training set, while the rest were used to test the performance of our model. We provide a method to reduce the estimation error for videos whose content changes within a specified period of time. Using our proposed scheme, we show how the VSN total power consumption is estimated.
The rest of the paper is organized as follows. Section 2 describes the H.264/AVC coding complexity and bitrate modeling. The encoding and transmission power consumption model is discussed in Section 3. Conclusions are drawn in Section 4.
2. H.264/AVC Complexity and Bitrate Model
In this section we describe our coding complexity and bitrate model. A method for reducing the estimation error is also described in this section.
2.1. Experiment Settings
In order to mimic realistic VSN applications, we have captured real-life videos using four cameras in the atrium of a public building. The cameras were installed so that each of them had a different point of view as shown in Figure 1. The views of some cameras were overlapping with one another. The scene arrangement was such that each camera point of view was different. In order to mimic a practical application, all video sequences were downsampled to 416 × 240 pixels of resolution and their frame rate was reduced to 15 frames per second (fps). Five shots of videos were captured using the four cameras, resulting in a total of 20 different videos. These videos were named using the convention
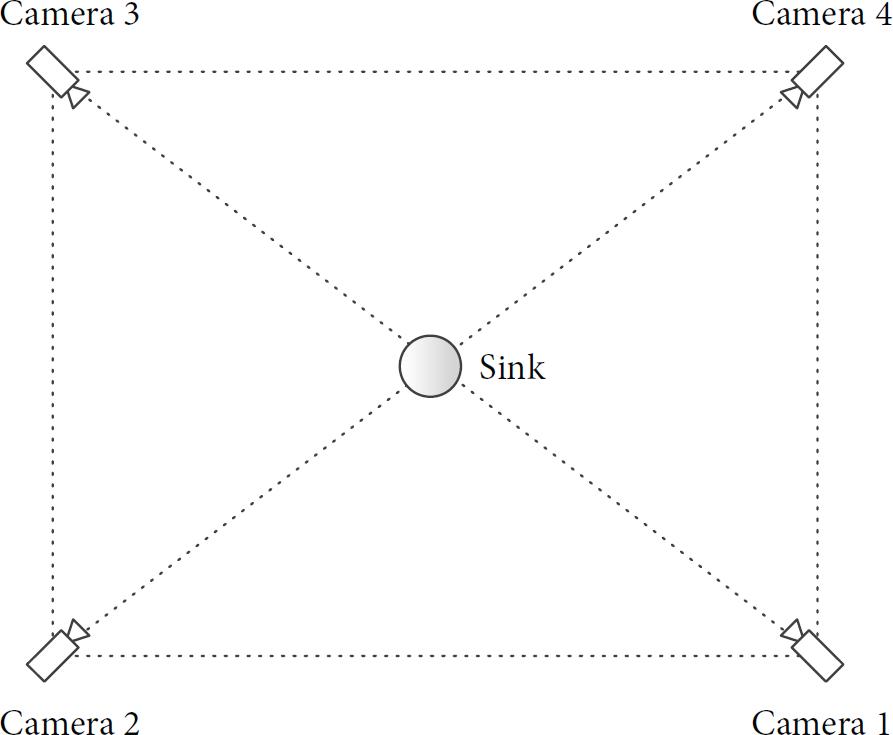
Camera placements.
In VSN applications, due to the limitations in energy and processing resources, less complex encoder configurations are used. To this end, we used the baseline profile of H.264/AVC that uses only I- and P-frames (no B-frames) and is suitable for low complexity applications. Note that, similar to its predecessor, H.264/AVC is a block based hybrid video encoder that utilizes intraframe and interframe prediction techniques. There are many parameters that control the encoding performance in terms of coding complexity and bitrate. The group of pictures (GOP) size that controls the number of interframe coded pictures in successive frames is a parameter that significantly affects the coding complexity and bitrate. The other factor that controls the complexity and the performance of the H.264/AVC codec is the number of block sizes used in the interprediction process. Increasing the number of block size candidates used in the interprediction results in a higher compression performance at the expense of increased complexity. In general, there are seven block sizes defined for interprediction in H.264/AVC. In this paper, the complexity of motion estimation (ME) is classified into different levels of complexity depending on the number of block size candidates used, as shown in Table 1.
ME complexity level (

The H.264/AVC reference software JM version 18.2 is used in our experiments. In addition to using only I- and P-frames, we also used context adaptive variable-length entropy coding (CAVLC) and one reference frame. Other settings include search range (SR) for motion estimation equal to 8, disabling the rate distortion optimization (RDO), rate control, subpel motion estimation, deblocking filter, and intracoding for P-frames options. The quantization parameter (QP) used to encode all videos is set equal to 28. Furthermore, to have an objective measure for the coding complexity, we use the number of basic instructions count to encode the video. This is provided by the instruction level profiler iprof [29]. We developed the coding complexity and bitrate models by considering the effect of GOP size and the number of block size candidates used to encode the video. These models are explained in detail in our previous work in [28]. The following subsections provide the basic information about the modeling process.
2.2. Coding Complexity Modeling
The coding complexity of a video sequence (


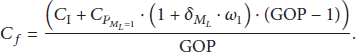
2.3. Bitrate Modeling
Similar to the coding complexity model, the total size of the encoded video sequence (in bits) is modeled as



2.4. Implementation of Our Model
In order to implement our model using the complexity and bitrate modeling, we need to obtain several variables from each video sequence. To this end, we encode the first two frames of each video sequence. For the bitrate model,
For the complexity modeling, the iprof tool will provide us with the complexity of encoding the first two frames of the video sequence; that is,
2.5. Proposed Method to Reduce the Estimation Error
In many real-life captured videos, content may change during a 10 s video shot. For example, Figure 2 shows frames 1, 70, and 100 of the camera1_shot3 video sequence. It can be seen that the content at the start of the video (frame number 1) differs significantly from the content towards the end of the video (frame number 100). On the other hand, Figure 3 shows frames 1, 60, and 110 of the camera2_shot2 video sequence, where the content at the start differs significantly from the ones captured at a later time, that is, frames 60 and 110. Looking at the two figures, it is clear that obtaining the model parameters from the first two frames at the beginning of the video may lead to a large estimation error. In order to tackle this problem, we divide the 10 s video into a number of subshots. In each subshot, bitrate and coding complexity estimation are performed. Figure 4 shows the flowchart of the proposed method to reduce the coding complexity and bitrate estimation error used in this paper. In that figure, the variable frame_num is the current frame number, while k denotes the length of a subshot in terms of the number of frames. Note that since the video is divided into

Content changes during a 10 s camera1_shot3 video sequence. (a) Frame 1; (b) frame 70; (c) frame 100.

Content changes during a 10 s camera2_shot2 video sequence. (a) Frame 1; (b) frame 60; (c) frame 110.

Flowchart for complexity and bitrate estimation error calculation.
In [30], the estimation error is calculated as the average estimation error of all the subshots. However, in order to provide a fair comparison, we calculate the estimation error from the complexity per second (

2.6. Analysis of the Model
In order to estimate the modeling error, the root mean square error (RMSE) of the coding complexity and bitrate for
Test sequences.

Table 3 shows the coding complexity estimation error of all test sequences and different values of k. The table shows that, in general, the coding complexity estimation error decreases as we use a larger number of subshots, that is, using smaller k values. We can also see that the proposed method manages to reduce the coding complexity estimation error in 11 out of 16 cases when k is set equal to 45. On the other hand, using
Coding complexity estimation error for different values of k.


Measured and estimated coding complexity for different values of k and GOP sizes for video sequences (a) TS4 and (b) TS9.
Furthermore, Table 4 shows the bitrate estimation of all test sequences and different values of k. Similar to the coding complexity case, the table shows that, in general, the bitrate estimation error decreases as we use smaller k values. We can also see that the proposed method manages to reduce the bitrate estimation error in 12 out of 16 cases when k is set equal to 45. However, when k is set equal to 60, the bitrate estimation error is reduced in 13 out of 16 cases. The highest error reduction is obtained in the case of the TS9 video sequence. In this particular video, the RMSE of the bitrate model for
Bitrate estimation error for different values of k.


Measured and estimated bitrate for different values of k and GOP sizes for the video sequences (a) TS4 and (b) TS9.
The results analyzed in the previous paragraphs show that, by dividing the video sequences into a number of subshots, the model estimation error is reduced. The results also show that the reduction of the estimation error varies from one video to another. However, it is observed that setting
3. Power Consumption Estimation and Analysis
The power consumption of a video node in a VSN consists of encoding energy consumption and communication power consumption. The power consumption for encoding is estimated as follows:
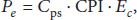

For our analysis, we use the topology shown in Figure 1, consisting of four video nodes and a sink. The parameters shown in Table 5 are used for the experiments. In order to analyze the effect of different video sources and encoding configurations, two sets of experiments are conducted. In the first experiment, the nodes' encoder parameter settings are set to be the same in all scenarios. However, the video sources used in each scenario vary. On the other hand, in the second experiment, the nodes are configured to use the same set of video sources in all scenarios, while the nodes' encoding parameter settings and the nodes' distance to the sink are varied.
Parameters used.

The scenarios' configuration for the first experiment is shown in Table 6. In the first scenario, the VSN nodes are using the videos obtained from the first shot: camera1_shot1, camera2_shot1, camera3_shot1, and camera4_shot1. On the other hand, in the second scenario of the first experiment, the videos used are the videos obtained from the second shot and so on. Note that, for this experiment,
Experiment 1 scenarios.


Nodes' power consumption in experiment 1: (a) scenario 1, (b) scenario 2, (c) scenario 3, and (d) scenario 4.
In the second set of experiments, the VSN nodes are set to use the videos from the first shot. However, the nodes' distance to the sink and the GOP size are varied.
Experiment 2 scenarios.


Nodes' power consumption in experiment 2: (a) scenario 1, (b) scenario 2, (c) scenario 3, and (d) scenario 4.
4. Conclusion
In this paper, we have proposed a new scheme for estimating the VSN power consumption. The scheme is based on using a coding complexity and bitrate model that incorporates some important encoding parameter settings. Through an adaptive scheme for adjusting the model parameters, we showed that the model estimation error could be reduced. Using our model, we analyzed the VSN node's power consumption under different scenarios that involved the use of various video content, encoding configurations, and nodes' distance from the sink. We showed that the VSN nodes' power consumption depends on the encoding parameter settings, the complexity of video content captured by the node, and the VSN topology. In our future work, in addition to the encoding parameters, we take into account the spatial and temporal complexity of the content. We also plan to include more complex VSN topology in our study, where some nodes may need to send their data through intermediate nodes. Thus, in order to find the optimal configuration for each node, the nodes' reception power consumption needs to be taken into account. Also, in order to comply with the bandwidth constraint, we may need to consider using different QP settings for different VSN nodes.
Footnotes
Disclaimer
The statements made herein are solely the responsibility of the authors.
Conflict of Interests
The authors declare that they have no conflict of interests.
Acknowledgment
This work was supported by NPRP Grant no. NPRP 4-463-2-172 from the Qatar National Research Fund (a member of the Qatar Foundation).