
Abstract
Adopting filtering mechanism of dynamic filtering windows installed on sensor nodes to process top-k queries is an important research direction in wireless sensor networks. The mechanism can reduce transmissions of redundant data by utilizing filters. However, existing algorithms based on filters consume a vast amount of energy due to filter updating. In this paper, an energy-efficient top-k query technique based on adaptive filters is proposed. Due to updating filters consuming a large amount of energy, an algorithm named FUGPR based on Gaussian process regression to process top-k queries is provided for saving energy. When the filters change, the sensor readings are predicted to calculate the updating costs of filters; then FUGPR decides whether the filters need to be updated or not. Thus, the energy consumption for updating filters is decreased. Experimental results show that our approach can reduce energy consumption efficiently for updating filters on two distinct real datasets.
1. Introduction
With the improved recognition to the physical world and the rapid development on technologies such as electron and wireless communication, wireless sensor networks have been applied to many areas such as military, medical treatment, and environment surveillance. The bright future of wireless sensor networks has attracted the attention of so many scholars. In wireless sensor networks, sensor nodes are energy-limited which are powered by batteries. In addition, various kinds of sensors generate a large amount of data. If all the data is sent to the base station, much energy will be consumed and sensors will run out of energy soon.
For large quantity of data generated by wireless sensors, users are always interested in max or min k objects among them. People are often interested in the k maximum or minimum values in a wireless sensor network. A top-k query which returns k sensor nodes with the highest readings can meet the requirements above. Top-k queries have been widely used in wireless sensor networks [1]; for instance, it can be used to effectively monitor environmental and ecological changes. Assume that there are many bird feeders placed in a forest, each of which includes a sensor node. These sensor nodes can detect weight changes to count the number of birds landing at the feeder; thus ornithologists can estimate the number of birds in different areas and choose k areas to observe living habits of birds. Yet, some sensor nodes frequently become the top-k queries candidate sets. After several runs of top-k queries, some failed nodes will emerge, because these nodes frequently perceive and transmit data. According to the top-k query semantic of the example above, the k best sensor nodes often become failed nodes. After that, the top-k query results can not reflect the true distribution of the birds in the forest due to the failed nodes whose energy is exhausted.
To answer top-k queries in wireless sensor networks, a typical solution is by making the use of filters. Filters are broadcasted into the network and used by individual sensor node to decide whether its value is relevant to compute the query result. FILA (filter based monitoring approach) [2, 3] is an energy-efficient approach among these algorithms. The basic idea of FILA is to install a filter at each child sensor node, which avoids redundant data transmitting to parent nodes or base station. However, the approach consumes much energy on updating filters. Eager filter update policy in FILA updates windows parameters immediately once sensor readings violate the filters while lazy update policy cannot guarantee the updated filters need not be reupdated to the old ones in next epochs. By predicting future sensor readings, we can decide whether it is necessary to update current filters for saving energy in a long period. Mai et al. [4, 5] proposed DAFM algorithm according to FILA. The algorithm predicts the next sensor readings of sensor nodes by linear regression model. Then, the base station decides whether to update filtering windows based on predicted benefits. When sensor data satisfies complicated distributions and varies widely over time, the predicted performance of linear regression is unsatisfactory and the performance of DAFM algorithm gets worse. These issues are essential to top-k queries in wireless sensor networks and are investigated in this paper. The contributions of this paper are summarized as follows: We adopt a powerful Gaussian process regression (GPR) model to predict next s steps’ sensor readings based on historical sensor data. The GPR model is suitable for sensor data due to the temporal correlations. Our proposed filter updating based on Gaussian process regression (FUGPR) approach focuses on reevaluation when filters need updating. FUGPR introduces prediction mechanism to achieve less energy consumption compared to eager filter update and lazy update policies in FILA approach. Also, comparing to DAFM approach, our FUGPR approach guarantees smaller mean squared error thus can perform effectively. Instead of one-step-forward prediction of DAFM approach, we adopt adaptive s step prediction based on prediction errors. To select suitable s values based on specified sensor data, FUGPR outperforms existing approaches. Extensive experiments are conducted to evaluate proposed FUGPR approach by using real data traces. The results show that our FUGPR approach outperforms DAFM, FILE-e, and FILA-l in terms of both energy consumption and network lifetime under single hop and multihop network configurations.
The rest of this paper is organized as follows. In Section 2, we discuss related work. Typical filtering methods for top-k query processing are introduced in Section 3 and our proposed FUGPR algorithm is provided in Section 4. In Section 5, extensive simulations are conducted to show the efficiency and accuracy of the proposed method. Finally, we conclude this paper in Section 6.
2. Related Work
A naive implementation for monitoring top-k query is to use a centralized approach in which all sensor readings are periodically collected by the base station, which then computes the top-k result set directly. The most predominant algorithm for top-k processing is the Threshold Algorithm (TA) [6]. Along with TA algorithm, Cao and Wang [7] developed a three-phase protocol (TPUT) which decreases the number of remote accesses in large distributed networks. Theobald et al. [8] introduced a family of approximate top-k algorithms with probabilistic guarantees for multidimensional data. By extending TPUT algorithm, Michel et al. [9] proposed the KLEE algorithm to provide approximate answers which provides an adaptive framework to allow trade-off efficiency against result quality and network bandwidth. Zeinalipour-Yazti et al. [10] proposed UB-K and UBLB-K algorithms that return upper/lower bounds instead of exact answers. Also, approximate evaluation of top-k queries has also been proposed by Silberstein et al. [11] based on sampling approaches.
In the area of wireless sensor networks, energy-efficient query processing has always been an important issue. A wireless sensor network can be viewed as a distributed network which consists of lots of energy-limited sensor nodes, and communication cost is the main energy consumption. Therefore, there is no doubt that the centralized approach will consume extra energy because of the transmission of massive data. Filtering and aggregation are two main strategies at present that cope with each other to process top-k queries in wireless sensor networks. In order to reduce the communication cost in data collection, Madden et al. [12] proposed an in-network aggregation technique, known as TAG, which keeps unavailable data from transmission compared with centralized algorithms. Similar to TAG, Cougar [13] and Kspot [14] also employ a centralized optimizer to coordinate sensor nodes in an energy-efficient manner. Chen et al. propose QF (Quantile Filter) [15] approach which treats sensing values and its sensor as a point. The goal of algorithm is to decrease energy consumption and prolong the lifetime of network which is not only minimizing the total energy consumption, but also consuming less energy on each node. Recently, they develop online algorithms for answering time-dependent top-k queries with different values of k through the dynamic maintenance of a materialized view that consists of historical top-k results [16]. Liu et al. [17] propose a new cross pruning (XP) aggregation framework for top-k query in wireless sensor networks. There is a cluster-tree routing structure to aggregate more objects locally and a broadcast-then-filter approach in the framework. In addition, it provides an in-network aggregation technique to filter out redundant values which enhance in-network filtering effectiveness. Abbasi et al. [18] proposed MOTE (model-based optimization technique) approach based on assigning filters on nodes by model-based optimization. Nevertheless, it is an NP-hard problem on how to get optimal filter settings for top-k set.
However, these approaches incur unnecessary updates in the network and are not really energy-efficient. Olston et al. [19] propose the range caching mechanism for approximate query processing. In range caching mechanism, the base station caches a value range for each sensor node and computes a tentative result based on cashed value ranges. The cashed values are refreshed only when the new values on the sensor nodes violate the ranges. Also, Olston et al. [20] use filters to bound error in query result over distributed streams. An adaptive scheme is proposed to reduce the communication cost by precision adjustment at each individual source. Inspired by the filter based ideas [19, 20], Wu et al. [2, 3] propose FILA approach for top-k monitoring, which is to install a filter on each sensor node to filter out unnecessary data not contributed to final results. Reevaluation and filter setting are two critical aspects that ensure the correctness and effectiveness. When the new filters are different from the old ones maintained by sensor nodes themselves, base station needs to update them. But when sensing values on nodes vary widely, base station needs updating filters to related nodes frequently which leads to large scales of updating cost and makes the performance of algorithm worse. Mai et al. [4, 5] propose DAFM approach which aims to reduce the communication cost of sending probe messages in reevaluation process as well as the transmission cost in filter updating in FILA. DAFM approach predicts the next readings of sensor nodes to determine these values are in or out of filtering windows by linear regression models. To some extent, this approach decreases the cost of filter updating. However, the sensed values are affected by various factors; the performance is worse when adopting linear regression models to predicate future sensor values. In our previous work [21], time series models are adopted for predicting next sensor values for unnecessary filter updates. However, this approach is more suitable for specific sensor data, that is, time series data distribution and not energy-efficient for non time series sensor data.
3. Filter Based Top-k Query Methods
We first give a formal definition in Section 3.1. Then, Section 3.2 provides filter based top-k query methods and discusses the limitations of existing methods.
3.1. Problem Definition
We consider there are N sensor nodes in a wireless sensor network labeled
3.2. Filter Based Top-k Query Processing
3.2.1. An Overview of Filter Based Methods
To reduce network traffic in data collection, TAG [12] as an in-network aggregation technique has been proposed. The topology of the sensor network can be assumed as a spanning tree rooted at the base station. In TAG solution for monitoring top-k queries, every intermediate node of the spanning tree collects all values from its children and forwards the k largest of these values to the base station. Although TAG achieves a reduction of the number of transmitted values by aggregation, the number of messages remains high. Consider the situation that the final k largest values fall in one branch of the spanning tree at some level; the readings of other branches do not need to be forwarded. Therefore, TAG incurs unnecessary transmissions in the network and is not energy-efficient.
Range caching method was first provided by Olston et al. [19, 20] and later utilized by Wu et al. [2, 3] to process top-k queries in wireless sensor networks. The base station cashes a value range α for the value at each sensor node. If sensed value is
To overcome the defect of range caching method, Wu et al. [2, 3] proposed FILA to process top-k queries in sensor networks. At the beginning of FILA, the base station collects the readings from all sensor nodes and sorts the sensor readings to obtain the initial top-k result set. Then the base station calculates a filter
(1) Filter Setting. At the beginning of FILA method, the base station has obtained the sorted readings of all the sensor nodes
To maximize the filtering capability, the upper bound of the top-1 node's filter


Filter setting.
(2) Query Reevaluation. In FILA, if there is at least one sensor reading sent to the base station for filter violation, the top-k results become undecided at the base station. Then the base station should probe some related sensor node(s) to reevaluate the top-k results.
When the updated reading overlaps with the filter of any other sensor node, there are three situations for this update.
Internal Update. An update originated from a top-k node jumps into the filter of another top-k node. For example, as shown in Figure 2(I),

Three situations of windows update.
Join Update. An update from a non-top-k node jumps over the critical bound and falls into the filter of a top-k node. For example, as shown in Figure 2(II),
Leave Update. An update from a top-k node jumps over the critical bound and falls into the filter of non-top-k nodes. For example, as shown in Figure 2(III),
It is obvious that if an update is an internal or a join one, then only the relevant top-k node whose filter covers the updated sensor reading needs to be probed to reevaluate the top-k result. Otherwise, a leave update from a node
(3) Filter Updating. When sensor readings pass their filters, the filter settings of corresponding sensor nodes need to be recomputed and the base station will send the new filtering windows to the nodes for installation. There are two approaches for updating the filter of each node
Eager Filter Update. If a new filtering window is different from the old one, then the new filter computed by the base station is immediately sent to the node
Lazy Filter Update. If a new filtering window
When top-k result set changes, the filters of the sensor nodes will also change. We demonstrate above two updating policies using the example shown in Figure 3. In Figure 3, we only consider four sensor nodes

Changes of filter window.
We can see that lazy filter update policy is naive and not energy-efficient. Due to delay of the filter updating to some sensor nodes, the gap between adjacent filters will occur as illustrated in Figure 4 which decreases the filtering capability. In addition, lazy filter update is a suboptimal method because the total number of filtering updates remains in a high level and consumes much energy though the number of updates is reduced for one time filter update.

Existence of the gap between windows.
3.2.2. Defects of FILA
To some extent, FILA avoids redundant data from transmission and saves energy. However, there is massive unnecessary energy consumption. Assume that after sampling in epoch t, the filtering windows are shown in Figure 5 [5]. In Figure 5(a), at epoch

Frequent updating of the filters.
In addition, from Figure 5, the values on the non-top-k vary in a small range; their filtering windows are useful to filter out irrelevant sensor nodes. However, the upper bound of non-top-k nodes is determined by the values of ith and
In this paper, we adopt Gaussian process regression to alleviate the burden of filter update in FILA. When the filters change, the sensor readings are predicted by Gaussian process regression to calculate the updating costs of filters. An algorithm for top-k processing under FILA framework named FUGPR is provided. FUGPR reduces the cost of filter updating when fluctuation of sensor readings occurs and prolongs the lifetime of the wireless sensor network.
4. Filter Updating Algorithms
FUGPR is efficient top-k processing method based on predicted benefits of Gaussian process regression [22, 23]. Gaussian processes let the data “speak” more clearly for themselves. Gaussian processes extend multivariate Gaussian distributions to infinite dimensionality. Formally, a Gaussian process generates data located throughout some domain such that any finite subset of the range follows a multivariate Gaussian distribution. Under Bayesian linear regression framework, a Gaussian process predictor calculates posteriors from priors over functions rather than from priors over parameters [24]. Gaussian process regression has been widely exploited in many research topics, such as human motion estimation and time series prediction [25]. Recently, Gaussian process approach has been adopted for predicting of monitoring models over distributed data streams [26] and real-time sensor data processing in wireless sensor networks [27].
In FUGPR, each node in the top-k list has a separate filter while all the remaining non-top-k nodes share a common one. This setting is along with the framework of FILA. The
4.1. Gaussian Process Regression for Prediction
We predict next epochs’ readings of a sensor node on their temporal correlations. The very simple example is to predict next epoch's sensor value based on current reading. For l step prediction, we assume
To facilitate the calculation, we only focus on energy consumption resulting from communication and omit other aspects of energy consumption. The assumption is reasonable for the communication of wireless sensor networks is main aspect of energy consumption. The total amount of energy spent in sending a message with m bytes of content is given by
Typical values for energy calculation.

From Table 1, we can learn that the energy consumption of communication is higher than data transmission. In order to reduce the number of communications, each transmission the sensor node sends more bytes for saving energy. In FUGPR, readings fallen in their corresponding filter need not be sent to the base station while the violated sensor readings along with their past p readings are sent to the base station together. For each sensor node, the p value is learned from the historical data at the base station. The p value can not be a large number because transmitting too much data will also consume much energy. In this paper, the p value varies from 1 to 5. We choose the p value with the minimum squared error (MSE) for the Gaussian process regression in FUGPR. At the base station, for each sensor node we use Gaussian process regression model on historical dataset
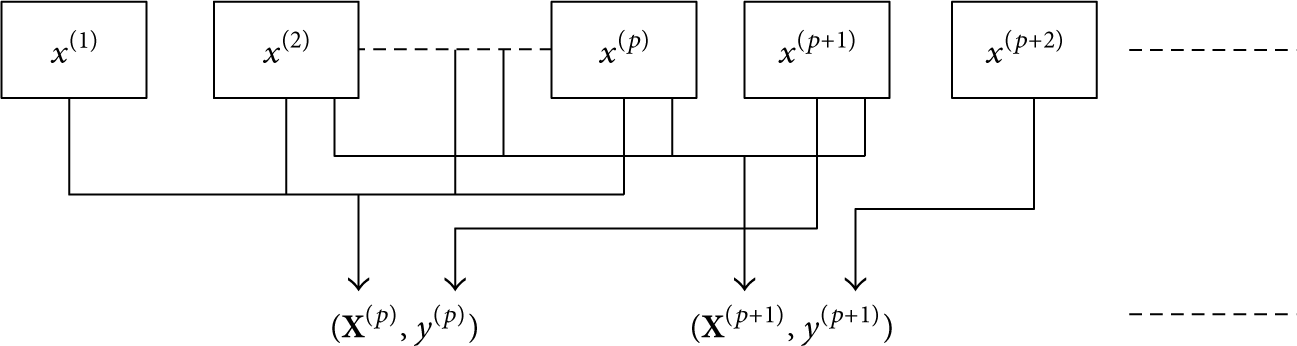
Construction of the training dataset.
To each sensor node, we use several past reading as the input and the reading at next epoch as the output; we can obtain the following equation through a Gaussian noise model:
Users often expect the underlying function 
Due to various sensor readings from real applications in wireless sensor networks, the prerequisites of linear regression method are not satisfied. Besides linear regression models, other analogical models may use the principles of model selection to choose among the various possibilities for we suspect
We illustrate Gaussian process regression as shown in Figure 7. For simplicity, we consider one-dimensional input space. The solid points are real sensor readings, the solid line indicates an estimation of prediction values for the real sensor readings, and the shaded region denotes 95% confidence intervals along with the regression line. If current sensor reading of a sensor node is 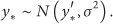

An example for Gaussian process regression.
4.1.1. Gaussian Process Regression
A Gaussian process is a collection of random variables, any finite number of which has a joint Gaussian distribution. In general, a Gaussian process is completely specified by its mean function
If there are m items in the training dataset 
When a new sensor reading 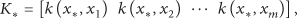
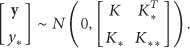
According to Bayesian rules, we can obtain
The mean value and variance of 
When given a new sensor reading
4.1.2. Training Gaussian Process Regression Models
How well does the selection of the covariance function decide the reliability of our regression process? The procedure mainly lies on the characteristics of the training sensor readings. In the Gaussian process literature, a popular choice is the squared exponential (SE) covariance function which is also adopted in our paper. Consider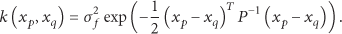
When folding the noise 
In the above equation, if
After covariance function is chosen, we call its parameters hyperparameters. Take the covariance function 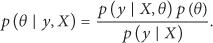
Assuming we have little prior knowledge about what θ should be, Bayes's theorem tells us this corresponds to maximizing 
For 
The log-style 
Simply run the favorite multivariate optimization algorithm (e.g., conjugate gradients, Nelder-Mead simplex) on this equation and a pretty good choice for θ will be found.
4.2. Optimization Strategies of Filter Updating
If the new reading of one sensor node is without its filters, then an update is sent to the base station. Now, the update is jump into other nodes’ filter; the top-k results become undecided at the base station. Therefore, the base station should probe some related sensor node(s) to reevaluate the top-k results. These nodes which should send their new readings to the base station need to wrap up the p readings of current and past epochs and then utilize Gaussian process regression for prediction to ascertain the means and variances of future readings. For these sensor nodes whose readings are not updated, the means and variances of their future readings still maintain the recent ones.
Assume the new reading of a node 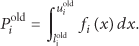
And the probability of the real reading of 
Let
If the base station needs updating the filters, the cost of using the new filters at the future s epochs is referred to as costnew. Otherwise, the cost of using the old filters is denoted as costold. If 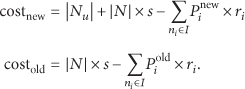
In formula (18),
5. Experiments
5.1. Experiments Settings
We use two real datasets: Intel Lab data and LEM data to conduct our experiments.
Intel Lab Data. The set contains information about data collected from 54 sensors deployed in the Intel Berkeley Research Lab [30]. We partition the sensor network into some nonoverlapping regions, making the sensors with positions close to each other in the same area. In this paper, we do not research in depth in how to partition regions more reasonably and only partition the sensor network based on location information by using the k-means algorithm. Taking an example of the Intel Berkeley Research Lab wireless sensor network, we partition it into 10 regions. Figure 8 shows the result of region partitioning, where the dark nodes denote the initial center points. We adopt

Sensor node topology of Intel Berkeley Research Lab.
LEM Data. The dataset is collected from the Live from Earth and Mars project at the University of Washington [31]. We adopt
We simulated a single hop network and two multihop networks. The single hop network has 12 sensor nodes as shown in Figure 9(a). The two multihop networks contain

Network layout.
5.2. Experimental Results
We compare our FUGPR with several typical methods, TAG, range caching, and FILA. TAG involves several basic aggregation methods which can be seen as the standards of energy consumption. In range caching method, if two filters are overlapped, the base station may request sensor values to decide final top-k results. In our experiments, the filter window value α for range caching method varies from 0.3 to 3.2 and energy consumptions under different α values are calculated. The α value with the minimum energy consumption is chosen as the final filter window value in our experiments. For FILA method, we adopt lazy filter update policy for our experiments. For our FUGPR method, we use the GPML MATLAB toolbox (http://www.gaussianprocess.org/gpml/) for prediction by our proposed Gaussian process regression models.
Figure 10 shows the comparison of energy consumption for TAG, range caching, FILA, and FUGPR after 1000 runs of top-k queries under Intel Berkeley Lab data:

Comparison of energy consumption of Intel Berkeley Research Lab sensor network.
Figure 11 shows the comparison of energy consumption for TAG, range caching, FILA, and FUGPR after 1000 runs of top-k queries for single hop sensor network. FILA and FUGPR can filter many sensor readings, especially when k is small. When k increases (>7), we can see that FILA consumes much energy. For the

Comparison of energy consumption of a single hop network.
Figures 12 and 13 show the comparison of energy consumption for TAG, range caching, FILA, and FUGPR after 1000 runs of top-k queries for two multihop sensor networks,

Comparison of energy consumption of

Comparison of energy consumption of
6. Conclusion
This paper combines Gaussian process regression models into FILA method and proposes FUGPR method for top-k query processing in wireless sensor networks. The prediction benefits of the Gaussian process regression models reduce the cost for filter updating caused by fluctuation of sensor values. Experimental results show that under two distinct real datasets, for example, Intel Berkeley Research Lab data, LEM data, and simulated single hop and multihop sensor network structures, our proposed FUGPR is prior to TAG, range caching, and FILA methods and thus reduces the energy consumption and prolongs the lifetime of the sensor networks.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This work is partially supported by the Fundamental Research Funds for the Central Universities of China under Grant no. NS2015095.