
Abstract
Cognitive spectrum management can improve the utilization efficiency of spectrum while increasing the energy consumption of sensor network nodes. Hence, how to balance the energy consumption and spectrum efficiency has become a critical challenge in the resource-constrained cognitive radio sensor networks. In this paper, by analyzing the channel characteristics and the energy efficiency of networks, a joint channel selection and power control spectrum decision algorithm based on distributed Q learning is proposed. To evaluate the performance of the proposed framework, an optimal Q value subject to communication efficiency index is formulated. Then, the learning strategy selection scheme is designed to solve the optimization problem by establishing a learning model. In this learning model, each node can get the strategy of other nodes to select the optimal strategy by introducing distributed strategy estimation. The simulation results show that the proposed algorithm has better performance than the existing methods.
1. Introduction
With the rapid development of wireless sensor networks, the traditional fixed spectrum allocation cannot meet the spectrum requirements of radio sensor network, so the cognitive radio sensor network (CRSN) arises at the historic moment [1], whose candidate characteristic is that the cognitive technique can be used for opportunistic spectrum access. But the dynamic spectrum management will increase the energy consumption of nodes while increasing network spectrum utilization [2], which is a severe challenge in CRSN with limited energy, storage, and computing resources. Therefore, how to ensure spectrum efficiency meanwhile without the energy efficiency loss is a critical issue in CRSN.
As the major part of spectrum management [3], spectrum decision is a crucial process in cognitive radio network [4], which can chose the best channels for secondary users to transmit data. Spectrum decision is usually divided into three steps [5], including channel characterization, channel selection, and parameter reconstruction. When the spectrum detected is available, the cognitive nodes will characterize the channel according to the observed local information and the channel statistical information of primary users. Then, nodes will select suitable channels according to these characteristics. Finally, we need to reconstruct the transmission parameters to adapt to the selected channel.
Due to the characteristics of spectrum holes [6], the behavior of primary user is changing over time, and cognitive nodes need to make spectrum decision dynamically to ensure the quality of communication [7]. Therefore, it is very important to seek an efficient spectrum decision method. Current spectrum decision methods can be divided into two categories [8]: the non-load-balancing method and the load balancing method.
For the non-load-balancing spectrum decision method, cognitive nodes can determine the communication channel according to the channel conditions, such as traffic load [9, 10], channel idle probability [11], the expected waiting time [12, 13], the expected remaining idle period [13, 14] or throughput expectation [15, 16]. Most methods have not considered spectrum sharing among cognitive nodes. If all cognitive nodes select the same frequency band for communication, there will exist serious channel competition [17]. In order to solve this problem, some scholars have begun to research spectrum decision methods based on load balancing.
For example, in [18], a spectrum decision method based on game is proposed to balance load, which uses game to seek the optimal channel choice probability. In order to reach the Nash equilibrium, each node relates its utility function to the candidate channel and then calculates the channel selection probability of each channel by the best response algorithm. In [19], a game theoretic framework is proposed to evaluate spectrum decision functionalities in CRSN. The spectrum decision process is cast as a noncooperative game among secondary users who can opportunistically select the “best” spectrum opportunity, under the tight constraint not to harm primary licensed users. However, because the information of each network node is changeable, the player should change their strategies instantaneously to reach equilibrium. It leads to a slow convergence speed. In this context, some scholars have introduced learning methods to solve the spectrum decision problem.
In [20], a method of channel choice probability based on adaptive learning is proposed. By exploring the uncertainty of cognitive network traffic, cognitive nodes can select the optimal channel, but its convergence speed may be slow if the network scale is large. Shiang et al. [21] assume that cognitive nodes have different priorities and present a dynamic strategy learning (DSL) algorithm that dynamically adapts the channel selection strategy to maximize the private utility function of nodes. By using this method, the spectrum decision of the cognitive nodes can reach the equilibrium, but it should be noted that the equilibrium of above method is not the global optimal solution, because each node strategy for spectrum decision is independently.
Energy efficiency has been researched in the current spectrum decision method, but there are still many difficulties, such as how to balance the communication performance and energy consumption, how to reduce the communication overhead, and how to improve energy efficiency and enhance the adaptability; those difficulties limit the application of the existing spectrum decision methods. Therefore, it is particularly important to design a spectrum decision method for CRSN, which can fully improve the efficiency of the spectrum management.
In this paper, we consider current CRSN requirements. By analyzing the network channel characterization and energy efficiency, we design an adaptive spectrum decision framework and propose a joint channel selection and power control spectrum decision algorithm based on distributed Q learning. In this algorithm, each node should consider other nodes strategies when it selects the strategy and then make decision together with other nodes. To evaluate the performance of the proposed framework and balance the energy consumption and spectrum efficiency, an optimal Q value which is subject to communication efficiency index is formulated. Then, the learning strategy selection scheme is designed by establishing a learning model to solve the optimization problem. The effectiveness of the proposed framework is validated by simulations.
The remainder of this paper is organized as follows. Section 2 describes the system model and problem formulation. Learning model and algorithm implementation are discussed in Section 3. Simulation results and analysis are given in Section 4, followed by concluding remarks work in Section 5.
2. System Model and Problem Formulation
In this section, we describe the network architecture and formulate the optimization as a comprehensive evaluation index which is subject to communication efficiency index.
2.1. Network Model
We consider a CRSN environment with some cognitive nodes. As shown in Figure 1. The network based on cluster structure and cluster nodes should cooperate with other nodes to determine the idle spectrum through spectrum sensing. Then, all the network nodes make spectrum decision together and the data is passed to the cluster head from network nodes within one hop, and the cluster nodes pass the data to the sink node with multiple hops.

The network model of CRSN.
In view of the cognitive wireless sensor network (CWSN), considering the general situation, the following assumptions are made throughout this paper.
When the primary users is communicating, its transmission power is very high and CRSN nodes transmission power is relatively small, so, in this case, the network nodes cannot communicate with other nodes. Different cognitive wireless sensor node can be in the same channel for communication, but must adjust their own power to avoid interference with other nodes. In the process of spectrum decision, cognitive nodes do not need to exchange information with each other and select their communication channels and transmission power, respectively, so it can achieve the goal of energy conservation. We assume that the channel state transition probabilities, as well as the channel rewards, are unknown with the secondary nodes at the beginning. They are fixed throughout the learning, unless otherwise noted. Therefore, the secondary nodes need to learn the channel properties. We consider all the noise as Gaussian white noise, and the mean value is 0 and the variance is σ.
2.2. Problem Formulation
2.2.1. Channel Characterization
In order to select appropriate channel, the network nodes must describe the current characteristics of each channel and ensure the current status of its. In this paper, we mainly consider the bandwidth, signal interference, false alarm rate of spectrum detection, and the idle time of band. The idle channel is evaluated whether it is suitable for communication by a comprehensive evaluation index as the current state of the channel. The following factors will be considered to construct the comprehensive index:
channel bandwidth signal interference the band last free time spectrum sensing of false alarm rate
In this paper, we assume that the

2.2.2. Energy Efficiency Analysis
Since cognitive wireless sensor nodes can communicate successfully on the idle channel, the nodes need to adjust the transmission power and optimize the energy efficiency. Due to the multiple nodes communication on the same band, there may exist both Gaussian white noise and mutual interference of each node at the receiving end. On one hand, the network nodes need to increase its transmission power, in order to obtain higher signal-to-interference plus noise ratio (SINR) and higher transmission rate, and then can get a better QoS; on the other hand, the network nodes must reduce the transmission power to achieve the goal of energy conservation, reducing the interference to other nodes at the same time. Therefore, the communication efficiency index is proposed to consider both communication quality and energy consumption, which will be the input of learning algorithm to realize balance.
Compared with the primary user, the CRSN nodes transmit data with low power, so its communication range is small. In this paper, we assume that the communication of each cognitive node is completely sight path, namely, the wireless transmission model is a free space propagation model, in which the channel gain h is as follows:



In order to achieve the equilibrium between communication ability and energy consumption, this paper defines the average number of bits in unit energy as the communication efficiency index:

2.2.3. Joint Spectrum Decision
In this paper, we proposed a joint channel selection and power control spectrum decision, as shown in Figure 2. Firstly, the network nodes must describe the current characteristics of each channel and determine the current status which is considered as the input of distribute Q learning. In order to guarantee the network communications QoS constraints and minimize the energy consumption of the network nodes, this paper considers both channel switching and energy efficiency to design return value and then calculates the instant return values for different network conditions. Finally, we realize the joint channel selection and power control spectrum decision by introducing distributed Q learning algorithm.

Distributed Q learning based energy efficiency optimization with joint channel selection and power control spectrum decision.
In order to balance network communication ability and energy efficiency, we formulate the optimization as follows:

3. Learning Model and Algorithm Implementation
In order to realize the balance of communication quality and energy consumption and optimize the network communication ability in the prerequisite of communication efficiency index, this section presents an adaptive spectrum decision based on distributed Q learning.
3.1. Learning Algorithm Analysis
Reinforcement learning is an on-line technique [22] that considers environmental feedback as the input and learns through constant interaction with the environment, then uses the feedback signal to find the optimal action which adapted to the current environment. Reinforcement learning systems mainly include two parts [23]; they are both environment and agent, and the basic framework is shown in Figure 3.
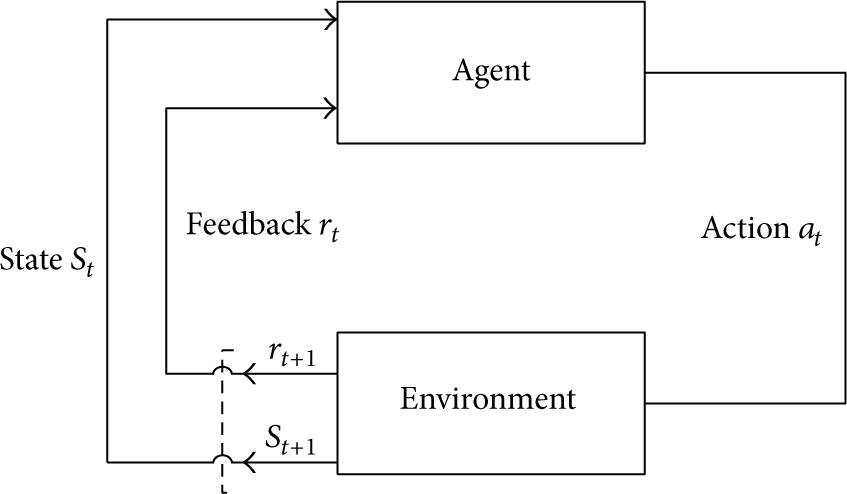
The interaction process of reinforcement learning.
As a model irrelevant learning algorithm, Q learning mainly cares about the evaluation value
Assuming that the state set is

In the strategy selection of learning algorithm, there exists a balance problem of exploration and exploitation. Exploration means the agent continuously updates learning knowledge to find the better strategy; exploitation means the agent selects the optimal action from all the action. In order to solve the balance problem, there are some algorithms like ε greedy algorithm and soft-max algorithm [24]. The ε greedy algorithm adopts random way to search. All the actions are chosen coequally. It means the worst action and the optimal action is chosen with the same probability, which will reduce the efficiency of learning algorithm. However, the soft-max algorithm sets different strategies according to different Q value, and it uses Boltzmann distribution to define action-selection probabilities:

Due to the cognitive wireless sensor nodes that locate in the same network environment, all of the network resources are competed equally. Therefore, the behavior of each node will affect other nodes in spectrum decision, and other nodes may also affect the strategy of this node. So, we must consider the strategy of other nodes in the strategy selection. The formula is shown as follows:

In order to get the strategy of


With the time increase,
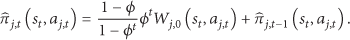
So, the strategy selection method of formula (9) can change to

3.2. Learning Model
In this paper, we consider each network node as an agent which can select communication channel and transmission power adaptively. This dynamic adjustment process can be defined as a Markov decision process (MDP), and its model is made up of a triple
According to the current network environment, network nodes select appropriate communication channel and transmission power to transmit data. Now, we define state, action, and reward function, respectively.
State
Action
Reward Function collision with primary user: due to the fact thatthe behavior of primary user is unpredictable and spectrum detection has a certain error, network node may conflict with the primary user when it selects a channel for communication. Then, we define the reward value as the lowest −0.5; channel switching: when the interference of current communication channel increased or the primary user suddenly appeared, nodes require switching of the channel. But switching the channel frequently will lead to excessive energy consumption, so we should avoid the channel switching times and set the reward value as −0.1; power adjustment: when the network nodes are working in a normal communication channel, it declare that this channel can satisfy the communication conditions of nodes, and nodes only need to adjust their power to achieve QoS and energy consumption constraints. So, we define the communication efficiency index in formula (5) as the reward value, but the SINR must satisfy constraint (4); otherwise, the reward value is 0.
Integrating all the situations, reward function
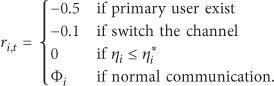
After the nodes obtain the free frequency band by cooperation, each node has competition with other nodes in the available channel for data transmission. The environment of CRSN is dynamic and complex networks, whose states are affected by many factors, which require network nodes to adjust the communication parameters adaptively and reduce the interference of each node as far as possible and then maximize the network energy efficiency under the demand of a certain communication at the same time. The transmission power is also different when the nodes work in different channel for wireless communication environment. Good channels only need a little transmission power, while poor channels need to increase transmission power to guarantee transmission. Therefore, the joint decisions for communication channel and transmission power can meet the demand of communication and energy efficiency.
In this paper, a joint spectrum decision of channel choice and power control based on distributed Q learning is proposed. By considering the energy efficiency and QoS constraints and reducing energy consumption as far as possible, we can achieve the purpose of extending network survival time. In order to save energy and reduce the communication overhead, this paper adopts the distributed Q value updating method, as shown in formula (7).
The joint spectrum decision of channel choice and power control with distributed Q learning is shown in Algorithm 1, and the flat chat of this algorithm is shown in Figure 4.
The initial learning rate optimal strategy (1) Initialize the learning strategies (2) Each node obtains the network state information of current available channel; (3) Calculate the comprehensive evaluation value according to the formula (1) to determine the state input of learning algorithm; (4) If the network state changes, then skip to Step 5, and need to select the channel and power again, otherwise skip to Step 8, and the nodes can communicate normally; (5) Calculate the reward value immediately and update the learning rate, then use the formula (7) to update the Q value table; (6) Record and estimate the strategy of other network nodes, and use the formula (12) to update the node strategy; (7) According to current strategy select the optimal action (8) If the quality of the selected channel is poor, namely and now the reward value is −0.1; (9) If the primary user appears in the communication process, then need to return to Step 2 and determine the idle spectrum set and network state again;

The flow chats of the joint spectrum decision algorithm based on distributed Q learning.
4. Analytical and Simulation Result
In this paper, we assume that there are six fixed clusters and a sink node in the CRSN, where each cluster is made up of 10 nodes, and each node selects appropriate channel and transmission power for data transmission. The radius of cluster is 70 m, and each cluster contains three primary users, whose transmission power is larger than other cognitive nodes. Assume that there are 20 authorized bands, including 4 VHF-TV bands, 4 AMPS bands, 4 GSM bands, 4 CDMA bands, and 4 WCDMA bands, and their bandwidths are 6 MHz, 30 KHz, 200 KHz, 1.25 MHz, and 5 MHz. The power of Gaussian white noise is
In this section, we will use the following performance indicators to evaluate the performance of the proposed algorithm, which will be compared with game algorithm and dynamic strategy learning algorithm, respectively:
energy efficiency: the number of bits per unit energy transmission. It is an important index in this paper and it reflects the situation of energy utilization; average channel switching times: the average channel switching times of network nodes in the whole communication. The smaller the value the better the algorithm, and it can reduce the energy consumption indirectly; average throughput: the number of bits per unit time in 1 Hz bandwidth. The index reflects the influence of the QoS of communication; successful transmission probability: the probability of successful communication for nodes in idle channel. The index reflects the advantages and disadvantages of the strategy and algorithm.
In Figure 5, we can see the changes of energy efficiency for different algorithms. Each algorithm will reach the convergence as time goes on. And we can find that the dynamic strategy learning algorithm can reach convergence quickly, but since there is no consideration about other nodes' strategies when the node selects strategy, it cannot realize the high energy efficiency. The spectrum decision based on game is better than dynamic strategy learning in energy efficiency but has inferior performance compared to the distribute Q learning, due to more information exchanged and more iteration needed in game framework. From Figure 5, it is shown that the distributed Q learning algorithm has the best energy efficiency and fastest convergence, because it considers the selection influence of both channel and power.

The energy efficiency of network node.
Figure 6 is the average channel switching times, it shows that the channel switching times of the proposed algorithm are convergent to 0.9, while dynamic strategy learning is convergent to 1.4 and the algorithm based on game is convergent to 3.6. Spectrum decision based on game algorithm requires communication between each node to follow the changes of nodes' information, so it needs most of the channel switching times. For the dynamic strategy learning method, because it did not consider the strategy of the other nodes, it may not choose the optimal channel, requiring the adjusting of the channel from time to time. The proposed algorithm has carried on the comprehensive evaluation and also considered the estimation strategy of other nodes for channel and power choice. Thus, it can choose the best channel and power, which has the fewest channel switching times and then reduce the energy consumption.
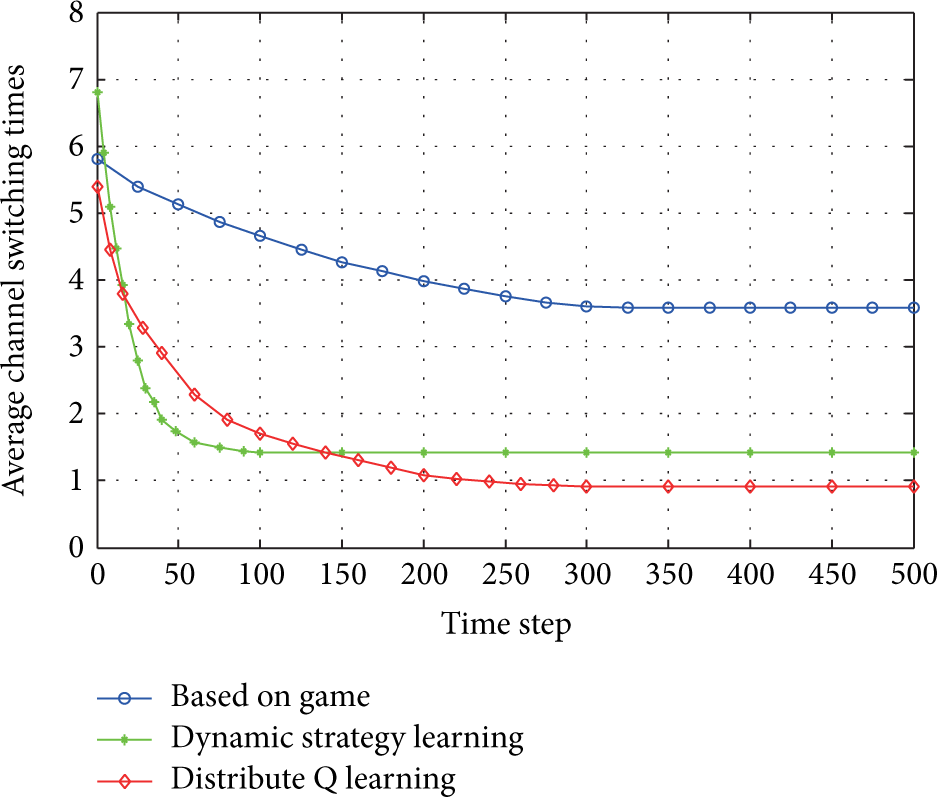
The average channel switch times of network node.
The comparison of the average throughput in CRSN is shown in Figure 7. It is shown that the proposed algorithm has the best network performance, and its throughput is superior to other algorithms. Compared with other algorithms, the proposed algorithm let each node get other nodes' strategies to select the optimal strategy by introducing distributed strategy estimation. Thus, it can select optimal channel and transmission power quickly, improving the rate of the data transmission. Therefore, the proposed algorithm can provide better QoS guarantee for CRSN.

The average throughput of network node.
As shown in Figure 8, the algorithm based on game can reach 82.8%, the algorithm based on dynamic strategy learning can reach 87.6%, and the proposed algorithm can achieve 93.8%. Because there existed strategy estimation between the nodes when selecting channel and power, the proposed algorithm can get the optimal selection strategy. Thus, it can achieve high success rate for data communication in CRSN. However, the dynamic strategy learning and game algorithm do not consider other nodes' strategies, so it cannot guarantee the global optimum and have inferior transmission rate compared to the proposed algorithm.

The successful transmission probability of network node.
5. Conclusion
In this paper, we consider the requirements of current CRSN and design an adaptive spectrum decision framework by analyzing the network channel characterization and energy efficiency. To balance the energy consumption and spectrum efficiency of this framework, we adopt a distributed Q learning algorithm to implement channel selection and power control jointly, which takes channel state as the input and takes the selected channel and transmit power as the output. By using this algorithm, the network nodes can get the optimal transmitted power and communication channel to guarantee the energy efficiency and spectrum efficiency simultaneously. Future works will focus on the restraining the interference of data transmission between secondary nodes when selecting the idle channel.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
The authors would like to acknowledge that this work was partially supported by the National Natural Science Foundation of China (Grant nos. 61379111, 61202342, 61402538, and 61403424) and Research Fund for the Doctoral Program of Higher Education of China (Grant no. 20110162110042).