
Abstract
Information diffusion is efficient via gossip or rumor spreading in many of the next generation networks. It is of great importance to select some seed nodes as information sources in a network so as to maximize the gossip spreading. In this paper, we deal with the issue of the selection of information sources, which are initially informed nodes (i.e., seed nodes) in a network, for pull-based gossip protocol. We prove that the gossip spreading maximization problem (GSMP) is NP-hard. We establish a temporal mapping of the gossip spreading process using virtual coupon collectors by leveraging the concept of temporal network, further prove that the gossip spreading process has the property of submodularity, and consequently propose a greedy algorithm for selecting the information sources, which yields a suboptimal solution within
1. Introduction
Information dissemination through networks is ubiquitous in the modern world [1–6], and gossip or rumor spreading is an efficient way of information diffusion: imagine that a rumor arises in a town and is epidemically like spread among the whole population [7]. There are two atomic types of gossip protocols: “pull,” an uninformed node requests an unpossessed message from a randomly chosen neighbor, and “push,” an informed node sends its possessed message to a randomly chosen neighbor. Gossip-based algorithms are simple, robust, flexible, and scalable and hence are promising for many of the next generation networks [8]. Existing applications are numerous, such as consensus and averaging problems in sensor networks [9, 10], ad hoc message routing [11], peer-to-peer (P2P) file distribution [12], and information dissemination in social networks [13].
Most existing analytical works on gossip spreading have dealt with (high probability) upper bounds of the completion time, disregarding the choice of information sources [7, 8, 12–15]. Given a static connected network graph, the completion time of a gossip protocol is the first time at which all the nodes are informed. Recently, the issue on the selection of information sources for gossip spreading has been treated in our previous work [16]. However, in [16], only the push-based gossip protocol was considered and the complexity issue of the gossip spreading maximization problem was left open.
In this paper, we consider the problem of selecting information sources for gossip spreading, focusing on the pull-based gossip protocol. The information sources are initially informed nodes (i.e., seed nodes) in a network. We ask the question: given a general network graph, the budgeted size of a seed set, and a constrained deadline, how to pick the elements in the seed set, which will be endowed with an identical message to be propagated to the rest of the network, such that the expected number of informed nodes is maximized within the deadline. The gossip spreading maximization problem (GSMP) frequently arises in many scenarios, especially when a popular content is demanded by a group of nodes. In sensor networks, one needs to decide the deployment of key sensors, capable of detecting and issuing emergence with the other hearing-and-forwarding sensors, so as to maximize the alarming area as quickly as possible. In P2P networks, one needs to decide the best choice of seeds so as to maximize the file distribution before delay tolerance. Besides, similar research topics can be found in viral marketing (a.k.a. influence maximization), detection of disease outbreak, and opportunistic cellular traffic offloading [17–19].
Our contributions are as follows.
Our work differs from previous works in several aspects. First, we deal with GSMP by selecting influential information sources, different from the analytical works on high-probability completion time (see, e.g., [8]). Second, we study GSMP in the area of gossip spreading and treat it using the coupon collecting and temporal mapping method, while the influence maximization problem is related to the social influence diffusion models and is treated with the coin flipping and equivalent view method (see, e.g., [17]). Third, beyond our previous work [16], we have focused on the “pull” model, rigorously proved the NP-hardness of GSMP, and leverage the new temporal mapping method to analyze the submodularity of gossip spreading.
The rest of this paper is organized as follows. Section 2 describes the pull-based gossip protocol and formulates the gossip spreading maximization problem. We analyze the complexity of GSMP and show its NP-hardness in Section 3. We recognize the submodularity in gossip spreading via a temporal mapping method and propose a suboptimal solution with performance guarantee for GSMP in Section 4. We carry out simulation experiments to study the spreading performance of our approach in Section 5. Finally, Section 6 concludes this paper.
2. System Model and Problem Formulation
In general, a directed network graph
Time is slotted and a message can be transferred from a sender to a receiver within a time slot, which is called round throughout this paper. No matter which content the information flow over the underlying network is carrying, we focus on only one piece of message in our model.
2.1. Gossip Protocol
The type of gossip spreading considered in this paper can be called multiple sources with single message [16]: initially the nodes in a seed set S become informed with an identical message, and all the other nodes wish to receive a copy of that message. Any uninformed node v can pull the message from one informed neighbor, which is connected to v by an incoming edge in E. That informed neighbor can belong to either the seed nodes in S or the other initially uninformed nodes that have already obtained the message.
In each round, the nodes in the network G contact their neighbors in the following manner: each of the uninformed nodes picks a partner uniformly at random from the set of all its neighbors (connected by incoming edges), oblivious of any state, history, or other nodes' choices. Once a partner is chosen, the uninformed node pulls its desired message from the chosen partner.
In any given round, an uninformed node can pull from only one partner, and it becomes informed if its chosen partner has already possessed its desired message and remains uniformed if this partner does not possess this message. Once a node gets informed in some round, it will stay informed forever. All communications are assumed to be error-free with error control coding and protocol overhead encapsulated by physical-layer design, which are not considered herein.
2.2. Problem Formulation
Consider the sample space Ω, where each sample specifies one possible realization of the gossip spreading process. Let X denote one sample in Ω, and let
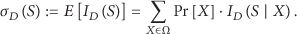
Given a directed network graph

3. Complexity Analysis
GSMP belongs to the field of stochastic programming, and we show that it is NP-hard in this section.
3.1. Preliminary
First of all, we consider the decision version of GSMP.
Problem 1 (gossip spreading decision problem).
Given a network graph
We see that
Problem 2 (partial set cover problem).
Given a ground set
3.2. GSMP is NP-Hard
Next we show that GSMP is NP-hard using a reduction from the NP-complete
Theorem 3.
The gossip spreading maximization problem (GSMP) for the pull-based gossip protocol is NP-hard.
Proof.
Consider an arbitrary instance of the partial set cover problem
If we can find h of the subsets in C such that the cardinality of their union is at least p, then we will show that h nodes can be found in
Conversely, if we can find h of the nodes in
In total, if the gossip spreading decision problem can be solvable, then the partial set cover problem must be solvable; that is, the decision version of GSMP is at least as hard as the NP-complete partial set cover problem.

Illustration of a directed bipartite graph
Remark 4.
The above arguing method can be applied in analyzing the complexity of GSMP under the “push” model. Since GSMP is NP-hard and polynomial-time algorithms have not yet been discovered for the class of NP-hard problems [20], we should exploit suboptimal solutions with performance guarantee.
4. Submodularity and Greedy Algorithm
In this section, we establish a temporal mapping of the gossip spreading process using virtual coupon collectors by leveraging the concept of temporal network [23]. This treatment provides a tractable way to recognize the submodularity in gossip spreading and leads to a greedy algorithm which yields a solution to GSMP within
4.1. Preliminary
Before the analysis, we introduce the preliminaries on the temporal network, the shortest time-respecting path, and the live diffusion path.
A temporal network embodies the information of when events occur in dynamic systems [23]. For the case of gossip spreading, the edge between any two interacting nodes is endowed with the information of contact times when these two nodes share message. For example in Figure 2, the weights on the edge from node

Illustration of a temporal network with a timeline indicating the information of when events occur.
Consider a directed temporal graph

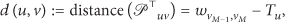
In particular, the shortest time-respecting path

Given a node set S, we say a node v is reachable if either
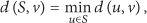
For an ordinary path
4.2. A Temporal Mapping
In the following, we establish a temporal mapping of the pull-based gossip spreading process by constructing a directed temporal graph. Note that all the multiple weights on each edge in the temporal graph are absolute time since the gossip spreading process starts up initially, and the temporal mapping method used in this paper is different from the equivalent view method used in our previous work [16]. These two methods are not simply coupled, and the “pull” model brings in new ingredients to GSMP.
Consider an arbitrary node v, which attempts to pull its desired message from its neighbors in each round since the beginning of round
Given the constrained deadline D, for each node v, we independently run
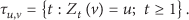
After all the coupon collecting processes

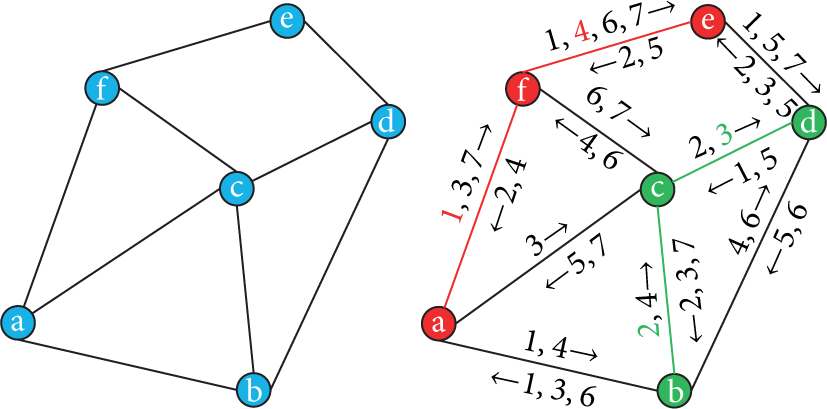
Illustration of the temporal mapping, in which, the red and green paths are the live diffusion paths from the seed nodes
Leveraging the constructed temporal graph
Theorem 5.
Given a directed network
Proof.
For each node
With all the coupon collecting processes
Specially, given an arbitrary seed set S of nodes, the informed time
Remark 6.
For any sample realization of the gossip spreading process, each of the resulting live diffusion paths from S to all the other reachable nodes on G is equivalent to the shortest time-respecting path from S to the considered node on
4.3. Submodularity in Gossip Spreading
The following arguments lead to a greedy algorithm that yields a solution within

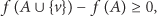
Leveraging the temporal mapping of the gossip spreading process established in Theorem 5, we have Theorem 7. Note that
Theorem 7.
Given a directed network
Proof.
Recall Theorem 5 and consider the sample space Ω, where each sample specifies one possible realization of

We now prove that the function
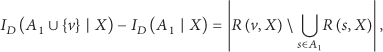

According to the defining property of submodularity in (9), we see that

Remark 8.
Submodularity is a widely applied mathematical tool in tackling a class of nonconvex combinatorial optimization problems, such as social influence maximization, maximum facility location, sensor placement, and optimization design of cellular networks [17, 26–28].
4.4. Greedy Algorithm with Performance Guarantee
We invoke the following result from [25]. Note that the greedy algorithm, presented in “Algorithm 1,” selects each new element with the largest marginal increase in the gossip spreading function
Initialize
Output S
Theorem 9 (see [25]).
For a nonnegative monotone submodular function

Remark 10.
Since
5. Experiments
In this section, we carry out simulation experiments to study the spreading performance of the greedy algorithm. For comparison, we also implement two heuristic algorithms and a random algorithm.
5.1. Setup
5.1.1. Random Geometric Network with Hotspots
We leverage the widely used random geometric graph to generate a network graph with hotspots. There are
In total, there are

Network layout of a random geometric network with hotspots on the
5.1.2. Four Typical Social Networks
We further implement our approach in four typical social networks to evaluate the spreading performance. The small-world network [31], the scale-free network [32], the scientific-collaboration network [33], and the autonomous-system network [34] and the main network statistics are presented in Table 1.
Node and edge numbers of four social networks.

5.2. Heuristic and Random Algorithms
The degree centrality and distance centrality-based heuristic algorithms are widely used in social network analysis [35]; and we can select the seed nodes from the network, using their degree centralities and distance centralities as the decision criteria.
The degree centrality
In particular, we assume the network is connected for the distance-centrality algorithm. The distance centrality
The random algorithm is the baseline, selecting k distinct seed nodes uniformly at random from all the network nodes.
5.3. Simulation Results
5.3.1. Spreading Performance in Random Geometric Network with Hotspots
We evaluate the spreading performance of the greedy algorithm using different deadlines and seed set sizes, and the results are presented in Figure 5. It is shown that the informed population (i.e., the expected number of informed nodes) grows larger as more seed nodes are selected. In addition, if the network nodes are willing to tolerate longer deadline, more of them can successfully receive their desired information.

Spreading performance of the greedy algorithm.
Next, we present the spreading performance of different seed-selecting algorithms in Figure 6. When the seed set size is 10, the greedy algorithm outperforms the degree-centrality algorithm by

Spreading performance of the greedy, heuristic, and random algorithms.
The greedy algorithm that leverages the dynamics of the gossip spreading process in the network performs much better than those centrality-based heuristic algorithms that rely only on the network's structural properties. In actual fact, many of the most central nodes (e.g., with high degree centralities or low distance centralities) are clustered, and thus it is unnecessary to select all of them. In Figure 7, this clustering effect of both centrality-based algorithms is illustrated.

Seed nodes picked by the greedy and heuristic algorithms.
Besides, we see that the random algorithm outperforms both these heuristic algorithms. The reason lies in the fact that the underlying network is generated from the random geometric graph and the random algorithm may often select some seed nodes which have high power to cause a large gossip spreading in different regions over the
5.3.2. Spreading Performance in Four Social Networks
We further evaluate the spreading performance of the greedy algorithm in Figures 8, 9, 10, and 11, with the random algorithm as a baseline for comparison. The deadline is 10 in Figures 8 and 10 and is 5 in Figures 9 and 11. Note that the spreading performances of different deadlines and algorithms in these four social networks have similar trends as those in the random geometric network with hotspots and hence omitted.

Spreading performance in the small-world network.

Spreading performance in the scale-free network.
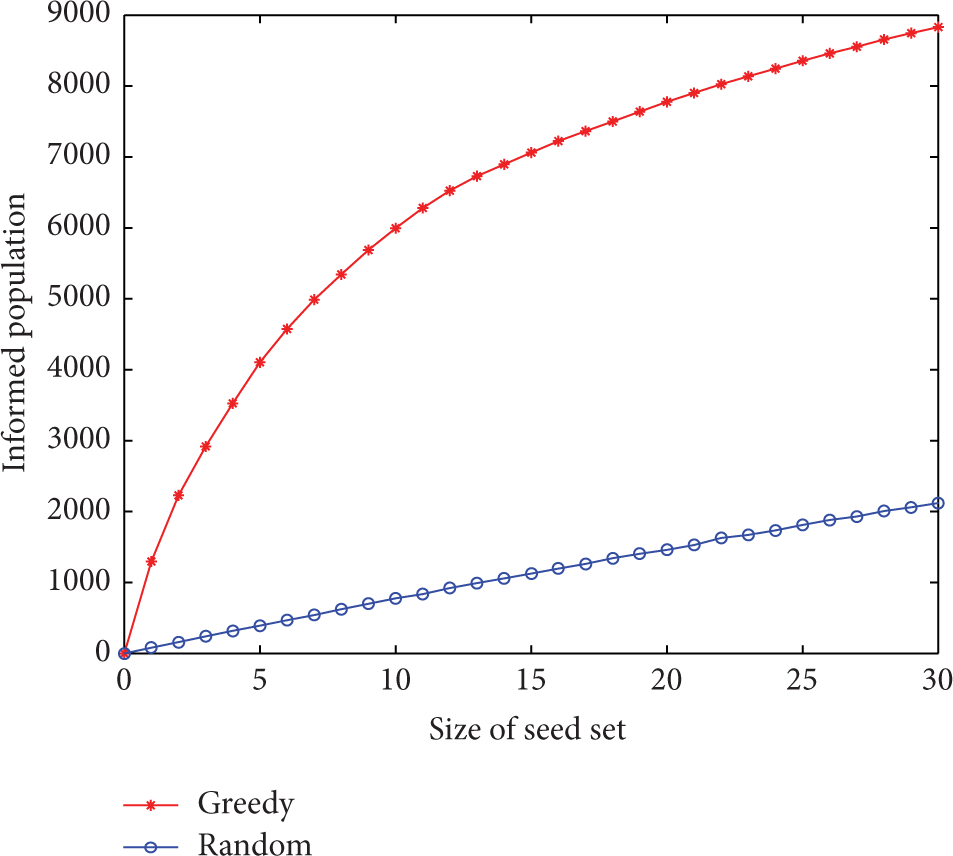
Spreading performance in the scientific-authorship network.

Spreading performance in the autonomous-system network.
From Figures 8, 9, 10, and 11, we see that a large portion of nodes in each network are informed when the seed set size is around 20 for the greedy algorithm. Besides, we see that the greedy algorithm significantly outperforms the random algorithm, especially in the scale-free network, the scientific-collaboration network, and the autonomous-system network.
6. Conclusions
In this paper, we have investigated the problem on the selection of information sources for pull-based gossip spreading. We have proved the NP-hardness of the gossip spreading maximization problem and proposed a suboptimal solution (i.e., the greedy algorithm) for this problem to select seed nodes as information sources. A temporal mapping of the dynamic gossip spreading process has been established via virtual coupon collectors by leveraging the concept of temporal network to analyze this problem. In addition, the temporal mapping method helps to bridge the connection from graph theoretic problems to submodularity and further lead to the greedy algorithm with performance guarantee. In the future, it is interesting to leverage the methods developed in the treatment of GSMP to deal with the problems on gossip spreading when implementing gossip-based algorithms in real-world networks.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
The work has been supported by National Basic Research Program of China (973 Program) through Grant 2012CB316004, SRFDP and RGC ERG Joint Research Scheme through Grant 20133402140001, National Natural Science Foundation of China through Grant 61379003, and the 100 Talents Program of Chinese Academy of Sciences.