
Abstract
This paper presents a novel matrix completion algorithm to enable energy efficient data gathering in wireless sensor networks. The algorithm takes full advantage of both the low-rankness and the DCT compactness features in the sensory data to improve the recovery accuracy. The time complexity of the algorithm is analyzed, which indicates it has a low computational cost. Moreover, the recovery error is carefully analyzed and a theoretical upper bound is derived. The error bound is then validated by experimental results. Extensive experiments are conducted on three datasets collected from two testbeds. Experimental results show that the proposed algorithm outperforms state-of-the-art methods for low sampling rate and achieves a good recovery accuracy even if the sampling rate is very low.
1. Introduction
Wireless sensor networks (WSNs) have been widely used in a variety of applications such as precision agriculture [1], personal health monitoring [2], and environment surveillance [3], in which sensor nodes with limited battery energy are deployed and periodically report their sensor readings to the base station or sink node. Therefore, a key issue in wireless sensor networks is how to efficiently gather these data from sensors provided with only limited energy resources. In the classical data gathering approach [4], each sensor node simply forwards its sensor readings to the sink, resulting in a large amount of traffic and energy consumption.
Recently, Compressive Sensing (CS) [5, 6] has emerged as a new approach to tackle the efficient data gathering problem in WSNs. Taking advantage of the sparsity in sensor readings, CS based methods [7–9] require fewer data packets than the classical approach. However, there are many practical problems when applying CS to data gathering in WSNs. Firstly, CS based methods require a prior dictionary to sparsify the sensor readings. Secondly, the measurement matrix in CS is composed of independent and identically distributed random Gaussian entries, which is dense with very few zero elements. Therefore, sensor nodes need to sample all sensor readings and perform a considerable number of measurement operations, resulting in a large amount of energy waste. Thirdly, CS requires the number of measurements to exceed a certain threshold (depending on the sparsity level of sensor readings) to achieve exact recovery. However, the realistic sensor signal is not always exactly sparse as it should be. Therefore, low sampling rate may lead to insufficient measurements and result in a bad recovery accuracy.
As an extension of CS, matrix completion [10] has shown its potential for enabling efficient data gathering in WSNs. Because the sensor readings are highly temporal-spatial correlated, the data matrix structured by the sensor readings will approximate to a low-rank matrix. Therefore, the sink node can gather only a few of the total sensor readings and adopt the matrix completion algorithm to reconstruct the missing data. However, unlike CS based methods, matrix completion based methods do not require the prior dictionary to sparsify the original signal. Furthermore, the sampling matrix (or measurement matrix) in matrix completion is much sparser than CS, which makes it more suitable for wireless sensor networks.
Utilizing the low-rankness feature in sensory data, there are many pioneering works [11–13] on applying matrix completion to WSN, which adopt the alternating least squares technique to estimate the low-rank matrix. The recovery accuracy is further improved by utilizing the spatiotemporal structure in the WSN data. However, the improvement is limited because the spatiotemporal structure directly implies the low-rank feature, and in some sense, these two features are equivalent. Moreover, the alternating least squares algorithm does not scale to large rank.
Besides the low-rankness feature, we observe that the sensor readings in WSNs also exhibit Discrete Cosine Transform (DCT) compactness feature. In other words, the sensor readings can be approximated by only a small number of DCT coefficients. Therefore, by taking full advantage of the DCT compactness feature of the WSNs data, in this paper, we propose a DCT Regularized Matrix Completion (DRMC) algorithm. We analyze the time complexity of DRMC, which indicates that the proposed algorithm has a low computational cost. Moreover, we analyze the recovery error of DRMC and derive a theoretical upper bound. The error bound is then validated by experimental results. Extensive experiments are carried out on three datasets that are collected from two realistic WSN testbeds. We compare the performance of DRMC with state-of-the-art methods. Experimental results show that DRMC outperforms state-of-the-art methods for low sampling rate and achieves a good recovery accuracy even if the sampling rate is very low.
The main contributions of this paper are summarized in the following:
We examine the sensor data collected from real-world WSNs, which reveal two data features: (1) low-rankness, (2) DCT compactness. Inspired by these observations, we design a novel DCT Regularized Matrix Completion (DRMC) algorithm to estimate the missing sensory data. Experimental results indicate that DRMC outperforms state-of-the-art methods when the sampling rate is low. We analyze the time complexity of the DRMC algorithm, which indicates that DRMC has a low computational cost. We analyze the recovery error of the DRMC algorithm and derive a theoretical upper bound, which is then validated by experimental results.
The rest of this paper is organized as follows. Section 2 reviews the state-of-the-art methods. Section 3 models the problem. Section 4 examines the data features in WSNs. Section 5 proposes the DRMC algorithm. Section 6 analyzes the time complexity of the algorithm. Section 7 analyzes the recovery error of the algorithm. Section 8 evaluates the effectiveness of the proposed algorithm. Section 9 concludes this paper.
2. Related Works
In this section, we make a brief review of previous works related to the data gathering problem in wireless sensor networks.
2.1. Compressive Sensing
Compressive Sensing (CS) theory suggests that sparse signals can be accurately reconstructed from only a small number of measurements [5, 6]. It is a new paradigm for signal processing of networked data [7] and there are many CS based methods for data gathering in wireless sensor networks. Luo et al. proposed a data gathering scheme that applies Compressive Sensing theory to reduce communication cost [14]. Quer et al. presented a framework for data gathering and signals recovery in actual WSN deployments with the integration of CS [9]. Ebrahimi and Assi recently proposed a decentralized method to apply the Compressive Sensing to data gathering in wireless sensor networks [15].
2.2. Matrix Completion
Recently, there are many applications that apply matrix completion technique to wireless sensor networks. Utilizing the low-rankness and spatiotemporal correlation, Zhang et al. proposed a method to recover the lost data in internet traffic matrices [13]. Kong et al. designed an algorithm using the low-rank structure, time stability, space similarity, and multiattribute correlation to estimate the missing data in highly incomplete data matrix [12]. Cheng et al. presented a Spatiotemporal Compressive Data Collection (STCDG) algorithm that utilizes the low-rankness and short-term stability features to reduce data traffic in WSNs [11].
In our earlier work [16], we have studied the data recovery problem in wireless sensor networks when historical data are available and proposed a DCT-Regularized Partial Matrix Completion (DCT-RPMC) algorithm. However, the new algorithm proposed in this paper does not depend on any historical data, which greatly widens its applicability to more general scenarios.
3. Problem Formulation
In this section, we formally formulate the data gathering and recovery problem in wireless sensor networks and state the goal of this paper. The main notations that will be used in the rest of this paper are listed in Summary of Notations.
Assume that the network is composed of n sensor nodes. During a certain sampling period, the ith sensor node acquires m samples, which are modeled as an m-dimensional sensor vector

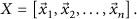
In order to reduce energy consumption, only a fraction of the entries of X will be transmitted to the sink node. We then define a matrix

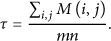
Let

After obtaining Y, the sink can reconstruct the original environment matrix X with the proposed algorithm in Section 5. Our goal is to generate a reconstructed matrix

4. Exploring the Data Features
In this section, we examine the data features in real-world wireless sensor networks.
4.1. Experimental Datasets
We use three datasets, which are collected from two WSN testbeds, to serve as the ground truth. The summary of the datasets is shown in Table 1.
Experimental datasets.

The first category of datasets is collected by 54 Mica2Dot nodes deployed in the Intel Berkeley Research Lab [17] between February 28 and April 5, 2004. The Mica2Dot node reports collected sensor data including humidity and temperature once every 30 seconds. However, we find that the raw dataset has considerable missing data. Therefore, we have rearranged the raw data (by changing the reporting interval from 30 seconds to 10 minutes) to avoid the missing data.
The second category of dataset consists of temperature readings, which are collected with a 10-minute interval by our own testbed, namely, PARED. PARED consists of 50 sensor nodes. More details about PARED can be found in [18].
4.2. Low-Rank Structure
We first examine the low-rank structure in WSN datasets using the Singular Value Decomposition (SVD). The environment matrix X can be decomposed into three matrices by SVD:
Because sensor readings in a WSN are spatiotemporal correlated, the environment matrix X would exhibit low-rank feature. More exactly, X should approximate to a low-rank matrix of rank r. So, the first r singular values will occupy the most energy of X. We use the following as the metric to examine the quality of the low-rank approximation:
Figure 1 shows the low-rank approximation quality of the three datasets. We found that the largest 10 singular values occupy the 93%–99% of the total energy, which suggests that the WSN datasets exhibit a good low-rank feature.
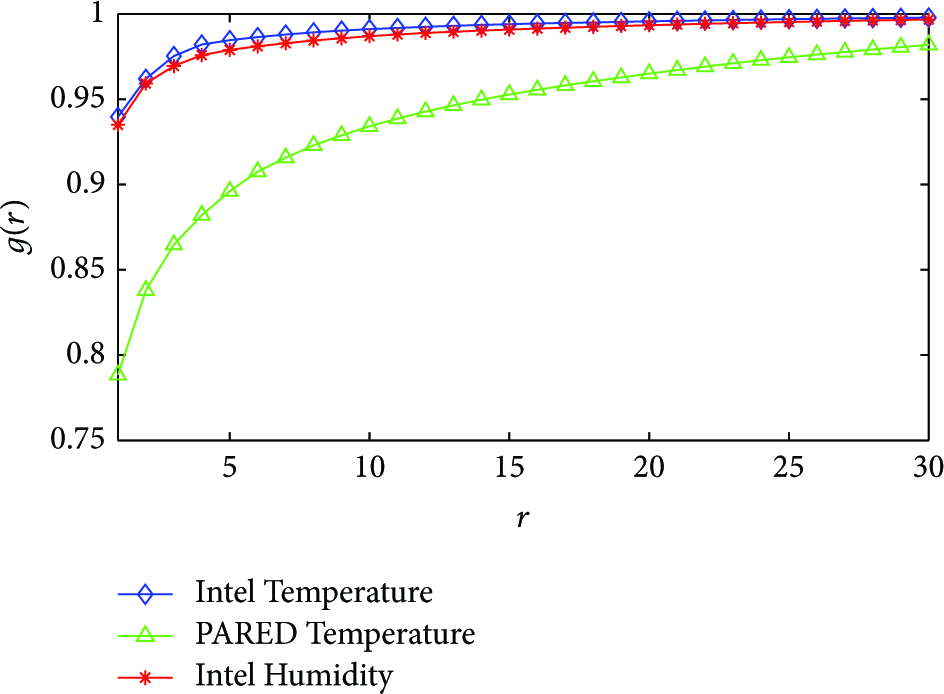
Low-rankness feature.
4.3. DCT Compactness
We also observed that the sensor readings in WSN exhibit DCT compactness feature. In other words, the first k DCT coefficients of the sensor vector
We first define D as the 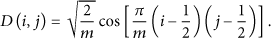

Therefore, if the first k DCT coefficients occupy the most energy of 
From Figure 2, we can see that the first 10 DCT coefficients concentrate

DCT compactness feature.
5. Algorithm
In this section, we proposed a novel matrix completion algorithm, namely, DCT Regularized Matrix Completion (DRMC), to solve the data recovery problem in WSN data gathering. DRMC takes full advantage of the low-rankness and DCT compactness features to improve the recovery accuracy.
5.1. Utilization of Low-Rankness
As mentioned before in Section 3, the goal of the recovery problem is to estimate X from only a fraction of known entries. According to [10], we can recover X by solving the following rank optimization problem if X is a low-rank matrix:
However, the rank minimization problem (12) is NP-hard and is not solvable in polynomial time. Since the nuclear norm is the optimal convex approximation of the rank function, a reasonable solution is to solve a convex relaxation problem with the rank function replaced by the nuclear norm:
However, in a more realistic occasion, the environment matrix X is not an exactly low-rank matrix. There may not exist low-rank matrices that exactly satisfy the constraints in problem (13). So, we converted the constrained optimization problem (13) into the following nuclear norm regularized optimization problem:
5.2. Utilization of DCT Compactness
Though we can estimate X by solving the optimization problem (14), it will overfit to the known entries of X when the sampling rate is low, which will lead to large recovery error in the estimation of the missing entries.
Therefore, to reduce the overfitting in (14), we exploit the DCT compactness feature of the sensor data. As mentioned in Section 4.3, 
5.3. The DRMC Algorithm
We present the DRMC algorithm by solving the optimization problem in (15). The pseudocode is shown in Algorithm 1. Next, we will describe the design of DRMC in details.
μ: DCT regularization parameter
( ( ( ( ( ( ( ( ( ( ( ( ( ( ( (
The object function in (15) can be rewritten into the following form:


Note that 

Since 
We then introduce an auxiliary variable G to minimize
What is more, we consider a warm-start technique for the nuclear regularization parameter λ. Rather than remaining unchanged, λ is monotonically decreasing in the iterative process. The nuclear regularization parameter λ starts with an initial value
Lemma 1.

Proof.
Since D is orthonormal,
And note that 
Proposition 2.
Assume that 
Proof.
Note that 
Definition 3.
Decompose the matrix 
Lemma 4.
Let 
Proof.
Proposition 5.
Let 

Proof.
Consider
6. Complexity Analysis
In this section, we discuss the time complexity of the proposed algorithm.
After analyzing the steps in Algorithm 1, we find that the most computationally intensive step is the singular value shrinkage operation that performs SVD on G, which dominates the computational complexity of this algorithm. The time complexity of SVD for an
We can further decrease the time complexity of the DRMC algorithm by applying Partial Reorthogonalization Package (PROPACK) [26] in the singular value shrinkage operation. PROPACK uses the Lanczos method [24] to compute only a partial SVD of G. However, it cannot a priori compute singular values that are greater than 
The time complexity of the Lanczos method is
7. Error Analysis
In this section, we analyze the recovery error of the DRMC algorithm and present a theoretical upper bound.
Before starting the analysis, we first introduce some assumptions and lemmas.
Assumption 6.
The original data matrix X can be approximated by the first k DCT coefficients, with approximation error ξ:
Assumption 7.
Let 
Then, there exists a constant 
Lemma 8.
Suppose that 
Proof.
Lemma 9.
Suppose that 
Proof.
Consider

The upper bound of the recovery error is then given in the following theorem.
Theorem 10.
Suppose that 
Proof.
When the iterative process in Algorithm 1 has converged, 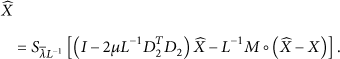

Combining (43) and Lemma 8, we have
Then, applying Assumption 6 and Lemma 9 to (44), we have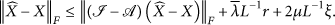

Let E represent the upper bound of the recovery error. Then, according to Theorem 10,
8. Evaluation
We designed a data gathering scheme based on the proposed DRMC algorithm. The data gathering procedure is similar to [11]. Firstly, sink node broadcasts a sampling rate to all sensor nodes. Secondly, each sensor node randomly and independently decides whether to forward its readings to the sink according to the sampling rate. Finally, the sink node collects the incomplete data matrix and uses DRMC to retrieve the missing data. After implementing this data gathering scheme by Matlab, we carried out extensive experiments on three real-world datasets (as shown in Table 1) to evaluate the effectiveness of DRMC.
8.1. Baseline Methods
We select two state-of-the-art methods to compare with DRMC. The first method is Compressive Sensing (CS). We choose the DCT matrix defined in (9) to serve as the orthonormal basis in CS. The second method is Spatiotemporal Compressive Data Collection (STCDG). The parameters of STCDG are set to
8.2. Recovery Accuracy
Firstly, we compared the recovery accuracy of the proposed algorithm with two baseline methods described above. The parameters of DRMC are listed in Table 2.
Parameter settings for DRMC.

Simulation experiments are carried out on three real-world datasets. Each simulation is conducted for 100 independent trials. The recovery errors are computed according to (6) and are averaged over the 100 trials.
Comparison results are shown in Figures 3–5. For experiments on Intel Temperature Trace, all methods achieve nearly the same recovery accuracy when the sampling rate is high. When the sampling rate is below a certain value (

Recovery accuracy on Intel Temperature Trace.
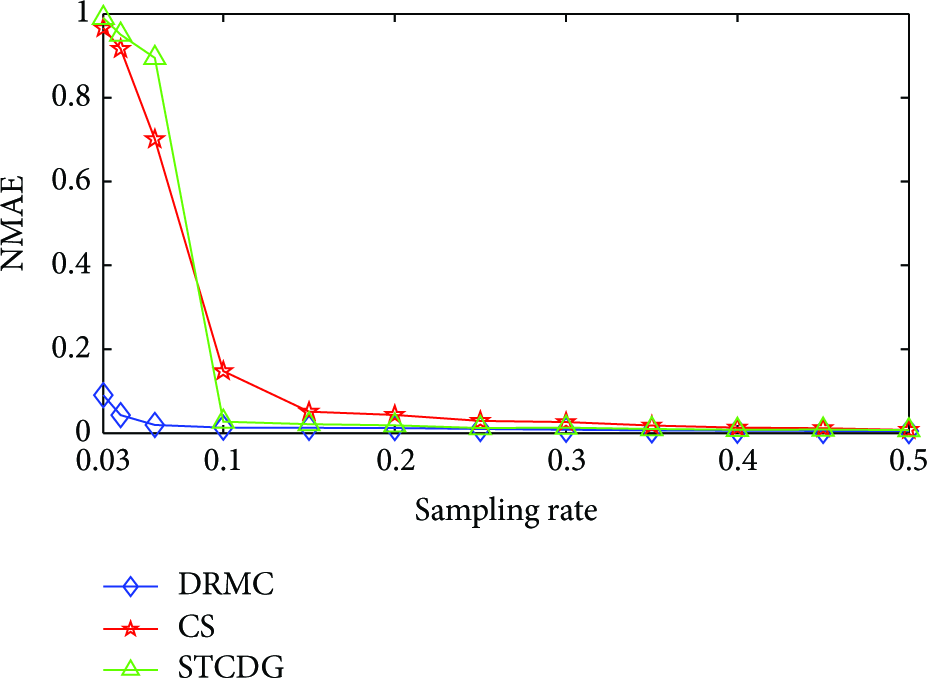
Recovery accuracy on Intel Humidity Trace.

Recovery accuracy on PARED Temperature Trace.
Comparison results on Intel Humidity Trace are very similar to that on Intel Temperature Trace. Recovery error of DRMC is about 9% when the sampling rate is 0.03, which is noticeably better than that of baseline methods.
For experiments on PARED Temperature Trace, DRMC still outperforms baseline methods for low sampling rate. The recovery error of DRMC is about
8.3. Parameter Settings
The DRMC algorithm depends on several input parameters. Clearly, the choice of these parameters will affect the recovery performance of DRMC. In this subsection, we discuss how to choose the parameters for DRMC.
The nuclear norm regularization parameter λ is an important parameter to ensure the low-rank feature of the reconstructed data matrix. In DRMC, we adopted a warm-start strategy for λ, in which λ is linearly reduced from
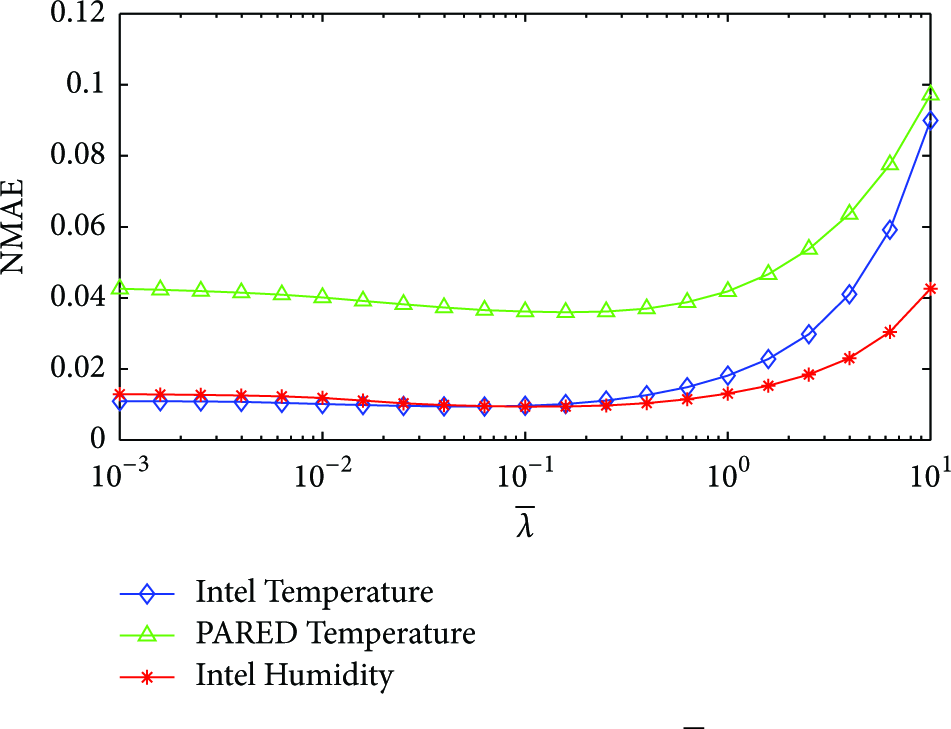
Effect of parameter
Parameter μ is a regularization parameter that guarantees the DCT compactness feature of the recovered signal. Figure 7 shows the effects of μ on the recovery performance of DRMC. The recovery errors decline with μ and are stable when

Effect of parameter μ.
Recall that k represents the number of concentrated DCT coefficients. As discussed before in Section 4.3, the first 10 DCT coefficients concentrate 99% of the total energy. As expected, Figure 8 shows that the recovery errors are dropping fast with k and are stable when

Effect of parameter k.
8.4. Energy Consumption and Network Lifespan
DRMC-based data gathering protocol is more energy efficient because it transmits less packets than the classic one (receiving and forwarding). As a result, DRMC-based protocol can save more energy and prolong the lifespan of wireless sensor networks. To verify this, simulation experiments are conducted and the simulation configuration is shown in Table 3.
Simulation configuration for network lifespan.

In the simulation, sensor nodes are randomly deployed in a 500 m × 500 m area and the sink node is deployed in the center. Each sensor node is equipped with 1 J energy. To evaluate the energy consumption, we adopt the following energy model [29]:
Figure 9 demonstrates the network lifespan of DRMC-based protocol and other baseline protocols under different sampling rate. Note that the network lifespan is defined as the time when the first energy exhausted node appears. Apparently, the sampling rate does not play a role in the classic data gathering, since it directly transmits all data without compression. Therefore, the lifespan curve of the classic protocol in Figure 9 is a straight line. For the CS method, the smaller the sampling rate is, the less measurements are taken. And as shown in Figure 9, the lifespan of CS is decreasing with the sampling rate. However, when the sampling rate is above a certain value, the lifespan of CS is even worse than the classic one. The reason why CS performs badly for large sampling rate is well analyzed in [30]. Figure 9 shows that DRMC-based protocol achieves the best lifespan. Similarly, the lifespan of DRMC is decreasing with the sampling rate. When the sampling rate decreases to 1, DRMC-based protocol is equivalent to the classic protocol and the lifespan of DRMC is equal to the classic one. Note that the lifespan of STCDG is exactly the same as DRMC, because both of the two methods are based on matrix completion. The lifespan of DRMC is longer than CS because the sampling matrix in DRMC is much sparser than that in CS.

Relation of network lifespan to sampling rate.
9. Conclusion
In this paper, we studied the data gathering and reconstruction problem in WSNs. We modeled the problem as matrix completion problem and investigated the data features in real WSN datasets. Then, by taking advantage of the low-rankness and DCT compactness features in WSNs, we proposed a DCT Regularized Matrix Completion (DRMC) algorithm to reconstruct the missing data. The recovery error of DRMC is carefully analyzed and a theoretical error upper bound is presented. Experimental results show that DRMC outperforms state-of-the-art methods for low sampling rate and achieves a good recovery accuracy even if the sampling rate is very low.
Footnotes
Summary of Notations
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This work is funded by the National Nature Science Foundation of China under Grant no. 61371135.