
Abstract
Mobile healthcare in a cloud-based system increases the easiness and the ubiquitous nature of patient-doctor relationship. One of the major issues of this healthcare is secure transmission and data authenticity. If the data is not transmitted securely or not authenticated, the clients may face embarrassment. In this paper, we propose a cloud-based healthcare framework that will authenticate speech data from a patient suspected to have Parkinson's disease. The patient sends his or her speech signal recorded via a smart phone through Internet to the cloud. A discrete wavelet transform- (DWT-) singular value decomposition (SVD) based speech watermarking module is run in the cloud to embed watermark to the signal. In case of authentication, watermark is extracted from the questioned signal and matched with the stored watermark. Experimental results indicate that the proposed DWT-SVD based watermarking system achieves imperceptibility and is robust against attacks such as additive white Gaussian noise and filtering.
1. Introduction
The application of healthcare system in a cloud-based framework is increasing day by day due to its heterogeneous nature in terms of processing capability and capacity [1, 2]. The introduction of cloud in healthcare has opened the possibility of elderly homecare, reduced the physical transportation of patients, increased the availability of multiple consultancy from the doctors, and so forth. However, the increasing use of wireless transmission of health related data raises the concern of data protection and authenticity. Medical data are considered to be private and should not be made public without proper permission. Without ensuring proper security, the patients' privacy may be vulnerable [3–6]. For example, if a patient has some embarrassing disease, any leakage of that data will make the patient embarrassed inside the society. This may lead to losing his or her job, making him or her isolated or depressed, problems to insurance protection, and so forth [7]. Medical data can be shared between the physicians, insurance companies, family members, caregivers, and sports coaches. If there is no appropriate protection, the data can be collected unauthorized by political party agents, personal enemies, and rival coaches. On the other hand, a hacker can hack any medical data and post on social networks to defame any individual. If there is no measurement of authentication of the data, that particular individual will suffer mental fatigue and embarrassment. If the healthcare service provider does not follow HIPAA rules [8], he or she is subject to face strict civil and criminal penalties. Therefore, data protection and data authentication are crucial in an e-healthcare system.
In this paper, we address the issue of data authentication by embedding watermark to speech data of Parkinson's disease patient. Parkinson's disease (PD) is a degenerative disorder in the central nervous system marked by tremor, rigidity, anxiety, dementia, and slow and imprecise movement of muscles. The name of this disease came after Doctor James Parkinson, who described PD as “shaking palsy” in 1817 [9]. PD is generally observed with elderly people, and the symptoms worsen over time. It affects speech production in the vocal folds and transmission through the vocal tract, motor activities such as writing and balance [10], and also nonmotor activities such as depression, autonomic dysfunction, and visual hallucinations [11]. PD is the second most common neurodegenerative disorder after Alzheimer. Approximately 10 million people around the world suffer from PD and Saudi Arabia is ranked 24th in terms of death rate by PD (2.6 per 100,000) [12]. PD is very difficult to cure; however, early detection and treatment can help the patient gain some control over some motor and nonmotor symptoms. The detection and treatment can be either invasive, such as surgery, or noninvasive, such as medicines; however, both surgery and medicines can be risky to the patient.
Most of the PD patients suffer from vocal fold dysphonia. Therefore, analyzing speech is a popular choice of PD diagnosis. This popularity comes from relatively low cost involved, its noninvasive nature, and being easy-to-use in telemedicine [13]. The speech of a PD patient is different than that of a healthy person, making the speech disorder detection for PD diagnosis a realistic approach. Many features of speech were investigated in the literature in this aspect, such as Mel-frequency cepstral coefficients (MFCC), shimmer, jitter, harmonic-to-noise ratio, pitch period entropy, degree of voice breaks, and autocorrelation [14].
To diagnose or treat PD in e-healthcare system, the transmission of speech signals should be protected and authenticated. To protect data, watermarking is one of the widely used techniques. Several watermarking algorithms exist in literature for telemedicine applications. For example, Singh et al. embedded text and image watermarks into cover radiological images for secure medical data transmission [15]. Optical 3D watermark was used in [16]; identification of liabilities based on watermarking was proposed in [17]. However, watermarking in audio, voice, or speech signal for telemedicine applications is not common.
This paper presents a watermarking procedure in e-healthcare system for the purpose of PD diagnosis in a cloud-based framework. Discrete wavelet transform (DWT) and singular value decomposition (SVD) are used in the watermarking procedure. DWT-SVD based audio watermarking was proposed before; however, it was not used in e-healthcare system. For example, Ali and Ahn presented DWT-SVD based watermarking procedure using self-adaptive differential evolution technique [18]. Two-level DWT was used and all the subbands were utilized to embed the watermark. Lei et al. proposed a blind watermark scheme based on SVD and discrete cosine transform (DCT) [19]. A selection of large singular value coefficients were utilized in SVD-DWT based audio watermarking algorithm in [20]. None of these methods considered the use of watermark in e-healthcare or in cloud-based systems. To the best of our knowledge, the present study is the first study to address audio watermarking in a cloud-based healthcare system. The feasibility of using DWT-SVD based watermarking is investigated by conducting a number of experiments in this study.
The rest of the paper is organized as follows. Section 2 outlines the framework of the proposed cloud-based healthcare framework; Section 3 describes the watermarking system; Section 4 presents the experiments; and, finally, Section 5 draws some conclusions.
2. Proposed Cloud-Based Healthcare Framework
A cloud framework has many interesting characteristics such as extensive network access, huge storage, on demand self-service, resource allocation, and measured service [21, 22]. The cloud infrastructure can be defined as a software-platform-infrastructure (SPI) model that consists of Software as a Service (SaaS), Platform as a Service (PaaS), and Infrastructure as a Service (IaaS). Clients interacted with SaaS and IaaS is connected to data center as shown in Figure 1. SaaS includes e-mail, office programs, and social networking through which a client can deliver his or her message or data. PaaS includes appropriate operating system (OS), database (DB), and webserver, while IaaS includes virtual machines (VMs) and virtual local area networks (LAN).

SPI model of a cloud infrastructure.
The proposed cloud-based healthcare framework is illustrated in Figure 2. There are two end users, who are patients or clients and medical doctors and caregivers. The patient or the client who wishes to examine whether he or she has PD or not will simply record his or her speech using a mobile app. The mobile phones are equipped with internal microphones that can sense the speech and record it. The sensing is thereby noninvasive and wireless. The other end user is medical doctor or caregiver, who is specialized to analyze PD from speech and has proper access to the system. This end user can be located anywhere in the world.

Cloud-based healthcare framework for watermarking of data.
The main component of the framework is the cloud manager (CM). The CM controls and manages the framework in a seamless way. The responsibilities of the CM includes the following:
Registration of the end users: the end users have to register at the beginning to be within this framework. The CM registers the end users. Authentication of the users: if a user wants to access the framework, the CM verifies his or her registered record and appropriately grants the access. Profile management: the CM manages the profile of the end users and periodically updates it if necessary. Context management: the CM extracts the context of the data and decides for watermarking or classifying the speech. Communication management: the CM initiates, controls, and terminates the collaboration between the users.
The resource allocation manager assigns different VM resources for various sessions and web services. Depending on the load capacity, it also configures VM capacities. The VMs work as an interface between the storage and the web servers.
The proposed framework contains some dedicated servers for the specific task of watermarking and classifying the speech signal. One server is responsible for watermark embedding and extraction and storing the appropriate keys. Another server is responsible for feature extraction from the speech signal and for classification. Watermark embedding and extraction will be described in detail in the following section.
The task flow of the whole framework is given below.
Step 1.
A client, whether he or she is a healthy person or a person suspected to have PD, requests the service by using his smart phone upon accessing Internet.
Step 2.
The CM registers the client and assigns him an ID.
Step 3.
The client records his or her speech through the smart phone and uploads it.
Step 4.
The recorded speech sample is sent to the CM, where it authenticates the client.
Step 5.
The CM sends the sample to the resource allocation manager, which in turn sends to collaborative service manager. The service manager allocates the task to watermark server to watermark the sample, stores it, and sends it to feature extraction and classification server for analysis.
Step 6.
If the sample is detected as a sample of PD, the CM sends the watermarked sample to the doctors and caregivers. If it is not detected as PD, the CM notifies the client.
Step 7.
The doctor downloads the sample and further analyzes it for diagnosis.
Step 8.
The doctor uploads his diagnosis and advice to the web.
Step 9.
The CM gets the diagnosis and alerts the client.
Step 10.
The client downloads the diagnosis and advice from the doctor.
3. Proposed Watermarking System
The proposed PD speech signal watermarking system has two main components, which are watermark embedding and watermark extraction. A DWT-SVD based watermarking scheme is adopted in the proposed system. The DWT-SVD watermarking scheme is computationally efficient and robust against major attacks in an audio signal. In the following subsections, the components are described in detail.
3.1. Discrete Wavelet Transform (DWT)
DWT is a multiresolution technique that decomposes a signal into different resolutions of time and frequency. For a one-level DWT, a given signal is passed through a low-pass filter and a high-pass filter. The output of the low-pass filter is called approximation (L), while that of the high-pass is called detail (H). Figure 3 shows a one-level decomposition of a signal
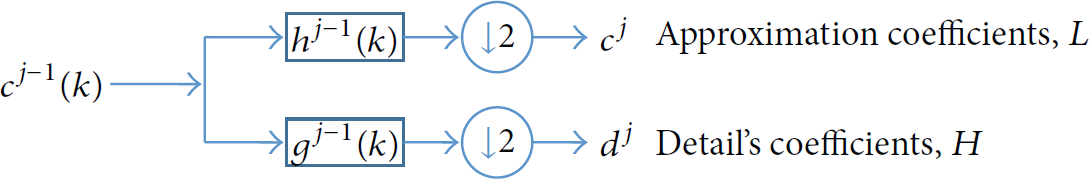
One-level decomposition of DWT.

Two-level decomposition of DWT.
There are several watermarking algorithms based on the subbands of DWT. Peng et al., Xiang, and Wu et al. used the approximation subband to embed watermark bits [23–25]. Many other algorithms used a detail's subband for embedding watermark bits [26–29]. They mainly differed on which detail's subband to use. A claim of good imperceptibility and high robustness was reported by using these algorithms.
3.2. Singular Matrix Decomposition (SVD)
SVD is a matrix factorization technique that decomposes a matrix into three matrices. If a rectangular matrix A of size

The application of SVD in watermarking algorithm is relatively new. El-Samie inserted watermark bits in all the singular values of matrix
3.3. DWT-SVD Based Watermark Algorithm
Figure 5 shows the proposed DWT-SVD based speech signal watermark algorithm. The watermarking is done in the cloud. The watermark is embedded in the

Proposed DWT-SVD based speech signal watermark algorithm.
3.3.1. Creating Watermark Image
The watermark image consists of the patient's ID in image format. For example, if the patient has the ID of A23415610, then the watermark image will look like Figure 6. Let one name the watermark image as watermark. The size of watermark is

Watermark image containing the patient's ID.
3.3.2. Transforming the Watermark Image Using SVD
SVD transformation is applied to the watermark image using the following steps.
Step 1.
Normalize the image matrix by 255:

Step 2.
Apply SVD on the normalized matrix. The resultant
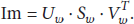
Step 3.
Multiply

Step 4.
Store
3.3.3. Transforming the Speech Signal Using DWT-SVD
DWT-SVD transformation is applied to the speech signal using the following steps.
Step 1.
Divide the speech signal into nonoverlapping frames, where the frame length is 30 milliseconds. Suppose we have N frames.
Step 2.
Apply two-level DWT on each frame. Take
Step 3.
Form a matrix G using
Step 4.
Apply SVD on matrix G. The resultant

3.3.4. Watermark Embedding
The watermark is embedded in the speech signal using the following steps.
Step 1.
A new matrix,
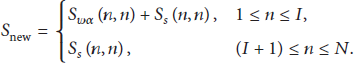
Step 2.
Using

Step 3.
Using
3.3.5. Watermark Extraction
Watermark extraction is just the reverse procedure of watermark embedding. Figure 7 shows the extraction procedure. From the figure, we notice that, to extract the watermark, we need the original speech signal

Watermark extraction procedure.
The following steps are applied to extract the watermark.
Step 1.
Subtract

Step 2.
Apply inverse SVD to get the normalized watermark:

Step 3.
Get the watermark image by multiplying the values by 255 and dividing by α
. Consider
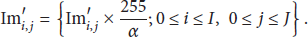
3.4. Feature Extraction and Classification
To detect whether the speech signal is coming from a patient having PD or from a normal person, the proposed framework also has an option to detect PD from the speech signal. To achieve this, features extraction and classification are performed in the cloud (see Figure 2).
In general, feature extraction should extract meaningful information (features) from a given signal. These features should be representative of the signal, discriminative for different classes, and nonredundant. In line with this, we extract five features, which are jitter, shimmer, harmonic-to-noise ratio (HNR), fraction of locally unvoiced frames, and mean pitch. These five features represent five different attributes of a signal. Jitter is a frequency feature that is defined as pitch perturbation and mathematically expressed as

Shimmer is an amplitude perturbation measure and mathematically expressed as

HNR is a harmonicity parameter, which is represented by

The feature “fraction of locally unvoiced frames” is a voicing parameter, and “mean pitch” is a pitch parameter.
These features are chosen because they are discriminative for normal voice and PD voice. A PD voice exhibits high jitter, high shimmer, low HNR, less locally unvoiced frames, and low pitch. In [14], some of these features were used; however, the levels of redundant features were high. For example, jitter (local), jitter (absolute), jitter (rap), jitter (ppq5), and jitter (ddp) were used to represent frequency attribute. All these jitter parameters represent the same using different mathematical expressions. In our proposed framework, we use one feature per attribute thereby limiting the confusion in the classification process.
For classification, we utilize support vector machine (SVM) for its simplicity and generalization capability. Linear kernel is used to project low dimensional space into a high dimensional space [14]. As the number of samples is low, we adopt leave-one-subject-out (LOSO) approach, where all but one subject samples are used in training and that subject's samples are used in testing. Therefore, there is no overlapping between training and testing samples in one round of experiment. This is repeated until all the subjects' samples are tested. The final accuracy is obtained by averaging the accuracies over rounds.
4. Experiments
In this section, the details of the experiments are presented. The description includes the database used in the experiments, evaluation metrics, experimental results, and comparison.
4.1. Dataset
4.1.1. For Watermarking
The speech signals from PD patients were obtained from [14]. As the raw wave signal is available only for their provided test data, we used these signals for our experiments. 28 PD patients were asked to sustain vowels “a” and “o” three times each. Therefore, a total of 168 recordings were available. The age range of the individuals was between 43 and 77, with mean 64.86 and standard deviation 8.97. The signals were recorded at the Department of Neurology in Cerrahpasa, Faculty of Medicine in Istanbul University. The sampling frequency were downsampled from 96 kHz to 32 kHz to reduce the transmission load.
Another dataset, called Saarbrucken Voice Disorder (SVD) database [34], was used for normal speech. The speech samples were recorded by the Institute of Phonetics of Saarland University, Germany. We selected speech samples from 100 normal subjects containing sustained vowels “a” and “o” with normal pitch.
4.1.2. For PD Detection
The speech signals from PD patients were obtained from [14]. There are two sets: training and testing. The training set consists of voice samples of 20 PD patients, of whom six are females and 14 are males, and 20 healthy persons of which 10 are females and 10 are males. We used only samples of sustained vowels “a” and “o.” The testing set consists of sustained vowels “a” and “o” samples spoken by 28 PD patients.
4.2. Evaluation Metrics
The performance of the proposed watermarking framework was measured in terms of imperceptibility and robustness against attacks [35]. Imperceptibility is a measure of how much the signal is distorted perceivably. To measure imperceptibility, we used signal-to-noise ratio (SNR) and listening test; the first one is objective and the second one is subjective. SNR is defined by

In the listening test, the human listeners rate the played speech signal with one of the following grades: imperceptible, perceptible but not annoying, slightly annoying, annoying, and very much annoying, where imperceptible has grade 5 and very much annoying has grade 1. There were 15 listeners, who listened to both the original speech signals and the watermarked speech signals during training. During actual testing, they were given watermarked speech randomly.
With regard to robustness against attack, we considered two common attacks, which are additive white Gaussian noise (AWGN) and filtering of type low-pass, high-pass, and band-pass. The measurements were obtained by using a correlation factor, η, which is computed by using

The performance of PD detection was measured in terms of accuracy (%).
4.3. Experimental Results
Table 1 shows SNR and PSNR, in decibels, for the speech signal “a” and “o.” In both the cases, the SNR and PSNR were well above 20 dB, which is a minimum requirement of the International Federation of Photographic Industry (IFPI) [36]. The SNR and PSNR were higher in normal speech than in PD speech. In normal speech, as the vocal folds can accurately open and close together, there is less or no noisy element, resulting in higher SNR or PSNR. In PD case, vocal folds cannot completely close or close in irregular manner; therefore it is already noisy (smaller amplitude), which causes relatively smaller SNR or PSNR. Table 2 shows the corresponding numbers when the watermarking was accomplished in the cloud. If we compare the values between Tables 1 and 2, we find that the wireless transmission of the speech signals did not distort the signal much, and hence the SNR (or the PSNR) values did not degrade much while the watermarking was embedded in the cloud server.
SNR (dB) and PSNR (dB) using the proposed watermark scheme (in local server).

SNR (dB) and PSNR (dB) using the proposed watermark scheme (in cloud server).

Table 3 shows average rating from the listeners to judge speech quality of the watermarked signals, when watermarking was done in the local server. As mentioned before, there were 15 human listeners. The values in Table 3 indicate that the proposed watermarking algorithm achieves imperceptibility. The listeners' ratings when the watermarking was done in the cloud server are given in Table 4. This rating is important because the doctors or the caregivers will actually listen to the speech signals that are watermarked in the cloud. From the table, we find that listeners' ratings did not change much even when the watermarking was done in the cloud server (transmission did not affect the algorithm).
Average rating from the listeners (watermarking in the local server).

Average rating from the listeners (watermarking in the cloud server).

Figure 8 shows correlation factor, η, after different types of attacks. The attacks were applied once the watermarking was embedded in the cloud server. The attacks included band-pass filtering with passband between 80 Hz and 4 kHz, high-pass filtering with cutoff frequencies of 80 Hz and 50 Hz, low-pass filtering with cutoff frequencies of 16 kHz, 8 kHz, and 4 kHz, and AGWN of 20 dB, 15 dB, and 10 dB. From the figure, we see that almost in all the cases the correlation factor was 1, which indicates the robustness of the proposed algorithm.
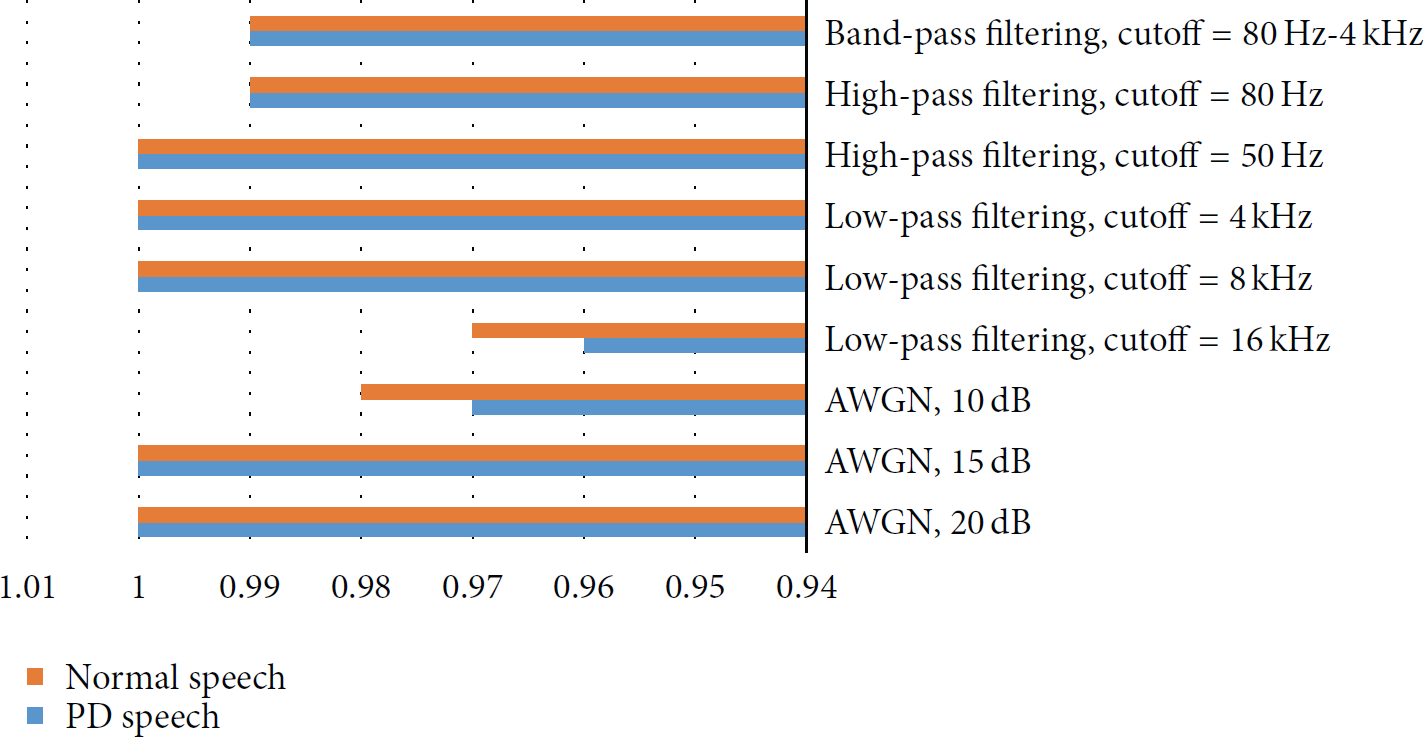
Correlation factor, η, after different types of attacks.
Figure 9 shows the accuracy of the proposed framework for PD detection. The proposed PD detection achieved 89.3% accuracy using samples “a” and 80.5% accuracy using samples “o.”

Accuracy (%) of PD detection for vowels “a” and “o.”
4.4. Comparison with Other Systems
We compared the proposed cloud-based watermarking system with other systems, namely, systems in [26, 37]. In [37], the system used DWT-DCT based approach. We took the results of these two systems as they were reported in the corresponding papers. Table 5 shows the comparison of performances between the two systems and the proposed system. All the systems' performances were based on the local server. It can be noted that imperceptibility results are hardly compared between the systems in the literature, because the materials are diverse, and the listeners are of course different. From the table, we find that the proposed system performed better than the two other systems.
Comparison of performances between the systems.

The proposed PD detection was compared with another similar system in [14]. The features in their system were acquired from their repository and the experiments were carried out using the same classification approach as our proposed system. The comparison of accuracy in both is shown in Figure 9. From the figure, we see that the proposed system outperforms the system in [14] both using samples “a” and using samples “o” significantly.
5. Conclusion
DWT-SVD based speech watermarking scheme to entrust data in a cloud-based healthcare system was proposed. As a case study, the speech from patients having PD and from healthy subjects was investigated. The watermarking was embedded in the cloud and could be extracted for authentication in the cloud. The experimental results showed that the proposed scheme achieved imperceptibility and robustness against certain attacks including AWGN and filtering. The listeners' ratings were also high.
The whole framework can be used in a mobile healthcare system in entrusted way to diagnose PD. The client sends his speech to the cloud, where it is watermarked for subsequent transmission. The watermark speech is then classified into normal or having PD, with a degree of severity, in the cloud. After that the client and the doctors are notified about the classification. In a future study, we would like to investigate the classification task using watermark speech signal.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
The authors extend their appreciation to the Deanship of Scientific Research at King Saud University, Riyadh, Saudi Arabia, for funding this work through the research group Project no. RG-1436-016.