
Abstract
The rapid development of mobile technology has improved users' quality of treatment, and tremendous amounts of medical information are readily available and widely used in data analysis and application, which bring on serious threats to users' privacy. Classical methods based on cryptography and anonymous-series models fail due to their high complexity, poor controllability, and dependence on the background knowledge of adversaries when it comes to current mobile healthcare applications. Differential privacy is a relatively new notion of privacy and has become the de facto standard for a security-controlled privacy guarantee. In this paper, the key aspects of basic concepts and implementation mechanisms related to differential privacy are explained, and the existing research results are concluded. The research results presented include methods based on histograms, tree structures, time series, graphs, and frequent pattern mining data release methods. Finally, shortcomings of existing methods and suggested directions for future research are presented.
1. Introduction
With the further development of mobile technology, it is easy to attain, store, and analyze mobile healthcare information, such as physiological data, social interactions, consumer record, and track data, which all inevitably involve user's privacy. MHR (mobile healthcare record) has been questioned because of user's privacy disclosure since its inception due to the high sensitivity of health data [1, 2]. In 2015, MIT researchers (de Montjoye et al. [3]) reported that the so-called unimportant dates and locations of only four pieces of consumption records are enough to identify 90 percent of the people in a dataset recording three months of credit-card transactions by 1.1 million users. Based on concerns about user's privacy in mobile healthcare, researchers propose a series of privacy protection schemes mainly including data distortion, data encryption, and restrictive release [4].
The anonymity models based on restrictive release were proposed greatly to guarantee user's privacy in healthcare application [5], such as k-anonymity, l-diversity, and t-closeness. k-anonymity was first introduced by Sweeney and Samarati [6, 7] and it has the property that each record is indistinguishable from at least
Avancha et al. [10] presented the privacy problems in mHealth systems and gave a conceptual privacy framework without specific technology; Francis et al. [11] proposed a privacy preserving model for the e-health system which uses the trusted authority to maintain the privacy of user's health records; Sadki and El Bakkali [12] proposed an integrated privacy module to protect user's privacy in mobile healthcare. However, existing privacy preserving models mainly depend on the background knowledge of adversaries who may harm the data by reidentifying it [1]. By reason of the dependence, the research of privacy protection falls into the strange circle; that is, a method is proposed to protect the privacy and is broken subsequently. Then, another method is proposed to solve this problem and is broken again, but differential privacy [13] can protect the presence of an individual regardless of the adversary's background knowledge and give the demarcation of adversary's ability.
In 2006, differential privacy based on probability model was first proposed by Dwork. It could be classified as data distortion and uses random noise to ensure that the adversary fails to guess whether the tuple is present in the dataset with high probability even if he knows all the tuples except the current tuple, which is the theoretical upper limit of attacking capability of the adversary. Differential privacy is a strictly provable and security-controlled method and is introduced quickly and widely to other data application scenes since it was proposed in database domain [14–16]. The popularity of network applications [17, 18] will certainly promote the development of differential privacy.
Leoni [19] reviewed differential privacy, which contains noninteractive processing and is mainly classified under technical level, such as dimensionality reduction and filtering; Xiong et al. [20] gave a survey on differential privacy and applications and neglected time series and graph data release methods; Yang et al. [21] described the classification of differential privacy; however, the detailed statement is insufficient. As the classification of many existing surveys is incomplete and its account is not quite clear, this paper is going to summarize the state of the art in differential privacy research from data level, mainly including a variety of categories, histogram, tree structure, time series, graph, and frequent pattern mining data release methods, and then to discuss open problems by analysis and comparison of existing methods.
The rest of this paper is organized as follows. Section 2 provides the preliminaries on differential privacy and implementation mechanism. Section 3 introduces data processing models and releasing strategies of differential privacy. Section 4 presents data release methods of differential privacy. Finally, it comes to conclude the paper and presents research directions for future work in Section 5.
2. Preliminaries
Differential privacy is a relatively new notion of privacy and is one of the most popular privacy concepts as well. Starting from the basic concept of privacy, this section introduces the notion, implementation mechanism, and two important properties of differential privacy.
2.1. Base Definitions
Privacy is most often defined as the right to be left alone, free from intrusion or interruption. It is an umbrella term, encompassing elements such as physical privacy, communications privacy, and information privacy [22].
Intuitionally, differential privacy ensures that the removal or addition of a single database tuple does not affect the outcome of any analysis [23]. The definition of differential privacy is as follows.
Definition 1 (differential privacy [13]).
Let D and

The parameter ε is called privacy budget, which is used to control the ratio of output of function A in neighboring datasets D and
The strong privacy guarantee of differential privacy comes at the price of much noise added to the results of queries and analyses [21]. Dwork et al. further proposed enhancing the utility of data by reducing the requirements of data security; then
Definition 2 ((
)-differential privacy [24, 25]).
Let D and

No hard rule dictates what value of privacy budget ε and δ should be and they can be set according to the actual application requirements. The value of δ is small usually (
The output probabilities of randomized function A in neighboring datasets D and

Output probabilities of randomized function A in neighboring datasets D and
Function A provides privacy guarantee by adding random noise to the output; that is,
A simple attack example is as follows: Table 1 is a health dataset and provides count service
Health records.

Now, we add a random noise to the output of count function f and let two count results fall into the same range with higher probability; for example,
2.2. Noise Mechanism
The two main noise mechanisms are Laplace mechanism and exponential mechanism, and the noise magnitude refers to privacy budget and global sensitivity.
Definition 3 (global sensitivity [13]).
Given a randomized function 
The global sensitivity for count function
Definition 4 (local sensitivity [41, 42]).
Given a randomized function 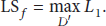
For example, given the subset
Definition 5 (smooth sensitivity [41]).
For 
2.2.1. Laplace Mechanism
The literature [42] proposed Laplace mechanism to achieve differential privacy by adding random noise drawn from the Laplace distribution to the output. Its definition is as follows.
Definition 6 (Laplace mechanism).
Given a dataset D and the function
Let
Let

Probability density function.
2.2.2. Exponential Mechanism
Laplace mechanism is used when the output is numerical, and exponential mechanism is another security-controlled scheme to satisfy differential privacy when the outputs are nonnumerical.
Intuitionally, exponential mechanism still ensures that the change of a single database tuple does not affect the outcome of the score function, and the definition is as follows.
Definition 7 (exponential mechanism [43]).
Let D denote the input dataset; 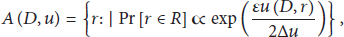

The exponential mechanism can output nonnumerical results according to their values of score function. The output probability refers to privacy budget from the definition above, and the highest scored result is outputted with higher probability when ε is larger; meanwhile, when the difference between the output probabilities grows, the security becomes less; vice versa, the smaller ε is, the higher the security will be.
2.3. Combination Properties
Differential privacy has two important properties [44], as follows.
Property 1 (sequential composition).
Set
Sequential composition shows that privacy budget and error are cumulative linearly when we use multiple differential privacy to release data for the same dataset.
Property 2 (parallel composition).
Set
Parallel composition shows that the degree of privacy guarantee depends on the value of
These two properties play a major role in proving whether an algorithm satisfies differential privacy and judging whether the budgeting strategy is reasonable [4]. For instance, given an algorithm A with n-step, each step has budget
Differential privacy has great advantages compared to traditional privacy protection model; however, there will be some sacrifice for utility of the data to satisfy differential privacy. From Definition 2, the level of similarity in query result of neighboring datasets depends on the value of ε: the smaller ε is, the higher the level of similarity of query results becomes and the stronger privacy guarantee for raw data will become; at the same time, smaller ε leads to larger noise and poor data utility, and vice versa. In short, utility and security of data are a pair of contradictions, so the aim of privacy guarantee is to ensure very high level of privacy while simultaneously providing extremely accurate information about the database [13].
In order to balance the security and the utility of the data, we need to consider how to meet the maximum number of queries using the smallest budget before exhausting ε or how to enhance the accuracy of query under giving ε. Existing methods usually use relative error [31], absolute error [31], variance [30, 38], standard deviation [31], and false negative [40] to evaluate the rationality of algorithm.
3. Data Process Models and Release Strategies
There are two data process models of differential privacy, namely, noninteractive model and interactive model; the latter is also called online query model as data requester is only allowed to access the information through an interface provided by data owner. Similarly, noninteractive model is called offline query model as data requester can directly access the sanitized dataset released by data owner [20, 42].
Interactive model is shown in Figure 3; data owner provides a data query algorithm based on differential privacy, and data requester sends a query request; when the query algorithm receives the request, it gets the raw data from the original database and does sanitizing process of raw data; then the sanitized data is returned to the requester. In this model, query number is restricted by privacy budget ε; the more query number leads to smaller budget for each query if total budget ε is a constant and a larger noise is added to the query result; in the end, the query result becomes inutile. So how to design the query algorithm to provide the maximum number of queries under limited budget ε is the key to this model.

Interactive model.
Noninteractive model is shown in Figure 4; data owner is a trusted curator and releases a sanitized dataset, and data requester sends a query request; when the sanitized dataset receives the request, the noisy result is returned to the requester. In this model, query number is unrestricted by privacy budget ε, so how to design the release algorithm with high efficiency to enhance the accuracy of query is the key to this model.

Noninteractive model.
Difference privacy research is based on the two above models and there are roughly three data release strategies as follows.
Strategy 1 (see [45]).
Noise
Algorithm 1.
Input. Raw data
Output. Released data
Strategy 2 (see [45]).
First, the conversion and the compression, which usually can reduce the sensitivity
Algorithm 2.
Input. Raw data
Output. Released data
Strategy 3.
Noise
Algorithm 3.
Input. Raw data
Output. Released data
These three data release strategies can be used alone or in combination. For instance, given a data release method, Strategy 3 is first used to allocate the budget reasonably; then Strategy 1 is used to further enhance the query accuracy by postprocessing.
4. Data Release Categories
How to ensure the level of privacy guarantee while simultaneously providing highly utility of the data is a real concern; therefore, many methods were proposed in this section, and we will give our categories of differential privacy.
4.1. Histogram Release
Histogram is constructed by splitting the input dataset into mutually disjoint subsets called buckets or bins depends on a set of attributes. Any access to the raw data is conducted through the differential privacy interface when users send data query, and the differential privacy histogram is used to answer the user's queries; the process is shown in Figure 5 [46].
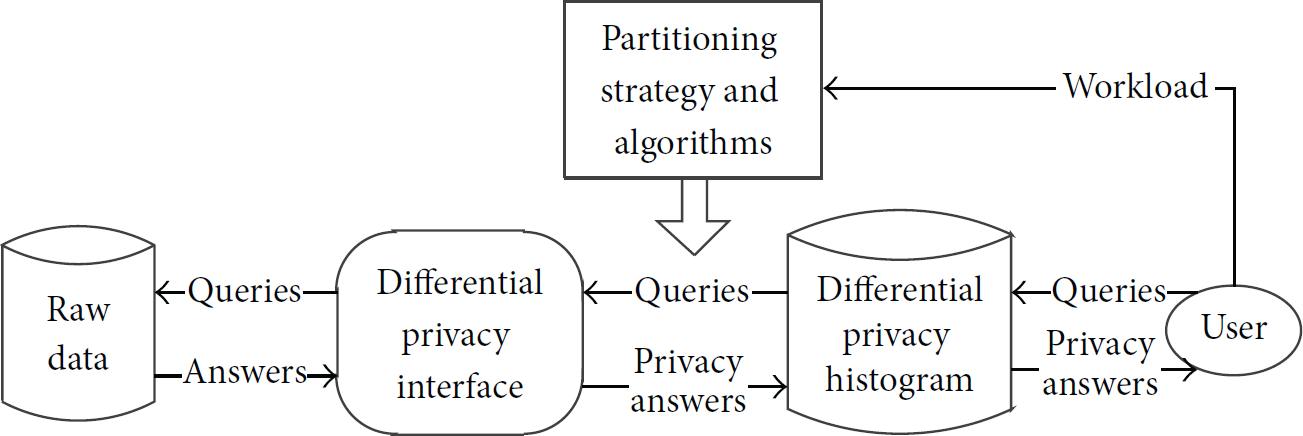
Different private histogram release.
The most straightforward method is to add Laplace noise to each histogram bucket using privacy parameter ε, and the noise is
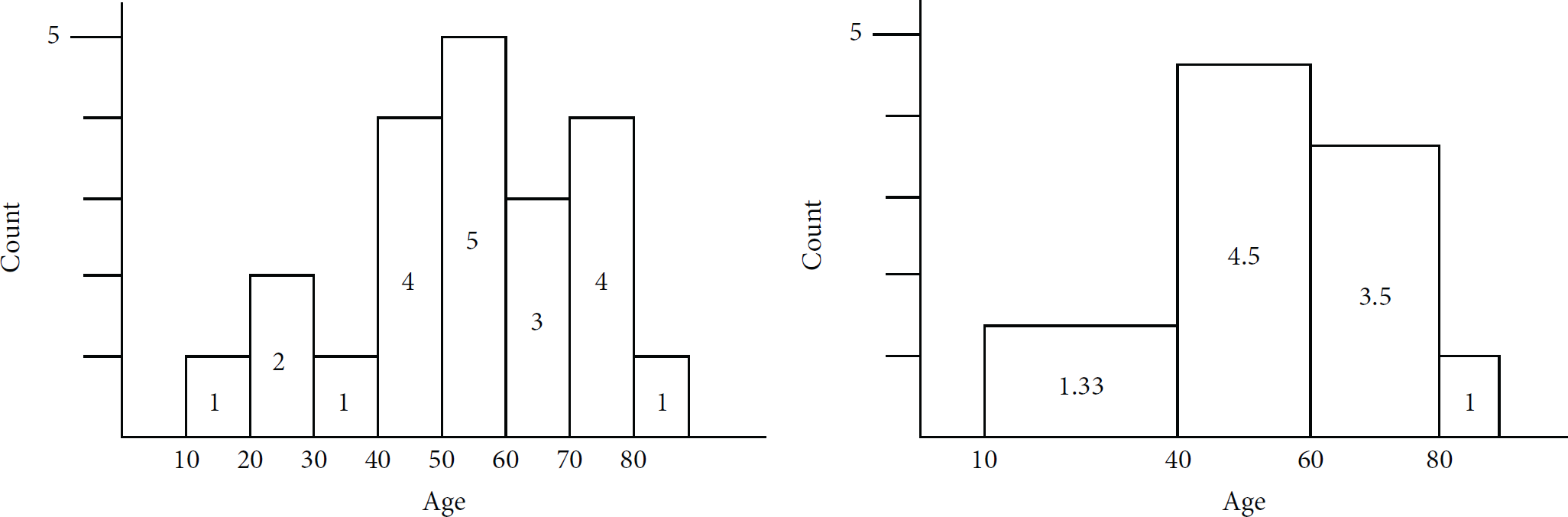
Example of buckets merger.
The noise noise is added to each bucket before the merger, and the total noise is 7noise; after merge operation, the total noise becomes 3noise, which is smaller than the value before the merger. However, merge operation introduces an approximation error as the number of tuples in the partition is the average value of the number of tuples in multiple buckets.
We need to make the least possible number of partitions to reduce the noise error and make the number of tuples of buckets in a partition the same as much as possible to reduce the approximation error. In general, a finer-grained partitioning will introduce smaller approximation error but larger noise error, so finding the right balance between approximation error and noise error is a key question [46].
Xiao et al. [29, 46] proposed a partitioning strategy based on the
The process of
In view of the right balance between the appropriation error and the noise error, Xu et al. [15] proposed the notion of Sum of Squared Error (SSE) in order to reduce the appropriation error and enhance the data query accuracy. SSE is defined as follows:
Two algorithms NoiseFirst and StructureFirst are proposed dependent on SSE to measure the error between the histogram H and the original count data D. Strategy 1 based NoiseFirst constructs the optimal histogram adopting by dynamic programming method after adding noise and is fit for short-range query; Strategy 2 based StructureFirst generates the optimal histogram based on the original count sequence, which has the risk of privacy disclosure. StructureFirst first uses partly privacy budget
In order to reduce the error in long-range query, Hay et al. [47] proposed optimizing histogram by hierarchical tree structure. Histogram is transformed into hierarchical tree structure; then one can arrange all queried intervals into a tree, where the unit-length intervals are the leaves [48], and the query accuracy is enhanced by the consistency check between each layer node of the tree.
In view of the hierarchical method for optimizing histogram, Qardaji et al. [48] researched the factors which affect the mean squared error (MSE) of range query under the consistency check and different budgeting strategies. The hierarchical method in one dimension can reduce MSE when branching factor is more than 4; however, the hierarchical method fails to adapt multidimensional histogram when the dimensionality is greater than or equal to 3. The noise is directly added to each unit bucket in the histogram, which is called the Flat method by Qardaji et al., and Flat outweighs the hierarchical method. Detailed analysis of histogram release methods is shown in Table 2.
Histogram release methods.

In a word, methods based on histogram release usually need to reconstruct the original histogram; when the number of partitions k grows, the approximation error gets less, but the noise error becomes larger; meanwhile, it will enlarge the time cost and make its application restricted. For instance, the time complexity of StructureFirst is
4.2. Tree Structure Release
In order to seek differential privacy budgeting strategy and reduce the query error, a series of methods based on tree-structure data split were proposed, and they are known as private spatial decompositions which divide the geospatial data into smaller regions and obtain statistics on the points within each region [30]. If the partition discloses the sensitive information during spatial decomposition, it is called data-dependent decomposition; otherwise, it is called data-independent decomposition. For instance,
(1) Data-Dependent Decomposition. As shown in Figure 7, node
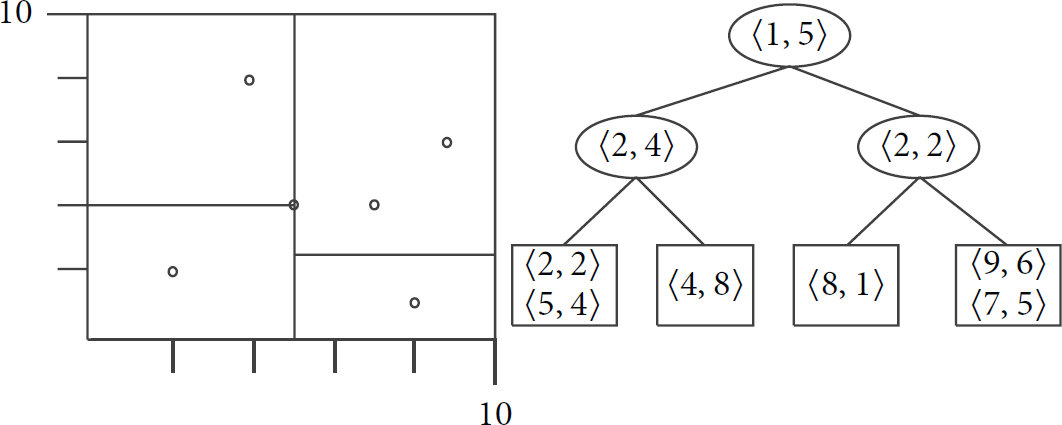
Example of private
As for indexing structure based on
Cormode et al. [30] proposed EM method to judge the median according to exponential mechanism among the
(2) Data-Independent Decomposition. Cormode et al. [30] proposed the algorithm Quad-opt based on quadtree, which recursively divides the data space into equal quadrants, does not disclosure data information, and belongs to data-independent decomposition. As shown in Figure 8, the data a is divided into four quadrants
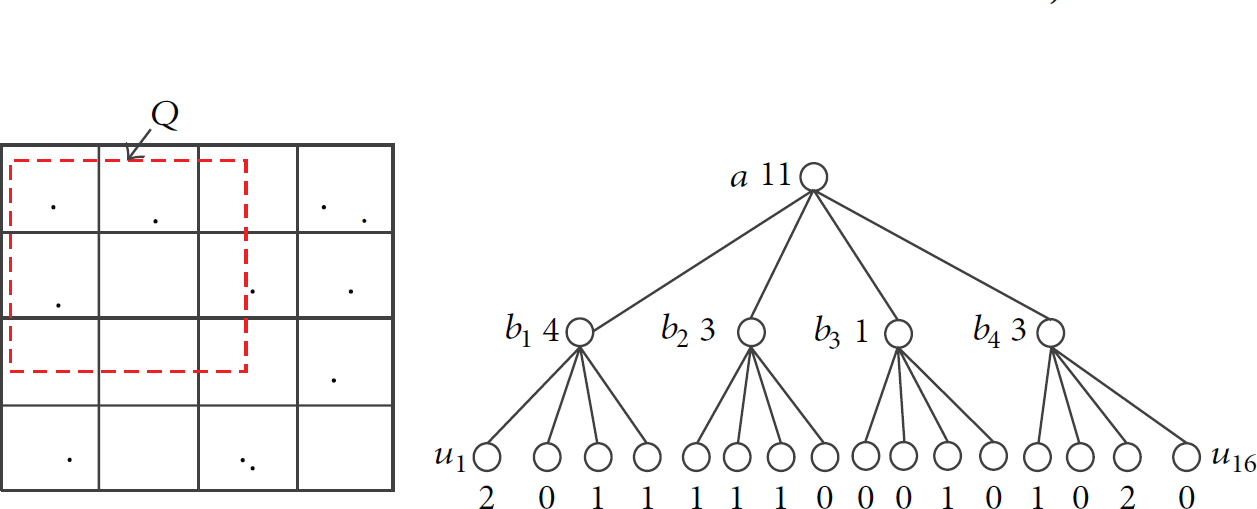
Example of private quadtree: the numbers are the actual counts.
If allocating all privacy budget to the leaf nodes, the algorithm is equivalent to directly dividing the data space into
The partition based on quadtree or
UG splits the space data into
UG treats all cells equally whether sparse cells or density cells. When the cell is very sparse, the noise error is too large; on the other hand, when the cell is very dense, the nonuniformity error is too large. Qardaji et al. further proposed the adaptive grids method AG to balance the two errors: when a region is sparse, a finer granularity is needed to reduce the noise error; when a region is dense, a coarse granularity is used to reduce the nonuniformity error.
AG first splits the space data into
Tree structure release methods.
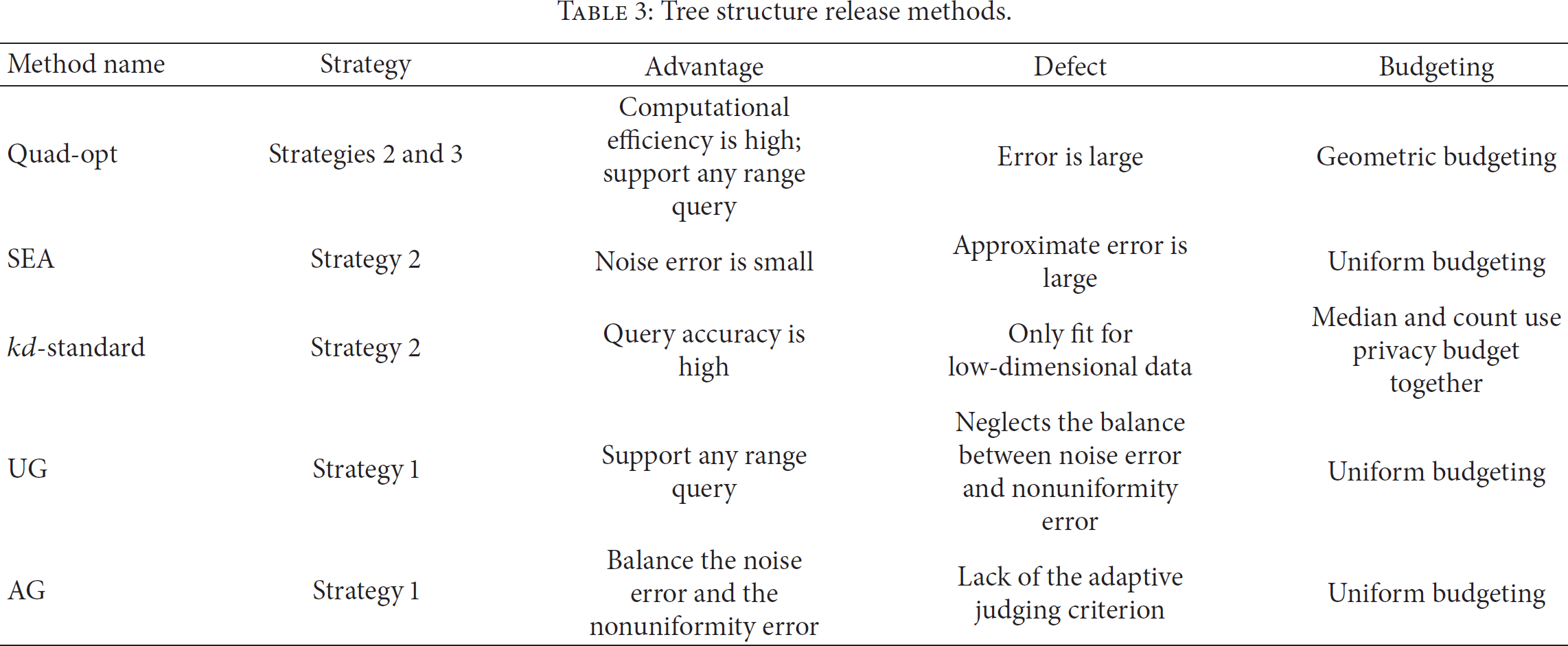
In conclusion, there is no privacy risk for tree structure in the data-independent decomposition, but how to reduce the noise error is the key for our special research. In Fan et al.'s data category, there are only sparse data and dense data, and the partition of data category is too coarse, so how to partition the data category based on the variance or information entropy to enhance the query accuracy is one of the research directions in the future. In data-dependent decomposition, some privacy budget is needed to guarantee the privacy for
4.3. Time Series Release
There are many differential privacy real time data release, such as MHR, GPS, and track. The real time data with higher correlation between time stamps has a timescale, if the length of the time series is T and the noise
As for time series data, in order to reduce the error, Rastogi and Nath [52] proposed algorithm
As for real time traffic monitoring data, in order to raise the execution efficiency and query accuracy of the algorithm in the real time environment, Fan et al. [32] proposed Temporal Estimation Algorithm (TEA) based on the time series model. Given the space G, TEA first splits the space into
For the time span T, if a real time system has higher sampling rate, larger noise will be introduced to satisfy the differential privacy; on the contrary, the approximate error is larger if the system is with lower sampling rate, so how to select the value of sampling rate is the key. Fan et al. proposed an adaptive sampling algorithm FAST [33, 34] to solve the problem in the subsequent research. FAST can adjust the sampling rate F automatically according to data dynamic and
As for web browsing behavior data, utilizing the rich correlation of the time series, Fan et al. proposed session-level differentially privacy algorithm U-KF [35] based on the user-level framework FAST. U-KF releases the differential privacy aggregates using state-space model in real time and adopts Kalman filter [53] during postprocessing. Given original data
Time series release methods.

As for record data, in order to enhance the query accuracy, Xiao et al. [54, 55] proposed Privelet method based on wavelet transform. Privelet does not directly perturb the frequent matrix M of input data, but first transforms the M into the wavelet coefficient matrix C, which is perturbed by Laplace noise; then the noisy coefficient matrix is mapped into noisy frequent matrix
4.4. Graph Release
Nowadays, digital health social network often contains user's sensitive information, and directly releasing these network data may harm individual privacy, so the network data should be sanitized before the release. Network data is different from general data, and it will be highly sensitive to small changes as the clustering coefficient is larger according to graph theory. For instance, adding random noise to a subgraph counting query for purpose of masking the presence or not of an edge, and larger noise implies poorer utility of the data. In order to enhance the utility of the sanitized data, a series of methods were proposed.
Hay et al. [57] first proposed edge differential privacy for networks data or differential privacy for short. Given graphs
Definition 8 (edge differential privacy [57]).
Let 
Similarly, edge differential privacy can be expanded to multiple edges; if neighboring datasets differ on k edges, that is,
In order to raise the utility of graph under the requested level of privacy, the graph's structure is needed to be captured first; then it would be converted back into a synthetic graph desired to be the same with original graph after adding noise. Sala et al. [58] proposed Pygmalion method, which captures the graph's structure according to

Example of
Pygmalion first captures the
Wang and Wu [36] also used
Wang et al. [37] proposed another method, that is, LNPP, which uses spectral graph to guarantee the graph data. Spectral graph analysis mainly applies the graph's adjacent matrix to construct the graph's topological structure. For example, the adjacent matrix
Adopting the spectral graph and the
Classical graph model is construed by considering the observed edges, and HRG uses the connection probabilities between vertices. In the HRG model, graph G can be represented by a hierarchical structure and the connection probabilities. The hierarchical structure of G is a rooted binary tree which has n leaf nodes corresponding to the n vertices of G [38]. Each internal node r has a probability
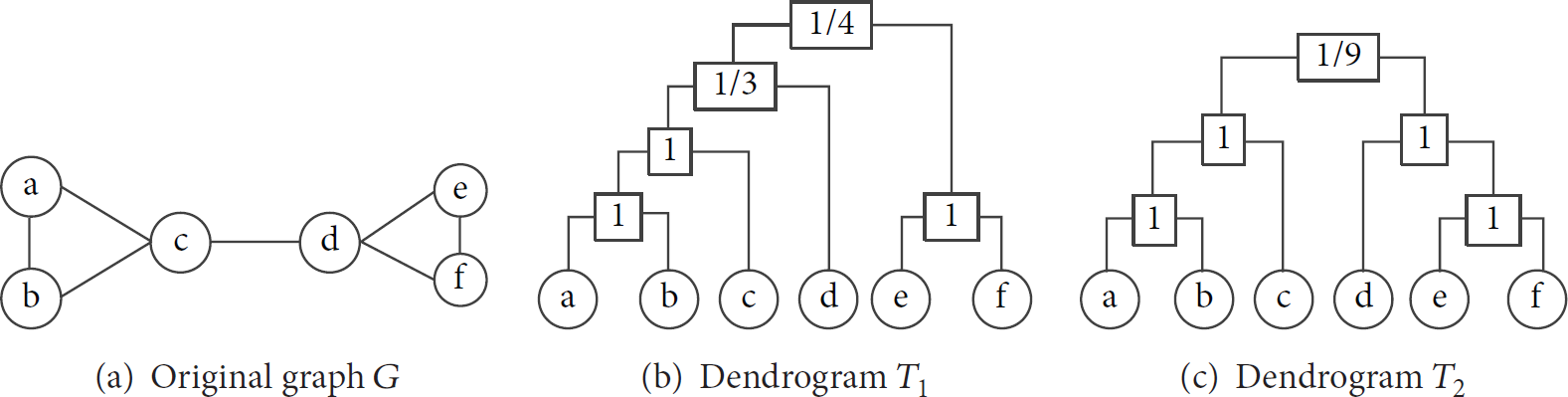
Example of the HRG model.
For graph G, in order to select a good dendrogram from numerous candidates, the notion likelihood is proposed to estimate how to represent G exactly by the selected dendrogram; that is,
In hrg-
Time series release methods.

To sum up, directly adding noise to graph will lead to poor utility of the data as high sensitivity of graph, and it requires to project the data to other data types, such as spectral domain,
4.5. Pattern Mining Release
Frequent pattern is a subset of items and is frequently present in dataset, such as item-set, subsequence, and substructure, and it is the basis of mining tasks, that is, classification, clustering, and so forth. However, it may reveal individual's privacy during frequent pattern mining, so how to identify the useful patterns in the data while simultaneously guarantee user's privacy is a new research direction of data mining.
Frequent pattern mining algorithm is usually measured by support degree [28, 39, 40], occurrence [61], and stay point [62, 63], given data
In terms of personal location information, in order to mine the useful pattern, for example, people's interesting geographic location, Ho and Ruan [62] proposed BuildDPQuadTree method based on quadtree and density-based clustering algorithm (DBSCAN). How to define the interesting region when we query the location history database is the focus, and the notion of stay point is proposed. Given the trajectory data
BuildDPQuadTree first recursively divides the data space G into small regions, given stay point set S, threshold
The sensitivity of itemset query depends on the dimensionality of itemset during Top-k frequent pattern mining. In order to reduce the sensitivity, the data usually is projected into a lower dimensional space. Li et al. [39] proposed PrivBasis method to search Top-k frequent patterns. In the initialization step, PrivBasis tries to reduce the search space by finding the minimal sets of items
In order to raise the utility of the data, Lee and Clifton [40] proposed the NoiseCut method based on the sparse vector technique and FP-tree. NoiseCut first identifies all frequent itemsets L; in this step, sparse vector technique is adopted to reduce consumption of privacy budget, that is, given a noisy threshold
As for graph data, Shen and Yu [28] proposed frequent graph pattern mining method Diff-FPM based on Markov chain Monte Carlo random walk technology. Diff-FPM obtains the Top-k frequent subgraph mainly according to random walk; then, the real counts of subgraphs are perturbed by Laplace random noise. The key to Diff-FPM is whether random walk can reach steady state or not. Diff-FPM satisfies ε-differential privacy if steady state is reached; if not, Diff-FPM only satisfies (
As for sequential data, such as DNA sequences and trajectories, Luca and Li [61] indicated that there are some disadvantages using support to mine frequent sequential patterns; for example, one pattern may fail to be regarded as frequent pattern if it repetitively occurs in the same transaction, which may issue in a loss of information patterns. In addition, patterns are represented as a subset of an universe of items and may not well describe the sequentiality of important events in reality [61]. In order to successfully mine the frequent sequential patterns from the sequential data, Bonomi et al. proposed the notion of occurrence which can identify repetitive patterns as frequent. Given a pattern
Pattern mining release methods.

Luca and Li pointed out the existing differently privacy frequent pattern mining methods mainly based on the exact data; however, the real data usually are noisy, and some patterns may be lost [61]. There are less research about how to mine the frequent patterns in the noisy data, which is a future research direction. At the same time, how to raise the utility of the data while simultaneously providing privacy guarantee is an issue for further research.
For different data types, related researchers proposed a series of differential privacy data release methods, and the methods summarized in this paper only are a part of the whole; there are many methods which the paper fails to describe, such as batch query methods based on matrix [68–70] and data release methods based on machine learning [71].
4.6. Discussion
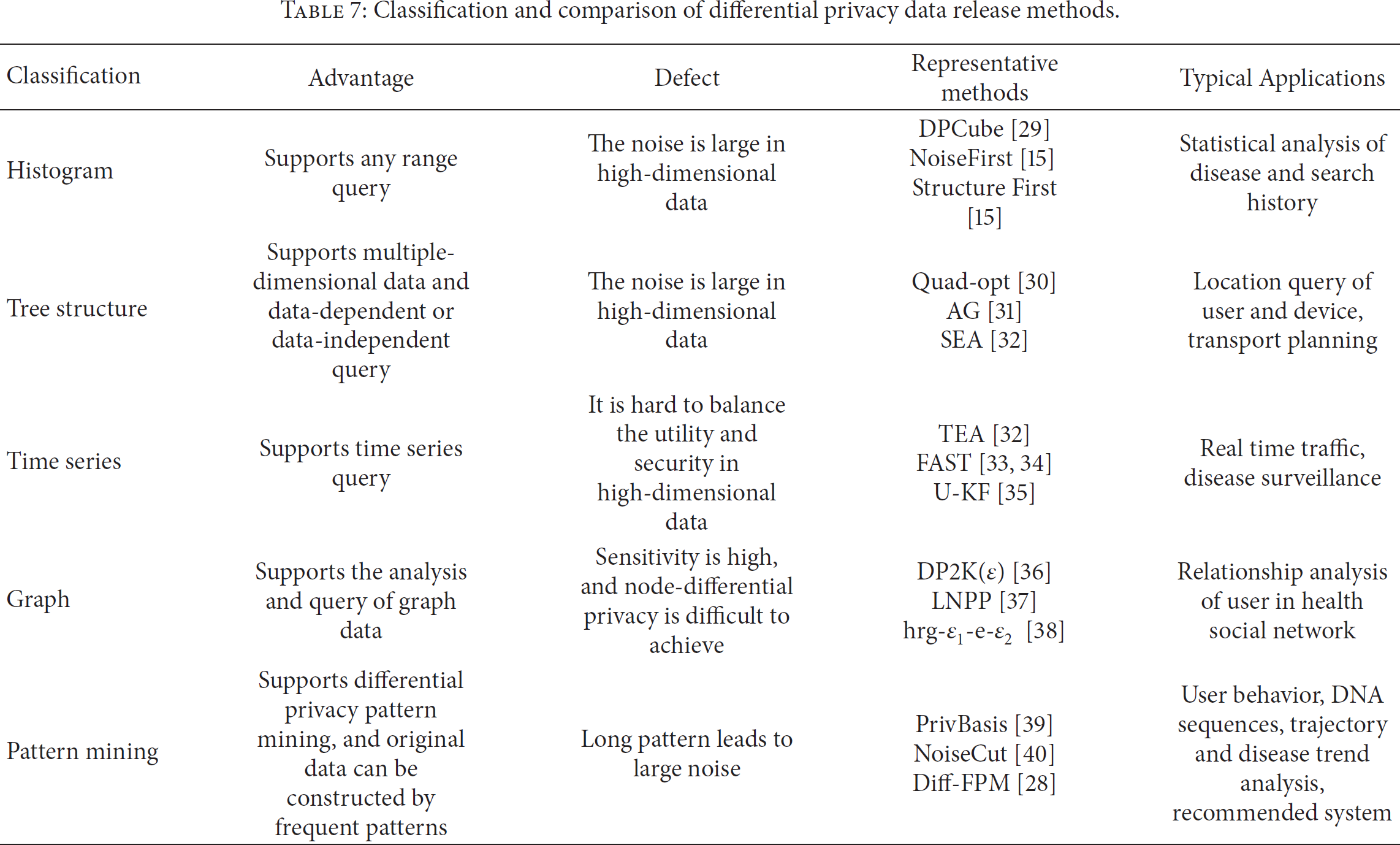
Data release methods under different strategies are the main research contents for differential privacy and are the theoretical basis for practical applications. Classification and comparison of the differential privacy data release methods are shown in Table 7, from which we can see that there are few research achievements in this new research area, and there still exists many urgent issues to be addressed and some new study directions to be explored.
Classification and comparison of differential privacy data release methods.
(1) Highly Sensitive Problem. As for multiple-dimensional or graph data, whose sensitivity is so high that it may lead to poor utility of the data, how to reduce the sensitivity of function f and enhance the utility require deep-going research.
(2) Time Series Problem. As far as time series data is concerned, how to balance the utility and the security when the time T is increasing is a question deserving research, and privacy guarantee for online data is another question worth studying as well.
(3) Efficiency Problem. Computational complexity of many differential privacy algorithms is relatively high, so how to ensure privacy while simultaneously improving algorithm efficiency is a question deserving research.
(4) New Research Direction for Differential Privacy. Among existing differential privacy data release methods, the data usually are stored in one party; if the data are stored in multiple parties, therefore how to share the data and guarantee user's privacy between multiple parties is a question deserving further research for distributed differential privacy [72, 73], which is also called security multiparty computation problem. It mainly faces the following difficulties: (1) excessive communication overhead makes the algorithm infeasible if the data and participants are large; (2) how to design an algorithm and make it satisfy differential privacy is another obstacle. So an efficient and safe algorithm with lower communication overhead is a question deserving research, for example, how to design a differential privacy algorithm for such distributed real time streaming data as financial data.
(5) The Definition Expansion of Differential Privacy. Kearns et al. [74] introduced the differential privacy into game theory to guarantee player's privacy. The paper points out that the equilibria of complete information games can be implemented in setting of incomplete information under certain conditions (the number of players is large). Any algorithm that estimates a correlated equilibrium of a complete information game while satisfying a variant of differential privacy is called joint differential privacy. By this time, no group of the players can derive “much” about the type of any player outside the group, even if these players collude in an arbitrary way [74].
Definition 9 (joint differential privacy [74]).
Given a randomized function 
In joint differential privacy, the input date has n data elements and the output also is a vector of n messages; that is, the input
Joint differential privacy is an appropriate solution concept for problems whose solution can be partitioned amongst the n players who provide the privacy data to the algorithm, such as equilibrium computation [74, 75] in game theory and agent's privacy guarantee in maximum matching problem [76].
5. Conclusion and Future Work
Differential privacy has become the de facto standard to guarantee privacy and is one of the hot research topics in the field of healthcare applications. In this paper, the methods of differentially private data releasing in recent years' literatures are classified, and a series of data release methods are summarized for privacy problem, which provide certain references for differential privacy in further study. In Section 4, as for different categories, different research directions are proposed; for example, it is pointed out that time series release combined with wavelet transform is one of the research directions to solve the privacy of real time streaming data. However, there are still some other questions which are worth studying. They are summarized as follows.
(1) The Privacy Budgeting for Tree Structure. Privacy budgeting strategy is usually uniform budgeting in tree structure release, and Cormode et al. [30] presented a novel nonuniform budgeting method based on complete quadtree to improve query accuracy. The key of the method is geometric budgeting strategy, and its theoretical analysis is conducted by the total variance of the all node variances with a great theoretical significance, but the effect is not optimal as fewer nodes may be touched in actual queries. Inspired by it, the error of the data query is small if privacy budget properly tilts toward to the below level nodes of the tree, so how to design an optimal privacy budgeting strategy is a great challenge.
(2) The Balance of the Noise Error and Nonuniformity Error. As for geospatial data, Qardaji et al. [31] constructed a differentially private synopsis by choosing the right partition granularity over the data domain to balance the noise error and nonuniformity error, which is proportional to the number of data points in the cells that intersect with the border of the query rectangle. However, nonuniformity error is not only connected with the point number, but also refers to the area of the cells that intersect with the border of the query rectangle, as the less area of intersected portion is, the less nonuniformity error will be. Nonuniformity error especially is 0 when the area of intersected portion is 0, so how to choose the optimal partition granularity for geospatial data when nonuniformity error is connected with both point number and area is a great challenge as well.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (Grant no. 41371402); the National Basic Research Program of China (973 Program) (Grant no. 2011CB302306); the Fundamental Research Funds for the Central Universities under Grant no. 2015211020201.