
Abstract
Providing reliable communication represents one of the major barriers to wireless sensor networks. In this paper, we propose a fault-tolerant tableless routing protocol called E-cube+, inspired from e-cube routing protocol, to support intelligent rerouting. A range of fault-tolerant routing properties of E-cube+ (such as loop-freeness, failure recovery guarantees, and bounded latency) have been derived and analyzed. Experiment results also show that E-cube+ is able to route data properly without complicated and energy-intensive routing table lookup processes even when node failures occur.
1. Introduction
Due to the constraints of available resources in WSN [1–4], sensor nodes are subject to relatively high fault rates. When certain sensor nodes fail, the communication function of the WSN would be interrupted, resulting in a low transmission efficiency of the entire network. In order to mitigate the impact of the limited resource constraints imposed on WSN, a better routing protocol that can tolerate node failures while keeping the transmission efficiency of the entire WSN is required. A fault-tolerant routing protocol can significantly improve the reliability and stability of the network system. However, some resource constraint characteristics (e.g., limited energy supply and small memory) make the design of fault-tolerant routing protocols for the WSN a challenging task.
For a healthy WSN without node failures, a routing algorithm called e-cube [5] is widely used in many WSN applications [6–8]. The e-cube is a dimension-ordered deterministic routing algorithm based on the hypercube model, which is easy to implement in parallel computer architectures. The conventional e-cube routing algorithm has many desired properties (such as low latency and loop freeness), but it is not able to work well under an injured hypercube, which has faulty links/nodes.
There are many existing protocols that can be used for WSNs that are fault-tolerant [9–14]. However, these protocols are unable to overcome the resource constraints of WSNs, because most protocols require a large memory space for the routing and power-consuming table lookup operations. In large-scale WSN, the impact of these requirements is more significant. Thus, in this paper, we explore the design of a memory-efficient and fault-tolerant routing protocol.
To dynamically adapt to network failures or congestions, Gaughan and Yalamanchili [15] proposed backtracking protocols to find an alternative path in a depth-first manner. In such cases, sensors must reestablish the routing information and cannot achieve an immediate path swap, which may increase the transmission cost (such as long latency and packet loss). Chen and Shin [16] used an n-bit vector tag to keep track of the abundant dimensions which are used to calculate alternative paths bypassing faulty components. The n-bit vector tag inevitably introduces communication overhead and additional computation. In the safety vector approach [17], each sensor node needs to maintain a vector indicating the awareness of the status of other nodes. This raises some communication and computation issues simultaneously, which make WSN routing design even more challenging. As such, these methods are not suitable for WSNs due to limited resources (such as CPU power or memory) and high latency problems.
In this paper, we propose a fault-tolerant routing protocol named E-cube+, which covers the e-cube original spirit and can be implemented in a hierarchical routing network. E-cube+ is able to compute the alternative backup paths without routing table lookup to recover the WSN from network failures. The proposed scheme offers a quick reroute functionality with low processing and memory overhead for the WSN. The salient features of E-cube+ are listed as below.
(1) No Routing Table. In the E-cube+ algorithm, every node finds the next hop to the destination using simple bit operations. Except for the storage of its own label and related proxy labels, it saves significant memory space and avoids power- and time-consuming routing table lookup. Unlike e-cube routing algorithm, E-cube+ routing protocol presented in this study not only forwards the packets but also effectively reroutes the packets by obtaining an alternative path to the destination node.
(2) Failure Recovery Guarantees. E-cube+ is capable of finding backup paths with (
(3) Bounded Latency. In m-DCH, every pair of nodes has a bounded length m due to the inherent property of the hypercube model. In addition, when a single node fails, the worst case message transmission latency (MTL) in terms of hop count is a fixed number of m (hops). The bounded latency for real-time packet transmission is a nice property, since there will not be out-of-control variation during data transmission.
2. Related Work
Fault tolerance is to ensure that the system still works as expected even failures occur. In fault-tolerant computing, some algorithms are able to produce a correct output or a quasicorrect output when in presence of memory faults. Many researches adopted the memory error detection/correction code, such as cyclic redundancy check (CRC), hamming code, and checksum, for soft errors in a memory system by little overhead of code size as there exist memory errors and mal-packet problems [18–22]. In data communication area, timeout detection and recovery (TDR) is a popular solution for resolving fault tolerance related issues. If the acknowledgement is not received by the sender within the timeout period, the data would be retransmitted [23].
Ad hoc on-demand distance vector routing (AODV) [24] and dynamic source routing (DSR) [25] are two simple and widely used routing protocols in WSN. Both protocols are efficient routing protocols to establish the shortest path with low power consumption. However, the nature of WSN topology is dynamic due to many factors including limited power supply of the sensor nodes, unstable wireless link quality, and physical damage. The above primitive single-path routing approaches are not well suitable for WSN because the source node triggers the alternative path discovery operation and may cause further unacceptable delay and overhead for data transmissions when the primary path fails to forward data towards the sink. Thus, multipath routing approach is deemed an effective technique to meet the fault tolerance demands. A set of multiple paths between the source nodes and the sink are stored to provide constructed alternative paths as the backup paths in case of the primary path failure. By summarizing previous typical multipath-based schemes such as [26–33], we introduce four phases of the multipath routing procedures.
Phase 1: locate a set of intermediate nodes to establish paths from the source node to the sink node based on different criteria (e.g., link-disjoint [26], node-disjoint [27], or partially disjoint paths [28]).
Phase 2: choose the right number and efficient paths from the set of path disjointedness discovered at Phase 1. Those selected paths are ready to transmit the data when the primary path fails. Of course, the path selection technique has a big impact on the fault tolerance capabilities [29]. For example, energy-adaptive multiple paths routing algorithm (EMRA) [30] considers energy consumption a part of the cost functions to be used for selecting fault-tolerant multiple paths.
Phase 3: activate the chosen paths from Phase 2 and start the data transmission across selected paths. There are several options to choose from when to deliver data (such “as one path at a time” [31], “simultaneous use of K-paths” [32], and “all paths at the same time” [33]). In “one path at a time approach”, source node uses only one path to transmit data and switches to another alternative path when failure occurs. On the other hand, the source node uses K distinctive paths or all paths for data transmission concurrently [32, 33]. The source node is able to utilize all activated paths sending multiple copies of the same packet over all paths in order to recover if some paths fail.
Phase 4: reinitiate path discovery process to accommodate the dynamic topology changes when a link/node fails.
In summary, multipath approaches can find a set of alternative paths via path recovery process. When the primary path failure occurs, the intermediate node will reroute the packet via the alternative path. The aforementioned methods construct the multipath routes through broadcasting message to the whole network in order to collect all information (such as residual energy, hop counts, and the signal strength) from the neighboring nodes and create the forwarding table for data transmission.
WSN typically involves hundreds or even thousands of sensors. Other distinctive features of wireless sensor networks are CPU capability and low-memory capacity. To our best knowledge, multipath routing protocols do not address the resource constraints of the sensor (such as CPU and storage). However, they need to process all information collected from the enormous number of sensor nodes, store all multipath routing information, and look up the routing table for every packet. As such, energy-aware multipath techniques usually suffer from broadcasting message overhead and a lack of scalability. To address this resource constraint issue of the sensor, the proposed E-cube+ routing algorithm applies simple bit operations in every node to determine the next hop to the destination without the routing table lookup.
We summarize the differences among E-cube, multipath routing based EMRA [30], and the proposed approach (E-cube+) at Table 1.
Comparison with various approaches.

3. Fault-Tolerant E-Cube+ Routing
We propose a fault-tolerant tableless routing protocol with low energy cost and low memory requirement called E-cube+ routing protocol, which extends e-cube routing protocol to handle the faulty conditions. For better describing the proposed E-cube+ algorithm, here we define some notations that will be used throughout this paper (as shown in Table 2).
Notations and descriptions in E-cube+ model.

3.1. Packet Header Format
As mentioned in the above description, E-cube+ uses the bit arrays of the vertices in the hypercube model as the labels for the nodes in the WSNs. The E-cube+ protocol combined with the packet header will be able to run the routing algorithm. The packet header format (as Figure 1) in the E-cube+ protocol is defined as follows.

Packet header format of E-cube+ in IEEE 802.15.4.
(i) Length. It is a byte to represent the length of each E-cube+ label and to imply the total length of E-cube+ packet header (one byte + five times of the length of each E-cube+ label).
(ii) Genuine Source Label (GSLabel). When the number of sensor nodes exceeds a complete hypercube, the extra nodes can use other nodes as their proxy for transmission. This field is for the source node, and the corresponding proxy node uses the source label field. If no proxy is used, GSLabel equals 0.
(iii) Genuine Destination Label (GDLabel). Similar to the GSLabel, this field is for the destination node. The corresponding proxy node uses the destination label field. If no proxy is used, GDLabel equals 0.
(iv) Source Label (SrcLabel). It is source node label or the proxy label of the real source.
(v) Destination Label (DstLabel). It is destination node label or the proxy label of the real destination.
(vi) Intermediate Label (ImdLabel). It is the current node label before transmission to the next node.
3.2. Routing Algorithm
Based on a hypercube model, the well-known e-cube or “left-to-right” (LR) routing algorithm routes a packet from source to destination by traversing the differing dimensions in a left-to-right order. However, e-cube routing algorithm does not address network link failure issues completely. To address this issue further, the proposed E-cube+ routing algorithm applies simple bit operations in every node to determine the next hop to the destination. Each node may perform two main functions:


For instance, the binary presentation of
If E-cube+ detects communication problem from the current node to destination node via node

The E-cube+ routing algorithm is illustrated in Algorithm 1. In a wireless sensor network equipped with E-cube+, during data transfer between nodes, every node in the process performs the following routing steps.
Line 03: receive the packet (Pkt).
Lines 04–11: if current node is the destination, there are three cases. (1) If there is a proxy before the destination (its label is Pkt.DstLabel), pass the packet to the upper-layer protocol; (2) the current node is the destination, and there is no other node as the proxy; (3) if it is the proxy of other nodes, then broadcast the packet to its proxy member.
Lines 13–16: call getLeftN and get the next hop of the main routing path; then put its own label in the Pkt.ImdLabel, and forward the packet to the next hop.
Lines 19–22: call getRightN and get the next hop of the backup path; then put its own label in the Pkt.ImdLabel, and forward the packet to it.
Lines 25–29: start backward routing. If it is already at the source node, discard the packet.
(01) MyID = selfID(); (02) while (TRUE) { (03) Pkt = receivePacket(); (04) if (MyID == Pkt.GDLabel) // Genuine receiver behind a proxy (05) sendUpperLayer(Pkt); (06) else if (MyID == Pkt.DstLabel) { (07) if (Pkt.GDLabel == 0) // Genuine receiver does not have a proxy (08) sendUpperLayer(Pkt); (09) else // Current node is a proxy and broadcasts in its domain (10) broadcastProxyMember(Pkt); (11) } (12) else { // Forward at intermediate nodes (13) LeftN = getLeftN (MyID, Pkt.DstLabel); // Main path (14) if ((LeftN != Pkt.ImdLabel) && Link(LeftN)){ (15) MarkPacketImd(MyID, Pkt); (16) sendPacket(LeftN, Pkt); (17) } (18) else { (19) RightN = getRightN (MyID, Pkt.DstLabel); // Backup path (20) if (Link(RightN)) { (21) MarkPacketImd(MyID, Pkt); (22) sendPacket(RightN, Pkt); (23) } (24) else { // Forwarding path failed (25) if (myID == Pkt.SrcLabel) // Drop as no available path (26) dropPacket(Pkt); (27) else { // Backward to previous node (28) MarkPacketImd(MyID, Pkt); (29) backwardPacket(PreviousNode, Pkt); (30)
In summary, the working path is decided by the routing functions based on E-cube+ routing algorithm (as shown in Algorithm 1). Routing path is determined based on the labels of the destination node and that of current node. Upon receiving the packet, the current node obtains the next hop of the principal working path via executing the Lines 13–16. If E-cube+ detects a communication problem to the next hop of the principal working path, it would execute the routing logic (Lines 19–22) to find the next hop of the backup path. If both next hops of the principal working path and the backup path are not reachable, the current node would perform the backtracking procedure to send the packet back to the previous node (Lines 25–29).
3.3. Example
For clear explanation, we will use a 5-DCH network topology as an example and demonstrate three cases with different failure nodes to explain the transmission of a packet from the source node
A tracing example of E-cube+.

Case 1 (normal routing with no failure nodes).
Case 2 (backup routing with a single failure node).
Case 3 (backward routing during multiple failures).
3.4. Property
In this section, we first perform the latency bound analysis for the fault tolerance capability of E-cube+ and then show the loop-free routing property for data transmission as in Theorems 1 and 2, respectively. Under m-DCH topology, the proposed E-cube+ method can guarantee successful transmission under
Theorem 1.
When there exists k node failures in m-DCH network topology, the upper bound of MTL is
Proof.
The formula can be proved by mathematical induction as follows.
Step 1. We first prove that the statement is true for
Step 2. We prove that if the statement is true for
When
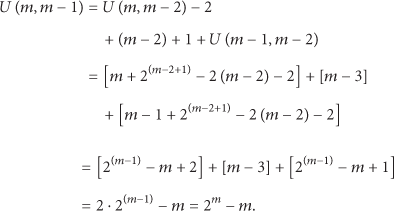
The E-cube+ produced routing path looks like Pascal's triangle, called Yang Hui's triangle in China, plus the final destination node. A brief explanation of the above derivation is listed as follows.
Finally, the MTL inferred above is equal to the result of the formula according to

Example of the transmission route from the source to the destination by E-cube+ under m-DCH for the worst case analysis.
Theorem 2.
The routing procedure of E-cube+ algorithm is loop-free, denoted as
Proof.
The loop-free property can also be proved by mathematical induction and recursive calculation. As mentioned above, the E-cube+ routing path produced is like Pascal's triangle, and we can define a Boolean function expressed as L (
Please note that
Initial. To consider the original routing
Inference. By applying divide and conquer recursively, we can derive that

Hence, it not only shows there are
3.5. Topology Control Concept Illustration
The main emphasis of this paper is to develop a fault-tolerant tableless routing protocol to support intelligent rerouting. The proposed scheme is designed to be able to run on any such hypercube topology. However, the events regarding adding new nodes/links and deleting existing nodes/links that become permanently unavailable are related to topology construction and maintenance issues. In this paper, we assume the topology is constructed by one of the hypercube construction algorithms, such as the topology control scheme proposed in BlueCube [34]. In the rest of this section, we introduce briefly the topology control in BlueCube. Three phases are designed to complete hypercube construction in BlueCube including Phase I: ring construction phase (RCP), Phase II: scatternet construction phase (SCP), and Phase III: BlueCube construction phase (BCP).
Phase I: RCP is used to construct the ring scatternet as well as to maximize the dimensions of the hypercube.
Phase II: SCP aims to reduce the number of piconets and bridges. It also aims to connect those devices that are not connected to the scatternet ring with the masters in the scatter ring.
Phase III: BCP restructures the scatternet ring to a hypercube structure.
Figure 3 briefly illustrates the BlueCube construction procedures. In BlueCube, some terms such as connection key (CK) and degree of connection (DOC) are defined to help distributed nodes to cooperate together in the process of hypercube construction. DOC is the degree of a BlueCube in a scatternet. Two scatternets can be linked together when their DOCs are the same.

BlueCube hypercube construction procedures (redrawn from [34]).
As shown in Figure 3(a), A and B form a scatternet, while C and D form another. The nodes with CK number of
Figure 3(b) shows that node B (the constructor of the scatternet formed by A, B) finds the other scatternet (formed by nodes C and D), and then node B sends a Join request to node C (the constructor of the scatternet formed by C, D). As a result, they can be combined to a bigger scatternet of four nodes (as seen in Figure 3(b)). Note that node D becomes the constructor of the new scatternet since CK = 01 is assigned to node D. As a result, node D is responsible for discovering and forming the bigger hypercube for this new scatternet. Notice that the black node (e.g., nodes C and B in Figure 3(a)) represents the master node in the scatternet. Master may be different from the constructor due to load sharing and role reduction for the embedded system.
As shown in Figure 3(c), the scatternet grows gradually. The combination procedure continues until all nodes join the hypercube. In order to illustrate the scatternet combining in detail, let us denote (A, B*) as a scatternet formed by nodes A and B. The node with an asterisk superscript stands for the constructor of that scatternet. The hypercube-grow process may present as below.
DOC = 1 (A, B*), (C*, D), (G, H*), (F*, E), (O, P*), (N*, M), (J, I*), (K*, L).
DOC = 2 (A, B, C, D*), (G, H, F, E*), (O, P, N, M*), (J, I, K*, L*).
DOC = 3 (A, B, C, D, G, H*, F, E), (O, P, N, M, J, I*, K, L).
DOC = 4 (A*, B, C, D, G, H, F, E, O, P, N, M, J, I, K, L).
After all nodes join the big scatternet, the new constructor node A (CK = 0111) connects node P (CK = 1111) to form a ring and Phase I is completed. As seen in Figure 3(d), in the overall topology, some other nodes (e.g., nodes X, Y) may exist that are not linked with the ring scatternet and will run Phase II (scatternet construction) after some timeout. The Phase II scatternet construction includes role switching procedure (RSP) and remaining device connection procedure (RDCP). After all nodes join the ring scatternet or the master node does not receive any response from the slave node within the timeout period, RDCP of Phase II is completed and Phase III begins. Hypercube is constructed to build a fault tolerance overlay structure based on the Hamming Distance of the CK values assigned to the nodes. Two nodes with Hamming Distance of one will connect to each other (dotted lines as shown in Figure 3(d)) to establish the BlueCube structure.
The events of adding new nodes to the BlueCube and deleting nodes from BlueCube can be handled according to the occurrence of the events. Since the BlueCube topology usually needs to reconstruct topology periodically in practice to optimize the mapping between physical devices with logical labels (CK numbers) assigned to them, new added nodes may participate in the new procedure of hypercube construction at that time. On the other hand, if the adding/deleting event occurs during the operation of two consecutive topology reconstructions, we suggest the addition and deletion events to be handled similarly as in Phase II. As shown in Figure 3(d), nodes X and Y join the scatternet of node F who is in the hypercube backbone. As a result, BlueCube Phase II may serve as temporal topology control service in the background. If the leaving node is a master node in the scatternet ring, the leaving master node selects one of its piconet members as the new master node and passes all its information (including CK, DOC) to the new master. As such, the new master can continue work having the same role in the hypercube structure. If the leaving node is not the master node in the scatternet ring, it may choose the neighbor with the shortest Hamming Distance as an agent to play its role until next topology reconstruction is triggered. For further details about topology control in BlueCube, the reader is referred to BlueCube [34].
4. Simulation and Results
In order to demonstrate the efficiency of the fault tolerance during the node failure period presented in Section 3, we perform the experiments of the label-based multipath routing (LMR) [35], E-cube+ with two labeling schemes, and the routing-table based EMRA (
Firstly, we will introduce the simulation software and the experimental parameters. The simulation was performed on QualNet 5.0. The experiment settings and parameters are listed as follows: (1) sensing field size in simulation: 4.5 × 4.5 km2; (2) data packet size: 512 bytes; (3) data packet rate: one packet per second; (4) transmission range:
From Figure 4, it can be observed that irrespective of the labeling method used in E-cube+ its transmission success rate is much higher than that of the LMR and EMRA. Specifically when the failure percentage of grid nodes reaches 20%, E-cube+ still achieves a success rate of more than 30%. Although E-cube+ with BlueCube can achieve a high success rate, its unrealistic assumption connects each node to eight neighboring nodes.
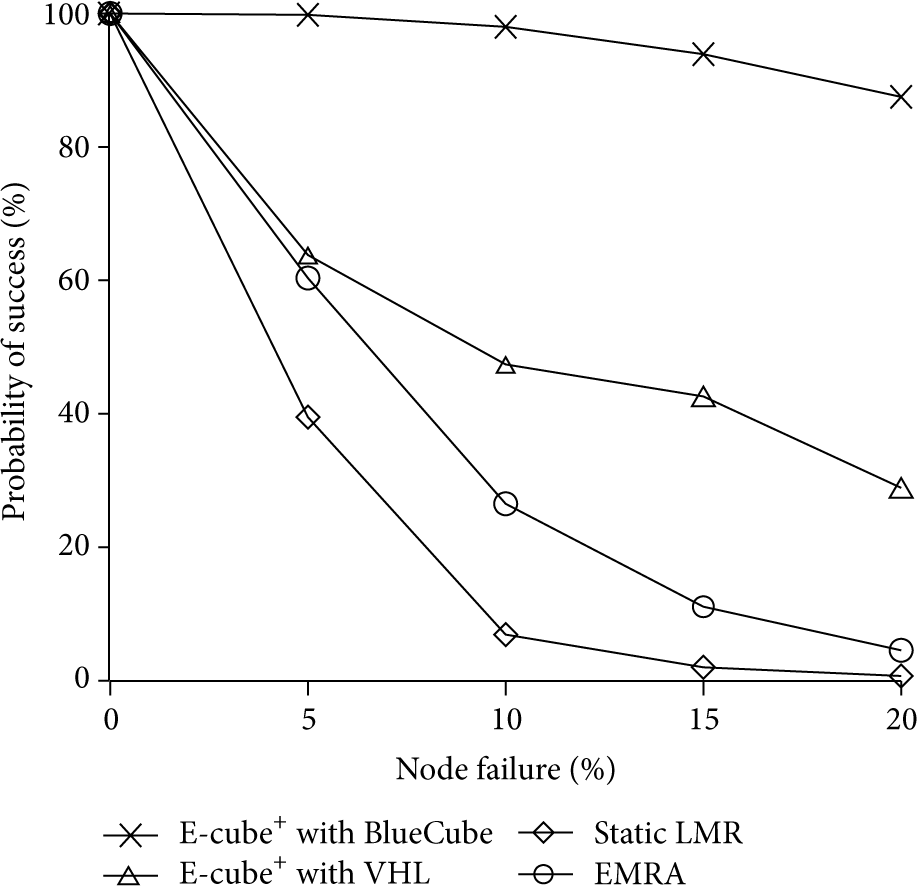
Probability of successful transmission versus percentage of node failures.
In E-cube+ with VHL, since the network topology is a grid, every node can connect to a maximum of four neighboring nodes, which is the same as that in the LMR. Due to routing method employed in E-cube+, every node has a backup route, like in a tree structure. Therefore, instead of just one backup path, multiple backup paths can be found. But in the LMR, only the source node has a single backup path. Thus, when any nodes in the main and backup paths fail, the data is not transmitted to the destination. As for EMRA, its probability of success is higher than LMR due to disjoint multiple path property.
Following the experiment with the longest pair of nodes, we tested the transmission success rate of node pairs with different Euclidean distances in a network with 10% failed nodes. In the 16 × 16 grid environment, the source node places in (0,0), and the 7 different sink locations (

Probability of successful transmission for varying distances.
When using the E-cube+ method, no routing table is required and simple calculations can provide routing decisions. In order to demonstrate that E-cube+ does not sacrifice transmission time for saving memory space, it can be seen in Figure 6 that the 7 different distances (
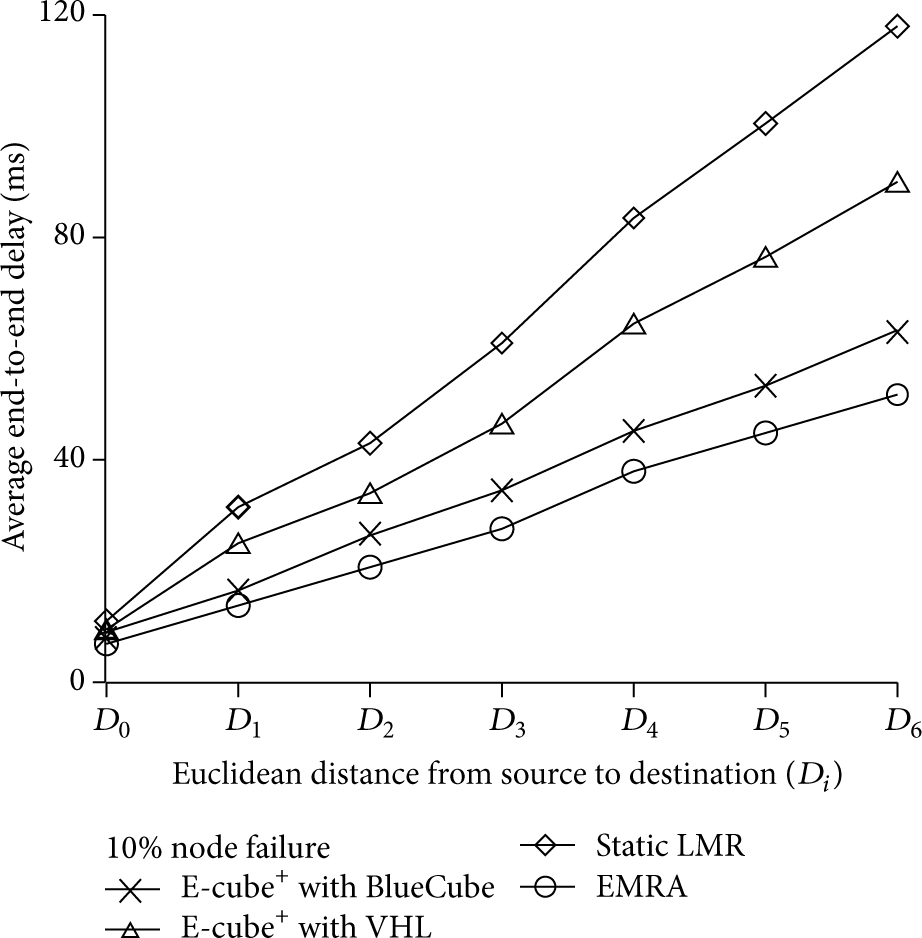
Average end-to-end delay for varying distances.
5. Conclusion
Due to the resource constraints and the existence of wireless features, wireless sensor networks are susceptible to relatively high fault rates. When certain nodes in a wireless sensor network fail, wireless network transmission will be interrupted, thus greatly lowering the reliability of the entire network. In this paper, we proposed a fault-tolerant tableless routing protocol termed E-cube+, to achieve a highly fault-tolerant protocol for a wireless sensor network. With these desired fault-tolerant salient features (including no routing table lookup, failure recovery guarantees, and bounded latency), E-cube+ is expected to become the fundamental support for wireless sensor networks.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.