
Abstract
Bilinear models have been successfully applied to separate two factors, for example, pose variances and different identities in face recognition problems. Asymmetric model is a type of bilinear model which models a system in the most concise way. But seldom there are works exploring the applications of asymmetric bilinear model on face recognition problem with illumination changes. In this work, we propose enhanced asymmetric model for illumination-robust face recognition. Instead of initializing the factor probabilities randomly, we initialize them with nearest neighbor method and optimize them for the test data. Above that, we update the factor model to be identified. We validate the proposed method on a designed data sample and extended Yale B dataset. The experiment results show that the enhanced asymmetric models give promising results and good recognition accuracies.
1. Introduction
Face recognition has been an active research area due to its applications in security entry systems and automatic law enforcement system. Pose variances, illumination changes, and noise from observations make it hard to define a model with promising recognition accuracies. Previous work [1–5] has proven that image variations of faces under varying illuminations could be modeled by linear spaces while view spaces which resulted from varying head poses are considered nonlinear [6]. Manifold learning [6, 7], bilinear models [8–10], linear dimensionality reduction [11, 12], and tensor analysis [13–15] have all been applied to solve face recognition problems. Recently deep learning techniques are also employed to solve face recognition problems and have achieved good performances [16–18].
Usually, faces need to be aligned before recognition. There has been lots of works which have been done on face alignment [19–30]. And it is well known that misalignment will result in recognition accuracy drop [20]. In our work, we explore the possibility of face recognition without alignment. In the proposed algorithm, we concentrate on separating factors that might affect recognition accuracy. To be specific, we use bilinear model to separate a varying factor from recognition target. And we prove in experiments that this separation is effective and required.
Bilinear models [8] are usually used to model systems with two factors and each factor itself is linear given the other factor fixed. Bilinear models for 2D image data have been widely used to solve face recognition problems due to their simplicity in formulation. In this category of solutions, factors introduced in a system are modeled as a symmetric bilinear model or asymmetric bilinear model. In this work, we also introduce asymmetric bilinear model due to its simplicity in representation.
Among all variance factors in face recognition problems, illumination change is one influential and intensively studied factor. Example works on illumination variations in face recognition problem include [9, 10], of which work in [10] is closely related to our work. Authors in [10] combine ridge regression into symmetric bilinear model to separate illumination and identity factor. Symmetric bilinear model decomposes input data into two factor matrices representing two factors and an interaction matrix denoting interactions between two factors. Instead of symmetric models, we utilize asymmetric models which decompose input data into a factor matrix and a matrix containing the other factor and interaction matrix. With fewer parameters to optimize, the asymmetric model does not suffer from convergence problem as in symmetric model. But, due to noise captured in image features, the original asymmetric model is not able to cope with illumination changes in real world face recognition problems.
In this work, we propose a modified asymmetric model for accurate face recognition. As in the original asymmetric bilinear model, we calculate probability predictions with Bayesian rules and expectation maximization method (EM). But instead of initializing the factor probabilities randomly, we initialize them with nearest neighbor method and optimize them for the test data. And we update the factor model to be identified. The enhanced asymmetric model is composed of three modules: calculating factor matrices from training data, initialization step for test data, and optimization and classification step for test data. In the first step, we use singular value decomposition to separate the factor to be identified from other factors based on training data. In the initialization step, a nearest neighbor method is introduced to initialize the joint probabilities of all factors which is further updated in optimization step. In the third step, we update the factor model to be identified. We validate the proposed method on a manually created data and cropped images from extended Yale B dataset. The experiment results show that the enhanced asymmetric models give promising results and good recognition accuracies.
The rest of this paper is organized as follows: in Section 2 we explain the proposed method in detail, including how to use Bayesian rules and EM method to optimize test factors and how to achieve illumination-robust face recognition and identity-robust illumination recognition goal with the proposed method; in Section 3, we validate the proposed method on two types of data: designed data and public available extended Yale B dataset; in Section 4, we will conclude our work and discuss possible future works.
2. Enhanced Asymmetric Bilinear Model
Bilinear models [8] separate the input data into two factors, described as style and content. Content is the factor to be identified; for example, identity and style are the factors that vary and need to be separated. Bilinear models reduce to the linear model when one factor is fixed. It contains symmetric and asymmetric models. Authors in [10] use symmetric model and take the identity as content and the illumination as style. In a symmetric bilinear model, style and content interact using an interaction matrix. But actually we are not interested in both style and content matrices in a single task classification problem. For simplicity, we choose an asymmetric model and modify it to accurately recognize factors.
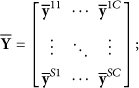
Suppose we represent content c with a vector of parameters



As in [8], we use singular value decomposition to fit asymmetric model to training data. First we stack

2.1. Optimizing Factor Matrix for Test Data
Given test data
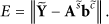
2.1.1. Bayesian Rules for Probability Predictions
We define the probability of a captured feature given a style and a content assignment


2.1.2. The Algorithm
To minimize the error between the test features and its approximation Initialize the matrix containing style factors Expectation step: calculate Maximization step: to maximize the total log-likelihood of the test data Update content matrix
2.1.3. Illumination-Robust Face Recognition and Identity-Robust Illumination Recognition
In this section, we explain the possible applications of the proposed method in face recognition problems. First, we define identity as content and illumination as style to show the application of linear models to illumination-robust face recognition problem; see Figure 1. Then we switch content and style and set the illumination as content and identity as style. It is widely acknowledged that the illumination changes could be modeled with linear space but it is not clear if the identity space is also the same case. We design the second experiment to show the application of the proposed method in identity-robust illumination recognition and to test the expansibility of the system. In the following section, we show experimental results of these two experiment settings.

In the illumination-robust identity recognition application, we show the split between the training and test data.
3. Experimental Results
We validate the proposed method with two categories of data: one is a manually defined sample data and another is a publicly available face recognition dataset. The aim of the designed sample data is to verify the soundness of the proposed method and the second category of experiments is to provide standard results.
3.1. Experiment on Designed Data
Suppose we have a tensor

With the proposed method, we get the experimental results in Table 1. The tables show recognition accuracies and approximation errors in each iteration. From the table, we can see that the proposed method can reach 100 percent recognition accuracy on the designed dataset.
Recognition accuracies and approximation errors of the enhanced asymmetric model on the designed data sample.

3.2. Experiment on Extended Yale B Dataset
The extended Yale Face Database B contains 16128 images of 28 human subjects under 9 poses and 64 illumination conditions and they provide a subset of cropped images. In our experiment we use the cropped images. With this dataset, we design two sets of experiments: illumination-robust face recognition and identity-robust illumination recognition.
In illumination-robust face recognition, we pick those illuminations with id ranging from
Recognition accuracies and approximation errors of the enhanced asymmetric model on illumination-robust face recognition experiment.

In identity-robust illumination recognition, we pick those persons with id ranging from
Recognition accuracies and approximation errors of the enhanced asymmetric model on identity-robust illumination recognition experiment.

We further show a set of experiments exploring the effect of training sample numbers. In illumination-robust identity recognition application, we pick the same test data as the previous experiment but we pick the illumination with identity ranging from

Experimental results of different training/test splits for illumination-robust identity recognition applications.
From the figure, we can see that, in the term of errors, the training sample numbers differences have an obvious effect in the first and the second iterations but tend to be subtle in the following iterations. In fact, with more training sample numbers, the optimization tends to be unstable. The best accuracy
The proposed algorithm is further compared with a nearest neighbor method to show the importance of separating style and content. We design the nearest neighbor method applied in identity recognition problem: first, varying numbers of training data are selected (i.e.,
Recognition accuracies of the nearest neighbor method on identity recognition experiment.

4. Conclusions and Future Works
In this paper, we present an enhanced asymmetric bilinear model and apply it to illumination-robust face recognition problem and identity-robust illumination recognition problems. By initializing the content and style probability with nearest neighbor method and adding update for content matrix, we achieve quite good recognition accuracies. In the future, it would be interesting to explore the application of the proposed method on models containing more than two factors. Also, we would like to explore applications of asymmetric models on applications other than face recognition.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
Authors acknowledge the support of the Fundamental Research Funds for the Central Universities 14CX02141A, start-up funds for introduced talent at China University of Petroleum 2014010583, and the Spanish Projects TIN2009-14501-C02-02 and TIN2012-39051.