
Abstract
With the rapid development of information technology and the coming of the era of big data, various data are constantly emerging and present the characteristics of autonomy and heterogeneity. How to optimize data quality and evaluate the effect has become a challenging problem. Firstly, a heterogeneous data integration model based on retrospective audit is proposed to locate the original data source and match the data. Secondly, in order to improve the integrated data quality, a retrospective audit model and associative audit rules are proposed to fix incomplete and incorrect data from multiple heterogeneous data sources. The heterogeneous data integration model based on retrospective audit is divided into four modules including original heterogeneous data, data structure, data processing, and data retrospective audit. At last, some assessment criteria such as redundancy, sparsity, and accuracy are defined to evaluate the effect of the optimized data quality. Experimental results show that the quality of the integrated data is significantly higher than the quality of the original data.
1. Introduction
With the rapid development of Internet technology and the advent of the era of big data, global enterprise information doubled every 1.5 years on average, and at present only 7% of the total information data has been utilized [1]. How to effectively integrate distributed, heterogeneous, and self-knowledge data, so as to realize data sharing, is a somewhat challenging research topic. Enterprises get valuable information through analyzing these data effectively, and data of high quality can help users make the right decision. There are many factors that can affect the quality of data. Among these factors, those related to original data include error in data format, data inconsistency, and nonconformity with the business logic.
At present, one of the approaches to heterogeneous data integration is through data warehouse model. Data warehouse model extracts data from one or more data sources, processes the data when necessary, and then stores the data in the target data warehouse. This model supports complex data conversion and has better performance. Data storage model generally adopts the forms of ETL (Extract, Transform, and Load) and data warehouse. ETL process includes data extracting, data transformation, and data loading. In this process, data from distributed and heterogeneous sources are extracted to the temporary middle layer and then cleaned, converted, integrated, and finally loaded into the data warehouse or data mart.
Some data integration methods are proposed to improve the traditional data integration, such as the method based on Xml middle-ware [2], that based on the conjoint method [3], and that using ontology [4]. As for real-time data integration, [5] proposes reducing the integration time by using component for data warehouse, and [6, 7] advocate using ODS technique for dynamic data loading process. Some data integration methods such as data dimension [8] and the market integration of the semi-structured data integration [9] were proposed to optimize the data integration quality. Pellegrino [10] for interactive visualization of data integration system has carried on the detailed research. Many researchers try to optimize the data quality in data integration from different perspectives [11–16].
However, the existing heterogeneous data integration process has the following disadvantages. Firstly, the traditional heterogeneous data integration technology is based on the process of ETL data extraction, integration, cleaning, and loading. It cannot update data in real-time because it needs to set a time interval value to specify how often to update regular periodic data passively. Secondly, traditional ETL process will not reverse changes on the original data. It is only for the use of the original data, not the quality assurance and quality improvement on the original data, and lacks maintenance process of the original data.
In this paper, we propose a multisource retrospective audit method for data quality optimization and evaluation. At first, a real-time multisource heterogeneous data integration model is established to improve the quality of the original data by employing the technologies of adapter, XML, and reverse cleaning. Secondly, in order to improve the quality of integrated data, a retrospective audit model and relevant audit rules are proposed to fix incomplete and incorrect data from multiple heterogeneous data sources. The heterogeneous data integration model based on retrospective audit is divided into four modules which includes original heterogeneous data, data structure, data processing, and data retrospective audit. Finally, some assessment criteria, such as redundancy, sparsity, and accuracy, are defined to evaluate the effect of the optimized data quality.
The remainder of the paper is organized as follows. In Section 2, we introduce the heterogeneous data integration model based on traceable audit. In Section 3, optimization process of traceable audit is described in detail. In Section 4, some assessment criteria, such as redundancy, sparsity, and accuracy, are defined to evaluate the effect of the optimized data quality. In Section 5, we present the experiment process, experiment results, and analysis. At last, we conclude the paper in Section 6.
2. Heterogeneous Data Integration Model Based on Traceable Audit
2.1. Data Lineage
In the view of the database update, there is a similar process called data lineage. In recent years, with the development of the network, data lineage has become a new field of research. Through data lineage tracing we can get the information about the source of data view. When the original data in the database are changed, the view of database can be updated through tracing the lineage of the data. Data lineage has attracted the attention of scholars in fields of Web Search and Mass Storage in recent years.
Reverse cleaning process is composed of building process and query process. For example, Table A is composed of Table B and Table C, and Table B is composed of Table D and Table E. We can use node to describe a table and use edge to describe the relationship between tables. Then, data bus can be generated according to the data lineage of A. We can record accurate data source according to the data flow process in constructing local dataset which need to be repaired.
The process of traceable audit optimization is in nature the process to find the sources of data and then match and modify the data in the process. We can follow a data convergence process to fix data in the integration of local raw data tables or files. For example, when we modify the first row in Table A, according to the reverse trace convergence process, we can analyze the source of Table A: A→(B, C)→[(D, E), C]. Then we will quickly find out the result like this: “First line of the Table A is actually recorded by row 1 of Table F, the row 5 of Table G, the row 3 of Table E, and the row 1 of Table C.” The reverse traceability process is shown on the right side in Figure 1.
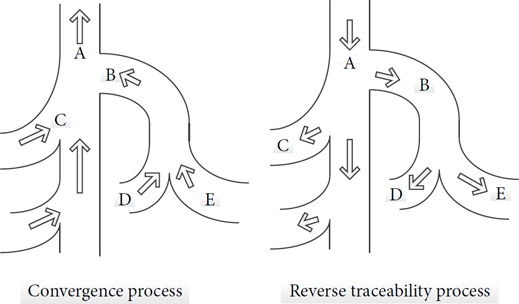
Data bus and reverse traceability.
2.2. Traceable Audit
Traceable audit means that the data audited can be traced. When heterogeneous data are integrated, the source of data will be marked. After the data have been treated according to different audit rules, the repair history can be recorded in detail. If the set of data to be repaired corresponds to several sources, after it is repaired, we can trace the record to know the data source according to which the repair is operated. Heterogeneous data sources are also the audit reference to repair the local data. It comes from the outside of the local data collection of the dataset with uncertain structure.
2.3. Integrating Heterogeneous Data Structures
The heterogeneous data integration model based on traceable audit is divided into original heterogeneous data, data structure, data processing, and data feedback audit, as follows.
Original data module: the module stored heterogeneous data from different data sources, such as structured MySQL, Oracle database, Html, Xml, semistructured and unstructured text, and Excel. Data structured module: its function lies in the different sources of heterogeneous data sources into a unified structured data structure, at the same time, according to the data source tree and relevant rules, define the data structure of the need of repair, convenient for later data processing. Data processing module consists of two parts, real-time data integration process and data restoration process. It means to integrate multiple heterogeneous data sources and to extract, integrate, clean, and preserve the original data. Data feedback audit module, which is divided into data feedback and the audit process, is mainly used to query the data source and the local corrects errors in the original data, in the case of confirmed raw data that needs to be fixed to update the original data.
Its structure is as in Figure 2.
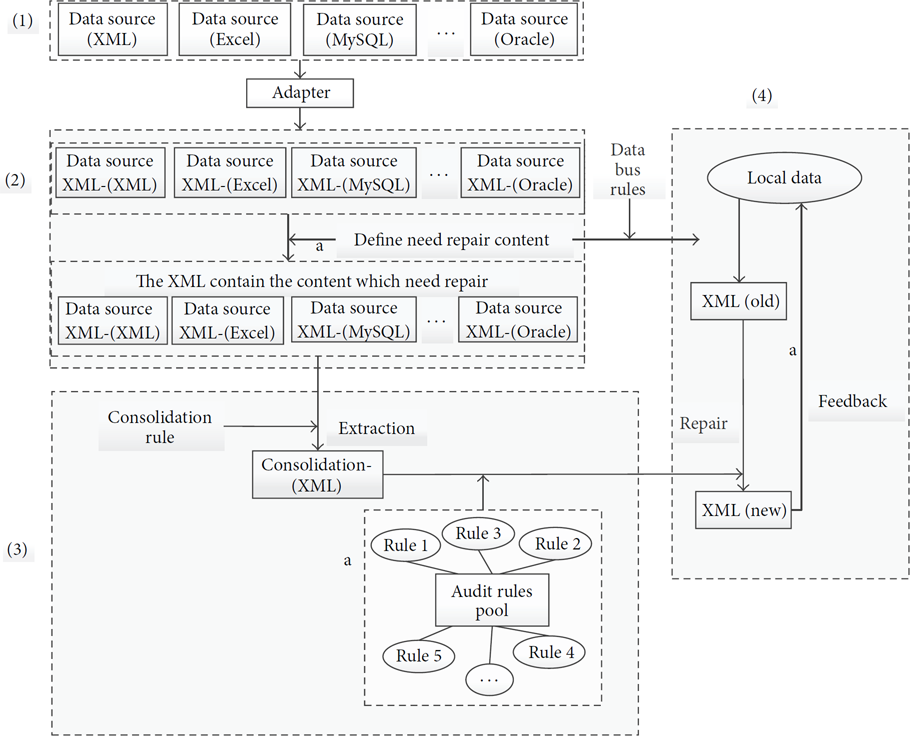
Structure of heterogeneous data integration.
3. Optimization Process of Traceable Audit
3.1. Data Traceable Audit Process
Traceable audit aims to repair the original data, in order to solve the distributed data sharing of credibility, quality, and the problem such as version information. The reverse feedback audit can clearly reflect the change of the original data in the database. It is helpful to solve the problem of updating wrong data in the process of heterogeneous data integration.
Feedback audit in this paper refers to the repair of database according to multiple heterogeneous data sources on the Internet, that is, to correct the local incomplete and incorrect data according to the high quality dataset integrated on the basis of certain rules. Figure 3 illustrates the feedback audit process in the form of a flowchart.
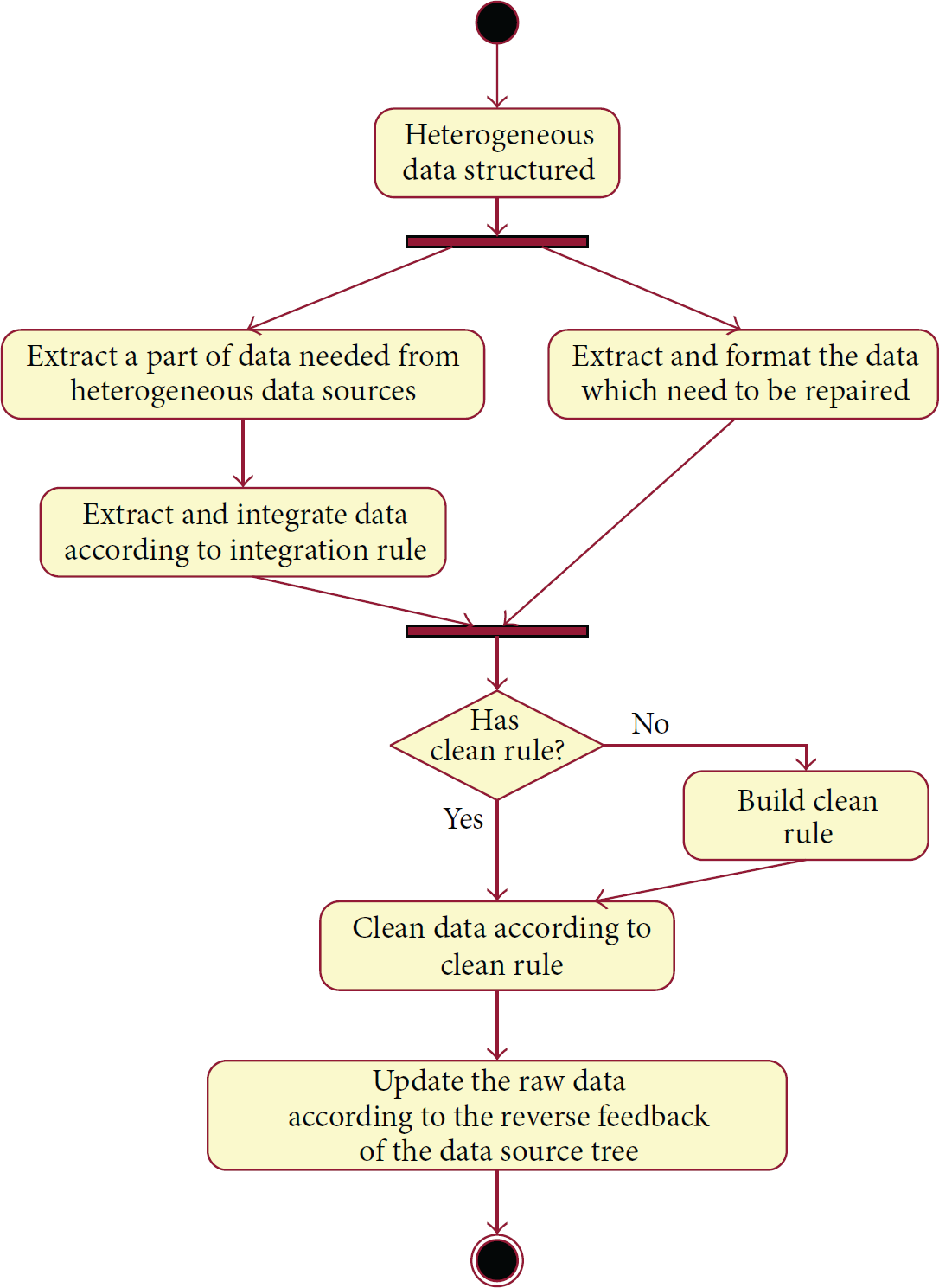
Data flow optimization traceability audit.
3.2. Integration Rules
In the feedback audit process, data integration rules affect the reverse audit quality immensely. Integration rules include defining the contents to be repaired, integration of heterogeneous data sources, and integration of local original data.
(1) Defining the Contents to Be Repaired. Defining the contents to be repaired means to identify the items to be repaired in original data. For example, if we are to repair data about business information such as address, and telephone number, we need to define the contents to be repaired beforehand so that we can extract relevant data from different data sources, hence reducing the computational complexity of the algorithm.
( 2) Integration of Local Original Data. Local raw data integration means extracting the local data according to the rules and then forming a structured data, which can be used for necessary feedback audit.
Algorithms extract the corresponding dataset from different database tables which need to be repaired according to the definition of repair content. At the same time, the source of each datum is recorded according to the data bus rules to ensure the trace of original data after retrospective repair. When data are extracted, they are structured at the same time.
( 3) Heterogeneous Data Integration. Heterogeneous data integration extracts the data integration in various forms except local data source data storage, including XML, MySQL, and TXT. It includes content extraction of heterogeneous data integration and merging rules.
Content Selection Rules. On the basis of repair contents defined, corresponding contents are extracted from different data sources and structured in a uniform XML storage. In MySQL, Oracle, Txt, Excel, and other storage structures, the algorithm, according to the definition of the repair content, conducts extraction of data from various sources. For example, if the material to be repaired is about basic information of students, the adapter, according to the definition, finds the corresponding record, field, property, and so forth, to extract data from multiple data sources, namely, to extract the basic information data from multiple data sources.
Merging Rules. Data from various sources were extracted, structured, and then merged into a dataset. On the basis of the extraction, the algorithm merges the structured XML documents such as Oracle-XML, MySQL-XML, Txt-XML, Excel-XML according to certain rules, such as labeling the source coupled with a time stamp.
3.3. Auditing Rules
3.3.1. Auditing Rules
In the heterogeneous data integration model, a pool of audit rules is built to store a series of auditing rules, such as the redundancy, sparsity, and accuracy rules defined in this paper.
( 1) Redundancy Auditing Rules. Data redundancy refers to the number of occurrences of the same record. The audit of redundancy means to delete the repeated ones in original data by certain algorithm. The main steps are as follows.
Step 1. Calculate the redundancy of dataset, and mark the same record in the dataset.
Step 2. Delete and back up the data according to the mark of repetition.
( 2) Sparsity Auditing Rules. Sparsity refers to the percentage of vacant fields in a dataset record. Sparsity audit aims to reduce the sparsity of data so as to avoid the waste of physical space. The main steps are as follows.
Step 1. Calculate rate of empty fields of a dataset that tag is empty field.
Step 2. Match and fill the empty fields according the integrated data.
( 3) Accuracy Auditing Rules. Accuracy means the difference between the local data and real data. The smaller the difference is, the higher the accuracy is. The main steps are as follows.
Step 1. Use consolidated results to repair the local data, and then generate the repaired data.
Step 2. Analyze data accuracy by matching the original data with the repaired data and the data after manual revision.
3.3.2. Active Learning Principles
The audit rules in the pool will follow certain principles of active learning, such priority of time, priority of amount, priority of history, and priority of artificial rectification.
Priority of time means that, in multiple data sources integration model, those updated most recently will be used as the standard in repairing the local data. Priority of amount means that, in the data model of multiple data sources integration, the great majority will be taken as the criterion; that is, as regards the same data, when the majority of the data source reveals the same value, the local data will be revised accordingly. Priority of history means that we determine which data source to be relatively accurate by reading historical records of repair and then take it as the ground for future repair. Artificial rectification refers to the human participation in the process.
4. Data Quality Assessment
4.1. Related Definitions
As far as the performance of the feedback audit process is concerned, relevant definitions for quantitative analysis are as follows.
Definition 1.
Record
Definition 2.
Record set
Definition 3.
Record-attribute matrix

Herein,
4.2. Performance Parameters
Local data are repaired through feedback audit and then compared with the actual data which have been repaired and verified manually. The following parameters of performance are generated: redundancy, sparsity, and accuracy.
4.2.1. Redundancy
The indicator of redundancy in this paper is worked out on the basis of the similarity between records in their attribute value, among which those that record the value of the attribute field are categorized into numeric type and character type (English characters, Chinese characters). The core theoretical foundation is the similarity between Chinese phrasal texts, which measures the similarity between Chinese record attribute values. According to Chinese phrase text similarity calculation method, we define the similarity of Chinese text phrases A and B as
We define records similarity between

On condition that the similarity is worked out, the repetition rate between

Also the repetition rate of record
Then the redundancy of record is

4.2.2. Sparsity
Sparsity of single record:
Sparsity of record set:

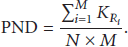
4.2.3. Accuracy
Accuracy of data refers to the similarity between corresponding fields achieved by comparing the data before and after repairing with the artificially revised data. According to phrase text similarity and matrix multiplication algorithm, set

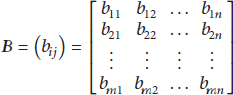
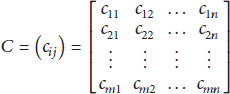
And define S as the accuracy of a collection of records before and after repair. And the similarity of matrix value is used as a reference. It means that the higher the similarity, the higher the accuracy. The matrix similarity formula is as follows:

Herein,
According to Definition 3, let the data matrix before restoration be
Then, accuracy of the data before restoration is
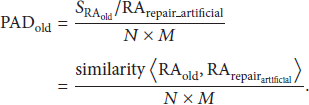
Accuracy of the data after restoration is

5. Case Studies
5.1. Experimental Environment
This experiment uses a medium-sized local life service dataset (http://www.dongway.com.cn) and several other datasets in the same field to test the algorithm. The local data collection is mainly information from catering industry, such as businesses, cuisines, and customer behaviors. The number of businesses is more than 28000 and that of users nearly 15000. These datasets are representative and have a certain influence on the industry.
The experiment selects a medium-sized subset from these datasets, which mainly contains the basic information of the merchants, such as business name, phone number, address, latitude and longitude, and the main business projects and other information.
5.2. Experiment Process
The experiment collects data from other sites and takes these heterogeneous data sources as a basis for the repair of local dataset. The experiment process is as follows.
Step 1. Select and format local dataset which needs to be fixed according to the data bus rules.
Step 2. Gather from multiple data sources on the Internet the same data objects with the local data according to integration rules.
Step 3. Integrate and format the dataset gathered in Step 2.
Step 4. Repair the local data according to auditing rules with the important repair parameters of dataset being redundancy, sparsity, and accuracy. Redundancy and sparsity concern a comparison between data before and after the repair, and accuracy applies in comparison between data before and after repair and artificially restored data.
5.3. Experimental Findings and Analysis
5.3.1. Redundancy Analysis
The experiment compared the value of redundancy records between the original data and the repaired data; the redundant records of raw data are as in Table 1.
Redundancy records of raw data.
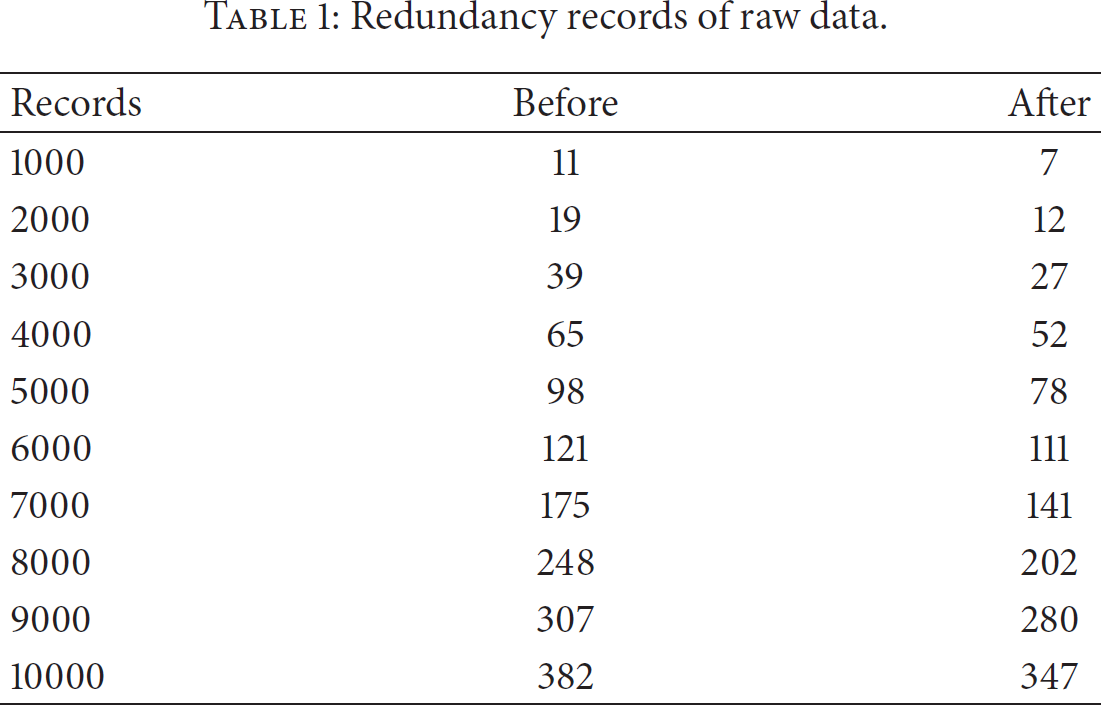
On the basis of the definitions of redundancy parameter in previous section, redundancy trend is as in Figure 4.

Redundancy PRD trend.
In Figure 4, PRD_b represents the redundancy of the dataset before repair and PRD_a represents the redundancy of the dataset after repair. It can be seen from the figure that the redundancy of the dataset becomes higher when the number of records is increasing. This trend indicates that the data quality is optimized significantly and the redundancy of the dataset reduces after repair audit.
5.3.2. Sparsity Analysis
Data sparsity describes the phenomenon of no enough useful data in dataset; it is a problem of estimating a sparse multidimensional vector. In our experiment, data sparsity is calculated by transformed matrix; we counted the number of elements 0 in the matrix to measure the dataset sparsity. Experiment results in sparsity trend as in Figure 5.

Sparsity PND trend.
In Figure 5, PND_b represents the sparsity of original data, PND_a3 is the sparsity of dataset repaired in the condition of 3 heterogeneous data sources, and PND_a5 has 5 heterogeneous data sources. Experiment results show that the data sparsity significantly decreased after repairing with the audit algorithm. On the other hand, the data sparsity gradually reduces when the heterogeneous data sources are increased.
5.3.3. Accuracy Analysis
Comparing data manually revised with those before and after algorithms audit, experiment results in accuracy trend as in Figure 6.
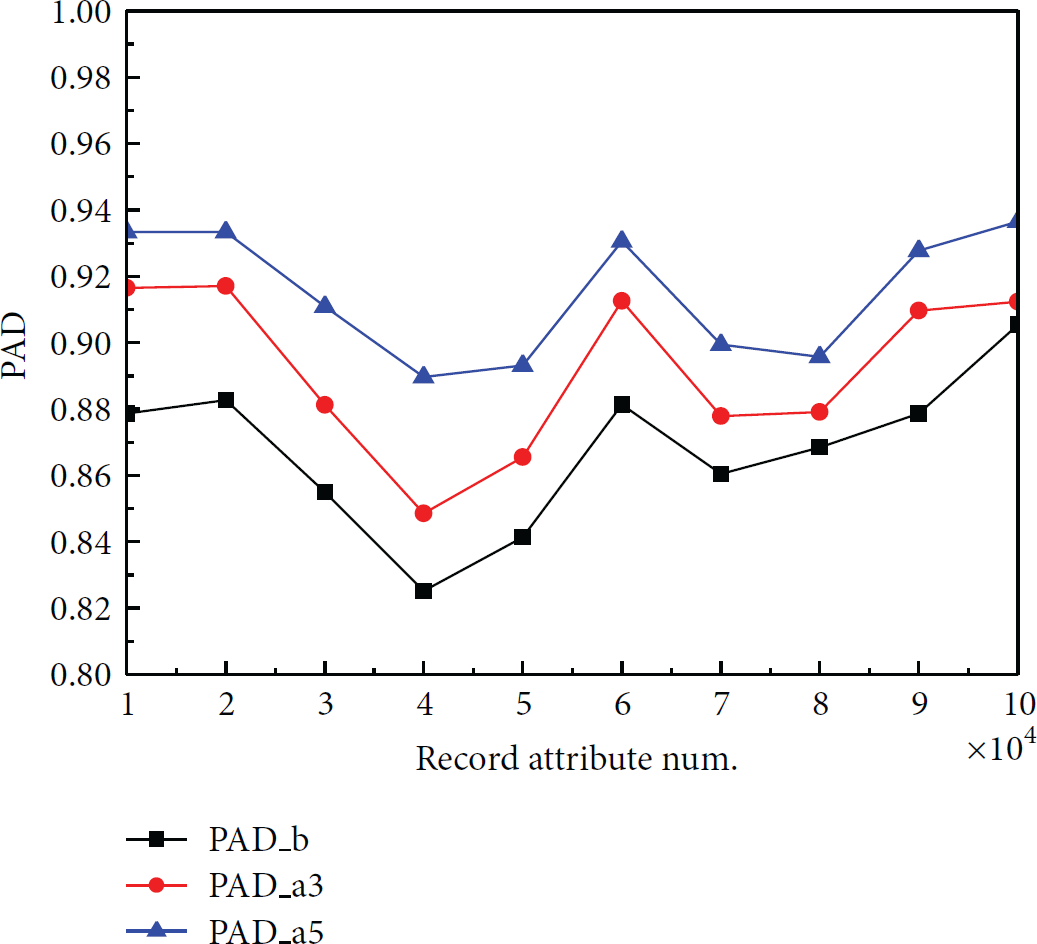
Accuracy PAD trend.
In Figure 6, PAD_b represents the accuracy of original data, PAD_a3 is the accuracy of dataset repaired in the condition of 3 heterogeneous data sources, and PAD_a5 has 5 heterogeneous data sources. Experiment results show that the data accuracy is significantly optimized after repairing by the audit algorithm. On the other hand, the data accuracy gradually increases when the heterogeneous data sources are increased.
6. Conclusions
How to optimize data quality and evaluate the effect is a challenging problem. In this paper, we proposed a multisource retrospective audit method for data quality optimization and evaluation. At first, in order to locate the original data source and match the data, we propose a heterogeneous data integration model based on retrospective audit. Secondly, a retrospective audit model and associative audit rules are proposed to improve the integrated data quality from multiple heterogeneous data sources. The heterogeneous data integration model based on retrospective audit is divided into original heterogeneous data, data structure, data processing, and data retrospective audit. At last, we define some assessment criteria such as redundancy, sparsity, and accuracy to evaluate the effect of the optimized data quality. Experimental results show that the model works well and the quality of the integrated data significantly improved. In future, our work can be extended in potential ways of data quality optimization and evaluation; further research needs to be done on the general framework for studying optimization methods for parameters in heterogeneous data integration model based on traceable audit.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This paper is partly supported by the National Science Foundation of China (Grant nos. 61472132, 61370226, 61472131, and 61300218).