
Abstract
We newly propose a query-by-singing/humming (QbSH) system considering both the preclassification and multiple classifier-based method by combining linear scaling (LS) and quantized dynamic time warping (QDTW) algorithm in order to enhance both the matching accuracy and processing speed. This is appropriate for the QbSH of high speed in the huge distributed server environment. This research is novel in the following three ways. First, the processing speed of the QDTW is generally much slower than the LS method. So, we perform the QDTW matching only in case that the matching distance by LS algorithm is smaller than predetermined threshold, by which the entire processing time is reduced while the matching accuracy is maintained. Second, we use the different measurement method of matching distance in LS algorithm by considering the characteristics of reference database. Third, we combine the calculated distances of LS and QDTW algorithms based on score level fusion in order to enhance the matching accuracy. The experimental results with the 2009 MIR-QbSH corpus and the AFA MIDI 100 databases showed that the proposed method reduced the total searching time of reference data while obtaining the higher accuracy compared to the QDTW.
1. Introduction
With the widespread music content and music databases on the Internet, portable media, and smart phone, fast and accurate content-based searching systems are required. Query-by-singing/humming (QbSH) is a representatively convenient and intelligent method in the field of content-based music retrieval systems. It matches the reference music file corresponding humming queries of a user. It can be used for retrieving a music file without singer's name and song title based on the melody of the music hummed/sung by a user.
In previous researches, the various kinds of QbSH systems have been researched [1–22]. Ghias et al. proposed the method of representing the pitch contour features extracted from the humming or whistle data as an up-down-repeat (UDR) string and using them for matching [2]. McNab et al. proposed the MELDEX system based on the pitch contour, interval, and duration with string matcher [3, 4]. In previous research [5], they proposed the Tuneserver representing the pitch contour as the UDR string like the method of [2]. Kornstadt et al. developed the Themefinder system which has the capability of searching the theme of music in the Humdrum database of classic music of the 16th century and folk songs on the web [6, 7]. In previous research [8], they showed the retrieval method using the changes of melody and the UDR string. Ryynänen and Klapuri proposed the method of extracting the pitch vectors by using a fixed-size time window and matching them by using locality sensitive hashing (LSH) method [9]. In another study [10], they adopted earth mover's distance (EMD) method which could calculate the minimum cost between the features of humming and reference data with the changes of the weight to measure melodic similarity. In the previous research [11], they proposed the method of content-based music retrieval which firstly filters out 80% unlikely candidates by using hierarchical filtering method and compares the input query with the remaining candidates. Salamon and Rohrmeier proposed the two-stage retrieval method for QbSH system [12]. As the first stage, the number of candidates is reduced by the indexing method using n-grams. And detail matching with the remaining candidates is performed with the remaining candidates based on local alignment with modified cost functions. Wang et al. proposed the QbSH system by combining the EMD and dynamic time warping (DTW) classifiers based on the weighted SUM rule [13].
The previous QbSH systems can be roughly categorized into top-down and bottom-up matching systems. As the top-down one, Wu et al. proposed recursive alignment algorithm which firstly compares two-feature data in global view and does them locally [14]. Other methods of [11, 12] belong to this category. On the contrary, bottom-up method locally calculates the distance between query and reference data in each position and searches the optimal path for obtaining a final matching score [2–4, 6–8, 15, 16].
For the QbSH system, DTW algorithm has been widely used for matcher. It has been widely used in speech recognition and can easily solve the time alignment problem. Since there generally has been much misalignment of time between the input humming/singing and the reference music file, the DTW algorithm is suitable for QbSH systems, but it has the limitation of high cost in computation. Jang and Gao converted the input query data into pitch vectors [15]. Using this method, they measured the similarity between singing/humming and reference songs based on the calculated distance by DTW with high accuracy; however, this method is also computationally demanding [23, 24]. Krishnamoorthy et al. also used DTW as distance measurement for the QbSH system on embedded platforms [19]. However, it still has the problem of high computation of the DTW method and lower matching accuracy by using single classifier. Li et al. proposed multistage matching-based system to enhance the performance of QbSH system [20]. It includes three stages. First and second stages aim to reduce the number of candidates in large amount of database by using earth mover's distance (EMD) based on tune and profile features, respectively. Finally, DTW calculates the matching distance with remaining candidate data. However, the final matching only by the single classifier of the DTW has the limitation of lower accuracy. The linear scaling (LS) method has the advantage of fast processing time, but its accuracy is relatively lower than the DTW method [16].
All of these previous researches are ones only by single classifier-based or by multiple classifier-based or by preclassification-based method. They do not adopt the scheme of considering both the preclassification and multiple classifier-based methods. To overcome the problems of the previous researches, we newly propose a QbSH system considering both the preclassification and multiple classifier-based method by combining LS and quantized DTW (QDTW) algorithm in order to enhance both the matching accuracy and the processing speed. The processing speed of the QDTW is generally much slower than the LS method, although QDTW is the modified version of DTW to enhance the matching accuracy and reduce the processing time. So, we perform the QDTW matching only in case that the matching distance by LS algorithm is smaller than predetermined threshold, by which the entire processing time is reduced by higher than 30% compared to that of QDTW method while the matching accuracy is maintained. We use the different measurement method of matching distance in LS algorithm by considering the characteristics of reference database. In addition, we combine the calculated distances of LS and QDTW algorithms based on score level fusion in order to enhance the matching accuracy. Table 1 shows the summarized comparisons of the proposed and previous methods.
Summarized comparisons of the proposed method to previous ones.

The rest of this paper is structured as follows. Section 2 explains the proposed QbSH system. Section 3 discusses the experimental results, and Section 4 states the conclusions of this study.
2. Proposed Method
2.1. Overview of the Proposed Method
Figure 1 shows a flowchart of the proposed method. First, pitch data are extracted from the user's input humming file by using musical note estimation method. Second, we perform the following normalization. We remove pitch values of 0 in the extracted pitch data, since these can be regarded as the meaningless data which are obtained from the silence period of melody.

Flowchart of the proposed method.
In general, the melody of the input humming/singing is relatively inaccurate compared to the reference musical instrument digital interface (MIDI) data because it is hummed or sung by an amateur. So, the pitch data of the input is quite different from the MIDI file which requires the further normalization of the pitch data in both input and MIDI files as follows. After eliminating the 0 values, the input humming data are normalized through mean shifting, average filtering, and min-max scaling [16, 17, 21]. Median and average filtering get rid of the peaked and vibrated noises, and min-max scaling adjusts the amplitude variations.
With the normalized pitch data, preclassification is performed based on the calculated distance by LS algorithm in order to decide whether the QDTW algorithm should be executed. In detail, it calculates the matching distance between the input query data and the reference MIDI data in the matching window. If the matching distance is greater than a specific threshold, the QDTW algorithm does not run because the humming and MIDI data are different. Then, the matching window of the MIDI data is moved to the next matching position, and the preclassification procedure is repeated. If the matching distance is less than the threshold, the QDTW is executed in order to obtain more accurate matching score. These procedures are iterated until the matching window reaches the last part of MIDI data. If arriving at the last part of MIDI data, the final matching distance between the input humming/singing and the MIDI file is determined by combining the matching distance of QDTW and that of LS algorithm based on score level fusion. The correct MIDI file is selected based on the final matching distance.
2.2. Pitch Extraction and Normalization
In order to extract the pitch data, we used a voice-activity detection (VAD) algorithm [16, 17, 21]. First, the VAD algorithm estimates the voiced frames, and then pitch data as integer value is extracted by the spectrotemporal autocorrelation (STA) method which is based on temporal and spectral autocorrelations with the sampling of every 32 ms.
However, a lot of noises are generally contained in the extracted pitch data. In addition, muted regions exist and the pitch data of input are quite different from the MIDI file since users cannot hum/sing perfectly like MIDI music. So, the extracted pitch data should be normalized to obtain an accurate matching result. In this research, we perform the procedures of removal of 0 values, mean shifting, median filtering, average filtering, and min-max scaling for normalization.
2.3. Preclassification by LS Algorithm
2.3.1. LS Method
The LS algorithm has been widely used in QbSH systems, since its processing complexity is very low [16]. It calculates the matching distance between input query data and reference MIDI data by changing linearly the length of input or reference data on time axis. In this research, we change the length of the reference MIDI data. Figure 2 shows the example of the LS algorithm.

Example of the operation of the LS algorithm.
2.3.2. Measuring Method of Matching Distance
In general, the characteristics of MIDI data are different according to the kind of reference databases. Although the 2009 MIR-QbSH corpus mostly consists of children's song and folk song, the AFA MIDI 100 database includes more various kinds of songs. So, the melodies of the 2009 MIR-QbSH corpus database are usually simpler than those of the AFA MIDI 100 database. In addition, more noises are included in the AFA MIDI 100 database. So, we use the different measurement method of matching distance in LS algorithm by considering the characteristics of reference database.
In general, the Euclidean distance is used to measure the dissimilarity between input query data and reference MIDI data in LS algorithm as shown in 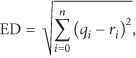

In (2), we define the (

Figure 3 shows the relationship between absolute difference (

2.4. Matching by QDTW
As shown in Figure 1, if the matching distance by LS algorithm is less than predetermined threshold, QDTW is executed to calculate a more accurate matching distance. In general, a difference in length exists between the MIDI and humming phrase. This problem of time alignment can be overcome by the DTW algorithm which can calculate the dissimilarity between the two patterns with insertion and deletion [16, 17, 21]. At each matching position of DTW, the dissimilarity between the humming and MIDI features is calculated by Euclidean distance. In this research, we adopted QDTW which has the only difference (from the DTW) that it uses the quantized pitch value instead of the original one. Since the original pitch value has variations caused by noise, they are represented as quantized integer values in QDTW.
Before matching by QDTW, we detect the zero to nonzero position (the position where the pitch value is changed from zero to nonzero) of the MIDI data and match the starting position of the humming data with each zero to nonzero position of the MIDI data. If the time interval between two-zero to nonzero positions is less than the threshold, only the first zero to nonzero position is used for matching, through which we can reduce the processing time and enhance the matching accuracy.
2.5. Score Level Fusion of Matching Distances
Score level fusion method has been used widely to enhance the matching accuracy, and there are a lot of methods into score level fusion. In this paper, we combined the two matching distances by the LS and QDTW methods based on simple fusion methods such as MIN, MAX, PRODUCT, and SUM rules and compared the performances of each fusion method. The MIN and MAX rules select the smaller and greater one among two matching distances as final matching score, respectively. The PRODUCT and SUM rule calculate the final matching score by multiplying and summing the two matching distances, respectively. Experimental results showed that the MIN rule showed the best performance among all methods.
3. Experimental Results
For experiments, we used two databases. The first database was the 2009 MIR-QbSH corpus which consists of 48 reference MIDI files and 4431 singing and humming queries as wav files [22]. A total of 118 persons sing or hum 8 s per each query in various environments such as telephones and microphones. Since the 2009 MIR-QbSH corpus database provides pitch vector (PV) files which included manually extracted pitch data, we used the PV files for the experiments to exclude the pitch extraction error.
The second database was the audio feature analysis (AFA) MIDI 100 database, which includes 1,000 singing and humming files recorded by microphone, and 100 MIDI files which are made up of 84 Korean songs, 6 children's songs, and 10 pop songs. The average time length of the input singing/humming files is 12 s. We performed our experiments on a desktop computer with a 3.4 GHz CPU and 8 GB RAM. To measure the matching accuracy, the mean reciprocal rank (MRR) is used as the criterion of performance, and it has been frequently used for measuring the accuracy of QbSH system [12, 16, 17, 21]: 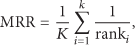
As the 1st experiment, we measured the matching accuracy of the LS algorithm according to various distance measurement methods of (3) and (4), as shown in Tables 2 and 3. The result showed that the case which uses log or arctan function shows better accuracy than other cases when using the AFA MIDI 100 database which has a lot of noises. However, the abs function shows the best matching accuracy when using the 2009 MIR-QbSH corpus database which has fewer noises. From that, we can confirm that the linear function for distance measurement can show better performance with the database of less noise while the nonlinear function can have better accuracy with the database of larger noises.


As the 2nd experiment, we measured the matching accuracy and processing time when using the LS algorithm as preclassification method before performing the QDTW algorithm. Based on Tables 2 and 3, the square function based distance measurement method for LS algorithm was excluded because it had the lower matching accuracy. As shown in Tables 4 and 5, the processing time was much reduced by the proposed method compared to the QDTW method although the MRR by the proposed method is the same to that of the QDTW.
The performance of the methods which combine LS and QDTW algorithm with PV files of 2009 MIR-QbSH corpus database.

The performance of the methods which combine LS and QDTW algorithm with AFA MIDI 100 database.

As the 3rd experiment, we compared the processing time and MRR of the original QDTW and the proposed method according to the threshold for preclassification by the LS method. If the matching distance by the LS method is greater than the threshold, the QDTW-based matching is not performed and matching window is moved to the next position for matching. If not, the QDTW-based matching is performed. If the threshold increases, the number of cases (that the matching distance by the LS method is less than the threshold) increases. Consequently, the number of cases of performing the QDTW-based matching is also increased, which enhances the MRR but increases the processing time. As shown in Figures 4 and 5, we can confirm that processing time by the proposed method is much reduced compared to that of QDTW while maintaining the MRR. By comparing Figures 4(a), 4(b), and 4(c), we can confirm that the proposed method using the preclassification based on abs function of (4) shows the better performance. In addition, we can also confirm that the proposed method using the preclassification based on arctan function of (4) shows the better performance by comparing Figures 5(a), 5(b), and 5(c).


The predetermined threshold for LS method was experimentally determined considering the minimum processing time with the maintained MRR (matching accuracy) of our method. That is, as shown in Figures 4(a)~4(c) and 5(a)~5(c), the predetermined thresholds are 3.2, 1.3, 1.5, 3.9, 1.5, and 1.5, respectively. The positions of the thresholds mean that the minimum processing time is taken while the MRR of our method does not degrade. As shown in Figures 4 and 5, the thresholds are different from the dataset and the measurement methods of matching distance (equation (4)) in LS algorithm.
The above results of Tables 4 and 5 and Figures 4 and 5 are the cases that two matching distances by the LS and QDTW are not combined. As the last experiment, we compared the performances when combining the matching distances by LS and QDTW algorithm. Since the matching distance by the LS algorithm was already calculated for preclassification and the processing time of score fusion such as MIN, MAX, PRODUCT, and SUM rule is almost 0 ms, the final processing time by combining two matching distances is not increased.
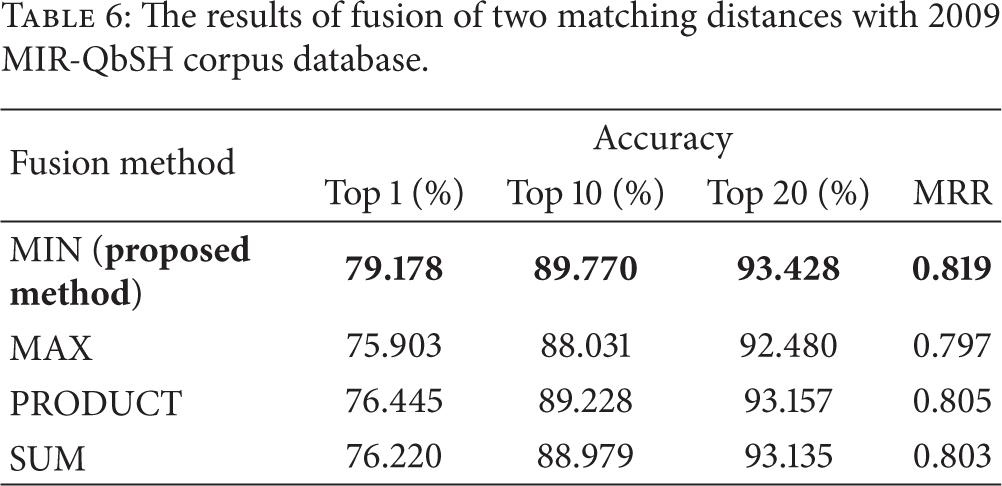
Tables 6 and 7 show the results of fusion of two matching distances. Based on the above results of Tables 4 and 5, the abs function-based LS algorithm was used for 2009 MIR-QbSH corpus database, and the arctan function-based LS algorithm was used for AFA MIDI 100 database.
The results of fusion of two matching distances with 2009 MIR-QbSH corpus database.
The results of fusion of two matching distances with AFA MIDI 100 database.
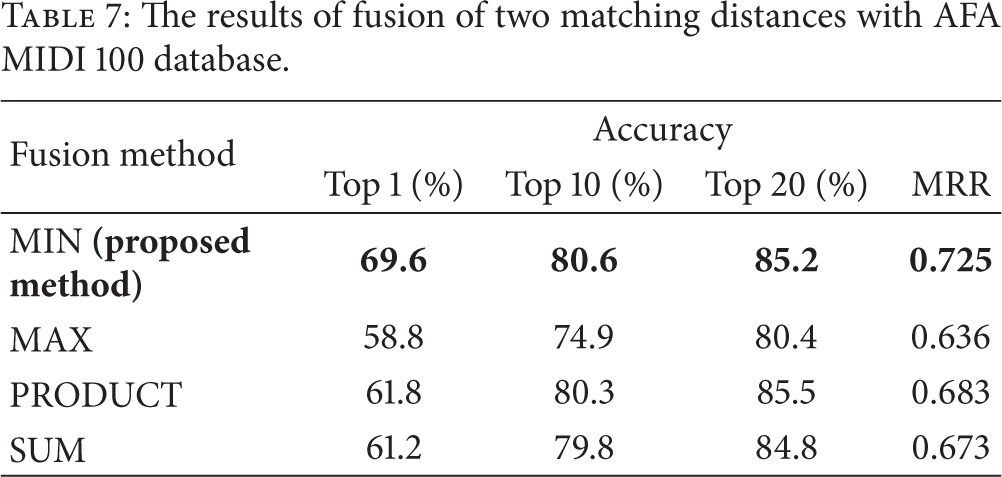
Tables 8 and 9 show the performance comparisons of the proposed method and others with 2009 MIR-QbSH corpus database and AFA MIDI 100 database, respectively. As shown in Table 8, the Top 10 and Top 20 rate of the proposed method are a little lower than those of QDTW and QDTW with preclassification by LS (not combining two matching distances) in case of using the 2009 MIR-QbSH corpus database. However, except for this case, the accuracies of the proposed method are higher than those of other methods in all the cases as shown in Tables 8 and 9. In most of the QbSH systems, the accuracy is evaluated based on the MRR of (5) and Top 1 rate. So, we can confirm that the matching accuracy of the proposed method was enhanced compared to others although the processing time of our algorithm was reduced by higher than 30% compared to that of QDTW. Although LS has the lowest processing time among them, it could not be used as single classifier because of poor matching accuracy.
Performance comparison of the proposed method with other single classifiers with the 2009 MIR-QbSH corpus database.

Performance comparison of the proposed method with other single classifiers with the AFA MIDI 100 database.

4. Conclusions
In QbSH systems, DTW is typically adopted as a matcher. However, this method is computationally expensive, and a reduction in processing time is required for real-time QbSH systems. To overcome this problem, in this paper we proposed a fast QbSH system that combines LS algorithm and QDTW algorithm. The experimental results showed that the proposed method enhanced the matching accuracy and reduced the processing time compared to the result when the QDTW algorithm was used as single classifier.
As a future work, we will compare the performance of our proposed method with other methods for a larger database on various platforms including mobile devices.
Footnotes
Conflict of Interests
The authors declare that they have no conflict of interests.
Acknowledgments
This research was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF-2012R1A1A2038666) and in part by the Public Welfare and Safety Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Science, ICT and Future Planning (NRF-2010-0020810).