
Abstract
Generally, face detection and tracking focus only on visual data analysis. In this paper, we propose a novel method for face tracking in camera video. By making use of the context metadata captured by wearable sensors on human bodies at the time of video recording, we could improve the performance and efficiency of traditional face tracking algorithms. Specifically, when subjects wearing motion sensors move around in the field of view (FOV) of a camera, motion features collected by those sensors help to locate frames most probably containing faces from the recorded video and thus save large amount of time spent on filtering out faceless frames and cut down the proportion of false alarms. We conduct extensive experiments to evaluate the proposed method and achieve promising results.
1. Introduction
Locating and tracking faces in video streams have long been the most fundamental techniques in computer vision. They are step stones of almost all facial analysis algorithms including face alignment, face modeling, face recognition, and gender/age recognition and have enabled numerous applications, such as human-computer interaction (HCI), video surveillance, and many other multimedia applications. Particularly in the context of HCI, only when computers could understand human faces well could they begin to truly figure out people's intentions and thoughts and react in a proper manner.
In general, the goal of face detection is to determine whether or not there are any faces present in an arbitrary image and, if present, return the location and extent of each face. While this appears to be a simple task for human beings, it is very difficult for computers and has been a hot topic in machine vision that attracts top researchers all over the world in the past few decades. The difficulties associated with face detection can be attributed to many variations of lighting conditions, scale, location, orientation, pose, facial expression and occlusions, and so forth. In addition, intraclass interferences that arise from make-up, beard, mustache, and glasses of the same person make face detection problem even more hard.
In recent years, face detection has made significant progress and been increasingly utilized in real world applications and products, like Google's Picasa. Nowadays most digital cameras are equipped with built-in face detector to help autofocus. However, face detection in unconstrained settings remains a challenging task. Modern face detection algorithms are mostly based on low level feature extraction and statistic model training and focus their attention wholly on visual data analysis. Herein more and more complex features and rigorous learning algorithms are developed to extract as much information as possible from the visual content.
Automatic face tracking requires face detection to initialize the tracking process. It is an application of object tracking. In its simplest form, tracking can be defined as the problem of estimating the trajectory of an object in the image plane as it moves around a scene [1]. In terms of face tracking, a tracker assigns consistent labels to detected faces in consecutive video frames. The main challenge in tracking is clutter. Clutter is the phenomenon when features expected from the target are difficult to discriminate against features extracted from other objects in the scene. Another challenge is introduced by appearance variations of the target itself. Intrinsic appearance variability includes pose variation and shape deformation, whereas extrinsic appearance variability includes illumination change, camera motion, and different camera viewpoints [2].
In this paper, we focus our attention to handle the task of face tracking with a new perspective. Typical face detection and tracking are conducted frame by frame and window by window. In terms of face detection, the time spent on filtering out a faceless frame is comparable to that on identifying a frame containing faces as every search window needs to be checked to ensure all possible faces are detected. Faces are tracked in following frames using relatively less computationally expensive methods. In case of track failure, face detection runs again to reinitialize the tracker. Large amount of time is wasted on searching faces in faceless frames. For example, when a subject in video turns his back and walks away from the camera, his face totally disappears and from that moment on there is no need to apply face detection and tracking. To improve the performance and cut down time cost, we take advantage of context metadata collected at the time of video capture in a sensor-assisted environment to rule out potential faceless frames.
The rapid advances in consumer electronics have led to a wide proliferation of cheap powerful wearable sensors, such as accelerometer, digital compass, gyroscope, and GPS. The availability of these sensors initially included in smart phones to improve user experience is now changing the landscape of potential applications and providing reliable sources of contextual information which helps to model human behavior. In this study, we employ smart phones as sensing platforms to collect measurements of orientation sensor and help interpreting human moving direction which is explored and utilized to improve face detection and tracking. To summarize, the main contributions of this paper are twofold. First, we present a sensor-assisted fast face detection and tracking approach. As far as we know, it is the first attempt to integrate personal sensing technologies into face detection and tracking in video. This integration of a new sensing model broadens the domain of semantic analysis of visual content and will be catalyzed by the growing popularity of wearable devices and concurrent advance in ubiquitous computing. Second, we implement a set of state-of-the-art multiobject tracking algorithms and conduct extensive experiments to evaluate our method.
The remainder of this paper is organized as follows. Section 2 presents the related work. Section 3 introduces the problem we tend to deal with. Section 4 details the proposed method. Section 5 describes our experiments together with result analysis. Concluding remarks are placed in Section 6.
2. Related Work
2.1. Face Detection
There have been hundreds of reported approaches to handle the problem of face detection. Based on early works of Yang et al. [3], existing face detection approaches can be grouped into four categories: knowledge-based methods, feature invariant approaches, template matching methods, and appearance-based methods. Knowledge-based methods employ predefined rules to determine face presence based on human knowledge; feature invariant approaches aim to find face structure features that are robust to pose and lighting variations; template matching methods make use of prestored face templates to judge if a face exists in an image; appearance-based methods rely on techniques from statistical analysis and machine learning to find the relevant characteristics of face and nonface images. The learned characteristics are in the form of distribution models or discriminant functions that are consequently used for face detection. Meanwhile, dimensionality reduction is usually carried out for the sake of computation efficiency and detection efficacy. Among these approaches, appearance-based methods have distinguished themselves as the most promising ones and had been showing superior performance to the others.
There are mainly two important factors that determine the success of a face detector: the features used for representing face images and the learning algorithm that implements the detection. Histogram based features have become very popular in recent years due to their excellent performance and efficiency, including local binary patterns [4], local ternary patterns [5], and histograms of oriented gradients [6]. Most state-of-the-art face detection methods usually use a combination of these features by concatenating them or by optimizing combination coefficients at the learning stage.
In terms of learning, most approaches treat face detection problem as a binary classification problem and determine whether current search window contains a face. Various machine learning methods ranging from the nearest neighbor classifier to more complex approaches such as neural networks, convolution neural networks, and classification trees have been employed for face detection. Among them, boosting based cascades have attracted a lot of research interest. Viola and Jones [7] introduced a very efficient face detector by using AdaBoost to train a cascade of pattern-rejection classifiers over rectangular wavelet features. Each stage of the cascade is designed to reject a considerable fraction of the negative cases that survive to that stage, so most of the windows that do not contain faces are rejected early in the cascade with comparatively little computation. As the cascade progresses, rejection typically gets harder so the single-stage classifiers grow in complexity. The structure of the cascaded detection process is essentially that of a degenerate decision tree. In our work, we employ this detector to initialize face tracking.
2.2. Object Tracking
Two tracking paradigms have been presented in [8]. Recursive tracking methods estimate current state
The research efforts mentioned above focus their attention wholly on the analysis of visual data. While in this study, we provide a novel method to exploit contextual information collected at the point of video recording to help face detection and tracking in video.
3. Problem Formulation
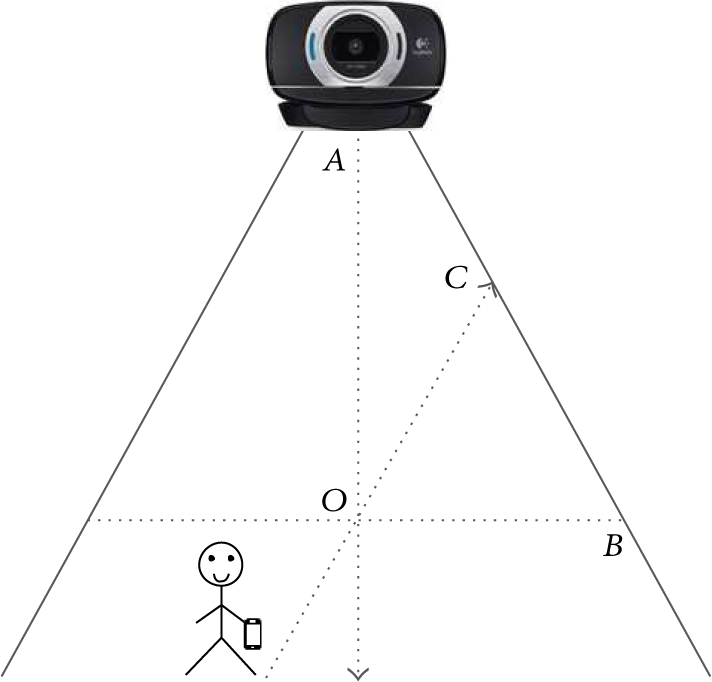
Subjects carrying smart phones move around casually in the FOV of a fixed digital camera. Video data are continuously recorded and motion measurements are collected by embedded sensors on the phone. As depicted in Figure 1, direction measurements captured by orientation sensor contained in the red brace indicate that the subject is moving toward camera, and during this period the camera could most likely capture clear faces. Based on this judgement, we could apply face detection and tracking directly to frames recorded in this period and skip faceless frames before and after. Our objective is to figure out these advantageous situations and improve face detection and tracking in various situations with the help of on-body sensors.

An application scenario of the proposed method. We believe that time period defined by the red brace is probably most suitable for face detection and tracking, during which the subject moves towards the camera.
4. Proposed Method
In this section, we elucidate the proposed method in detail. As illustrated in Figure 2,
A subject moving in the FOV of a camera.
Based on the above analysis, we propose a two-stage automatic face tracking framework. In first stage, context metadata collected at the time of video capture are scanned to identify advantageous situations for visual analysis. Video frames are automatically labeled to indicate whether they contain faces. In second stage, face detection and tracking are conducted over the labeled frames to locate and track all faces.
4.1. Sensor Description
Two types of sensor are involved in the proposed method, camera sensor and orientation sensor. Video streams recorded from the camera sensor are saved on the disk as discrete files. In this subsection, we put emphasis on orientation measurements collection from orientation sensor on smart phones.
Currently most smart phones are equipped with various types of specialized sensors originally aimed at improving user experience, including orientation sensor. An orientation sensor usually consists of an accelerometer and a magnetometer and can sense the orientation of a smart phone relative to the earth with three different values, pitch, roll, and azimuth, as shown in Figure 3. Pitch indicates rotation about the x-axis and ranges from −180° to 180° inclusively, with positive values when the z-axis tilts toward the y-axis; roll indicates rotation about y-axis and ranges from −90° to 90° inclusively, with positive values when the z-axis tilts toward the x-axis. Azimuth indicates angle between the y-axis and magnetic north direction and ranges from 0° to 359° inclusively. Experiments have demonstrated that with the specified phone attachment shown in Figure 3, azimuth angle of the smart phone could be utilized to estimate moving direction of human body.
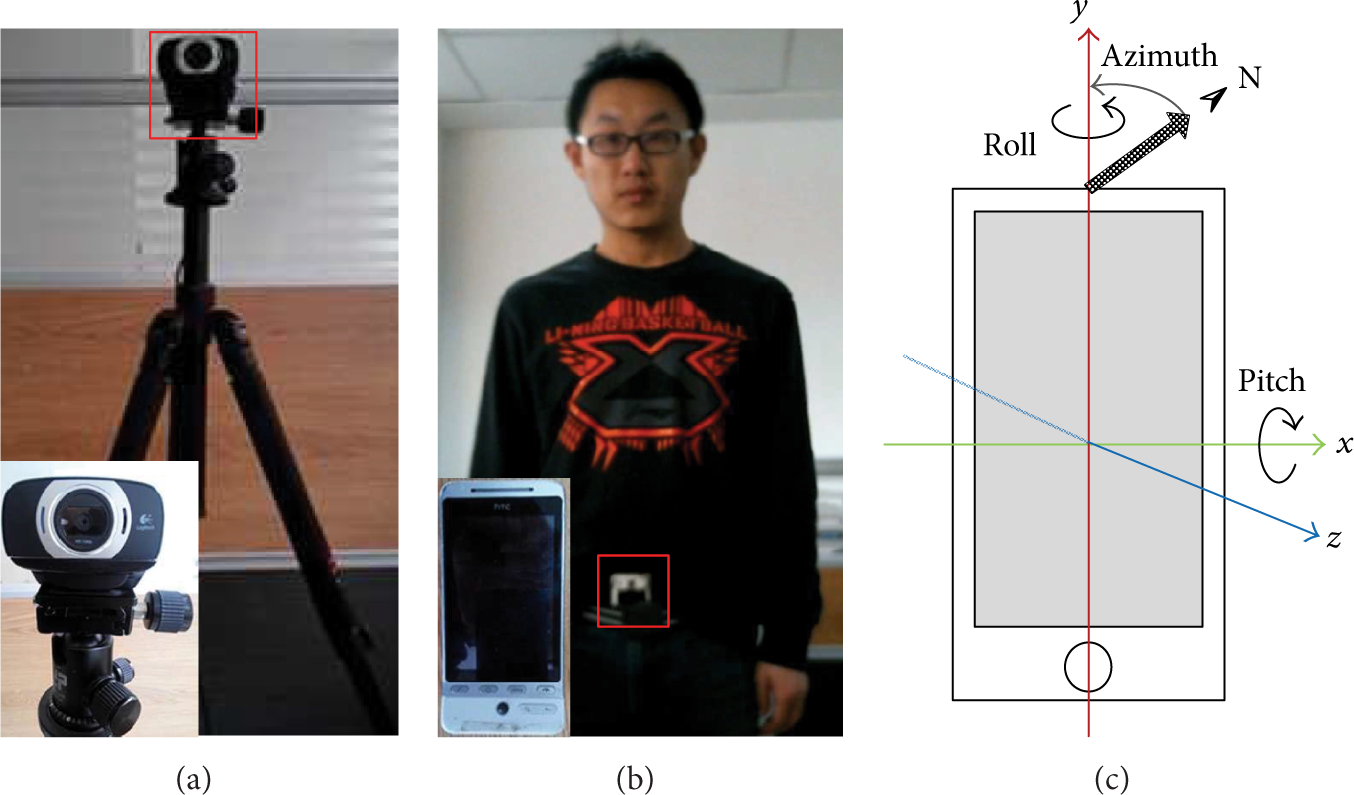
(a) A Logitech C615 digital camera fixed to a tripod. (b) An HTC G3 Android smart phone with a built-in 3-axis accelerometer and a geomagnetic field sensor. The phone is attached to the waist belt of a subject. (c) Reference frame of a smart phone, with front view to the page.
4.2. Frame Labeling
We conduct a preliminary experiment to quantitatively measure impacts of moving direction on face detection. First, we divide

Sector layout in half of camera FOV. Each sector covers an angle of 15°.
We manually count the number of faces in every video clip and then perform face detection using a Haar feature based face detector [7] in OpenCV [16]. Statistics about collected data and detection results are listed in Table 1, where
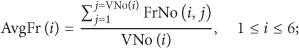
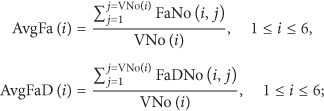
Basic information about video clips collected from each sector.

From the result we could conclude that faces, either manually labeled (AvgFa) or detector predicted (AvgFaD), start to decrease dramatically from sector
With the obtained threshold, we design a frame labeling algorithm, as listed in Algorithm 1. All collected orientation measurements are first smoothed to reduce noise and then scanned to label video frames recorded at that time period to prepare for face detection and tracking. Once a qualified azimuth sample is detected within a time window, all frames within that window will be labeled positive. By this strategy we could alleviate the adverse impacts of sudden body turning. With respect to situations when multiple subjects exist, to simplify the problem, we assume that all subjects stay within camera FOV in all experiments. Final result of frame labeling is calculated by applying logical OR to the set of
w: time window in seconds. b: a boolean variable indicating whether frames within a time window should be labeled positive. (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15)
4.3. Face Tracking
In this section, we provide three sensor-assisted tracking algorithms to track faces in the labeled frame sequences, including track by detection, track by mean shift, and track by TLD (tracking-learning-detection). In these algorithms, we employ the Viola-Jones face detector [7] to initialize the tracking process. Moreover, to reduce detection time, we filter out nonskin areas from each frame using a skin model presented in [17]. To deal with multiface tracking, we design a face classification algorithm to group different faces, as shown in Algorithm 2. The logic of the algorithm is straightforward. For each face, we search the most similar descriptor by comparing the normalized face patches. In this paper we resize each face to a 
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25) (26) (27) Create new descriptor (28) (29) (30) (31) (32) (33) (34)
(1) Track by Detection. As shown in Algorithm 3, we apply face detection over each positively labeled frame containing faces. The detected faces are then classified using Algorithm 2. The performance of this algorithm totally relies on the generalizability and representability of training samples of the detector. We use this algorithm as a benchmark for parameter optimization in Section 5.1.
(1) (2) (3) (4) (5) Detect faces from (6) (7) (8) (9)
(2) Track by Mean Shift. We provide a tracking algorithm based on mean shift [10] in Algorithm 4. Mean shift is a procedure for locating the maxima of a density function given discrete data sampled from that function. In 
int: the interval of track reinitialization. (1) (2) (3) (4) (5) (6) (7) Detect faces from (8) (9) (10) (11) (12) (13) Get last index (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25) (26)
(3) Track by TLD. TLD was proposed by Kalal et al. [18, 19]. It is a framework designed for long-term tracking of an unknown object in unconstrained environments. The object is tracked and simultaneously learned in order to build a detector that supports the tracker once it fails. The detector is built upon the information from the first frame as well as the information provided by the tracker. The original TLD tracker tracks only one object. We create a multiobject tracker based on OpenTLD provided in [20]. In Algorithm 5, we first initialize TLD tracker in
(1) (2) (3) (4) (5) (6) (7) (8) (9) Detect faces in (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25) (26) (27)
5. Experiments
In this section, we conduct extensive experiments to evaluate the proposed method. In addition to video devices and capture settings used in Section 4.2, we also utilize Android smart phones equipped with orientation sensors. Two subjects are recruited to take part in our experiments and phones are attached to waist belt where moving direction of subjects could be best approximated, as shown in Figure 3. A simple GUI application is created to start and stop data collection on phones. Orientation measurements are recorded and saved in text files on phone SD card and later accessed via USB. We implement labeling and tracking algorithms proposed in Section 4 based on OpenCV library [16]. Experiments are performed in various situations including indoor single-face, indoor multiple-face, outdoor single-face, and outdoor multiple-face. Subjects move randomly within part of camera FOV where their faces could be distinguished by the naked eye. In each situation, we repeat the experiment four times and each lasts about five minutes. In all we collect sixteen video clips and thirty-two text files of orientation measurements.
5.1. Tracking Optimization
To label frames using Algorithm 1, we set 
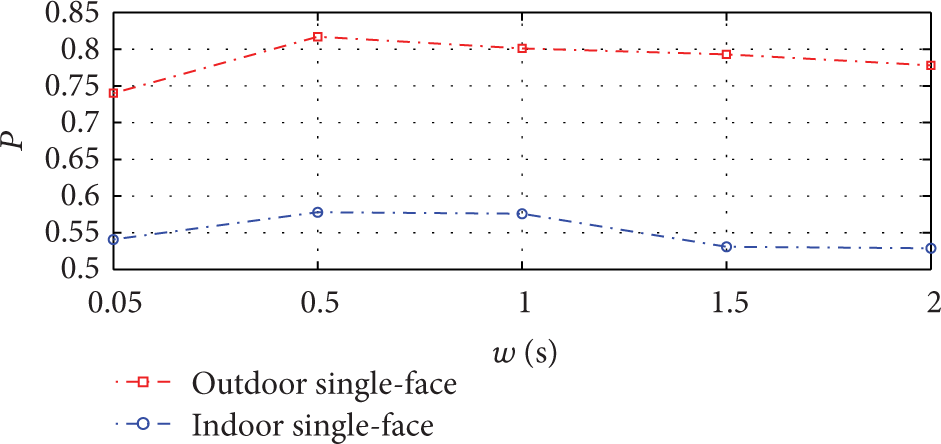
Performance of frame labeling with different time windows.
The threshold
As illustrated in Figure 6, Algorithm 4 achieves its best result in both indoor and outdoor environment when using an interval of 



Averaged F-score obtained from mean shift tracking with different intervals. The first interval is 1 frame.
5.2. Tracking Comparison
In this subsection, we compare the sensor-assisted face tracking algorithms depicted in Algorithms 3, 4, and 5 with their sensorless counterparts in terms of performance and processing speed. To conduct sensorless face tracking, we just set elements of
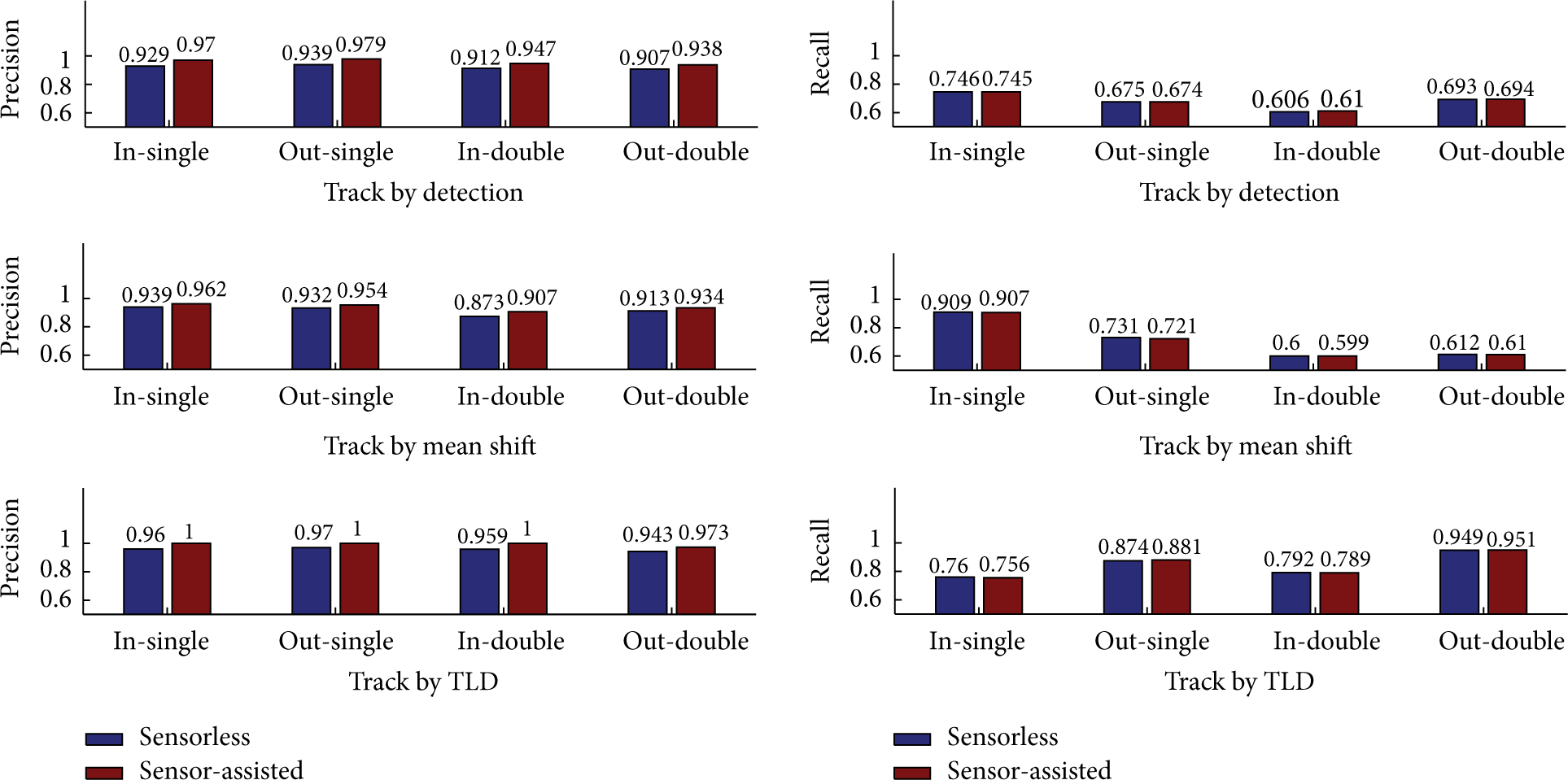
Precision and recall of sensorless and sensor-assisted face tracking algorithms in each situation.

Negatively labeled frames that contain false positive results in different situations.
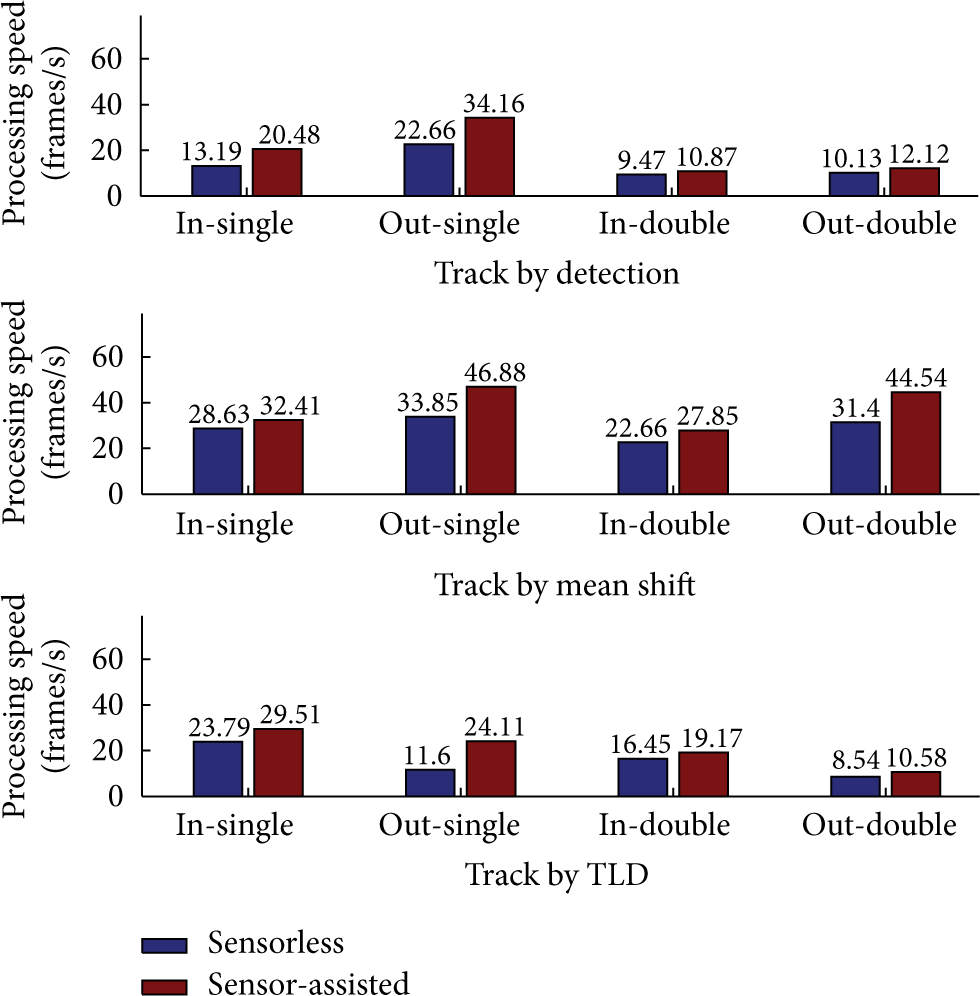
Processing speed of sensorless and sensor-assisted tracking algorithms in each situation.

Extracted frames of tracking results, where (a1)–(f1) are from track by detection, (a2)–(f2) are from track by mean shift, and (a3)–(f3) are from track by TLD.
6. Conclusion
In this paper, we propose a novel method for fast face tracking. The method innovatively leverages sensor captured contextual information and could be utilized as a preliminary step to assist various algorithms for face detection and tracking in video. Experiment results demonstrate the performance improvement brought by the proposed method. However, the method is limited in the following aspects. First, users have to register and carry their smart phones in order to facilitate the tracking process. This necessary attachment of sensors damages the unobtrusiveness of visual sensing and causes inconvenience to users and limits application of the method to specific groups of people at some restricted places, where their healthcare and security are concerned, such as inpatients in hospitals and elders in nursing homes. Second, frames might be mislabeled on some occasions which may damage performance of the method. For example, when a subject turns head to attractions around the camera while his body is back to it, video frames recorded during this period are labeled negative by the proposed method and his face may be missed. In another case, when subjects move out of camera FOV while still facing the opposite of camera direction, frames recorded at this moment are labeled positive while in fact the subject is not in them and the tracking analysis over these frames is wasted. Third, the proposed method does not apply to video archives created in the past due to the absence of contextual metadata. A lot of work needs to be done to make the method better. In the future, we plan to explore the possibility of applying more other wearable sensors to the field of content analysis of visual data.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work is partially supported by the Project on the Architecture, Key Technology Research and Demonstration of Web-Based Wireless Ubiquitous Business Environment (no. 2012ZX03005008-001), the National Natural Science Foundation of China (Grant nos. 61202436 and 61271041), Natural Science Foundation of Jiangsu Province, China (Grant no. BK20130164), and EU funded iCore project, “Internet Connected Objects for Reconfigurable Ecosystems.”