
Abstract
Tag collision is one of the main issues impacting the performance of radio-frequency identification (RFID) systems. Several research efforts have been done in order to solve such problem. Current RFID standards, such as EPCGen2 and ISO-18000-7, adopt ALOHA-based protocols as the basis to solve collisions. In recent years, there has been a trend on designing schemes that split the interrogation zone into smaller regions with the aim of improving the system's performance. In this paper, we evaluate and optimize the performance of ALOHA-based protocols for this new type of partitioning schemes. We establish the guidelines for adapting ALOHA protocols to this new approach in order to exploit the advantages it offers. Thus, we propose a new version of the EPCGen2 standard adapted to the new partitioning schemes, which overcomes its counterpart for the traditional approach, significantly reducing the identification delay, which is the main parameter to optimize in RFID.
1. Introduction
RFID systems have become common in our daily life; their utility has largely exceeded that of bar codes since they offer a large set of new advantages on their use such as being in no need of a direct sight line or contact for communications, the ability of making simultaneous identifications, and having a wider identification range [1]. Some of the most popular applications for RFID technology are asset tracking, reusable containers, automatized inventories, and parts moving to a manufacturing production line, just to mention a few. Thus, it is crucial to improve the performance of RFID technology so as to get an overall impact on such wide range of applications.
There are two types of devices in an RFID network: readers and tags. On one hand, a reader is a powerful device in terms of memory and processing capabilities; it energizes the tags, controls the network's communication sequence, transfers information among the application and the tags, and identifies the set of existing tags in its interrogation zone. On the other hand, tags are small devices that are normally attached to the objects to be identified. Each tag has a unique identifier (ID) and may be active or passive [2]. Active tags account with a high storage capacity as well as with considerable processing capabilities; they normally come equipped with a battery. Passive tags gather the incoming energy from the reader to power up their circuitry, which makes them cheap to produce, thus making the use of passive RFID environments the most important for industry and research.
Several communication processes may be performed in an RFID network, such as missing-tag detection [3], estimation of the cardinality of a set of tags [4], and tag identification [5], the latter being the most frequent for a large set of actual applications. Thus, the identification process is performed by the interaction of reader(s) and tags in order to discover the whole set of tags present within the identification range of the reader(s). Such process is as follows: the reader broadcasts an information request, querying for IDs. Hence, each tag tries to reply in an ordered way, which may produce a collision if two or more tags respond at the same time, wasting energy and channel resources. This problem is known as the tag collision problem and is one of the main research topics in RFID networks. We can find work in the literature aiming to solve such issue; however, most of the contributions focus on the design of efficient communication protocols for the traditional one reader-one set of RFID tags scenario [6, 7]. There are a few recent revolutionary approaches aiming to shift from the traditional RFID scheme to new communication approaches. In [8], the authors propose to solve the tag collision problem by partitioning the interrogation zone into smaller zones and query one at a time using any given anticollision protocol. The authors' idea is very similar to the one used in the tree-based protocols, which splits a set of tags into several subsets in order to fasten the identification process by using the concept of power distance clustering (PDC). Later, in [9] the same authors add new devices to the process, increasing the complexity of the communication between reader and tags. The main idea presented there is to divide the set of tags and query them in a parallel fashion. Finally, in [10] the authors propose a full replacement of the traditional RFID system with one composed of one transmitter and several receiver RFID listeners. Such contribution proposes to extend the coverage area of an RFID system and uses cooperative reception techniques [11, 12]. Thus, we clearly see a new promising trend on the architecture of RFID systems. Such trend shows the need of new protocols for these new approaches, since most of them have been evaluated with tree-based protocols disregarding ALOHA-based ones, which have shown to be more efficient on the identification time. Moreover, ALOHA protocols are of great importance on RFID networks since they have been adopted as the basis of the two existing standards to solve collisions for active and passive RFID environments.
In this paper, we evaluate the performance of ALOHA-based protocols under the so-called PDC mechanism, which seems to be very promising.
In a recent work [13], we analyze an identification mechanism proposed in [9], and we propose an ALOHA-based protocol that exploits the advantages offered by such mechanism. The analyzed identification mechanism differs from the PDC approach in its architecture, since it introduces a new additional device in the RFID network, which is called a cluster-head. This new device plays the role of a relay between the reader and the tags. Additionally in that work, we study the advantages and disadvantages of such scheme compared to the traditional centralized identification approach.
In this paper, by means of surface analysis we adapt ALOHA protocols for their use with PDC in an optimal manner regarding time identification. Unlike tree-based protocols, ALOHA-based protocols work on a probabilistic basis, which complicates their use on a partitioning scheme. Hence, the rest of this paper is organized as follows; Section 2 discusses the related work on ALOHA-based protocols and the PDC scheme. In Section 3, we detail our proposal, where we adapt the operation of ALOHA to the PDC paradigm. Section 4 describes the performance measures we consider to evaluate our proposal. In Section 5, we address our results. Finally, in Section 6 we conclude this paper with a discussion of the results and contributions of our work.
2. Related Work
Several anticollision protocols for RFID have been proposed in the literature; they can be classified in two groups: ALOHA-based and tree-based protocols [1]. Some designers may choose to implement tree-based protocols because they are often more reliable than ALOHA-based ones; however, the latter are the most used type of protocols in RFID for two main reasons:
ALOHA protocols are probabilistic; thus they introduce randomness during the identification process. One of the most representative protocols falling into this category is the Dynamic Framed Slotted ALOHA protocol (DFSA) [1], which considers that time is slotted and grouped into frames [14]. In DFSA, the frame length varies during the whole identification process as the size of the set of tag decreases. In order to get this behavior, DFSA uses an estimation function that predicts the number of unidentified tags, which sets the frame length equal to such predicted number, so as to reach the maximum efficiency of ALOHA protocols [15]. Several estimation functions have been proposed in the literature such as those proposed in [16, 17]; most of them take as input parameters the number of empty slots
Since tree-based protocols are deterministic, they are able to identify a set of tags in a finite time. The performance of tree-based protocols strongly depends on the coding mechanism used for transmission. The main idea of such type of protocols is to divide the set of tags into many subsets. Their implementation is cheap; however, they need more commands than ALOHA protocols to carry out the identification process. This type of protocols may be classified as follows: prefix, bit by bit, and scanning-based [20]. On one hand, prefix-based protocols take a portion of the ID to carry out the identification of a given tag. On the other hand, bit by bit based protocols use bit-wise arbitration and pointers to the ID. Finally, scanning-based protocols exploit the uniqueness of IDs; thus they use the information obtained in a collision to generate all the possible IDs.
2.1. EPC Class-1 Generation-2 Standard
EPCglobal published the Class-1 Generation-2 standard (EPC Gen2 hereafter) for air interface protocols, which defines the physical and logical requirements for an RFID system of readers and passive tags in order to solve collisions in passive RFID scenarios [21]. EPC Gen2 is based on a modified version of DFSA, which uses the Q protocol as a mechanism to adapt the frame length at the end of each frame [22]. As Figure 1 shows, the Q protocol adapts the frame length according to the number of collision and empty slots. There are several papers in the literature proposing mechanisms to improve the performance of EPC Gen2. Some work proposes modifications to the Q protocol or the use of an alternative mechanism to adapt the frame length; a common conclusion among such contributions is that the frame length must be equal to the estimated number of unidentified tags (
Optimal
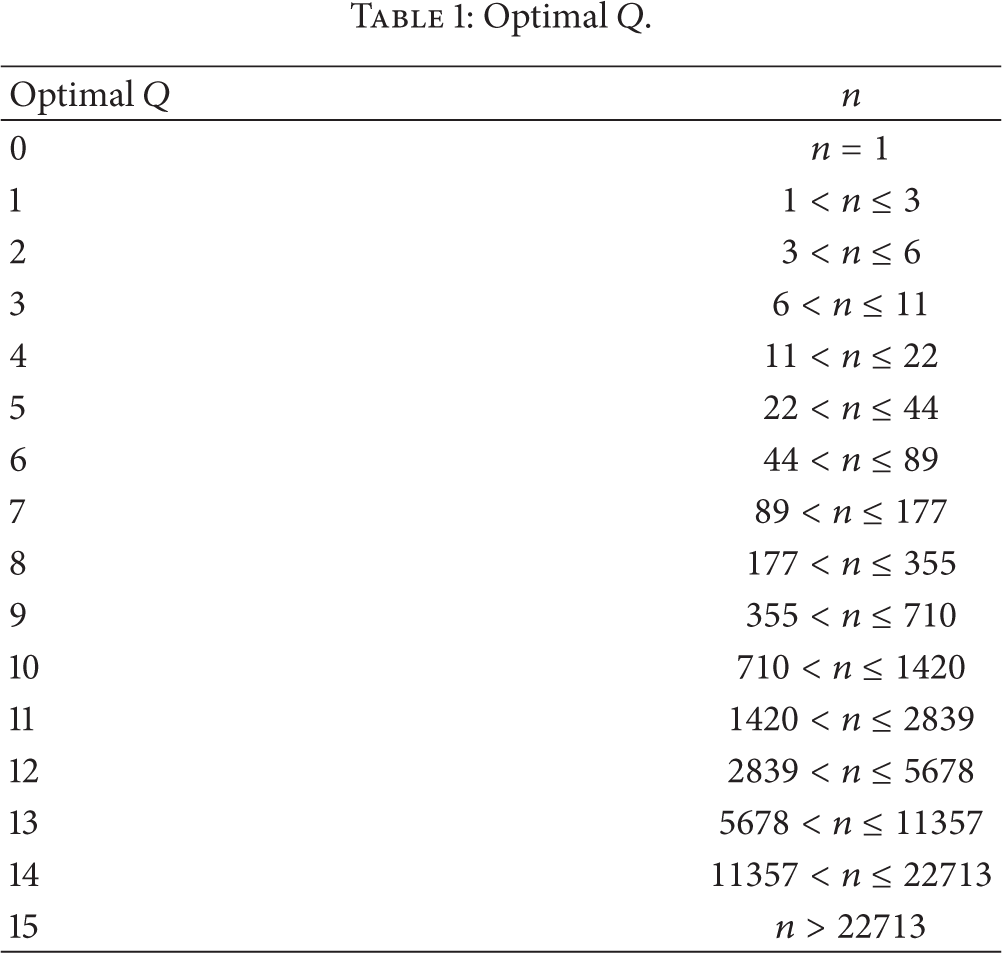
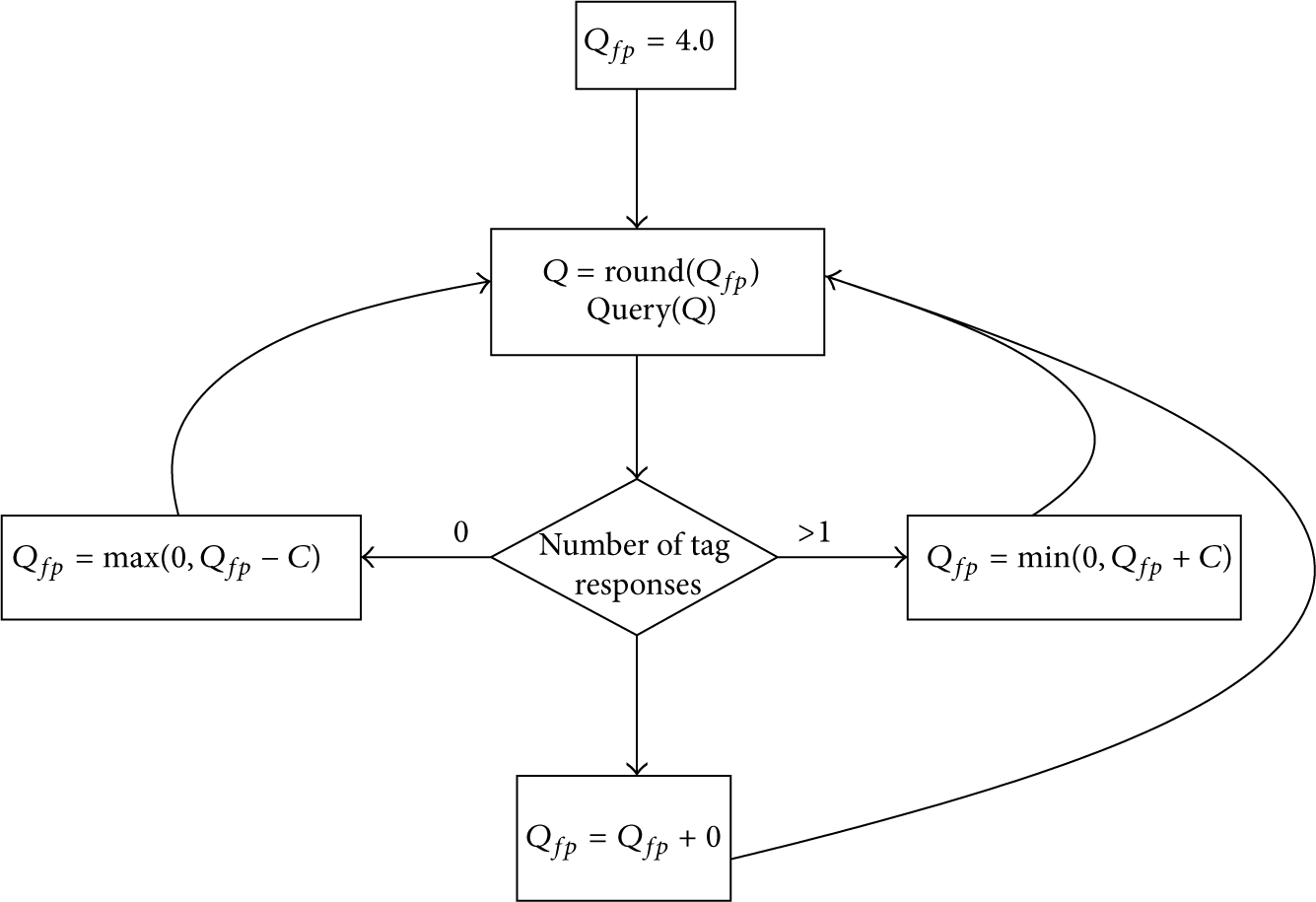
Additionally, the performance of EPC Gen2 when choosing an optimal Q may be improved with the knowledge of extra information, such as the number of tags within the reader's interrogation zone. Thus, we can fasten the identification process by setting the length of the first frame equal to the existing number of tags in the interrogation zone, rather than initializing the process with the default value of Q.
2.2. Power-Based Distance Clustering Anticollision Scheme
In [8], the authors propose to adjust the reader's coverage range by varying the antenna's power. The main idea is to gradually extend the reader's interrogation zone from an initial value until reaching the maximum interrogation range. This means that, at any time, only the tags within the same cluster respond to the reader request. The main goal of such proposal is to reduce the number of concurrent participating tags, as is shown in Figure 2. We can see that the interrogation zone is divided into clusters

Clustering based on the distance from reader to tags.
A key parameter for PDC is the “step” value (d), since it determines the number of clusters within the interrogation zone. Therefore, it is common to use small values of d for dense environments and large values for sparse scenarios.
(1) Optimal Power-Based Distance Clustering for Tag Anticollision in RFID Systems. An optimization of the PDC scheme is presented in [20]. Based on the protocol used and tag distribution, the authors provide an analytical model to get the optimal number of clusters. Thus, they take advantage of the deterministic feature of tree-based protocols to compute the optimal value of d, using the query-tree protocol by assuming a uniform distribution [24]. The authors mention that a similar analysis may be made for any other protocol and a given distribution; nevertheless, they are unable to make such analysis for ALOHA-based protocols [25].
(2) Discrete Power-Based Distance Clustering for Anticollision Schemes in RFID Systems. In [25], the authors optimize their previous work on PDC, which they call Optimal Discrete-PDC (OD-PDC). The proposal consists of partitioning the identification zone based on the possible transmission range of a reader. The OD-PDC scheme is independent of both the tags distribution and the anticollision protocol used within a single cluster. Despite the advantages mentioned before, the proposal has a strong requirement to make ALOHA protocols work under the PDC scheme, which is to know the total number of tags within the interrogation zone. This means that ALOHA protocols cannot be used if such information is unavailable and, more importantly, optimality cannot be reached as well.
3. Power Distance Clustering for ALOHA Protocols
We have seen so far that PDC is a promising mechanism to improve the performance of RFID; however, it has been barely evaluated for standard protocols. Since ALOHA is the basis of the most important standards for RFID, it becomes vital to evaluate its performance for this new promising PDC paradigm. Even if the proposal presented in [25] shows some results of the Q Algorithm on the PDC scheme, they are unclear since the authors do not mention how the frame length is chosen and how good is the performance achieved in terms of time, besides the fact that they are unable to find how to make ALOHA protocols work to the PDC in scenarios without prior information.
In this section, we adapt the operation of the ALOHA-based protocol required by the EPC Gen2 standard to work under the PDC approach. By means of surface analysis, we provide such functionality for ALOHA protocols in an optimum manner for both cases:
In this paper, on one hand we take advantage of the adaptable frame length feature of ALOHA protocols, and on the other hand we profit the ability of the PDC scheme to reduce the number of active tags at a time. In this way, we take the best features of both paradigms in order to make ALOHA protocols work on the PDC approach.
We model the system as follows: we consider a system with an RFID reader placed at the center of the interrogation zone, covering n passive tags. We use the spherical approach to model the interrogation zone, which has a radius of R units and an area
Likewise, to optimize the performance of ALOHA protocols we use both, the number of clusters, k, and the knowledge acquired along the identification process to estimate the number of tags within each cluster. Thus, we adapt the frame length according to the estimated number of tags to avoid the first identification cycle. Additionally, as we will see in the following sections, we can ignore the time required to compute the number of clusters and the power needed to cover a given area. This is because this process is executed during a phase previous to the identification process.
3.1. Unknown Number of Tags: Constant Number of Clusters
A constant number of clusters may be obtained by initializing either d or k. Thus, in both cases the number of clusters is constant and is given by

On one hand, by setting d, we define different cluster areas 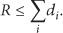
On the other hand, if we set k, we need to determine its value at the ith step, that is, the value of 


Proof by Induction
Base Case: Two Clusters. From (4), we know that 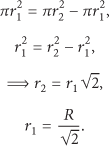
Inductive Step. For k clusters, we know that



Thus, the value of 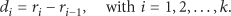
In this case, i ranges from 2 to k since when
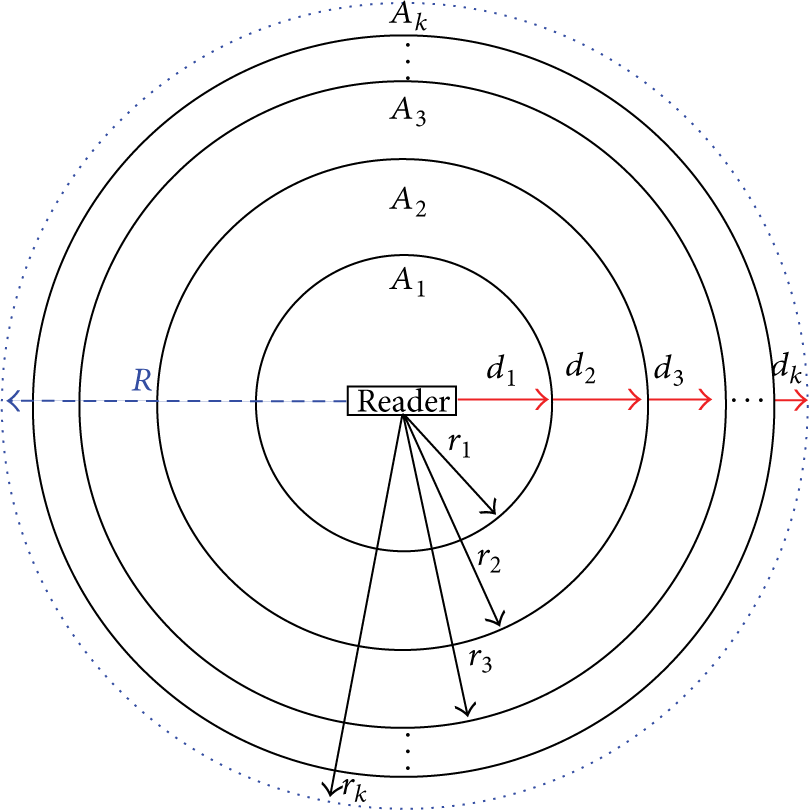
Coverage areas for k clusters within the interrogation zone.
Figure 4 shows the cases for equal and different areas. As we can see in Figure 4(a), when d is constant, the areas are different. In this case, d is added to the current

Methods for partitioning the interrogation zone.
Indeed, we can estimate the total number of tags, 
Correspondingly, the estimated number of tags within the ith cluster is given by

Once
Algorithm 1 summarizes our proposal, which is comprised of two phases: tag set partitioning and identification process. During the first phase in lines 4–22, the end system splits the set of tags according to k. Then, during the second phase in lines 26–28, the reader executes the identification process for the first cluster and afterwards, in lines 32–36, it estimates the number of tags within each cluster. In line 38, the reader uses the number of tags within each cluster to compute the initial value of Q; then in lines 40–42 it executes the identification process for the rest of the clusters using the corresponding Q. The identification process is executed in an incremental way in order to cover the whole interrogation zone, with the end to guarantee that there is only one active zone at a time.
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23)
(24) (25) (26) (27) (28) (29) (30) (31) (32) (33) (34) (35) (36) (37) (38) (39) (40) (41) (42) (43)
It is important to remember that previous to the identification process the end system performs Phase 1 from Algorithm 1. The delay spent during this phase is negligible because of two reasons. First, our proposal is
3.2. Known Number of Tags: Number of Clusters Based on the Population
As we mentioned above, the number of tags within the interrogation zone is generally unknown for most of the RFID applications. However, for a subset of them such data is known or it is estimated before the identification process; inventories or counting tasks are applications falling into this category. For such cases, we can exploit the knowledge about the number of tags within the interrogation zone, in order to execute the identification process in a faster way.
Since we know the number and the distribution of tags within the interrogation zone, we may improve the performance of the whole identification process by computing the number of clusters, such that the expected number of tags by cluster, 
From (13), we compute the number of clusters and from (5) we can find the clusters area. Since the expected number of tags within each cluster will be less than or equal to W, we may use the EPC Gen2 standard with a frame length equal to W in order to achieve the maximum system throughput. However, this does not work very well because the number of tags within the interrogation zone decreases as the process evolves. Hence, we may improve the performance of EPC Gen2 by starting the identification process in each cluster with a frame length equal to the expected number of tags within each of them, and afterwards we may use any mechanism to adapt the frame length for the rest of identification process. Notice that W is of great importance since it defines the initial frame length in each cluster.
The corresponding pseudocode is given in Algorithm 2. The first phase, in lines 5–13, is a prephase of the identification process during which the end system computes the number of clusters according to the total number of present tags and the expected number of tags within each cluster. The second phase, in line 14, corresponds to the identification process, where the reader computes the initial value of Q in order to start the identification for each cluster. Finally, in lines 17–19, the reader executes the identification process in each cluster using the corresponding value of Q.
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13)
(14) (15) (16) (17) (18) (19) (20)
As in Algorithm 1, Phase 1 from Algorithm 2 is performed by the end system as a prephase of the identification process. Additionally, we find that Phase 1 is
4. Evaluation
In this section, we evaluate the performance of our proposal. We evaluate the EPC Gen2 standard for both, the traditional centralized scheme and our proposal on the PDC scheme. The main goal is to show the improvement obtained with EPC Gen2 when the interrogation zone is divided in an optimal way. We take the identification delay as the main performance measure. The identification delay is the time needed to discover the whole set of RFID tags in the reader's coverage range. The identification delay is measured starting from the time the first query is sent by the reader until the time the last response is issued by the last unidentified tag. In order to do this, since the identification cycle is a function of the number of used slots and the messages exchanged among reader and tags, we express the identification cycles in absolute time.
Therefore, we choose Matlab to deploy the protocols to evaluate as follows.
We implement two versions of the EPC Gen2 standard. We call the first one EPCGen2; it uses the Q protocol as mechanism to adapt the frame length in each identification cycle. The second version we implement, EPCGen2Q, uses the heuristic proposed in [23] along with the estimation function of [26] as mechanism to adapt the frame length. Also, we consider the following cases.
We consider an RFID reader placed at the center of the interrogation zone with a coverage range of 10 meters. For the case when the number of clusters is constant,
we vary the step, d, in the range we vary the number of clusters, k, from 10 to 50. For the case when the number of clusters is based on the population,
we vary W from 15 to 255. We choose these values according to the results obtained in a previous work [27], which concludes that a well suited value to start the identification process is From [22], if we set the number of subcarrier cycles per symbol to We assume that all the participant devices have a coherent clear channel assessment (CCA); that is, the channel is busy when a packet's preamble is detected. We consider that the network is free of the capture effect, since such phenomenon impacts the identification process in an RFID network. The capture effect occurs when two or more tags transmit simultaneously to a reader, and one of them succeeds because it has favorable physical conditions. In order to get reliable results, we run each protocol for
5. Results
5.1. The Case of Constant d and Constant Number of Clusters k
(1) EPC Gen2. In Figure 5, we plot the identification delay for the EPCGen2 for different values of d. As we can see, the best results are obtained with

EPC Gen2 with constant d.
Next, we plot the identification delay for the EPCGen2 protocol in Figure 6 for different values of k. As we can see, the best results are obtained with the highest value of k. The reason is that when there are more clusters, there are less tags as well in each of them, which results in a lower identification delay. Again, notice that when the number of tags is greater than 1800, it is better to choose

EPC Gen2 with constant k.
(2) EPC Gen2 with Optimal Q. Figure 7 plots the identification delay for the EPCGen2Q protocol. We can clearly see that the better results are obtained with

EPC Gen2 with optimal Q and constant d.
In Figure 8, we can see the identification delay for the EPCGen2QMod protocol. Notice that the lower identification delay is obtained when
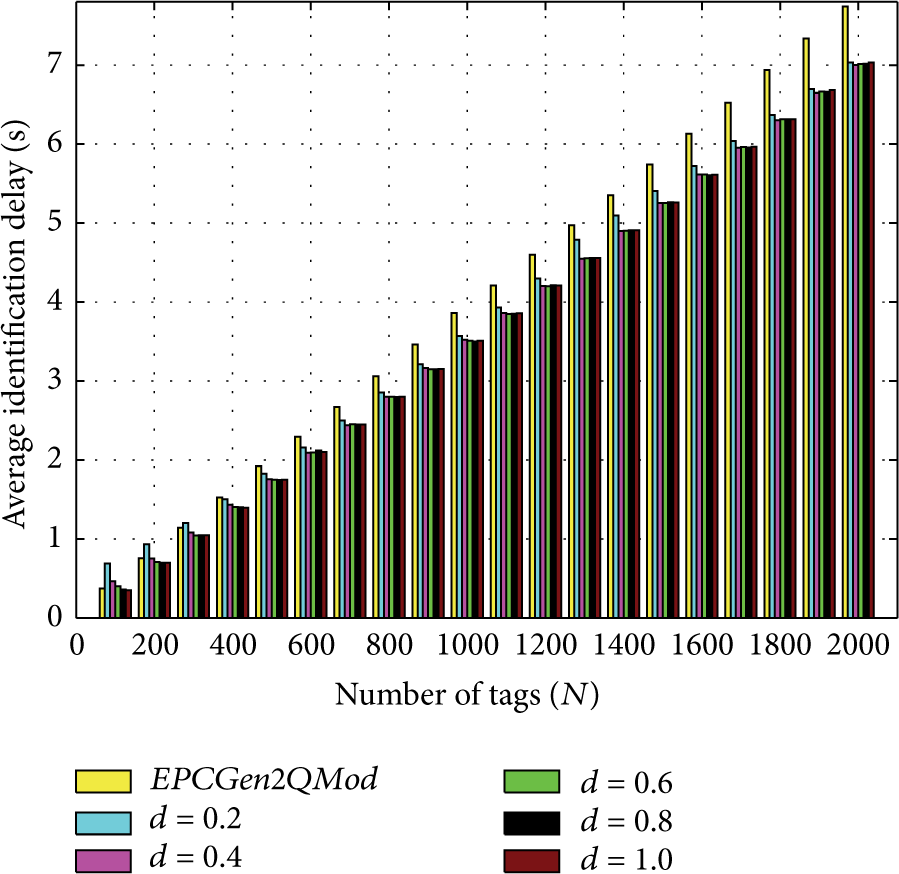
EPC Gen2 with optimal Q adapted to start with a frame length equal to the estimated number of tags and constant d.
Now, let us see in Figure 9 the identification delay for the EPCGen2Q protocol for different values of k. We can see a behavior similar to the EPCGen2Q protocol with different values of d. It is clear that the best result is achieved with
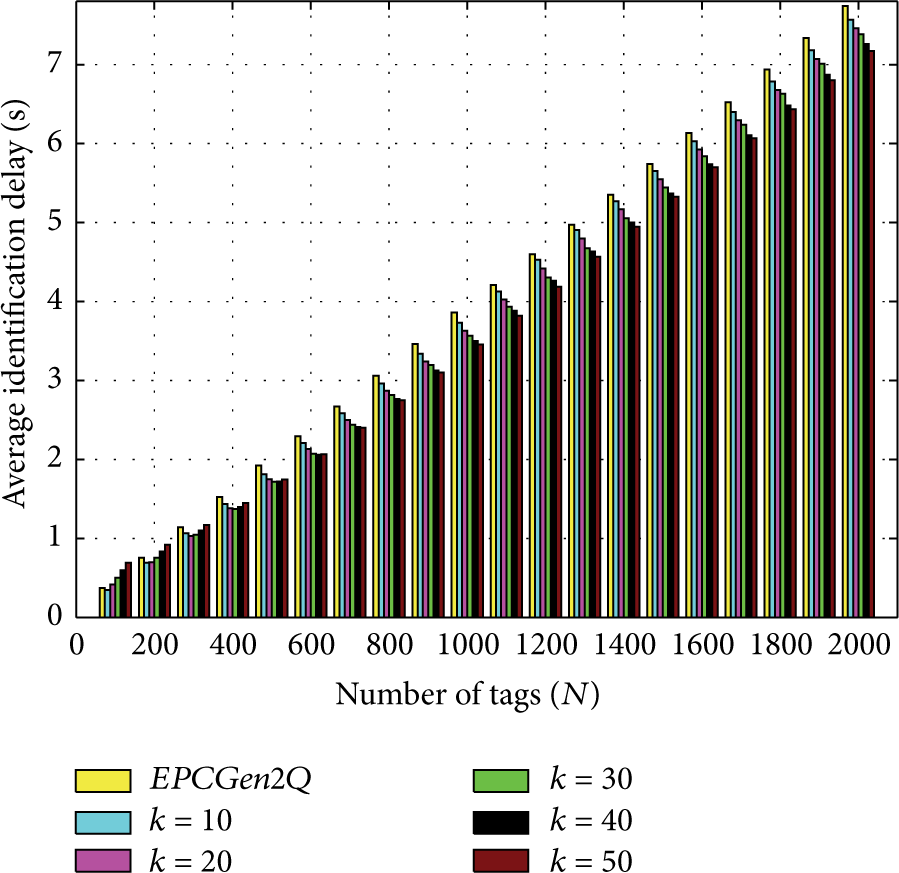
EPC Gen2 with optimal Q and constant k.
The behavior of the EPCGen2QMod protocol for different values of k is shown in Figure 10. There is a great improvement on the identification delay with
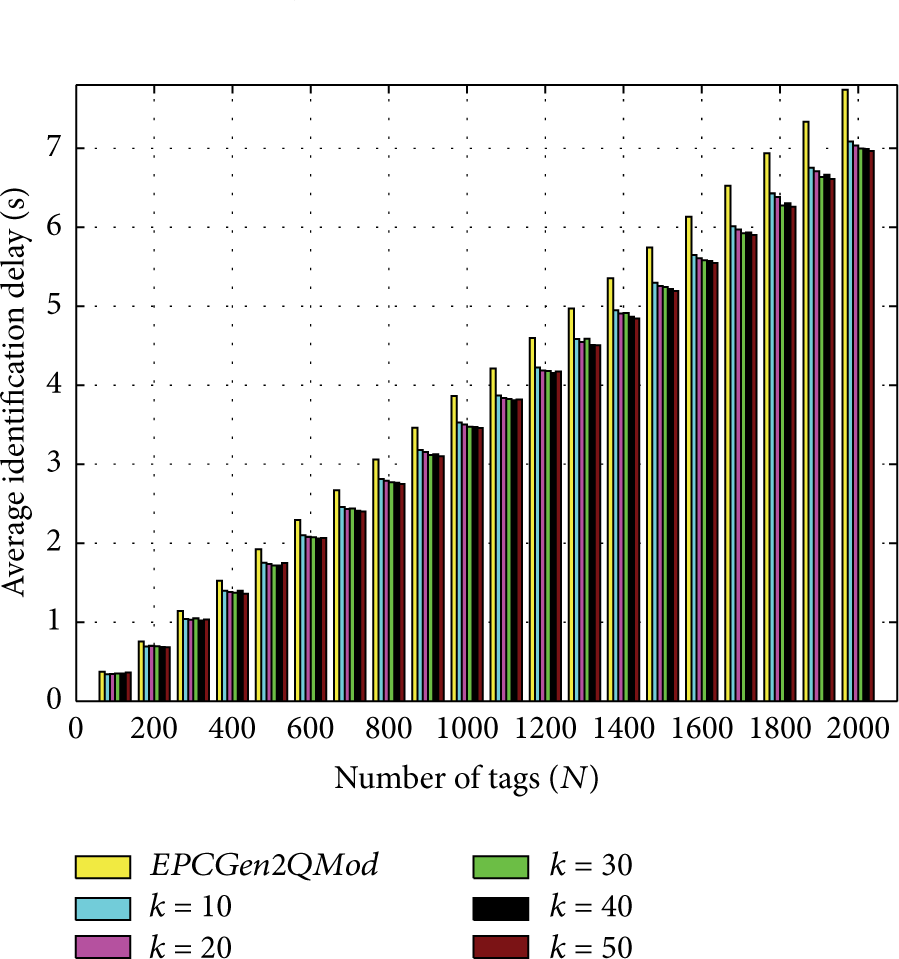
EPC Gen2 with optimal Q adapted to start with a frame length equal to the estimated number of tags and constant k.
5.2. Number of Clusters, k, as a Function of the Population
(1) EPC Gen2. We evaluate now the EPCGen2 protocol for the case when the number of tags is known. Thus, the EPCGen2 protocol is evaluated for different values of W. Figure 11 shows the corresponding results, where we see that the best results are obtained when
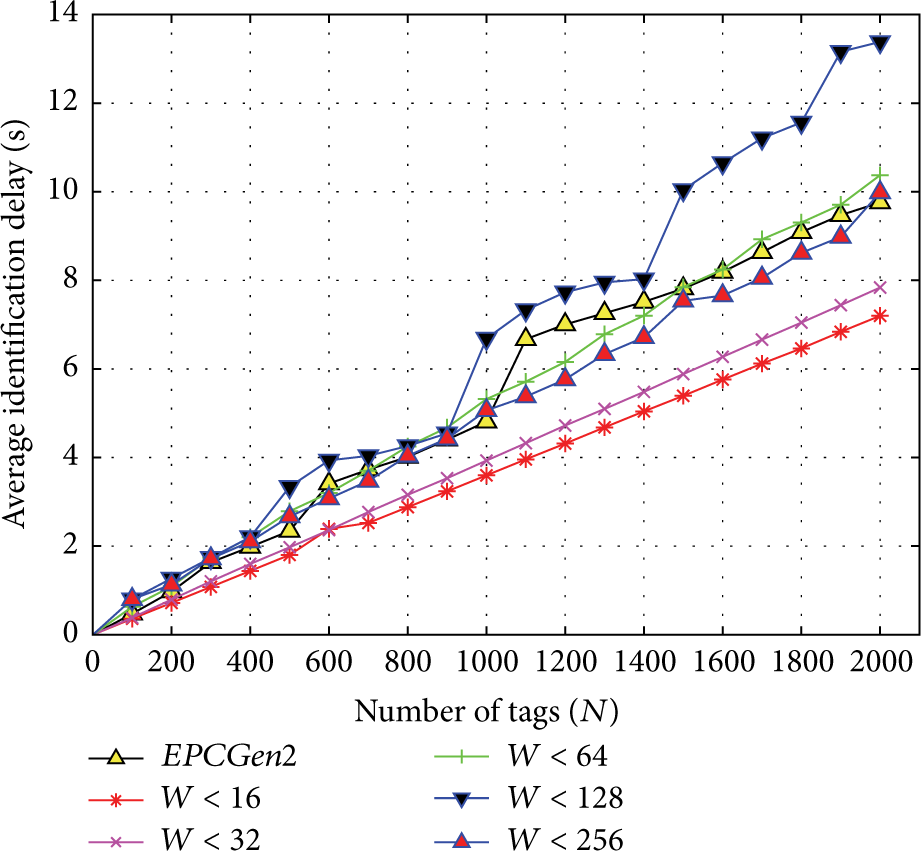
EPC Gen2 with optimum k and initial Q.
(2) EPC Gen2 with Optimal Q. Finally, we plot in Figure 12 the performance of the EPCGen2QMod protocol for different values of W. It is clear that the best performance is achieved when

EPC Gen2 with optimal Q, optimum k, and initial Q.
6. Conclusions
Power distance clustering (PDC) has shown to be very promising to improve the performance of radio-frequency identification (RFID) systems. However, to our best knowledge, PDC has been mainly evaluated with nonstandard protocols and barely evaluated with an ALOHA-based approach. Thus, in this paper we proposed a full implementation of an optimum ALOHA-based protocol for RFID working with the EPC Gen2 requirements under the PDC approach. On one hand, our proposal optimizes the time spent of the EPC Gen2 standard and on the other hand it respects all the features required by the standard; that is, we keep the standard unmodified. Consequently, the features of our proposal are of great utility over other proposals in the literature, since an implementation based on it might be done seamlessly thanks to the standard.
Additionally, we found an optimal way of splitting an interrogation zone using ALOHA-based protocols along with a PDC approach. Such splitting spends a minimal delay and it may be executed as a prephase of the identification process.
Our evaluations have demonstrated that the performance of ALOHA-based protocols improves when there exists additional information about the interrogation process, like number of tags and their distribution. Similarly, we have shown the advantages of using the knowledge acquired during the identification process, like the number of identified tags. In such sense, we found that we may avoid the first identification cycle if we start the identification process with a Q value based on the collected information, which improves all the identification process by reducing collisions, empty slots, and consequently the identification delay.
Finally, we found the lower limit of ALOHA-based protocols for an identification process executed with the PDC approach. Such limit is reached when there is the largest number of subzones within the interrogation range of the reader, which is a consequence of the nature of ALOHA-based protocols in optimal conditions for the traditional approach.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.