
Abstract
In this paper, a novel distributed online anomaly detection method in resource-constrained WSNs was proposed. Firstly, the spatiotemporal correlation existing in the sensed data was exploited and a series of single anomaly detectors were built in each distributed deployment sensor node based on ensemble learning theory. Secondly, these trained detectors were broadcasted to the member sensor nodes in the cluster, combining with its trained detector, and the initial ensemble detector was built. Thirdly, considering resources-constrained WSNs, ensemble pruning based on biogeographical based optimization (BBO) was employed in the cluster head node to obtain an optimized subset of ensemble members. Further, the pruned ensemble detector coded by the state matrix was broadcasted to each member sensor nodes for the distributed online global anomaly detection. Finally, the experiments operated on a real WSN dataset demonstrated the effectiveness of the proposed method.
1. Introduction
Wireless sensor networks (WSNs) are integrated with sensing, data processing, and wireless communication capabilities [1], which have received considerable attention for multiple types of applications. However, WSNs are highly susceptible to suffer from various kinds of interferences and faults hardware fault, electromagnetic interference, environmental factor, and network intrusion. Consequently, anomalous observations arise inevitably in WSNs. These unusual observations (i.e., anomalies or outliers) can be generally classified into two different types: one is error and the other is event [2, 3]. The former refers to the observations that deviate from the true measurement significantly such as the dirty data. Detecting and cleaning them timely can save the limited memory and computation as well as expensive communication resources. The later usually refers to an event that occurred such as temperature change caused by the forest fire. Detecting such event timely can help to take corresponding measure. With the wide application of WSNs, detecting these anomalous observations accurately and timely is an important task.
Though there are many anomaly detection methods available up to now based on data mining and machine learning methods, most of them do not take the resource limitation into account and are not designed specifically for WSNs. Considering the limited resource (i.e., computation, memory, communication, and so on) of WSNs, how to develop a suitable anomaly detection method becomes an important and urgent work. Up to now, researchers have done some works and proposed some anomaly detection methods for WSNs [1, 4–7], which took resource limitation into account to some extent.
As the first of four research directions in machine learning community, ensemble learning has attracted many researchers attention and been used widely in different applications [8]. However, seldom work was done for anomaly detection of WSNs. A large body of theoretical and empirical researches has shown that the combination of the detecting results of multiple individual detectors can improve the generalization performance observably, but original ensemble learning method usually needs to build and store multiple individual detectors which incur a large amount of computation and storage resource requirement and may not be appropriate for WSNs. The possible strategy is to select part of individual detectors to perform the anomaly detection. Consequently, the ensemble pruning is a necessary strategy [9], which can obtain the better (at least same) performance compared to the initial ensemble while the number of individual detectors decreased greatly.
Analyzing the spatiotemporal correlation of sensed data in WSNs and motived by the online ensemble learning method, the paper proposes a distributed anomaly detection method for WSNs from the perspective of both model building and resource saving. Further, to mitigate the high communication requirements caused by broadcast ensemble detectors, BBO based ensemble pruning is used to select the optimized individual detectors to build the final ensemble detector that has at least same performance compared to the initial ensemble detector. The main contributions of this paper include the following:
A distributed anomaly detection method for WSNs is proposed based on online ensemble learning. BBO based ensemble pruning is used to get the optimal subset for saving the limited store and communication resources in WSNs. State matrix encoding method is designed for ensemble detector, which can decrease the communication and memory overhead significantly.
The rest of this paper is organized as follows. The related work is described in Section 2. Based on ensemble learning theory and BBO, our proposed anomaly detection method is presented in Section 3. Experiment analysis is provided in Section 4. Finally, conclusions and future work are presented in Section 5.
2. Related Work
To clearly analyze the motivation of the paper, the state of the art of three key aspects related to our paper is summarized, that is, anomaly detection in WSNs, online ensemble learning, and ensemble pruning.
2.1. Anomaly Detection Method and Classification in WSNs
With the rapid development and wide application of WSNs, some anomaly detection techniques for WSNs have been developed and summarized based on different perspective. For example, [10] discussed the prioritization of various characteristics of WSNs including of spatiotemporal and attribute correlations of sensed data, anomaly types, anomaly identification, anomaly score, and so forth. A brief overview of the classifications strategies for anomaly detection methods in WSNs deployed in harsh environment was provided, which grouped anomaly detection methods into four types, that is, statistical-based techniques, the nearest neighbor based techniques, the clustering based techniques, and classification-based techniques. Based on the nature of sensor data, specific requirements, and limitations of the WSNs, [1] provided a comprehensive overview of existing anomaly detection techniques specifically developed for WSNs. It presented a technique-based taxonomy and gave a comparative table which could be used as a guideline to select the suitable method for the specific application. For example, based on the characteristic such as data types, anomaly types, and anomaly degree, statistical-based methods are further classified into parametric-based methods and nonparametric-based methods. Based on how the probability distribution model is built, classification-based methods are categorized as support vector machined-based methods and radial basis function neural networks-based methods [11], and so on. The interested reader is referred to more anomaly detection methods and taxonomies in [5, 6, 12, 13]. These taxonomies of aforementioned methods may be some overlaps, and machine learning and computational intelligence-based techniques are an increasing important research direction beyond all doubt with respect to the complicated application. Moreover, though these methods have acceptable performance to some extent, the resource constraint usually was not or seldom taken into account. With the wide applications of WSNs, it also attracted some researchers' attentions [14]. Another noticeable characteristic of aforementioned methods was that only a single detector or model was trained. It is well-known that the single model may be not well learned the complicated decision boundary with respect to the complicated data set. For the sensed streaming data with the dynamic data distribution, single model is hard to or need expensive cost to learn and obtain the whole profile such as training artificial neural network, which leads to overlearning and degrade the generalization performance. Besides, concept drift [15] was a common phenomenon that occurred in dataset collected from WSNs, and the single mode was difficult in dealing with such dynamic changing of data distribution and providing a comprehensive detector to detect anomaly. Moreover, detector updating based on all available dataset is also a hard work for online learning.
2.2. Ensemble Learning Method
Ensemble learning is a computational intelligence method, and theory and experiment have proved that the combination of the predictions of many individual detectors can enhance the generalization performance. There are many different ensemble learning methods used widely and successfully such as Bagging [16, 17], Boosting [18, 19], Random Forest [20], and their online version [21, 22]. Generally, an ensemble anomaly detector is constructed in two steps. Firstly, a number of base detectors are trained using the training dataset. Secondly, a combination strategy of result is designed to obtain the aggregated result based on the results of each single detector. For time-series dataset such as sensed dataset in WSNs, learning a single model to profile the whole dataset usually is difficult or impossible. Generally, there are two categorized ensemble patterns to handle the streaming data, that is, horizontal ensemble and vertical ensemble. The former follows such strategy that the nearest n consecutive data chunks are firstly used to train n base detector and the combination method is employed to build the ensemble detector used to predict data in the yet-to-arrive chunk. The advantage of horizontal ensemble is that it can handle noise data in the streaming dataset because the prediction of newly arriving data chunk depends on the combination of different chunks. Even if the noise data may deteriorate some chunks, the ensemble can still generate relatively accurate prediction result. The disadvantage of horizontal ensemble is that the streaming data is continuously changing, and the information contained in the previous chunks may be invalid so that using these old concept models will not improve the overall result of prediction. The latter ensemble pattern is vertical ensemble, which uses the newest chunk to build ensemble model. The advantage of vertical ensemble is that it uses different algorithms (heterogeneous ensemble) on same dataset or same algorithm (homogeneous ensemble) on different sampling subdataset from the chunk to build the model, which can decrease the bias error between models. The disadvantage is that vertical ensemble assumes that the data chunk is errorless; in real situation, this precondition usually is hard to meet. Currently, because online ensemble learning method can address the concept drift and noisy data problem in streaming data, ensemble learning has been used in anomaly detection for WSNs [23–25]. In this paper, after exploiting the spatiotemporal correlation existing in the sensed dataset in WSNs, a distributed method is proposed based on horizontal ensemble and like-vertical ensemble. Section 3 will give the detailed description.
2.3. Ensemble Pruning Based on Optimization Search Method
Although there are many advantages for ensemble learning, the nontrivial disadvantage is that it needs more memory, especially more communication resource to store and communicate multiple detectors in WSNs, which can drain energy quickly and is intolerable in WSNs. Motivated by the “many could be better than all” in the ensemble learning community [9], it implied that the combination of all detectors maybe not a good choice in ensemble learning community. Ensemble pruning, as necessary strategy to solve resource-limitation question [26], is employed, which selects a subset of initial ensemble and obtains better or at least equal detecting performance than the original ensemble. The most advantage of ensemble pruning is that it reduces the communication requirement greatly. In WSNs, broadcasting the relative few detectors can save the battery energy considerably. However, it is well known that pruning an ensemble of size N requires to search in the space composed of
3. Proposed Method
Motivated by the increasing online ensemble learning methodology [25] and considering the resource limitation of sensor node in WSNs, we propose a distributed online anomaly detection method based on the ensemble learning. Further, BBO is used for ensemble pruning to decrease the communication and memory requirements.
3.1. Problem Statement of WSNs
In this paper, we assume that the WSNs is applied in untouched area and to assure the sensed data quality, the sensor nodes usually are deployed densely. Besides, we assume that sensor nodes are time synchronized, which is mainly for clear presentation purpose rather than a limitation of our proposed method. Figure 1 shows WSNs, which consist of a large amount of sensor nodes and a base station (BS) [30]. Generally, the WSNs can be represented as a graph
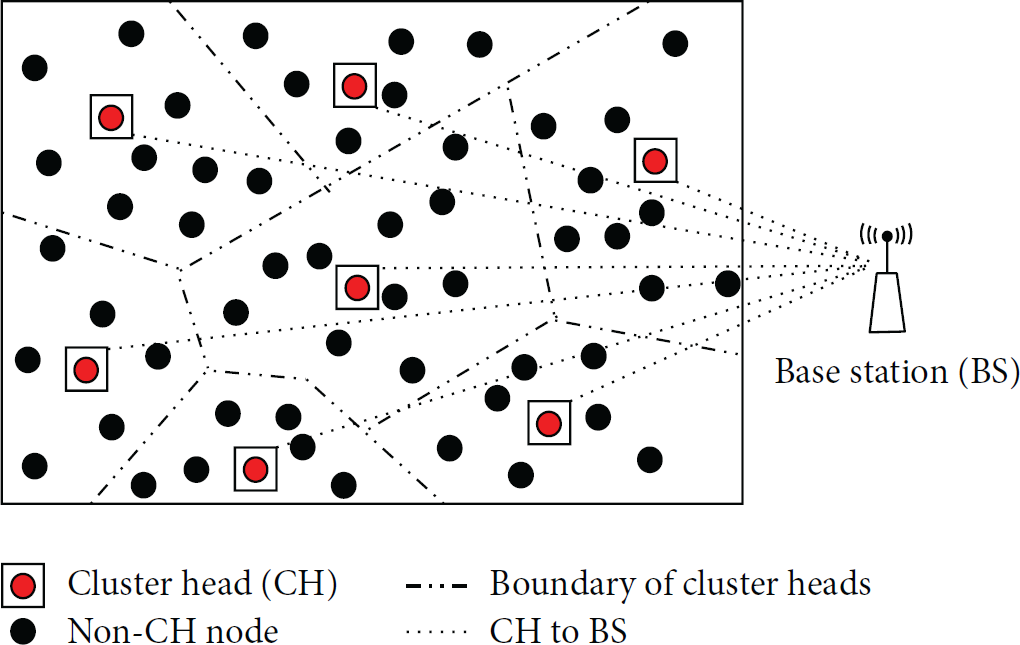
The considered WSN.
From Figure 1, we can clearly have an idea that some clusters are formed based on node geographical positions information and communication capability reachable. Here, we only consider the one-hop communications among sensor nodes. Similarly, this assumption is mainly for clear representation of our proposed method rather than a limitation of communication capability of sensors. In fact, our proposed method can easily extend to multiple hop relaying communication. Besides, in order to concisely describe our proposed anomaly detection method, a relatively small subnetwork consisted of some sensor nodes deployed densely is taken into account, which forms a cluster
For one cluster,
3.2. Spatial and Temporal (Spatiotemporal) Correlation of Sensed Dataset
For the sensed dataset in a cluster, we described the spatiotemporal correlation firstly, which will be used later to build our proposed online ensemble detection.
The collected sensor dataset from WSNs is a time series dataset. A time series is a sequence of value
To obtain the detector, the foremost requirement is to achieve a stationary time series dataset. Some data processing methods are used to eliminate data trend and obtain a stationary time series dataset such as polynomial fitting, moving averages, differencing, and double exponential smoothing [32–34]. Considering the requirement of low computational complexity, a simple and efficient nonparametric technique (i.e., first differencing) is used to eliminate the temporal trend and obtain a stationary time series for dataset collected in WSNs, which can be formulated as:
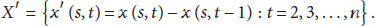
Besides, the sensor nodes are always deployed densely and the space redundancy existed. A dataset,

Consequently, for sensed data collected in a local region, two reasonable assumptions are described as follows:
The sensed data of adjacent nonfault sensor nodes are similar at the same timestamp. The sensed data of adjacent nonfault sensor nodes have the similar trend over time.
Motivated by the two assumptions and ensemble learning theory, a novel anomaly detection method is proposed in this paper. We will give the details in the following section.
3.3. Proposed Ensemble Learning Method of Anomaly Detection in WSNs
Spatiotemporal correlation exists among sensor data in a local region of WSNs, and a relatively small component, that is, a cluster, consisting of a few of sensor nodes and a cluster head node, is taken into account to clearly describe proposed distributed anomaly detection method based on ensemble learning. Ensemble pruning based on BBO was adopted to optimize the initial trained detector for mitigating the resource requirements. The optimized ensemble detector was used to identify global anomalous observations at each individual sensor timely. Our proposed method is shown as Figure 2.

Distributed ensemble anomaly detection method based on BBO pruning in WSNs.
Online anomaly detection method consists of three key procedures, that is, detector training, online detecting, and online detector updating. From Figure 2, it can be seen that our proposed method enables each distributed deployment sensor node to globally judge every new coming observation normal or anomalous in time. Distributed detecting is employed to achieve load (communication, computation, and storage) evenly in the network and to prolong the lifetime of the whole network.
The whole procedure of proposed method is described as follows.
Step 1.
Considering the temporal correlation at the certain time period, each sensor node
Step 2.
Each sensor node
Step 3.
Cluster head node received the local ensemble detectors from its member nodes and combined with its own trained detector, the initial global ensemble detector is built.
Step 4.
The BBO method is introduced in the cluster head to prune the initial global ensemble detector and to obtain an acceptable final ensemble detector.
Step 5.
The pruned ensemble detector, that is, final ensemble detector, is broadcasted to its each member sensor node for online global anomaly detection.
Step 6.
Each sensor node selectively retains the test data for online update based on the predefined sampling probability p.
Step 7.
Once the updating condition was activated, the procedure of retraining and detector updating was triggered.
This method can scale well with increase of number of nodes in WSNs due to its distributed processing nature. It has low communication requirements and does not need to transmit any actual observations between cluster head node and its member sensor node, which saves the communication resource significantly.
Next, we described some important procedures mentioned above in detail. Further, considering the context of resource constraint of each sensor node in WSNs, some tricks are designed to save the communication and memory requirements.
3.3.1. Building the Initial Ensemble Detector
An initial ensemble detector is constructed by two steps. Firstly, a number of base detectors are trained sequentially for each sensor nodes in a cluster (including the cluster head node itself) based on the history dataset. Because the data distribution may be changed over time, the previous trained detector may be useless for the future detection. Moreover, the limited memory resource in the sensor node is another constraint to store too many previous detectors. In practice, according to the space of memory resource, only the latest multiple detectors are kept to build the initial local ensemble for one sensor node. For example, to sensor node i, the sensed data is collected and divided into data chunk based on a time interval
Many techniques can be employed for combining the results of each detector to obtain the final detection result. The common used method in the literature is the majority vote (for classification problem) and weighted average (for regression problem). In our paper, the final ensemble detection result can be calculated by (3), where

3.3.2. Ensemble Pruning Based on BBO Search
To mitigate the expensive communication cost and high memory requirement induced by ensemble learning, inspired by the principle of “many could be better than all” in the ensemble learning community, the ensemble pruning is necessary.
Given an initial ensemble anomaly detector,
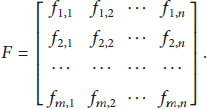
The final fitness function can be defined as
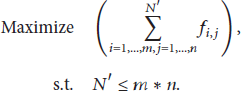
Here, the problem of ensemble pruning is to find the subset of
BBO is a population-based, global optimization method, which has some common characteristics similar to the existing evolutionary algorithms (EAs) such as genetic algorithm (GA), particle swarm optimization (PSO), and ant colony optimization (ACO). When it was used to search the solution domain and obtain an optimal/suboptimal solution, some operators were employed to share information among solutions, which makes BBO applicable to many problems that GA and PSO are used. The more distinctive difference between BBO and other EAs can be seen in [27, 28].
The pseudo-code of ensemble pruning based on BBO can be described as shown in Algorithm 1 [7]. Here H indicates habit, HIS is fitness, and SIV (suitability index variable) is a solution feature.
Create a random set of habitats (populations) Compute corresponding fitness, that is, HSI values; While (!T) Compute immigration rate λ and emigration rate u for each habitat based on HSI; / Select If Select If Randomly select a SIV form Replace a random SIV in End if End if / Select an SIV in If Replace End if Re-compute HSI values; T = T − 1; End while Get the final ensemble of anomaly detector
3.3.3. Some Tricks Designed to Mitigate the Communication Requirement
In the WSNs, the main reason of quick energy depletion is the radio communication among the sensor nodes. It has been known that the cost of communication of one bit equals the cost of processing thousands of bits in sensors [35]. This means that the most energy in sensor node is consumed by radio communication rather than collecting or processing data. Consequently, reducing the communication quantity will decrease the power resource requirement and eventually lengthen the lifetime of the whole WSNs.
It is obvious that the aforementioned method has relative high communication overhead. Each sensor node transmits its local ensemble detector to the cluster head and the final pruned global ensemble detector broadcasts back to its each member sensor nodes. In order to relieve communication burden, some skills are used to descend the communication overhead.
In fact, the distributed training/learning method only transmits the summary information of trained local ensemble detector to the cluster head which has significantly decreased the communication cost compared to centralized anomaly detection manners that sent all trained data to cluster head to build detector. Besides, after the pruned ensemble is obtained in cluster head node, each member sensor node in this cluster can obtain the pruned ensemble detector from the cluster head node. A straightforward method is broadcasting this pruned ensemble to its member sensor nodes. This is a common used strategy, but it does not make full use of local ensemble detector information and will cost more communication resources. Here, a state matrix P is designed in the cluster head; its element

After the pruned procedure is finished, the cluster head broadcasts the state matrix P to its member sensor node, each sensor node keeps the single detector, whose corresponding value of state element equals 1, and it deletes the rest to build the pruned ensemble global detector. Employing the state matrix can save the energy greatly. For example, after the ensemble pruning is finished,
3.3.4. Online Update and Relearning
Distribution change of sensed dataset occurred possibly and detector updating is necessary. Online detector update will accompany a relearning procedure. A comprised strategy (i.e., delay updating strategy [36]) can cater this situation and save the computation, communication, and memory resources to some extent. Simple to say, for the new coming observation, whether saving and using it to update the current detector or not are decided by a sample probability p. Some heuristic rules can be employed to guide its value; for example, if the dynamics is relatively stationary, the small p should be used; otherwise, the big p should be chosen. When the buffer of a sensor node is replaced by the new data completely, online update is triggered and new detector is trained. The pseudo-codes of algorithm can be described as shown in Algorithm 2.
For each sensor node Retain the new observation with probability p; If buffer is replaced completely by new observations Train new detector and transmit its summary to cluster head; Broadcast
4. Experimental and Analysis
In this section, the dataset, data preprocessing method, experiment results, and analysis are described, respectively. Experiments were conducted on a personal PC with Intel Core 2 Duo CPU, P7450@2.13 GHZ, and 4 GB memory. The operating system is Windows 7 professional. The data processing is partly on the MATLAB 2010, and the algorithm mentioned in Section 3 was implemented with Microsoft Visual C++ platform.
4.1. Dataset and Data Preprocessing
IBRL datasets [37] were used in our paper to validate proposed method, which was collected from a WSN deployed in Intel Research Laboratory at University of Berkeley and commonly used to evaluate the performance of some existing models for WSNs [35, 36, 38–41]. This network consists of 54 Mica2Dot sensor nodes; Figure 3 shows the location of each node of the deployment (node locations are shown in black hexagon with their corresponding node IDs) [35]. The whole dataset was collected from 29/02/2004 to 05/04/2004. Four types of measures data, that is, light, temperature, and humidity as well as voltage, were collected and those measurements were recorded in 31 s interval. Because these sensors were deployed inside a lab and the measurement variables had little changes over time (except the light having the sudden changes due to the irregular nature of this variable and frequent on/off operation), this dataset was considered a type of static datasets for many researchers. In our experiments, to evaluate our proposed anomaly detection algorithm, some artificial anomalies are created by randomly modifying some observations which is widely used by many researchers in the literature [41].

Sensor nodes location in the IBRL deployment.
Since our proposed method adopts the cluster structure, a cluster (consisting of 4 sensor nodes, i.e., N7, N8, N9, and N10) and dataset (collected on 29/02/2004) are chosen. The data distribution can be seen in [7]. Here, only part observations (during 00:00:00 a.m.–07:59:59 a.m.) from each sensor node are employed to evaluate proposed method. The data trend is depicted in Figure 4.

The data (temperature, humidity) trend during 0:00:00 a.m.–7:59:59 a.m. on February 29, 2004.
From Figure 4, an obvious fact is that data distribution in a cluster is almost same which well proved that spatial correlation exists. Though there are some trivial differences, after analyzing the dataset carefully, the main reason is that dataset has some missing data points largely due to packet loss which can be further proved from Figure 4. In our experiment, these missing observations can be interpolated using the method described in Section 3.3. The obvious fact is that sudden peak/valley appeared in Figure 4 for each sensor observation, which implies that an interested event may occurred.
Suppose that
Detail dataset information of selected sensor node on 29/02/2004.

T: temperature, H: humidity.
4.2. Performance Evaluation Metrics and BBO Parameters
In order to evaluate our proposed method, some commonly used performance evaluation metrics for anomaly detection are used in our paper, such as detection accuracy (ACC), true positive rate (TPR), and false positive/alarm rate (FPR). They are described as follows:
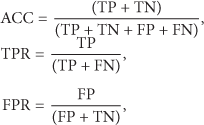
BBO is employed to prune the initial ensemble, and the migration model is same as that present in [27, 28] and the related parameters are set as follows.
Habitat (population) size
HSI (habitat suitability index) is a fitness function similar to other population-based optimization algorithms. HIS is evaluated by F-measure (F-score), which considers both the precision probability and the recall probability of binary classification problem:

F-measure can be interpreted as a weighted average of the precision and recall, and its value reaches best at 1 and worst at 0. β is a parameter used to adjust the relative importance between precision and recall,
4.3. Results Presentation and Discussions
In the data mining and machine learning communities, SVM-based method has been widely used in classification problem, which separates the data belonging to the different classes by fitting a hyperplane. One class SVM based method, as a variation of this method, is especially favored for anomaly detection [42–44]. In the paper, it was used to train the base detector. The dataset of each sensor node was divided into two parts: about 66% was used for training the local detector and the remainder as the test set was to evaluate proposed method.
Online Bagging, the commonly used ensemble strategy, was used to build initial ensemble detector. Our experiments aim to achieve two goals. Firstly, it is to prove the effectiveness of proposed method based on ensemble learning theory. Secondly, it is to prove that pruned ensemble detector can obtain better (at least equal) performance compared to initial ensemble detector and mitigate the resource requirement. As a result, three experiments were done, that is, local ensemble anomaly detector only considering the temporal correlation of each sensor node, global ensemble anomaly detector considering the spatiotemporal correlation, and the global pruned ensemble anomaly detector based on BBO. The experimental results can be seen in Tables 2, 3, and 4, respectively.
Detection performance of local ensemble detector.

Detection performance of global ensemble detector [7].

Detection performance of global ensemble detector based on BBO pruning [7].

Table 2 shows the performance of each sensor node under the different ensemble size, which does not take into account the spatial correlation of sensed data in a cluster. Though the ensemble detection performance is becoming “good” gradual with the increasing of ensemble size (the higher value of ACC, TPR, the better performance, and the lower value of FPR, the better performance), the overall performance is relatively low. The maximum value of detection accuracy is only 89.33%, and most of true positive rates are unacceptable and most of false positive rates (FPR) have a relative high value. All these results indicate that the performance of local ensemble detector is poor. Table 3 shows the global detection performance of each sensor node. Here, after the local ensemble detector was trained, each member node sent its local ensemble to each other to form the global ensemble detector and each member node used this global detector to online test the local observation. From the results of Table 3 [7], an obvious fact is that the detection performances are higher than presented in Table 2. With the help of neighbor detector, the detection results become better and better corresponding to the increasing of ensemble size.
In order to further optimize the proposed algorithm performance and save the resource, ensemble pruning is used for global ensemble detector; Table 4 [7] shows the result of detection performance of pruned global ensemble detector based on BBO.
Table 4 shows a more practicable result, and the size of global ensemble decreases sharply, while the detector performance is as good as or better than the initial global ensemble detector. From the results of Table 5, when the size of initial ensemble reaches 80, the 60% resource cost is saved. In our experiment, only for validating the method effectively, we set the ensemble sizes 5, 10, 15, and 20 for each local ensemble detector, which may be small for the practical applications. In fact, how many local ensemble detectors are chosen is an open topic and is decided by many factors such as the computation capability and the communication cost as well as memory usage of sensor node, the expected detecting accuracy requirement, and so on. In the practical application, a trade-off is commonly considered.
Rate of saving resource cost based on global ensemble detector of BBO pruned.

5. Conclusion and Future Work
After exploiting the spatiotemporal correlation existing in the sensed data of WSNs and motivated by the advantages of online ensemble learning, a distributed online ensemble anomaly detector method has been proposed. Due to the specific resource constrained in the WSNs, ensemble pruning based on BBO is employed to mitigate the high resource requirement and obtain the optimized detector that performs at least as good as the original ones. The experimental results on real dataset demonstrated that our proposed method is effective.
Because the diversity of base learners is a key factor related to the performance of ensemble learning, as a possible extension of our work, we plan to include some diversity measures in fitness function to improve the detecting performance in future. Besides, the cost of communication is the main reason of quick energy depletion of sensor nodes, especially for the cluster head, the adaptive selection of cluster head based on energy state will be taken into account to lengthen the lifetime of WSNs in next work.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This work is supported by the National Key Scientific Instrument and Equipment Development Project (2012YQ15008703), the Zhejiang Provincial Natural Science Foundation of China (LY13F020015), the Open Project of Top Key Discipline of Computer Software and Theory in Zhejiang Provincial (ZC323014100), National Science Foundation of China (61473182), Science and Technology Commission of Shanghai Municipality (11JC1404000, 14JC1402200), and Shanghai Rising-Star Program (13QA1401600).