
Abstract
With the rapid development of mobile telecommunication, voice call spam has become a growing problem in China. Many mobile phone users have become the victim of spam calls and suffered heavy financial loss. Discovering of call spammers can benefit mobile network operators as well as users. Nowadays, the popular method for the task of mining call spammers has been performed by different applications on smartphones. These applications combine manual and automatic methods to detect spammers. Although the results of these client-based solutions are quite satisfying, it is extremely unfortunate that many people still use feature phones, which can not be equipped with third party applications. In this paper, we propose a server-based solution and take a call log file as an example, to analyze the characteristics of mobile call patterns. A time-based graph model and a simple and effective call log rank (CLRank) algorithm with ranking and classification were proposed to find potential call spammers. Compared with existing methods, our model just uses link information, and thus protects user privacy to the maximum extent. Experimental results show that our proposed model can find spammers from call logs automatically, dynamically, and effectively (with 84.5~91.8% of accuracy) without any manual interventions.
1. Introduction
Voice call has become a basic and reliable service provided by mobile network operators for many years. Although it has been partly replaced by many applications on smartphones, such as LINE and WeChat, it is still the most widely used mobile communication method. With the rapid growth of mobile telecommunication, more and more people in China are equipped with mobile phones [1, 2]. However, the number of spam calls has increased dramatically (http://www.shanghaidaily.com/metro/society/Harassing-phone-calls-from-city-plague-2m/shdaily.shtml). Many users have become the victims of phone scams and suffered heavy financial loss (http://www.hollywoodreporter.com/news/chinese-actress-tang-wei-falls-670430). The content of spam calls can be classified into three categories: harassment, fraud, and illegal advertisement. The harassment calls is composed of jokes and hoaxes. The consequence is often harmless. However, the fraud and illegal advertisement calls can be very harmful. These malicious calls induce people to pay money for unwanted subscription, transfer money, and expose serious personal information. Many mobile phone users trust the content of spam calls and the response rates are high compared with traditional Email spam. It is necessary to detect potential call spammers as soon as possible.
There are two popular methods for call spam detection: the server-based solution provided by cellular network operators and the client-based third-party applications provided by software companies. Since it is huge workload to analyze call contents at the server side, in reality, the task of call spam detection is mainly performed by applications on smartphones, such as Tencent mobile manager. However in China, there are 70 percent of mobile users in rural areas who still use feature phones, which cannot install antispam software and thus have completely no protection against call spam. There are also two popular methods for call spam detection: the crowdsourcing approach and the automatic call spam filtering. In reality, the crowdsourcing approach is widely adopted by client-based applications. People can label a specified phone number as spammer by software, and then this information is sent to a server and distributed to other users as needed. However, research results have shown that almost all third-party applications do not use machine learning methods, thus the effectiveness of antispam software have been restricted [3]. The automatic method takes call log into consideration, uses a social network analysis approach and analyzes the behavior patterns of mobile users. This method has the advantage of being deployed on the server of mobile network operators. Based on the analysis above, we summarize that it is necessary to perform call spam detection at the server side automatically with minimum user information.
In this study, we try to conduct a systematic investigation of the case of finding potential call spammers from mobile call logs. Identification of call spammers can provide better mobile experience, as it protects people against malicious information senders.
The approach we take to handle call spam detection is rather different from existing relevant research.
(1) Log Information Only. Our work only uses call log information. There is no supervised information indicating which node sends call spam. However, the content-based methods use the content of the call as a judgment of ham or spam. Our method protects user privacy, while achieves good performance.
(2) Time-Dependent. The role of a node in mobile network may shift dynamically. One could turn from a call spammer to a normal node and vice versa. However, there is no clear sign when the transition happens.
(3) Server-Based Solution. Most of the existing methods utilize client-based applications. Our method can be deployed on the servers of cellular network operators and thus can provide protection for smartphones as well as feature phones.
In this paper, we formulate the problem of mining call spammers as a classification problem and propose a time-based communication graph to model the dynamic communication network. Our model partitions mobile communication stream into a series of segments, builds the time-based communication graph, then uses an algorithm with ranking and classification to detect the potential call spammers. Experimental results have shown that this unsupervised approach can achieve an accuracy of 84.5~91.8%. Our method can detect call spammer automatically, dynamically and effectively with minimum user information.
The rest of the paper is organized as follows. Section 2 discusses related work. Section 3 motivates the call spammer detection problem. Section 4 describes the proposed CLRank algorithm. Section 5 presents experimental results and compares the effectiveness of CLRank with other baseline methods. Section 6 concludes the study.
2. Related Work
In this section, we discuss several areas of related work: (1) complete manual methods which are used by cellular network operator, (2) semiautomatic content-based call spam filtering methods, and (3) automatic social network call spam filtering methods.
The most widely used methods by cellular network operator are the restriction of maximum number of calls per day. However, the restriction method taken by cellular network operator has the following disadvantages: (1) it is hard to define the threshold of number of calls per day. Some public service numbers may make a lot of phone calls in one day legally; (2) phone scam criminals can use different phone numbers to perform spam calls, while the calls of each number per day is within the threshold. The content-based call spam filtering techniques adopted by client-based applications are based on crowdsourcing and phone number blacklisting. For example, Yadav et al. propose a client-based Naïve Bayes filter for user to send feedback to a centralized server, which can further benefit other users [4]. The effectiveness of the system is largely depended on user feedback. However, many people do not send feedback in time, the effectiveness of the system is relatively low. In China, there are Tencent mobile manager and Qihoo 360 Mobile Security Solution which have similar functionalities. Social network spam detection approaches are mainly based on the fundamental technological advancement of collecting, organizing and storing network data [5–11]. Sun and Jara have proposed a series of models to organize network data, including a two-layered data management model to organize the data in Internet of Things [8], an event-linked network (ELN) model for the organization of big sensing data [9], an approach to extract events and their internal links from large scale data leveraging predefined event schemas in the Web of Things [10] and a synergetic mechanism for digital library to provide information service in the mobile and cloud computing environment [11]. The differences between content-based and social network approach are: (1) the aim of content-based approach is to predict whether a specified number is a spam or not; (2) the social network approach always generates a directed graph from logs, then use algorithms to analyze the behavior of mobile users. Xu et al. used static, temporal and network features and the SVM and KNN algorithms to deal with the spammer classification problem [12]. However, it does not take temporal information into classification process. Balasubramaniyan et al. have proposed CallRank algorithm to deal with spam detection [13]. CallRank computes global reputation by Eigentrust algorithm in P2P networks [14]. However, the effectiveness of CallRank is unconvincing since the experiments are performed on the simulation data of VoIP system.
There are also some detection techniques to deal with Email spam which might facilitate the call spam detection. In [15], Ramachandran et al. used an algorithm based on eigencluster, which has been proposed by Cheng et al. [16] to detect Email spam. The algorithm has two phases: a divide phase and a merge phase. For the divide phase, the algorithm takes data with pair similarities as input, and then uses an efficient implementation of the spectral algorithm to recursively partition data into two disjoint parts. However, the performance of the algorithm is not stable since the time and space requirement of the algorithm is depended on the balancing of the partition process. Lam and Yeung [6] proposed 7 features for Email spam detection and then used the similarity weighted k-NN method to detect Email spam. The weights of the seven features are specified by user, and the effectiveness of the algorithm largely depends on user experience.
3. Problem Formulation
In this section, we present the problem formulation and define notations used throughout the paper.
3.1. Basic Concepts
In general, our study takes a call log file F as input, where F is composed of 4 fields: user, other, direction, and timestamp. The user field denotes the phone number of the specified user at observation, and the other field stands for the identification of the other user on the communication. The direction field represents the direction of the communication, incoming and outgoing. If it is incoming, the call is from other to user; otherwise, if it is outgoing, the call is from user to other. The timestamp field defines the time of communication. A call log file usually has another field named duration, which we do not take into consideration in our CLRank algorithm.
The original call log file F can be transformed into a call log stream. Here, we present the definitions of call log stream and call log stream segment.
Definition 1 (call log stream).
A call log stream G is a series of directed graphs
Definition 2 (call log stream segment).
The series of static graphs between time interval [
The relations between two nodes
Definition 3 (callee).
Node
According to the definition, Callees represents the relationship of the incoming links of a node. We denote the set
Definition 4 (caller).
Node
Callers represent the relationship of the outgoing links of a node. We denote the set
Definition 5 (mutual friend).
Node
Mutual friend represents the relationship of two users calling each other. Let
Definition 6 (stranger).
Node
Here, we propose our naïve solution of call spam detection. We propose two indexes named reputation and reciprocity to help to determine whether a node is a spammer. The definitions of reputation and reciprocity are motivated by the following observations.
A certified mobile user tends to have a lot of mutual friends, which means a user should make and also receive calls in a specified time interval. The call pattern of a certified user is usually bidirectional. A spammer wants to quickly spread information to victims by communicating with many users intensively. These accounts have many outgoing links, while the number of incoming links is relatively small. The call pattern of a spammer is largely unidirectional. A spammer tends to have few mutual friends. There is a wide gap between the number of calls made and received by a spammer. Although call spam accounts have sent huge quantities of messages, only a small fraction of recipients will reply in a specified interval.
Definition 7 (reputation).
The reputation of node

From Definition 7 we can observe that if the numbers of the callees is much smaller than the amount of callers, the reputation is close to zero,
Definition 8 (reciprocity).
The reciprocity of node
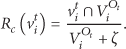
3.2. PageRank and HITS Algorithms
PageRank computes a score for each web page by link analysis. It is motivated by the observation that a hyperlink from one web page to another is an authority transformation to the destination page. Given a page p with inlinks

Hubs and Authorities (HITS) filters search results for a specified topic [17]. Most of the web pages for searching a topic are of two types: authorities and hubs. The authority is a web page with good, authoritative content on a specific topic, and the hub is a web page pointing to many authoritative web pages. Given a topic, HITS first finds a subset of the web pages. The subset should have the characteristics of being small, consisting of pages relevant to the given query and containing most of the authoritative pages. The subset of the web pages is obtained by analyzing the connection of a root set of nodes. The root set contains the top k search results of the given query from a search engine. Then two scores, a hub score and an authority score are assigned to each node of the subset of web pages. The scores can be computed by an iterative algorithm.
4. Approach
In this section, we propose a two-stage framework and present the approach for each stage. The first stage uses a ranking algorithm CLRank; the second stage classifies the results. Temporal information is taken into consideration in both stages.
4.1. Preprocessing
The purpose of preprocessing is to generate mobile social network from call logs. First, the input of call log stream is partitioned into many call log stream segments. The logs can be represented as a
The strategy of assigning different weights to different edges by timestamp may improve the performance of our algorithm. Here, we omit this step for simplicity. The length of the call log stream segment is 5 days in our settings.
4.2. CLRank
The goal of CLRank is to assign a rank to each mobile node in call log stream segment and to use this value (1) to decide whether each caller is a spam or not and (2) to rank nonspam nodes.
CLRank is composed of two steps:
select a seed set of nodes with high reputation in the call log social network; apply CLRank algorithm to the call log graph to compute the final score based on the seed set in procedure 1.
Since the final CLRank scores are based on the seed set in step 1, it is very important for seed node selection in procedure 1 to exclude spammers. In reality, there are three methods to obtain the seed set. A manual method which requires the selection process is processed by human. However, it is very time-consuming and human tend to make mistakes. An automatic method means to use seed selection algorithms to obtain the seed set. This method has the advantage of high efficiency. However, the effectiveness of selection algorithm is critical. A semiautomatic method is composed of two steps: first, the algorithm uses an automatic method to obtain an intermediate result; then the final seed set is determined by human. In this paper, we use a semiautomatic method to compute the seed set.
Suppose the whole rank value in the given call log graph is ω, our seed selection algorithm adds the highest rank of the nodes
The CLRank algorithm is presented in Algorithm 1.
Input: t: a specified time interval λ: seed set λ obtained by semi-automatic method α: decay factor. ε: precision threshold Output: Variables: s: vector of scores σ: error between s and Algorithm: (1) For Each node (2) If (3) For Each connection from (4) (5) Else For Each node (6) (7) Let (8) Initialize s = (9) While (10) (11) (12) return
CLRank computes vector A spammer node, if the score is larger than A normal node, if the score is less than An undefined node, if the node is not in the call log graph.
Since the behavior patterns of spammer might vary from time to time, CLRank should recalculate
4.3. CLRank System Architecture
CLRank can be deployed on the server of mobile network operator. The server uses call logs from all mobile users to perform CLRank algorithm and utilizes the results to detect spammers. The results of CLRank algorithm are assigned with a time to live field to record its lifetime. After the specified lifetime, the server runs the CLRank algorithm again so it can detect nodes which behave normal for some time, and after that, it performs malicious behavior. If a phone number is recognized as a spammer, the system blocks the communication of the phone number for some time. The system might also send voice prompt to the user to explain the reasons of blockage. There is no need to install software on mobile phone; thus, our algorithm can provide protection for smartphones as well as feature phones.
5. Experimental Evaluation
In this section, we evaluate the effectiveness of CLRank algorithm. We describe experimental data and environment in Section 5.1. We present results for our real dataset in Section 5.2. We briefly discuss the effects of parameter values in Section 5.3.
5.1. Experimental Setting
We use real mobile call data set to perform experimental evaluation. Our data set is composed of call logs from city C (The name of the city is not provided as requested by the data provider) collected by a mobile network operator in China. The dataset covers over 10 million people and includes mobile call records of 30 days. It contains rich information, such as related cell tower during phone call. The positional accuracy of cell tower data is within 300–500 m. Unlike MIT Reality dataset or Nokia mobile dataset, our dataset does not provide GPS or WLAN data. We extract 4 fields from elementary data for experiments: user, other, direction, and timestamp. Table 1 presents a sample record. The information has been preprocessed for privacy issues.
A sample record from city C.

CLRank could compute ranking scores of nodes which reflect the sending patterns in a specified interval. We build a call spam classifier by constructing
5.2. Accuracy Evaluation
The accuracy evaluation results of 6 time intervals are displayed in Figure 1.
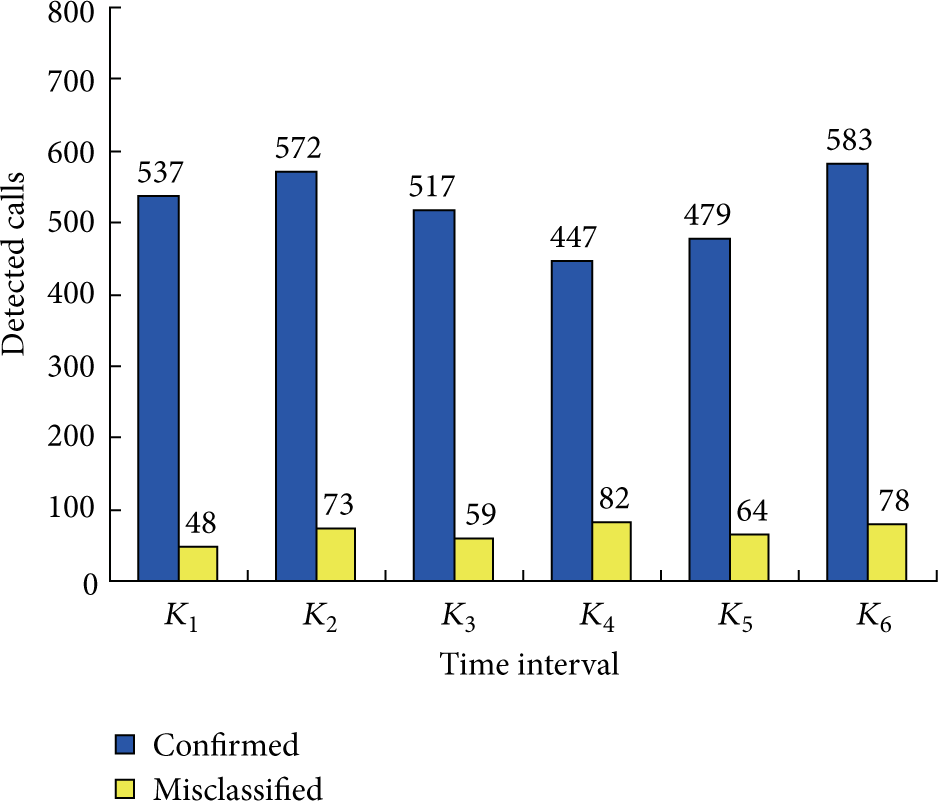
Accuracy evaluation of CLRank.
Figure 1 shows the correctly classified and misclassified spam numbers by CLRank. The accuracy of CLRank is 84.5~91.8%. The results of CLRank have been affected by the sparsity of
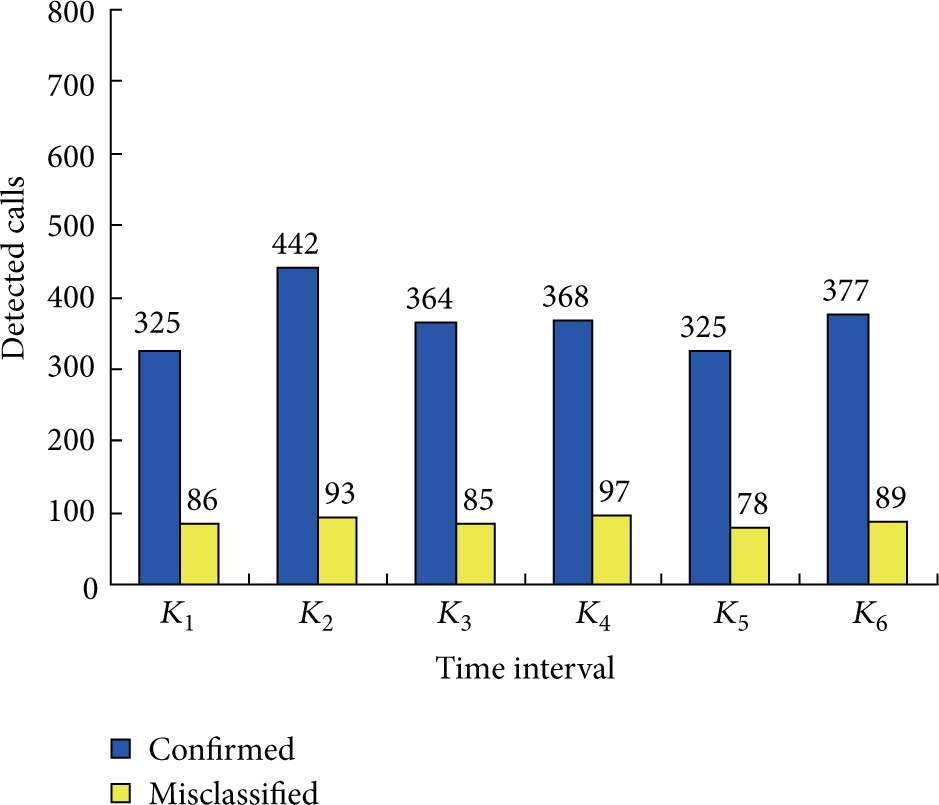
It is very difficult for us to determine the values of reputation and reciprocity while analyzing call spam by our naïve solution. We have tried different parameter values and selected the parameters which lead to high confirmed and low misclassified values. Figure 2 shows the results by our Naïve solutions with the optimal parameter values (

Accuracy evaluation of naïve solution.
5.3. CLRank versus Other Ranking Algorithms
PageRank is a classical algorithm for web spam detection. Figure 3 shows the correctly classified and misclassified spam numbers on the same dataset by PageRank. The accuracy of PageRank is 79.1~82.6%. The number of correctly classified calls is lower than CLRank while the number of misclassified calls is higher and thus results in lower detection rate. The reason of this phenomenon is that the PageRank algorithm does not have high reputation node selection process. It is possible that some disguised spammers receive high PageRank scores.
Accuracy evaluation of PageRank.
Now we introduce the concept of demotion [19]. Here, it denotes the set of nodes which receive high scores from PageRank while receive low scores from CLRank. The demotion reflects the effectiveness of CLRank to cut down the influence of spams. Figure 4 shows the demotion in CLRank. The vertical axis of Figure 4 shows the number of nodes which receive high scores from PageRank got demoted in TrustRank. Blue bars represent spam. Yellow bars denote the reputable nodes. We point out that CLRank detects most of the spams from top-scored users effectively, and the result of reputable ones detected by CLRank is quite stable. CLRank ensures that top-scored users are reputable users.
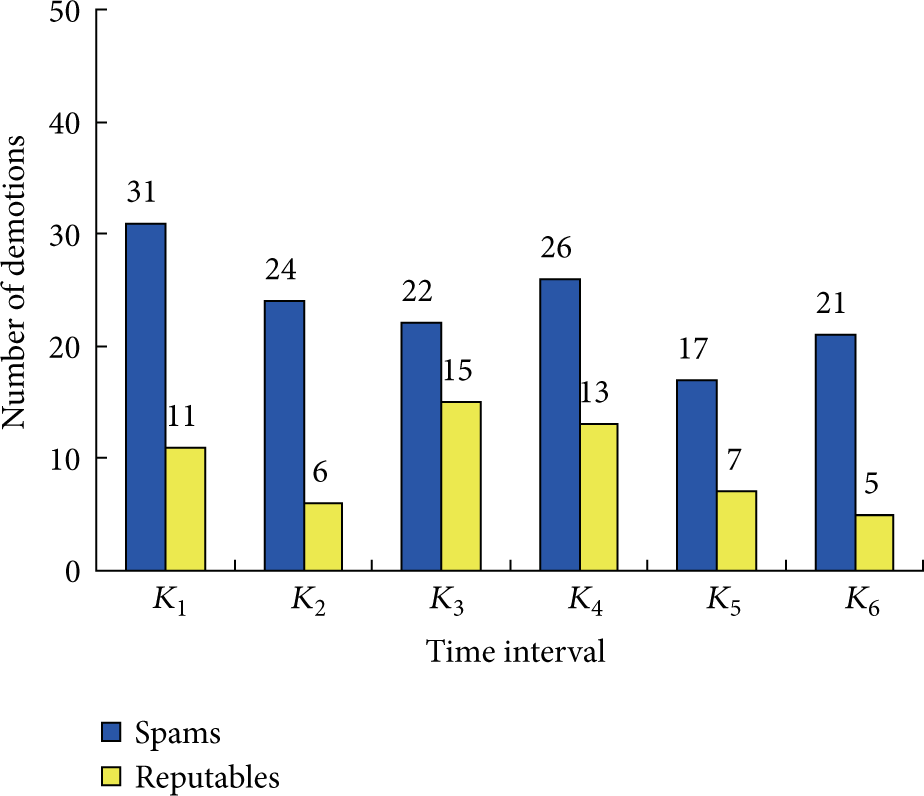
Demotion in CLRank.
CallRank is a social network ranking algorithm for combating spam over internet telephony by call duration and global reputation. Figure 5 shows the number of correctly classified and misclassified spammers on the same dataset by CallRank. The accuracy of CallRank is 83.3~89.4%. The results are better than PageRank, and are better than CLRank in
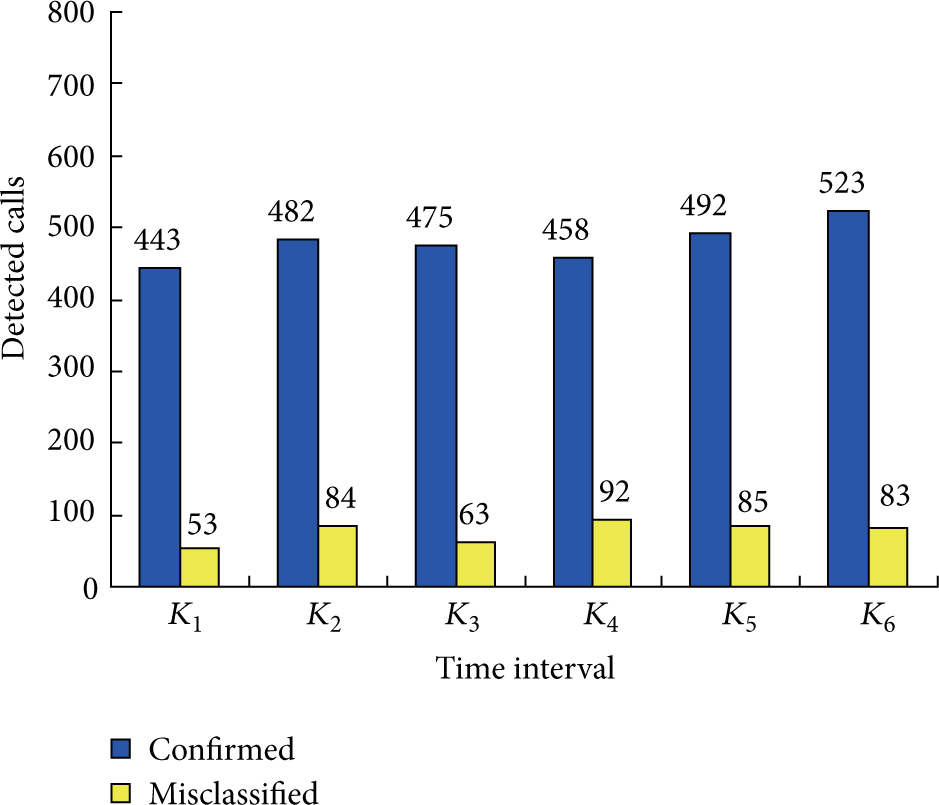
Accuracy evaluation of CallRank.
5.4. Effects of Parameter Values
We have tested the effects of parameter values on the results of CLRank. If we set parameter
6. Discussion and Conclusions
6.1. Discussion
We discuss some possible extensions of our CLRank algorithm.
(1) Accuracy. We can assign different weights to different edges when collapsing time axis during the second step of preprocessing. The weight can be determined by timestamp and the duration of the call. This extension will improve the accuracy of our algorithm.
(2) Efficiency. We can design and implement our solution by parallel technology. A number of platforms, for example, Apache Hadoop, have been developed for this purpose in the context of big data. We are applying these techniques to mobile data and implementing faster algorithms.
6.2. Conclusion
In this paper, we have proposed a server-based solution for detecting spammers automatically. Our algorithm takes a call log file as an example, to analyze the characteristics of call logs and discover the potential call spammers. A time-based graph model and a simple and effective algorithm CLRank with ranking and classification were proposed to find potential spammers. The detection process of CLRank can be performed on the server of mobile network operator, without any involvement of users. To show the effectiveness of CLRank, we have performed experiments on a real data set provided by a Chinese mobile network operator. Experimental results show that our proposed model can find spammers from call logs effectively (with 84.5~91.8% of accuracy) without any manual interventions.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This research is sponsored by The National Natural Science Foundation of China Civil Aviation joint Fund (Grant no. U1433116), the Fundamental Research Funds for the Central Universities (NZ2013306), the 333 Project of Jiangsu Province and the Technology Foundation (JSJC2013605C009).