
Abstract
With continuous queries that are used widely in location based mobile social networking services, how to protect the location privacy effectively for continuous query has been a hot topic for researchers. In this paper, we analyze the existing location privacy protection systems and algorithms for location based services; considering their disadvantages of slow responding time and high anonymization costs, we propose a new enhanced greedy cloaking algorithm which predicts a cloaking area at the initial query to be the cloaking region in the whole query lifetime by the comprehensive computation of privacy monitor, quality monitor, and dynamic adjuster. Privacy monitor and quality monitor charge the privacy protection level and service quality degree respectively; dynamic adjuster can adjust the cycle center point dynamically. We employ cycle as cloaking region form which can effectively alleviate the computation overhead. And we compare it with the earlier algorithm on three aspects. The experimental result shows that the enhanced greedy cloaking algorithm is better than the original greedy algorithm on average responding time or anonymization cost.
1. Introduction
With the rapid development of location based mobile social networking services (LBMSS) [1, 2], location information has been a key factor for improving the quality of location based mobile social networking services. However, when users enjoy the convenience and efficiency of LBMSS, the location privacy leakage problems have become more and more serious than before. For example, Loopt [3] is a popular mobile social networking application which can create a map on the phone that will locate users' friend's residences and where they have visited; when users want to maintain the social talks with their nearest friends, they have to contentiously query the friends' locations. The adversary can infer the privacy of these people from the query content history and the people's location history. Although there are some mature measures such as K-anonymity scheme [4–6] to solve it, most of them resolve the snapshot query that the content of any two consecutive queries from one user is uncorrelated. But in the mobile social networks users often need to repeat queries on a certain content during a time. For instance, in the mobile social navigation application WAZE [7], the road traffic information is gathered by reports from all users based on their current positions. When users report the road traffic situation based on their current locations, they probably need to continuously query the latitude and longitude of current location to report the road situation on continuous time. We call this kind of queries as continuous query. Directly applying the privacy protection algorithms for snapshot query to continuous query would cause some problems; the bad guys can infer the users' exact positions according to some contextual knowledge [8, 9]. As an example, a common traditional location protection method for snapshot query is that replacing users' location position with a space region which consists of k users who request queries in the same time period. However, for continuous query, if the above method is employed, there will be many consecutive space regions at different time which probably have intersections with each other, and the intersection part may be used to infer the users' location. Later on, some researchers [10–12] proposed schemes that a region is generated at first query to be the cloaked region in the whole life cycle of continuous queries. Thus there is no need to worry about intersection inference problems. Yet, how to select the first cloaked region and how to prevent the mobile users of continuous queries from converging to one point or be too dispersive have been a new research problem to be solved.
2. Background
Traditional privacy protection algorithms such as k-anonymity (replace one query user's location with a region consisting of at least k users) are mainly for snapshot query that a user issues one query on each interest point. Each query is uncorrelated with others. But in physical world, continuous query is more common than snapshot query such as GPS navigation for the users' nearest friend in a time period. When users who request queries are moving, the adversaries can collect the different cloaked regions to infer the users' exact location or movement route.
Here we give the details of some typical location privacy inference problems.
2.1. Cloaked Regions Intersection Problem
Cloaked regions intersection problem is that the adversary may infer the user's exact location without having the user's any contextual knowledge. The adversary gets the consecutive cloaked regions to calculate the intersection part from these regions to understand the exact location of the user.
When a user send a continuous query to the location anonymizer (A server who charging anonymizing users queries is called as an anonymizer), the anonymizer will generate consecutive different cloaked regions for one query. The adversary can explore the cloaked regions to find out the user's location. An example is presented in Figure 1.

Privacy explore of continuous query.
In Figure 1, mobile user A issues a 3-anonymity continuous query, which generates three different cloaked regions on three consecutive time points. Figure 1(a) shows the cloaked region a on
2.2. Privacy Inference Problems Based on Contextual Knowledge
Commonly location data in location based mobile social networking services consists of users' coordinates {longitude, latitude}, velocity, and direction. We called these data users' contextual information. If one or some items are known by the adversary, he can easily infer the users' sensitive privacy. Figure 2 shows how the privacy is inferred when mobile users' direction and velocity are known by the adversary.
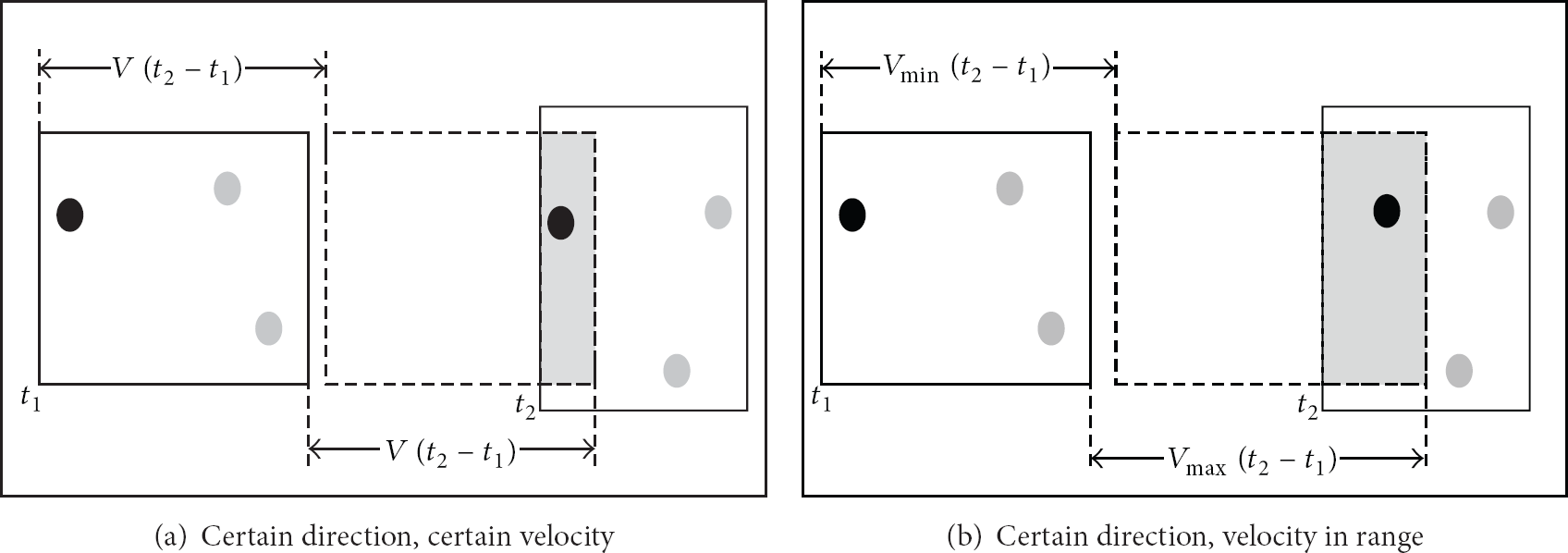
Privacy leakage on a certain direction and velocity.
As shown in Figure 2(a), the black solid point is a user issuing queries; gray solid points are other mobile users. Three-anonymity cloaked region is generated like the black rectangle at
As shown in Figure 3(a), the direction of mobile user is unknown but a range of angle
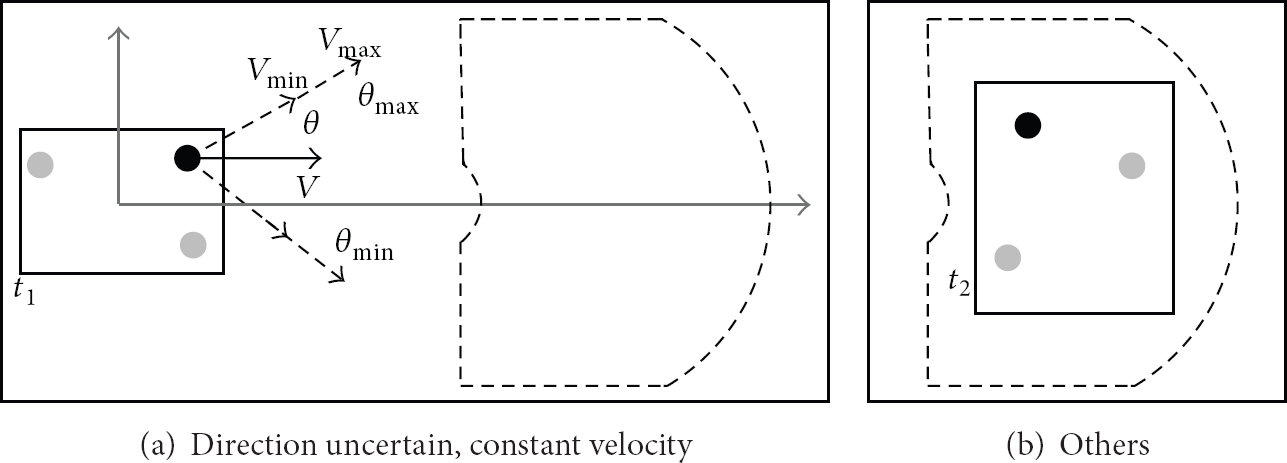
Uncertain direction privacy leakage and others.
According to the above analysis, we can find that the capability to protect the privacy of continuous query is very limited. The adversary can analyze the users' independent cloaked regions or some other background knowledge, and then users' privacy may be inferred and exposed. Therefore, we need to research on new advanced privacy preserving scheme for continuous query of location based social networking services.
For the privacy protection of continuous query, some researchers have proposed some schemes. Chow et al. [11, 12] proposed a scheme that the users included in the initial cloaked area will last in the whole query life cycle; in other words, it is that the cloaked region selected at the first should also works at the end of the continuous queries. As shown in Figure 4.

Anonymous users are effective in the whole life cycle.
User A sends a 3-anonymity query, at initial time

Cloaking multifactors.
Continuous query is one of the most common query types for location based services; however, current methods for protecting the privacy of continuous query are few and cost too much computation. Therefore, we study it and propose a new scheme to reduce computation of the estimation of the users' future location in order to alleviate pressure of anonymizer servers.
3. Enhanced Greedy Algorithm Scheme
In our scheme, we adopt greedy algorithm as the basic idea and improve it by changing cloaked region form and adding adjustment algorithm; at the same time, we improved privacy and quality models to let them suit the new situation. The major notations are shown in Notations section.
3.1. Definitions
Assumption: we assume that one user only sends one query at a certain time; in other words, one query at a certain time is responding to a certain user.
Here we give some formal definitions.
Definition 1.
In query Q, define each query from users as Q, and Q is a quintuple:

Currently most of cloaking regions are represented as rectangles, marked as the coordinate of left-bottom corner and top-right corner. In our scheme, we pick cycle as cloaking region forms which is represented by center coordinate of the cycle and radius, and the definition is as follows.
Definition 2 (cloaked cycle CS (cloaked cycle)).
Each cloaked region represented by CS is a spatial-temporal area which includes at least k users:

As shown in Figure 6(a), the rectangle represents the whole system, points represent the users who request query, dashed cycles represent cloaked cycle, the black points inside the cloaked cycle represent k anonymity users, and the gray points outside the cycle represent the mobile users around. Suppose mobile users U6 request 3-anonymity query; then the dash cycle is the qualified cloaked cycle.

Cloaking cycle and distance cycle.
Definition 3 (distance cycle).
We define the cycle formed by the distance from the query users to other users at some time as the distance cycle from query user to some certain user:
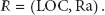
Definition 4 (cloaking angle (CA)).
Cloaking angle is the inclined angle between coordinate x and the beveled edge of triangle formed by Ra's area and radius of the cloaking cycle:


Cloaking angle CA.
From Figure 7,
3.2. Cloaking Model
We improved cloaking model by privacy monitor, quality monitor, and dynamic adjuster.
Privacy monitor guarantees that, in the whole query life cycle, any two queries in the cloaked region cannot gather to one point.
Definition 5 (privacy monitor α).
Suppose CS is a cloaked cycle including k queries
Quality monitor mainly prevents the queries of the mobile users from getting too scattered; therefore, we need to forecast the furthest possible location according to the biggest velocity.
Definition 6 (quality monitor β).
Suppose S is a query user, Q is an outside user,

3.3. Enhanced Greedy Cloaking Scheme
The main idea of enhanced greedy cloaking algorithm (EGCA) is that when mobile users request location based services, they send anonymization query requests to anonymizer, the server checks each unexpired queries from candidate cloaking set QS one by one after receiving the query request s and judges whether the anonymized queries (anonymized s and QS) satisfy quality monitor model, if yes, then it inserts s into QS, if not, it finds the next query and repeats the process until all queries of QS are checked (Algorithm 1). Then the server compares the numbers of QS with the users' anonymity requirement k; if they are bigger, then it forms a cloaked cycle and judges whether they satisfy privacy monitor model, if yes, then it calls the center position adapting function to adjust the position of the cloaked cycle center, if not or the queries number is smaller than k, then it inserts s into QS.
/*When user issues a query candidate cloaking set U = insert s to U; for (each q in QS) { if (s· get the next q in QS; else { if IsMeetQ( { inset q to U; if { if (IsMeetP(U)) then { Generate CS; CenterAdj(CS); Return CS; } } } } inert s to QS; }
The details are as follows.
We can divide the algorithms into 4 parts: improved greedy algorithm, quality monitor model, privacy monitor model, and center adjustment algorithm (Algorithm 4).
In order to make sure that the cloaked region will not be too scattered to affect the service quality and efficiency in the query life cycle, we adopt quality monitor algorithm to avoid the above problem by predicting all possible locations of the querier according to the most biggest velocities at the initial time; thus qualified and appropriate queriers will be selected to be anonymized while unqualified ones will not be selected, as shown in Figure 8(a).
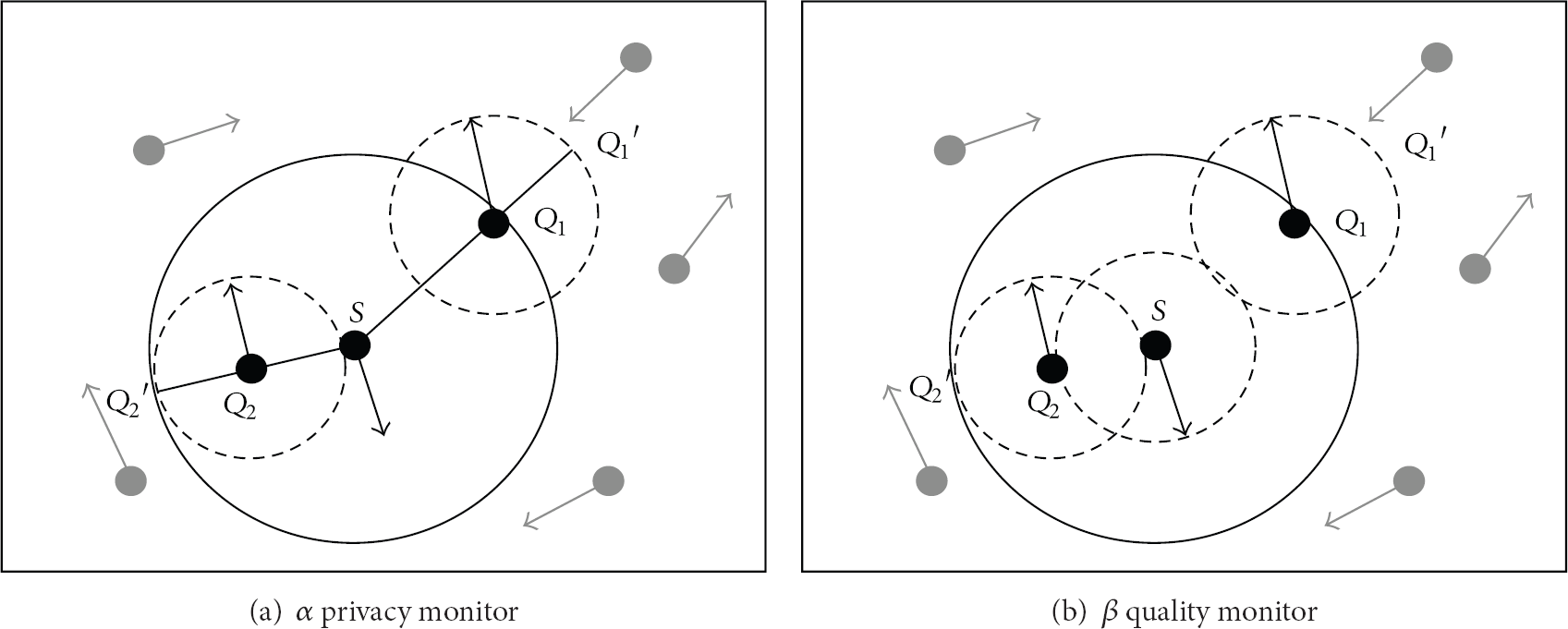
Privacy monitor and quality monitor.
For the query shown in Figure 8(a), the arrow represents the possible biggest velocity of the queriers and the dashed cycle represents all possible positions of the queriers in the whole query life cycle. In the graph, suppose s is a querier who issues 2-anonymity request;
/*judge whether the querier q satisfies quality monitor requirement*/ Function (Query const PI = 3.1415926 { double distance = 0; distance = the length from s to the center of cycle q distance += the length from s to the center of cycle If return true else return false; }
Algorithm 2 prevents the queriers from getting too dispersive at the initial time, while for the problem where queriers might converge to one point, we have to solve it after k queriers are selected. To solve the problem, we propose another algorithm privacy monitor β (Algorithm 3), a conservative way, and calculate all the possible future positions of each querier in the cloaked cycle and build equation set EQ of possible future position of each querier to judge whether there is solution of
Function (CS cs) { Define EQ[cs·QS·count]; double for (each q in cs·QS) push for (equation Group in EQ) if (have solution of equation Group) then return false else return true; }
Function (CS cs, Query s) { For (each q in cs·QS) { if ( if ( if ( if ( } x = Random( y = Random( if ( Cs·x += x else cs·x −= x; if ( else cs·y −= y; Return cs; }
Since we adopt cycle as cloaked region, the center is the querier location. In order to avoid the adversaries computing the center position of the cloaked cycle, we need to adjust the cycle center. The main idea of adjustment is to generate two random numbers according to the positions inside the cycle, as shown in Figure 9.

Center adjustment.
The main objective of the algorithm is to move the center position of the cycle while the size of the cycle is unchanged. It can effectively prevent the adversaries from calculating the center position of the cloaked cycle to identify the position.
4. Evaluation
We simulated mobile users and generated their location data by Brinkhoff Generator [15]. Input data is the city network map of OldenburGen, output is location data of mobile users' query which is stored in Oracle 10 g database, and the algorithms are coded by Java. We mainly analyze the feasibility and effectivity of the algorithms from three aspects: average responding time, average anonymization cost, and anonymization success rate.
4.1. Simulator Configuration (Brinkhoff Generator)
In our experiment, we select Brinkhoff generator as the simulator which can simulate mobile objects for city roads; it has two basic city road maps, OldenburgGen and Sanfrancisco. We adopt OldenburgGen city network map, which includes 6105 nodes and 7035 edges, the generated data is stored in Oracle 10 g database, the algorithms are coded by JAVA, and the configuration of simulation computer is CPU: Intel i3 3.20 GHz 3.20 GHz, Mem: 2 G.
Brinkhoff generator input parameters are shown in Table 1.
Configuration of simulator.

After configuration Brinkhoff generator is running to generate mobile users and outside objects' location data. Figure 10 shows the 395th time stamp graph after running Brinkhoff generator.

The 395th time stamp of mobile objects.
263434 records have been generated in table moving objects, and 12078 records have been generated in table external objects. The parameters for the algorithms are configured, as shown in Table 2.
Input parameters of moving objects.

4.2. Simulation Analysis
We compare our algorithm EGCA with the original one GCA from the average responding time, average anonymity cost, and anonymity successful rate.
4.3. Average Responding Time
Average responding time is the average time cost from that each query is send out until the cloaked region is received. Here it only calculates the successful anonymized queries. The time comparison of average responding time is shown in Figure 11.
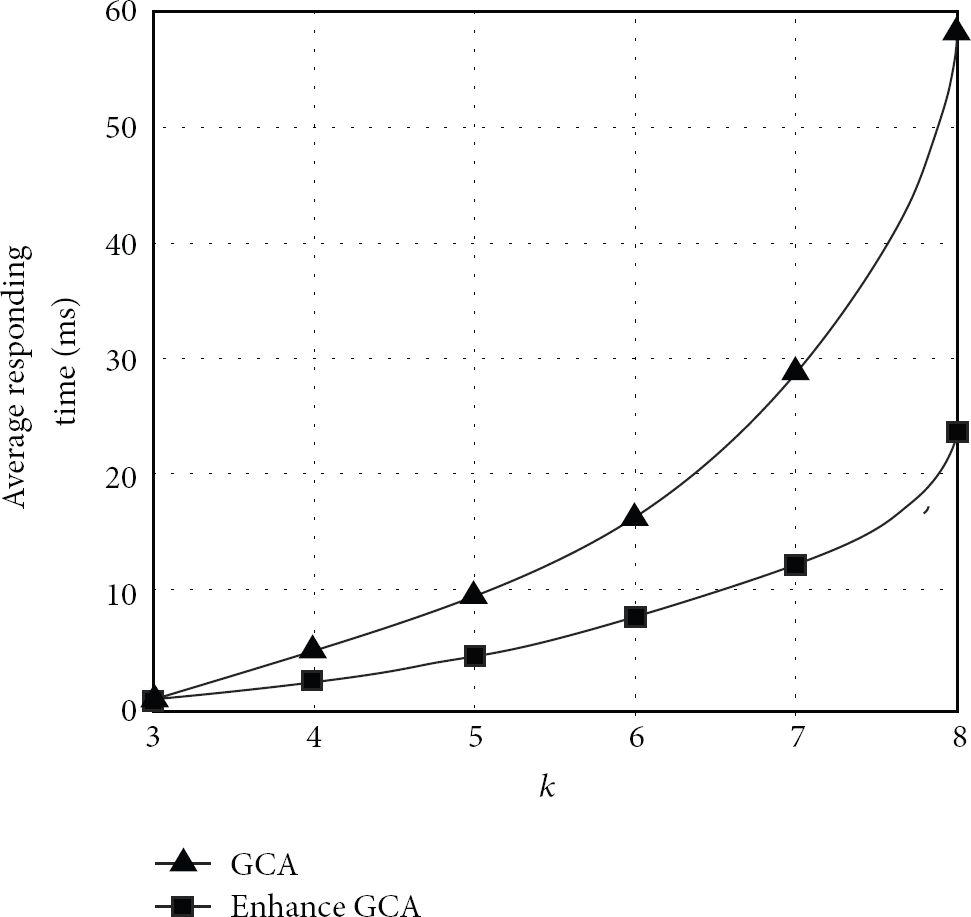
Average responding time.
From Figure 11, the average responding time varies with the degree k of anonymity. If k is bigger, the average responding time is longer and rise of freight rate, in that with k becomes bigger, more mobile queries need to be solved. It needs more compuatation to get the distance cycles, thus it alleviates the anonymizer and responding time is longer. In the figure, the average responding time of ECGA is less than CGA, in which ECGA predicts all possible positions of the mobile queries which satisfy quality monitor and privacy monitor requirement at the initial time. Thus in the whole query life cycle, each query moving position is in a certain area. When anonymizer generates cloaked cycle, it only needs to update the current position of each query. While CGA needs to check the border of rectangle cloaked region and calculate the space anonymizing degree of each query by definite integration, besides, it needs to check the length and width of rectangle for quality model and solve the set of two equations; however, ECGA only needs to check whether the regions of all the possible positions of the query inside the cloaked region have intersection that only needs to solve one equation set. Therefore, the average responding time of ECGA is less than CGA.
4.4. Average Anonymization Costs
Average anonymization costs represent the costs that the anonymizer solves the query requests after the requests are sent out. In CGA, the average anonymization costs are defined as the average perimeters of the cloaked rectangle in the query life cycle, when the average perimeter is bigger, then the cost is higher. While the average anonymization costs in ECGA is defined as the average perimeter of cloaked cycle in the query life cycle, Figure 12 shows the comparison.

Average anonymization costs.
For Figure 12, the average anonymity cost of both algorithms rises with the increasing of k. In the figure, we can find that two curves are intersectant; before the intersection point, average anonymization costs of ECGA is higher than CGA, while after the intersection point, ECGA is lower in average anonymization costs. In both algorithms we use average perimeter to calculate the average anonymization costs, while both perimeters and diameters are decided by two furthest queries along coordinates x and y, which means that when the region perimeter is 6.28R (R is half of the distance between two furthest queries), both perimeters are identical. When the region perimeter is smaller than 6.28R, the average anonymization costs of ECGA are higher, and when the perimeter is bigger than 6.28R, costs are lower than CGA.
4.5. Anonymization Success Rate
Anonymization success rate means the ratio of the number of queries which return cloaked cycle with the numbers of all request queries. It reflects the feasibility of algorithm. Figure 13 gives a comparison columnar graph of the anonymization success rate of ECGA and GCA and the anonymity degree k is from 3 to 8.

Anonymization success rate.
As shown in Figure 13, the success rate of EGCA anonymization is equal or a little higher than GCA when k is relatively small. When k becomes bigger, the success rate of EGCA anonymization is a littel lower than GCA. When EGCA searches the qualified mobile queries, the quality monitor is defined to be relative fixed in strict way while GCA is changing. When k is small, the qualified queries are relatively few; when k is big, the fixed condition limits some mobile queries, so the success rate starts to decline and becomes lower than GCA. However, from the simulation, even k is 10, the success rate is still above 90%, and thus it is acceptable for practice in real application.
5. Conclusion
In this paper, we analyze the existing location privacy protection systems and algorithms for location based services, considering their disadvantages of slow responding time and high anonymization costs; we propose a new enhanced greedy cloaking algorithm which predicts a cloaking area at the initial query to be the cloaking region in the whole query lifetime by comprehensive control of privacy monitor, quality monitor, and dynamic adjuster. Privacy monitor and quality monitor charge the privacy protection level and service quality degree, respectively; dynamic adjuster can adjust the cycle center point dynamically. We employ cycle as cloaking region form which it can effectively alleviate the computation overhead. And we compare it with the earlier algorithm on three aspects. The experiment result shows that the enhanced greedy cloaking algorithm is better than the original greedy algorithm on average responding time or anonymization cost.
Footnotes
Notations
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgments
This research was supported by the National Natural Science Foundation of China (no. 61100192) and Research Fund for the Doctoral Program of Higher Education of China (no. 20112302120074) and was partially supported by Shenzhen Strategic Emerging Industry Development Foundation (nos. JCYJ20120613151032592 and ZDSY20120613125016389), National Key Technology R&D Program of MOST China under Grant no. 2012BAK17B08, and the National Commonweal Technology R&D Program of AQSIQ China under Grant no. 201310087. The authors thank the reviewers for their comments.