
Abstract
Cognitive radio (CR) is an efficient way to increase spectrum efficiency for the small low earth orbit (LEO) satellite communication system. Due to the implementation difficulties, we focus on the CR in the uplink transmission. In CR, the cognitive medium access (CMA) is designed to enable the coexistence with the interferences from other systems. However, the CMA schemes designed for the terrestrial system cannot deal well with the global history of interferences in our system. Here, we design the memorized centroid bucket (MCB) scheme that can efficiently utilize the global history of interferences onboard without storing the complete interference samples. With MCB, we can achieve the effective long-term interference prediction to meet the special requirements of the LEO satellite. The key component in MCB is the matching algorithm that can help retrieve the useful historical information. In this paper, we propose three different matching algorithms and the corresponding MCB schemes. The schemes are also compared with the widely used Markovian method and the pair counting-based method. Among all the schemes, the Bayesian scheme MCB-FSNMI-Bayes is the best. The conclusion is validated experimentally with the real data that were collected by an LEO satellite.
1. Introduction
The low earth orbit (LEO) satellite systems, such as Iridium, have been used to provide the worldwide communication services for decades. The exclusive spectrum band over many countries is usually assigned to such systems. Recently, it is further suggested to use a small LEO satellite system to provide communications for the small-scale and short lived events [1]. Such a system usually consists of a few satellites that only cover a few regions at a time. Therefore, it is inefficient to assign the exclusive spectrum band for these systems as before. Cognitive radio (CR) [2] is an emerging technology that helps the communication system to utilize the spectrum more efficiently. It can help the small LEO satellite system find the available spectrum resource by avoiding the interferences [3].
However, CR for satellites is quite different from CR on the ground. One of the important reasons, as suggested in [3], is that CR is difficult to be implemented in satellite's downlink. It is because the satellite covers a lot of users that are remotely located. The available spectrum bands for the users could be quite different from each other due to the distinct local electromagnetic environments. So, we focus on the CR in the uplink transmission, in which the interferences can only be sensed and predicted by the satellite itself rather than the distributed terminals on the ground. The interferences are predicted in a centralized manner.
The channel characteristics of the satellite communication have been investigated for decades. The behavior of the land mobile satellite channel was characterized by a three-state Markov-chain-based model [4–7], which is well fit for the channel at the lower frequency band. For the higher frequency band, the tropospheric effect is also modeled in [8–11]. But the above models cannot be used to characterize the interference sensed by the satellite. The sensing result here is a combination of many remotely located users' signals that are transmitted on many different channels. In this paper, the sensing data are collected by the satellite at the lower bands where the local environment propagation is the main factor.
Cognitive medium access (CMA) is designed to enable the coexistence with the interferences from other systems. The method is usually designed to deal with the stochastic modeling and the prediction of the combination of different interferences. There is a CMA protocol that is proposed to model the medium access process as a constrained Markov decision process in [12]. The proposed protocol can provide a structured solution to utilize the spectrum in a proactive way. In the work, it is assumed that the interferences happen in an unslotted way. It is also assumed that the spectrum can be fully observed so that all the parallel channels can be observed simultaneously by energy detection. According to the solution, the channels are available as long as the collision rate is kept below some interference constraints. The effect of retransmission is further evaluated experimentally in [13]. There are also some other works that assume the partially observable CMA [14–17]. In this paper, the sensing data are collected by the satellite that can fully observe the spectrum, so the proposed onboard interference prediction scheme CMA is compared with the one in [12, 13].
In the works mentioned above, the receiver of CR is assumed to locate in some certain areas. Thus, the interference statics can be obtained based on the local history of interferences. Regarding the LEO satellite uplink transmission, however, the receiver is fast moving over different regions and the electromagnetic environment varies dramatically. So, an LEO satellite needs to utilize the global history of interferences rather than the local one.
The most straightforward way to utilize the global history of interferences is to build a database for different regions [18–20]. Building database is not feasible onboard for the LEO satellite, since an LEO satellite is always unable to store such huge data. Therefore, we could transmit the sensing results to the ground station and build a database there. However, this solution will bring great burden on the satellite downlink and lower the systematic reliability.
In this paper, we propose the memorized centroid bucket (MCB) schemes to achieve the long-term interference prediction by the suggested stationary spectral distribution (SSD) of interferences. The sensing results are reduced in frequency domain by clustering. Only the reduced information is stored by the system. Thus, the global history of interference can be utilized onboard, and the frequent spectrum handoff can be avoided as well. The most important module in these schemes is the matching algorithm that helps effectively retrieve the useful historical information for the prediction. There are three different MCB schemes with the different matching algorithms: MCB-ML that matches by the maximum likelihood criterion, MCB-FSNMI that matches with the proposed frequency sensitive normalized mutual information (FSNMI), and MCB-FSNMI-Bayes that matches by combining both the maximum likelihood method and the proposed prior information FSNMI. Besides the MCB schemes, the pair counting-based method and the Markovian method are also described. All these prediction schemes are evaluated and compared with the real data that were collected by an LEO satellite. It is validated that the Bayesian MCB scheme MCB-FSNMI-Bayes is the most proper scheme for the interference prediction here.
2. Problem Statement and System Description
The CMA in the LEO satellite uplink transmission is different from that on the ground because the electromagnetic environment of the satellite always keeps changing. As shown in Figure 1, for example, the LEO satellite moves around the earth for 5 times. Every time it passes the same latitude of the same hemisphere, the longitude has a small shift. It will take a very long time for the satellite to revisit the same place. Even if the satellite revisits the same place after a long time, the electromagnetic environment, however, may not be the same as before. So, the electromagnetic environment just keeps changing for an LEO satellite. Despite the fact mentioned above, the sensing results of the satellite may be similar in some cases. As shown in Figure 1, some of the interfering sources may be located at the overlapped covering area of the satellite antenna beams. The shadows in Figure 1 represent the covering areas of the satellite antenna beams. Therefore, the satellite may be interfered by the same interfering source while visiting the adjacent areas. And the interference samples collected by the satellite may be similar. This situation could happen when the satellite visits the adjacent areas in two adjacent passes as shown in Figure 1 or after a long time. However, it is difficult to utilize such similarities of the sensing results, because the similarities are hard to model without the prior knowledge about locations of the interfering sources. So, rather than using the widely used methods for CMA, we design a novel interference prediction scheme for the LEO satellite to utilize the global history effectively and efficiently. This scheme can be implemented with the onboard computational and storing capabilities of the satellite.

Changes of the electromagnetic environment in the LEO satellite uplink.
There is a special problem in designing the CMA in the LEO satellite uplink transmission: the overhead of the frequent spectrum handoffs is very expensive here. The connection between a small LEO satellite constellation and a terminal is very precious, because a small LEO satellite system can only support the transmission for a few times in a day. The uplink transmission cannot afford to be interrupted by the frequent spectrum handoffs. We prefer to predict the interference in the long run in order to avoid the frequent spectrum handoffs. Therefore, the observation time should firstly be segmented into a series of periods before the prediction. Then, the frequencies to be interfered could be predicted at the beginning of each period.
In our system, we firstly segment the observation time. After the proper segmentation, we can obtain some insight about the practical electromagnetic environment by observing the real data that were collected by an LEO satellite. Some of the real data are shown in Figure 2 for the illustration. In Figure 2, the values on the X-axis represent the time at which the interferences were sampled, and the values on the Y-axis represent the frequencies of the interferences. We think that some interference occurs at a specific time and frequency if the measured power level is higher than a given threshold. The dot points in Figure 2 represent the existences of the interferences in the 2-dimensional space. There are two subfigures in Figure 2, which represent the interference samples that were collected at different time. The samples shown in Figure 2(a) and those shown in Figure 2(b) are separated in time for about 7 days.

Stationary spectral distribution.
Firstly, it could be seen that both the samples in Figures 2(a) and 2(b) can be properly segmented into two periods. After the segmentation, the interferences in the first and in the second period of Figure 2(a) can be partitioned in frequency domain with two sets of rectangles that are called “spectrum partition 1” and “spectrum partition 2,” respectively. It can be inferred from the rectangles that we can partition in frequency domain the samples collected early and the samples collected later similarly for each well-segmented period. This phenomenon is named as the stationary spectral distribution (SSD) of interferences here. Moreover, it can be seen that the interference samples in Figure 2(b) are distributed similarly to those in Figure 2(a) in frequency domain. At the same time, the two spectrum partitions in Figure 2(b) are identical to those in Figure 2(a). This illustrates the similarities of the sensing results as mentioned above. It also shows the possibility of using the spectrum partition to find the similar interference samples.
SSD is reasonable if we think over the practical situations. In practice, the frequently occupied spectrum bands are dependent on the regions that the LEO satellite flies over. In a properly segmented period, all the sensing results might be collected over the same region. So, in such a period, the early observed interferences could be highly correlated with the later ones in frequency domain. Then, it is possible to represent the samples in a period with their spectrum partition by SSD. When there are two spectrum partitions similar to each other, the satellite may encounter the similar interferences.
By SSD, we can design a scheme to predict for each period the spectrum partition of the remaining samples with the spectrum partition of a few samples collected at the beginning. The spectrum partition of the coming interferences can be well predicted without observing all the samples. Furthermore, it is possible for us to find a similar spectrum partition by utilizing the historical information. Such a similar spectrum partition of the same samples can imply a similar spectral distribution of the interference samples. Therefore, the prediction and the similarity of the spectrum partitions can be combined to predict the frequencies that will be interfered in the long run.
Before the detailed description of the prediction method, we have several definitions to characterize the memorization of this history-based system. Firstly, we define in this paper the memorized period as the information of a period memorized by the system. The information contained in the memorized period depends on the prediction scheme we use. The memorized period stored by the prediction scheme above contains the reduced information, which consists of the memorized spectrum partition information (MSPI) and the frequencies that were interfered (FWI). MSPI is defined as the historical information that can guide the partition of the collected samples. It is extracted from the spectrum partition of the interference samples in the previous period. FWI is defined as the set of frequencies that have been interfered in the previous period. It can be obtained directly from the interference samples. However, the memorized period stored by some other schemes may need to contain the full dataset of the interferences. We also define the memory depth as the number of the memorized periods stored by the satellite onboard. The size of the memory depth is usually constrained by the onboard storing capability. More than one similar memorized period may be retrieved for the prediction. Then, we define the packet size as the number of the memorized periods that are retrieved. The true partition is defined as the most reasonable spectrum partition of the samples. Meanwhile, the memorized partition is defined as the partition of the samples with the memorized period. We can partition the samples in the normal way for the true partition and partition them with the MSPI of a memorized period to obtain the memorized partition.
So, the prediction procedure can be described in detail with the block diagram in Figure 3. For instance, we want to predict the frequencies that will be interfered for the first period in Figure 2(b). Firstly, we collect a few samples at the beginning of the period. After the collection, we can predict the spectrum partitions of the remaining samples in the period by SSD. The prediction of the spectrum partition is the true partition here. Then, we utilize the memorized periods to obtain the memorized partitions and try to find the memorized partitions that are most similar to the true partition. According to Figure 2, we can examine the first period in Figure 2(a). In Figure 2, the “spectrum partition 1” can be regarded as the MSPI of this period. Moreover, since the samples in the first period in Figures 2(b) and 2(a) have the same spectrum partition, the memorized partition mentioned above will be similar to the true partition. Then, the FWI of the first period in Figure 2(a) can be retrieved for prediction. Because the similar spectrum partitions may represent the similar spectral distributions of the interference samples, we can predict that the frequencies in the retrieved FWI may also be interfered in the remaining time of the first period in Figure 2(b). This method can achieve the long-term prediction of interference and help us save the onboard computational and storing resources.

Prediction procedure.
We have described the long-term onboard prediction procedure that is inspired by the observation of the real interference samples. However, the generation, the storing, and the comparison of the spectrum partitions need to be further refined for the implementation. Here, we propose the onboard interference prediction scheme memorized centroid bucket (MCB) whose system model is shown in Figure 4. In this model, the spectrum can be fully observed by the full spectrum sensing, and we predict the interferences for the current period. Firstly, a few samples are collected by the initial scan at the beginning of the current period. At the same time, the interference samples in the last period are clustered in frequency domain so as to obtain a set of centroids that represent the mean frequencies of the different clusters of samples. With the set of centroids, the interference samples can be partitioned in frequency domain by the nearest centroid rule. The set of centroids can represent the MSPI of the last period. Thus, the memorized period that consists of the MSPI and the FWI of the last period is stored in the centroid bucket. The centroid bucket is the component that stores the memorized periods. Then, we need to compare the spectrum partitions and retrieve the similar memorized periods. There is a matching algorithm in the system that matches the samples collected in the initial scan to the most similar memorized periods. There are three different kinds of MCB schemes with the different matching algorithms.

System model of the memorized centroid bucket scheme.
The matching can be achieved in a direct way with the memorized periods and the data collected in the initial scan. We calculate the likelihood of the collected samples given the different MSPI. By the maximum likelihood criterion, the memorized periods, whose MSPI will lead to the maximal likelihood, are matched, and their FWI are retrieved for the prediction (MCB-ML). Furthermore, we can match the samples collected in the initial scan more efficiently by comparing the true partition and the memorized partitions of them. These two kinds of partitions of the collected samples will be described in Section 3.2. The result of the comparison is the proposed prior information FSNMI. FSNMI can be used alone to match the samples and predict the interferences (MCB-FSNMI). We can also combine FSNMI with the maximum likelihood method to match the samples in a Bayesian way (MCB-FSNMI-Bayes). The prior information FSNMI can complement the maximum likelihood method by utilizing the samples in the initial scan as a whole. By comparing the three MCB schemes with the prediction procedure shown in Figure 3, it can be shown that MCB-FSNMI-Bayes is the full implementation of the procedure, while the other two schemes are the simplified ones.
3. Matching and Prediction Algorithms
We have described SSD, the prediction procedure, and the system model of the MCB schemes as above. However, the feasibility and the performances of the MCB schemes are highly related to the matching algorithms that can help retrieve the useful historical information. The difficulty in designing such a matching algorithm lies in the efficient utilization of the small amount of data that are collected in the initial scan. After matching, we will predict the frequencies to be interfered in the remaining time of the current period.
In this section, we propose the different matching algorithms of the MCB schemes, and the pair counting-based method as well. Then, the prediction strategy based on the retrieved historical information is introduced, and the Markovian predictor is also analyzed. It will be shown that the Markovian method is suboptimal to the problem.
The memory depth and the packet size are represented with L and M, respectively. It is assumed that the current period is the sth period in sequence. In Figure 2, the interference samples are plotted in a 2-dimensional space of time and frequency. However, after the proper time segmentation, the samples X and Y discussed in the following sections are the frequencies of the interferences.
3.1. Matching by Pair Counting
Before introducing the matching algorithms for the information retrieval in the MCB schemes, we firstly discuss a more direct yet inefficient method: the pair counting-based method. The interference samples in two periods are compared by counting the number of the occurrences of interference at different frequencies. The interference samples in two periods are regarded as similar to each other if the interference often occurs at the same frequencies. The similarity can be calculated in a similar way as introduced in [21]. Suppose that the interference occurs at the frequency

The pair counting-based matching algorithm is designed based on (1) as in Algorithm 1.
Calculate Sim(s, i) between Store Sim(s, i) in Find the Find the FWI with the same sequence number. (Matching)
This method does not need to be implemented in the same way as the MCB. However, the memorized periods of the scheme need to contain all the interference samples and the corresponding FWI in the previous L periods. This is inefficient and unrealistic considering the storing capability of an LEO satellite. Moreover, it is not an effective method for us to compare the initial scan with a memorized period, since the data collected in an initial scan is usually too small to use here and the complete dataset contains the disturbing noise. This conclusion is validated by the experiments on the real data. So, we need to design some other matching algorithms further.
3.2. Spectrum Partition
The MCB schemes are based on the spectrum partitions of the interference samples in frequency domain. We reduce the interference samples in a period to their MSPI in MCB. Here, the partitioning is carried out by clustering the samples with the most well-known centroid algorithm K-means [22]. This algorithm is used to implement the “clustering for the MSPI” and the “clustering” block in Figure 4. The input of the block is the spectral information of all the interference samples, and the output is the centroid set that represents the mean frequencies of the different clusters of interference samples.
K-means is an iterative algorithm that will converge after iterating for enough times. It should be noticed that the final results are dependent on the initial centroids to a great extent. So, we assume that the initial centroids are the same for all the periods to make the partitions consistent. And, it is reasonable to place the initial centroids evenly in frequency domain. Let the number of the initial centroids be N. For the example of the ith period, the kth initial centroid should be placed at the frequency

After t iterations, the centroid will be moved to
Some of the centroids may vanish as the algorithm iterates. However, we still keep the initial indexes
The samples collected in the initial scan can be partitioned in frequency domain by K-means for the true partition. In a true partition, the samples belong to the different clusters in frequency domain, and thus they are well partitioned. On the other hand, the samples can also be partitioned in frequency with the MSPI for the memorized partition. With the set of centroids that represent the MSPI, the spectrum can be partitioned by the nearest centroid rule. By the nearest centroid rule, a given sample is attributed to the cluster whose centroid is nearest to it in frequency domain. Therefore, the interference samples are partitioned with a given set of centroids in frequency domain. Clustering is not new to spectrum sensing [23, 24] where it is often used to divide the groups of nodes in the cognitive radio networks. But it is now used to partition spectrum for the data reduction and information retrieval.
3.3. Matching Algorithms in MCB
The samples in the initial scan are matched to the memorized periods properly in MCB in order to retrieve the historical information. In fact, MCB could match by SSD not only the initial scan but also the rest of the current period in a predictive way. With the MSPI, the ideal way to match is based on the posterior probability of the set of centroids given all the samples in the sth period. The sets of centroids that have the highest posterior probabilities are matched to the sth period. Although by the initial scan we only collect a few samples instead of all the samples in the period, we can approximate the posterior probability by SSD. The matching algorithm based on the posterior probability is a Bayesian algorithm. Here, we derive the basic formula of this Bayesian matching algorithm and design a simplified version of the algorithm by the maximum likelihood criterion. The Bayesian algorithm will be described in Section 3.4.
We utilize here not only the w frequency samples

The distribution of R can be inferred from that of X, though the data in R are unknown to us. It can be further assumed that the data in R are almost certain if X is already known. Thus, we can approximate
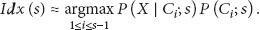
The prior probability
According to K-means, the elements of each cluster are assumed to scatter around their centroid by Gaussian distribution, and the variances of the different clusters in each period are the same. The variance


The matching algorithm of MCB-ML is designed based on (6) as in Algorithm 2.
Find the centroid Calculate Store Find the Find the FWI with the same sequence number. (Matching)
For this maximum likelihood algorithm, the number of the samples collected in the initial scan is usually too small, and each of the samples is treated individually. Furthermore, a Bayesian algorithm is more suitable to deal with such small data. The performance will be improved if we obtain a reasonable prior
3.4. Frequency Sensitive Normalized Mutual Information
We only have the incomplete information in the matching process of MCB. This incomplete information consists of the MSPI, the FWI, and a few samples collected in the initial scan of the current period. This information is not sufficient for many statistical methods. However, by SSD, some extra information can be obtained by computing the similarities between the true partition and the memorized partitions of the same samples collected in the initial scan. This information is the frequency sensitive normalized mutual information (FSNMI).
Besides the partitions and the likelihood that we calculate in Section 3.3, we also take into account the initial indexes
We utilize the samples collected in the initial scan as a whole by extracting the spectral partition information of them. By clustering, we can obtain the true partition of these samples. According to SSD, the true partition of the samples contains the correlated information between the collected data X and unknown data R. So, the samples collected in the initial scan are treated altogether by clustering. Therefore, it is possible to learn the prior information
It is assumed that the true partition of X in the sth period consists of the nonoverlap subsets (clusters)
Table of the two partitions.

The similarity between two partitions of the same samples can be quantified by computing the normalized mutual information (NMI) between them [21]. Let 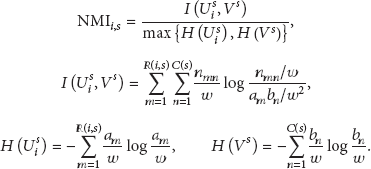
However, NMI is not sufficient to represent the similarity between the spectrum partitions. It is only related to the partitions of the samples, and it cannot represent the positions of the interferences in frequency domain. So, the prior information is further learnt by adding some frequency sensitive information to NMI. It is useful to utilize the relationship that the less difference of the spectral positions between two sets of centroids implies the more similarity between them. The precise frequencies of the centroids are not used as the frequency sensitive information. Rather, we represent the information with the initial indexes 
Thus, the memorized periods are matched in MCB-FSNMI by (7) and (8). The algorithm is designed as in Algorithm 3.
Cluster Partition Store Find the Find the FWI with the same sequence number. (Matching)
Furthermore, the Bayesian method MCB-FSNMI-Bayes can be obtained if we combine MCB-ML with the learnt prior information FSNMI. Then the formula in the matching algorithm can be derived from (4) and (5) as follows:
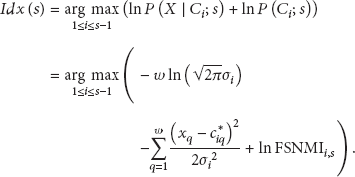
According to (9), the distance 
The matching algorithm of MCB-FSNMI-Bayes is designed based on (10) as in Algorithm 4.
Cluster Partition Find the centroid Calculate Store Find the Find the FWI with the same sequence number. (Matching)
3.5. Prediction and Evaluation
After the matching process, we can make the long-term predictions with the matched results, which predict the frequencies to be interfered in the remaining time of the current period. The frequencies that are predicted to be idle may be used by the system in the remaining time of the current period. The length of the initial scan is very short in time, and the remaining time is often several tens of times longer. This proactive CMA enables the long-term occupation of the same channel. It is very important to the transmission of an LEO satellite, because the overhead of the spectrum handoff for the CMA in the LEO satellite uplink is much more expensive than that for the terrestrial CMA system. The spectrum handoff during a period happens when the long-term prediction fails, which is, however, not the topic of this study. Our focus here lies on the long-term interference prediction whose performance determines the feasibility of the CMA in our system. The performance is evaluated by the
The MCB schemes and the pair counting-based method have the same strategy to predict with the matched results. The matched results are the FWI of the M retrieved memorized periods. It is reasonable to predict that the same frequencies are to be interfered again for the rest of the current period. A larger packet size will lead to a higher 
There may be some loss in performance when using OR rule to merge the information of the different memorized periods. The different matched memorized periods are treated equivalently if OR rule is used. A more sophisticated strategy, for example, a weighting strategy could be utilized to merge the information, which may improve the performance. Such a strategy should be designed carefully, and it needs to be further investigated.
The MCB schemes and the pair counting-based method should also be compared with the widely used Markovian method. It is assumed in [12, 13] that the system can fully observe the spectrum, which is the same as our system. We can model the occurrences of interferences in each period as a Markov chain reasonably for our problem. The channels are regarded to be available as long as the collision rate is kept below some interference constraints. The experimental test bed in [13] measures the throughput and collision rate experimentally. It also adjusts the transmission rate so that the interference constraint can be met. For example, a randomized policy is adopted to transmit in the idle channel with the lowest interference arrival rate, so that the interference level is lower than the cumulative interference constraint. Here the interference arrival rate represents the rate of the interference occurrences. We define this rate as λ and the transmission slot duration as T for a specific channel. In our system, T could represent the length of a well-segmented period. In [12], the expected immediate cost d for communicating in the channel can be computed as follows:

To achieve the long-term proactive CMA with the Markovian method above, we observe each channel for some time and evaluate it with the immediate cost d. In the prediction, all the channels are assumed as available beforehand, but they need to be evaluated by the immediate costs. The channels whose immediate costs exceed the predefined threshold are predicted to be interfered sometimes in the current period. It is not needed to use OR rule to merge the different matched results here. The Markovian prediction algorithm is designed as in Algorithm 5.
Collect all the samples in Calculate λ for all the frequencies (channels) with the collected samples and T. Calculate d for all the frequencies (channels) with λ and T by (12). Find the frequencies (channels) that have a d greater than the predefined threshold. (These found frequencies (channels) will be interfered in the remaining time of the sth period.)
Compared with MCB, the Markovian method cannot utilize the global history efficiently. In the Markovian method, the parameters, such as the arrival rate, are usually assumed as constant. However, the interference arrival rate in our problem varies as the LEO satellite moves around the earth. Thus the Markovian method will treat the interferences of different regions equivalently. As the memory depth gets larger, MCB could retrieve some more similar memorized periods and perform better while the prediction of the Markovian method is suboptimal. Apart from the variables T and L defined above, 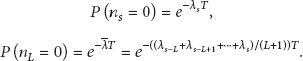
To evaluate the performance, we firstly compute 
Moreover, we need a measure to evaluate both 

4. Experiments on the Real Dataset
In this section, we compare the performances of the different predictors with the real sensing data collected by an LEO satellite. The three different MCB schemes, the pair counting-based method, and the Markovian method are compared here. The performance of the interference prediction in the practical situations can be evaluated with the real data. The data are collected by sensing the spectrum, which is 1.6 MHz in width and 19.2 KHz in resolution. The spectrum is sensed in a parallel way so that the spectrum is fully observable here. The central frequency of the spectrum band is in the L-band, in which the mobility effects, such as multipath, shadowing, and blockage, play the main role in characterizing the channel [11]. These data are collected in about 126 hrs, and the observation time is segmented into 75 periods. Each period is about 1.7 hrs long. Without loss of generality, the spectrum information is only collected over some specific regions. In MCB, only a few samples are collected for the initial scan. Here, we only take the first 10 samples in each period to predict the frequencies that are likely to be interfered for the rest of the current period. The interferences are predicted in each of the 75 periods. The performances in all the periods are considered together and the average scores are used to evaluate the overall performance of the predictor in all the situations encountered.
4.1. Selection of the Packet Size
There is a tradeoff between

Evaluation of the packet size by the

Evaluation of the packet size by the
The test shows the changes of the performances as the packet sizes increase. As shown in Figures 5 and 6, the difference between the results evaluated by the
Besides the results analyzed above, it should also be noticed that the performance of the scheme MCB-FSNMI will not get deteriorated as the packet size increases since the matching algorithm of MCB-FSNMI is not a strong algorithm as the others. This algorithm cannot find enough memorized periods as the packet size increases. Therefore, there will not be too many memorized periods matched to deteriorate the performance in MCB-FSNMI. Despite the advantage, the scheme has the worst performance among all the four schemes. So, FSNMI can only be utilized to assist the other schemes as it does in MCB-FSNMI-Bayes.
It can also be shown that MCB-FSNMI-Bayes outperforms both MCB-ML and the pair counting-based method if the packet sizes are selected properly. This is because MCB-FSNMI-Bayes can utilize all the samples collected in the initial scan as a whole, which can provide some extra information for the matching and the corresponding prediction. The best performance of MCB-ML is comparable to that of the pair counting-based method since both of them treat the samples collected in the initial scan independently. Moreover, the optimal choices of the packet size for both MCB-ML and MCB-FSNMI-Bayes are the same. The best choice of the packet size is 2 for both the schemes. It can be reasoned by the fact that MCB-FSNMI-Bayes is based on MCB-ML, and FSNMI is not a strong factor in choosing the packet size as mentioned above.
The packet size is an important parameter that has an impact on the performance of the predictor. So, the predictors with different packet sizes are incomparable when we evaluate the performances with different memory depths in test (Section 4.2). It is important to have the same packet size for all the schemes in the related tests. Therefore, it is better to set the packet size as 2 for all the schemes in test (Section 4.2), though the best packet size is 4 for the pair counting-based method. This choice will not affect the comparison of the best performances among the four schemes given the optimal packet sizes. It will make the comparison in test (Section 4.2) more plausible.
4.2. Utilization of the Global History
The utilization of the global history is the most important in designing the interference predictor for the CMA in the LEO satellite uplink. The memory depth is defined as the number of the memorized periods utilized for the prediction, which can represent the length of the history utilized. The dataset with a large memory depth contains the global history of interferences. Therefore, we can evaluate how well a predictor utilizes the global history by observing the change of its performance as the memory depth increases. The predictor can utilize the global history well if its performance increases dramatically and keeps increasing as the memory depth increases. In this test, we analyze for each predictor the change of the performance. We measure the performances of the different predictors given the different memory depths by the
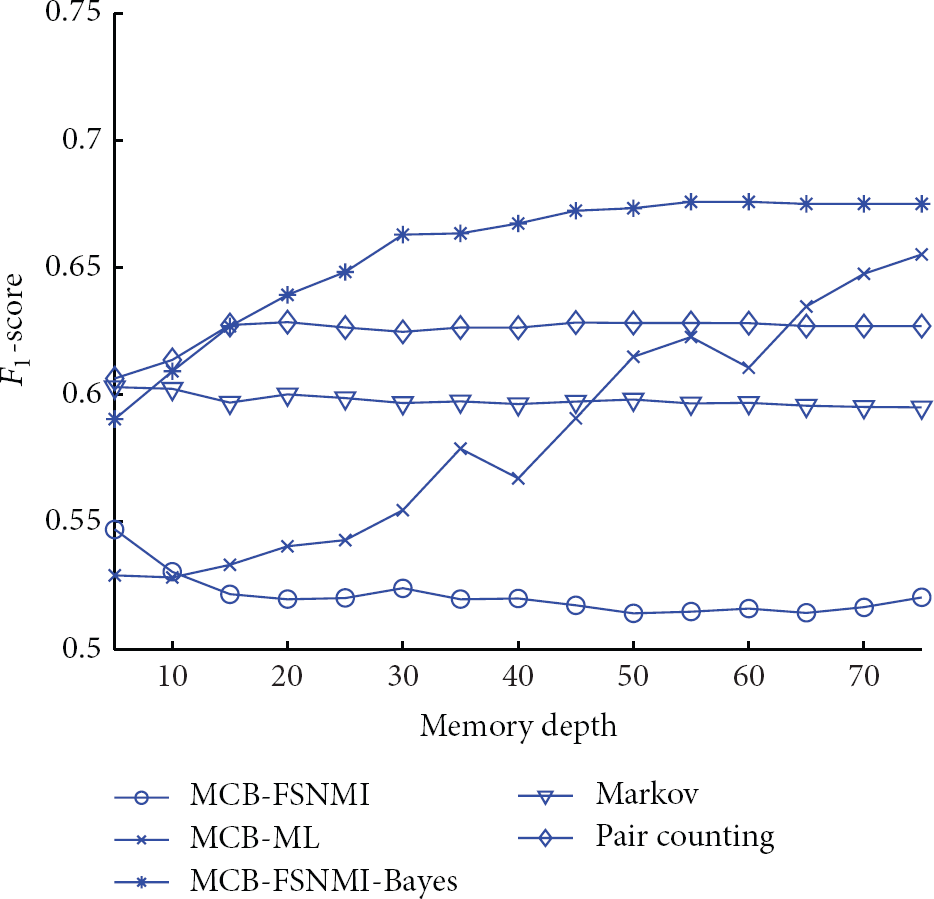
Comparisons under the different memory depths by the

Comparisons under the different memory depths by the
As shown in Figures 7 and 8, the difference between the results evaluated by the
MCB-ML works poorly when the memory depth is no larger than 40. However, its performance is improved dramatically as the memory depth increases. Finally, it is the second best among all the predictors when the memory depth is no less than 65. The scheme works poorly given a small memory depth because it is designed by the maximum likelihood criterion. The likelihood in matching the different memorized periods may be close to each other if there is no prior information and the memory depth is small. Thus, the error could happen when the likelihood is used for the matching and the corresponding prediction. It is well known that the maximum likelihood algorithm always works poorly when the dataset is not big enough. The predictor could be misled by the data before the correct information is obtained from a large dataset. Therefore, it can be concluded that MCB-ML can utilize the global history, but its performance is constrained by the size of the dataset seriously. MCB-ML cannot perform well when the memory depth is not large enough. Even if the memory depth is 75, it is still inferior to MCB-FSNMI-Bayes since the Bayesian method can be assisted by the prior information.
MCB-FSNMI works poorly when the memory depth is 5, and it works even more poorly as the memory depth increases. The scheme cannot distinguish the different memorized periods effectively. As analyzed in test (Section 4.1), it is improper to use FSNMI alone for the matching and the corresponding prediction.
It is better to use FSNMI as the assistant information for the other schemes. For example, we combine FSNMI with MCB-ML to obtain the Bayesian scheme MCB-FSNMI-Bayes. The scheme is inferior to the pair counting-based method when the memory depth is no larger than 15. But its performance can increase dramatically in Figures 7 and 8 when the memory depth is no larger than 30. And it still keeps increasing slowly when the memory depth is even larger. Compared with MCB-ML, its performance is much better when the memory depth is less than 45. The reason is that the scheme can avoid the misleading of the small dataset by utilizing the prior information FSNMI. And, even if the memory depth is 75, the scheme still works better than MCB-ML. MCB-FSNMI-Bayes is the best of all when the memory depth is larger than 15 since it can utilize both the global history and the samples collected in the initial scan as a whole.
The Markovian method is better than MCB-FSNMI-Bayes and MCB-ML when the memory depth is no larger than 5 and 45, respectively. However, its performance cannot be improved as the memory depth gets larger. On the contrary, the performance gets even slightly worse when more memorized periods are used for the statistics. The Markovian method cannot utilize the global history and the performance is not desirable as the memory depth increases. This is because the method always assumes the constant parameters and thus it cannot deal with global history of the interferences.
4.3. Probability of Detection and the Spectrum Loss Rate
The performances of the predictors have been evaluated by the
We evaluate the overall performances of the predictors with the

Comparison of MCB-FSNMI-Bayes and the Markovian method by the

Comparison of MCB-FSNMI-Bayes and the Markovian method by the

Comparison of MCB-FSNMI-Bayes and the pair counting-based method by the
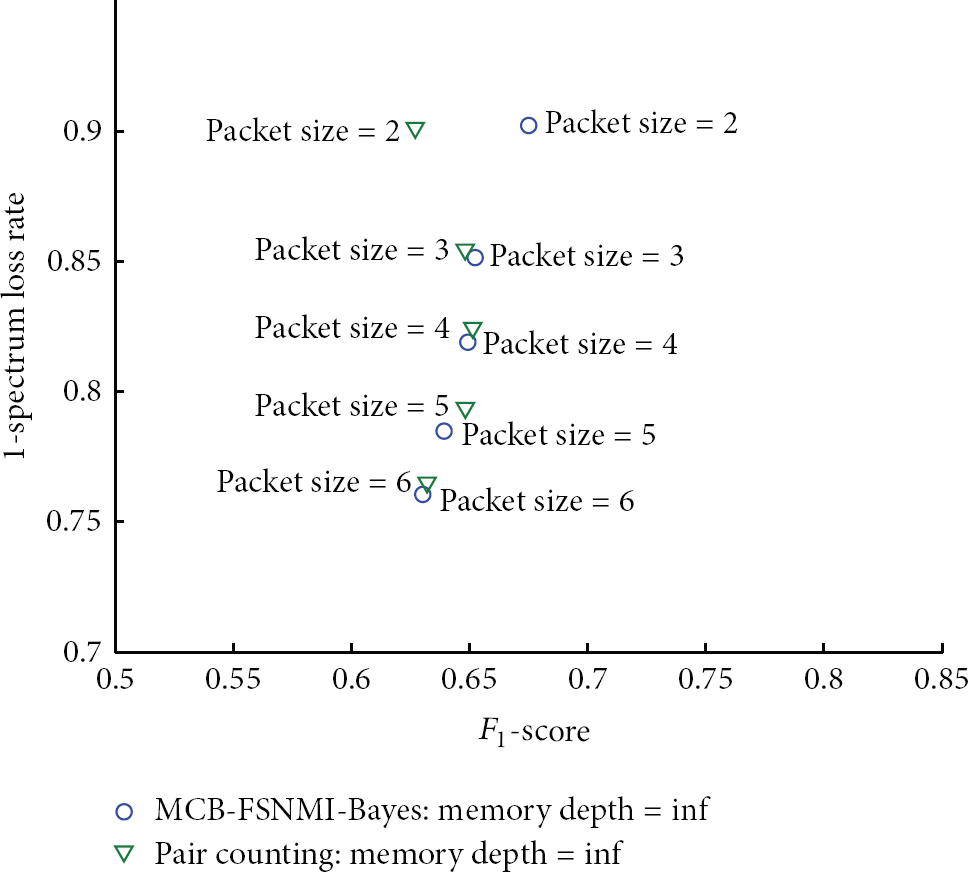
Comparison of MCB-FSNMI-Bayes and the pair counting-based method by the
The values on the Y-axis of Figures 9 and 11 represent
The memory depths of the predictors are set to be optimal according to the results in test (Section 4.2). The memory depths of both the MCB-FSNMI-Bayes and the pair counting-based method are set as infinite. It is because the performances will not get deteriorated as the memory depth increases. But the memory depth of the Markovian method is set to be 5, since the method cannot utilize the global history and its performance gets slightly worse as the memory depth increases. For MCB-FSNMI-Bayes and the pair counting-based method, the different
As shown in Figure 9, MCB-FSNMI-Bayes has a higher
It can be concluded from the results in Figures 9 and 10 that MCB-FSNMI-Bayes has a better performance than the Markovian method under the specific requirement of
We also compare MCB-FSNMI-Bayes with the pair counting-based method in the same way. The results in Figures 11 and 12 also show that MCB-FSNMI-Bayes has a higher
5. Conclusion
The onboard interference prediction for the CMA in the LEO satellite uplink transmission is difficult because of the global history of interferences and the limited onboard storing capability of the LEO satellite. Moreover, a long-term interference prediction is important for the LEO satellite to avoid the expensive overhead of the frequent spectrum handoff. In this study, we design the MCB scheme that can efficiently utilize the global history by SSD for the prediction. There are three different MCB schemes with the different matching algorithms. Among the MCB schemes, the best one is MCB-FSNMI-Bayes that can treat the samples collected in the initial scan as whole and utilize the proposed prior information FSNMI as well. The different MCB schemes are also compared with the pair counting-based method and the Markovian method. Compared with MCB-FSNMI-Bayes, the pair counting-based method is neither effective nor efficient, and the Markovian method can only utilize the local history of interferences rather than the global one. So, the proposed method MCB-FSNMI-Bayes is the most proper scheme for the interference prediction here. All these conclusions are validated experimentally with the real interference data that were collected by an LEO satellite. The experiments on the real data assure that the proposed schemes are suitable for the practical use.
Footnotes
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.